
OpenCL: Die Brücke zu parallelen Welten

Einleitung
Dieser Beitrag ist der erste in einer kurzen Reihe von Publikationen zur Programmierung in OpenCL oder Open Computing Language. Vor der Unterstützung von OpenCL erlaubte die MetaTrader-5-Plattform in ihrer aktuellen Form nicht den direkten, d. h. nativen Gebrauch und Genuss der Vorteile von Multi-Core-Prozessoren zur Beschleunigung von Berechnungen.
Natürlich konnten die Entwickler endlos betonen, dass das Terminal Multithreading-fähig ist und dass "alle EAs/Scripts in einem separaten Thread ausgeführt werden", doch der Programmierer hat keine Möglichkeit für eine relativ einfache parallele Ausführung der folgenden simplen Schleife (ein Code zum Berechnen des Wertes von Pi = 3,14159265...):
long num_steps = 1000000000; double step = 1.0 / num_steps; double x, pi, sum = 0.0; for (long i = 0; i<num_steps; i++) { x = (i + 0.5)*step; sum += 4.0/(1.0 + x*x); } pi = sum*step;
Doch schon 18 Monate vor diesem Beitrag erschien im Bereich "Beiträge" eine sehr interessante Arbeit mit dem Titel "Parallele Berechnungen in MetaTrader 5". Und dennoch erhält man den Eindruck, dass dieser Ansatz trotz seiner Raffinesse etwas unnatürlich ist – eine ganze Programmhierarchie (der Expert Advisor und zwei Indikatoren), geschrieben, um die Berechnungen in der oben aufgeführten Schleife zu beschleunigen, wäre zu viel des Guten gewesen.
Wir wissen bereits, dass keine Unterstützung von OpenMP geplant ist, und sind uns bewusst, dass das Hinzufügen von OMP eine drastische Neuprogrammierung des Compilers erfordert. Leider wird es keine günstige und einfache Lösung für Programmierer geben, die keine eigenen Denkleistungen voraussetzt.
Die Ankündigung der nativen Unterstützung von OpenCL in MQL5 war deshalb eine äußerst willkommene Nachricht. Ab Seite 22 desselben Threads begann MetaDriver, Scripts zu veröffentlichen, die es ermöglichen, den Unterschied zwischen der Umsetzung auf dem Prozessor und der Grafikkarte zu bewerten. OpenCL sorgte für reges Interesse.
Der Verfasser dieses Beitrags distanzierte sich zunächst von dem Prozess: Die ziemlich schwache Computerkonfiguration (Pentium G840/8 GB DDR-III 1333/keine Grafikkarte) schien für die effektive Verwendung von OpenCL ungeeignet.
Doch nach der Installation von AMD APP SDK, einer speziellen Software von AMD, wurde das erste von MetaDriver vorgeschlagene Script, das von anderen nur ausgeführt wurde, wenn eine diskrete Grafikkarte verfügbar war, erfolgreich auf dem Computer des Verfassers ausgeführt und zeigte einen Geschwindigkeitsanstieg, der im Vergleich mit einer Standardlaufzeit auf einem Prozessorkern alles andere als unerheblich war: Es wurden etwa 25-fache Geschwindigkeiten erreicht. Später erreichte die Beschleunigung derselben Script-Laufzeit dank der erfolgreichen Installation von Intel OpenCL Runtime mithilfe des Support-Teams das 75-Fache.
Nach einem eingehenden Studium des Forums und der Materialien von ixbt.com fand der Verfasser heraus, dass Intels Integrated Graphics Prozessor (IGP) erst ab Ivy-Bridge-Prozessoren und höher OpenCL 1.1 unterstützt. Somit konnte die auf dem PC mit der oben aufgeführten Konfiguration erreichte Beschleunigung nichts mit dem IGP zu tun haben, und der OpenCL-Programmcode wurde in diesem konkreten Fall nur auf einer x86-Kern-CPU ausgeführt.
Als der Verfasser die Beschleunigungszahlen mit den Experten von ixbt teilte, antworteten sie sofort und alle zusammen, dass dies das Ergebnis einer erheblichen Unteroptimierung der Quellsprache (MQL5) sei. Unter OpenCL-Profis ist bekannt, dass die korrekte Optimierung eines C++-Quellcodes (natürlich unter der Voraussetzung, dass ein Multi-Core-Prozessor und SSEx-Vektorbefehle verwendet wurden) bestenfalls zu einem Gewinn von einigen Dutzend Prozent bei OpenCL-Emulation führt. Im Worst-Case-Szenario müssen Sie sogar mit Einbußen rechnen, z. B. aufgrund von extrem hohen (Zeit)-Kosten bei der Übergabe von Daten.
Deshalb eine weitere Annahme: "Wunderhafte" Beschleunigungszahlen in MetaTrader 5 bei reiner OpenCL-Emulation müssen mit einer gewissen Skepsis behandelt werden, ohne sie auf die "Coolness" von OpenCL zurückzuführen. Ein wirklich großer Vorteil der GPU gegenüber einem gut optimierten Programm in C++ kann nur mithilfe einer ziemlich starken diskreten Grafikkarte erreicht werden, da ihre Rechenleistungen bei bestimmten Algorithmen die Leistungen jeder modernen CPU weit übersteigen.
Die Entwickler des Terminals beteuern, dass es noch nicht richtig optimiert wurde. Sie haben auch auf eine mehrfache Beschleunigung nach der Optimierung hingedeutet. Somit werden alle Beschleunigungszahlen in OpenCL entsprechend um dieses "Mehrfache" reduziert. Allerdings werden sie immer noch wesentlich höher sein als Eins.
Das ist ein guter Anlass, um die Sprache OpenCL zu erlernen (auch wenn Ihre Grafikkarte OpenCL 1.1 nicht unterstützt oder Sie schlicht und einfach keine haben), womit wir nun anfangen werden. Doch lassen Sie mich zunächst ein paar Worte über die Grundlagen verlieren: Software, die OpenCL unterstützt, und die entsprechende Hardware.
1. Grundlegende Software und Hardware
1.1. AMD
Die entsprechende Software wird von AMD, Intel und NVidia hergestellt, den Mitgliedern der Khronos-Gruppe, eines gemeinnützigen Branchenkonsortiums, das verschiedene Sprachspezifikationen in Bezug auf Berechnungen in heterogenen Umgebungen entwickelt.
Einige nützliche Materialien finden Sie auf der offiziellen Webseite der Khronos-Gruppe, z. B.:
Diese Dokumente werden beim Lernen von OpenCL ziemlich häufig benötigt, da das Terminal noch keine Hilfe zu OpenCL bietet (es gibt nur eine kurze Zusammenfassung der OpenCL-API). Alle drei Firmen (AMD, Intel und NVidia) sind Hersteller von Videohardware und jede von ihnen hat ihre eigene Umsetzung der OpenCL Runtime und entsprechende Softwareentwicklungskits (SDKs). Sehen wir uns die Besonderheiten bei der Auswahl der Grafikkarte anhand des Beispiels von AMD an.
Wenn Ihre AMD-Grafikkarte nicht allzu alt ist (Produktion ab 2009-2010), wird es ziemlich einfach sein: Eine Aktualisierung Ihres Grafikkartentreibers sollte ausreichen, um sofort arbeiten zu können. Eine Liste von OpenCL-kompatiblen Grafikkarten finden Sie hier. Andererseits wird auch eine Grafikkarte, die für ihre Zeit sehr gut ist, wie die Radeon HD 4850 (4870) Sie nicht vor den Schwierigkeiten im Umgang mit OpenCL bewahren.
Wenn Sie noch keine AMD-Grafikkarte besitzen, aber eine beschaffen möchten, sehen Sie sich zuerst ihre Spezifikationen an. Hier sehen Sie eine ziemlich umfassende Spezifikationstabelle für moderne AMD-Grafikkarten. Folgendes ist für uns am wichtigsten:
- On-board Memory – die Menge des lokalen Speichers. Je größer, desto besser. 1 GB müsste für gewöhnlich reichen.
- Core Clock – Arbeitsfrequenz des Kerns. Es ist ebenfalls klar: Je höher die Arbeitsfrequenz der GPU-Multiprozessoren, desto besser. 650-700 MHz sind schon nicht schlecht.
- [Memory] Type – Typ des Videospeichers. Der Speicher sollte idealerweise schnell sein, d. h. GDDR5. GDDR3 wäre auch in Ordnung, allerdings zweimal schlechter in puncto Speicherbandbreite.
- [Memory] Clock (Eff.) – (effektive) Arbeitsfrequenz des Videospeichers. Technisch betrachtet ist dieser Parameter eng mit dem vorherigen verwandt. Die effektive Arbeitsfrequenz von GDDR5 ist im Durchschnitt zweimal so hoch wie die von GDDR3. Das hat nichts damit zu tun, dass "höhere" Speichertypen mit höheren Frequenzen arbeiten, sondern liegt an der Menge der vom Speicher genutzten Datenübertragungskanäle. In anderen Worten: Es hängt mit der Speicherbandbreite zusammen.
- [Memory] Bus – Breite des Datenbusses. Mindestens 256 Bit werden empfohlen.
- MBW — Memory BandWidth. Dieser Parameter ist im Wesentlichen eine Kombination aus allen drei der oben aufgeführten Videospeicher-Parametern. Je höher, desto besser.
- Config Core (SPU:TMU(TF):ROP) – Konfiguration der Prozessorkerne. Für uns, d. h. für nichtgrafische Berechnungen, ist die erste Zahl wichtig. Die Angabe 1024:64:32 würde bedeuten, dass wir den Wert 1024 brauchen (die Anzahl von Unified-Stream-Prozessoren oder Shadern). Natürlich gilt auch hier: Je höher, desto besser.
- Processing Power – theoretische Performance bei Gleitkommaberechnungen (FP32 (einfache Genauigkeit) / FP64 (doppelte Genauigkeit)). Während Spezifikationstabellen immer einen Wert enthalten, der FP32 entspricht (alle Grafikkarten können mit Berechnungen mit einfacher Genauigkeit umgehen), trifft das noch lange nicht auf FP64 zu, da die doppelte Genauigkeit nicht von jeder Grafikkarte unterstützt wird. Wenn Sie sicher sind, dass Sie für Ihre GPU-Berechnungen niemals doppelte Genauigkeit (Typ double) benötigen werden, können Sie den zweiten Parameter ignorieren. Doch in jedem Fall gilt: Je höher dieser Parameter ist, desto besser.
- TDP – Thermal Design Power. Das ist, grob gesagt, die maximale Leistung, die die Grafikkarte bei den schwierigsten Berechnungen aufbringt. Wenn Ihr Expert Advisor regelmäßig auf die GPU zugreifen wird, wird die Grafikkarte nicht nur viel Strom verbrauchen (was nicht schlimm ist, wenn es sich lohnt), sondern wird auch ziemlich laut sein.
Nun zum zweiten Fall: Es gibt keine Grafikkarte oder die vorhandene Grafikkarte unterstützt nicht OpenCL 1.1, aber Sie haben einen AMD-Prozessor. Hier können Sie AMD APP SDK herunterladen, das neben der Laufzeit auch SDK, Kernel Analyzer und Profiler enthält. Nach der Installation von AMD APP SDK sollte der Prozessor als OpenCL-Gerät erkannt werden und Sie werden voll funktionsfähige OpenCL-Anwendungen im Emulationsmodus auf der CPU entwickeln können.
Das wichtigste Merkmal des SDK von AMD ist, dass es auch mit Intel-Prozessoren kompatibel ist (obwohl bei der Entwicklung auf einer Intel-CPU das native SDK viel effizienter ist, da es die SSE4.1-, SSE4.2- und AVX-Befehlssätze unterstützt, die erst kürzlich für AMD-Prozessoren verfügbar geworden sind).
1,2. Intel
Für die Arbeit mit Intel-Prozessoren sollten Sie zuerst Intel OpenCL SDK/Runtime herunterladen.
Wir sollten Folgendes festhalten:
- Wenn Sie OpenCL-Anwendungen nur mithilfe der CPU entwickeln möchten (OpenCL-Emulationsmodus), sollten Sie wissen, dass das Grafik-Kernel der Intel-CPU OpenCL 1.1 für Prozessoren bis einschließlich Sandy Bridge nicht unterstützt. Diese Unterstützung ist nur mit Ivy-Bridge-Prozessoren verfügbar, doch das wird sogar bei der extrem leistungsstarken integrierten Grafikeinheit Intel HD 4000 kaum einen Unterschied machen. Für Prozessoren unter Ivy Bridge würde das bedeuten, dass die erzielte Beschleunigung in der MQL5-Umgebung ausschließlich den verwendeten SS(S)Ex-Vektorbefehlen zu verdanken ist. Doch auch diese Beschleunigung ist bereits wesentlich.
- Nach der Installation von Intel OpenCL SDK muss der Registry-Eintrag HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\OpenCL\Vendors folgendermaßen angepasst werden: Ersetzen Sie IntelOpenCL64.dll in der Spalte Name durch intelocl.dll. Starten Sie den Computer anschließend neu und starten Sie MetaTrader 5. Die CPU wird nun als OpenCL-1.1-Gerät erkannt.
Um ehrlich zu sein, wurde das Problem mit der Unterstützung von OpenCL von Intel noch nicht vollständig gelöst, also sollten wir in Zukunft mit einigen Klarstellungen von den Entwicklern des Terminals rechnen. Der Punkt ist grundsätzlich der, dass niemand für Sie nach Fehlern im Kernel-Code suchen wird (OpenCL kernel ist ein auf der GPU ausgeführtes Programm) – das ist nicht der MQL5-Compiler. Der Compiler nimmt einfach eine große Zeile des Kernels vollständig auf und versucht sie auszuführen. Wenn Sie beispielsweise eine bestimmte Variable x, die im Kernel verwendet wird, nicht deklariert haben, wird das Kernel technisch immer noch ausgeführt, allerdings mit Fehlern.
Allerdings belaufen sich alle Fehler, die Sie im Terminal erhalten, auf weniger als ein Dutzend aus denen, die in der Hilfe zu OpenCL-API für die Funktionen CLKernelCreate() und CLProgramCreate() beschrieben werden. Die Syntax der Sprache ist der von C sehr ähnlich und wird durch Vektorfunktionen und Datentypen ergänzt (tatsächlich ist diese Sprache C99, die 1999 als ANSI-C-Standard übernommen wurde).
Der Verfasser dieses Beitrags nutzte Intel OpenCL Offline Compiler zum Debuggen des Codes für OpenCL. Das ist wesentlich praktischer, als in MetaEditor blind nach Kernel-Fehlern zu suchen. Die Situation wird sich in Zukunft hoffentlich bessern.
1,3. NVidia
Leider hat der Verfasser nicht nach Informationen zu diesem Thema gesucht. Die grundsätzlichen Empfehlungen bleiben dennoch die gleichen. Treiber für neue NVidia-Grafikkarten unterstützen automatisch OpenCL.
Der Verfasser dieses Beitrags hat grundsätzlich nichts gegen NVidia-Grafikkarten, zieht aber den folgenden Schluss aus dem Wissen, das er sich aus der Suche nach Informationen und Forumsdiskussionen angeeignet hat: Für nichtgrafische Berechnungen scheinen AMD-Grafikkarten in Bezug auf ihr Preis-Leistungs-Verhältnis besser zu sein als NVidia-Grafikkarten.
Widmen wir uns nun der Programmierung.
2. Das erste MQL5-Programm mit Nutzung von OpenCL
Um unser erstes, äußerst simples Programm zu entwickeln, müssen wir zunächst die Aufgabe an sich definieren. In Kursen zur parallelen Programmierung muss es mittlerweile Standard sein, den Wert Pi als Beispiel zu berechnen, der etwa 3,14159265 gleicht.
Zu diesem Zweck wird die folgende Formel verwendet (der Verfasser ist vorher nie auf diese spezielle Formel gestoßen, doch sie scheint zu stimmen):

Wir wollen den Wert auf 12 Nachkommastellen genau berechnen. Eine solche Genauigkeit lässt sich grundsätzlich mit etwa 1 Million Iterationen erreichen, doch diese Zahl ermöglicht es uns nicht, den Vorteil von Berechnungen in OpenCL zu bewerten, da die Dauer von Berechnungen auf der GPU zu kurz wird.
GPGPU-Programmierkurse raten zu einer Wahl der Anzahl von Berechnungen, mit der die Dauer der GPU-Aufgabe mindestens 20 Millisekunden beträgt. In unserem Fall sollte diese Grenze aufgrund der wesentlichen Abweichung der Funktion GetTickCount() im Bereich von 100 ms höher angesetzt werden.
Nachfolgend sehen Sie das MQL5-Programm, in dem diese Berechnung umgesetzt wird:
//+------------------------------------------------------------------+ //| pi.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" long _num_steps = 1000000000; long _divisor = 40000; double _step = 1.0 / _num_steps; long _intrnCnt = _num_steps / _divisor; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { uint start,stop; double x,pi,sum=0.0; start=GetTickCount(); //--- first option - direct calculation for(long i=0; i<_num_steps; i++) { x=(i+0.5)*_step; sum+=4.0/(1.+x*x); } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); //--- calculate using the second option start=GetTickCount(); sum=0.; long divisor=40000; long internalCnt=_num_steps/divisor; double partsum=0.; for(long i=0; i<divisor; i++) { partsum=0.; for(long j=i*internalCnt; j<(i+1)*internalCnt; j++) { x=(j+0.5)*_step; partsum+=4.0/(1.+x*x); } sum+=partsum; } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); Print("_______________________________________________"); return(0); } //+------------------------------------------------------------------+Nach der Kompilierung und Ausführung dieses Scripts erhalten wir:
2012.05.03 02:02:23 pi (EURUSD,H1) The time to calculate PI was 8.783 seconds 2012.05.03 02:02:23 pi (EURUSD,H1) The value of PI is 3.141592653590 2012.05.03 02:02:15 pi (EURUSD,H1) The time to calculate PI was 7.940 seconds 2012.05.03 02:02:15 pi (EURUSD,H1) The value of PI is 3.141592653590
Der Wert Pi ~ 3,14159265 wird auf zwei leicht unterschiedliche Arten berechnet.
Die erste kann beinahe als klassische Methode zum Demonstrieren der Möglichkeiten von Multithreading-Bibliotheken wie OpenMP, Intel TPP, Intel MKL und so weiter betrachtet werden.
Die zweite ist die gleiche Berechnung in Form einer doppelten Schleife. Die gesamte Berechnung aus 1 Milliarde Iterationen wird in große Blöcke der äußeren Schleife aufgeteilt (es gibt 40000 davon), wobei jeder Block 25000 "Basisiterationen" ausführt und die innere Schleife bildet.
Sie können sehen, dass diese Berechnung um 10-15 % langsamer ist. Doch genau diese Berechnung werden wir als Basis beim Übergang zu OpenCL verwenden. Der Hauptgrund ist die Auswahl des Kernels (der grundlegenden Berechnungsaufgabe, die auf der GPU ausgeführt wird), die einen annehmbaren Kompromiss zwischen der Dauer der Übertragung von Daten von einem Speicherbereich zum anderen und den im Kernel ausgeführten Berechnungen als solche bildet. In Bezug auf die vorliegende Aufgabe wird das Kernel, grob gesagt, die innere Schleife des zweiten Berechnungsalgorithmus sein.
Berechnen wir nun den Wert mithilfe von OpenCL. Auf einen vollständigen Programmcode folgen kurze Kommentare zur Funktionsweise der Verbindung der Host-Sprache (MQL5) mit OpenCL. Doch zunächst möchte ich einige Punkte in Bezug auf typische "Hürden" ansprechen, die das Programmieren in OpenCL stören könnten:
- Das Kernel sieht keine Variablen, die außerhalb des Kernels deklariert wurden. Deshalb müssen die globalen Variablen _step und _intrnCnt am Anfang des Kernel-Codes erneut deklariert werden (siehe unten). Ihre jeweiligen Werte müssen in Strings umgewandelt werden, um im Kernel-Code korrekt gelesen zu werden. Allerdings wird sich diese Besonderheit der Programmierung in OpenCL später noch als sehr nützlich erweisen, z. B. beim Erstellen von Vektor-Datentypen, die in C ursprünglich fehlen.
- Versuchen Sie, so viele Berechnungen wie möglich an das Kernel zu übergeben, ihre Anzahl dabei aber in einem vernünftigen Rahmen zu lassen. Das ist für diesen Code nicht ausschlaggebend, da das Kernel in diesem Code auf der vorhandenen Software nicht sehr schnell ist. Doch dieser Faktor wird Ihnen helfen, die Berechnungen zu beschleunigen, wenn eine leistungsstarke diskrete Grafikkarte verwendet wird.
Hier ist also der Script-Code mit dem OpenCL-Kernel:
//+------------------------------------------------------------------+ //| OCL_pi_float.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs; input int _device=0; /// OpenCL device number (0, I have CPU) #define _num_steps 1000000000 #define _divisor 40000 #define _step 1.0 / _num_steps #define _intrnCnt _num_steps / _divisor string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(int arg) { return IntegerToString(arg); } const string clSrc= "#define _step "+d2s(_step,12)+" \r\n" "#define _intrnCnt "+i2s(_intrnCnt)+" \r\n" " \r\n" "__kernel void pi( __global float *out ) \r\n" // type float "{ \r\n" " int i = get_global_id( 0 ); \r\n" " float partsum = 0.0; \r\n" // type float " float x = 0.0; \r\n" // type float " long from = i * _intrnCnt; \r\n" " long to = from + _intrnCnt; \r\n" " for( long j = from; j < to; j ++ ) \r\n" " { \r\n" " x = ( j + 0.5 ) * _step; \r\n" " partsum += 4.0 / ( 1. + x * x ); \r\n" " } \r\n" " out[ i ] = partsum; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { Print("FLOAT: _step = "+d2s(_step,12)+"; _intrnCnt = "+i2s(_intrnCnt)); int clCtx=CLContextCreate(_device); int clPrg = CLProgramCreate( clCtx, clSrc ); int clKrn = CLKernelCreate( clPrg, "pi" ); uint st=GetTickCount(); int clMem=CLBufferCreate(clCtx,_divisor*sizeof(float),CL_MEM_READ_WRITE); // type float CLSetKernelArgMem(clKrn,0,clMem); const uint offs[ 1 ] = { 0 }; const uint works[ 1 ] = { _divisor }; bool ex=CLExecute(clKrn,1,offs,works); //--- Print( "CL program executed: " + ex ); float buf[]; // type float ArrayResize(buf,_divisor); uint read=CLBufferRead(clMem,buf); Print("read = "+i2s(read)+" elements"); float sum=0.0; // type float for(int cnt=0; cnt<_divisor; cnt++) sum+=buf[cnt]; float pi=float(sum*_step); // type float Print("pi = "+d2s(pi,12)); CLBufferFree(clMem); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); double gone=(GetTickCount()-st)/1000.; Print("OpenCl: gone = "+d2s(gone,3)+" sec."); Print("________________________"); return(0); } //+------------------------------------------------------------------+
Der Script-Code wird später in größerem Detail beschrieben.
Kompilieren und starten Sie in der Zwischenzeit das Programm, um das folgende Ergebnis zu erhalten:
2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) ________________________ 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) OpenCl: gone = 5.538 sec. 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) pi = 3.141622066498 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) read = 40000 elements 2012.05.03 02:20:15 OCl_pi_float (EURUSD,H1) FLOAT: _step = 0.000000001000; _intrnCnt = 25000
Wie Sie sehen können, hat sich die Dauer der Ausführung ein wenig verringert. Doch das stellt uns noch nicht zufrieden: Der Wert von Pi ~ 3,14159265 ist offensichtlich nur bis zur 3. Nachkommastelle genau. Diese Ungenauigkeit der Berechnungen liegt daran, dass das Kernel bei realen Berechnungen Zahlen des Typen float nutzt, deren Genauigkeit klar unter der erforderlichen Genauigkeit von 12 Nachkommastellen liegt.
Laut MQL5-Dokumentation liegt die Genauigkeit einer Zahl des Typen float bei 7 signifikanten Stellen. Die Genauigkeit einer Zahl des Typen double liegt im Vergleich dazu bei 15 signifikanten Stellen.
Deshalb müssen wir den realen Datentyp "genauer" machen. Im oben aufgeführten Code sind die Zeilen, in denen der Typ float durch den Typ double ersetzt werden muss, mit dem Kommentar ///type float gekennzeichnet. Nach der Kompilierung mit den gleichen Eingabedaten erhalten wir das folgende Ergebnis (neue Datei mit dem Quellcode: OCL_pi_double.mq5):
2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) OpenCl: gone = 12.480 sec. 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.03 03:25:23 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Die Dauer der Ausführung ist deutlich gestiegen und hat die Dauer des Quellcodes ohne OpenCL (8,783 Sek.) sogar überschritten.
Sie werden denken: "Es ist ganz klar der Typ double, der die Berechnungen verlangsamt." Lassen Sie uns aber experimentieren und den Eingabeparameter _divisor deutlich von 40000 zu 40000000 verändern:
2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) OpenCl: gone = 5.070 sec. 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) read = 40000000 elements 2012.05.03 03:26:50 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25
Die Genauigkeit wurde nicht beeinträchtigt und die Dauer der Ausführung wurde im Vergleich zum Typ float sogar leicht verkürzt. Aber wenn wir einfach alle ganzzahligen Typen von long zu int ändern und den vorherigen Wert von _divisor = 40000 wiederherstellen, sinkt die Kernel-Laufzeit um über die Hälfte:
2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) OpenCl: gone = 2.262 sec. 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.16 00:22:44 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
Denken Sie immer daran: Wenn es eine ziemlich "lange", aber "leichte" Schleife gibt (d. h. eine Schleife, die aus vielen Iterationen besteht, von denen jede nur wenig berechnet), kann eine einfache Veränderung der Datentypen von "schweren" (Typ long – 8 Byte) zu "leichten" (int – 4 Byte) die Kernel-Laufzeit deutlich verringern.
Lassen Sie uns nun unsere Programmierexperimente kurz unterbrechen und uns auf die Bedeutung der gesamten "Anbindung" des Kernel-Codes konzentrieren, um nachvollziehen zu können, was wir eigentlich tun. Mit der "Anbindung" des Kernel-Codes meinen wir vorläufig die OpenCL-API, also ein System von Befehlen, die es dem Kernel ermöglicht, mit dem Host-Programm (in diesem Fall dem MQL5-Programm) zu kommunizieren.
3. Funktionen der OpenCL-API
3,1. Erstellen eines Kontexts
Der unten aufgeführte Befehl erstellt einen Kontext, d. h. eine Umgebung für die Verwaltung von OpenCL-Objekten und -Ressourcen.
int clCtx = CLContextCreate( _device );
Zunächst ein paar Worte über das Modell der Plattform.
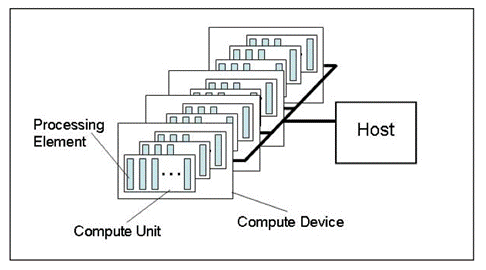
Abb. 1. Abstraktes Modell einer Computerplattform
Die Abbildung zeigt ein abstraktes Modell einer Computerplattform. Es ist keine sehr detaillierte Beschreibung der Struktur der Hardware in Bezug auf Grafikkarten, doch es kommt der Realität sehr nahe und vermittelt eine gute allgemeine Vorstellung.
Der Host ist die Haupt-CPU, die den gesamten Ausführungsprozess des Programms steuert. Er kann einige OpenCL-Devices (Compute Devices) erkennen. In den meisten Fällen, in denen ein Händler über eine Grafikkarte im Systemblock für Berechnungen verfügt, gilt die Grafikkarte als Device (Grafikkarten mit zwei Prozessoren werden als zwei Devices betrachtet!). Außerdem wird der Host an sich, d. h. die CPU, immer als OpenCL-Device betrachtet. Jedes Device hat eine eindeutige Nummer innerhalb der Plattform.
In jedem Device gibt es mehrere Compute Units, die im Fall der CPU x86-Kernen entsprechen (einschließlich der "virtuellen" Kerne der Intel-CPU, also per Hyperthreading erstellte "Kerne"). Bei Grafikkarten sind es SIMD Engines, d. h. SIMD-Kerne oder Miniprozessoren gemäß dem Beitrag GPU-Berechnungen. Merkmale der Architektur von AMD/ATI Radeon. Leistungsstarke Grafikkarten haben für gewöhnlich etwa 20 SIMD-Kerne.
Jeder SIMD-Kern enthält Stream-Prozessoren. Die Grafikkarte Radeon HD 5870 verfügt etwa über 16 Stream-Prozessoren in jeder SIMD Engine.
Zu guter Letzt hat jeder Stream-Prozessor 4 oder 5 Verarbeitungselemente. d. h. ALU, in der gleichen Karte.
Es sollte festgehalten werden, dass die von allen bedeutenden Grafikanbietern verwendete Terminologie für Hardware ziemlich verwirrend ist, insbesondere für Neueinsteiger. Es ist nicht immer klar, was mit dem Begriff "Bienen" gemeint ist, der häufig in einem beliebten Thread über OpenCL genutzt wird. Dennoch ist die Menge der Threads, d. h. gleichzeitigen Berechnungs-Threads bei modernen Grafikkarten sehr hoch. Die geschätzte Menge von Threads der Grafikkarte Radeon HD 5870 liegt beispielsweise bei über 5000.
Die nachfolgende Abbildung zeigt die technischen Standardspezifikationen dieser Grafikkarte.

Abb. 2. Eigenschaften der GPU Radeon HD 5870
Alle im Nachfolgenden aufgeführten Angaben (OpenCL-Ressourcen) müssen unbedingt mit dem durch die Funktion CLContextCreate() erstellten Kontext assoziiert werden:
- OpenCL-Devices, d. h. für Berechnungen verwendete Hardware;
- Programmobjekte, d. h. Programmcode, der das Kernel ausführt;
- Kernels, d. h. Funktionen, die auf den Devices ausgeführt werden;
- Speicherobjekte, d. h. Daten (z. B. Puffer, 2D- und 3D-Bilder), die vom Device manipuliert werden;
- Befehlswarteschlangen (die aktuelle Implementierung der Terminalsprache sieht keine entsprechende API vor).
Der erstellte Kontext kann als leeres Feld mit angehängten Devices illustriert werden, wie nachfolgend abgebildet.
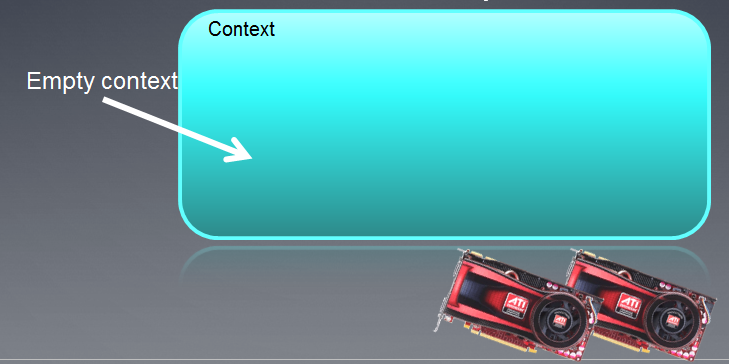
Abb. 3. OpenCL-Kontext
Nach der Ausführung der Funktion ist das Kontextfeld derzeit leer.
Es sollte festgehalten werden, dass der OpenCL-Kontext in MQL5 mit nur einem Device arbeitet.
3,2. Erstellen eines Programms
int clPrg = CLProgramCreate( clCtx, clSrc );
Die Funktion CLProgramCreate() erstellt die Ressource "OpenCL-Programm".
Das Objekt "Programm" ist im Grunde eine Sammlung von OpenCL-Kernels (die im nächsten Abschnitt behandelt werden), doch in der Implementierung von MetaQuotes kann es anscheinend nur ein Kernel im OpenCL-Programm geben. Um das Objekt "Programm" zu erstellen, müssen Sie sicherstellen, dass der Quellcode (hier: clSrc) in einen String eingelesen wird.
Das ist in unserem Fall nicht erforderlich, da der String clSrc bereits als globale Variable deklariert wurde:

Die nachfolgende Abbildung zeigt das Programm als Teil des vorher erstellten Kontexts.

Abb. 4. Programm als Teil des Kontexts
Falls die Kompilierung des Programms fehlgeschlagen ist, muss der Entwickler eigenständig eine Datenanfrage am Ausgang des Compilers einleiten. Eine voll funktionsfähige OpenCL-API verfügt über die API-Funktion clGetProgramBuildInfo(), nach deren Aufruf ein String am Ausgang des Compilers ausgegeben wird.
Die aktuelle Version (b.642) unterstützt diese Funktion nicht, doch sie sollte vermutlich in die OpenCL-API eingebunden werden, um OpenCL-Entwicklern mehr Informationen über die Richtigkeit des Kernel-Codes zu liefern.
"Zungen" aus den Devices (Grafikkarten) sind Befehlswarteschlagen, die anscheinend nicht auf API-Ebene von MQL5 unterstützt werden.
3,3. Erstellen eines Kernels
Die Funktion CLKernelCreate() erstellt die OpenCL-Ressource "Kernel".
int clKrn = CLKernelCreate( clPrg, "pi" );
Kernel ist eine Funktion, die in dem Programm, das auf dem OpenCL-Device ausgeführt wird, deklariert ist.
In unserem Fall ist es die Funktion pi() mit dem Namen "pi". Das Objekt "Kernel" ist die Funktion des Kernels zusammen mit den entsprechenden Argumenten. Das zweite Argument in dieser Funktion ist der Funktionsname, der dem Funktionsnamen innerhalb des Programms genau entsprechen muss.

Abb. 5. Kernel
"Kernel"-Objekte können beim Festlegen verschiedener Argumente für dieselbe als Kernel deklarierte Funktion so oft wie nötig verwendet werden.
Wir sollten nun mit den Funktionen CLSetKernelArg() und CLSetKernelArgMem() fortfahren. Doch zunächst sollten wir noch etwas über Objekte im Speicher der Devices erfahren.
3,4. Speicherobjekte
Zuallererst müssen wir verstehen, dass jedes "große" Objekt, das auf der GPU verarbeitet wird, zuerst im Speicher der GPU selbst erstellt oder aus dem Host-Speicher (RAM) dorthin verschoben werden muss. Mit "großem" Objekt meinen wir entweder einen Puffer (eindimensionales Array) oder ein Bild, das zwei- oder dreidimensional (2D oder 3D) sein kann.
Ein Puffer ist ein großer Speicherbereich, der separate benachbarte Pufferelemente beinhaltet. Dabei kann es sich um einfache Datentypen (char, double, float, long usw.) oder komplexe Datentypen (Strukturen, Unions usw.) handeln. Auf separate Pufferelemente ist ein direkter Zugriff möglich und sie können gelesen und geschrieben werden.
Bilder werden wir uns vorerst nicht ansehen, da es sich bei ihnen um einen besonderen Datentyp handelt. Der Code, den die Entwickler des Terminals auf der ersten Seite des Threads über OpenCL bereitstellen, lässt darauf schließen, dass sich die Entwickler nicht mit der Verwendung von Bildern beschäftigt haben.
Im vorgestellten Code sieht die Funktion, die den Puffer erstellt, so aus:
int clMem = CLBufferCreate( clCtx, _divisor * sizeof( double ), CL_MEM_READ_WRITE );
Der erste Parameter ist ein Kontext-Handle, mit dem der OpenCL-Puffer als Ressource assoziiert wird. Der zweite Parameter ist der dem Puffer zugewiesene Speicher. Der dritte Parameter zeigt, was mit diesem Objekt getan werden kann. Der ausgegebene Wert ist ein Handle zum OpenCL-Puffer (bei erfolgreicher Erstellung) oder -1 (falls die Erstellung aufgrund eines Fehlers fehlgeschlagen ist).
In unserem Fall wurde der Puffer direkt im Speicher der GPU, also des OpenCL-Devices, erstellt. Falls er ohne diese Funktion im RAM erstellt wurde, sollte er in den Speicher des OpenCL-Devices (GPU) verschoben werden, wie nachfolgend illustriert:

Abb. 6. OpenCL-Speicherobjekte
Eingabe-/Ausgabepuffer (nicht zwangsläufig Bilder – die Mona Lisa dient hier nur der Veranschaulichung!), die keine OpenCL-Speicherobjekte sind, werden auf der linken Seite gezeigt. Leere, nicht initialisierte OpenCL-Speicherobjekte werden weiter rechts, im Hauptfeld des Kontexts gezeigt. Die Ausgangsdaten (die "Mona Lisa") werden anschließend in das OpenCL-Kontextfeld verschoben und was durch das OpenCL-Programm ausgegeben wird, muss zurück nach links, d. h. in den RAM verschoben werden.
Die in OpenCL für das Kopieren von Daten aus dem/in das Host-/Open-CL-Device verwendeten Begriffe sind:
- Das Kopieren von Daten aus dem Host in den Device-Speicher wird Schreiben genannt (Funktion CLBufferWrite());
- Das Kopieren von Daten aus dem Device-Speicher in den Host-Speicher wird Lesen genannt (Funktion CLBufferRead(), siehe unten).
Der Schreibbefehl (Host -> Device) initialisiert ein Speicherobjekt nach Daten und platziert das Objekt gleichzeitig im Device-Speicher.
Denken Sie daran, dass die Gültigkeit von Speicherobjekten, die im Device bereitgestellt werden, nicht in den Open-CL-Spezifikationen festgelegt ist, da sie vom Hersteller der dem Device entsprechenden Hardware abhängig ist. Seien Sie deshalb vorsichtig, wenn Sie Speicherobjekte erstellen.
Nachdem die Speicherobjekte initialisiert und in Devices geschrieben wurden, sieht das Bild etwa so aus:

Abb. 7. Ergebnis der Initialisierung der OpenCL-Speicherobjekte
Nun können wir mit Funktionen fortfahren, die die Parameter des Kernels bestimmen.
3,5. Festlegen der Parameter des Kernels
CLSetKernelArgMem( clKrn, 0, clMem );
Die Funktion CLSetKernelArgMem() definiert den vorher erstellten Puffer als Nullparameter des Kernels.
Wenn wir uns nun denselben Parameter im Kernel-Code ansehen, stellen wir fest, dass er so aussieht:
__kernel void pi( __global float *out )
Im Kernel ist es das Array out[ ], das den gleichen Typ hat, der von der API-Funktion CLBufferCreate() erstellt wird.
Es gibt eine ähnliche Funktion zum Festlegen von Nichtpuffer-Parametern:
bool CLSetKernelArg( int kernel, // handle to the kernel of the OpenCL program uint arg_index, // OpenCL function argument number void arg_value ); // function argument value
Wenn wir beispielsweise beschlossen haben, ein double x0 als zweiten Parameter des Kernels festzulegen, müsste es zuerst im MQL5-Programm deklariert und initialisiert werden:
double x0 = -2;
und die Funktion muss dann aufgerufen werden (auch im MQL5-Code):
CLSetKernelArg( cl_krn, 1, x0 );
Nach den oben aufgeführten Manipulationen sieht das Bild so aus:

Abb. 8. Ergebnis der Festlegung der Parameter des Kernels
3,6. Programmausführung
bool ex = CLExecute( clKrn, 1, offs, works );
Der Verfasser konnte kein direktes Gegenstück dieser Funktion in der OpenCL-Spezifikation finden. Die Funktion führt das Kernel clKrn mit den gegebenen Parametern aus. Der letzte Parameter "works" bestimmt die Menge der Aufgaben, die pro Berechnung der Berechnungsaufgabe ausgeführt werden sollen. Die Funktion demonstriert das SPMD-Prinzip (Single Program Multiple Data): Ein Aufruf der Funktion erstellt Kernel-Instanzen mit ihren eigenen Parametern, deren Menge dem Wert des Parameters works entspricht. Diese Kernel-Instanzen werden, konventionell betrachtet, gleichzeitig, aber auf verschiedenen Kernen (Stream Cores) ausgeführt.
Die universelle Anwendbarkeit von OpenCL ist dadurch begründet, dass die Sprache nicht durch die zugrunde liegende Hardwareinfrastruktur hinter der Ausführung des Codes eingeschränkt wird: Der Programmierer muss nicht die Hardwarespezifikationen kennen, um ein OpenCL-Programm ordnungsgemäß ausführen zu können. Es wird dennoch ausgeführt. Es wird jedoch ausdrücklich empfohlen, diese Spezifikationen zu kennen, um die Effizienz des Codes (z. B. seine Geschwindigkeit) zu erhöhen.
Dieser Code wird beispielsweise problemlos auf der Hardware des Verfassers ohne diskrete Grafikkarte ausgeführt. Dabei hat der Verfasser nur eine sehr ungefähre Vorstellung von der Struktur der CPU selbst, auf der die gesamte Emulation stattfindet.
Das OpenCL-Programm wurde nun also endlich ausgeführt und wir können seine Ergebnisse jetzt im Host-Programm nutzen.
3,7. Lesen der Ausgabedaten
Nachfolgend sehen Sie ein Fragment des Host-Programms, das Daten aus dem Device liest:
float buf[ ]; ArrayResize( buf, _divisor ); uint read = CLBufferRead( clMem, buf );
Denken Sie daran, dass das Lesen von Daten in OpenCL bedeutet, dass diese Daten aus dem Device in den Host kopiert werden. Diese drei Zeilen veranschaulichen, wie dies bewerkstelligt wird. Es reicht aus, den Puffer buf[] des gleichen Typen zu erstellen wie des zu lesenden OpenCL-Puffers im Hauptprogramm, und die Funktion aufzurufen. Der Typ des im Host-Programm erstellten Puffers (hier: in MQL5) kann sich vom Typ des Puffers im Kernel unterscheiden, doch ihre Größen müssen übereinstimmen.
Die Daten wurden nun in den Host-Speicher kopiert und stehen uns vollständig innerhalb des Hauptprogramms, d. h. des MQL5-Programms, zur Verfügung.
Wenn alle erforderlichen Berechnungen auf dem OpenCL-Device abgeschlossen sind, muss der Speicher von allen Objekten befreit werden.
3,8. Vernichten aller OpenCL-Objekte
Das geschieht mithilfe folgender Befehle:
CLBufferFree( clMem ); CLKernelFree( clKrn ); CLProgramFree( clPrg ); CLContextFree( clCtx );
Die größte Besonderheit dieser Reihe von Funktionen besteht darin, dass die Objekte in umgekehrter Reihenfolge ihrer Erstellung vernichtet werden müssen.
Sehen wir uns nun kurz den Kernel-Code selbst an.
3,9. Kernel
Wie Sie sehen können, ist der ganze Kernel-Code ein einzelner langer String, der aus mehreren Strings besteht.
Die Kopfzeile des Kernels sieht wie eine Standardfunktion aus:
__kernel void pi( __global float *out )
Dies sind die Anforderungen an die Kopfzeile des Kernels:
- Der Typ von ausgegebenen Werten ist immer void;
- Der Spezifikator __kernel muss nicht zwangsläufig zwei Unterstriche enthalten, sondern kann auch kernel heißen;
- Falls ein Argument ein Array (Puffer) ist, wird er nur per Verweis übergeben. Der Speicherspezifikator __global (oder global) bedeutet, dass dieser Puffer im globalen Speicher des Devices gespeichert wird.
- Argumente einfacher Datentypen werden nach Wert übergeben.
Der Körper des Kernels unterscheidet sich durch nichts vom Standardcode in C.
Wichtig: Der String:
int i = get_global_id( 0 );
bedeutet, dass i die Nummer einer Berechnungszelle innerhalb der GPU ist, die das Berechnungsergebnis innerhalb dieser Zelle bestimmt. Dieses Ergebnis wird weiter in das Ausgabe-Array geschrieben (in unserem Fall out[]), woraufhin seine Werte nach dem Lesen des Arrays aus dem GPU-Speicher in den CPU-Speicher im Host-Programm addiert werden.
Es sollte festgehalten werden, dass es im OpenCL-Programmcode mehr als eine Funktion geben kann. Beispielsweise kann eine einfache Inline-Funktion, die sich außerhalb der Funktion pi() befindet, innerhalb der "Hauptfunktion" pi() des Kernels aufgerufen werden. Diesen Fall werden wir weiter betrachten.
Nun, da wir uns kurz mit der OpenCL-API in der MetaQuotes-Implementierung befasst haben, können wir weiter experimentieren. Der Verfasser möchte in diesem Beitrag nicht tiefer in die Details der Hardware eintauchen, die es uns ermöglichen würden, die Laufzeit maximal zu optimieren. Die Hauptaufgabe ist es im Moment, einen Ausgangspunkt für die OpenCL-Programmierung als solche zu bilden.
In anderen Worten: Der Code ist ziemlich naiv, da er die Hardwarespezifikationen nicht berücksichtigt. Gleichzeitig ist er weitestgehend allgemeingültig, sodass er auf jeder beliebigen Hardware ausgeführt werden kann – CPU, IGP von AMD (in die CPU integrierte GPU) oder diskrete Grafikkarte von AMD / NVidia.
Bevor wir weitere "naive" Optimierungen mithilfe von "Vektor-Datentypen" betrachten, müssen wir uns zunächst mit ihnen vertraut machen.
4. Vektor-Datentypen
Vektor-Datentypen sind OpenCL-spezifische Typen, die die Sprache von C99 unterscheiden. Dazu gehören alle Typen von (u)charN, (u)shortN, (u)intN, (u)longN, floatN, wobei N = {2|3|4|8|16}.
Diese Typen sollen dann verwendet werden, wenn wir wissen (oder annehmen), dass der integrierte Compiler mit einer zusätzlichen Parallelisierung der Berechnungen umgehen kann. Wir müssen an dieser Stelle festhalten, dass dies nicht immer der Fall ist, auch wenn sich die Kernel-Codes nur um den Wert N unterscheiden und in allen anderen Belangen gleich sind (der Verfasser konnte sich selbst davon überzeugen).
Nachfolgend sehen Sie die Liste der integrierten Datentypen:

Tabelle 1. Integrierte Vektor-Datentypen in OpenCL
Diese Typen werden von allen Devices unterstützt. Jeder dieser Typen hat einen entsprechenden API-Typ für die Kommunikation zwischen dem Kernel und dem Host-Programm. Das ist in der aktuellen MQL5-Implementierung nicht vorgesehen, doch das ist nicht schlimm.
Es gibt auch zusätzliche Typen, doch sie müssen explizit festgelegt werden, um verwendet werden zu können, da sie nicht von allen Devices unterstützt werden:

Tabelle 2. Sonstige integrierte Datentypen in OpenCL
Zusätzlich existieren reservierte Datentypen, die derzeit noch nicht von OpenCL unterstützt werden. In der Spezifikation der Sprache finden Sie eine ziemlich lange Liste dieser Typen.
Um eine Konstante oder Variable des Vektortypen zu deklarieren, sollten Sie einfache, intuitive Regeln befolgen.
Nachfolgend sehen Sie einige Beispiele:
float4 f = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f); uint4 u = ( uint4 ) ( 1 ); /// u is converted to a vector (1, 1, 1, 1). float4 f = ( float4 ) ( ( float2 )( 1.0f, 2.0f ), ( float2 )( 3.0f, 4.0f ) ); float4 f = ( float4 ) ( 1.0f, ( float2 )( 2.0f, 3.0f ), 4.0f ); float4 f = ( float4 ) ( 1.0f, 2.0f ); /// error
Wie Sie sehen können, reicht es aus, die Datentypen auf der rechten Seite zusammen mit der "Breite" der auf der linken Seite deklarierten Variable (hier ist sie gleich 4) anzugleichen. Die einzige Ausnahme bildet die Umwandlung eines Skalars in einen Vektor mit Komponenten, die dem Skalar gleichen (Zeile 2).
Für den Umgang mit Vektorkomponenten gibt es einen einfachen Mechanismus für jeden Vektor-Datentyp. Sie sind einerseits Vektoren (Arrays), andererseits Strukturen. So lässt sich beispielsweise die erste Komponente von Vektoren mit der Breite 2 (z. B. float2 u) als u.x, die zweite als u.y ansprechen.
Die drei Komponenten eines Vektors des Typen long3 u sind: u.x, u.y, u.z.
Bei einem Vektor des Typen float4u sind es dementsprechend xyzw, d. h. u.x, u.y, u.z, u.w.
float2 pos; pos.x = 1.0f; // valid pos.z = 1.0f; // invalid because pos.z does not exist float3 pos; pos.z = 1.0f; // valid pos.w = 1.0f; // invalid because pos.w does not exist
Sie können mehrere Komponenten gleichzeitig auswählen und sie sogar vertauschen (Gruppennotation):
float4 c; c.xyzw = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); c.z = 1.0f; c.xy = ( float2 ) ( 3.0f, 4.0f ); c.xyz = ( float3 ) ( 3.0f, 4.0f, 5.0f ); float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 swiz= pos.wzyx; // swiz = ( 4.0f, 3.0f, 2.0f, 1.0f ) float4 dup = pos.xxyy; // dup = ( 1.0f, 1.0f, 2.0f, 2.0f )Die Gruppennotation, also die Angabe von mehreren Komponenten, kann auf der linken Seite der Zuordnungsanweisung auftreten (d. h. l-value):
float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); pos.xw = ( float2 ) ( 5.0f, 6.0f ); // pos = ( 5.0f, 2.0f, 3.0f, 6.0f ) pos.wx = ( float2 ) ( 7.0f, 8.0f ); // pos = ( 8.0f, 2.0f, 3.0f, 7.0f ) pos.xyz = ( float3 ) ( 3.0f, 5.0f, 9.0f ); // pos = ( 3.0f, 5.0f, 9.0f, 4.0f ) pos.xx = ( float2 ) ( 3.0f, 4.0f ); // invalid as 'x' is used twice pos.xy = ( float4 ) (1.0f, 2.0f, 3.0f, 4.0f ); // mismatch between float2 and float4 float4 a, b, c, d; float16 x; x = ( float16 ) ( a, b, c, d ); x = ( float16 ) ( a.xxxx, b.xyz, c.xyz, d.xyz, a.yzw ); x = ( float16 ) ( a.xxxxxxx, b.xyz, c.xyz, d.xyz ); // invalid as the component a.xxxxxxx is not a valid vector type
Der Zugriff auf einzelne Komponenten lässt sich mit einer anderen Notation bewerkstelligen: Durch den Buchstaben s (oder S), der in einer Gruppennotation vor einer hexadezimalen Ziffer oder mehreren Ziffern eingefügt wird:

Tabelle 3. Indizes, die für den Zugriff auf einzelne Komponenten von Vektor-Datentypen genutzt werden
Wenn Sie die Vektorvariable f deklarieren,
float8 f;dann ist f.s0 die 1. Komponente des Vektors und f.s7 die 8.
Wenn wir einen 16-dimensionalen Vektor x deklarieren,
float16 x;ist x.sa (oder x.sA) die 11. Komponente des Vektors X und x.sf (oder x.sF) bezieht sich auf die 16. Komponente des Vektors x.
Numerische Indizes (.x0123456789abcdef) und Buchstabennotationen (.xyzw) können nicht gleichzeitig in demselben Identifikator mit der Gruppennotation von Komponenten verwendet werden:
float4 f, a; a = f.x12w; // invalid as numeric indices are intermixed with the letter notations .xyzw a.xyzw = f.s0123; // valid
Und zu guter Letzt gibt es noch eine weitere Art, Komponenten von Vektortypen zu manipulieren – mithilfe von .lo, .hi, .even, .odd.
Diese Suffixe werden folgendermaßen verwendet:
- .lo bezieht sich auf die untere Hälfte eines bestimmten Vektors;
- .hi bezieht sich auf die obere Hälfte eines bestimmten Vektors;
- .even bezieht sich auf alle geraden Komponenten eines Vektors;
- .odd bezieht sich auf alle ungeraden Komponenten eines Vektors.
Zum Beispiel:
float4 vf; float2 low = vf.lo; // vf.xy float2 high = vf.hi; // vf.zw float2 even = vf.even; // vf.xz float2 odd = vf.odd; // vf.yw
Diese Notation kann wiederholt verwendet werden, bis ein Skalar (Nichtvektor-Datentyp) auftritt.
float8 u = (float8) ( 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f ); float2 s = u.lo.lo; // ( 1.0f, 2.0f ) float2 t = u.hi.lo; // ( 5.0f, 6.0f ) float2 q = u.even.lo; // ( 1.0f, 3.0f ) float r = u.odd.lo.hi; // 4.0f
Bei Vektortypen mit 3 Komponenten ist die Situation etwas komplizierter: Technisch betrachtet, handelt es sich um einen Vektortyp mit 4 Komponenten mit nicht definierter 4. Komponente.
float3 vf = (float3) (1.0f, 2.0f, 3.0f); float2 low = vf.lo; // ( 1.0f, 2.0f ); float2 high = vf.hi; // ( 3.0f, undefined );
Kurz zu den Grundrechenarten (+, -, *, /).
Alle angegebenen arithmetischen Operationen werden für Vektoren mit der gleichen Dimension definiert und werden nach Komponenten umgesetzt.
float4 d = (float4) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 w = (float4) ( 5.0f, 8.0f, 10.0f, -1.0f ); float4 _sum = d + w; // ( 6.0f, 10.0f, 13.0f, 3.0f ) float4 _mul = d * w; // ( 5.0f, 16.0f, 30.0f, -4.0f ) float4 _div = w / d; // ( 5.0f, 4.0f, 3.333333f, -0.25f )
Die einzige Ausnahme ist, wenn einer der Operanden ein Skalar und der andere ein Vektor ist. In diesem Fall wird der Skalartyp in den im Vektor deklarierten Datentyp umgewandelt, während der Skalar selbst in einen Vektor mit der gleichen Dimension wie der Vektoroperand umgewandelt wird. Darauf folgt eine arithmetische Operation. Das Gleiche gilt für Vergleichsoperatoren (<, >, <=, >=).
Davon abgeleitete Datentypen, die für C99 nativ sind (z. B. struct, union, Arrays usw.), die aus den in der ersten Tabelle in diesem Abschnitt aufgezählten Datentypen hergestellt werden können, werden auch von der OpenCL-Sprache unterstützt.
Und zu guter Letzt: Wenn Sie die GPU für exakte Berechnungen nutzen möchten, müssen Sie zwangsläufig den Datentyp double und somit doubleN nutzen.
Fügen wir zu diesem Zweck die Zeile:
#pragma OPENCL EXTENSION cl_khr_fp64 : enable
am Anfang des Kernel-Codes ein.
Diese Informationen sollten bereits ausreichen, um vieles von dem zu verstehen, was nun folgt. Sollten Sie Fragen haben, sehen sie sich bitte die OpenCL-1.1-Spezifikation an.
5. Umsetzung des Kernels mit Vektor-Datentypen
Um ehrlich zu sein, hat es der Verfasser nicht geschafft, aus dem Stegreif einen funktionierenden Code mit Vektor-Datentypen zu schreiben.
Anfangs las der Verfasser die Spezifikation der Sprache nicht sehr sorgfältig, da er überzeugt war, dass alles von selbst funktionieren würde, sobald ein Vektor-Datentyp, zum Beispiel double8, innerhalb des Kernels deklariert ist. Zudem schlug auch der Versuch des Verfassers fehl, nur ein Ausgabe-Array als Array von double8-Vektoren zu deklarieren.
Die Erkenntnis, dass das absolut nicht reicht, um das Kernel effektiv zu vektorisieren und eine echte Beschleunigung zu erzielen, ließ auf sich warten. Das Problem wird nicht durch die Ausgabe der Ergebnisse im Vektor-Array gelöst, da die Daten nicht nur schnell ein- und ausgegeben, sondern auch schnell berechnet werden müssen. Das Erkennen dieser Tatsache beschleunigte den Prozess und erhöhte seine Effektivität, sodass es endlich möglich war, einen viel schnelleren Code zu entwickeln.
Doch das ist noch nicht alles. Während der oben aufgeführte Kernel-Code fast blindlings debuggt werden könnte, ist die Suche nach Fehlern nun aufgrund der Verwendung von Vektordaten ziemlich schwierig geworden. Welche konstruktive Information können wir aus dieser Standardmeldung erhalten:
ERR_OPENCL_INVALID_HANDLE - invalid handle to the OpenCL program
oder
ERR_OPENCL_KERNEL_CREATE - internal error while creating an OpenCL object
?
Deshalb musste der Verfasser auf SDK zurückgreifen. In diesem Fall wurde es aufgrund der dem Verfasser zur Verfügung stehenden Hardwarekonfiguration der Intel OpenCL SDK Offline Compiler (32 bit), der im Intel OpenCL SDK bereitgestellt wird (bei CPUs/GPUs von anderen Herstellern als Intel sollte das SDK auch relevante Offline-Compiler enthalten). Der Compiler ist praktisch, weil er es ermöglicht, den Kernel-Code ohne jegliche Anbindung an die Host-API zu debuggen.
Man gibt einfach den Kernel-Code in das Compiler-Fenster ein, allerdings nicht in der im MQL5-Code verwendeten Form, sondern stattdessen ohne äußere Anführungszeichen und "\r\n" (Zeilenumbrüche), und drückt den Button Build mit dem Zahnrad-Icon.
Damit werden im Fenster Build Log Informationen über den Build-Prozess und dessen Fortschritt angezeigt:
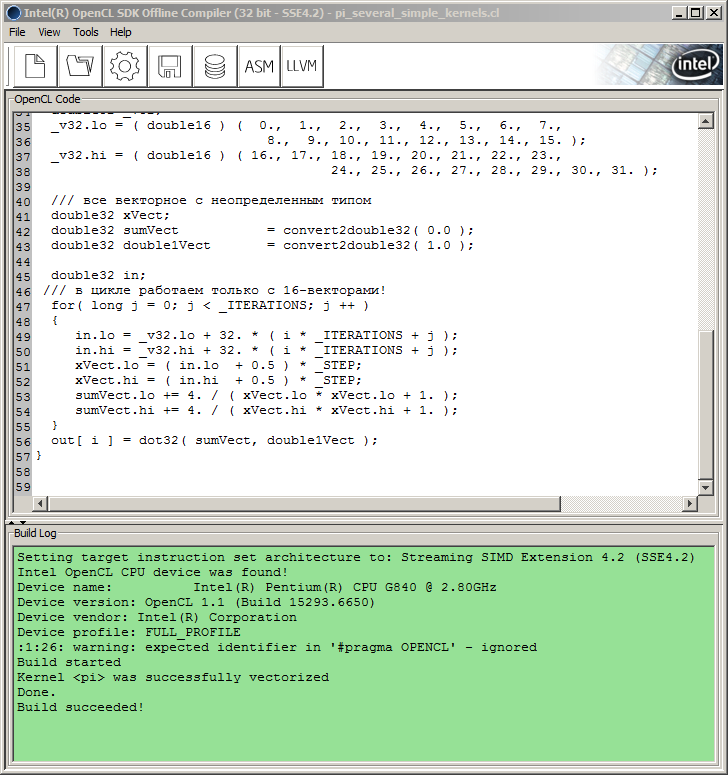
Abb. 9. Kompilierung des Programms im Intel OpenCL SDK Offline Compiler
Um den Kernel-Code ohne Anführungszeichen zu erhalten, wäre es hilfreich, ein simples Programm in der Host-Sprache (MQL5) zu schreiben, das den Kernel-Code in einer Datei ausgibt – WriteCLProgram(). Es ist nun im Code des Host-Programms enthalten.
Meldungen des Compilers sind nicht immer sehr verständlich, doch sie liefern viel mehr Informationen, als MQL5 derzeit liefern kann. Fehler können gleich im Compiler-Fenster behoben werden und sobald Sie sich überzeugt haben, dass es keine weiteren Fehler gibt, können die Korrekturen an den Kernel-Code im MetaEditor übertragen werden.
Und zuletzt: Die ursprüngliche Idee des Verfassers war es, einen vektorisierten Code zu entwickeln, der mit double4-, double8- und double16-Vektoren durch die Festlegung des globalen Parameters "Anzahl der Kanäle" arbeiten kann. Das wurde nach mehreren Tagen harter Arbeit mit dem tokeneinfügenden Operator ## erreicht, der sich aus irgendeinem Grund weigerte, mit dem Kernel-Code zu funktionieren.
In dieser Zeit konnte der Verfasser erfolgreich einen funktionierenden Code des Scripts mit drei Kernel-Codes entwickeln, von denen jedes für seine Dimension geeignet ist – 4, 8 oder 16. Dieser Zwischencode wird in diesem Beitrag nicht bereitgestellt, doch er sollte nicht unerwähnt bleiben, falls Sie ohne viel Ärger einen Kernel-Code schreiben möchten. Der Code dieser Umsetzung des Scripts (OCL_pi_double_several_simple_kernels.mq5) ist am Ende des Beitrags angehängt.
Und hier ist der Code des vektorisierten Kernels:
"/// enable extensions with doubles \r\n" "#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _intrnCnt ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" "#define _CH " + i2s( _ch ) + " \r\n" "#define _DOUBLETYPE double" + i2s( _ch ) + " \r\n" " \r\n" "/// extensions for 4-, 8- and 16- scalar products \r\n" "#define dot4( a, b ) dot( a, b ) \r\n" " \r\n" "inline double dot8( double8 a, double8 b ) \r\n" "{ \r\n" " return dot4( a.lo, b.lo ) + dot4( a.hi, b.hi ); \r\n" "} \r\n" " \r\n" "inline double dot16( double16 a, double16 b ) \r\n" "{ \r\n" " double16 c = a * b; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot4( c.lo.lo + c.lo.hi + c.hi.lo + c.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double16 v16 = ( double16 ) ( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ); \r\n" " double8 v8 = v16.lo; \r\n" " double4 v4 = v16.lo.lo; \r\n" " double2 v2 = v16.lo.lo.lo; \r\n" " \r\n" " /// all vector-related with the calculated type \r\n" " _DOUBLETYPE in; \r\n" " _DOUBLETYPE xVect; \r\n" " _DOUBLETYPE sumVect = ( _DOUBLETYPE ) ( 0.0 ); \r\n" " _DOUBLETYPE doubleOneVect = ( _DOUBLETYPE ) ( 1.0 ); \r\n" " _DOUBLETYPE doubleCHVect = ( _DOUBLETYPE ) ( _CH + 0. ); \r\n" " _DOUBLETYPE doubleSTEPVect = ( _DOUBLETYPE ) ( _STEP ); \r\n" " \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in = v" + i2s( _ch ) + " + doubleCHVect * ( i * _ITERATIONS + j ); \r\n" " xVect = ( in + 0.5 ) * doubleSTEPVect; \r\n" " sumVect += 4.0 / ( xVect * xVect + 1. ); \r\n" " } \r\n" " out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n" "} \r\n";
Das externe Host-Programm hat sich nicht sehr verändert, abgesehen von der neuen globalen Konstante _ch, die die Menge der "Vektorisierungskanäle" bestimmt, und der globalen Konstante _intrnCnt, die _ch Mal kleiner geworden ist. Deshalb hat der Verfasser beschlossen, den Code des Host-Programms hier nicht zu zeigen. Sie finden ihn in der an diesen Beitrag angehängten Scriptdatei (OCL_pi_double_parallel_straight.mq5).
Wie Sie sehen können, verfügen wir nun abgesehen von der "Hauptfunktion" pi() des Kernels über zwei Inline-Funktionen, die das Skalarprodukt der Vektoren dotN( a, b ) bestimmen, und eine Makroersetzung. Diese Funktionen sind deshalb involviert, weil die Funktion dot() in OpenCL in Bezug auf Vektoren, deren Dimension 4 nicht überschreitet, definiert ist.
Das Makro dot4(), das die Funktion dot() neu definiert, existiert nur, um den Aufruf der Funktion dotN() mit dem berechneten Namen zu erleichtern:
" out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n"
Hätten wir die Funktion dot() in ihrer ursprünglichen Form ohne den Index 4 verwendet, hätten wir sie bei _ch = 4 (Menge der Vektorisierungskanäle gleich 4) nicht so einfach aufrufen können, wie es hier gezeigt wird.
Diese Zeile illustriert ein weiteres nützliches Merkmal dieser spezifischen Form des Kernels, das dadurch bedingt ist, dass das Kernel als solches innerhalb des Host-Programms als String behandelt wird: Wir können im Kernel berechnete Indikatoren nicht nur für Funktionen, sondern auch für Datentypen nutzen!
Der vollständige Code des Host-Programms mit diesem Kernel ist unten angehängt (OCL_pi_double_parallel_straight.mq5).
Bei Ausführung des Scripts mit der "Breite" des Vektors gleich 16 ( _ch = 16 ) erhalten wir:
2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) ================================================== 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) CPUtime / GPUtime = 4.130 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The time to calculate PI was 8.830 seconds 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The value of PI is 3.141592653590 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The time to calculate PI was 8.002 seconds 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The value of PI is 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: gone = 2.138 sec. 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: pi = 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) read = 20000 elements 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) CLProgramCreate: unknown error. 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) ==================================================
Sie sehen, dass sogar die Optimierung mithilfe von Vektor-Datentypen das Kernel nicht schneller gemacht hat.
Doch wenn Sie denselben Code auf der GPU ausführen, wird der Geschwindigkeitsgewinn viel deutlicher.
Laut Informationen von MetaDriver (Grafikkarte: HIS Radeon HD 6930, CPU: AMD Phenom II x6 1100T) liefert der gleiche Code die folgenden Ergebnisse:
2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) ================================================== 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) CPUtime / GPUtime = 84.983 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The time to calculate PI was 14.617 seconds 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The value of PI is 3.141592653590 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The time to calculate PI was 14.040 seconds 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The value of PI is 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: gone = 0.172 sec. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) read = 20000 elements 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) CLProgramCreate: unknown error. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) ==================================================
6. Der letzte Schliff
Hier ist ein weiteres Kernel (Sie finden es in der hier angehängten Datei OCL_pi_double_several_simple_kernels.mq5, die hier allerdings nicht demonstriert wird).
Das Script ist eine Umsetzung der Idee, die der Verfasser hatte, als er den Versuch, ein "einzelnes" Kernel zu schreiben, zwischendurch aufgegeben hatte und vier einfache Kernels für unterschiedliche Vektordimensionen (4, 8, 16, 32) schrieb:
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _itInKern ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" " \r\n" "typedef struct \r\n" "{ \r\n" " double16 lo; \r\n" " double16 hi; \r\n" "} double32; \r\n" " \r\n" "inline double32 convert2double32( double a ) \r\n" "{ \r\n" " double32 b; \r\n" " b.lo = ( double16 )( a ); \r\n" " b.hi = ( double16 )( a ); \r\n" " return b; \r\n" "} \r\n" " \r\n" "inline double dot32( double32 a, double32 b ) \r\n" "{ \r\n" " double32 c; \r\n" " c.lo = a.lo * b.lo; \r\n" " c.hi = a.hi * b.hi; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot( c.lo.lo.lo + c.lo.lo.hi + c.lo.hi.lo + c.lo.hi.hi + \r\n" " c.hi.lo.lo + c.hi.lo.hi + c.hi.hi.lo + c.hi.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double32 _v32; \r\n" " _v32.lo = ( double16 ) ( 0., 1., 2., 3., 4., 5., 6., 7., \r\n" " 8., 9., 10., 11., 12., 13., 14., 15. ); \r\n" " _v32.hi = ( double16 ) ( 16., 17., 18., 19., 20., 21., 22., 23., \r\n" " 24., 25., 26., 27., 28., 29., 30., 31. ); \r\n" " \r\n" " /// all vector-related with undefined type \r\n" " double32 xVect; \r\n" " double32 sumVect = convert2double32( 0.0 ); \r\n" " double32 double1Vect = convert2double32( 1.0 ); \r\n" " \r\n" " double32 in; \r\n" " /// work only with 16-vectors in the loop! \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in.lo = _v32.lo + 32. * ( i * _ITERATIONS + j ); \r\n" " in.hi = _v32.hi + 32. * ( i * _ITERATIONS + j ); \r\n" " xVect.lo = ( in.lo + 0.5 ) * _STEP; \r\n" " xVect.hi = ( in.hi + 0.5 ) * _STEP; \r\n" " sumVect.lo += 4. / ( xVect.lo * xVect.lo + 1. ); \r\n" " sumVect.hi += 4. / ( xVect.hi * xVect.hi + 1. ); \r\n" " } \r\n" " out[ i ] = dot32( sumVect, double1Vect ); \r\n" "} \r\n";
In genau diesem Kernel wird die Vektordimension 32 umgesetzt. Der neue Vektortyp und einige notwendige Inline-Funktionen werden außerhalb der Hauptfunktion des Kernels definiert. Davon abgesehen (und das ist wichtig!), werden alle Berechnungen innerhalb der Hauptschleife absichtlich nur mit Standard-Vektordatentypen ausgeführt. Nicht-Standardtypen werden außerhalb der Schleife verarbeitet. Dies ermöglicht uns eine deutliche Beschleunigung der Ausführungsdauer des Codes.
In unserer Berechnung scheint das Kernel nicht langsamer zu sein als bei der Verwendung für Vektoren mit einer Breite von 16, doch es ist auch nicht viel schneller.
Laut Informationen von MetaDriver führt das Script mit diesem Kernel (_ch=32) zu den folgenden Ergebnissen:
2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: gone = 0.156 sec. 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) read = 10000 elements 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) CLProgramCreate: unknown error or no error. 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) GetLastError returned .. 0 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _itInKern = 3125; vectorization channels - 32 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) =================================================================
Zusammenfassung und Schlussfolgerungen
Der Verfasser versteht vollkommen, dass die Aufgabe, die zum Vorführen der Ressourcen von OpenCL gewählt wurde, für diese Sprache nicht sehr typisch ist.
Es wäre viel einfacher gewesen, ein Lehrbuch zur Hand zu nehmen und ein Standardbeispiel für die Multiplikation großer Matrizen abzuschreiben, um es hier darzulegen. Dieses Beispiel wäre natürlich beeindruckend gewesen. Aber gibt es viele Nutzer des mql5.com-Forums, die sich mit finanziellen Berechnungen beschäftigen, die die Multiplikation großer Matrizen erfordern? Das ist weniger wahrscheinlich. Der Verfasser wollte sein eigenes Beispiel wählen und alle auftretenden Schwierigkeiten selbst überwinden und dabei gleichzeitig versuchen, seine Erfahrungen mit anderen zu teilen. Das Urteil liegt natürlich in Ihren Händen, liebe Forumnutzer.
Der Effizienzgewinn bei der OpenCL-Emulation (auf einer "nackten" CPU) erwies sich als ziemlich gering im Vergleich mit den hunderten und tausenden, die die Scripts von MetaDriver erzielten. Doch auf einer ordentlichen GPU wird er um mindestens eine Größenordnung größer als bei der Emulation sein, auch wenn wir eine etwas längere Laufzeit auf der CPU bei einer AMD-CPU ignorieren. OpenCL ist es immer noch wert, erlernt zu werden, auch wenn die Zunahme der Berechnungsgeschwindigkeit noch so klein ist!
Im nächsten Beitrag des Verfassers soll auf Probleme in Bezug auf die Besonderheiten bei der Darstellung abstrakter OpenCL-Modelle auf realer Hardware eingegangen werden. Die Kenntnis dieser Dinge ermöglicht es manchmal, die Berechnungen nochmals deutlich zu beschleunigen.
Der Verfasser möchte sich besonders bei MetaDriver für sehr wertvolle Tipps zur Programmierung und Performance-Optimierung und beim Support-Team für die Möglichkeit, Intel OpenCL SDK zu nutzen, bedanken.
Inhalte der angehängten Dateien:
- pi.mq5 – ein Script in reinem MQL5 mit zwei Arten zur Berechnung des Wertes von "Pi";
- OCl_pi_float.mq5 – erste Umsetzung des Scripts mit OpenCL-Kernel und echten Berechnungen mit dem Typ float;
- OCL_pi_double.mq5 – das Gleiche, aber mit echten Berechnungen mit dem Typ double;
- OCL_pi_double_several_simple_kernels.mq5 – Script mit mehreren spezifischen Kernels für verschiedene "Breiten" von Vektoren (4, 8, 16, 32);
- OCL_pi_double_parallel_straight.mq5 – Script mit einem einzelnen Kernel für einige "Breiten" von Vektoren (4, 8, 16).
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/405
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Warum ist MQL5 Market der beste Ort für den Verkauf von Handelsstrategien und technischen Indikatoren?
Warum ist MQL5 Market der beste Ort für den Verkauf von Handelsstrategien und technischen Indikatoren?
 Automatenbasierte Programmierung als neue Herangehensweise an die Erstellung automatisierter Handelssysteme
Automatenbasierte Programmierung als neue Herangehensweise an die Erstellung automatisierter Handelssysteme
 Unbegrenzte Möglichkeiten mit MetaTrader 5 und MQL5
Unbegrenzte Möglichkeiten mit MetaTrader 5 und MQL5
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Der neue Artikel OpenCL: A Bridge to a Parallel World wurde veröffentlicht:
Von Sceptic Philozoff
OpenCL-Unterstützung ist eine sehr gute Wahl, jetzt und in der Zukunft der Computing-Plattform Heterogenität ist sehr offensichtlich, aber jetzt die gleichen Algorithmen unter den Bedingungen der Verwendung von OpenCL als CUDA Leistung ist viel niedriger, vielleicht CUDA als OpenCL ist mehr zugrunde, besser für seine eigene GPU optimiert. NVIDIAs GPUs haben eine bessere Leistung, bessere Dynamik, und die CUDA-Compiler hat LLVM angenommen. NVIDIA's GPU Leistung ist besser, die Entwicklung Dynamik ist besser, und CUDA-Compiler hat LLVM angenommen, wird es mehr und mehr Sprachen zu unterstützen CUDA, Python kann nun unterstützen, vor allem CUDA6.0 in der Programmierung Benutzerfreundlichkeit ist mehr prominente, vor allem Unified Memory-Technologie, in der Zukunft, mit der CUDA-Laufzeit-Unterstützung für die automatische Datenmigration ist besser, die Leistung des Programms und der Programmierung Produktivität wird besser sein. MQL5 Unterstützung für OpenCL ist ein guter Anfang, und es kann einige Dinge, die auf CUDA in der Zukunft getan werden kann.
Autor oder Experten antworten bitte:
Wo wird der untenstehende Code schneller funktionieren, auf dem Hauptstein oder im Vidicon? Und gibt es irgendwelche Besonderheiten?
void OnStart()
{
long total= 1000000000;
for(long i=0;i<total;i++)
for(long q=0;q<total;q++)
for(long w=0;w<total;w++)
for(long e=0;e<total;e++)
for(long r=0;r<total;r++)
for(long t=0;t<total;t++)
for(long y=0;y<total;y++)
for(long u=0;u<total;u++)
func(i,q,w,e,r,t,y,u);
}
Zum Beispiel :
Pi = 4*atan(1);
oder
Pi = acos(-1);
Ich glaube nicht, dass mehr als 7 Sekunden, um den Wert von PI auf 12 Dezimalstellen zu erhalten, die höchste Effizienz ist.
Ich habe schon von OpenCV für Python und maschinelles Lernen gehört, das sogar in einem sehr psychologischen Bereich wie dem Handel von Nutzen sein kann, aber noch nie von OpenCL. Aus diesen Gründen gibt es heute mit ZeroMQ eine schöne Schnittstellenumgebung. Nun, ich denke, dass die Kommunikation zwischen der Plattform MTx und der Python-Umgebung ein wenig Zeit in Anspruch nehmen kann, vor allem, wenn eine große Menge an Daten übertragen werden muss.
Vielen Dank für den Artikel in der Tat.