Discusión sobre el artículo "Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC)"
{kind=link}
Dmitry, gracias por tu duro trabajo. Todo está funcionando.
Recojo ejemplos por Expert Advisor Investigación para 100 pases, entrenar el modelo por Expert Advisor Estudio, prueba con Test. Luego recojo 50 pases de nuevo, entreno durante 10 000 iteraciones, pruebo de nuevo.
Y así sucesivamente hasta que el modelo aprenda. Excepto que tengo hasta ahora Prueba constantemente da resultados diferentes después del ciclo y no siempre positivo. He ejecutado un ciclo, 2-3 pruebas y los resultados son diferentes.
¿En qué ciclo se estabilizará el resultado? ¿O es un trabajo sin fin y el resultado siempre será diferente?
Gracias.
Y así sucesivamente hasta que el modelo aprenda. Salvo que hasta ahora Test da constantemente resultados diferentes después del ciclo y no siempre positivos. Es decir, ejecuto un ciclo, 2-3 pruebas y los resultados son diferentes.
¿En qué ciclo el resultado será estable? ¿O es un trabajo sin fin y el resultado siempre será diferente?
Gracias.
El Asesor Experto entrena un modelo con una política estocástica. Esto significa que el modelo aprende las probabilidades de maximizar las recompensas por realizar determinadas acciones en determinados estados del sistema. A medida que interactúa con el entorno, las acciones se muestrean con las probabilidades aprendidas. En la fase inicial, las probabilidades de todas las acciones son las mismas y el modelo selecciona una acción al azar. En el proceso de aprendizaje, las probabilidades cambiarán y la elección de las acciones será más consciente.
Hola Dmitry, ¿cuántos ciclos te tomó como Nikolay descrito anteriormente para obtener un resultado positivo estable?
Y otra cosa interesante es que si un Asesor Experto aprende para el periodo actual y si por ejemplo dentro de un mes habrá que volver a entrenarlo teniendo en cuenta los nuevos datos, ¿se volverá a entrenar completamente o antes de aprender? ¿El proceso de entrenamiento será comparable al inicial o mucho más corto y rápido? Y también si hemos entrenado un modelo sobre EURUSD, entonces para trabajar sobre GBPUSD ¿se reentrenará tanto como el inicial o será más rápido justo antes de entrenar? Esta pregunta no es acerca de este artículo en particular de los suyos, sino de todos sus asesores expertos que trabajan en el principio de aprendizaje por refuerzo.
Buenos días.
Dimitri, gracias por tu trabajo.
Quiero aclarar para todos...
Lo que Dimitri publica no es un "Grial".
Es un ejemplo clásico de problema académico, que implica la preparación para actividades de investigación científica de carácter teórico y metodológico.
Y todo el mundo quiere ver un resultado positivo en su cuenta, aquí y ahora....
Dmitry nos enseña a resolver (nuestro/mío/vuestro/su) problema con todos los métodos presentados por Dmitry.
¡¡¡¡Popular AI (GPT) tiene más de 700 millones de parámetros!!!! ¿Cuánto cuesta esta IA?
Si quieres conseguir un buen resultado, intercambia ideas (añade parámetros), da resultados de pruebas, etc.
Crea una sala de chat separada y "consigue" el resultado allí. Puedes presumir aquí :-), mostrando así la eficacia del trabajo de Dmitry...
Crea una sala de chat separada y "consigue" el resultado allí. Puedes presumir aquí :-), mostrando así la eficacia del trabajo de Dmitry...
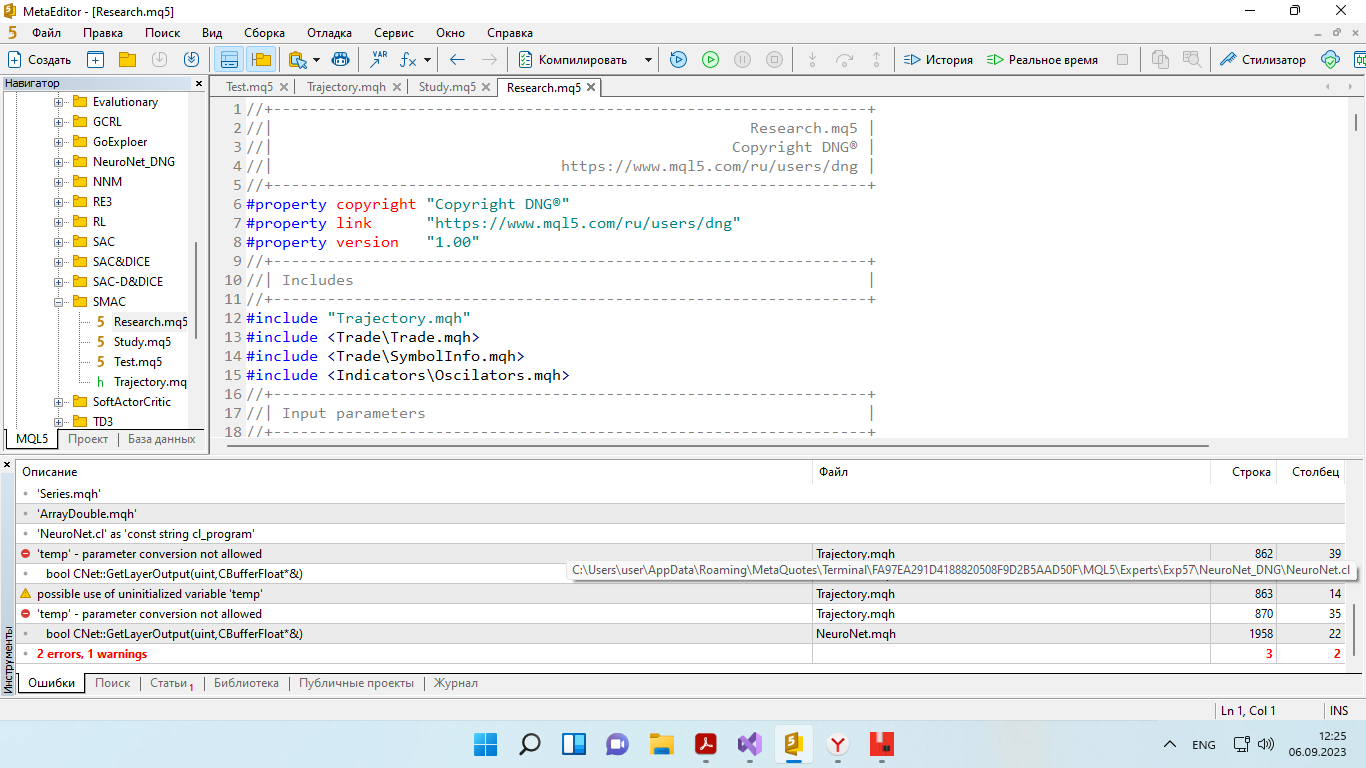
Amigo, ¡aquí nadie está esperando el grial! Sólo me gustaría ver que lo que pone Dmitriy funciona de verdad. No por las palabras de Dmitry en sus artículos (todos sus artículos tienen resultados casi positivos), sino en mi ordenador. He descargado su Asesor Experto de este artículo y ya he hecho 63 ciclos de entrenamiento (recopilación de datos -> entrenamiento). Y todavía está perdiendo dinero. Para todos los 63 ciclos sólo había un par de colecciones de datos, cuando de 50 nuevos ejemplos había 5-6 positivos. Todo lo demás es negativo. ¿Cómo puedo ver que realmente funciona?
Le pregunté a Dmitriy en el post anterior, no respondió nada. El mismo problema en otros artículos - no hay resultado por mucho que entrenes.....
Amigo, si usted consiguió un resultado estable, a continuación, escriba cuántos ciclos que hizo antes de resultado estable, por ejemplo en este artículo? Si cambiar, ¿qué cambiar para ver el resultado en el equipo, sólo en el probador? No es un grial, pero al menos para ver que funciona?
Crea un CHAT aparte y "consigue" el resultado allí. Puedes presumir aquí :-), mostrando así la eficacia del trabajo de Dmitry ...
Aquí están los Params: (basado en Dmitry y algunas investigaciones.)
#include "FQF.mqh"
La longitud del mensaje no debe superar los 64000 caracteres
===CORTÉ LAS ÚLTIMAS PARTES ya que los Comentarios están limitados a 64000 Caracteres pero ya sabes lo que hay que hacer... =)
La longitud del mensaje no debe superar los 64000 caracteres
{kind=link}
{kind=link}
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC):
Hoy le proponemos introducir un algoritmo bastante nuevo, el Stochastic Marginal Actor-Critic (SMAC), que permite la construcción de políticas de variable latente dentro de un marco de maximización de la entropía.
Al construir un sistema comercial automatizado, desarrollamos algoritmos para la toma de decisiones secuenciales. Los métodos de aprendizaje por refuerzo tienen por objeto resolver este tipo de problemas. Uno de los retos clave en el aprendizaje por refuerzo es el proceso de exploración, en el que el Agente aprende a interactuar con el entorno. En este contexto, el principio de máxima entropía se usa a menudo para motivar al Agente a realizar acciones con el mayor grado de aleatoriedad. Sin embargo, en la práctica, dichos algoritmos entrenan Agentes simples que solo aprenden cambios locales en torno a una única acción. Esto se debe a la necesidad de calcular la entropía de la política del Agente y usarla como parte del objetivo del entrenamiento.
Al mismo tiempo, un enfoque relativamente sencillo para aumentar la expresividad de la política del Agente sería utilizar variables latentes que proporcionen al Agente su propio procedimiento de inferencia para modelar la estocasticidad en las observaciones, el entorno y las recompensas desconocidas.
La introducción de variables latentes en la política del Agente permitirá abarcar una mayor variedad de escenarios compatibles con la historia de observaciones. Aquí cabe señalar que las políticas con variables latentes no admitirán una expresión sencilla para definir su entropía. Una estimación ingenua de la entropía puede provocar fallos catastróficos en la optimización de las políticas. Además, las actualizaciones estocásticas con alta varianza para maximizar la entropía no distinguen de inmediato entre efectos aleatorios locales y exploración multimodal.
Una de las soluciones a estas deficiencias de las políticas de variables latentes se ofreció en el artículo "Latent State Marginalization as a Low-cost Approach for Improving Exploration". En él, los autores proponen un algoritmo de optimización de políticas sencillo pero eficaz que puede posibilitar una exploración más eficiente y robusta tanto en entornos totalmente observados como parcialmente observados.
Autor: Dmitriy Gizlyk