
从基础到中级:结构(四)

概述
在前一篇文章“从基础到中级:结构(三)”中,我们开始探讨一个令初学者感到非常困惑的话题:结构化代码和组织化代码之间的区别。许多人将代码组织良好与代码结构化混淆了。虽然这些概念看起来相似,但它们并不完全相同。然而,本文只是结构化编程领域中更复杂、更优雅、更迷人内容的起点。
由于根据先前的实践经验,某些概念可能较难或较易理解,我们将努力以清晰客观的方式呈现每个概念。我们的目标是让你正确理解什么是结构化代码,以及如何利用它来构建几乎任何东西。我说“几乎”是因为结构化代码的管控能力是有限的。当我们遇到这一限制时,就有必要引入另一个概念:类。届时,我们将告别结构化编程,转而进入面向对象编程(OOP)。然而,就目前而言,我们可以探索许多内容,并通过创建多个结构化代码示例来获得许多乐趣,从而真正掌握结构化编程的概念和局限性。
好的,让我们从上一篇文章中断的地方继续。这就是我们提到并演示如何使用公有代码段和私有代码段的地方。虽然我们没有解释这样做的原因,但我们现在将从这一点开始解释。
结构中代码的私有部分
由于结构中定义的每个元素默认为公有的,我认为没有必要解释公有部分,因为它不需要在代码中声明 —— 由于是在结构内部声明的,所以是隐式的。但是,代码的私有部分则有所不同。在这种情况下,必须明确指出该部分。但这对于代码以及我们如何使用它有一定的影响。我们先从简单的事情开始。既然目标是教育性的,那么就不要试图去寻找为什么代码应该以特定方式实现的逻辑。试着理解这个概念,因为这才是对我们真正重要的。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
代码 01
代码 01 的功能非常简单、实用且易于理解。其理念是创建完全结构化的代码。为此,我们首先必须定义我们自己的结构。这是在第 04 行完成的。现在,请注意:在此结构中,通常唯一会执行的操作就是第 07 行的声明。因为这正是关于结构的文章中所解释和研究的内容。然而,在上一篇文章中,我们开始讨论结构化代码,为了实现它,我们在结构中增加了一些内容。在这种情况下,我们将继续添加函数和/或过程。因此,结构内部将出现内部子程序,这些子程序将定义结构化代码。
然而,这些子程序,无论是函数还是过程,都必须成为上下文的一部分,而这个上下文与结构中存在的变量或结构的设计和实现目的相关。目前,我认为你已经理解了所有内容。一旦结构被定义,我们就可以开始使用它了。为了说明这种特定结构的使用,我们将利用第 43 行 OnStart 过程中的内容。
首先,在第 45 行,我们定义了一个数值常量数组。这些值代表什么并不重要;我们只需要它们存在。现在,在第 46 行,我们声明了一个变量来访问第 04 行定义的结构。在此之后,我们可以选择两条路径。第一种方法是使用我们在第 48 行看到的内容;第二种方法我们稍后再考虑。执行第 48 行后,结构体中第 07 行声明的数组将被填充我们当前感兴趣的值。这就是事情开始变得有趣的地方。
遵循这种推理方式,你就能理解结构化代码是如何让理解变量的目的变得更加容易的。当我们在第 46 行声明 Info 时,我们并不知道这个声明的目的是什么;我们只是需要一个这种特定类型的变量。但由于该结构包含内部函数和过程,这些函数和过程为其所包含的值提供了上下文,因此我们知道在使用它时可以开展何种活动。如果这些函数和过程没有被声明,我们的结构就可以(而且现在仍然可以)用于任何目的。这与一个尚未解决的问题有关。然而,通过查看第 49 行和第 50 行,我们发现该结构旨在计算我们输入数据的平均值和中位数。
诸如此类的事情就构成了我们所知的语境。换言之,只有当我们理解了某事物存在的原因时,它才具有意义。没有它,任何变量、函数或过程都可能代表任何含义,服务于任何目的。因此,执行代码 01 时,我们将看到以下结果:
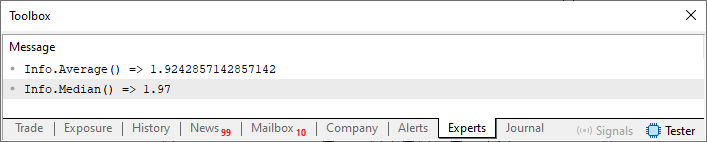
图 01
换言之,我们并不关心第 45 行指定的值是什么意思,或者它们与现实世界有何关联。但我们可以断言,在给定的值结构上下文中,要显示的结果应如下所示:这些内容可以以多种方式进行扩展,因为每当我们需要与结构中的数据相关的内容时,我们都可以利用上下文来强调和简化对结果本身的理解,因为结构本身就为这类信息提供了上下文。
请注意,我们本可以为相同目的编写类似的代码,但那样的话,我们就会缺乏一个真正的上下文,将结构中的数据与生成的答案联系起来。现在我们要讲到许多初学者经常觉得难以理解的部分。它指出,由于结构中未指定任何访问部分,因此其中的所有内容都被视为公有内容。换言之,我们可以以完全任意的方式处理信息。为了演示这一点并理解该过程的复杂性,让我们对代码进行如下修改:
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
代码 02
在代码 02 中,这只是完整代码(将在附录中提供)的一个片段,我们可以看到,只有与 OnStart 过程相关的部分被修改了。然而,这一修改虽然未改变结构的上下文,却彻底粉碎了获得合适数值的所有希望。这是因为结构中的内部变量可以被修改,或者更准确地说,可以被访问。这确实非常危险。人们可能会想:“当然,当我们运行这段代码时,这些值会有所不同。”这是显而易见的,因为第 55 行给第 04 行定义的变量赋新值,而该变量又位于结构体内部。
既然我们都能清楚地看到发生了什么,我真不明白这里的问题出在哪里。没错,亲爱的读者,但我必须提醒你,这些是教学代码,因此其中的错误很容易被发现。在实际代码中,你很难实现这一点,因为正在使用的上下文会在结构中保留并存在。然而,在第 55 行,我们强制改变了结构中的变量,而结构本身对此却一无所知,这一事实使情况变得异常复杂,难以理解结果为何不正确且与预期不符。
这种类型的错误被称为“封装错误”,因为本不应访问某些内容的代码确实访问了这些内容,或者更糟糕的是,设法修改了本不应更改的变量。然而,问题甚至更为严重。为了理解这一点,我们需要知道执行代码 02 的结果。这部分内容如下所示:
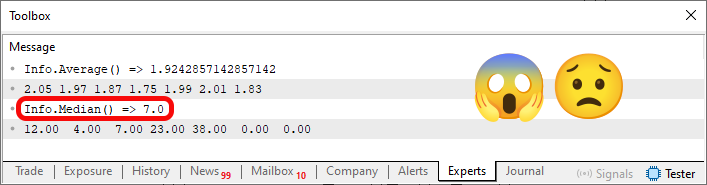
图 02
要小心,因为这是程序员测试中失败的一个原因,因为如果雇主想要评估你对代码中可能存在的错误的理解程度,你会发现自己处于一个尴尬的境地。当执行第 50 行代码时,会分配足够的内存来存储第 45 行代码中的值。到目前为止,一切都很好。因此,当执行第 53 行时,我们可以看到第 45 行声明的值。也就是说,代码按预期运行,且结构定义正确。然而,当执行第 54 行代码时,结构中的所有变量都将被重置。这不是错误。事实上,在许多情况下,这甚至是允许且可取的,因为一个结构可能包含多个预定义的元素,而我们希望将它们全部删除。
但是当执行第 55 行代码时,代码中出现了错误。这是因为分配的内存没有被释放;它只是被重置了。因此,内存的实际内容会显示在第 59 行。因此,图 02 中突出显示的中值 K 是不正确的。“但为什么这样做是错的呢?我不明白。”要理解这一点,你需要知道中位数 K 应该是多少。如果你查看代码 02,假设你知道如何找到中位数,你会发现正确的值是 12,而不是 7。数值错误的原因在于,在第 59 行所示的结构中,存在零值或本不应存在的元素。
这正是我们需要使用代码私有部分的原因。这就引出了构成本主题基础的问题:了解为什么以及何时使用私有部分。但人们可能会想:“兄弟,如果我没有像代码 02 中那样使用所有内容,而是不小心在第 55 行重复了第 50 行,只是将 H 替换成了 K,那会怎么样?那样不就能解决问题了吗?”在这种情况下,答案是否定的。结构代码中存在一个小缺陷,但我们稍后会再讨论这个问题。其理念在于理解我们可能会在不知不觉中犯下某些错误。然而,通过应用正确的概念,可以避免这些错误,并且代码也会更容易修复。
为了解决第一个问题,即我们可以直接访问结构中声明的变量,我们需要对代码进行如下修改:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
代码 03
现在请注意,因为很多程序员不在结构体中使用私有部分,正是因为接下来要发生的事情。
还记得吗,我们说过整个问题是由第 59 行代码引起的?在代码 03 中,我们告诉编译器,结构内部声明的变量是私有类型,这意味着它将不再对结构外部可见。这种情况正是由于有第 07 行代码。但是我们需要第 11 行代码来允许在结构外访问其他元素;在本例中,这些元素是函数和过程。否则,这个构造将变得毫无用处。
当我们尝试编译代码 03 时,编译器会发出警告消息,指出代码中的错误。这是流程的一部分,因为我们已经改变了结构的使用方式。以下可以看到这些错误:
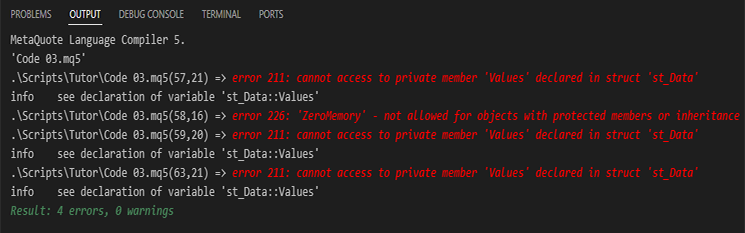
图 03
人们可能会认为错误只会发生在代码 03 的第 59 行,因为正是在那里我们给变量赋值。然而,出现了四处错误。为什么呢?原因很简单,图 03 中可以看到第 57、59 和 63 行的错误,这恰恰与我们试图访问无法再访问的内容有关,因为该变量在结构中是私有的。因此,它只能在声明它的结构内部访问,该结构创建并维护了结构的存在以及变量本身的上下文。
但是第 58 行的错误是怎么回事?我们在那里使用了库函数 ZeroMemory 来完全清除结构中的数据。为什么现在会出现这个错误?这样做的原因在于,我们正在为结构及其所包含的数据创建一个上下文。
因此,我们不能再直接访问或修改数据结构,因为这会破坏封装,并可能影响内部数据上下文。正是这些概念——封装和上下文——确保了结构中的数据始终保持完整和安全。这迫使我们实施了一系列新的解决方案来保留这些概念。这就是我们开始构建完全结构化编程的方式。
“但是请等一下,如果我们不能像以前那样做每件事,那我们该如何保持这段代码的正常运行呢?封装和上下文似乎就是为了让我们的生活变得更艰难而设计的。我更喜欢用以前的方式编程——这样简单得多。”嗯,我部分同意你的观点,许多程序员在初次遇到新事物时,也会有同样的想法。当我开始编程时,我也这么想过。我讨厌编写结构化代码,因为我觉得它没什么意义,因为它经常迫使我们思考并详细说明每件事实际上应该如何运作。但随着时间的推移,我渐渐习惯了,尤其是当你的代码变得越来越复杂时。这时你才会意识到,结构化编程能带来巨大的不同。
现在让我们回到代码本身。由于代码 03 无法生成可执行文件,我们必须修复它才能使其正常工作。为此,我们将对其进行如下修改:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
代码 04
在代码 04 中,我们提供了一种可能实现方式,实现了之前在代码 02 中所做的工作,即生成 H 的平均值,然后生成 K 值的中位数。但请注意,我们并不打算检查结构的内部内容,因为我们已知哪些值将用于分析。但是,请查看代码 04 中的第 15 行。在这里,我们正在修复在尝试为结构分配新的内部值时出现的错误。这就是为什么我说这只是可能的解决方案之一 —— 根据每个具体案例的不同,这种清理工作可能会有不同的处理方式。
例如,假设我们需要代码来执行与代码 02 中完全相同的功能。换句话说,我们希望像代码 02 的第 54 行那样清除结构的值,并且能够输出变量的内容。我们如何在保留封装和上下文概念的同时解决这个问题?为此,下面给出了一种可能的建议。这是游戏中最有趣的部分,因为每个程序员都能想出并开发出不同的方法来解决同一任务。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
代码 05
如果在 MetaTrader 5 中运行代码 05,结果如下:
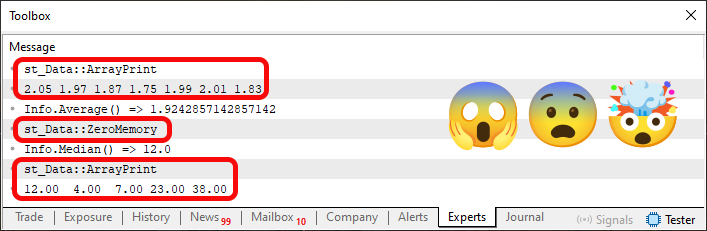
图 04
请注意,在图 04 中,我们强调了某些特定方面。当然,你可能会问:为什么要强调这些内容?原因可以在代码 05 中找到。“请看第 19 行和第 25 行。你在这里究竟在做什么疯狂的事?这甚至是被允许的吗?”
正如我最近提到的,最有趣的部分恰恰在于,每个程序员都可以开发出不同的方法来解决同一任务。在结构化编程中,你可以自由使用函数或库过程的名称,就像我在代码 05 中所做的那样。然而,你必须小心,不要无意中生成递归调用,就像我们在这里重载 MQL5 库的标准函数时发生的那样。
我们是在结构中现有的上下文背景下进行这项工作的。这种结构造不会产生任何问题,尤其是因为第 68、70 和 74 行的代码比创建特殊标签要容易理解得多,我们可以清楚地看到应该执行哪个过程或函数。但有一个小细节:如前所述,在实施时需要谨慎。为了演示这在实践中是如何运作的,我在代码中添加了第 21 行和第 27 行,这样你就可以跟随执行流程,并理解我们从一开始就没有使用标准库调用。首先,编译器会使用结构中声明的过程,然后才会继续执行后续操作。
对于 ArrayPrint 调用,编译器首先使用结构中声明的内容。这是因为在第 68 行和第 74 行中,我们告知它正在执行的代码位于结构内部。只有解决了这个问题,编译器才会处理第二个问题 —— 第 28 行的调用。此调用将执行流程引导至标准 MQL5 库中的代码。
请注意,即使没有声明一个私有部分(这将使第 9 行声明的变量仅对该结构体可见,而对代码的其他部分隐藏),我们也可以轻松地将代码 05 转换为代码 02,因为只需要进行少量修改即可。反过来也是一样的:将代码 02 转换为代码 05。然而,在这种情况下,转换过程可能不会非常顺畅,而这恰恰是因为代码 02 中的第 55 行。但是,如果代码 02 中的执行问题对您来说不是问题,则可以在 100% 结构化编程的框架内,实现与代码 02 的功能 100% 一致的解决方案。为了实现这一目标,我们需要采取以下措施:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
代码 06
执行代码 06 时,我们将得到与图 02 中完全相同的结果。但是,请注意代码 06 与代码 02 的区别。
首先,代码 02 没有遵循封装原则,因此,结构的上下文会受到威胁,因为在某些时候,我们可能会面临在结构未察觉的情况下更改其内部内容的风险。
其次,由于代码 06 充分利用了结构化代码,因此任何问题或故障都不能归咎于简单的疏忽,因为在创建结构化程序的过程中,我们清楚自己正在创建什么。因此,如果发生故障,那正是因为使用不当或试图修改结构的上下文,甚至不了解其原始目的。
当我们从结构化编程过渡到面向对象编程(OOP)时,这类事情会引发诸多困惑,因为在面向对象编程中,我们可以完全改变一个对象(理论上应该是一个结构)的含义,使其变得与原始对象毫无关联。在未来,当我们讨论面向对象编程(OOP)时,我们将再次回到上下文这个问题上。
因此,切记不要跳过任何步骤,也不要操之过急。作为程序员,如果不先掌握那些使实现变得复杂的简单概念,就试图去理解一些东西,那将对你没有帮助。对概念理解得越透彻,就越容易将其应用于各种各样的情境中。
“我想我开始理解结构化编程的目的了。”从本质上讲,它有助于我们编写更安全、更高效的代码。但我有个问题:到目前为止,我们所做的一切都是手动完成的。也就是说,在解释重载以及函数和过程模板的使用时,我们并没有从编译器那里得到太多关于所讨论问题的帮助。我们能否在这种类型的编程中,在编译器的帮助下,避免生成重载,并使用函数和过程模板来创建结构化代码?那还算是结构化编程吗?
这的确是个非常好的问题。不过,我会让你带着学习如何做到这一点的渴望,至少等到下一篇文章发布。
总结性思考
在本文中,我们探讨了如何创建所谓的结构化代码,即将处理变量和信息的整个上下文和方法置于一个结构中,从而为实施我们所需的任何代码建立合适的上下文。我们已经认识到使用私有部分将公有部分与非公有部分分开的必要性,从而遵守封装规则,并维护数据结构创建时所处环境的完整性、安全性和可靠性。我们还观察到,即使在结构化的代码中,也可能出现错误 —— 或者更确切地说,可能引发一连串的漏洞 —— 这正是由于引入了违反原本预期上下文的函数或过程,从而使简单的代码变得复杂,难以维护和使用。
会上还提出了在这种实现方式中使用模板的问题。鉴于这是一个更为复杂的话题,且本文已提供了充足的理解和实践材料,我们将在下一篇文章中开始讨论结构化代码中的模板主题。但你现在就可以通过使用这里提供的代码开始关注它。这将帮助你将使用概念的假设付诸实践,这些概念适用于你尚未考虑或探索过的事物。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15860
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
