Discusión sobre el artículo "Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas"
 Buenas tardes.
Buenas tardes.
Dmitry, ¿dónde conseguir las funciones values.Assign y MathRandomNormal? Tus scripts no están construidos y hacen referencia a la ausencia de estas funciones. El archivo VAE.mqh es rechazado.
Buenas tardes.
Dmitry, ¿dónde conseguir las funciones values.Assign y MathRandomNormal? Tus scripts no están construidos y hacen referencia a la ausencia de estas funciones. El archivo VAE.mqh es rechazado.
Buenos días, Victor.
En cuanto a values.Assign, intenta actualizar el terminal. Se trata de una función incorporada recientemente en MQL5. MathRandomNormal está incluida en la librería estándar del terminal y se añade en el fichero "\MQL5\Include\Math\Stat\Normal.mqh" .
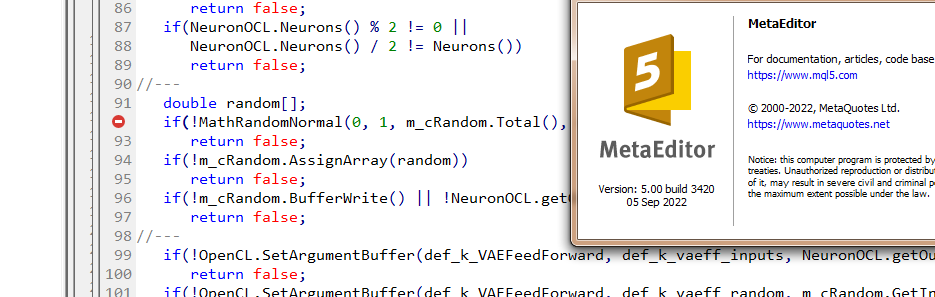
Dmitry Tengo la versión 3391 de terminal del 5 de agosto de 2022 (última versión estable). Ahora he intentado actualizar a la versión beta 3420 del 5 de septiembre de 2022. El error con values.Assign ha desaparecido. Pero el error con MathRandomNormal no desaparece. Tengo una biblioteca con esta función en la ruta tal como escribiste. Pero en el archivo VAE.m qh no tiene una referencia a esta biblioteca, pero en el archivo NeuroNet.mqh especifica esta biblioteca de la siguiente manera:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Pero no es así como yo lo tengo montado. :(
PD: Si especifico la ruta a la librería directamente en el fichero VAE.mqh. ¿Es posible hacer eso? No entiendo muy bien cómo se pone la librería en el fichero NeuroNet.mqh, ¿no habrá un conflicto?
He intentado añadir la línea #include <Math\Stat\Normal . mqh> directamente en el archivo VAE .mqh, pero no ha funcionado. El compilador sigue escribiendo 'MathRandomNormal' - identificador no declarado VAE.mqh 92 8. Si borras esta función y empiezas a escribir de nuevo, aparece un tooltip con esta función, que, según tengo entendido, indica que se puede ver desde el fichero VAE.mqh.
En general, he probado en otro ordenador con una versión diferente incluso de la vinda, y el resultado es el mismo - no ve la función y no compila. mt5 última versión betta 3420 del 5 de septiembre de 2022.
Dmitry, ¿tiene alguna configuración habilitada en el editor?
En general, lo he probado en otro ordenador con otra versión de Windows, y el resultado es el mismo - no ve la función y no compila. mt5 última versión betta 3420 del 5 de septiembre de 2022.
Dmitry, ¿tienes alguna configuración habilitada en el editor?
Prueba a comentar la línea"namespace Math
Dmitry Tengo la versión 3391 de terminal del 5 de agosto de 2022 (última versión estable). Ahora he intentado actualizar a la versión beta 3420 del 5 de septiembre de 2022. El error con values.Assign ha desaparecido. Pero el error con MathRandomNormal no desaparece. Tengo una biblioteca con esta función en la ruta tal como escribiste. Pero en el archivo VAE.m qh no tiene una referencia a esta biblioteca, pero en el archivo NeuroNet.mqh especifica esta biblioteca de la siguiente manera:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Pero así no es como estoy consiguiendo que funcione. :(
PD: Si directamente en el archivo VAE.mqh especificar la ruta a la biblioteca. ¿Es posible hacer eso? No entiendo muy bien cómo se pone la librería en el archivo NeuroNet.mqh, ¿no habrá conflicto?
3445 del 23 de septiembre - lo mismo.
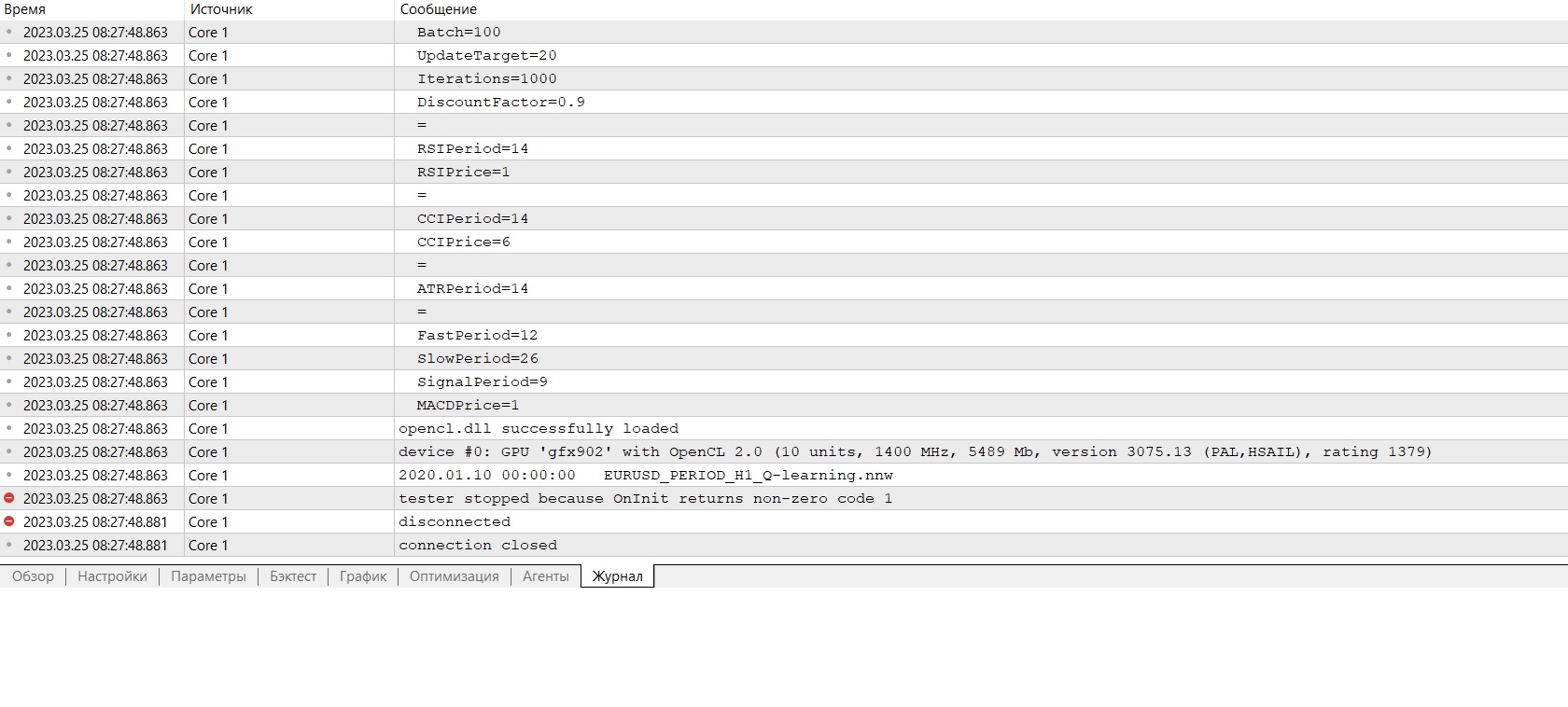 Hola.
Hola.
Necesito consejo :) Acabo de entrar en el terminal después de la reinstalación, quiero hacer la formación y da un error
{kind=link}
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas:
Continuamos analizando los métodos de aprendizaje por refuerzo. En el artículo anterior, nos familiarizamos con el método de aprendizaje Q profundo, en el que entrenamos un modelo para predecir la próxima recompensa dependiendo de la acción realizada en una situación particular. Luego realizamos una acción según nuestra política y la recompensa esperada, pero no siempre es posible aproximar la función Q, o su aproximación no ofrece el resultado deseado. En estos casos, los métodos de aproximación no se utilizan para funciones de utilidad, sino para una política (estrategia) de acciones directa. Precisamente a tales métodos pertenece el gradiente de políticas o policy gradient.
Primero pusimos a prueba el modelo de DQN. Y aquí nos esperaba una sorpresa inesperada. El modelo obtuvo beneficios, pero al mismo tiempo, solo realizó una operación comercial, que estuvo abierta durante toda la prueba. El gráfico del instrumento con la transacción realizada se muestra a continuación.
Al evaluar la transacción en el gráfico de instrumentos, no podemos dejar de estar de acuerdo con que el modelo ha identificado claramente la tendencia global y ha abierto una transacción en su dirección. La transacción es rentable, pero nos queda una pregunta sin respuesta: ¿será capaz el modelo de cerrar a tiempo una transacción así? En realidad, hemos entrenado el modelo con datos históricos de los últimos 2 años, y durante los 2 años, el mercado ha estado dominado por una tendencia bajista para el instrumento analizado. Por lo tanto, nos preguntamos si el modelo podrá cerrar la transacción a tiempo.
Y aquí debemos decir que al usar la estrategia codiciosa, el modelo de gradiente de políticas ofrece resultados similares. Recuerde que cuando comenzamos a estudiar los métodos de aprendizaje por refuerzo, enfatizamos repetidamente la necesidad de elegir correctamente la política de recompensas, y luego decidimos experimentar con ella. En particular, para evitar quedarnos más tiempo en una posición con pérdidas, decidimos aumentar las sanciones por las posiciones no rentables, y, en consecuencia, entrenamos el modelo de gradiente de políticas considerando la nueva política de recompensas. Después de varios experimentos con los hiperparámetros del modelo, hemos logrado alcanzar un 60% de rentabilidad en las operaciones. A continuación, mostramos el gráfico de pruebas.
El tiempo medio de mantenimiento de una posición es de 1 hora y 40 minutos.
Autor: Dmitriy Gizlyk