
Verwenden von OpenCL, um Kerzenmuster zu testen

Einführung
Wenn Händler anfangen, OpenCL zu beherrschen, stehen sie vor der Frage, wie sie es einsetzen sollen. Solche anschaulichen Beispiele wie die Multiplikation von Matrizen oder das Sortieren großer Datenmengen werden bei der Entwicklung von Indikatoren oder automatisierten Handelssystemen nicht häufig verwendet. Eine weitere gängige Anwendung — das Arbeiten mit neuronalen Netzen — erfordert bestimmte Kenntnisse in diesem Bereich. Das Studium neuronaler Netze kann für einen gewöhnlichen Programmierer viel Zeit kosten, ohne Ergebnisse beim Handel zu garantieren. Dieser Umstand kann diejenigen enttäuschen, die die volle Kraft von OpenCL bei der Lösung von elementaren Aufgaben spüren möchten.
In diesem Artikel werden wir den Einsatz von OpenCL zur Lösung der einfachsten Aufgabe des algorithmischen Handels betrachten — das Auffinden von Kerzenmustern und das Testen in der Vergangenheit. Wir werden den Algorithmus zum Testen eines einzelnen Durchlaufs und zur Optimierung zweier Parameter im Handelsmodus "1 Minute OHLC" entwickeln. Danach werden wir die Leistung des integrierten Strategietesters mit der von OpenCL vergleichen und herausfinden, welcher von ihnen (und in welchem Maße) schneller ist.
Es wird davon ausgegangen, dass der Leser bereits mit den Grundlagen von OpenCL vertraut ist. Ansonsten empfehle ich die Artikel "OpenCL: Die Brücke zu parallelen Welten" und "OpenCL: Vom naiven zum aufschlussreicheren Programmieren". Es wäre auch gut, die OpenCL Specification Version 1.2 zur Hand zu haben. Der Artikel konzentriert sich auf den Algorithmus zum Aufbau eines Testers, ohne sich mit den Grundlagen der OpenCL-Programmierung zu befassen.
- Einführung
- 1. Implementation in MQL5
- 2. Implementation in OpenCL
- 2.1 Laden der Preise
- 2.2 Einzeltest
- 2.2.1. Die Suche nach den Mustern in OpenCL
- 2.2.2. Verschieben der Aufträge auf den Zeitrahmen M1
- 2.2.3. Erhalt der Handelsergebnisse
- 2.3. Starten eines Tests
- 2.4. Optimierung
- 2.4.1. Vorbereitung der Aufträge
- 2.4.2. Erhalt der Handelsergebnisse
- 2.4.3. Die Suche nach den Mustern und die Formung der Testergebnisse
- 2.5. Starten der Optimierung
- 3. Leistungsvergleich
- 3.1. Optimization on EURUSD
- 3.2. Optimierung auf GBPUSD
- 3.3. Optimierung auf USDJPY
- 3.4. Tabelle der Leistungsergebnisse
- Schlussfolgerung
1. Implementation in MQL5
Wir müssen uns auf etwas verlassen können, um sicherzustellen, dass die Implementierung des Testers auf OpenCL korrekt funktioniert. Zuerst werden wir einen MQL5-EA entwickeln. Dann werden wir die Ergebnisse der Prüfung und Optimierung mit einem normalen Tester mit denen des OpenCL-Testers vergleichen.
- Bearish (abwärts) Pin-Bar
- Bullish (aufwärts) Pin-Bar
- Bearish Engulfing (umhüllend)
- Bullish Engulfing (umhüllend)
Die Strategie ist einfach:
- Bearish Pin-Bar oder Bearish Engulfing — verkaufen
- Bullish Pin-Bar oder Bullish Engulfing — kaufen
- Die Anzahl gleichzeitig offenere Positionen — unbegrenzt
- Maximale Haltezeit der Positionen — begrenzt, nutzerdefiniert
- Take-Profit und Stop-Loss — unveränderlich, nutzerdefiniert
Das Vorhandensein eines Musters ist mit komplett geschlossenen Bars zu überprüfen. Mit anderen Worten wir suchen die Muster mittels drei vorherigen Bars sobald eine neue Bar erscheint.
Die Bedingung der Mustererkennung ist wie folgt:

Abb. 1. Die Muster von "Bearish Pin-Bar" (a) und "Bullish Pin-Bar" (b)
Für die Bearish Pin-Bar (Fig. 1, a):
- Der obere Schatten ("tail") der ersten Bar ist größer als der Referenzwert: tail>=Reference
- Die Bar 0 ist bullish: Close[0]>Open[0]
- Die zweite Bar ist bearish: Open[2]>Close[2]
- Das Hoch der ersten Bar ist das lokale Maximum: High[1]>MathMax(High[0],High[2])
- Der Körper der ersten Bar ist kleiner als der obere Schatten: MathAbs(Open[1]-Close[1])<tail
- tail = High[1]-max(Open[1],Close[1])
Für die Bullish Pin-Bar (Fig. 1, b):
- Der untere Schatten ("tail") der ersten Bar ist größer als der Referenzwert: tail>=Reference
- Die Bar 0 ist bearish: Open[0]>Close[0]
- Die zweite Bar ist bullish: Close[2]>Open[2]
- Das Tief der ersten Bar ist das lokale Minimum: Low[1]<MathMin(Low[0],Low[2])
- Der Körper der ersten Bar ist kleiner als der untere Schatten: MathAbs(Open[1]-Close[1])<tail
-
tail = min(Open[1],Close[1])-Low[1]

Abb. 2. "Bearish Engulfing" (a) und "Bullish Engulfing" (b)
Für Bearish Engulfing (Fig. 2, a):
- Die erste Bar ist bullish, ihr Körper ist größer als der Referenzwert: (Close[1]-Open[1])>=Reference
- Das Hoch der Bar Null ist kleiner als der Schlusskurs der ersten Bar: High[0]<Close[1]
- Der Eröffnungspreis der zweiten Bar überschreitet den Schlusskurs der ersten Bar: Open[2]>CLose[1]
- Der Schlusskurs der zweiten Bar ist kleiner als der Eröffnungspreis der ersten Bar: Close[2]<Open[1]
Für Bullish Engulfing (Fig. 2, b):
- Die erste Bar ist bearish, ihr Körper ist größer als der Referenzwert: (Close[1]-Open[1])>=Reference
- Das Tief der Bar Null ist größer als der Schlusskurs der ersten Bar: Low[0]>Close[1]
- Der Eröffnungspreis der zweiten Bar unterschreitet den Schlusskurs der ersten Bar: Open[2]<Close[1]
- Der Schlusskurs der zweiten Bar ist größer als der Eröffnungspreis der ersten Bar: Close[2]>Open[1]
1.1 Die Suche nach den Mustern
ENUM_PATTERN Check(MqlRates &r[],uint flags,double ref) { //--- Bearish Pin-Bar if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-MathMax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>MathMax(H(0),H(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- Bullish Pin-Bar if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=MathMin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<MathMin(L(0),L(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- Bearish Engulfing if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- Bullish Engulfing if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- nichts gefunden return PAT_NONE; }
Hier sollten wir die Enumeration ENUM_PATTERN anschauen. Die Werte sind wie Flags, die kombiniert und als Argument mittels bitwise OR übergeben werden können:
enum ENUM_PATTERN { PAT_NONE=0, PAT_PINBAR_BEARISH = (1<<0), PAT_PINBAR_BULLISH = (1<<1), PAT_ENGULFING_BEARISH = (1<<2), PAT_ENGULFING_BULLISH = (1<<3) };
Wir haben auch die Möglichkeit zu Makros für einen kompakten Code:
#define O(i) (r[i].open) #define H(i) (r[i].high) #define L(i) (r[i].low) #define C(i) (r[i].close)
Die Funktion Check() wird von der Funktion IsPattern() aufgerufen, um das Vorhandensein eines angegebenen Musters beim Erscheinen einer neuen Bar zu überprüfen:
ENUM_PATTERN IsPattern(uint flags,uint ref) { MqlRates r[]; if(CopyRates(_Symbol,_Period,1,PBARS,r)<PBARS) return 0; ArraySetAsSeries(r,false); return Check(r,flags,double(ref)*_Point); }
1.2 Zusammenbau des EAs
Als erstes müssen die Eingabeparameter definiert werden. Wir aben einen Referenzwert in den Bedingungen für die Muster. Es ist dies die kleinste Länge des "tail" einer Pin-Bar oder die sich kreuzenden Körper bei Engulfing. Wir geben das in Points an:
input int inp_ref=50;
Außerdem haben wir eine Reihe von Mustern, mit denen wir arbeiten. Aus Gründen der Übersichtlichkeit werden wir das Register der Flags in den Eingängen nicht verwenden. Stattdessen werden wir es in vier Parameter vom Typ bool unterteilen:
input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true;
Und kombinieren sie in eine unsignierten Variablen in der Initialisierungsfunktion:
p_flags = 0; if(inp_bullish_pin_bar==true) p_flags|=PAT_PINBAR_BULLISH; if(inp_bearish_pin_bar==true) p_flags|=PAT_PINBAR_BEARISH; if(inp_bullish_engulfing==true) p_flags|=PAT_ENGULFING_BULLISH; if(inp_bearish_engulfing==true) p_flags|=PAT_ENGULFING_BEARISH;
Als nächstes bestimmen wir die maximal erlaubte Haltezeit der Positionen in Stunden, Take-Profit und Stop-Loss und auch das Volumen.
input int inp_timeout=5; input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true; input double inp_lot_size=1;Für den Handel verwenden wir die Klasse CTrade aus der Standardbibliothek. Um die Testergeschwindigkeit zu definieren, verwenden wir die Klasse CDuration, die es ermöglicht, Zeitintervalle zwischen Kontrollpunkten der Programmausführung in Mikrosekunden zu messen und in einer komfortablen Form anzuzeigen. In diesem Fall messen wir die Zeit zwischen den Funktionen OnInit() und OnDeinit(). Der vollständige Klassencode ist in der angehängten Datei Duration.mqh enthalten.
CDuration time; int OnInit() { time.Start(); // ... return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { time.Stop(); Print("Test lasted "+time.ToStr()); }
Der EA ist exterm einfach und besteht aus dem Folgenden.
Die Hauptaufgabe der Funktion OnTick() ist die Bearbeitung offener Positionen. Sie schließt eine Position, wenn deren Haltezeit den in den Eingängen angegebenen Wert überschreitet. Anschließend wird das Öffnen eines neuen Balkens überprüft. Wenn die Prüfung bestanden ist, wird das Vorhandensein des Musters mit der Funktion IsPattern() überprüft. Wird ein Muster gefunden, wird eine Kauf- oder Verkaufsposition gemäß der Strategie eröffnet. Der vollständige Funktionscode von OnTick() ist unten aufgeführt:
void OnTick() { //--- bearbeiten der offenen Positionen int total= PositionsTotal(); for(int i=0;i<total;i++) { PositionSelect(_Symbol); datetime t0=datetime(PositionGetInteger(POSITION_TIME)); if(TimeCurrent()>=(t0+(inp_timeout*3600))) { trade.PositionClose(PositionGetInteger(POSITION_TICKET)); } else break; } if(IsNewBar()==false) return; //--- prüfen auf vorhandene Muster ENUM_PATTERN pat=IsPattern(p_flags,inp_ref); if(pat==PAT_NONE) return; //--- Positionseröffnung double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); if((pat&(PAT_ENGULFING_BULLISH|PAT_PINBAR_BULLISH))!=0)//Kauf trade.Buy(inp_lot_size,_Symbol,ask,NormalizeDouble(ask-inp_sl*_Point,_Digits),NormalizeDouble(ask+inp_tp*_Point,_Digits),DoubleToString(ask,_Digits)); else//Verkauf trade.Sell(inp_lot_size,_Symbol,bid,NormalizeDouble(bid+inp_sl*_Point,_Digits),NormalizeDouble(bid-inp_tp*_Point,_Digits),DoubleToString(bid,_Digits)); }
1.3 Tests
Zuerst einmal, starten wir die Optimierung, um die besten Eingabewerte für den EA herauszufinden, um profitabel zu handeln oder zumindest die Positionen zu eröffnen. Wir werden zwei Parameter optimieren — einen Referenzwert für Muster und den Stop-Loss in Points. Setzen wir Take-Profit Level auf 50 Points und wählen alle Muster zum Testen aus.
Die Optimierung soll mit EURUSD M5 durchgeführt werden. Zeitintervall: 01.01.2018 — 01.10.2018. Schnelle Optimierung (genetischer Algorithmus), Handelsmodus: "1 Minute OHLC".
Die Werte der optimierten Parameter werden in einem weiten Bereich mit einer großen Anzahl von Abstufungen ausgewählt:
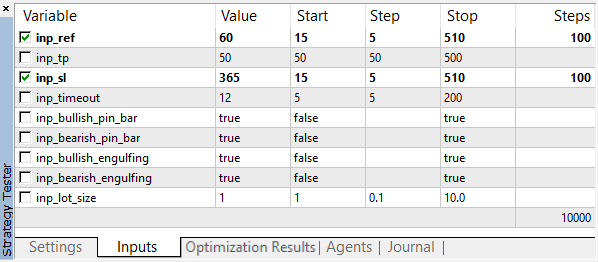
Abb. 3. Optimierungsparameter
Nach der Optimierung werden die Werte nach dem Gewinn sortiert:
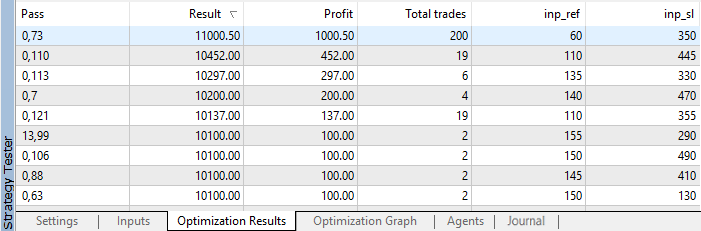
Abb. 4. Optimierungsergebnisse
Wie man sehen kann, erzielten wir das beste Ergebnis mit einen Gewinn von 1000,50 bei einem Referenzwert von 60 Points und einem Stop-Loss von 350 Points. Starten wir den Test mit diesen drei Parameterwerten und achten auf die Ausführungszeit.
Abb. 5. Der Testzeitraum eines einzelnen Durchlaufn im integrierten Tester
Wir merken uns diese Werte und fahren fort mit den Tests derselben Strategie ohne den normalen Tester zu verwenden. Entwickeln wir unseren eigenen Tester unter der Verwendung von OpenCL.
2. Implementation in OpenCL
Um mit OpenCL zu arbeiten, werden wir die Klasse COpenCL aus der Standardbibliothek mit kleinen Änderungen verwenden. Ziel der Verbesserungen ist es, so viele Informationen wie möglich über auftretende Fehler zu erhalten. Dabei sollten wir den Code jedoch nicht durch Bedingungen und die Ausgabe von Daten an die Konsole überladen. Dazu erstellen wir die Klasse COpenCLx. Der vollständige Code befindet sich in der unten angehängten Datei OpenCLx.mqh:
class COpenCLx : public COpenCL { private: COpenCL *ocl; public: COpenCLx(); ~COpenCLx(); STR_ERROR m_last_error; // letzter Fehler COCLStat m_stat; // OpenCL Statistik //--- Arbeit mit Puffern bool BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line); template<typename T> bool BufferFromArray(const ENUM_BUFFERS buffer_index,T &data[],const uint data_array_offset,const uint data_array_count,const uint flags,const string function,const int line); template<typename T> bool BufferRead(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); template<typename T> bool BufferWrite(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); //--- Bestimmen der Argumente template<typename T> bool SetArgument(const ENUM_KERNELS kernel_index,const int arg_index,T value,const string function,const int line); bool SetArgumentBuffer(const ENUM_KERNELS kernel_index,const int arg_index,const ENUM_BUFFERS buffer_index,const string function,const int line); //--- arbeit mit dem Kernel bool KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line); bool Execute(const ENUM_KERNELS kernel_index,const int work_dim,const uint &work_offset[],const uint &work_size[],const string function,const int line); //--- bool Init(ENUM_INIT_MODE mode); void Deinit(void); };
Wie wir sehen können, enthält die Klasse einen Zeiger auf das Objekt COpenCL sowie mehrere Methoden, die als Wrapper für die gleichnamigen Klassenmethoden COpenCL dienen. Jede dieser Methoden hat den Namen der Funktion und die Zeichenkette, aus der sie unter den Argumenten aufgerufen wurde. Darüber hinaus werden anstelle von Kernel-Indizes und -Puffern Enumeratoren verwendet. Dies geschieht, um die Anwendung von EnumToString() in der Fehlermeldung zu ermöglichen, was viel informativer ist als nur ein Index.
Lassen Sie uns eine dieser Methoden näher betrachten.
bool COpenCLx::KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL object does not exist",function,line); return false; } //--- Starten der Ausführung des Kernels ::ResetLastError(); if(!ocl.KernelCreate(kernel_index,kernel_name)) { string comment="Failed to create kernel "+EnumToString(kernel_index)+", name \""+kernel_name+"\""; SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_KERNEL_CREATE,comment,function,line); return(false); } //--- return true; }
Es gibt hier zwei Prüfungen: auf das Vorhandensein des Objekts der Klasse COpenCL und des Erfolgs der Kernelerstellungsmethode. Anstatt jedoch mit der Funktion Print() einen Text anzuzeigen, werden die Meldungen zusammen mit dem Fehlercode, dem Funktionsnamen und der Aufrufzeichenfolge an Makros übergeben. Diese Makros speichern Fehlerinformationen in der Klasse m_last_error Klassenfehler. Deren Struktur ist unten dargestellt:
struct STR_ERROR { int code; // Code string comment; // Kommentar string function; // Funktion des aufgetretenen Fehlers int line; // Zeile des aufgetretenen Fehlers };
Insgesamt gibt es vier Makros. Betrachten wir sie einzeln.
Das Makro SET_ERR schreibt den letzten Ausführungsfehler, Funktion und Zeile, wo es aufgerufen wurde, werden mit dem übergebenen Parameter ausgewiesen:
#define SET_ERR(c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Das Makro SET_ERRx ist ähnlich wie SET_ERR:
#define SET_ERRx(c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Es unterscheidet sich dadurch, dass Funktion und Zeile als Parameter übergeben werden. Warum das? Angenommen, es ist ein Fehler in der Methode KernelCreate() aufgetreten. Wenn wir das Makro SET_ERR verwenden, können wir den KernelCreate() Methodennamen sehen, aber es ist viel nützlicher zu wissen, wo die Methode aufgerufen wurde. Um dies zu erreichen, übergeben wir die Funktion und Zeile beim Aufruf der Methode als Argumente dem Makro.
Das Makro SET_UERR kommt als nächstes. Es ist für das Schreiben von nutzerdefinierten Fehlern gedacht:
#define SET_UERR(err,c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
In dem Makro wird die Fehlernummer als Argument übergeben, statt die Funktion GetLastError() zu verwenden. In gewisser Hinsicht ist es ähnlich dem Makro SET_ERR.
Das Makro SET_UERRx soll die nutzerdefinierten Fehler ausweisen, es werden Funktionsname und Zeile des Aufrufs übergeben:
#define SET_UERRx(err,c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
So haben wir im Fehlerfall alle notwendigen Informationen. Im Gegensatz zu den Fehlern, die von der Klasse COpenCL an die Konsole gesendet werden, ist dies eine Spezifikation des Zielkerns und von wo aus die Methode ihrer Erstellung aufgerufen wurde. Vergleichen wir einfach die Ausgabe der Klasse COpenCL (obere Zeichenkette) und die erweiterte Ausgabe der Klasse COpenCLx (zwei untere Zeilen):

Abb. 6. Fehler bei der Kernelerstellung
Betrachten wir ein anderes Beispiel einer Wrappermethode: die Methode zum Erstellen des Puffers:
bool COpenCLx::BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL object does not exist",function,line); return false; } //--- abrufen und prüfen des freien Speichers if((m_stat.gpu_mem_usage+=size_in_bytes)==false) { CMemsize cmem=m_stat.gpu_mem_usage.Comp(size_in_bytes); SET_UERRx(UERR_NO_ENOUGH_MEM,"No free GPU memory. Insufficient "+cmem.ToStr(),function,line); return false; } //--- Puffer erstellen ::ResetLastError(); if(ocl.BufferCreate(buffer_index,size_in_bytes,flags)==false) { string comment="Failed to create buffer "+EnumToString(buffer_index); SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_BUFFER_CREATE,comment,function,line); return(false); } //--- return(true); }
Neben der Überprüfung des Vorhandenseins des Objekts und des Operationsergebnisses der Klasse COpenCL enthält sie auch die Funktion zur Abrechnung und Überprüfung des freien Speichers. Da wir es mit relativ großen Mengen an Speicher (Hunderte von Megabyte) zu tun haben, müssen wir den Prozess des Verbrauchs kontrollieren. Diese Aufgabe ist СMemsize zugeordnet. Der vollständige Code ist in der Datei Memsize.mqh enthalten.
Es gibt jedoch einen Nachteil. Trotz des komfortablen Debuggens wird der Code umständlich. Der Code für die Puffererstellung sieht beispielsweise wie folgt aus:
if(BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE,__FUNCTION__,__LINE__)==false) return false;
Es gibt zu viele unnötige Informationen, die die Konzentration auf den Algorithmus schwierig machen. Hier kommen uns die Makros wieder einmal zur Hilfe. Jede der Wrapper-Methoden wird durch ein Makro dupliziert, wodurch der Aufruf kompakter wird. Für die Methode BufferCreate() ist es das Makro _BufferCreate:
#define _BufferCreate(buffer_index,size_in_bytes,flags) \ if(BufferCreate(buffer_index,size_in_bytes,flags,__FUNCTION__,__LINE__)==false) return false
Dank des Makros wird der Aufruf der Methode zum Erstellen der Puffer einfacher:
_BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
Das Erstellen des Kernels sieht wie folgt aus:
_KernelCreate(k_FIND_PATTERNS,"find_patterns");
Die meisten dieser Makros enden mit return false, während _KernelCreate mit break endet. Dies sollte bei der Entwicklung des Codes berücksichtigt werden. Alle Makros sind in der Datei OCLDefines.mqh definiert.
Die Klasse beinhaltet auch die Initialisierung- und Deinitialisierungsmethoden. Neben dem Erstellen des Klassenobjekts COpenCL überprüft die erste die Unterstützung von 'double', erstellt Kernel und fragt den verfügbaren Speicher ab:
bool COpenCLx::Init(ENUM_INIT_MODE mode) { if(ocl) Deinit(); //--- erstellen des Objekts der Klasse COpenCL ocl=new COpenCL; while(!IsStopped()) { //--- initialisieren von OpenCL ::ResetLastError(); if(!ocl.Initialize(cl_tester,true)) { SET_ERR("OpenCL initialization error"); break; } //--- prüfen, ob die Arbeit mit 'double' unterstützt wird if(!ocl.SupportDouble()) { SET_UERR(UERR_DOUBLE_NOT_SUPP,"Working with double (cl_khr_fp64) is not supported by the device"); break; } //---bestimmen der Anzahl der Kernels if(!ocl.SetKernelsCount(OCL_KERNELS_COUNT)) break; //--- erstellen der Kernel if(mode==i_MODE_TESTER) { _KernelCreate(k_FIND_PATTERNS,"find_patterns"); _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_ORDER_TO_M1,"order_to_M1"); _KernelCreate(k_TESTER_STEP,"tester_step"); }else if(mode==i_MODE_OPTIMIZER){ _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_TESTER_OPT_PREPARE,"tester_opt_prepare"); _KernelCreate(k_TESTER_OPT_STEP,"tester_opt_step"); _KernelCreate(k_FIND_PATTERNS_OPT,"find_patterns_opt"); } else break; //--- erstellen der Puffer if(!ocl.SetBuffersCount(OCL_BUFFERS_COUNT)) { SET_UERR(UERR_SET_BUF_COUNT,"Failed to create buffers"); break; } //--- abrufen der Größe des RAM long gpu_mem_size; if(ocl.GetGlobalMemorySize(gpu_mem_size)==false) { SET_UERR(UERR_GET_MEMORY_SIZE,"Failed to receive RAM value"); break; } m_stat.gpu_mem_size.Set(gpu_mem_size); m_stat.gpu_mem_usage.Max(gpu_mem_size); return true; } Deinit(); return false; }
Das Argument mode setzt den Initialisierungsmodus. Dies kann eine Optimierung oder ein Einzeltest sein. Darauf aufbauend werden verschiedene Kernel erstellt.
Kernel- und Pufferenumeratoren werden in der Datei OCLInc.mqh deklariert. Die Quellcodes der Kernel werden dort als Ressource angehängt, wie z.B. die Zeichenkette cl_tester.
Die Methode Deinit() löscht OpenCL-Programme und -Objekte:
void COpenCLx::Deinit() { if(ocl!=NULL) { //--- löschen der OpenCL-Objekte ocl.Shutdown(); delete ocl; ocl=NULL; } }
Nachdem alle Vorkehrungen erfüllt sind, ist es an der Zeit, mit der Hauptarbeit zu beginnen. Wir haben bereits einen relativ kompakten Code und umfassende Informationen über Fehler.
Aber zuerst müssen wir die Daten hochladen, mit denen wir arbeiten sollen. Das ist nicht so einfach, wie es auf den ersten Blick scheint.
2.1 Laden der Preise
The CBuffering class uploads the data.
class CBuffering { private: string m_symbol; ENUM_TIMEFRAMES m_period; int m_maxbars; uint m_memory_usage; //Verwendeter Speicher bool m_spread_ena; //hochladen des Puffers spread datetime m_from; datetime m_to; uint m_timeout; //Timeout in Millisekunden für das Hochladen ulong m_ts_abort; //Zeitwert in Mikrosekunden, wenn die Operation abgebrochen werden soll //--- erzwungenes Hochladen bool ForceUploading(datetime from,datetime to); public: CBuffering(); ~CBuffering(); //--- Datenmenge in den Puffern int Depth; //--- Puffer double Open[]; double High[]; double Low[]; double Close[]; double Spread[]; datetime Time[]; //--- abrufen der zeitlichen Beschränkung für das Hochladen der Daten datetime TimeFrom(void){return m_from;} datetime TimeTo(void){return m_to;} //--- int Copy(string symbol,ENUM_TIMEFRAMES period,datetime from,datetime to,double point=0); uint GetMemoryUsage(void){return m_memory_usage;} bool SpreadBufEnable(void){return m_spread_ena;} void SpreadBufEnable(bool ena){m_spread_ena=ena;} void SetTimeout(uint timeout){m_timeout=timeout;} };
Wir werden uns nicht zu sehr damit beschäftigen, da der Daten-Upload keinen direkten Bezug zum aktuellen Thema hat. Wir sollten jedoch seine Anwendung kurz prüfen.
Die Klasse enthält die Puffer Open[], High[], Low[], Close[], Time[] und Spread[]. Wir können mit ihnen arbeiten, nachdem die Methode Copy() erfolgreich funktioniert hat. Vergessen wir nicht, dass der Puffer Spread[] vom Typ 'double' ist und nicht in Points, sondern als eine Preisdifferenz ausgedrückt wird. Außerdem ist das Kopieren des Spread[]-Puffers zunächst deaktiviert. Gegebenenfalls sollte es mit der Methode SpreadBufEnable() aktiviert werden.
Für den Upload wird die Methode Copy() verwendet. Das Argument point wird nur verwendet, um den Spread von Punkten in die Preisdifferenz umzurechnen. Wenn das Kopieren der Spreads ausgeschaltet ist, wird dieses Argument nicht verwendet.
Die Hauptgründe für die Einrichtung einer eigenen Klasse für das Hochladen von Daten sind:
- Die Unmöglichkeit, Daten in einer Menge herunterzuladen, die TERMINAL_MAXBARS übersteigt, mit der Funktion CopyTime() und dergleichen.
- Es kann nicht garantiert werden, dass das Terminal die Daten lokal hat.
Die Klasse Cuffering ist in der Lage, große Datenmengen zu kopieren, die über TERMINAL_MAXBARS hinausgehen, sowie den Upload fehlender Daten vom Server auszulösen und auf deren Fertigstellung zu warten. Aufgrund dieses Wartens müssen wir auf die Methode SetTimeout() achten, die zum Einstellen der maximalen Datenladezeit (einschließlich Warten) in Millisekunden bestimmt ist. Standardmäßig ist der Klassenkonstruktor gleich 5000 (5 Sekunden). Wenn Sie den Timeout auf Null setzen, wird er deaktiviert. Dies ist höchst unerwünscht, kann aber in einigen Fällen nützlich sein.
Es gibt jedoch einige Einschränkungen: M1-Periodendaten werden nicht für den Zeitraum von mehr als einem Jahr hochgeladen, was die Reichweite unserer Tester teilweise einschränkt.
2.2 Einzeltest
Der Einzeltest besteht aus den folgenden Punkten:
- Herunterladen der Zeitreihenpuffer
- Initialisierung von OpenCL
- Kopieren der Zeitreihenpuffer in OpenCL-Puffer
- Starten des Kernels, der die Muster auf dem aktuellen Chart findet und Ergebnisse in den Orderpuffer als Markteintrittspunkte hinzufügt.
- Starten des Kernels, der Aufträge in das M1-Diagramm verschiebt.
- Starten des Kernels, der die Handelsergebnisse nach Orders auf Diagramm M1 zählt und sie in den Puffer hinzufügt.
- Verarbeitung des Ergebnispuffers und Berechnung der Testergebnisse
- Deinitialisierung von OpenCL
- Entfernen der Zeitreihenpuffer
Die CBuffering Download-Zeitreihe. Dann sollten diese Daten in die OpenCL-Puffer kopiert werden, damit die Kernel mit ihnen arbeiten können. Diese Aufgabe ist der Methode LoadTimeseriesOCL() zugeordnet. Der Code ist unten aufgeführt:
bool CTestPatterns::LoadTimeseriesOCL() { //--- Open Puffer: _BufferFromArray(buf_OPEN,m_sbuf.Open,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- High Puffer: _BufferFromArray(buf_HIGH,m_sbuf.High,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Low Puffer: _BufferFromArray(buf_LOW,m_sbuf.Low,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Close Puffer: _BufferFromArray(buf_CLOSE,m_sbuf.Close,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Time Puffer: _BufferFromArray(buf_TIME,m_sbuf.Time,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Open (M1) Puffer: _BufferFromArray(buf_OPEN_M1,m_tbuf.Open,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- High (M1) Puffer: _BufferFromArray(buf_HIGH_M1,m_tbuf.High,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Low (M1) Puffer: _BufferFromArray(buf_LOW_M1,m_tbuf.Low,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Close (M1) Puffer: _BufferFromArray(buf_CLOSE_M1,m_tbuf.Close,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Spread (M1) Puffer: _BufferFromArray(buf_SPREAD_M1,m_tbuf.Spread,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Time (M1) Puffer: _BufferFromArray(buf_TIME_M1,m_tbuf.Time,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- kopieren war erfolgreich return true; }
Die Daten sind also heruntergeladen worden. Jetzt ist es Zeit den Testalgorithmus zu implementieren.
2.2.1 Die Suche nach den Mustern in OpenCL
Der Code für die Muster für OpenCL unterscheidet sich nicht besonders von dem für MQL5:
//--- Muster #define PAT_NONE 0 #define PAT_PINBAR_BEARISH (1<<0) #define PAT_PINBAR_BULLISH (1<<1) #define PAT_ENGULFING_BEARISH (1<<2) #define PAT_ENGULFING_BULLISH (1<<3) //--- Preise #define O(i) Open[i] #define H(i) High[i] #define L(i) Low[i] #define C(i) Close[i] //+------------------------------------------------------------------+ //| Prüfen, ob es Muster gibt | //+------------------------------------------------------------------+ uint Check(__global double *Open,__global double *High,__global double *Low,__global double *Close,double ref,uint flags) { //--- Bearish Pin-Bar if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-fmax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>fmax(H(0),H(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- Bullish Pin-Bar if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=fmin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<fmin(L(0),L(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- Bearish Engulfing if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- Bullish Engulfing if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- nichts gefunden return PAT_NONE; }
Einer der kleinen Unterschiede besteht darin, dass die Puffer über einen Zeiger und nicht als Referenz übergeben werden. Außerdem gibt es den Modifikator __global, der anzeigt, dass sich die Zeitreihenpuffer im globalen Speicher befinden. Alle OpenCL-Puffer, die wir erstellen sollen, befinden sich im globalen Speicher.
Die Funktion Check() ruft den Kernel find_patterns() auf:
__kernel void find_patterns(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global int *Order, // Auftragspuffer __global int *Count, // Anzahl der Aufträge im Puffer const double ref, // Parameter der Muster const uint flags) // Suche nach welchem Muster { //--- arbeiten in einer Dimension //--- Barindex size_t x=get_global_id(0); //--- Größe des Raums der Mustersuche size_t depth=get_global_size(0)-PBARS; if(x>=depth) return; //--- prüfen, ob Muster existieren uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref,flags); if(res==PAT_NONE) return; //--- bestimmen der Aufträge if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) {//verkaufen int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL; } else if(res==PAT_PINBAR_BULLISH || res==PAT_ENGULFING_BULLISH) {//kaufen int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_BUY; } }
Wir werden das verwenden, um nach Mustern zu suchen und Aufträge in einem speziell dafür vorgesehenen Puffer zu finden.
Der Kernel find_patterns() arbeitet in einem eindimensionalen Aufgabenbereich. Während des Starts erstellen wir die Anzahl der Arbeitselemente, die wir im Aufgabenraum für die Dimension 0 angeben sollen. In diesem Fall ist es die Anzahl der Balken im aktuellen Zeitrahmen. Um zu verstehen, welche Bar bearbeitet wird, müssen wir den Aufgabenindex abrufen:
size_t x=get_global_id(0);
Wobei Null der Maßindex ist.
Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL;
Um die Nummer des Auftrags zu erhalten, verwenden wir die Funktion atomic_inc(). Bei der Ausführung einer Aufgabe haben wir keine Ahnung, welche Aufgaben und Balken bereits erledigt sind. Das sind parallele Berechnungen, und es gibt hier absolut keine Reihenfolge von irgendetwas. Ein Aufgabenindex ist nicht auf die Anzahl der bereits erledigten Aufgaben bezogen. Daher wissen wir nicht, wie viele Aufträge bereits im Puffer liegen. Wenn wir versuchen, ihre Nummer in Zelle 0 des Puffers Count[] zu lesen, kann ein anderer Task gleichzeitig etwas schreiben. Um das zu vermeiden, verwenden wir die Atomicfunktionen.
In unserem Fall deaktiviert die Funktion atomic_inc() den Zugriff anderer Aufgaben auf die Zelle Count[0]. Danach erhöht er seinen Wert um eins, während der vorherige Wert als Ergebnis zurückgegeben wird.
int i=atomic_inc(&Count[0]);
Natürlich verlangsamt dies die Arbeit, da andere Aufgaben warten müssen, solange der Zugriff auf Count[0] gesperrt ist. Aber in einigen Fällen (wie bei uns) gibt es einfach keine andere Lösung.
Nachdem alle Aufgaben erledigt sind, erhalten wir den Puffer mit den erteilen Aufträgen Order[] und deren Anzahl in der Zelle Count[0].
2.2.2 Verschieben der Aufträge auf den Zeitrahmen M1
Also, wir haben Muster im aktuellen Zeitrahmen gefunden, aber die Tests sollten im M1-Zeitrahmen durchgeführt werden. Das bedeutet, dass für alle Einstiegspunkte des aktuellen Zeitrahmens die entsprechenden Bars auf M1 gefunden werden müssen. Da das Handelsmuster auch in kleinen Zeitfenstern eine relativ geringe Anzahl von Einstiegspunkten hat, werden wir eine eher grobe, aber durchaus geeignete Methode wählen — die Enumeration. Wir werden die Zeit jedes gefundenen Auftrags mit der Zeit jeder Bar des Zeitrahmens M1 vergleichen. Dazu erstellen Sie den Kernel order_to_M1():
__kernel void order_to_M1(__global ulong *Time,__global ulong *TimeM1, __global int *Order,__global int *OrderM1, __global int *Count, const ulong shift) // Zeitversatz in Sekunden { //--- Arbeiten in zwei Dimensionen size_t x=get_global_id(0); //Index des Zeitindex der Aufträge if(OrderM1[x*2]>=0) return; size_t y=get_global_id(1); //Index in TimeM1 if((Time[Order[x*2]]+shift)==TimeM1[y]) { atomic_inc(&Count[1]); //--- setzen der geraden Indices im Puffer TimeM1 OrderM1[x*2]=y; //--- setzen (OP_BUY/OP_SELL) ungeraden Indices OrderM1[(x*2)+1]=Order[(x*2)+1]; } }
Hier haben wir einen zweidimensionalen Aufgabenraum. Die Dimension 0 ist für die Anzahl der erteilten Aufträge, während die Dimension 1 für Anzahl der Bars des Zeitrahmens M1 ist. Wenn die Eröffnungszeit der Bar eines Auftrags und die der Bar in M1 übereinstimmen, wird der Vorgang des aktuellen Auftrags in den Puffer OrderM1[] kopiert und der erfasste Barindex in der Zeitreihe des M1-Zeitrahmens gesetzt.
Es gibt hier zwei Dinge, die auf den ersten Blick nicht existieren sollten.
- Die erste ist die atomic_inc() Atomicfunktion, die aus irgendeinem Grund die Einstiegspunkte des M1-Zeitrahmens zählt. In der Dimension 0 arbeitet jeder Auftrag mit ihrem Index, während es im Index 1 nicht mehr als eine Übereinstimmung geben kann. Das bedeutet, dass der Versuch des gemeinsamen Zugriffs völlig ausgeschlossen ist. Warum müssen wir dennoch zählen?
- Das zweite ist das Argument shift, das zur aktuellen Zeit der aktuellen Bar des Zeitrahmens hinzugefügt wurde.
Dafür gibt es besondere Gründe. Die Welt ist nicht perfekt. Das Vorhandensein einer Bar auf dem M5-Diagramm mit der Öffnungszeit von 01:00:00:00 bedeutet nicht, dass eine Bar mit der gleichen Öffnungszeit auf dem M1-Diagramm vorhanden ist.
Die entsprechende Bar auf dem M1-Diagramm kann eine Öffnungszeit von entweder 01:01:00 oder 01:04:00 haben. Mit anderen Worten, die Anzahl der Variationen entspricht dem Verhältnis der Dauer der Zeitrahmen. Dazu wird die Funktion des Zählens der Anzahl der erfassten Eintrittspunkte für M1 eingeführt:
atomic_inc(&Count[1]);
Wenn nach Abschluss des Kerneloperationen die Anzahl der gefundenen M1-Aufträge gleich der Anzahl der im aktuellen Zeitrahmen erfassten Aufträge ist, dann ist die Aufgabe vollständig abgeschlossen. Andernfalls ist ein Neustart mit einem anderen Argument shift erforderlich. Es kann so viele Neustarts geben, wie es M1-Perioden im aktuellen Zeitrahmen gibt
Die folgende Prüfung wurde eingeführt, um sicherzustellen, dass erkannte Einstiegspunkte während eines Neustarts mit einem Argumentwert ungleich Null shift nicht durch andere Werte neu geschrieben werden:
if(OrderM1[x*2]>=0) return;
Damit es funktioniert, füllen wir den Puffer OrderM1[] mit dem Wert -1, bevor wir den Kernel starten. Wir erstellen dazu den Kernel array_fill():
__kernel void array_fill(__global int *Buf,const int value) { //--- arbeitet mit einer Dimension size_t x=get_global_id(0); Buf[x]=value; }
2.2.3 Erhalt der Handelsergebnisse
Nachdem die Einstiegspunkte auf M1 gefunden wurden, können wir beginnen, Handelsergebnisse zu ermitteln. Dazu benötigen wir einen Kernel, der offene Positionen begleitet. Mit anderen Worten, wir sollten aus einem der vier Gründe warten, bis sie geschlossen sind:
- Take-Profit erreicht,
- Stop-Loss erreicht,
- Ablauf der maximalen Haltezeit der offenen Position erreicht,
- Ende des Testzeitraums erreicht.
Die Aufgabe für den Kernel ist eindimensional und ihre Größe entspricht der Anzahl der Aufträge. Der Kernel soll über die Balken iterieren, beginnend mit der geöffneten Position und die oben beschriebenen Bedingungen überprüfen. Innerhalb der Bar werden die Ticks im Modus "1 Minute OHLC" simuliert, wie im Abschnitt "Testing Trading Strategies" der Dokumentation beschrieben.
Wichtig ist, dass einige Positionen fast unmittelbar nach dem Öffnen geschlossen werden, einige später, während andere durch Timeout oder nach Beendigung des Tests geschlossen werden. Dies bedeutet, dass die Ausführungszeit der Aufgabe für verschiedene Einstiegspunkte sehr unterschiedlich ist.
Die Praxis hat gezeigt, dass das Begleiten einer Position vor dem Schließen in einem Durchgang nicht effizient ist. Im Gegensatz dazu führt die Aufteilung des Prüfraums (die Anzahl der Bars vor dem Zzwangsweisen Schließen der Position wegen des Erreichens der Haltezeit) in mehrere Teile und die Durchführung des Handlings in mehreren Durchgängen zu deutlich besseren Ergebnissen in Bezug auf die Leistung.
Die Aufgaben, die im aktuellen Durchgang nicht erledigt sind, werden auf den nächsten verschoben. Somit wird die Größe des Aufgabenbereichs mit jedem Durchlauf verringert. Um dies zu implementieren, müssen Sie jedoch einen anderen Puffer verwenden, um die Task-Indizes zu speichern. Jede Aufgabe ist ein Index eines Einstiegspunktes im Auftragspuffer. Zum Zeitpunkt des ersten Starts entspricht der Inhalt des Aufgabenpuffers vollständig dem Auftragspuffer. Bei den nächsten Starts wird es die Indizes der Aufträge enthalten, für die noch keine Positionen geschlossen wurden. Um mit dem Aufgabenpuffer zu arbeiten und die Aufgaben für den nächsten Lauf dort gleichzeitig zu speichern, sollte es zwei Bänke haben: Eine Bank wird beim aktuellen Start verwendet, während eine andere für die Bildung von Aufgaben für den nächsten.
In der Praxis sieht das so aus. Angenommen, wir haben 1000 Einstiegspunkte, für die wir Handelsergebnisse ermitteln müssen. Die Haltezeit einer offenen Position entspricht 800 Bars. Wir haben uns entschieden, den Test in 4 Durchläufe aufzuteilen. Grafisch sieht es so aus, wie in Abb. 7 dargestellt.
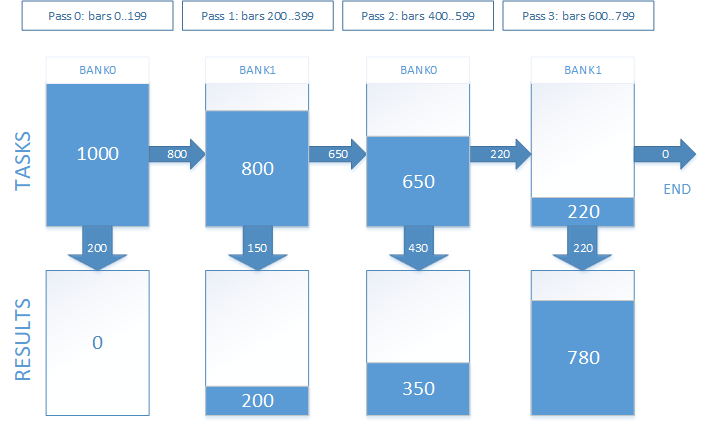
Abb. 7. Begleiten der offenen Positionen in mehreren Durchläufen
Durch Versuch und Irrtum haben wir die optimale Anzahl von Durchläufen von 8 für eine Positionshaltezeit von 12 Stunden (oder 720 Minutenbars) ermittelt. Dies ist der Standardwert. Er variiert für verschiedene Timeout-Werte und OpenCL-Geräte. Für maximale Leistung wird eine sorgfältige Auswahl empfohlen.
Somit werden die Puffer der Tasks[] und der Index der Bank der Tasks, mit denen wir arbeiten, zu den Argumenten des Kernels neben den Zeitreihen hinzugefügt. Außerdem fügen wir den Puffer Res[] hinzu, um die Ergebnisse zu speichern.
Die Menge der Ist-Daten im Task-Puffer wird über den Puffer Left[] zurückgegeben, der die Größe der beiden Elemente hat — jeweils für jede der Banken.
Da der Test in Teilen durchgeführt wird, sollten die Werte der Start- und Endbars für die Positionsverfolgung zwischen den Kernelargumenten übergeben werden. Dies ist ein relativer Wert, der mit dem Index der positionell öffnenden Balken aufsummiert wird, um den absoluten Index der aktuellen Bars in der Zeitreihe zu erhalten. Außerdem sollte der maximal zulässige Index der Bars in der Zeitreihe an den Kernel übergeben werden, um die Pufferlänge nicht zu überschreiten.
Dadurch sehen die Kernelargumente von tester_step(), der die offene Positionen verfolgen soll, wie folgt aus:
__kernel void tester_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1, // Differenz in Preisen, nicht in Points __global ulong *TimeM1, __global int *OrderM1, // Auftragspuffer, wobei [0] den Index von OHLC(M1), [1] - (kaufen/verkaufen) enthält __global int *Tasks, // Aufgabenpuffer (der offenen Positionen) speichert die Indices der Aufträge im Puffer OrderM1 __global int *Left, // Anzahl der verbliebenen Aufgaben, zwei Elemente: [0] - für bank0, [1] - für bank1 __global double *Res, // Ergebnispuffer const uint bank, // laufende Bank const uint orders, // Auftragsanzahl in OrderM1 const uint start_bar, // Seriennummer der bearbeiteten Bar (asl Abstand zum angegebenen Index in OrderM1) const uint stop_bar, // die letzte zu bearbeitenden Bar const uint maxbar, // maximal akzeptabler Barindex (die letzte Bar des Arrays) const double tp_dP, // TP als Preisdifferenz const double sl_dP, // SL als Preisdifferenz const ulong timeout) // für das zwangsweise Schließen einer Position (in Sekunden)
Der Kernel tester_step() arbeitet in zwei Dimensionen. Die Größe der Dimension der Aufgaben ändert sich bei jedem Aufruf, die mit der Nummer des Auftrags beginnt und sich mit jedem Durchlauf vermindert.
Wir erhalten eine Arbeits-ID (task ID) beim Start des Kernels:
size_t id=get_global_id(0);
Dann, basierend auf dem Index der aktuellen Bank, der über das Argument bank übergeben wird, berechnen wir den Index wie folgt:
uint bank_next=(bank)?0:1;
Wir berechnen den Index des Auftrags, mit der wir arbeiten sollen. Beim ersten Start (wenn start_bar gleich Null ist) entspricht der Task-Puffer dem Auftragspuffer, d.h. der Auftragsindex ist gleich dem Arbeitsindex. Bei den nachfolgenden Starts wird der Auftragsindex aus dem Aufgabenpuffer unter Berücksichtigung der aktuellen Bank und des Arbeitsindex ermittelt:
if(!start_bar) idx=id; else idx=Tasks[(orders*bank)+id];
Da wir den Auftragsindex kennen, erhalten wir den Index der Bar in der Zeitreihe und die Arbeitsnummer:
//--- Index der Bar der Positionseröffnung im Puffer M1 uint iO=OrderM1[idx*2]; //--- (OP_BUY/OP_SELL) Aktion uint op=OrderM1[(idx*2)+1];
Auf Basis des Wertes des Arguments timeout, wird die Zeit berechnet für ein erzwungenes Schließen der Position:
ulong tclose=TimeM1[iO]+timeout;
Dann wird die offene Position bearbeitet. Betrachten wir beispielsweise den Umgang mit KAUF-Positionen (mit VERKAUFS-Positionen wird ähnlich verfahren).
if(op==OP_BUY) { //--- Eröffnungspreis der Position double open=OpenM1[iO]+SpreadM1[iO]; double tp = open+tp_dP; double sl = open-sl_dP; double p=0; for(uint j=iO+start_bar; j<=(iO+stop_bar); j++) { for(uint k=0;k<4;k++) { if(k==0) { p=OpenM1[j]; if(j>=maxbar || TimeM1[j]>=tclose) { //--- erzwungenes Schließen wegen der Zeit Res[idx]=p-open; return; } } else if(k==1) p=HighM1[j]; else if(k==2) p=LowM1[j]; else p=CloseM1[j]; //--- prüfen, on TP oder SL ausgelöst wurden if(p<=sl) { Res[idx]=sl-open; return; } else if(p>=tp) { Res[idx]=tp-open; return; } } } }
Wenn keine der Bedingung für das Verlassen des Kernels erfüllt sind, wird die Aufgabe auf den nächsten Durchlauf verschoben:
uint i=atomic_inc(&Left[bank_next]);
Tasks[(orders*bank_next)+i]=idx;
Nachdem alle Durchläufe bearbeitet wurden, speichert der Puffer Res[] die Ergebnisse aller Positionen. Um das Testergebnis zu erhalten, müssten diese zusammengefasst werden.
Nachdem der Algorithmus klar ist und die Kernel bereit sind, sollten wir damit beginnen, zu starten.
2.3 Starten eines Tests
Die Klasse CTestPatterns wird uns dabei helfen:
class CTestPatterns : private COpenCLx { private: CBuffering *m_sbuf; // Zeitreihen des aktuellen Zeitrahmens CBuffering *m_tbuf; // Zeitreihen des M1-Zeitrahmens int m_prepare_passes; uint m_tester_passes; bool LoadTimeseries(datetime from,datetime to); bool LoadTimeseriesOCL(void); bool test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); bool optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); void buffers_free(void); public: CTestPatterns(); ~CTestPatterns(); //--- starten eines Einzeltests bool Test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); //--- starten der Optimierung bool Optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); //--- abrufen der Pointer auf das Programm der Statistik COCLStat *GetStat(void){return &m_stat;} //--- Abfrage des letzten fehlers int GetLastError(void){return m_last_error.code;} //--- abrufen der Struktur des letzten Fehlers STR_ERROR GetLastErrorExt(void){return m_last_error;} //--- Rücksetzen des letzten Fehlers void ResetLastError(void); //--- Anzahl der Durchläufe, in die der Start des Testkerns unterteilt ist. void SetTesterPasses(uint tp){m_tester_passes=tp;} //--- Anzahl der Durchläufe, in die der Start des Kernels der Auftragsvorbereitung unterteilt ist. void SetPrepPasses(int p){m_prepare_passes=p;} };
Betrachten wir die Methode Test() im Detail:
bool CTestPatterns::Test(STR_TEST_RESULT &result,datetime from,datetime to,STR_TEST_PARS &par) { ResetLastError(); m_stat.Reset(); m_stat.time_total.Start(); //--- hochladen der Daten der Zeitreihen m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- initialisieren von OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_TESTER)==false) return false; m_stat.time_ocl_init.Stop(); //--- Teststart bool result=test(stat,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return result; }
Beim Start gibt es eine Zeitspanne, in der die Strategie getestet werden soll, sowie die Links zur Struktur der Parameter und der Testergebnisse.
Wenn erfolgreich, gibt die Methode 'true' zurück und schreibt die Ergebnisse in das Argument "result". Wenn während der Ausführung ein Fehler aufgetreten ist, gibt die Methode 'false' zurück. Um Fehlerdetails zu erhalten, rufen wir GetLastErrorExt() auf.
Zuerst laden wir die Daten der Zeitreihe hoch. Dann initialisieren wir OpenCL. Dazu gehört auch das Erstellen von Objekten und der Kernel. Wenn alles in Ordnung ist, rufen wir die Methode test() auf, die den gesamten Testalgorithmus enthält. Tatsächlich ist die Methode Test() ein Wrapper für test(). Dies geschieht, um sicherzustellen, dass die Deinitialisierung nach jedem Ende "test"-Methode durchgeführt wird und Zeitreihenpuffer freigegeben werden.
In der Methode test() beginnt alles mit dem Hochladen von Zeitreihenpuffern in die OpenCL-Puffer:if(LoadTimeseriesOCL () ==false)returnfalse;
Die geschieht mit der oben bereits beschriebenen Methode LoadTimeseriesOCL().
Der Kernel find_patterns(), der mit der Enumeration k_FIND_PATTERNS korrespondiert, wird zuerst gestartet. Vor dem Start, sollten wir die Puffer der Aufträge und der Ergebnisse erstellen:
_BufferCreate(buf_ORDER,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
Die Größe des Auftrags-Puffers ist doppelt so groß wie die des aktuellen Zeitrahmens. Da wir nicht genau wissen, wieviele Muster gefunden werden, wird angenommen, es gäbe ein Muster auf jeder Bar. Diese Annahme mag auf den ersten Blick absurd erscheinen. Im Weiteren aber, wenn zusätzliche Muster hinzugefügt werden, würde uns das viele Probleme ersparen.
Bestimmen der Argumente:
_SetArgumentBuffer(k_FIND_PATTERNS,0,buf_OPEN); _SetArgumentBuffer(k_FIND_PATTERNS,1,buf_HIGH); _SetArgumentBuffer(k_FIND_PATTERNS,2,buf_LOW); _SetArgumentBuffer(k_FIND_PATTERNS,3,buf_CLOSE); _SetArgumentBuffer(k_FIND_PATTERNS,4,buf_ORDER); _SetArgumentBuffer(k_FIND_PATTERNS,5,buf_COUNT); _SetArgument(k_FIND_PATTERNS,6,double(par.ref)*_Point); _SetArgument(k_FIND_PATTERNS,7,par.flags);
Für den Kernel find_patterns() bestimmen wir einen eindimensionalen Arbeitsraum mit einem Offset von Null:
uint global_size[1]; global_size[0]=m_sbuf.Depth; uint work_offset[1]={0};
Wir beginnen die Ausführung des Kernels find_patterns().
_Execute(k_FIND_PATTERNS,1,work_offset,global_size);
Es ist zu beachten, dass das Beenden der Methode Execute() nicht bedeutet, dass das Programm ausgeführt wird. Es kann noch ausgeführt oder zur Ausführung in die Warteschlange gestellt werden. Um den aktuellen Status zu ermitteln, verwenden wir die Funktion CLExecutionStatus(). Wenn wir auf den Abschluss des Programms warten müssen, können wir seinen Status regelmäßig überwachen oder den Puffer lesen, in den das Programm die Ergebnisse stellt. Im zweiten Fall erfolgt das Warten auf die Beendigung des Programms in der Methode BufferRead() zum Lesen der Puffer.
_BufferRead(buf_COUNT,count,0,0,2);
Jetzt können wir beim Index 0 des Puffers Count[] die Anzahl der erkannten Muster oder die Anzahl der Aufträge im entsprechenden Puffer finden. Der nächste Schritt besteht darin, die entsprechenden Einstiegspunkte im M1-Zeitrahmen zu finden. Der Kernel order_to_M1() summiert die erfasste Menge in den gleichen Puffer count[], allerdings bei Index 1. Das Auslösen der Bedingung (count[0]==count[1]) gilt als erfolgreich.
Aber zuerst müssen wir den Puffer der Aufträge für M1 erstellen und ihn mit dem Wert -1 füllen. Da wir die Anzahl der Aufträge bereits kennen, geben wir die genaue Größe des Puffers an:
int len=count[0]*2; _BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
Wir setzen die Argumente für den Kernel array_fill():
_SetArgumentBuffer(k_ARRAY_FILL,0,buf_ORDER_M1); _SetArgument(k_ARRAY_FILL,1,int(-1));
Wir setzen den eindimensionalen Aufgabenraum mit dem Anfangswert Null und der Größe des Puffers Start der Ausführung:
uint opt_init_work_size[1]; opt_init_work_size[0]=len; uint opt_init_work_offset[1]={0}; _Execute(k_ARRAY_FILL,1,opt_init_work_offset,opt_init_work_size);
Als nächstes sollten wir die Ausführung des Kernels order_to_M1() starten:
//--- bestimmen der Argumente _SetArgumentBuffer(k_ORDER_TO_M1,0,buf_TIME); _SetArgumentBuffer(k_ORDER_TO_M1,1,buf_TIME_M1); _SetArgumentBuffer(k_ORDER_TO_M1,2,buf_ORDER); _SetArgumentBuffer(k_ORDER_TO_M1,3,buf_ORDER_M1); _SetArgumentBuffer(k_ORDER_TO_M1,4,buf_COUNT); //--- der Aufgabenraum für den Kernel k_ORDER_TO_M1 ist zweidimensional uint global_work_size[2]; //--- die erste Dimension enthält die übriggebliebenen Aufträge des Kernels k_FIND_PATTERNS global_work_size[0]=count[0]; //--- die zweite Dimension enthält alle M1-Bars global_work_size[1]=m_tbuf.Depth; //--- der anfängliche Offset im Aufgabenraum für beide Dimensionen ist gleich Null uint global_work_offset[2]={0,0};
Das Argument mit dem Index 5 wird nicht gesetzt, da sein Wert unterschiedlich ist und es unmittelbar vor dem Start der Kernelausführung gesetzt wird. Aus dem oben genannten Grund kann die Ausführung des Kernels order_to_M1() mehrmals mit unterschiedlichem Offsetwert in Sekunden ausgeführt werden. Die maximale Anzahl der Starts wird durch das Verhältnis der Dauer der aktuellen und M1-Diagramme begrenzt:
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1);
Die ganze Schleife sieht so aus:
for(int s=0;s<maxshift;s++) { //--- setzen des Offset des aktuellen Durchlaufs _SetArgument(k_ORDER_TO_M1,5,ulong(s*60)); //--- ausführen des Kernels _Execute(k_ORDER_TO_M1,2,global_work_offset,global_work_size); //--- lesen der Ergebnisse _BufferRead(buf_COUNT,count,0,0,2); //--- auf dem Index 0, befinden sich die Anzahl der Aufträge auf dem aktuellen Chart //--- auf dem Index 1, die Anzahl der entsprechenden Bars im M1-Chart //--- wenn beide Werte übereinstimmen, wird der Schleife verlassen if(count[0]==count[1]) break; //--- andernfalls wird mit der nächsten Iteration fortgesetzt und der Kernel mit einem anderen Offset gestartet } //--- nochmal prüfen, ob die Anzahl der Aufträge stimmt, falls die Schleife eben nicht mittels 'break' beendet wurde if(count[0]!=count[1]) { SET_UERRt(UERR_ORDERS_PREPARE,"M1 orders preparation error"); return false; }
Jetzt ist es an der Zeit, den Kernel tester_step() zu starten, der die Ergebnisse der Positionen berechnet, die von erkannten Einstiegspunkten geöffnet wurden. Zuerst erstellen wir die fehlenden Puffer und setzen die Argumente:
//--- erstellen des Aufgabenpuffers, wobei die Anzahl der Aufgaben des nächsten Durchlaufs ermittelt wird _BufferCreate(buf_TASKS,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); //--- erstellen des Ergebnispuffers, dem die Ergebnisse zugewiesen werden _BufferCreate(buf_RESULT,m_sbuf.Depth*sizeof(double),CL_MEM_READ_WRITE); //--- setzen der Argumente für den Kernel eines Einzeltests _SetArgumentBuffer(k_TESTER_STEP,0,buf_OPEN_M1); _SetArgumentBuffer(k_TESTER_STEP,1,buf_HIGH_M1); _SetArgumentBuffer(k_TESTER_STEP,2,buf_LOW_M1); _SetArgumentBuffer(k_TESTER_STEP,3,buf_CLOSE_M1); _SetArgumentBuffer(k_TESTER_STEP,4,buf_SPREAD_M1); _SetArgumentBuffer(k_TESTER_STEP,5,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_STEP,6,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_STEP,7,buf_TASKS); _SetArgumentBuffer(k_TESTER_STEP,8,buf_COUNT); _SetArgumentBuffer(k_TESTER_STEP,9,buf_RESULT); uint orders_count=count[0]; _SetArgument(k_TESTER_STEP,11,uint(orders_count)); _SetArgument(k_TESTER_STEP,14,uint(m_tbuf.Depth-1)); _SetArgument(k_TESTER_STEP,15, double(par.tp)*_Point); _SetArgument(k_TESTER_STEP,16, double(par.sl)*_Point); _SetArgument(k_TESTER_STEP,17,ulong(par.timeout));
Als Nächstes konvertieren wir die maximale Haltezeit in die Anzahl der Bars auf M1:
uint maxdepth=(par.timeout/PeriodSeconds(PERIOD_M1))+1;
Dann prüfen wir, ob die angegebene Anzahl der Ausführungsdurchläufe der Kernel gültig ist. Standardmäßig sind es 8, aber um die optimale Leistung für verschiedene OpenCL-Geräte zu definieren, ist es erlaubt, andere Werte mit der Methode SetTesterPasses() einzustellen.
if(m_frames_counter<1) m_tester_passes=1; if(m_tester_passes>maxdepth) m_tester_passes=maxdepth; uint step_size=maxdepth/m_tester_passes;
Wir setzen die Größe des Arbeitsraums für eine einzelne Dimension und starten die Schleife zur Berechnung der Handelsergebnisse:
global_size[0]=orders_count; m_stat.time_ocl_test.Start(); for(uint i=0;i<m_tester_passes;i++) { //--- setzen des Index der laufenden Bank _SetArgument(k_TESTER_STEP,10,uint(i&0x01)); uint start_bar=i*step_size; //--- setzen des Index der Bar, mit dem der aktuelle Durchlauf startet _SetArgument(k_TESTER_STEP,12,start_bar); //--- setzen des Index der Bar, mit dem der Test während des laufenden Durchlaufs durchgeführt werden soll uint stop_bar=(i==(m_tester_passes-1))?(m_tbuf.Depth-1):(start_bar+step_size-1); _SetArgument(k_TESTER_STEP,13,stop_bar); //--- rücksetzen der Anzahl der Aufgaben in der nächsten Bank //--- damit soll die Anzahl der noch übrigen Aufträge für den nächsten Durchlauf gesichert werden count[(~i)&0x01]=0; _BufferWrite(buf_COUNT,count,0,0,2); //--- starten des Testkernels _Execute(k_TESTER_STEP,1,work_offset,global_size); //--- lesen der Anzahl der verbliebenen Aufträge für den nächsten Durchlauf _BufferRead(buf_COUNT,count,0,0,2); //--- setzt die neue Zahl an Aufgaben gleich der Anzahl an Aufträgen global_size[0]=count[(~i)&0x01]; //--- wenn keine Aufgaben mehr existieren, Schleife verlassen if(!global_size[0]) break; } m_stat.time_ocl_test.Stop();
Wir erstellen den Puffer zum Lesen der Handelsergebnisse:
double Result[]; ArrayResize(Result,orders_count); _BufferRead(buf_RESULT,Result,0,0,orders_count);
Um vergleichbare Ergebnisse zu denen des integrierten Testers zu erhalten, sollten die gelesenen Werte in _Point umgewandelt werden. Der Code zur Berechnung der Ergebnisse und Statistiken ist unten aufgeführt:
m_stat.time_proc.Start(); result.trades_total=0; result.gross_loss=0; result.gross_profit=0; result.net_profit=0; result.loss_trades=0; result.profit_trades=0; for(uint i=0;i<orders_count;i++) { double r=Result[i]/_Point; if(r>=0) { result.gross_profit+=r; result.profit_trades++; }else{ result.gross_loss+=r; result.loss_trades++; } } result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; m_stat.time_proc.Stop();
Schreiben wir noch ein Skript, das es uns erlaubt, unseren Tester zu starten.
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script Programm Start Funktion | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- setzen der Testparameter STR_TEST_PARS pars; pars.ref= 60; pars.sl = 350; pars.tp = 50; pars.flags=15; // alle Muster pars.timeout=12*3600; //--- Ergebnisstruktur STR_TEST_RESULT res; //--- Teststart tpat.Test(res,from,to,pars); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- Testergebnisse Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- Ausführungsstatistik COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Die verwendete Zeitspanne des Tests, das Symbol und der Zeitrahmen sind diejenigen, mit denen wir bereits den in MQL5 implementierten EA getestet haben. Die verwendeten Werte von Referenz und Stop-Loss sind diejenigen, die bei der Optimierung gefunden wurden. Jetzt müssen wir nur noch das Skript ausführen und das erhaltene Ergebnis mit dem des integrierten Testers vergleichen.
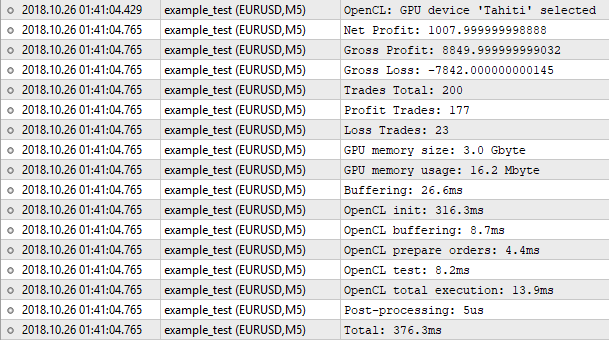
Abb. 8. Die Ergebnisse des in OpenCL implementierten Testers
Somit ist die Anzahl der Positionen gleich, während der Nettogewinn nicht gleich ist. Der integrierte Tester zeigt einen Wert von 1000,50 an, während unser Tester 1007,99 ausgibt. Der Grund dafür ist wie folgt. Um die gleichen Ergebnisse zu erzielen, müssten wir unter anderem die Swaps berücksichtigen. Aber die Implementierung in unseren Tester ist nicht gerechtfertigt. Für eine grobe Schätzung, bei der der Modus "1 Minute OHLC" angewendet wird, können solche Kleinigkeiten vernachlässigt werden. Wichtig ist, dass die Ergebnisse fast gleich sind, was bedeutet, dass unser Algorithmus korrekt funktioniert.
Werfen wir nun einen Blick auf die Statistik der Programmausführung. Es wurden nur 16 MB Speicherplatz benötigt. Die Initialisierung von OpenCL hat am meisten Zeit in Anspruch genommen. Der gesamte Prozess dauerte 376 Millisekunden, was dem integrierten Tester sehr ähnlich ist. Es ist sinnlos, hier einen Performancegewinn zu erwarten. Bei 200 Positionen werden wir mehr Zeit mit Vorbereitungsarbeiten wie Initialisierung, Kopieren von Puffern und so weiter verbringen. Um den Unterschied zu spüren, brauchen wir hundertmal mehr Aufträge für den Test. Es ist an der Zeit, zur Optimierung überzugehen.
2.4. Optimierung
Der Optimierungsalgorithmus soll dem einzelnen Testalgorithmus mit einem grundlegenden Unterschied ähnlich sein. Während wir im Tester nach Mustern suchen und dann die Handelsergebnisse zählen, ist hier die Reihenfolge der Aktionen unterschiedlich. Zuerst zählen wir die Handelsergebnisse und beginnen danach mit der Suche nach Mustern. Der Grund dafür ist, dass wir zwei optimierte Parameter haben. Der erste ist ein Referenzwert für das Auffinden der Muster. Der zweite ist Stop-Loss, der für die Berechnung des Handelsergebnisses verwendet wird. So beeinflusst einer von ihnen die Anzahl der Einstiegspunkte, während der andere Einfluss auf die Handelsergebnisse und die Dauer der Verfolgung der offenen Positionen hat. Wenn wir die gleiche Reihenfolge der Aktionen wie im einzelnen Testalgorithmus beibehalten, werden wir nicht vermeiden, dass ein erneuter Test der gleichen Einstiegspunkte zu einem enormen Zeitverlust führt, da sich die Pin-Bar mit einem "tail" von 300 Points bei jedem Referenzwert befindet, der gleich oder kleiner als dieser Wert ist.
Daher ist es in unserem Fall viel sinnvoller, die Ergebnisse der Positionen mit Einstiegspunkten auf jeder Bar (einschließlich Kauf und Verkauf) zu berechnen und dann mit diesen Daten während der Mustersuche zu arbeiten. Die Reihenfolge der Aktionen bei der Optimierung sieht also wie folgt aus:
- Herunterladen der Zeitreihenpuffer
- Initialisierung von OpenCL
- Kopieren der Zeitreihenpuffer in OpenCL-Puffer
- Starten der Vorbereitung des Auftragskernels (zwei Aufträge - Kauf und Verkauf - für jede Bar des aktuellen Zeitrahmens)
- Starten des Kernels, der Aufträge in das M1-Diagramm verschiebt.
- Starten des Kernels, der die Handelsergebnisse mittels der Aufträge zählt
- Starten des Kernels, der die Muster findet und die Testergebnisse für jede Kombination der optimierten Parameter der fertigen Handelsergebnisse findet
- Bearbeiten der Ergebnispuffer und nach den optimierten Parametern sucht, die zum besten Ergebnis führen
- Deinitialisierung von OpenCL
- Entfernen der Zeitreihenpuffer
Darüber hinaus wird die Anzahl der Aufgaben zum Durchsuchen von Mustern mit der Anzahl der Werte des Referenzwerts multipliziert und die Anzahl der Aufgaben zum Berechnen der Ergebnisse von Transaktionen wird mit der Anzahl der Werte der Stop-Loss-Stufe multipliziert.
2.4.1 Vorbereitung der Aufträge
Wir gehen davon aus, dass die gewünschten Muster auf jeder Bar zu finden sein könnten. Das bedeutet, dass wir für jede Bar eine Kauf- oder Verkaufsorder platzieren müssten. Die Puffergröße kann durch die folgende Gleichung definiert werden:
N = Depth*4*SL_count;
wobei Depth eine Größe der Puffer der Zeitreihen ist, während SL_count eine Anzahl von Stop-Loss Werten ist.
Außerdem sollten die Indizes der Bars aus der M1-Zeitreihe stammen. Der Kernel tester_opt_prepare() durchsucht die Zeitreihe nach M1 Bars mit der Öffnungszeit, die der Öffnungszeit der aktuellen Zeitrahmen entspricht, und platziert sie im oben angegebenen Format im Auftragspuffer. Im Allgemeinen ist seine Arbeit ähnlich wie die des Kernels order_to_M1():
__kernel void tester_opt_prepare(__global ulong *Time,__global ulong *TimeM1, __global int *OrderM1,// Auftragspuffer __global int *Count, const int SL_count, // Anzahl von SL const ulong shift) // Zeitversatz in Sekunden { //--- Arbeiten in zwei Dimensionen size_t x=get_global_id(0); //Index in Time if(OrderM1[x*SL_count*4]>=0) return; size_t y=get_global_id(1); //Index in TimeM1 if((Time[x]+shift)==TimeM1[y]) { //--- finden des höchsten Barindex für M1 atomic_max(&Count[1],y); uint offset=x*SL_count*4; for(int i=0;i<SL_count;i++) { uint idx=offset+i*4; //--- zwei Aufträge (Kauf- und Verkauf) für jede Bar hinzufügen OrderM1[idx++]=y; OrderM1[idx++]=OP_BUY |(i<<2); OrderM1[idx++]=y; OrderM1[idx] =OP_SELL|(i<<2); } atomic_inc(&Count[0]); } }
Es gibt jedoch einen wichtigen Unterschied — das Finden des maximalen Index der M1-Zeitreihe. Lassen Sie mich erklären, warum dies geschehen ist.
Bei der Prüfung eines einzelnen Durchlaufs haben wir es mit einer relativ geringen Anzahl von Aufträgen zu tun. Die Anzahl der Aufgaben, die der Anzahl der Aufträge multipliziert mit der Größe der Puffer der M1-Zeitreihe entspricht, ist ebenfalls relativ gering. Wenn wir die Daten betrachten, mit denen wir den Test durchgeführt haben, sind das 200 Aufträge multipliziert mit 279 039 М1-Bars, die letztlich 55,8 Millionen Aufgaben liefern.
In der aktuellen Situation wird die Anzahl der Aufgaben viel größer sein. Dies sind beispielsweise 279 039 M1-Bars multipliziert mit 55 843 Bars der aktuellen Periode (M5), was 15,6 Milliarden Aufgaben entspricht. Es lohnt sich auch zu bedenken, dass man diesen Kernel mit einem anderen Wert für Time-Shift erneut ausführen kann. Die Enumeratiosmethode ist hier zu ressourcenintensiv.
Um dieses Problem zu lösen, lassen wir die Aufzählung unverändert, obwohl wir den Handhabungsbereich der aktuellen Periodenbalken in mehrere Teile unterteilen. Außerdem sollten wir den Bereich der geeigneten Minutenbars begrenzen. Da jedoch der berechnete Indexwert des oberen Randes der Minutenbalken in den meisten Fällen den tatsächlichen übersteigt, geben wir nach Count[1] den maximalen Index eines Minutenbalkens zurück, um den nächsten Durchgang von diesem Punkt aus zu starten.
2.4.2 Erhalt der Handelsergebnisse
Nach der Vorbereitung der Aufträge ist es an der Zeit, Handelsergebnisse abzurufen.
Der Kernel Tester_opt_step() ist dem Tester_step() sehr ähnlich. Daher werde ich nicht den gesamten Code zur Verfügung stellen, sondern mich auf die Unterschiede konzentrieren. Zuerst haben sich die Eingaben geändert:
__kernel void tester_opt_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1,// in Preisdifferenzen, nicht in Points __global ulong *TimeM1, __global int *OrderM1, // Auftragspuffer, wobei [0] den Index von OHLC(M1), [1] - (kaufen/verkaufen) enthält __global int *Tasks, // Aufgabenpuffer (der offenen Positionen) speichert die Indices der Aufträge im Puffer OrderM1 __global int *Left, // Anzahl der verbliebenen Aufgaben, zwei Elemente: [0] - für bank0, [1] - für bank1 __global double *Res, // Ergebnispuffe, Zuweisung erfolgt gleich nach Erhalt, const uint bank, // der laufenden bank const uint orders, // Auftragsanzahl in OrderM1 const uint start_bar, // Seriennummer der bearbeiteten Bar (asl Abstand zum angegebenen Index in OrderM1) - tatsächlich kommt "i" aus der Schleife, die den Kernel startet const uint stop_bar, // die letzte zu bearbeitende Bar - meist gleich 'bar' const uint maxbar, // maximal akzeptabler Barindex (die letzte Bar des Arrays) const double tp_dP, // TP als Preisdifferenz const uint sl_start, // SL in Points - Anfangswert const uint sl_step, // SL in Points - Schrittweite const ulong timeout, // Laufzeit der Positionen (in Sekunden), danach werden sie zwangsweise geschlossen const double point) // _Point
Anstelle des Arguments sl_dP, mit dem der SL-Level-Wert, ausgedrückt in Preisdifferenz, übergeben wird, haben wir nun zwei Argumente: sl_start und sl_step sowie das Argument 'point'. Nun sollte die folgende Gleichung angewendet werden, um den SL-Pegelwert zu berechnen:
SL = (sl_start+sl_step*sli)*point;
wobei sli ein Wert des im Auftrag enthaltenen Stop-Loss Index ist.
Der zweite Unterschied ist ein Code zum Empfangen des Indexes sli aus dem Auftragspuffer:
//--- Aktion (bits 1:0) und SL-Index (bits 9:2) uint opsl=OrderM1[(idx*2)+1]; //--- SL-Index abrufen uint sli=opsl>>2;
Der Rest des Codes ist identisch mit Tester_step().
Nach der Ausführung erhalten wir Kauf- und Verkaufsergebnisse für jede Bar und jeden Stop-Loss im Res[] Puffer.
2.4.3 Die Suche nach den Mustern und die Formung der Testergebnisse
Im Gegensatz zum Testen fassen wir hier die Ergebnisse der Positionen direkt im Kernel zusammen, nicht im MQL-Code. Es gibt jedoch einen unangenehmen Nachteil — wir müssen die Ergebnisse in einen ganzzahligen Typ umwandeln, was zwangsläufig zu einem Verlust an Genauigkeit führt. Daher sollten wir im Argument point den Wert _Point dividiert durch 100 übergeben.
Die erzwungene Umwandlung der Ergebnisse in den Typ 'int' ist darauf zurückzuführen, dass die Atomicfunktionen nicht mit dem Typ 'double' umgehen können. atomic_add() ist für die Summierung der Ergebnisse zu verwenden.
Der Kernel find_patterns_opt() soll im dreidimensionalen Aufgabenraum arbeiten:
- Dimension 0: Barindex des aktuellen Zeitrahmens
- Dimension 1: Referenzwertindex der Muster
- Dimension 2: Stop-Loss Index
Im Laufe der Arbeit wird ein Ergebnispuffer erzeugt. Der Puffer enthält Teststatistiken für jede Kombination aus Stop-Loss und Referenzwert. Die Teststatistik ist eine Struktur, die die folgenden Werte enthält:
- Gesamtgewinn
- Gesamtverlust
- Anzahl der Positionen mit Gewinn
- Anzahl der Positionen mit Verlust
Alle sind vom Typ 'int'. Mit denen kann dann der Nettogewinn und die Gesamtzahl aller Positionen ermittelt werden. Der Code des Kernels ist im folgenden zu sehen:
__kernel void find_patterns_opt(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global double *Test, // Puffer der Testergebnisse von jeder Bar, die Größe ist 2*x*z ([0]-buy, [1]-sell ... ) __global int *Results, // Ergebnispuffer, Größe: 4*y*z const double ref_start, // Parameter der Muster const double ref_step, // const uint flags, // welche Muster sollen gesucht werden const double point) // _Point/100 { //--- arbeitet wmit drei Dimensionen //--- Barindex size_t x=get_global_id(0); //--- Ref.-Wert-Index size_t y=get_global_id(1); //--- SL-Index size_t z=get_global_id(2); //--- Anzahl der Bars size_t x_sz=get_global_size(0); //--- Anzahl der Ref.-Werte size_t y_sz=get_global_size(1); //--- Anzahl der SL-Werte size_t z_sz=get_global_size(2); //--- Größe des Raums der Mustersuche size_t depth=x_sz-PBARS; if(x>=depth)//nahe am Pufferende keine neue Position eröffnen return; // uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref_start+ref_step*y,flags); if(res==PAT_NONE) return; //--- berechnen des Indes des Handelsergebnisses für den Puffer Test[] int ri; if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) //verkaufen ri = (x+PBARS)*z_sz*2+z*2+1; else //kaufen ri=(x+PBARS)*z_sz*2+z*2; //--- abrufen des Ergebnisses des errechneten Index und konvertieren in Cents int r=Test[ri]/point; //--- berechnen des Index des Testergebnisses im Puffer Results[] int idx=z*y_sz*4+y*4; //--- hinzufügen des Handelsergebnisses zum aktuellen Muster if(r>=0) {//--- Gewinn //--- summieren des Gesamtgewinns in Cent atomic_add(&Results[idx],r); //--- Erhöhen der Anzahl der Positionen mit Gewinn atomic_inc(&Results[idx+2]); } else {//--- Verlust //--- summieren des Gesamtverlustes in Cent atomic_add(&Results[idx+1],r); //--- Erhöhen der Anzahl der Positionen mit Verlust atomic_inc(&Results[idx+3]); } }
Der Puffer Test[] in den Argumenten enthält die Ergebnisse nach der Ausführung des Kernels tester_opt_step().
2.5 Starten der Optimierung
Der Code zum Starten der Kernel aus MQL5 während der Optimierung ist ähnlich aufgebaut wie der Testprozess. Die öffentliche Methode Optimize() ist ein Wrapper der Methode optimize(), mit der die Reihenfolge der Vorbereitung und des Starts der Kernel festgelegt wird.
bool CTestPatterns::Optimize(STR_TEST_RESULT &result,datetime from,datetime to,STR_OPT_PARS &par) { ResetLastError(); if(par.sl.step<=0 || par.sl.stop<par.sl.start || par.ref.step<=0 || par.ref.stop<par.ref.start) { SET_UERR(UERR_OPT_PARS,"Optimization parameters are incorrect"); return false; } m_stat.Reset(); m_stat.time_total.Start(); //--- hochladen der Daten der Zeitreihen m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- initialisieren von OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_OPTIMIZER)==false) return false; m_stat.time_ocl_init.Stop(); //--- starten der Optimierung bool res=optimize(result,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return res; }
Wir werden nicht jede Zeile im Detail betrachten. Konzentrieren wir uns nur auf die Unterschiede, insbesondere den Start des Kernels tester_opt_prepare().
Erstellen wir zunächst den Puffer für die Verwaltung der Anzahl der bearbeiteten Bars und geben den maximalen Index der M1-Bars zurück:
int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
Dann bestimmen wir die Argumente und die Größe der Arbeitsraum.
_SetArgumentBuffer(k_TESTER_OPT_PREPARE,0,buf_TIME); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,1,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,2,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,3,buf_COUNT); _SetArgument(k_TESTER_OPT_PREPARE,4,int(slc)); // Anzahl von SL //--- der Kernel k_TESTER_OPT_PREPARE hat einen zweidimensionalen Aufgabenraum uint global_work_size[2]; //--- Dimension 0 - Aufträge des aktuellen Zeitrahmens global_work_size[0]=m_sbuf.Depth; //--- Dimension 1 - alle Bars von M1 global_work_size[1]=m_tbuf.Depth; //--- für den ersten Start wird der Offset im Aufgabenraum für beide Dimensionen auf Null setzen. uint global_work_offset[2]={0,0};
Der Offset der 1. Dimension im Arbeitsraum wird nach der Bearbeitung eines Teils der Bars vergrößert. Sein Wert soll gleich dem Maximalwert von М1 Bar sein, d.h. den um 1 erhöhten Kernel zurückgeben.
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1); int prep_step=m_sbuf.Depth/m_prepare_passes; for(int p=0;p<m_prepare_passes;p++) { //Offset des aktuellen Zeitrahmens im Aufgabenraum space global_work_offset[0]=p*prep_step; //Offset des Zeitrahmens M1 im Aufgabenraum global_work_offset[1]=count[1]; //Aufgabengröße des aktuellen Zeitrahmens global_work_size[0]=(p<(m_prepare_passes-1))?prep_step:(m_sbuf.Depth-global_work_offset[0]); //Aufgabengröße des M1-Zeitrahmens uint sz=maxshift*global_work_size[0]; uint sz_max=m_tbuf.Depth-global_work_offset[1]; global_work_size[1]=(sz>sz_max)?sz_max:sz; // count[0]=0; _BufferWrite(buf_COUNT,count,0,0,2); for(int s=0;s<maxshift;s++) { _SetArgument(k_TESTER_OPT_PREPARE,5,ulong(s*60)); //--- Kernelausführung _Execute(k_TESTER_OPT_PREPARE,2,global_work_offset,global_work_size); //--- abrufen der Ergebnisse (die Zahl sollte mit m_sbuf.Depth übereinstimmen) _BufferRead(buf_COUNT,count,0,0,2); if(count[0]==global_work_size[0]) break; } count[1]++; } if(count[0]!=global_work_size[0]) { SET_UERRt(UERR_ORDERS_PREPARE,"Failed to prepare M1 orders"); return false; }
Der Parameter m_prepare_passes gibt an, in wie viele Durchläufe die Auftragsvorbereitung unterteilt werden soll. Standardmäßig ist sein Wert 64, allerdings kann er mit der Methode SetPrepPasses() geändert werden.
Nach dem Lesen der Testergebnisse im Puffer OptResults[] wird nach der Kombination optimierter Parameter gesucht, die zu einem maximalen Nettogewinn führen.
int max_profit=-2147483648; uint idx_ref_best= 0; uint idx_sl_best = 0; for(uint i=0;i<refc;i++) for(uint j=0;j<slc;j++) { uint idx=j*refc*4+i*4; int profit=OptResults[idx]+OptResults[idx+1]; //sum+=profit; if(max_profit<profit) { max_profit=profit; idx_ref_best= i; idx_sl_best = j; } }
Danach werden die Ergebnisse in 'double' umgerechnet und die gewünschten Werte der optimierten Parameter in der entsprechenden Struktur zugewiesen.
uint idx=idx_sl_best*refc*4+idx_ref_best*4; result.gross_profit=double(OptResults[idx])/100; result.gross_loss=double(OptResults[idx+1])/100; result.profit_trades=OptResults[idx+2]; result.loss_trades=OptResults[idx+3]; result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; //--- par.ref.value= int(par.ref.start+idx_ref_best*par.ref.step); par.sl.value = int(par.sl.start+idx_sl_best*par.sl.step);
Beachten Sie, dass die Umwandlung von 'int' in 'double' und umgekehrt die Ergebnisse sicherlich beeinflusst, so dass sie sich leicht von denen unterscheiden, die während des Einzeltests erzielt wurden.
Schreiben wir ein kleines Skript, um die Optimierung zu starten:
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script Programm Start Funktion | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- setzen der Optimierungsparameter STR_OPT_PARS optpar; optpar.ref.start = 15; optpar.ref.step = 5; optpar.ref.stop = 510; optpar.sl.start = 15; optpar.sl.step = 5; optpar.sl.stop = 510; optpar.flags=15; optpar.tp=50; optpar.timeout=12*3600; //--- Ergebnisstruktur STR_TEST_RESULT res; //--- starten der Optimierung tpat.Optimize(res,from,to,optpar); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- Werte der optimierten Parameter Print("Ref: ",optpar.ref.value,", SL: ",optpar.sl.value); //--- Testergebnisse Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- Ausführungsstatistik COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Die Eingabeparameter sind die gleichen, die wir für die Optimierung mit dem integrierten Tester verwende. Starten wir:
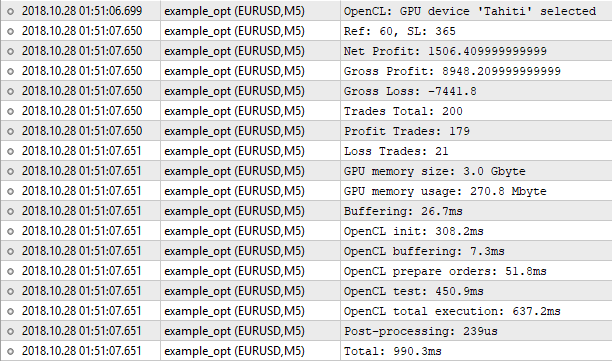
Abb. 9. Optimierung mit OpenCL
Wie man sieht, stimmen die Ergebnisse mit denen des integrierten Testers nicht überein. Warum? Könnte der Verlust der Genauigkeit bei der Umwandlung von 'double' in 'int' und umgekehrt dabei eine entscheidende Rolle spielen? Theoretisch könnte dies der Fall sein, wenn sich die Ergebniszahlen nach dem Komma unterscheiden. Aber die Unterschiede sind signifikant.
Der eingebaute Tester zeigt Ref = 60 und SL = 350 mit dem Nettogewinn von 1000,50. Der OpenCL-Tester zeigt Ref = 60 und SL = 365 mit dem Nettogewinn von 1506,40. Versuchen wir, einen normalen Tester mit den Werten des OpenCL-Testers auszuführen:

Abb. 10. Überprüfen der Optimierungsergebnisse des OpenCL-Testers
Das Ergebnis ist unserem sehr ähnlich. Das ist also nicht der Verlust der Genauigkeit. Der genetische Algorithmus hat diese Kombination von optimierten Parametern übersprungen. Starten wir den integrierten Tester im Modus der langsamen Optimierung mit dem Test aller Parameter.
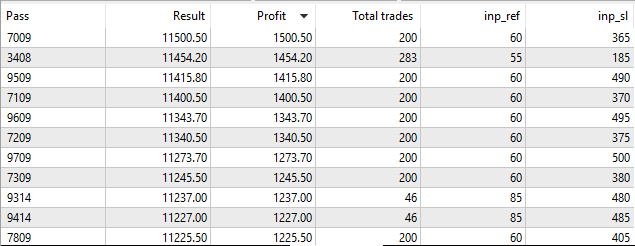
Abb. 11. Starten des integrierten Strategietesters im Modus der langsamen Optimierung
Wie wir sehen können, findet der integrierte Tester bei einer Optimierung mit allen Parametern die gleichen Sollwerte Ref = 60 und SL = 365 wie der OpenCL-Tester. Das bedeutet, dass der von uns implementierte Optimierungsalgorithmus korrekt funktioniert.
3. Leistungsvergleich
Jetzt ist es an der Zeit, die Leistung des integrierten mit der des OpenCL-Testers zu vergleichen.
Wir werden den Zeitaufwand für die Optimierung der Parameter der oben beschriebenen Strategie vergleichen. Der integrierte Tester soll in zwei Modi gestartet werden: schnell (genetischer Algorithmus, ausgewählte Parameterkombinationen) und langsam optimiert (alle Parameterkombinationen). Der Start erfolgt auf einem PC mit den folgenden Eigenschaften:
| Betriebssystem |
Windows 10 (build 17134) x64 |
| CPU |
AMD FX-8300 Eight-Core Processor, 3600MHz |
| RAM |
24 574 Mb |
| Typ der Medien, auf denen der MetaTrader installiert wurde |
HDD |
6 von 8 Kernen sind den Testagenten zugeordnet.
Der OpenCL-Tester soll auf AMD Radeon HD 7950 Video 3Gb RAM und 800Mhz GPU-Frequenz gestartet werden.
Die Optimierung soll mit drei Paaren durchgeführt werden: EURUSD, GBPUSD und USDJPY. Bei jedem Paar wird die Optimierung in vier Zeitbereichen für jeden Optimierungsmodus durchgeführt. Wir werden die folgenden Abkürzungen verwenden:
| Optimierungsmodus |
Beschreibung |
|---|---|
| Tester Fast |
Integrierter Strategietester, genetischer Algorithmus |
| Tester Slow |
Integrierter Strategietester, es werden alle Parameterkombinationen getestet |
| Tester OpenCL |
Tester, der OpenCL verwendet |
Ausersehene Testzeiträume:
| Zeiträume |
Zeitspannen |
|---|---|
| 1 month |
2018.09.01 - 2018.10.01 |
| 3 Monate |
2018.07.01 - 2018.10.01 |
| 6 Monate |
2018.04.01 - 2018.10.01 |
| 9 Monate |
2018.01.01 - 2018.10.01 |
Das für uns wichtigste Ergebnis sind die Werte der gesuchten Parameter, den Nettogewinn, die Anzahl der Positionen und der Zeitbedarf für die Optimierung.
3.1. Optimization on EURUSD
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
15 |
15 |
15 |
| Stop-Loss |
330 |
510 |
500 |
| Gesamt netto Profit |
942.5 |
954.8 |
909.59 |
| Anzahl der Positionen |
48 |
48 |
47 |
| Dauer der Optimierung |
10 Sek. |
6 Min. 2 Sek. |
405.8 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 50 |
65 |
70 |
| Stop-Loss | 250 |
235 |
235 |
| Gesamt netto Profit | 1233.8 |
1503.8 |
1428.35 |
| Anzahl der Positionen | 110 |
89 |
76 |
| Dauer der Optimierung | 9 Sek. |
8 Min. 8 Sek. |
457.9 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 15 |
20 |
20 |
| Stop-Loss | 455 |
435 |
435 |
| Gesamt netto Profit | 1641.9 |
1981.9 |
1977.42 |
| Anzahl der Positionen | 325 |
318 |
317 |
| Dauer der Optimierung | 15 Sec. |
11 Min. 13 Sek. |
405.5 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 15 |
15 |
15 |
| Stop-Loss | 440 |
435 |
435 |
| Gesamt netto Profit | 1162.0 |
1313.7 |
1715.77 |
| Anzahl der Positionen | 521 |
521 |
520 |
| Dauer der Optimierung | 20 Sek. |
16 Min. 44 Sek. |
438.4 ms |
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
135 |
45 |
45 |
| Stop-Loss |
270 |
205 |
205 |
| Gesamt netto Profit |
47 |
417 |
419.67 |
| Anzahl der Positionen |
1 |
39 |
39 |
| Dauer der Optimierung |
7 Sek. |
9 Min. 27 Sek. |
418 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 120 |
70 |
70 |
| Stop-Loss | 440 |
405 |
405 |
| Gesamt netto Profit | 147 |
342 |
344.85 |
| Anzahl der Positionen | 3 |
16 |
16 |
| Dauer der Optimierung | 11 Sek. |
8 Min. 25 Sek. |
585.9 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 85 |
70 |
70 |
| Stop-Loss | 440 |
470 |
470 |
| Gesamt netto Profit | 607 |
787 |
739.6 |
| Anzahl der Positionen | 22 |
47 |
46 |
| Dauer der Optimierung | 21 Sek. |
12 Min. 03 Sek. |
796.3 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 60 |
60 |
60 |
| Stop-Loss | 495 |
365 |
365 |
| Gesamt netto Profit | 1343.7 |
1500.5 |
1506.4 |
| Anzahl der Positionen | 200 |
200 | 200 |
| Dauer der Optimierung | 20 Sek. |
16 Min. 44 Sek. |
438.4 ms |
3.2. Optimierung auf GBPUSD
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
175 |
90 |
90 |
| Stop-Loss |
435 |
185 |
185 |
| Gesamt netto Profit |
143.40 |
173.4 |
179.91 |
| Anzahl der Positionen |
3 |
13 |
13 |
| Dauer der Optimierung |
10 Sek. |
4 Min. 33 Sek. |
385.1 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 175 |
145 |
145 |
| Stop-Loss | 225 |
335 |
335 |
| Gesamt netto Profit | 93.40 |
427 |
435.84 |
| Anzahl der Positionen | 13 |
19 |
19 |
| Dauer der Optimierung | 12 Sek. |
7 Min. 37 Sek. |
364.5 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 165 |
170 |
165 |
| Stop-Loss | 230 |
335 | 335 |
| Gesamt netto Profit | 797.40 |
841.2 |
904.72 |
| Anzahl der Positionen | 31 |
31 |
32 |
| Dauer der Optimierung | 18 Sek. |
11 Min. 3 Sek. |
403.6 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 165 |
165 | 165 |
| Stop-Loss | 380 |
245 |
245 |
| Gesamt netto Profit | 1303.8 |
1441.6 |
1503.33 |
| Anzahl der Positionen | 74 |
74 |
75 |
| Dauer der Optimierung | 24 Sek. |
19 Min. 23 Sek. |
428.5 ms |
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
335 |
45 |
45 |
| Stop-Loss |
450 |
485 |
485 |
| Gesamt netto Profit |
50 |
484.6 |
538.15 |
| Anzahl der Positionen |
1 |
104 |
105 |
| Dauer der Optimierung |
12 Sek. |
9 Min. 42 Sek. |
412.8 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 450 | 105 |
105 |
| Stop-Loss | 440 | 240 |
240 |
| Gesamt netto Profit | 0 |
220 |
219.88 |
| Anzahl der Positionen | 0 |
16 |
16 |
| Dauer der Optimierung | 15 Sec. |
8 Min. 17 Sek. |
552.6 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 510 |
105 |
105 |
| Stop-Loss | 420 |
260 |
260 |
| Gesamt netto Profit | 0 |
220 |
219.82 |
| Anzahl der Positionen | 0 |
23 |
23 |
| Dauer der Optimierung | 24 Sek. |
14 Min. 58 Sek. |
796.5 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 185 |
195 |
185 |
| Stop-Loss | 205 |
160 |
160 |
| Gesamt netto Profit | 195 |
240 |
239.92 |
| Anzahl der Positionen | 9 |
9 |
9 |
| Dauer der Optimierung | 25 Sek. |
20 Min. 58 Sek. |
4.4 ms |
3.3. Optimierung auf USDJPY
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
60 |
50 |
50 |
| Stop-Loss |
425 |
510 |
315 |
| Gesamt netto Profit |
658.19 |
700.14 |
833.81 |
| Anzahl der Positionen |
18 |
24 |
24 |
| Dauer der Optimierung |
6 Sek. |
4 Min. 33 Sek. |
387.2 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 75 |
55 |
55 |
| Stop-Loss | 510 |
510 |
460 |
| Gesamt netto Profit | 970.99 |
1433.95 |
1642.38 |
| Anzahl der Positionen | 50 |
82 |
82 |
| Dauer der Optimierung | 10 Sek. |
6 Min. 32 Sek. |
369 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 150 |
150 |
150 |
| Stop-Loss | 345 |
330 |
330 |
| Gesamt netto Profit | 273.35 |
287.14 |
319.88 |
| Anzahl der Positionen | 14 |
14 |
14 |
| Dauer der Optimierung | 17 Sek. |
11 Min. 25 Sek. |
409.2 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 190 |
190 |
190 |
| Stop-Loss | 425 |
510 |
485 |
| Gesamt netto Profit | 244.51 |
693.86 |
755.84 |
| Anzahl der Positionen | 16 |
16 |
16 |
| Dauer der Optimierung | 24 Sek. |
17 Min. 47 Sek. |
445.3 ms |
H1, 1 Monat:
| Ergebnis |
Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference |
30 |
35 |
35 |
| Stop-Loss |
225 |
100 |
100 |
| Gesamt netto Profit |
373.60 |
623.73 |
699.79 |
| Anzahl der Positionen |
53 |
35 |
35 |
| Dauer der Optimierung |
7 Sek. |
4 Min. 34 Sek. |
415.4 ms |
H1, 3 Monate:
| Ergebnis | Tester Fast |
Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 45 |
40 |
40 |
| Stop-Loss | 335 |
250 |
250 |
| Gesamt netto Profit | 1199.34 |
1960.96 |
2181.21 |
| Anzahl der Positionen | 71 |
99 |
99 |
| Dauer der Optimierung | 12 Sek. |
8 Min. |
607.2 ms |
H1, 6 Monate:
| Ergebnis | Tester Fast | Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 130 |
40 |
40 |
| Stop-Loss | 400 |
130 |
130 |
| Gesamt netto Profit | 181.12 |
1733.9 |
1908.77 |
| Anzahl der Positionen | 4 |
229 |
229 |
| Dauer der Optimierung | 19 Sek. |
12 Min. 31 Sek. |
844 ms |
H1, 9 Monate:
| Ergebnis | Tester Fast |
Tester Slow |
Tester OpenCL |
|---|---|---|---|
| Reference | 35 |
30 |
30 |
| Stop-Loss | 460 |
500 |
500 |
| Gesamt netto Profit | 3701.30 |
5612.16 |
6094.31 |
| Anzahl der Positionen | 681 |
1091 |
1091 |
| Dauer der Optimierung | 34 Sek. |
18 Min. 56 Sek. |
1 Sek. |
3.4. Tabelle der Leistungsergebnisse
Die erzielten Ergebnisse zeigen, dass der integrierte Tester im schnellen Optimierungsmodus (genetischer Algorithmus) oft die besten Ergebnisse überspringt. Daher ist es fairer, die Leistung bei einer Optimierung aller Parametermöglichkeiten mit der von OpenCL zu vergleichen. Für mehr Transparenz sollten wir eine Übersichtstabelle über die Zeit, die für die Optimierung aufgewendet wird, erstellen.
| Optimierungsbedingungen |
Tester Slow |
Tester OpenCL |
Verhältnis |
|---|---|---|---|
| EURUSD, H1, 1 Monat: |
6 Min. 2 Sek. |
405.8 ms |
891 |
| EURUSD, H1, 3 Monat: |
8 Min. 8 Sek. |
457.9 ms |
1065 |
| EURUSD, H1, 6 Monat: |
11 Min. 13 Sek. |
405.5 ms |
1657 |
| EURUSD, H1, 9 Monat: |
16 Min. 44 Sek. |
438.4 ms |
2292 |
| EURUSD, H1, 1 Monat: |
9 Min. 27 Sek. |
418 ms |
1356 |
| EURUSD, H1, 3 Monat: |
8 Min. 25 Sek. |
585.9 ms |
861 |
| EURUSD, H1, 6 Monat: |
12 Min. 3 Sek. |
796.3 ms |
908 |
| EURUSD, H1, 9 Monat: |
17 Min. 39 Sek. |
1 Sek. |
1059 |
| GBPUSD, H1, 1 Monat: | 4 Min. 33 Sek. |
385.1 ms |
708 |
| GBPUSD, H1, 3 Monat: | 7 Min. 37 Sek. |
364.5 ms |
1253 |
| GBPUSD, H1, 6 Monat: | 11 Min. 3 Sek. |
403.6 ms |
1642 |
| GBPUSD, H1, 9 Monat: | 19 Min. 23 Sek. |
428.5 ms |
2714 |
| GBPUSD, H1, 1 Monat: | 9 Min. 42 Sek. |
412.8 ms |
1409 |
| GBPUSD, H1, 3 Monat: | 8 Min. 17 Sek. |
552.6 ms |
899 |
| GBPUSD, H1, 6 Monat: | 14 Min. 58 Sek. |
796.4 ms |
1127 |
| GBPUSD, H1, 9 Monat: | 20 Min. 58 Sek. |
970.4 ms |
1296 |
| GBPUSD, H1, 1 Monat: | 4 Min. 33 Sek. |
387.2 ms |
705 |
| GBPUSD, H1, 3 Monat: | 6 Min. 32 Sek. |
369 ms |
1062 |
| USDJPY, H1, 6 Monat: | 11 Min. 25 Sek. |
409.2 ms |
1673 |
| USDJPY, H1, 9 Monat: | 17 Min. 47 Sek. |
455.3 ms |
2396 |
| USDJPY, M5, 1 Monat: | 4 Min. 34 Sek. |
415.4 ms |
659 |
| USDJPY, H1, 3 Monat: | 8 Min. |
607.2 ms |
790 |
| USDJPY, M5, 6 Monat: | 12 Min. 31 Sek. |
844 ms |
889 |
| USDJPY, M5, 9 Monat: | 18 Min. 56 Sek. |
1 Sek. |
1136 |
Schlussfolgerung
In diesem Artikel haben wir den Algorithmus zum Aufbau eines Testers für die einfachste Handelsstrategie mit OpenCL implementiert. Natürlich ist diese Implementierung nur eine der möglichen Lösungen, und sie hat viele Nachteile. Unter ihnen sind:
- Arbeiten im Modus "1 Minute OHLC", geeignet nur für grobe Schätzungen.
- Keine Berücksichtigungen von Swaps und Provisionen
- Falsches Arbeiten mit Umtauschraten
- Kein Trailing-Stop
- Keine Berücksichtigung der Anzahl der gleichzeitig geöffneten Positionen
- Kein Nachteil bei der Rückgabe von Parametern
Trotzdem kann der Algorithmus sehr hilfreich sein, wenn es darum geht, die Leistung der einfachsten Muster schnell und grob zu bewerten, da er es Ihnen ermöglicht, dies tausendmal schneller zu bewältigen als der integrierte Tester, wenn er mit der langsamen, vollständigen Optimierung läuft, und zehnmal schneller als der Tester mit dem genetischen Algorithmus.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/4236
 Entwicklung eines Symbolauswahl- und Navigationsprogramms in MQL5 und MQL4
Entwicklung eines Symbolauswahl- und Navigationsprogramms in MQL5 und MQL4
 Die eigene, multi-threaded, asynchrone Web-Anfrage in MQL5
Die eigene, multi-threaded, asynchrone Web-Anfrage in MQL5
 Die Wahrscheinlichkeitstheorie für den Handel von Kurslücken verwenden
Die Wahrscheinlichkeitstheorie für den Handel von Kurslücken verwenden
 Umkehrung: Formalisieren des Einstiegspunktes und die Entwicklung eines Algorithmus für den manuellen Handel
Umkehrung: Formalisieren des Einstiegspunktes und die Entwicklung eines Algorithmus für den manuellen Handel
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.