
Von der Grundstufe bis zur Mittelstufe: Arrays und Zeichenketten (III)

Einführung
Der hier dargestellte Inhalt ist ausschließlich für Bildungszwecke bestimmt. Es sollte unter keinen Umständen zu einem anderen Zweck als zum Erlernen und Beherrschen der vorgestellten Konzepte betrachtet werden.
Im vorigen Artikel, „Von der Grundstufe zur Mittelstufe: Arrays and Zeichenketten (II)“, habe ich auf sehr einfache und verständliche Weise gezeigt, wie Sie das bis dahin vermittelte Wissen bereits anwenden können. Ziel war es, zu zeigen, wie man zwei einfache Arten von Lösungen erstellt, von denen viele annehmen, dass sie weitaus fortgeschrittenere Kenntnisse erfordern. Alles, was in diesem Artikel behandelt und implementiert wird, kann jedoch auch von jedem Anfänger in der Programmierung erreicht werden. Vorausgesetzt natürlich, dass sie ein wenig Kreativität an den Tag legen und die bisher vorgestellten Konzepte anwenden.
Aber obwohl das, was dort gezeigt wurde, tatsächlich funktioniert und ohne große Schwierigkeiten erstellt werden kann, gibt es ein kleines Detail, das viele Anfänger behindern kann. Und dieses Detail steht in unmittelbarem Zusammenhang mit der in diesem Artikel beschriebenen Anwendung.
Viele von Ihnen haben sich vielleicht schon gewundert: „Wie war es möglich, aus zwei scheinbar einfachen Texten oder Phrasen ein Passwort zu generieren?“ Ich konnte nicht begreifen, warum das funktionierte. Auch wenn ich die Idee verfolgte und den Code verstand, ergab das für mich keinen Sinn. Die Wahrheit ist, liebe Leserin, lieber Leser, dass es Aspekte der Programmierung gibt, die für Nicht-Programmierer nicht viel Sinn ergeben. Ein solches Beispiel ist genau das, was in diesem Artikel gemacht wurde, wo wir Textmanipulationen mit sehr einfacher und grundlegender Mathematik durchgeführt haben.
Da diese Art von Konzept bei verschiedenen Programmieraufgaben weit verbreitet ist, glaube ich, dass es sich lohnt, genauer zu erklären, warum es funktioniert. Dies wird Ihnen zweifellos helfen, wie ein Programmierer zu denken und nicht nur wie ein Nutzer. Daher kann das Hauptthema dieses Artikels - Arrays - etwas verschoben werden. Dennoch werden wir uns auch hier mit Arrays befassen, wenn auch auf einfachere Art und Weise. Beginnen wir also mit dem ersten Thema, um zu verstehen, warum das, was im vorherigen Artikel gezeigt wurde, tatsächlich funktioniert.
Übersetzen der Werte
Eine der häufigsten Aufgaben beim Programmieren ist das Übersetzen und Bearbeiten von Informationen oder Datenbanken. Beim Programmieren geht es im Wesentlichen um dieses Thema. Wenn Sie darüber nachdenken, Programmieren zu lernen, aber nicht verstehen, dass der Zweck einer Anwendung darin besteht, Daten zu erstellen, die ein Computer interpretieren kann, und diese Daten dann in Informationen zu übersetzen, die Menschen verstehen können, sind Sie auf dem falschen Weg. Es wäre besser, aufzuhören und von vorne zu beginnen. Denn in Wahrheit basiert die Programmierung auf diesem einfachen Prinzip. Wir haben Informationen, die für den Computer verständlich gemacht werden müssen. Sobald der Computer ein Ergebnis liefert, müssen wir dieses Ergebnis in etwas übersetzen, das wir verstehen können.
Computer können hervorragend mit Einsen und Nullen arbeiten. Aber sie sind völlig nutzlos, wenn es um die Verarbeitung anderer Informationen geht. Das Gleiche gilt für den Menschen: Wir sind furchtbar schlecht darin, Reihen von Einsen und Nullen zu interpretieren, aber wir können die Bedeutung eines Wortes oder einer Grafik leicht verstehen.
Lassen Sie uns nun ein wenig einfacher über einige Konzepte sprechen. In den Anfängen der Computertechnik verfügten die ersten Prozessoren über einen OpCode-Satz - eine Reihe von Anweisungen für die Arbeit mit Dezimalwerten. Ja, liebe Leserin, lieber Leser, die frühesten Prozessoren konnten verstehen, was eine 8 oder eine 5 ist. Diese Befehle waren Teil des BCD-Satzes, der es den Prozessoren ermöglichte, mit Zahlen in einer für den Menschen sinnvollen Weise zu arbeiten, jedoch unter Verwendung binärer Logik.
Im Laufe der Zeit wurden die BCD-Befehle jedoch nicht mehr verwendet. Es erwies sich als weitaus komplizierter, eine Schaltung zu entwerfen, die dezimale Berechnungen durchführen kann, als Berechnungen im Binärformat durchzuführen und das Ergebnis dann in Dezimalzahlen umzuwandeln. Infolgedessen wurde die Verantwortung für die Durchführung dieser Übersetzung auf den Programmierer übertragen.
Damals war der Umgang mit Fließkommazahlen praktisch ein Chaos, ein echter „Obstsalat“. Aber das ist ein Thema für ein anderes Mal, denn mit den bisher vorgestellten Werkzeugen und Konzepten wäre es noch nicht möglich, die Funktionsweise von Gleitkommasystemen zu erklären. Bevor ich dazu komme, muss ich noch ein paar weitere Konzepte behandeln.
Ein wichtiger Hinweis: Das BCD-System wird auch heute noch verwendet, wenn auch nicht in der Weise, wie Sie es sich vielleicht vorstellen. In einem späteren Artikel werden wir uns mit dem BCD-System befassen.
Aber kommen wir zurück zum eigentlichen Thema. Zu dieser Zeit entstanden die ersten Übersetzungsbibliotheken, die Dezimalwerte in Binärwerte umwandelten und umgekehrt. Andere Zahlenbasen wie Hexadezimal und Oktal, die in bestimmten Anwendungen häufiger vorkommen, werden ebenfalls unterstützt.
Na gut. Dies bringt uns zu dem, was in den vorherigen Artikeln besprochen wurde, wo ich gezeigt habe, dass MQL5 Funktionen enthält, die es uns ermöglichen, diese Art von Übersetzung durchzuführen. In allen Fällen basiert die Transformation auf einer Zeichenkette, die entweder Eingabe oder Ausgabe ist. Diese Zeichenfolge stellt die für den Menschen lesbaren Informationen dar. Die binären Daten werden dann zur Verarbeitung an den Computer gesendet. Obwohl diese Bibliotheken gut funktionieren und sehr praktisch sind, verbergen sie doch einen Großteil des zugrundeliegenden Wissens darüber, wie Daten direkt bearbeitet werden können. Aus diesem Grund bringen manche Programmierkurse keine Programmierer hervor - sie bringen Leute hervor, die sich für Programmierer halten, aber nicht verstehen, wie die Dinge unter der Haube funktionieren.
Da MQL5 uns ein gewisses Maß an kreativer Freiheit gibt, können wir etwas Ähnliches wie eine dieser Bibliotheken erstellen (ausschließlich für Ausbildungszwecke). Es ist jedoch wichtig zu beachten, dass jede Bibliothek, die ohne eine Low-Level-Sprache erstellt wird, nicht schneller oder effizienter als die Standardbibliothek ist. Und wenn ich Low-Level-Sprache sage, meine ich Programmierung in C oder C++. Da diese beiden Sprachen Code erzeugen können, der reinem Assembler sehr ähnlich ist, ist nichts schneller als sie. Was wir hier erforschen werden, dient also ausschließlich zu Bildungszwecken.
Großartig. Nach dieser ersten Erklärung wollen wir nun einen kleinen Übersetzer bauen. Mit dem bisher erworbenen Wissen wird dies eine recht einfache Aufgabe sein. In diesem Übersetzer werden wir zunächst binäre Werte in hexadezimale oder oktale Werte umwandeln, da diese einfacher zu übersetzen sind und weniger Operationen erfordern. Wir werden also den folgenden Code als Ausgangspunkt verwenden.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
Code 01
Wenn wir das Codefragment 01 ausführen, zeigt das Terminal die in Abbildung 01 dargestellte Ausgabe an. Achten Sie auf die hier verwendeten Formatangaben. Werden andere Bezeichner verwendet, wird die Ausgabe unterschiedlich ausfallen. Probieren Sie dies später aus, um besser zu verstehen, wie diese Art der Formatierung funktioniert.
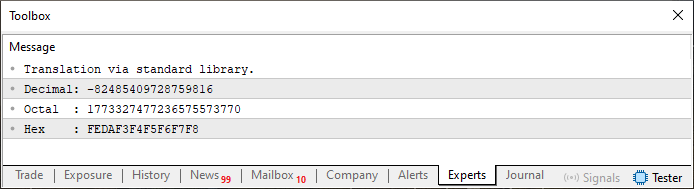
Abbildung 01
Wie Sie sehen können, ist dies recht einfach, praktisch und unkompliziert. Aber wie schafft die Standardbibliothek das? Nun, das ist die „Magie“, die wir gleich erforschen werden, lieber Leser. Zuvor müssen Sie jedoch ein weiteres wichtiges Konzept verstehen: die Formatierung der angezeigten Informationen. Ja, hinter dieser Ausgabe verbirgt sich eine Formatierung. Um die Sache einfach zu halten, möchte ich Sie bitten, eine bestimmte Tabelle im Internet nachzuschlagen. Diese Tabelle ist sehr leicht zu finden: Sie heißt ASCII-Tabelle. Der Einfachheit halber stelle ich im Folgenden eine Version dieser Tabelle zur Verfügung. Es gibt noch weitere Versionen mit mehr Details, aber das, was Sie in Abbildung 02 sehen, ist für unsere Zwecke hier ausreichend.
Abbildung 02
Der Teil der Tabelle, der uns interessiert, ist der Abschnitt mit den druckbaren Zeichen, der sich in der Mitte von Abbildung 02 befindet. Die linke Seite enthält Sonderzeichen, während die rechte Seite je nach Tabellenversion variieren kann; sie könnte sogar von unserer Anwendung selbst definiert werden. Dies ist jedoch im Fall von MQL5 nicht möglich, da die Erstellung dieses Teils den Zugriff auf bestimmte Teile der Hardware erfordern würde, was MQL5 nicht zulässt und was auch in den meisten Hochsprachen eingeschränkt ist. Diese Art der Anpassung ist in der Regel nur möglich, wenn man mit Low-Level-Sprachen wie C oder C++ arbeitet. Ich erwähne dies nur, damit Sie wissen, dass die Symbole auf der rechten Seite der Tabelle je nach Implementierung unterschiedlich sein können.
Nun gut, aber warum ist die ASCII-Tabelle für uns hier in MQL5 so wichtig? In Wahrheit ist die ASCII-Tabelle nicht nur hier wichtig, sondern für jeden, der Daten manipulieren will, unerlässlich. Es gibt noch weitere Kodierungstabellen, wie UTF-8, UTF-16, ISO 8859 usw. Jeder von ihnen hat unterschiedliche Werte und Symbole für verschiedene Zwecke. Aber in MQL5 verlassen wir uns normalerweise auf die ASCII-Tabelle, außer in bestimmten Fällen, die eine der anderen erfordern. Auf diese Ausnahmen werden wir in einem späteren Beitrag eingehen.
Um Informationen übersetzen zu können, müssen Sie, liebe Leserin, lieber Leser, einen wichtigen Punkt verstehen. Schauen wir uns noch einmal Abbildung 02 an. Um einen binären Wert in einen hexadezimalen Wert umzuwandeln, benötigen wir die Ziffern 0 bis 9 und die Buchstaben A bis F.
Anhand der ASCII-Tabelle sehen Sie, dass die Ziffer 0 dem Dezimalwert 48 entspricht. Von da an erhöht sich jede weitere Ziffer um eins. Wenn wir also zum Beispiel sechs Stellen nach vorne gehen, was der Ziffer 6 entspricht, verwenden wir den Wert 54. Haben Sie es? Das Gleiche gilt für Buchstaben. Der Großbuchstabe A entspricht dem Wert 65. Dies gibt uns einen Ausgangspunkt. Denken Sie daran, dass der Buchstabe A im Hexadezimalsystem für den Wert 10 steht, B für 11 und so weiter bis hin zu F, das für 15 steht.
Es ist alles ganz einfach. Das Einzige, worauf man achten muss, ist, dass es zwischen der Ziffer 9 und dem Buchstaben A einige Symbole in der ASCII-Tabelle gibt, die übersprungen werden müssen. Andernfalls kann Ihre hexadezimale Zeichenfolge seltsame oder unerwünschte Zeichen enthalten. Dies geschieht, wenn Sie direkt auf die ASCII-Tabelle zugreifen, ohne die Zwischenwerte herauszufiltern. Auch wenn dies möglich ist, werden wir für unsere Zwecke einen etwas anderen Ansatz wählen. Das liegt daran, dass das Ziel darin besteht, zu erklären, warum der im vorherigen Artikel gezeigte Code funktioniert.
Um dieses Ziel zu erreichen, sollten wir uns den neuen Code ansehen. Sie können es gleich unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
Code 02
Wenn wir das Codefragment 02 ausführen, sieht die Terminalausgabe wie folgt aus.
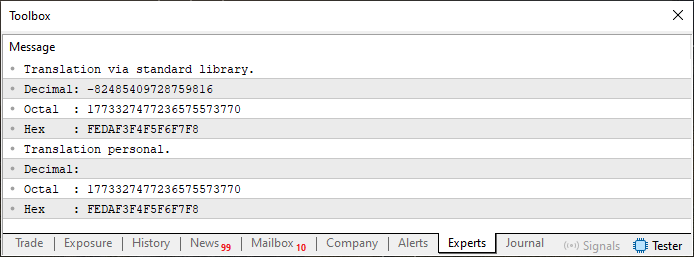
Abbildung 03
Da der größte Teil dieses Codes für diejenigen, die den Inhalt der vorangegangenen Artikel verfolgt und studiert haben, recht einfach zu verstehen ist, werde ich nur die Vorgänge in den Zeilen 37 und 41 hervorheben. Dies ist auf die Verwendung des AND-Operators zur Isolierung bestimmter Bits zurückzuführen. Es mag kompliziert erscheinen, aber es ist viel einfacher, als es aussieht.
Konzentrieren wir uns zunächst nur auf Zeile 37. Wir wissen, dass ein oktaler Wert nur Ziffern von 0 bis 7 enthält. Im Binärformat wird die Zahl 7 als 111 dargestellt. Wenn wir also eine bitweise UND-Verknüpfung mit einem beliebigen Wert durchführen, wird das Ergebnis eine Zahl zwischen 0 und 7 sein. Die gleiche Logik gilt für Zeile 41, mit dem Unterschied, dass in diesem Fall der resultierende Wert zwischen 0 und 15 liegen wird.
Schauen Sie sich nun die Zeile 26 an. In dieser Zeile werden die Zeichen festgelegt, die bei der Erstellung der Ausgabe verwendet werden sollen. In MQL5 ist ein String eine besondere Art von Array. Wenn wir also auf die in Zeile 26 definierte Zeichenkette so zugreifen, wie es in den Zeilen 37 und 41 geschieht, rufen wir im Wesentlichen nur ein einziges der Zeichen in dieser Zeichenkette ab. Zu diesem Zeitpunkt wird die Zeichenfolge also NICHT als Zeichenfolge, sondern als Array aufgerufen.
Aufgrund der Funktionsweise der Indizierung beginnt die Zählung der Elemente immer bei Null. Diese Null steht jedoch nicht für die Größe der Zeichenkette, sondern für das erste Zeichen in ihr. Wenn die Zeichenkette leer ist, ist ihre Länge gleich Null. Wenn es einen Inhalt gibt, ist die Länge größer als Null. Dennoch beginnt der Index immer noch bei Null.
Ich verstehe, dass dies auf den ersten Blick verwirrend und völlig unlogisch erscheinen mag. Aber je vertrauter Sie mit der Verwendung von Arrays werden, desto natürlicher wird Ihnen diese Art von Logik vorkommen, liebe Leserin, lieber Leser.
Allerdings fehlt in diesem Codefragment 02 noch ein Element: die Behandlung von Dezimalwerten. Um mit Dezimalwerten richtig umgehen zu können, brauchen wir eine Funktion, die ich noch nicht erklärt habe - nämlich wie man mit ihr arbeitet. Aber um Sie nicht ohne eine angemessene Erklärung zurückzulassen, lassen Sie uns erst einmal eine einfache Annahme machen. Es macht keinen Sinn, den Code unnötig zu verkomplizieren, nur um die perfekte Darstellung der Daten zu gewährleisten. Außerdem können wir so, wie es derzeit implementiert ist - auch wenn eine Funktion fehlt, die später behandelt wird -, bereits jeden Integer-Wert mit einer Breite von bis zu 64 Bit mit fast vollständiger Genauigkeit konvertieren. Sobald wir die fehlende Funktion erforschen, die die Erstellung von Vorlagen und die Verwendung von typename beinhaltet, können wir jeden Wert mühelos umwandeln. Bis dahin sollten wir uns nur auf die einfacheren Aspekte konzentrieren.
Beachten Sie nun, dass der in Zeile sechs deklarierte Typ eine Ganzzahl mit Vorzeichen ist. Aus diesem Grund müssen wir prüfen, ob der Wert negativ ist oder nicht. Um die Dinge jedoch nicht unnötig kompliziert zu machen, nehmen wir vorerst an, dass alle Werte vorzeichenlose Ganzzahlen sind. Mit anderen Worten: Negative Werte werden nicht dargestellt. Unter dieser Voraussetzung können wir den Code ändern und prüfen, ob die Werte korrekt angezeigt werden. Dies wird durch die unten dargestellte Implementierung erreicht.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
Code 03
Als zusätzlichen Bonus habe ich in Codefragment 03 auch die Umwandlung des Wertes in seine binäre Darstellung hinzugefügt. Es ist genau so einfach wie in den vorherigen Fällen. In jedem Fall sieht die Ausgabe von Code 03 nach der Ausführung wie folgt aus.
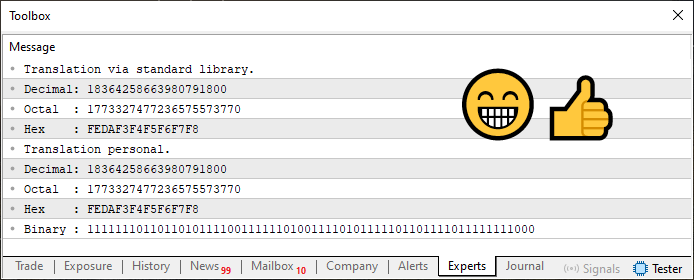
Abbildung 04
Und nun, liebe Leserinnen und Leser, achten Sie bitte ganz genau darauf, was hier passiert. Dies ist vielleicht der wichtigste Punkt, der in diesem gesamten Artikel erörtert und aufgezeigt wird. Zwischen Code 03 und Code 02 gibt es fast keinen Unterschied. Wenn Sie jedoch Abbildung 03 und Abbildung 04 vergleichen, werden Sie etwas anderes feststellen.
Der Unterschied liegt in dem Wert, der für die Übersetzung mit der Standardbibliothek angezeigt wird. Sehen Sie sich den DECIMAL-Wert genau an. Sie werden sehen, dass das anders ist. Dies macht jedoch keinen Sinn, da die Zeile sechs sowohl in Code 03 als auch in Code 04 genau gleich ist. Wo liegt also die Diskrepanz, die dazu geführt hat, dass der Wert auf so unerwartete Weise gedruckt wurde?
Nun, liebe Leserin, lieber Leser, der Unterschied findet sich genau in Zeile neun. Schauen Sie sich die Zeile neun von Code 03 und dann Code 04 sehr genau an. Schon diese winzige Änderung reicht aus, um den Wert, der nach dem in Zeile 6 deklarierten Typ negativ sein sollte, in einen positiven Wert zu verwandeln. Es gibt eine Möglichkeit, diese Art von Problem zu lösen. Aber wie bereits erwähnt, ist dafür ein Konzept erforderlich, das bisher noch nicht erklärt worden ist.
Bis dahin sollten Sie beim Drucken von Werten auf dem Terminal vorsichtig sein. Ein kleines Versehen kann dazu führen, dass Sie die berechneten Werte falsch interpretieren. Deshalb ist es wichtig, das Gezeigte zu studieren und zu üben. Das bloße Lesen von Dokumentationen oder Artikeln wie diesen reicht nicht aus, um Sie zu einem fähigen Programmierer zu machen. Sie müssen alles, was präsentiert wird, aktiv üben und verinnerlichen.
Trotz dieser geringfügigen Diskrepanz können Sie sehen, dass die Umrechnung des Wertes in seine dezimale Darstellung absolut korrekt ist. Und beachten Sie, dass die für diese Umrechnung erforderlichen Berechnungen recht einfach sind. In Zeile 35 verwenden wir den Modulus-Operator %, um den Rest der Division durch 10 zu erhalten, der angibt, welches Zeichen aus szChars verwendet werden soll. In Zeile 36 wird dann der Wert von arg aktualisiert. Dazu wird arg einfach durch 10 geteilt. Der daraus resultierende Wert wird im nächsten Schritt verwendet. Auf diese Weise wandeln wir einen binären Wert in einen für Menschen lesbaren Wert um.
Auf der Grundlage dieser Erklärung lassen sich die im vorigen Artikel gezeigten Code-Beispiele nun viel besser verstehen. Dennoch können wir das bisher Gezeigte noch verbessern. Dazu verwenden wir den letzten Codefragment aus dem vorherigen Artikel - den Code, in dem Arrays direkter verwendet wurden. Aber um richtig voranzukommen, sollten wir ein neues Thema beginnen.
Einstellen der Passwortlänge
Um etwas zu besprechen, das wir in Code 06 ändern können (wie im vorigen Artikel gezeigt), müssen wir zunächst einen Blick auf dieses Stück Code werfen. Es ist unten dargestellt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Code 04
Beginnen wir mit der folgenden Tatsache. Es gibt zwei Arten von Arrays, die wir verwenden können: ein statisches Array und ein dynamisches Array. Ob ein Array statisch oder dynamisch ist, hängt davon ab, wie es deklariert wird. Dies hat nichts mit der Verwendung des Schlüsselworts static in der Deklaration zu tun. Da dieses Thema zu komplex ist, um es auf einmal zu erklären, werde ich eine kurze Zusammenfassung geben, damit Sie Code 04 verstehen können.
Ein dynamisches Array wird wie in Zeile 15 gezeigt deklariert. Beachten Sie, dass auf den Variablennamen, der in diesem Fall „psw“ lautet, eine öffnende und schließende Klammer [] folgt, in der sich nichts befindet. Dies ist ein dynamisches Array. Dynamisch zu sein bedeutet, dass wir seine Größe zur Laufzeit festlegen können. Wir müssen dies sogar tun, denn der Versuch, auf ein Element eines nicht zugewiesenen dynamischen Arrays zuzugreifen, wird als Fehler betrachtet und führt dazu, dass Ihr Code sofort abgebrochen wird. Aus diesem Grund haben wir in Zeile 18 den Punkt, an dem wir genügend Speicher zuweisen, um Daten im Array zu speichern.
Denken Sie daran: Eine Zeichenkette ist eine besondere Art von Array. Und wenn sie nicht als konstant deklariert ist, ist eine Zeichenkette ein dynamisches Array, das keine manuelle Speicherzuweisung erfordert. Der Compiler selbst fügt die notwendigen Routinen hinzu, um dies automatisch und ohne unser direktes Zutun zu erledigen. Da wir hier aber keine Zeichenkette, sondern ein reguläres Array verwenden, müssen wir explizit angeben, wie viel Speicher wir benötigen. Und genau hier liegt ein kleines, aber wichtiges Detail.
Wenn wir während der Ausführung von Zeile 18 in Code 04 die Länge des zu generierenden Kennworts angeben, können wir die Dinge sehr effektiv steuern. Gleichzeitig können wir das Passwort, das erstellt wird, besser verwalten. Dazu sind ein paar kleine Änderungen am Code 04 erforderlich. Diese Änderungen sind unten zu sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Code 05
Achten Sie nun genau auf die folgende Tatsache. In Zeile 8 von Code 05 übergeben wir ein neues Argument an die Funktion in Zeile 11. Dasselbe Argument wird in Zeile 18 verwendet, um festzulegen, wie viele Zeichen das Kennwort enthalten soll: in diesem Fall acht Zeichen. Wenn Sie jedoch versuchen, Code 05 auszuführen, schlägt dies fehl. Und der Grund liegt in Zeile 22. Der Grund dafür ist, dass wir in Zeile 6 eine geheime Phrase definieren, der mehr als acht Zeichen enthält. Da die Schleife in Zeile 19 nur dann anhält, wenn sie ein NULL-Symbol in der Zeichenkette szArg findet, die in Zeile 6 deklariert wurde, werden wir schließlich auf Zeile 22 stoßen, wo wir versuchen, auf eine ungültige Speicherposition zuzugreifen. Dies ist ein Fehler, und das Programm wird abstürzen.
Aber das ist eigentlich kein wirkliches Problem. Wir müssen nur entscheiden, ob wir die gesamte in Zeile 6 definierte Phrase oder nur einen Teil davon verwenden wollen, um das gewünschte achtstellige Passwort zu vervollständigen. Je nachdem, wie wir uns entscheiden, erhalten wir eine etwas andere Richtung, wie sich der endgültige Code verhalten wird. Deshalb ist es wichtig, dass man programmieren lernt. Ein Programmierer schlägt vielleicht eine bestimmte Lösung vor, die aber nicht unbedingt die beste für Sie ist. Durch Kommunikation kann jedoch ein gegenseitiges Verständnis erreicht werden. Wenn Sie in der Lage sind, einen Code zu schreiben, können Sie selbst entscheiden, was in Ihrem Fall am besten funktioniert, und sind nicht völlig von den Entscheidungen anderer abhängig.
Also gut, treffen wir folgende Entscheidung: Wir werden die geheime Phrase ganz verwenden. Aber gleichzeitig werden wir die Zeichenkette aus Zeile 13 in eine andere ändern - die Zeichenkette, die in einem früheren Artikel gezeigt wurde. Auf diese Weise erhalten wir etwas Interessanteres.
Bevor wir jedoch den eigentlichen Code schreiben, möchte ich, dass Sie zu Abbildung 02 aus dem vorigen Abschnitt zurückkehren und sich jeden Wert in dieser Tabelle, der in der in Zeile 6 deklarierten Zeichenfolge erscheint, genau ansehen. Fällt Ihnen an diesen Daten etwas Interessantes auf? Der Punkt ist, dass wir, wenn wir die gesamte Phrase aus Zeile 6 verwenden wollen, hier einen anderen Trick anwenden müssen. Denn wenn wir die Änderung wie im untenstehenden Code vornehmen, werden wir auf einige Probleme stoßen...
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
Code 06
Wir verwenden eigentlich nicht die ganze Phrase, sondern nur einen Teil davon. Tatsächlich verwenden wir nur die letzten acht Zeichen der in Zeile sechs definierten geheimen Phrase. Dies lässt sich bestätigen, wenn man den Code 06 ausführt und die Ergebnisse mit denen des vorherigen Artikels vergleicht, in dem dieselbe Phrase wie in Code 06 verwendet wurde.
Aber auch ohne die Ausführung von Code 06 zeigt eine einfache Analyse, dass Zeile 23 zwar nicht mehr zum Scheitern des Codes führt, aber kaum Auswirkungen hat. Das liegt daran, dass Zeile 24 uns dazu zwingt, den Wert des Kennworts ständig genau an der Stelle zu überschreiben, die als Kennwortgrenze definiert ist. Obwohl die Phrase in Zeile 6 alle diese Zeichen enthält, sieht es so aus, als ob nur acht davon tatsächlich existieren. Dies gibt uns ein falsches Gefühl der Sicherheit, wenn wir eine geheime Phrase erstellen.
Wie wir aus Abbildung 02 wissen, ist jedes Symbol durch einen Wert definiert, sodass wir mit Hilfe dieser Matrix eine Summe dieser Werte berechnen können. Auf diese Weise werden alle Symbole effektiv genutzt. Aber achten Sie auf ein wichtiges Detail, lieber Leser. Der maximale Wert, den wir im Array zuweisen können, wird durch den im Array selbst verwendeten Typ bestimmt. Ich werde im nächsten Artikel ausführlicher darauf eingehen. Jetzt können wir noch ein paar Anpassungen am Code vornehmen, wie unten gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
Code 07
Jetzt haben wir endlich etwas, das die geheime Phrase voll ausnutzt. Beachten Sie, dass nur minimale Änderungen am Code erforderlich waren. Zu den Änderungen gehört, dass in Zeile 20 angegeben wird, dass das Array mit einem bestimmten Wert initialisiert werden soll, der in diesem Fall Null ist. Sie können einen anderen Ausgangswert wählen, wenn Sie dies wünschen. Dies wird sich später als nützlich erweisen, vor allem, wenn Ihre geheime Phrase wiederholte Zeichen enthält.
Es gibt verschiedene Methoden, um zu vermeiden, dass demselben Symbol an verschiedenen Stellen derselbe Wert zugewiesen wird. Hierauf wird im nächsten Artikel näher eingegangen. Das entscheidende Detail befindet sich jedoch in Zeile 24. Jetzt summieren wir die Werte, was bedeutet, dass wir beide Phrasen vollständig ausnutzen. Es gibt jedoch ein Problem. Dies wird deutlich, wenn wir den Code ausführen.
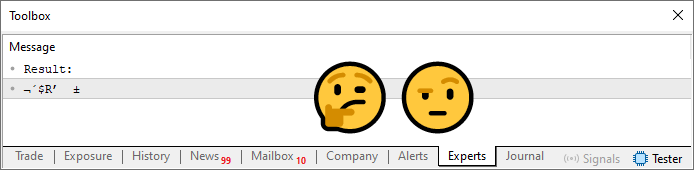
Abbildung 05
Wie würden Sie also dieses Passwort verwenden? Das ist nicht einfach, oder? Was hier passiert, ist, dass das Array Werte enthält, die durch die Summe berechnet werden, aber sie sind eingeschränkt. Wir müssen sicherstellen, dass diese berechneten Werte tatsächlich einem der Zeichen in der in Zeile 13 angegebenen Zeichenkette entsprechen. Um dies zu erreichen, müssen wir eine weitere Schleife hinzufügen. Die endgültige Version des Codes ist unten abgebildet.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Code 08
Nachdem wir die Schleife in Zeile 28 von Code 08 durchlaufen haben, erhalten wir ein Ergebnis, das Sie in der folgenden Abbildung sehen können.
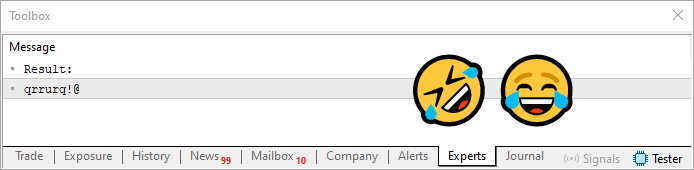
Abbildung 06
Das nenne ich eine glückliche Fügung. Ich hatte gerade darüber gesprochen, dass ein Kennwort wiederholte Zeichen enthalten könnte und wie wir das angehen könnten. Und zu unserer Freude stellte sich heraus, dass das Ergebnis wiederkehrende Zeichen enthielt. Das ist wirklich ein Glücksfall! (lacht)
Abschließende Schlussfolgerungen
In diesem Artikel haben wir teilweise untersucht, wie Binärwerte in andere Formate übersetzt werden. Wir haben auch erste Schritte unternommen, um zu verstehen, wie eine Zeichenkette wie ein Array behandelt werden kann. Darüber hinaus haben wir gelernt, wie wir einen sehr häufigen Fehler bei der Arbeit mit Arrays in unserem Code vermeiden können. Was wir hier gesehen haben, endete jedoch mit einem glücklichen Zufall, auf den wir im nächsten Artikel näher eingehen werden. Dort werden wir auch sehen, wie man solche Situationen in Zukunft verhindern kann. Wir werden auch unser Verständnis von Datentypen in Arrays weiter ausbauen. Bis bald!
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15461
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.