
От начального до среднего уровня: Массивы и строки (III)

Введение
Представленный здесь контент предназначен исключительно для образовательных целей. Не стоит его рассматривать в качестве приложения для чего либо другого, кроме изучения представленных концепций.
В предыдущей статье «От начального до среднего уровня: Массивы и строки (II)» я наглядно и доступно продемонстрировал, как можно применить полученные к этому моменту знания. Цель заключалась в создании двух довольно простых типов решений, чья реализация, по мнению многих, требует гораздо больше опыта и умений. Тем не менее, все увиденное и реализованное в этой статье может выполнить любой новичок в программировании. Конечно, в том случае, если проявит немного креативности и применит концепции, показанные до этого момента.
Однако, хоть все продемонстрированное ранее действительно работает и вполне осуществимо без особых трудностей, есть одна маленькая деталь, которая способна обескуражить многих новичков. И эта деталь имеет прямое отношение к приложению, представленному конкретно в этой статье.
Многие из вас наверняка задавались вопросом: как возможно сгенерировать пароль из двух, казалось бы, простых текстов или фраз? Трудно понять, как что-то подобное может работать, несмотря на следование общей идее и понятность кода, подобные вещи для некоторых бессмысленны. На самом деле, дорогой читатель, в программировании есть вещи, которые не имеют особого смысла для непосвященных. Одна из таких вещей — именно то, что было проделано в той статье, где мы манипулировали текстом, используя очень простую и базовую математику.
Поскольку подобные концепции и подходы широко используются в различных видах программирования, я считаю целесообразным более подробно объяснить, почему они работают. Без сомнения, это поможет вам начать думать как программист, а не как обычный пользователь. Так что, вероятней всего, основная тема этой статьи — массивы — будет немного отложена. Мы все же поговорим о массивах в статье, но не особенно углубляясь. Итак, давайте сначала разберем, почему то, что мы увидели в предыдущей статье, работает.
Перевод значений
Одной из наиболее распространенных задач в программировании является перевод и обработка информации или баз данных, и программирование имеет к этому непосредственное отношение. Если вы думаете о том, чтобы научиться программировать, но не понимаете или еще не усвоили, что целью приложения является создание данных, которые могут интерпретироваться компьютером, с последующим их преобразованием в понятную человеку информацию, вы идете по неверному пути. Лучше остановиться и начать с нуля. Потому что на самом деле, программирование целиком и полностью основано на этом простом принципе. У нас есть информация, и нам нужно сделать так, чтобы компьютер смог ее понять. Как только компьютер выдает результат, мы должны преобразовать его так, чтобы он стал понятен человеку.
Компьютеры очень хороши, оперируя нулями и единицами, но совершенно бесполезны, если им приходится обрабатывать какой-либо другой тип информации. То же самое происходит и с людьми: они плохо умеют интерпретировать кучу нулей и единиц, но прекрасно понимают значение слов или графических изображений.
Теперь нам будет проще рассуждать на некоторые темы. На заре компьютерной эры первые процессоры включали в свой набор инструкций, известный как OpCode, коды, предназначенные для работы с десятичными значениями. Да-да, дорогой читатель, первые процессоры могли понимать, что такое 8 или 5. Эти инструкции были частью набора BCD, поскольку они позволяли процессорам использовать числа, имеющие смысл для нас, людей, но с использованием бинарной логики.
Однако, со временем, эти инструкции BCD вышли из употребления. Поскольку обучение или, вернее, создание схемы, способной выполнять десятичные вычисления, было гораздо сложнее, чем проводить вычисления в бинарной системе, а затем преобразовывать их в десятичные, выполнение и реализация этого перевода стали обязанностью программистов.
Вначале был настоящий «фруктовый салат» в отношении обработки чисел с плавающей точкой. Но мы коснемся этого в другой раз, так как используя существующие инструменты, рассмотренные нами до сего момента, невозможно объяснить, как работает система с плавающей точкой. Прежде чем приступить к этому, мне нужно познакомить вас с еще несколькими концепциями.
Важная деталь: эта система BCD все еще используется, но не так, как вы могли бы себе представить. В следующей статье мы исследуем кое-что, связанное с этой системой BCD.
Возвращаясь же к нашему вопросу, именно так появились первые библиотеки для перевода десятичных значений в бинарные и наоборот. Можно также использовать и другие базы данных, например, шестнадцатеричную и восьмеричную, которые являются наиболее распространенными, хотя и ориентированы, как правило, на более конкретные приложения.
Отлично, на этом этапе мы подошли к тому, что было показано в предыдущих статьях, где я демонстрировал, что в MQL5 есть функции, позволяющие выполнять подобное преобразование. Во всех случаях преобразование основано на строке, которая является либо входной, либо выходной. Эта строка представляет информацию, которую мы, люди, понимаем. А бинарная часть отправляется для обработки компьютеру. Однако, хотя эти библиотеки очень удобны и работают отлично, они скрывают большую часть знаний о том, как фактически можно манипулировать данными. По этой причине курсы, на которых преподают определенные языки, на самом деле готовят не программистов, а людей, которые лишь считают себя таковыми, но не понимают, как все устроено изнутри.
Поскольку MQL5 дает нам некоторую творческую свободу, мы можем создать нечто похожее на одну из этих библиотек, хоть бы даже исключительно в образовательных целях. Однако, важно отметить следующее: библиотека, созданная без использования языка низкого уровня, не будет быстрее или эффективнее стандартной библиотеки языка. И когда я говорю о языке низкого уровня, я имею в виду программирование на языках C или C++. Эти два языка позволяют создавать код, очень похожий на чистый ассемблер, и ничто не будет быстрее их. Поэтому то, что мы здесь увидим, носит исключительно образовательный характер.
Отлично. Учитывая это первоначальное объяснение, давайте создадим небольшой переводчик. Использование знаний, уже полученных к текущему моменту, делает эту задачу довольно простой. В этом переводчике мы сначала преобразуем бинарные значения в шестнадцатеричные или восьмеричные, поскольку эти преобразования самые простые и не требуют большого количества операций. Для этого, в качестве отправной точки, мы будем использовать код, показанный ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
Код 01
Когда мы запустим этот код, в терминале будет сгенерировано то, что можно увидеть на изображении 01. Обратите внимание, какие спецификаторы форматов здесь использованы. Если использовать другие, результат будет другим. Поэкспериментируйте с этим позже, чтобы лучше понять, как оно работает.
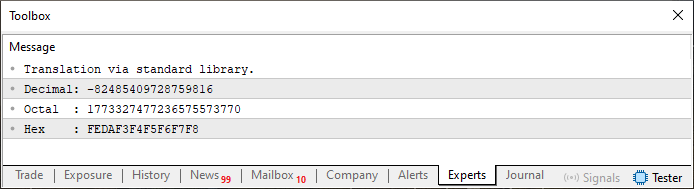
Рисунок 01
Обратите внимание, что это довольно просто, практично и недвусмысленно. Но как это удается стандартной библиотеке? Ну вот, это и есть «магия», которую мы сейчас рассмотрим, дорогой читатель. Но прежде нам нужно разобрать кое-что еще: форматирование отображаемой информации. И да, за этой информацией стоит определенный формат. Чтобы все сделать проще и не усложнять, я хочу, чтобы вы поискали в интернете одну таблицу. Эта таблица, которую очень легко найти, известна как таблица ASCII. Для удобства, я приведу пример этой таблицы ниже. Существуют и другие, содержащие больше информации, но того, что показано на изображении 02, будет достаточно, чтобы понять, что мы собираемся делать.
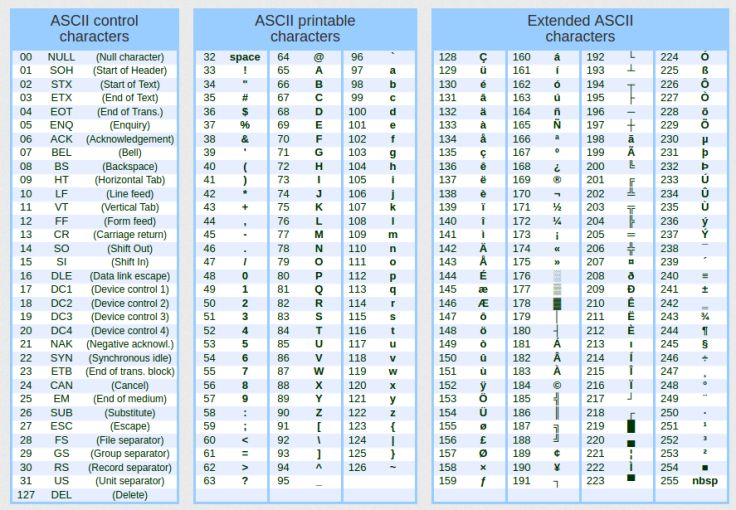
Рисунок 02
Нас интересует таблица с печатными символами, то есть та, что находится в центральной части изображения 02. Левая часть содержит специальные символы, в то время как правая — варьируется от таблицы к таблице, и может даже быть создана с помощью нашего собственного приложения. Но не в случае с MQL5, поскольку создание этой таблицы справа требует доступа к определенным частям оборудования, что не разрешено в MQL5 и недоступно в большинстве языков. В основном, этот тип задач выполняется теми, кто программирует на языках низкого уровня, таких как C или C++. Однако я упоминаю об этом только для того, чтобы вы знали: между правыми частями таблицы, показанной на изображении, могут быть различия.
Итак, почему эта таблица ASCII так важна для нас в MQL5? На самом деле она важна не только для нас, но и для всех тех, кто хочет манипулировать данными. Существуют и другие таблицы с другими значениями и символами, такие как UTF-8, UTF-16, ISO 8859 и т. д. Каждая из них предназначена для определенных целей. Однако здесь, в MQL5, мы обычно можем использовать таблицу ASCII, за исключением определенных случаев, когда нам могут понадобиться другие таблицы. В определенный момент в будущем это будет объяснено.
Очень хорошо, дорогой читатель, теперь, для того, чтобы переводить информацию, мне нужно, чтобы вы поняли одну вещь. Посмотрите на изображение 02. Чтобы перевести бинарное значение в шестнадцатеричное, мы должны использовать цифры от 0 до 9 и буквы от A до F.
Глядя на таблицу, мы видим, что цифра ноль соответствует числу 48, и что начиная с этой точки, каждое последующее число соответствует цифре. Например, если мы продвинемся на шесть позиций, что будет цифрой шесть, мы используем значение 54. Понятно? То же самое происходит и с буквами. Заглавная буква А имеет значение 65. И вот, у нас уже есть отправная точка. Однако вы должны помнить, что заглавная буква A в шестнадцатеричной системе представляет собой число десять и так далее. При этом буква F соответствует числу пятнадцать.
По сути, это довольно просто и практично. Единственное, с чем нужно быть осторожным в этом случае, это символы, существующие между цифрой 9 и буквой A, которые необходимо пропустить. Это позволит нам избежать появления странных символов в шестнадцатеричной строке. Если мы хотим осуществить прямой доступ к таблице ASCII, мы можем сделать это таким образом. Однако, хоть это и возможно, для наших целей мы используем несколько иной подход. Цель — объяснить, почему код, показанный в предыдущей статье, работает.
Итак, имея это в виду, давайте рассмотрим код, который будет использован. Его можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
Код 02
При выполнении этого кода 02, результат отображаемый в терминале, показан ниже.
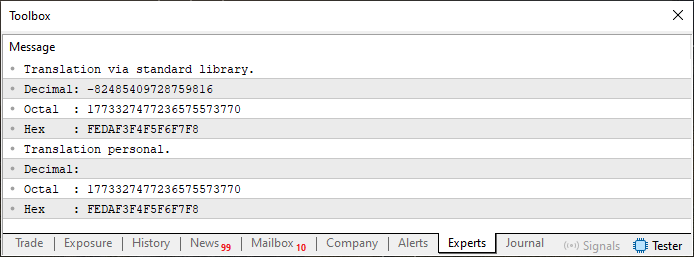
Рисунок 03
Поскольку большая часть этого кода совершенно понятна тем, кто следит за серией и изучает содержание статей, я сосредоточусь только на том, что происходит в строках 37 и 41. Это связано с использованием оператора AND для изоляции определенных битов. Это может показаться сложным, но на самом деле все гораздо проще, чем кажется.
Давайте рассмотрим только строку 37. Мы знаем, что восьмеричное значение будет иметь только цифры в диапазоне от нуля до семи. В бинарной системе число семь представляется следующим образом – 111. То есть, если мы выполним побитовую операцию AND с любым значением, то получим результат в диапазоне от нуля до семи. То же самое происходит в строке 41, за исключением того, что там значение изменится от нуля до пятнадцати.
Теперь посмотрим на строку 26. Здесь у нас есть символы, которые будут использоваться при генерации информации. Поскольку в MQL5 строка является особым типом массива, обращаясь к цепочке, содержащейся в строке 26, таким образом, как это делается в строках 37 и 41, мы фактически будем искать ОДИН и только ОДИН из символов, присутствующих в строке. Таким образом, в этот момент ДОСТУП К СТРОКЕ осуществляется не как к строке, а как массиву.
Из-за определенных проблем нумерация элементов всегда начинается с нуля. Однако, этот ноль НЕ ОТОБРАЖАЕТ размер строки, а лишь первый отображаемый в ней символ. Если символов нет, длина строки будет равна нулю. Если есть хоть один, длина будет больше нуля. Но это не меняет того факта, что нумерация всегда будет начинаться с нуля.
Я знаю, что поначалу это может показаться очень запутанным и нелогичным. Однако, по мере того, как вы будете знакомиться с использованием массивов, подобные вещи будут становиться для вас все более и более естественными, дорогой читатель.
Однако в этом коде 02 еще есть один нереализованный аспект, относящийся конкретно к десятичным значениям. Чтобы правильно решить вопрос с десятичными значениями, нам нужно использовать некий ресурс, который мы еще не разбирали, уметь с ним работать. Чтобы не оставлять вас без должного объяснения, давайте сделаем небольшое предположение. Нет смысла излишне усложнять код, чтобы обеспечить точное представление данных. Тем более, что отсутствующий ресурс, который будет объяснен позже, в том виде, в котором он реализован, уже позволяет преобразовывать любое целочисленное значение длиной до 64 бит с точностью почти 100%. Однако, когда мы разберемся с этим ресурсом, а именно с созданием template и typename, мы сможем без проблем преобразовывать любое значение. А пока давайте сосредоточимся на более простых вещах.
Обратите внимание, что тип, объявленный в строке шесть, представляет собой целое число со знаком. По этой причине нам следует проверить, может ли значение быть отрицательным. Однако, чтобы без необходимости ничего не усложнять, давайте предположим, что все значения будут беззнаковыми целыми числами. То есть, представить отрицательные значения будет невозможно. Применив это предположение к нашему коду, мы можем изменить его, чтобы проверить, правильно ли отображаются значения. Это делается с помощью кода, представленного ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
Код 03
В качестве дополнительного бонуса в этот код 03 я также добавил преобразование значения в его бинарное представление. Как и в других случаях, здесь все так же просто. Как бы там ни было, результат выполнения этого кода 03 приводится ниже.
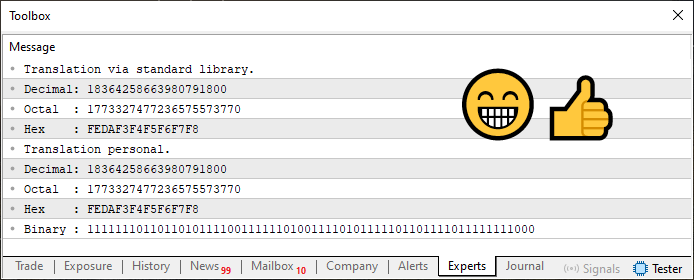
Изображение 04
Теперь, дорогой читатель, обратите пристальное внимание на то, что происходит здесь. Это, пожалуй, самое важное, что будет сказано и показано в этой статье. Различий между кодами 03 и 02 практически нет. Однако, если вы посмотрите на изображение 03 и сравните его с изображением 04, вы заметите определенную разницу.
Она состоит в значении перевода, выполняемого стандартной библиотекой. Посмотрите на ДЕСЯТИЧНОЕ значение. Заметьте, что оно отличается. Однако это не имеет смысла, поскольку строка шесть, как в коде 03, так и в коде 04, абсолютно идентична. Так в чем же разница, из-за которой значение было напечатано совершенно иначе, чем ожидалось?
Ну что ж, дорогой читатель, разницу можно увидеть в девятой строке. Посмотрите очень внимательно на эту строку в коде 03, а затем в коде 04. Сам факт наличия этого минимального отличия приводит к тому, что значение, которое согласно объявлению типа в строке шесть, должно быть отрицательным, становится положительным. Существует способ устранения такого рода проблем, но, как я уже упоминал, необходимо объяснить, как использовать другой ресурс, который нами еще не был рассмотрен.
До тех пор будьте осторожны при вводе значений в терминал. Это связано с тем, что любая небрежность может привести к ошибке в интерпретации вычисленных значений. Поэтому важно изучать и применять на практике то, что вы видите. Чтения документации или этих статей недостаточно для того, чтобы стать квалифицированным программистом. Необходимо практиковать и изучать все представленное.
Хорошо, исключая эту небольшую деталь, вы можете видеть, что перевод значения в десятичное представление абсолютно корректен. Более того, расчет, необходимый для выполнения преобразования, довольно прост. В строке 35 мы используем символ процента % для получения остатка от деления на 10, который указывает, какой символ следует использовать из числа присутствующих в szChars. Сразу после этого, в строке 36, мы корректируем значение arg, разделив его на 10, и результатом является значение, которое будет использоваться в следующей итерации. Таким образом мы преобразуем бинарное значение в понятное человеку.
Исходя из этого объяснения, я полагаю, что теперь коды, показанные в предыдущей статье, будут интерпретированы верно. И тем не менее, мы можем немного улучшить ситуацию по сравнению с тем, что было показано ранее. Для этого мы воспользуемся последним кодом, представленным в предыдущей статье, то есть кодом, который использует массивы наиболее прямым способом. Однако, чтобы сделать это должным образом, перейдем к новой теме.
Настройка ширины пароля
Итак, чтобы начать говорить о том, что мы можем сделать в коде 06, показанном в предыдущей статье, давайте сначала посмотрим на него здесь. И для этого воспроизведем этот код ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Код 04
Давайте начнем с объяснения следующего факта. Существует два типа массивов, которые мы можем использовать: статический массив и динамический массив. Способ объявления массива определяет, является ли тот статическим или динамическим. Этот вопрос не имеет ничего общего с использованием ключевого слова static в объявлении, или с тем фактом, используется сам массив или нет. Поскольку эта тема довольно сложна для объяснений на скорую руку, я ограничусь лишь кратким изложением, чтобы вы смогли понять код 04.
Динамический массив объявляется, как показано в строке 15. Обратите внимание, что здесь указано имя переменной, в данном случае psw, а сразу за ним — пара пустых скобок, внутри которых нет никакой информации. Это динамический массив. Поскольку он динамичен, мы можем определить его размер во время выполнения. На самом деле, это необходимо сделать, поскольку попытка доступа к любой позиции НЕВЫДЕЛЕННОГО динамического массива считается ошибкой и приведет к немедленному завершению работы вашего кода. По этой причине в строке 18 находится место, где мы выделяем достаточно памяти для хранения данных в массиве.
Помните, что строка — это особый вид массива. И строка, если она не является константой, всегда представляет собой динамический массив, для которого нам не нужно выделять память. Компилятор сам добавляет необходимые процедуры для решения этой задачи, без необходимости нашего прямого вмешательства. Однако, поскольку здесь мы используем не строку, а обычный простой массив, нам нужно указать, какой объем памяти нам необходим или желателен. И вот здесь кроется маленький секрет.
Если во время выполнения строки 18 кода 04, указать размер пароля, который мы хотим создать, то можно ограничить его довольно интересным способом. В то же время, это позволит нам лучше поработать над паролем, который необходимо сгенерировать. С учетом этого, возникает необходимость внесения в этот код небольших изменений, которые показаны ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Код 05
Теперь обратите пристальное внимание на следующий факт. В строке 8 кода 05 мы передаем новый аргумент функции из строки 11. Этот же самый аргумент используется в строке 18 для определения количества символов в пароле, которое в данном случае равно восьми. Однако, если вы попытаетесь запустить этот код, он завершится ошибкой в строке 22. Это связано с тем, что в строке шесть мы создаем секретную фразу, содержащую более восьми символов. Поскольку цикл в строке 19 будет завершен только тогда, когда символ NULL будет найден в строке szArg, которая в данном случае является именно строкой, объявленной в строке 6; в строке 22 будет предпринята попытка доступа к недопустимой позиции в памяти. Это приведет к ошибке, и код не будет выполнен.
Однако на самом деле это не проблема. Все, что нам нужно сделать, это решить, хотим ли мы использовать всю фразу, определенную в шестой строке, или только ее часть, чтобы заполнить нужные восемь символов. В зависимости от принятого нами решения, подход к окончательному коду будет немного отличаться. Вот почему важно научиться программировать, ведь решение, предложенное одним программистом, может другого не удовлетворить. Однако, с помощью общения можно достичь взаимопонимания. Тем не менее, если вы не умеете программировать, вы не сможете реализовать лучшее для себя решение и будете полностью зависеть от кого-то, кто примет его за вас.
Итак, давайте примем следующее решение: мы будем использовать всю секретную фразу. В то же время, мы заменим содержимое строки 13 на другое, увиденное в предыдущей статье. Таким образом, мы получим нечто более интересное.
Однако перед тем, как приступить к созданию кода, я хочу, чтобы вы вернулись к изображению 02 из предшествующей темы и посмотрели на каждое из значений, присутствующих в таблице, которые включены в содержимое, объявленное в строке шесть. Отмечаете ли вы что-то интересное в этих данных? Дело в том, что, решив использовать все предложение, объявленное в шестой строке, нам придется использовать какой-то другой ресурс. Все потому, что если мы внесем изменения, показанные в следующем коде...
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
Код 06
...мы не будем использовать всю фразу, а только последние восемь символов, присутствующих в секретной фразе, определенной в строке шесть. В этом можно убедиться, выполнив код 06 и сравнив результаты с теми, что мы видели в предыдущей статье, где была использована та же фраза, что и в коде 06.
Но даже не выполняя код 06, а просто анализируя, можно увидеть, что хотя строка 23 больше не вызывает сбой кода, она будет иметь не большой эффект. Это связано с тем, что строка 24 заставляет нас всегда обновлять значение пароля в точно определенной позиции, которую мы установили в качестве предела. Таким образом, даже если фраза в шестой строке содержит все эти символы, в конечном итоге будет так, как будто на самом деле существуют только восемь из них. Это вызывает у нас ложное ощущение безопасности при создании секретной фразы.
Теперь, как нам известно на основании изображения 02, каждый символ определяется значением, поэтому мы можем использовать этот массив для создания суммы этих значений. Таким образом, будут использованы все символы. Но здесь обратите внимание на одну деталь, мой дорогой читатель. Максимальное значение, которое мы можем присвоить массиву, определяется используемым в нем типом. Я расскажу более подробно об этом в следующей статье. Но пока, мы можем внести еще несколько изменений в код, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
Код 07
Теперь да, у нас есть нечто, использующее всю секретную фразу. Обратите внимание, что код потребовалось изменить совсем чуть-чуть. Среди изменений выделим то, что в строке 20 мы указываем, что массив инициализируется определенным значением: в данном случае — нулем. При желании, вы можете установить другое начальное значение. Это понадобится нам в дальнейшем, особенно если у вас есть секретная фраза, в которой один и тот же символ используется более одного раза.
Для подобной проблемы существует несколько различных методов, позволяющих предотвратить ситуацию, когда один и тот же символ присваивает одно и то же значение разным позициям. В следующей статье мы поговорим об этом подробнее. Но весь вопрос заключается именно в строке 24. Теперь мы складываем значения и, таким образом, полностью используем обе фразы. Однако, и здесь есть проблема. Она наблюдается при выполнении кода.
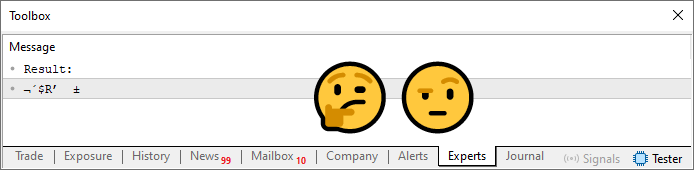
Изображение 05
Так как же вы сможете использовать этот пароль? Трудно, не правда ли? А происходит следующее: массив содержит значения, вычисленные с помощью ограниченного суммирования. Нам необходимо сделать так, чтобы вычисленные значения указывали на одно из значений, присутствующих в содержимом, объявленном в строке 13. Для этого, нам необходимо будет использовать еще один цикл. Полученный код показан ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Код 08
Теперь, пройдя цикл, который находится в строке 28 этого кода 08, мы получим то, что вы можете видеть чуть ниже.
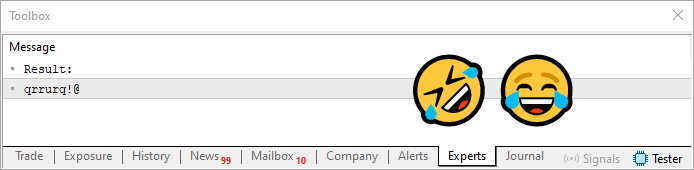
Рисунок 06
Вот это я могу назвать счастливым совпадением. Я говорил о пароле, который может содержать повторяющиеся символы, и о том, как можно с этим справиться. И вот, на наше счастье, результат содержит только повторяющиеся символы. Вот уж действительно большая удача! (смех).
Заключительные выводы
В этой статье частично показано, как бинарные значения переводятся в другие типы значений. Мы также сделали первые шаги к пониманию того, как можно строку обрабатывать как массив. Кроме того, мы увидели, как избежать очень распространенного типа ошибок при использовании массивов в коде. Однако то, что мы здесь увидели, завершилось счастливым совпадением, которое будет более подробно объяснено в следующей статье. Из нее вы также узнаете, как предотвратить повторение подобных ситуаций в будущем. А еще, мы немного основательней коснемся типов данных в массивах. До скорой встречи!
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15461
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования