
Klassische Strategien neu interpretieren (Teil 17): Modellierung technischer Indikatoren

Die Anwendung des maschinellen Lernens und anderer moderner statistischer Verfahren auf den algorithmischen Handel ist eine besondere Herausforderung. Die Probleme, mit denen unsere Community konfrontiert ist, betreffen ausschließlich die Finanzmärkte – und werden daher in breiteren Kreisen des maschinellen Lernens nur selten diskutiert. Infolgedessen bietet das klassische überwachte Lernen nur sehr wenige praktische Anleitungen zu Themen, die für unsere Gemeinschaft von Bedeutung sind. Eines der am meisten übersehenen Probleme in unserem Bereich ist die Tatsache, dass wir bei der Modellierung von Finanzdaten kein festes Ziel haben. Dies mag auf den ersten Blick nicht problematisch erscheinen, ist es aber.
Zur Veranschaulichung wollen wir darüber nachdenken, wie diese Modelle in der Medizin angewandt werden – der Leser sollte sich daran erinnern, dass die Medizin der Bereich ist, aus dem viele Techniken des überwachten Lernens ursprünglich hervorgegangen sind, und unsere Gemeinschaft sich diese Techniken „ausleiht“. In der Medizin ist die Zielvariable eindeutig und wohldefiniert. Ein Arzt könnte einen Patienten als krebskrank oder nicht krebskrank einstufen wollen – ein binäres Klassifizierungsproblem mit einer eindeutigen und unveränderlichen Bezeichnung. Das Ziel des Arztes ändert sich nie, und das Ziel ist in der physischen Realität verankert. Außerdem arbeiten medizinische Modelle innerhalb natürlicher Zwänge – biologischer, ethischer oder verfahrenstechnischer Art – die dem Lernproblem eine einheitliche Struktur geben.
Im Gegensatz dazu fehlt im Finanzbereich eine solche Struktur. Als algorithmische Händler haben wir keine feste Definition des Ziels. Wir können den Markt in Form von Jahresrenditen, Tagesrenditen, 15-Minuten-Renditen, jährlichen Kurssteigerungen, maximalen Drawdowns, Volatilität oder sogar relativen Bewegungen zwischen Vermögenswerten modellieren. Es gibt in der Tat unendlich viele Möglichkeiten, die Bedeutung des „Ziels“ im Handelskontext zu definieren. Und obwohl diese Ziele alle von denselben zugrunde liegenden Daten abgeleitet werden, sind einige Ziele weitaus schwieriger zu prognostizieren als andere.
Dies wirft eine kritische Frage auf: Könnte unsere offensichtliche Leistungsgrenze nicht durch Modellschwächen oder Datenqualität, sondern durch unsere schlechte Wahl des Ziels verursacht sein? Erschwerend kommt hinzu, dass wir im Voraus nicht wissen, was das „richtige“ Ziel ist – oder ob es überhaupt ein universelles Ziel für die verschiedenen Märkte gibt. Jeder Markt kann seine eigene optimale Formulierung des Vorhersageproblems haben.
Unter diesem Gesichtspunkt wird deutlich, dass die Leistung unserer statistischen Modelle nicht unbedingt ihre wahre Leistungsfähigkeit widerspiegelt. Die Grenzen, auf die wir stoßen – die Fehlerquoten, die nicht reduzierbar zu sein scheinen – sind oft Symptome einer methodologischen gläsernen Decke.
In diesem Artikel wird gezeigt, dass wir durch sorgfältiges Experimentieren und adaptive Methoden die Leistung unseres Modells kontinuierlich verbessern können, indem wir einfach überdenken, was wir vom Modell vorhersagen wollen, und nicht nur, wie wir es trainieren. Indem wir verschiedene Zieldefinitionen durchgehen, werden wir zeigen, dass die Leistung nicht nur von der Datenqualität und der Modellkomplexität abhängt, sondern auch – und vielleicht am wichtigsten – von der Methodik, mit der wir das Lernproblem selbst formulieren.
Abrufen unserer Daten in MetaTrader 5
Um unsere Übung zu beginnen, holen wir uns zunächst die notwendigen Marktdaten aus dem MetaTrader 5 Terminal. Um die Konsistenz zwischen den Daten, die unser Modell während des Trainings erhält, und den Daten, die es während des Live-Handels erhält, sicherzustellen, holen wir unsere Daten mit einem speziellen MQL5-Skript ab. Dieser Ansatz ermöglicht es uns, dieselben Datentransformationen auch nach der Backtest-Periode zu reproduzieren.
Das Skript ruft die vier primären Kursniveaus ab – Open, High, Low und Close – und fügt jedem von ihnen einen technischen Indikator zu. Sobald diese Werte ermittelt sind, zeichnet das Skript sowohl die Rohpreise als auch die entsprechenden Indikatorwerte auf. Als Nächstes berechnen wir das Wachstum (die Veränderung) für jedes der vier Preisniveaus und die dazugehörigen Indikatoren. Anschließend berechnen wir das relative Wachstum zwischen jedem Paar von Kursniveaus – zum Beispiel das Wachstum zwischen Eröffnungs- und Höchstkurs, Eröffnungs- und Tiefstkurs sowie Eröffnungs- und Schlusskurs. Dieser Prozess führt zu einer detaillierten Aufschlüsselung der Preisbewegungen innerhalb einer Kerze, was dem Modell ein besseres Verständnis der Preisentwicklung innerhalb jedes Balkens ermöglicht.
//+------------------------------------------------------------------+ //| Fetch Data MA | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_TYPE MODE_SMA //--- Type of moving average we have //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Detailed Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000; input int MA_PERIOD = 5; input int HORIZON = 5; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA O", "True MA H", "True MA L", "True MA C", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", "Diff MA Close 2", //--- Growth Across Price Levels "O-C", "H-L", "O-H", "O-L", "C-H", "C-L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_reading[(i + HORIZON)], //--- Growth Across Price Levels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_TYPE //+------------------------------------------------------------------+
Erste Schritte mit unserer Analyse in Python
Sobald das Skript für die Datenextraktion fertig ist, wechseln wir zu Python für die Analyse. Wie bei den meisten unserer Experimente im Bereich des maschinellen Lernens besteht unser erstes Ziel darin, mit Hilfe klassischer Modellierungsparadigmen ein grundlegendes Leistungsniveau zu ermitteln. Wir beginnen mit dem Laden unserer Standard-Python-Bibliotheken.
#Import the libraries we need to get started import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Es ist erwähnenswert, dass die ursprüngliche Version unseres MQL5-Skripts, die hier verwendet wurde, sich leicht von der endgültigen Version unterscheidet, die später in dieser Diskussion vorgestellt wird – die frühere Version ruft 17 Spalten ab, während die endgültige Version zusätzliche Funktionen enthält. Diese Diskrepanzen und die Gründe für die Erweiterung des Datensatzes werden am Ende des Artikels deutlich werden.
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
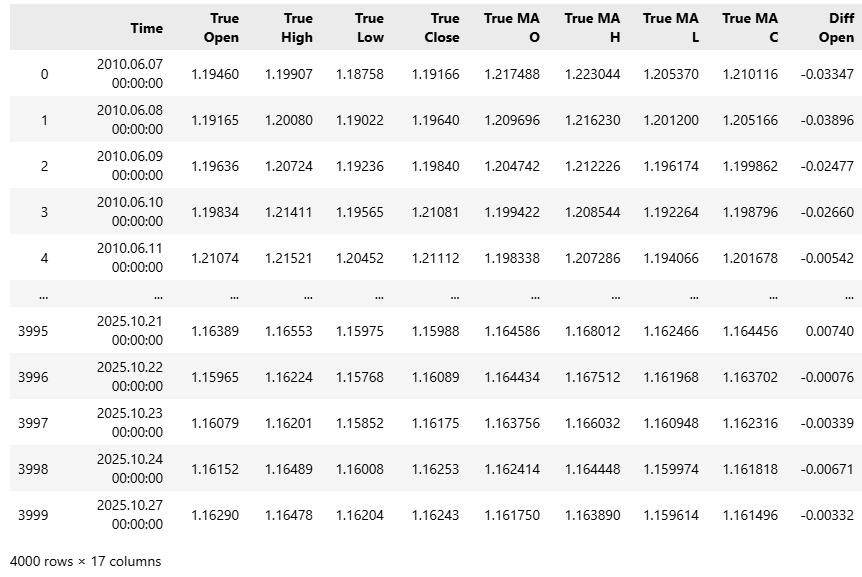
Abbildung 1: Unser Datensatz ist recht groß und enthält im Ausgangszustand 17 Spalten
Nach dem Einlesen des Datensatzes beschriften wir nun unsere Daten nach dem klassischen Ein-Schritt-Ansatz.
#Classical Target #Baseline value HORIZON = 1 #Label the data data['Target'] = data['True Close'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Die Leser sollten sich daran erinnern, dass wir beabsichtigen, dieses statistische Modell durch Backtests zu bewerten. Daher lassen wir die letzten drei Jahre der Beobachtungen weg und behalten sie in einem separaten Testsatz. Wir werden das Modell nicht an diesen Testsatz anpassen, da dies den Zweck unserer Diskussion verfehlen würde.
#Drop the last 3 years of data test = data.iloc[-(365*3):,:] data = data.iloc[:-(365*3),:]
Es ist interessant festzustellen, dass die Stärke der Korrelation zwischen dem Ziel und den Eingaben im Laufe der Zeit besonders unbeständig ist. Wir untersuchten dies, indem wir die Pearson-Korrelation zwischen unserem Ziel und jeder Eingabevariablen unter Verwendung eines sich erweiternden Fensters von Beobachtungen berechneten. Auf diese Weise erhalten wir einen Vektor, dessen Werte die Stärke der Korrelation zwischen dem Ziel und jeder Eingabe darstellen. Wir haben dann die L1-Norm (die Summe der absoluten Werte) dieses Vektors genommen, um ein einziges Maß für die Gesamtkorrelationsstärke zu erhalten.
Wir begannen mit Daten für einen Tag, dann zwei Tage, drei Tage und so weiter, bis wir schließlich ein ganzes Jahr (365 Tage) erreicht hatten. Wie die nachstehende Abbildung zeigt, ist der Korrelationsgrad nicht stationär, sondern schwankt. An manchen Tagen erscheint sie stark, an anderen schwächer. Insgesamt scheint sie mit zunehmender Vergrößerung des Fensters abzunehmen, was darauf hindeutet, dass die Beziehungen zwischen den Eingaben und dem Ziel im Laufe der Zeit instabil sind.
corr_strength = [] EPOCHS = 365 for i in np.arange(EPOCHS): corr_strength.append(np.linalg.norm(data.loc[:i+1,:].corr().iloc[:,-1],ord=1)) sns.barplot(corr_strength) plt.ylabel('Correlational Strength') plt.title('Correlation Between Future Price And Historical Data')
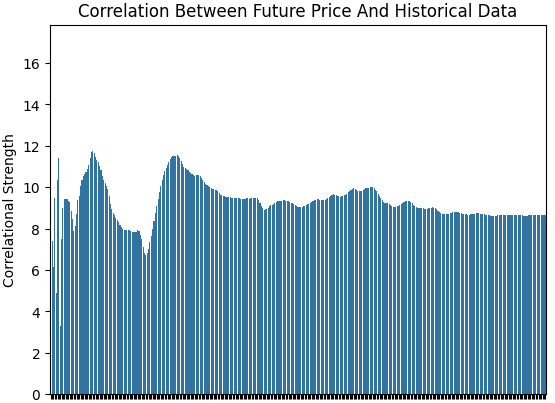
Abbildung 2: Die Stärke der Korrelation im historischen EURUSD-Datensatz ist nicht stationär
Als Nächstes haben wir die Korrelationsstruktur zwischen allen Eingaben in der gesamten Trainingsmenge mithilfe einer Heatmap visualisiert. Wie wir sehen, ist das Ziel tendenziell stark mit den realen Preisniveaus und ihren gleitenden Durchschnitten korreliert, während die Veränderungen dieser Inputs nur schwach mit dem Ziel korreliert sind.
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 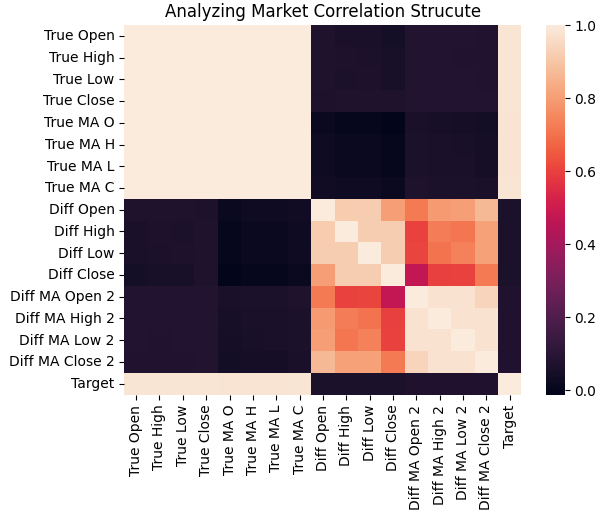
Abbildung 3: Die Korrelationsstruktur unserer historischen EURUSD-Marktdaten zeigt, dass das Ziel stark mit den historischen Preisen verbunden ist
Das ist noch nicht alles, was wir aus der Korrelationsmatrix lernen können. Wir können auch eine Eigenwertzerlegung durchführen, indem wir die eig-Funktion in NumPy verwenden, die sowohl die Eigenwerte als auch die Eigenvektoren zurückgibt. Im Moment konzentrieren wir uns auf die Eigenwerte. Die Eigenwerte zeigen, wie viel Varianz in der Korrelationsstruktur von jeder Hauptkomponente erfasst wird. Mit anderen Worten, die Eigenwerte sagen uns, wie viele dominante „Ausdrucksformen“ unsere Marktdaten zu haben scheinen.
Ein stabiler Markt wird in der Regel von einem dominanten Modus – wie einem starken Trend oder einem Mittelwertumkehrprozess – beherrscht, während ein chaotischerer Markt mehrere konkurrierende Modi aufweist. In unserem Fall zeigt das Balkendiagramm der Eigenwerte zwei große, dominante Modi und einen dritten, der leicht über dem durchschnittlichen Schwellenwert liegt. Dies deutet darauf hin, dass unser System möglicherweise zwei dominante Verhaltensweisen und eine schwächere dritte aufweist. Die übrigen Eigenwerte sind vernachlässigbar und können vernachlässigt werden, da sie keinen bedeutenden Beitrag zur Korrelationsstruktur der Daten leisten.
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
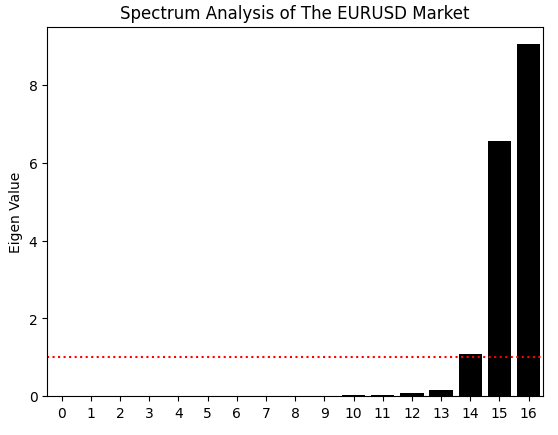
Abbildung 4: Die Eigenwerte der Korrelationsstruktur unserer historischen EURUSD-Daten deuten darauf hin, dass der Markt drei instabile Hauptformen aufweist
Wir fahren nun fort, unsere statistischen Lernbibliotheken zu laden
from sklearn.linear_model import LinearRegression
Definieren wir unseren Input und unser Ziel. Wir werden mit einem einfachen Modell beginnen, das 4 Eingaben benötigt.
X = ['True Open','True High','True Low','True Close'] y = 'Target'
Anpassung des Modells an unsere Marktdaten.
model = LinearRegression() model.fit(data.loc[:,X],data[y])
Das Modell scheint die Marktergebnisse auch außerhalb der Stichprobe angemessen erfassen zu können.
preds = model.predict(test.loc[:,X]) plt.plot(preds,color='black') plt.plot(test.loc[:,y].values,color='red',linestyle=':') plt.title('Visualizing Our Accuracy Out of Sample') plt.xlabel('Historical Time') plt.ylabel('EURUSD Exchange Rate') plt.legend(['Model Predictions','Observed Exchange Rate']) plt.grid()
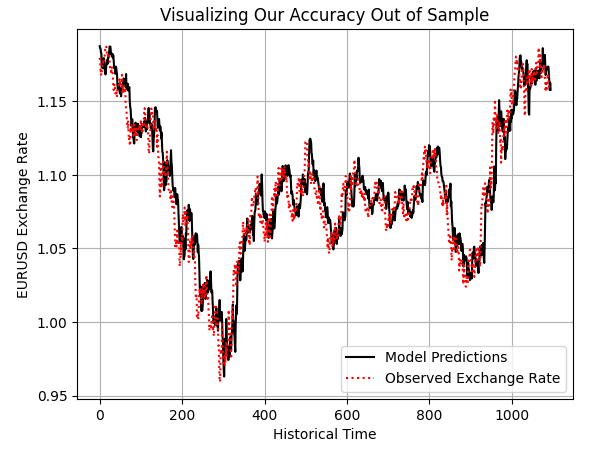
Abbildung 5: Untersuchung der Vorhersagen unseres Modells außerhalb der Stichprobe, um zu prüfen, ob das Modell solide ist
Exportieren nach ONNX
Wir sind nun bereit, unser gelerntes statistisches Modell in das ONNX-Format zu exportieren. ONNX, die Abkürzung für Open Neural Network Exchange, ist eine weltweit anerkannte API, die es Entwicklern ermöglicht, Modelle für maschinelles Lernen zu erstellen und bereitzustellen, ohne dass Abhängigkeiten von dem zu ihrer Erstellung verwendeten Trainingsframework bestehen. Um zu beginnen, laden wir die notwendigen ONNX-Bibliotheken.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Als Nächstes definieren wir die Eingabe- und Ausgabeformen unseres Modells. In unserem Fall benötigt das Modell vier Eingaben und erzeugt eine Ausgabe.
initial_types = [('float_input',FloatTensorType([1,4]))] final_types = [('float_output',FloatTensorType([1,1]))]
Von hier aus erstellen wir einen ONNX-Prototyp-Puffer – eine Zwischenstruktur, die unser Modell vor der endgültigen Konvertierung enthält.
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12) Sobald dies geschehen ist, speichern wir das Modell als .onnx-Datei, indem wir sowohl den Prototyp-Puffer als auch den gewünschten Dateinamen an die ONNX-Speicherfunktion übergeben.
onnx.save(onnx_proto,"EURUSD 2022-2025 LR.onnx") Festlegung einer Basislinie mit Hilfe klassischer Techniken
Damit sind wir bereit, mit dem Aufbau unserer Handelsanwendung in MQL5 zu beginnen. Der erste Schritt besteht darin, die ONNX-Datei zu importieren, die wir gerade aus unserer Python-Analyse exportiert haben.
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR.onnx" as const uchar onnx_proto[];
Anschließend laden wir mehrere unterstützende Bibliotheken, die uns bei der Durchführung von Routineaufgaben helfen, z. B. beim Eröffnen, Schließen und Ändern von Handelsgeschäften, beim Prüfen auf neue Kerzen, beim Verwalten von ONNX-Puffern und anderen damit verbundenen Vorgängen.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *time; TradeInfo *trade; ONNXFloat *onnx_model;
Als Nächstes initialisieren wir einige globale Variablen, die in der gesamten Anwendung verwendet werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int atr_handler; double atr[]; float prediction;
Während der Initialisierung erstellen wir unser ONNX-Modell aus dem Puffer, den wir zuvor geladen haben. In früheren Diskussionen haben wir eine spezielle Bibliothek entwickelt, um ONNX-Dateien effizient zu bearbeiten. Dank dieser nutzerdefinierten Bibliothek konnte die Anzahl der Einrichtungsschritte, die zum Laden und Verwenden unseres ONNX-Modells erforderlich sind, erheblich reduziert werden.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_model = new ONNXFloat(onnx_proto); trade = new TradeInfo(Symbol(),PERIOD_CURRENT); time = new Time(Symbol(),PERIOD_D1); atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); if(!onnx_model.DefineOnnxInputShape(0,1,4)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); } if(!onnx_model.DefineOnnxOutputShape(0,1,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
Wenn wir das ONNX-Modell oder andere zugewiesene Ressourcen nicht mehr verwenden, stellen wir sicher, dass sie ordnungsgemäß freigegeben werden, da dies bei der Entwicklung von MetaTrader 5 als Best Practice gilt.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete onnx_model; delete time; delete trade; }
Immer wenn neue Kursdaten eintreffen, aktualisieren wir unsere Indikatorpuffer, definieren die entsprechenden Eingabewerte für das ONNX-Modell und rufen eine Vorhersage ab. Auf der Grundlage der Vorhersage führen wir die Geschäfte entsprechend aus oder schließen sie. Wenn ein Problem auftritt, wird dem Nutzer eine Fehlermeldung angezeigt.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(prediction > iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } if(prediction < iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
Jetzt können wir mit unserem Backtest beginnen. Wir beginnen mit der Auswahl der Anwendung, die wir testen wollen – in diesem Fall die Benchmark-Version unseres Handelssystems. Wir definieren den Testzeitraum, der sich von 2022 bis Oktober 2025 (zum Zeitpunkt der Erstellung dieses Berichts) erstreckt.

Abbildung 6: Der anfängliche Baseline-Backtest ist sehr wichtig, denn er gibt uns eine Benchmark, die wir anstreben können.
Anschließend legen wir die Testbedingungen fest, unter denen die Strategie bewertet werden soll. Um ein realistisches Marktverhalten zu simulieren, aktivieren wir eine zufällige Verzögerung, die dazu beiträgt, die Unvorhersehbarkeit des Live-Handels zu simulieren.
Abbildung 7: Wählen Sie zufällige Verzögerungseinstellungen für eine realistische Emulation der Echtzeit-Marktbedingungen
Wie wir aus den Ergebnissen ersehen können, scheint die Strategie unter diesen einfachen Bedingungen ziemlich instabil zu sein. Diese Ergebnisse sind nicht völlig überraschend, da das Modell so konzipiert ist, dass es nur einen Schritt in die Zukunft voraussagen kann, d. h. es macht effektiv Vorhersagen für jeden einzelnen Handel, Kerze für Kerze. Dieser Ansatz entspricht nicht der Sichtweise eines menschlichen Händlers auf den Markt und schränkt natürlich die Realitätsnähe und Robustheit des Systems ein. Nichtsdestotrotz dient dies als Basisergebnis, das wir nach den bewährten Standardverfahren ermittelt haben.
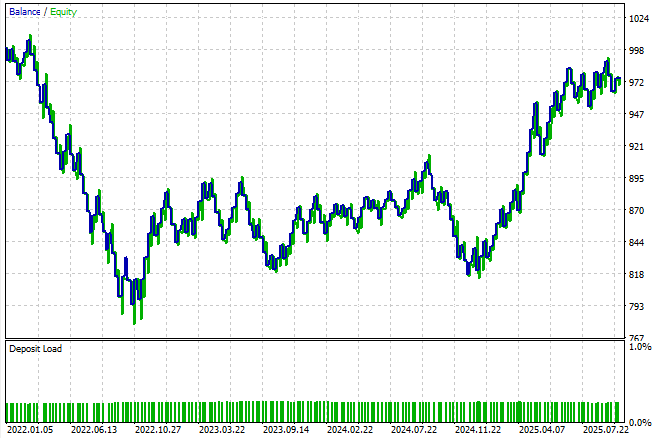
Abbildung 8: Die Kapitalkurve, die von der ersten Version unserer Handelsanwendung erzeugt wird, fordert uns auf, mehr Aufwand zu betreiben
Bei näherer Betrachtung des Backtests stellen wir fest, dass das System eine stark unterdurchschnittliche Performance aufweist. Nicht nur, dass er während des gesamten Backtests durchweg Geld verliert, seine Handelsverteilung ist auch suboptimal und spiegelt kein sinnvolles Verständnis der Marktdynamik wider. Über einen Zeitraum von drei Jahren eröffnete das statistische Modell 183 Kaufgeschäfte und nur ein Verkaufsgeschäft. Dieses Ungleichgewicht verdeutlicht die Unfähigkeit des Modells, den Markt effektiv zu interpretieren – und zeigt deutlich, dass wir eine weitaus bessere Leistung erzielen können, als es die Standardverfahren des maschinellen Lernens allein vermuten lassen würden.
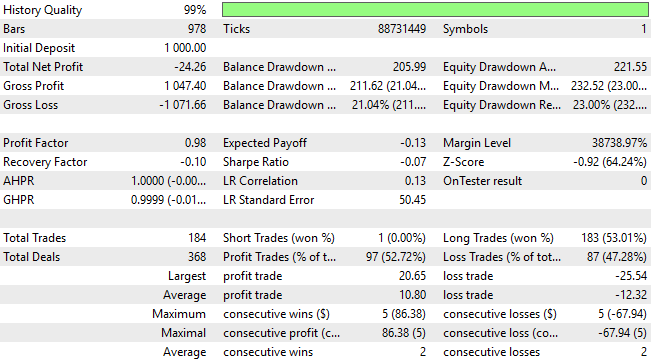
Abbildung 9: Die detaillierten Statistiken unserer Handelsanwendung zeigen die Schwächen des traditionellen Ansatzes auf
Verbesserung der Basislinie mit Hilfe klassischer Techniken
Beginnen wir nun mit der Umsetzung von Verbesserungen an unserer Handelsanwendung. Die erste Verbesserung, die wir vornehmen können, betrifft unseren Prognosehorizont. Im Allgemeinen spiegeln Prognosen, die nur einen Schritt in die Zukunft reichen, nicht die Arbeitsweise profitabler menschlicher Händler wider. Daher werden wir unseren Prognosehorizont auf 10 Schritte in die Zukunft ausdehnen, was realistischere Aussichten bieten dürfte als eine Vorhersage in einem Schritt. In diesem Stadium bleibt der Rest des Codes in unserem Jupyter-Notebook unverändert, daher lassen wir diese Abschnitte weg und heben nur die Segmente hervor, die sich unterscheiden.
#Classical Target #V1 value HORIZON = 10
Nachdem wir unser Modell so angepasst haben, dass es 10 Schritte voraus ist, speichern wir es in einer Datei und laden dann die aktualisierte Version in unsere Handelsanwendung.
onnx.save(onnx_proto,"EURUSD 2022-2025 LR V1.onnx") Implementierung der Verbesserungen an unserer MetaTrader 5 Anwendung
Wie bereits erwähnt, bleibt die Gesamtstruktur der Anwendung weitgehend gleich. Aus Gründen der Kürze lassen wir daher unveränderte Codesegmente weg.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR V1.onnx" as const uchar onnx_proto[];
Sobald das aktualisierte Modell in die Anwendung eingebettet ist, führen wir einen neuen Backtest über denselben Zeitraum durch, um seine Leistung zu bewerten.
Abbildung 10: Wir werden nun unseren ersten Versuch bewerten, die Benchmark-Version unserer Handelsanwendung zu übertreffen
Bei der Untersuchung der Kapitalkurve, die von dieser neuen Version unseres Systems erzeugt wird, stellen wir fest, dass sich visuell nur sehr wenig zwischen den beiden Versionen geändert hat. Ein genauerer Blick auf die detaillierten Statistiken zeigt jedoch einige bedeutende Verbesserungen.
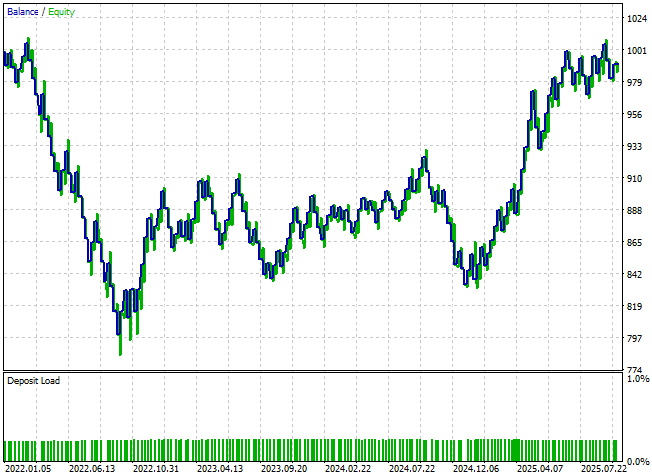
Abbildung 11: Die Kapitalkurve, die durch unseren ersten Versuch, unsere Handelsanwendung zu verbessern, erzeugt wurde, ist identisch mit der ersten Anwendung, mit der wir begonnen haben
Der Gesamtnettoverlust hat sich erheblich verringert – von -24 $ auf -8 $ – obwohl das Ergebnis immer noch unerwünscht ist. Darüber hinaus bleibt die Gesamtzahl der Verkäufe bei Null, was darauf hindeutet, dass das System noch immer kein ausgewogenes oder umfassendes Verständnis der Marktrichtung besitzt. Es ist daher klar, dass die Änderungen zwar hilfreich waren, aber noch viel Raum für Verbesserungen besteht.
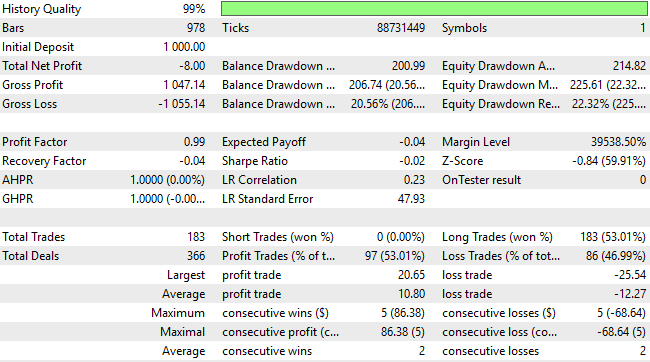
Abbildung 12: Eine detaillierte Analyse unserer neuen Ergebnisse zeigt, dass wir zwar einige Verbesserungen erzielt haben, aber noch weit von unserem Ziel entfernt sind
Mehr Leistung als die klassischen Techniken
An diesem Punkt haben wir die Grundsätze der klassischen Modellierung fast ausgeschöpft. Deshalb werden wir jetzt damit beginnen, uns von traditionellen Ideologien zu lösen und auf der Grundlage der in dieser Artikelserie gewonnenen Erkenntnisse nach Verbesserungen zu suchen. Eine besonders aussagekräftige Beobachtung, die wir gemacht haben, ist die, dass auf den meisten Märkten die technischen Indikatoren oft leichter zu prognostizieren sind als der Rohpreis selbst. Aufbauend auf dieser Erkenntnis werden wir nun unser Modellierungssetup ändern, indem wir die Zielvariable ändern – vom zukünftigen Wert des Preises zum zukünftigen Wert des gleitenden Durchschnitts.#Classical Target #V1 value HORIZON = 10 #Label the data data['Target'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Diese Änderung erfordert natürlich, dass wir auch den Eingaberaum unseres Modells neu definieren. Wir werden vier neue Variablen einführen, die den aktuellen Stand der gleitenden Durchschnitte beschreiben und damit unseren gesamten Merkmalsatz erweitern.
X = ['True Open','True High','True Low','True Close','True MA O','True MA H','True MA L','True MA C'] y = 'Target'
Folglich müssen wir auch die Eingabeform unseres Modells überarbeiten, um diese aktualisierte Konfiguration widerzuspiegeln.
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,1]))]
Nach der Fertigstellung speichern wir das neue Modell.
onnx.save(onnx_proto,"EURUSD 2022-2025 R V2.onnx") Implementierung unserer Verbesserungen in MQL5
Jetzt aktualisieren wir unsere Handelsanwendung, um auf das aktualisierte ONNX-Modell zu verweisen.
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V2.onnx" as const uchar onnx_proto[];
Da die Indikatoren für gleitende Durchschnitte nun Teil des Eingaberaums des Modells sind, beginnen wir mit der Definition von Systemkonstanten, die sowohl den Zeitraum als auch den Typ der verwendeten gleitenden Durchschnitte angeben.
//--- System constants #define MA_PERIOD 5 #define MA_TYPE MODE_SMA
Anschließend erstellen wir Indikator-Handles, um die neuesten gleitenden Durchschnittswerte kontinuierlich zu lesen und zu aktualisieren, sobald neue Kursniveaus erreicht werden.
//---Setup our technical indicators atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW);
Auch unser Verfahren zur Eröffnung der Handelsgeschäfte ändert sich. Zunächst werden die letzten Indikatorwerte aus den vier Handles des gleitenden Durchschnitts in ihre jeweiligen Puffer kopiert. Dann bereiten wir mit einer Funktion aus unserer OnyxTools-Bibliothek namens DefineInputValues() die aktuellen Eingaben für das ONNX-Modell vor. Anschließend rufen wir die Funktion OnyxPredict() auf, um eine Vorhersage zu erhalten, die in einer Fließkomma-Variablen namens prediction gespeichert wird. Sobald die Prognose vorliegt, vergleichen wir den vom Modell vorhergesagten zukünftigen Wert des gleitenden Durchschnitts mit seinem aktuellen Wert. Wenn ein Anstieg des gleitenden Durchschnitts erwartet wird, eröffnen wir Kaufpositionen. Wenn ein Rückgang erwartet wird, eröffnen wir Verkaufspositionen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,1,ma_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(prediction > ma_reading[0]) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(prediction < ma_reading[0]) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
Wie zuvor lassen wir diese neue Version der Anwendung über denselben Testzeitraum laufen, den das Modell während des Trainings noch nie gesehen hat.

Abbildung 13: Ausführung unserer überarbeiteten Handelsanwendung über dasselbe Testfenster, um unsere Verbesserungen zu bewerten
Die Kapitalkurve zeigt nun endlich Anzeichen für eine gesunde Entwicklung und bildet einen Aufwärtstrend, auch wenn sie immer noch eine gewisse Volatilität aufweist.
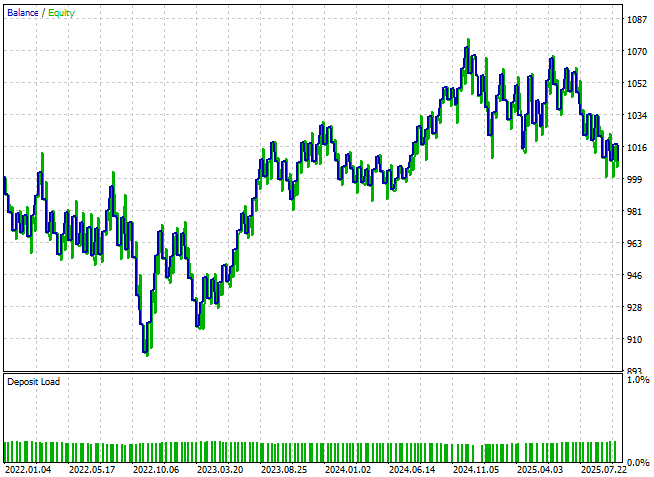
Abbildung 14: Unsere Anwendung hat endlich zum ersten Mal die Gewinnschwelle überschritten
Wenn wir die detaillierten Performancestatistiken betrachten, stellen wir fest, dass die Strategie den Breakeven überschritten hat. Die Gewinne sind zwar nach wie vor bescheiden, aber der Anteil der gewinnbringenden Handelsgeschäfte ist auf über 50 % gestiegen und liegt nun bei 53 %, und der Gewinnfaktor zeigt nun eine positive Erwartung an. Es ist klar, dass diese Verbesserungen das System in die richtige Richtung lenken, auch wenn es noch mehr Raum für Verbesserungen gibt.
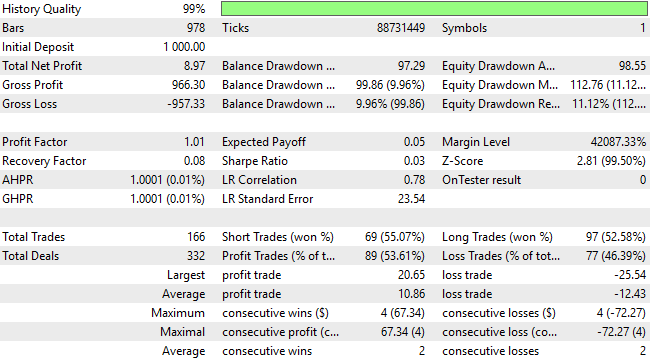
Abbildung 15: Die Anwendung scheint eine ausgewogene Sichtweise auf Käufe und Verkäufe zu haben, obwohl die Rentabilität untragbar ist.
Mehr Raum für Verbesserungen erkennen
Bei der weiteren Abkehr von klassischen Ideologien können wir uns auf eine weitere wichtige Beobachtung aus unserer verwandten Artikelserie Überwindung der Grenzen der KI stützen. In dieser Studie haben wir festgestellt, dass die Verwendung mehrerer Prognosehorizonte manchmal zu Modellen führen kann, die intern kohärenter sind – d. h. mehr mit sich selbst übereinstimmen – als mit den realen Daten. Wir werden nun prüfen, ob uns diese Erkenntnis auch bei dieser Aufgabe helfen kann. Zu diesem Zweck werden wir zwei Ziele für unser Modell erstellen.
Nämlich der Wert des Indikators des gleitenden Durchschnitts einen Schritt voraus und der Wert desselben Indikators zehn Schritte voraus. Für Leser, die den früheren Artikel nicht gelesen haben, ist die Logik hinter diesem Ansatz ganz einfach: Wir werden unsere Handelssignale aus der impliziten Steigung zwischen den beiden Prognosehorizonten ableiten. Mit anderen Worten: Wenn erwartet wird, dass der gleitende Durchschnitt über die beiden Prognosehorizonte hinweg fällt, werden wir verkaufen. Andernfalls, wenn ein Anstieg zu erwarten ist, werden wir kaufen.
#Classical Target #V1 value HORIZON = 10 #Label the data data['Target 1'] = data['True MA C'].shift(-1) data['Target 2'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Wie erwartet, werden diese Änderungen die Form der Ausgabe unseres ONNX-Modells verändern. Daher müssen wir die Modelldefinition aktualisieren, um die neue Ausgangskonfiguration zu berücksichtigen.
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,2]))]
Dann speichern und laden Sie das überarbeitete Modell in unserer Anwendung neu.
onnx.save(onnx_proto,"EURUSD 2022-2025 R MFH V3.onnx") Die Umsetzung der Verbesserungen in MQL5
Jetzt laden wir die aktualisierte ONNX-Datei.//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R MFH V3.onnx" as const uchar onnx_proto[];
Nach dem Laden definieren wir die neue Modellform.
if(!onnx_model.DefineOnnxOutputShape(0,2,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); }
Jetzt nehmen wir alle notwendigen Anpassungen vor, um die Vorhersagen zu interpretieren. Es ist wichtig zu betonen, dass wir in diesem Stadium nicht mehr die Vorhersagen des Modells mit dem tatsächlichen Wert des Indikators vergleichen. Stattdessen orientieren wir uns ausschließlich an der impliziten Steigung zwischen den kurz- und langfristigen Prognosen.
if(onnx_model.Predict()) { onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } }
Für diejenigen, die in der Praxis mitmachen, empfehle ich, eine klare Dateihierarchie zu haben. Auf meiner lokalen Workstation habe ich für jede Version der Anwendung einen eigenen Ordner angelegt. Dies trägt zur Aufrechterhaltung guter Arbeitsstandards bei und macht es einfach, bei Bedarf auf frühere Versionen zurückzugreifen.
Abbildung 16: Die Beibehaltung einer klaren Dateistruktur ist wichtig, wenn iterative Verbesserungen an einer Anwendung vorgenommen werden.
Sobald die entsprechende Version der Anwendung fertig ist, führen wir unsere Tests mit demselben Backtest-Fenster wie zuvor durch.
Abbildung 17: Backtests der dritten Version unserer Anwendung während des Testzeitraums zur Bewertung der von uns vorgenommenen Änderungen
Die sich daraus ergebende Kapitalkurve zeigt eine hervorragende Verbesserung im Vergleich zu unseren ersten Ergebnissen. Der Aufwärtstrend ist jetzt viel ausgeprägter und dominanter als zu Beginn dieser Analyse. Darüber hinaus erreicht die Anwendung nun neue Höchststände, die bei einer direkten Vorhersage künftiger Kursniveaus bisher unerreichbar waren. Obwohl die Gleichgewichtskurve nach wie vor eine gewisse Volatilität aufweist und eine vollständige Stabilisierung noch nicht erreicht wurde, ist der Wachstumspfad insgesamt eindeutig stärker.
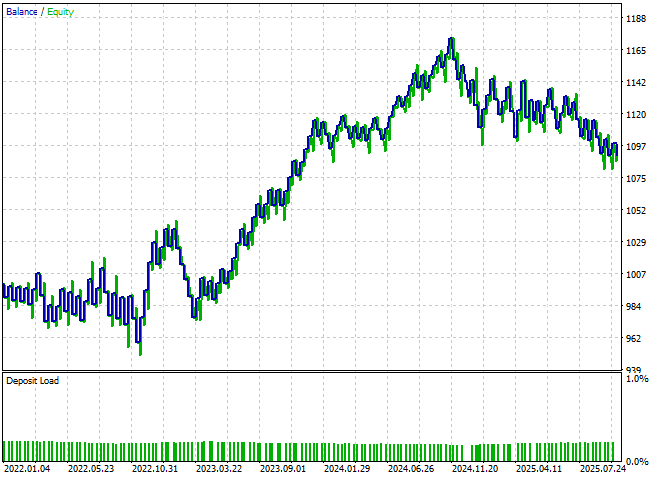
Abbildung 18: Unsere neue Kapitalkurve zeigt, dass unsere Anwendung jetzt neue Höchststände erreicht, die wir vorher nicht erreichen konnten.
Wenn wir uns die detaillierten Ergebnisse ansehen, sehen wir wesentliche Verbesserungen: Das System hat sich von einem anfänglichen Verlust von 24 Einheiten zu einem Gewinn von 90 Einheiten entwickelt – eine bemerkenswerte Veränderung. Dies ist besonders beeindruckend, da wir weder die Komplexität der Strategie erhöht noch die Modellierungsarchitektur verändert haben. Alle bisher erzielten Fortschritte beruhen ausschließlich darauf, dass wir bessere methodische Lösungen gefunden und solche verworfen haben, die unseren Zielen nicht mehr dienlich sind.
Ein genauerer Blick auf die Verteilung des Handels gibt weitere Aufschlüsse. Die aktualisierte Version der Anwendung führt nun deutlich mehr Verkäufe aus und behebt damit eine der größten Schwächen der Vorgängerversion, die sich schwer tat, Verkaufschancen zu erkennen. Das Modell klassifiziert nun Verkäufe mit einer Genauigkeit von etwa 62 %, obwohl es nach wie vor leicht verzerrt ist – es werden etwa doppelt so viele Kaufpositionen wie Verkaufspositionen platziert. Dies fordert uns zu größeren Anstrengungen auf, indem wir uns die Frage stellen: Hat sich die Leistung zwar erheblich verbessert, aber gibt es noch Raum für weitere Verbesserungen?
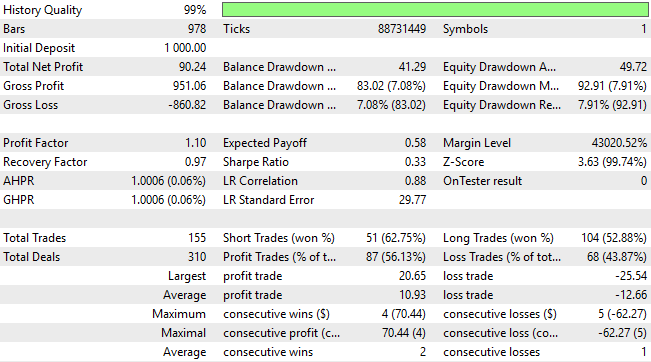
Abbildung 19: Eine detaillierte Analyse der Ergebnisse, die wir mit der dritten Version unserer Handelsanwendung erzielt haben
Suche nach weiteren Verfeinerungen
Wir sind nun bereit, unsere Handelsanwendung weiter zu verbessern. Nach einigem Nachdenken kam ich zu dem Schluss, dass wir bessere Ergebnisse erzielen könnten, wenn wir unserem Modell eine detailliertere Beschreibung der aktuellen Marktlage geben würden. Um dies zu erreichen, habe ich mehrere neue Merkmale in unseren Datensatz aufgenommen, wodurch sich die Gesamtzahl der Eingabevariablen auf 23 erhöht. Alle 23 Funktionen werden von den Skripten, die am Anfang dieses Artikels bereitgestellt werden, vollständig erfasst.
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
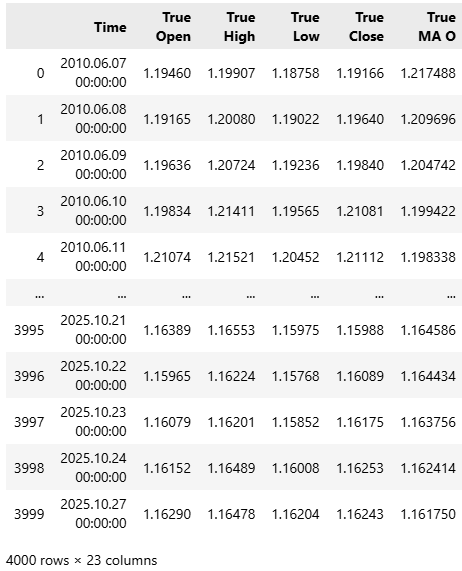
Abbildung 20: Unsere aktualisierten Marktdaten umfassen insgesamt 23 Spalten
Mit diesen Ergänzungen können wir nun untersuchen, wie sich die Korrelationsstruktur der Daten verändert hat. Vergleicht man die neue Heatmap mit der früheren, die in Abbildung 3 dargestellt ist, so fallen die Unterschiede auf. Wenn wir uns dieses Mal auf die beiden Vorhersageziele konzentrieren, können wir ein viel zuverlässigeres und strukturierteres Korrelationsmuster zwischen den Zielen und den Eingaben beobachten. Im Gegensatz zu Abbildung 3 – wo die Zielvariablen schwache oder inkonsistente Beziehungen zu den Eingaben aufwiesen – ist die neue Heatmap deutlich heißer, was auf stärkere und aussagekräftigere Abhängigkeiten innerhalb der Daten hinweist.
Diese Verbesserung ist sinnvoll. Wie sich der Leser vielleicht erinnert, werden die gleitenden Durchschnittswerte, die wir jetzt prognostizieren, direkt von den Preisniveaus abgeleitet. Daher ist eine starke Korrelation zwischen den gleitenden Durchschnitten und den Inputs sowohl zu erwarten als auch wünschenswert, da der gleitende Durchschnitt im Wesentlichen eine gewichtete Summe vergangener Preise ist.
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 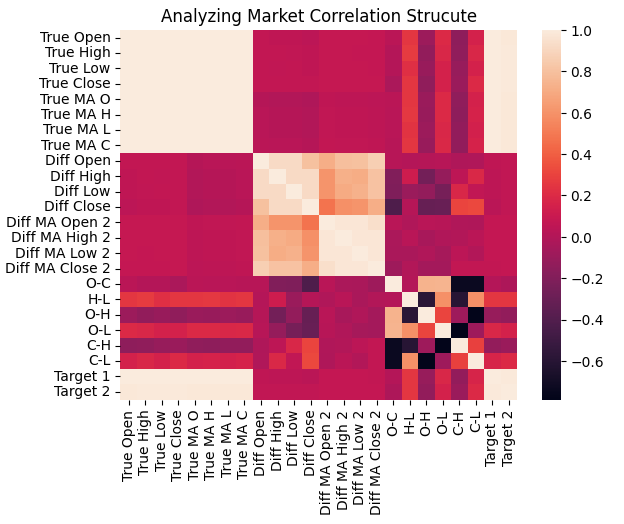
Abbildung 21: Unsere aktualisierten Marktdaten weisen stärkere Korrelationsniveaus auf als die, mit denen wir in Abbildung 3 begonnen haben
Wenn wir jedoch das Spektrum der Eigenwerte analysieren, die sich aus der Korrelationsmatrix dieses neuen Datensatzes ergeben, ergibt sich ein komplexeres Bild. In Abbildung 4, die den früheren Datensatz darstellt, haben wir ungefähr zwei dominante Eigenwerte beobachtet, wobei ein dritter Eigenwert nur leicht über dem Durchschnitt liegt. Dies bedeutete, dass das System zuvor zwei starke Ausdrucksformen hatte und eine dritte, die relativ unbedeutend war.
In der aktualisierten Darstellung des Marktes – nach Hinzufügung der neuen Merkmale – finden wir nun vier Eigenwerte über dem durchschnittlichen Schwellenwert. Dies ist eine kritische Feststellung. Dies deutet darauf hin, dass unser angereicherter Merkmalsatz zusätzliche dominante Ausdrucksformen oder, einfacher ausgedrückt, ausgeprägtere Marktregime eingeführt hat, was zwar eine umfassendere Beschreibung des Marktes ermöglicht, aber auch eine Herausforderung mit sich bringt: Die Daten weisen nun einen höheren Grad an struktureller Komplexität auf, was eine zuverlässige Modellierung erschweren kann. Das System, das wir zu modellieren versuchen, weist nun mehr Regime und dynamische Verhaltensweisen auf als zuvor.
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
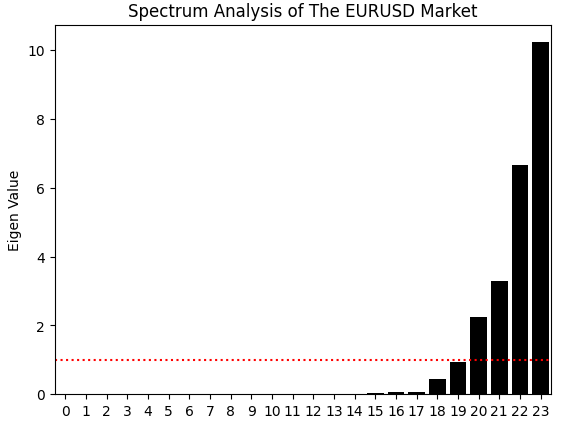
Abbildung 22: Leider scheinen auch die Marktdaten immer komplexer zu werden und konkurrierende Ausdrucksformen zu haben
Wir gehen jedoch so vor, dass wir unsere Eingangsvariablen von den Zielvariablen trennen.
X = data.iloc[:,1:-2].columns y = ['Target 1','Target 2']
Wir definieren die aktualisierte Eingabeform für das Modell und
initial_types = [('float_input',FloatTensorType([1,len(X)]))] final_types = [('float_output',FloatTensorType([1,2]))]
speichern schließlich das neu trainierte Modell in einer Datei.
onnx.save(onnx_proto,"EURUSD 2022-2025 R V4.onnx") Für die Leser, die sich für die genaue Konfiguration interessieren: Das neue Modell hat jetzt 22 Eingabefunktionen.
len(X)
22
Die Umsetzung unserer Verbesserungen
Sobald das Modell trainiert ist, laden wir es in unsere Handelsanwendung.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V4.onnx" as const uchar onnx_proto[];
Und denken Sie daran, die ONNX-Modelldefinition entsprechend zu aktualisieren.
if(!onnx_model.DefineOnnxInputShape(0,1,22)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); }
Die wichtigste Änderung besteht darin, wie die Anwendung mit neu eingehenden Preisdaten umgeht. Jedes der 22 Merkmale muss nun definiert und einzeln in einen Float-Typ umgewandelt werden, um Präzisionsverluste durch automatisches Abschneiden der Daten zu vermeiden. Abgesehen von diesen Anpassungen der Eingaben bleibt die Logik für die Interpretation der Vorhersagen des Modells unverändert.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,HORIZON*2,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,HORIZON*2,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,HORIZON*2,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,HORIZON*2,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); onnx_model.DefineInputValues(8,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(9,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(10,(float) iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(11,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(12,(float) ma_o_reading[0] - ma_o_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(13,(float) ma_h_reading[0] - ma_h_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(14,(float) ma_l_reading[0] - ma_l_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(15,(float) ma_reading[0] - ma_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(16,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(17,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(18,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(19,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(20,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(21,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
Anschließend führen wir den Backtest über das gleiche Auswertungsfenster wie zuvor durch.
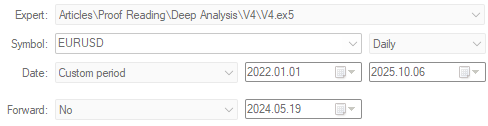
Abbildung 23: Ausführung der vierten Version unserer Handelsanwendung über denselben Backtestzeitraum
Leider zeigt die sich daraus ergebende Kapitalkurve wenig bis gar keine Verbesserung. Die Leistung scheint weitgehend unverändert zu sein, und der endgültige Kontostand ist sogar zurückgegangen.
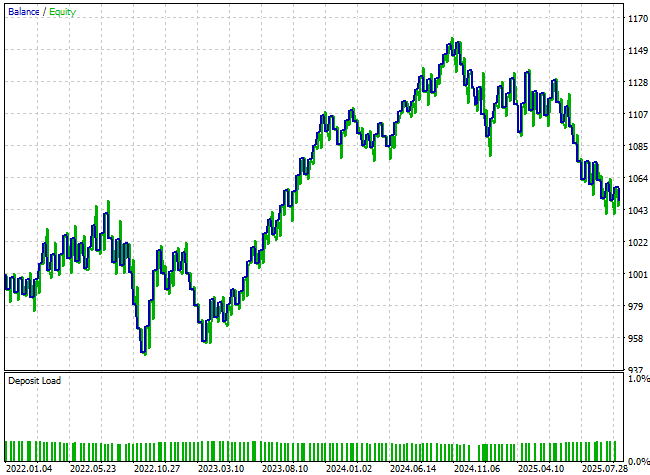
Abbildung 24: Die neuen Merkmale, die wir hinzugefügt haben, scheinen nur wenig dazu beigetragen zu haben, dass unser Modell die Marktlage besser einschätzen kann.
Ein genauerer Blick auf die detaillierten Leistungsstatistiken zeigt, dass wir uns nun einer Region mit abnehmendem Ertrag nähern. Sowohl der Gesamtnettogewinn als auch die Gesamtgenauigkeit der Anwendung sind gesunken. Es sei daran erinnert, dass eines unserer Hauptziele darin bestand, dem System zu helfen, mehr Verkaufsgelegenheiten zu erkennen, da die frühere Version fast doppelt so viele Kaufpositionen wie Verkaufspositionen ausführte. Dieses Ungleichgewicht besteht jedoch nach wie vor – das Modell bevorzugt nach wie vor Käufe, und die gewünschte Verbesserung der Verkäufe ist noch nicht eingetreten.
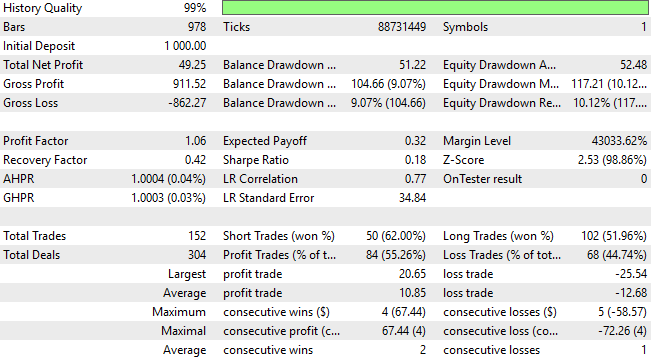
Abbildung 25: Unsere detaillierten Ergebnisse zeigen, dass wir mit unseren neuen Merkmalen möglicherweise einen abnehmenden Nutzen erzielen
Letzter Verbesserungsversuch
Die 22 Merkmale, die wir eingeführt haben, können in einem nichtlinearen Verhältnis zueinander stehen. Infolgedessen war das starre lineare Modell, auf das wir uns bisher gestützt haben, möglicherweise nicht flexibel genug, um diese komplexen Beziehungen zu erfassen. Um dieses Problem zu lösen, definieren wir nun ein leistungsfähigeres nichtlineares Modell, nämlich einen Random Forest. Bei einem Random Forest wird ein Ensemble aus mehreren Entscheidungsbäumen gebildet und dann der Durchschnitt ihrer Ergebnisse ermittelt. Auf diese Weise können nicht-lineare Interaktionen erlernt und subtilere Abhängigkeiten innerhalb der Daten erfasst werden, die von linearen Modellen möglicherweise übersehen werden.
from sklearn.ensemble import RandomForestRegressor
Wir werden nun unser neues nicht-lineares Modell auf denselben Datensatz anwenden.
model = RandomForestRegressor(random_state=0,max_depth=5,n_estimators=50) model.fit(data.loc[:,X],data[y])
Schließlich exportieren wir sie in eine ONNX-Datei.
onnx.save(onnx_proto,"EURUSD 2022-2025 RFR V5.onnx") Umsetzung der Änderungen in MQL5
Wir laden das aktualisierte ONNX-Modell, das wir gerade exportiert haben.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 RFR V5.onnx" as const uchar onnx_proto[];
Sobald das Modell geladen ist, führen wir die Anwendung erneut in demselben Backtest-Fenster wie zuvor aus.

Abbildung 26: Bewertung der endgültigen Version unserer Handelsanwendung über denselben Testzeitraum
Leider zeigen die Ergebnisse, dass sich die Rentabilität im Vergleich zur Vorgängerversion zwar leicht verbessert hat, die Performance aber weiterhin deutlich unter den optimalen Ergebnissen liegt, die mit Version 3 der Handelsstrategie erzielt wurden. Wenn wir außerdem die Verteilung der Verkäufe und Käufe analysieren, stellen wir fest, dass sich die Signalqualität erneut verschlechtert hat. Das Verhältnis von Verkäufen zu Käufen hat sich verschlechtert, was darauf hindeutet, dass das Modell erneut seine Fähigkeit verliert, Verkaufsgelegenheiten effektiv zu identifizieren. Mit anderen Worten, wir scheinen härter zu arbeiten, nur um ein einfacheres Modell – das in Version 3 implementierte – einzuholen, das mit weniger Komplexität stärkere und stabilere Ergebnisse erzielte.
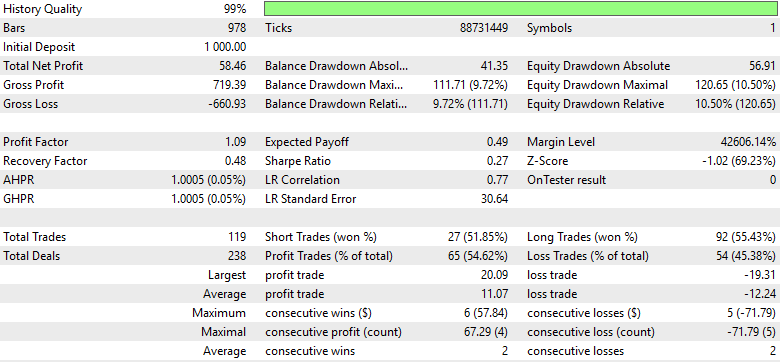
Fiugre 27: Eine detaillierte Analyse der endgültigen Version unserer Handelsanwendung zeigt, dass wir uns von unseren Spitzenleistungen entfernt haben
Wenn wir uns die Kapitalkurve dieser neuesten Version ansehen, stellen wir keine nennenswerte Verbesserung der Stabilität oder Rentabilität fest. Dieses Ergebnis stimmt uns zuversichtlich, dass wir wahrscheinlich einen natürlichen Haltepunkt bei der Erforschung immer komplexerer Modelle erreicht haben. Daher ist es vielleicht am sinnvollsten, zu Version 3 der Anwendung zurückzukehren und diese als stabile Basis für zukünftige Experimente zu verwenden.
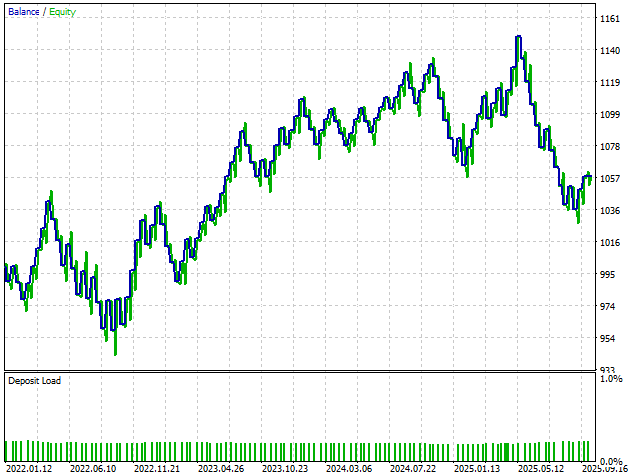
Abbildung 28: Die endgültige Kapitalkurve, die wir aus der endgültigen Version unserer Handelsanwendung erhalten haben, deutet darauf hin, dass die dritte Version optimal war
Schlussfolgerung
Nach der Lektüre dieser Diskussion gewinnt der Leser ein tieferes Verständnis für die wahren Herausforderungen, die die Rentabilität und das Potenzial statistischer Modelle im Finanzwesen begrenzen. Entscheidend ist, dass der Erfolg weniger von der Komplexität der Modelle als vielmehr von der Methodik abhängt, d. h. davon, wie die Modelle konzipiert, angewendet und interpretiert werden.
Das Streben nach den fortschrittlichsten Modellen oder den größten Datensätzen ist keine Garantie für bessere Ergebnisse; es kann sogar zu unnötigen Kosten und abnehmenden Erträgen führen. Ein einfaches Modell, das intelligent angewandt wird, ist oft besser als ein komplexes Modell, das auf fehlerhaften Annahmen beruht. Die Leistung des Modells wird nicht nur durch die Mathematik bestimmt, sondern auch durch die Ziele, den Bewertungsrahmen und die Designentscheidungen, die dem Modell auferlegt werden. In vielen Fällen ist die Methodik selbst das versteckte Hindernis – der „Elefant im Raum“.
Jahrzehntelang hat sich die Finanzmodellierung auf feste Beziehungen und starre Prognosehorizonte verlassen, obwohl die Märkte von Natur aus dynamisch sind. Wenn Modelle scheitern, liegt das oft nicht daran, dass sie nicht lernen können, sondern daran, dass sie mit der falschen Aufgabe betraut oder mit einem ungeeigneten Ansatz unterrichtet werden.
Diese Diskussion unterstreicht, wie wichtig sorgfältiges Experimentieren, Sorgfalt und methodische Strenge bei der Anwendung des maschinellen Lernens im Finanzbereich sind. Wenn der Fortschritt ins Stocken gerät, ist die Lösung nicht immer ein größeres Modell oder mehr Daten; manchmal liegt der Schlüssel einfach darin, ein besseres Ziel zu finden oder den Prozess zu verfeinern. Eine durchdachte Methodik und nicht die bloße Komplexität erschließt das wahre Potenzial statistischer Modelle.
| Dateiname | Beschreibung der Datei |
|---|---|
| Benchmark.mq5 | Die Benchmark-Version unserer Anwendung war nicht gewinnbringend, aber es wurden Leistungskennzahlen festgelegt, die wir übertreffen sollten. |
| V1.mq5 | Die erste Version unserer Anwendung wurde nach klassischen Techniken entwickelt, konnte aber im Backtest keine profitablen Ergebnisse erzielen. |
| V2.mq5 | Die zweite Version unserer Anwendung löste sich von den klassischen Modellierungstechniken und modellierte den gleitenden Durchschnittsindikator mit geringem Erfolg. |
| V3.mq5 | Die beste Version der Anwendung, die wir in unserer Diskussion entdeckten, modellierte den gleitenden Durchschnittsindikator für mehrere Horizonte und handelte die implizite Steigung. |
| V4.mq5 | Die vierte Version der Anwendung hatte das gleiche Ziel wie die dritte Version, verwendete aber mehr Daten. Diese Änderung der Methodik schränkte unsere Rentabilität ein. |
| V5.mq5 | In der endgültigen Version unserer Anwendung wurde ein nichtlinearer Lerner zur Modellierung des größeren Datensatzes eingesetzt. Sie war zwar rentabler als die vierte Version unserer Anwendung, erreichte aber nicht die Leistung der dritten Version. |
| Deep_Analysis_V5.ipynb | Das Jupyter-Notebook, das wir für die Analyse der Marktdaten verwendet haben, die wir im Rahmen unserer Diskussion abgerufen haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20090
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.