价格行为分析工具包开发(第 35 部分):预测模型训练与部署

引言
在上一篇文章中,我们搭建了一套稳定的数据流转通道:通过 MQL5 脚本将历史行情数据流式传输至 Python,并将其保存至本地磁盘。上篇内容止步于数据接入层,仅完成了市场 K 线数据的采集、序列化与重新加载,并未进一步开展模型拟合训练工作。
本文将承接上文内容,继续往下拓展。突破数据存储环节,依次讲解以下核心流程:
- 基于已接入的行情数据训练预测模型;
- 针对不同交易品种,对模型进行打包与缓存处理;
- 将模型部署至轻量化 REST API 服务,供 MQL5 智能 EA 实时调用查询。
整套方案融合了Python 机器学习生态的算法优势与MT5 平台的执行速度。EA 负责与市场交互,Python 服务端则承担特征工程、模型推理以及按需进行周期性再训练。
本文所指的可训练模型,泛指所有能够通过数据优化内部参数的算法模型。针对表格化特征数据集,可选用基于 Scikit-learn 的传统机器学习算法,如梯度提升、支持向量机;若业务需要更复杂的网络结构,则可采用 TensorFlow、PyTorch 等深度学习框架搭建模型。Python 凭借丰富的第三方库、简洁的语法、繁荣的生态以及活跃的技术社区,成为该流程环节的首选开发语言。
下表汇总了整套成型系统中各组件的分工职责:
| 系统组件 | 流程职责 |
|---|---|
| MQL5 EA | 采集实时 K 线与账户状态;发起特征数据请求;接收 API 返回的交易信号并执行下单操作。 |
| Python 数据接入脚本 | 接收 MT5 传输的分块历史数据,完成数据清洗并以 Parquet 格式存储。 |
| 特征工程模块 | 将原始 OHLC 行情数据,转换为技术指标特征与统计量化特征。 |
| 模型训练模块 | 为每个交易品种拟合或更新专属模型;通过 joblib 完成模型序列化保存。 |
| Flask REST 服务 | 提供 /predict、/upload_history 等接口服务;搭建内存模型缓存,实现毫秒级响应。 |
本文结构如下:
让我们开始深入探讨。
数据采集流程回顾
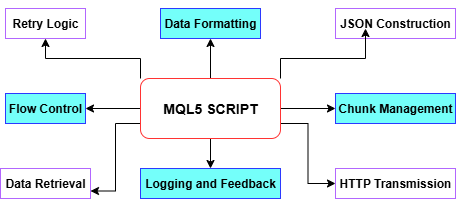
正如上一篇文章所述,我们的历史数据采集脚本,打通了从 MT5 到 Python 的全流程数据流转:脚本首先通过 CopyRates 函数读取目标历史 K 线数据,接着解析时间戳、最高价、最低价、收盘价并存入数组,再通过 BuildJSON 将每段数据组装为 JSON 数据包。为适配 MT5 的WebRequest请求尺寸限制,脚本会自动将数据切分为合适大小的数据包块;必要时自动减半分片尺寸,直至设定的最小分片阈值。随后通过 PostChunk 函数将每一分片数据发送至 Python 服务接口,同时内置重试机制与超时控制。整个过程会在 EA 日志面板记录每一步运行状态与报错信息;一旦程序异常则安全退出,全部数据上传完成后给出完成确认,为后续的尖峰检测流程打下了坚实基础。
可参考下方流程图,拆解 MQL5 脚本内部各核心函数的工作逻辑。
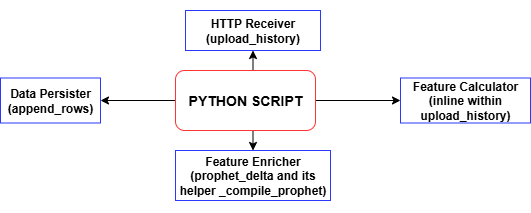
每当 MQL5 脚本上传一段历史 K 线分片数据时,Python 服务的 upload_history 接口会即时计算所有技术特征与交易标签,再调用 append_rows 将数据写入训练集文件 training_set.csv,无文件则自动新建并生成表头。随着持续上传数据,即可构建一份完整、带时间序列标记的标准数据集,可直接用于模型训练。training_set.csv 文件,正是我们后续训练尖峰行情检测模型所使用的核心数据源。
MQL5 和 Python 实现
在 Python 实现部分,本文不再使用简易脚本,转而开发一套完整的 EA,实现行情持续监控与 Python 后端实时通信 —— 这是独立脚本难以高效实现的功能。MT5 端的脉冲检测 EA采用客户端 - 服务端架构:EA 作为客户端,Python Flask 服务作为后端服务端。EA 持续监听新 K 线生成;每隔设定周期,采集指定数量的历史 K 线(OHLCV 行情 + 时间戳),序列化为 JSON 格式,通过 HTTP POST 请求发送至 Python 服务端。
Python 后端内置机器学习模型或自定义规则逻辑,对接收到的行情数据进行分析,并返回交易信号:买入、卖出、平仓、观望。EA 收到响应信号后,按预设规则解析并执行对应动作:在图表绘制交易箭头、开仓交易、平掉现有持仓,全部遵循用户自定义参数设置。这套闭环交互机制,让 MT5 能够实时外接 Python 的数据分析能力、拓展原生功能边界,真正实现MT5 交易执行引擎 + Python 算力与算法模型的强强结合。
MQL5实现
脚本元数据与严格编译模式
在 MQL5 文件最顶部,可通过元数据属性声明,如 #property copyright 版权声明、#property link 作者链接、#property version 版本号,将作者信息与版本信息直接嵌入编译后的 EA 程序中。开启 #property strict 严格编译模式,会启用最严格的编译校验机制,可提前排查语法错误、类型不匹配问题,同时强制代码遵循专业开发规范。
#property copyright "Copyright 2025, MetaQuotes Ltd." #property link "https://www.mql5.com/en/users/lynnchris" #property version "1.0" #property strict
引入交易类库
引入头文件 <Trade\Trade.mqh> 并实例化 CTrade 对象,即可调用 MT5 原生交易管理 API。该内置类库提供市价单、挂单、平仓等全套核心交易方法,可根据服务端返回的信号,通过代码程序化实现开仓、改单、平仓等操作。
#include <Trade\Trade.mqh> static CTrade trade;
自定义输入参数
所有可由用户配置的参数 —— 包括 REST 服务接口地址 InpServerURL、发送 K 线数量 InpBufferBars、图表绘制选项、交易执行开关等,均通过 input 语句集中声明。每个参数附带行内注释说明用途,让 EA 具备自注释特性;交易者无需修改代码,直接在 MT5 图形界面即可微调 EA 各项运行参数。
// REST endpoint & polling input string InpServerURL = "http://127.0.0.1:5000/analyze"; input int InpBufferBars = 200; input int MinSecsBetweenReq = 10; // Visual & trading options input color ColorBuy = clrLime; input color ColorSell = clrRed; input bool DrawSLTPLines = true; input bool EnableTrading = true; input double FixedLots = 0.10; // Debug & retry controls input int MaxRetry = 3; input bool DebugPrintJSON = true; input bool DebugPrintReply = true;
全局状态变量
你需要维护一系列全局变量:例如 lastBarTime 和 lastReqTime 用于限制请求频率,retryCount 用于 HTTP 重试逻辑,_digits 和 tickSize 用于精准的价格格式化。objPrefix 字符串以当前图表 ID 为基础生成,用于给 EA 创建的所有图表对象(箭头、线段)添加命名空间前缀,方便后续精准识别与清理。
datetime lastBarTime = 0; datetime lastReqTime = 0; int retryCount = 0; int _digits; double tickSize; string objPrefix;
在 OnInit 中初始化
EA 启动时,OnInit() 只会执行一次,用于校验输入参数(例如确保请求至少 2 根 K 线)、缓存品种属性(SYMBOL_DIGITS 小数位数、SYMBOL_POINT 最小点值),并生成唯一的对象前缀。启动日志会输出即将发送的 K 线数量与目标服务器 URL,确认 EA 已准备就绪进入轮询循环。
int OnInit() { if(InpBufferBars < 2) return INIT_FAILED; _digits = (int)SymbolInfoInteger(_Symbol, SYMBOL_DIGITS); tickSize = SymbolInfoDouble(_Symbol, SYMBOL_POINT); objPrefix = StringFormat("SpikeEA_%I64d_", ChartID()); PrintFormat("[SpikeEA] Initialized: posting %d bars → %s", InpBufferBars, InpServerURL); return INIT_SUCCEEDED; }
在 OnDeinit 中清理资源
当 EA 被移除或关闭时,OnDeinit() 会倒序遍历图表上所有对象,并删除名称以 objPrefix 开头的所有元素。这确保 EA 停用后,图表上不会残留多余箭头、止损 / 止盈线段,保持界面整洁。
void OnDeinit(const int reason) { for(int i = ObjectsTotal(0) - 1; i >= 0; --i) { string name = ObjectName(0, i); if(StringFind(name, objPrefix) == 0) ObjectDelete(0, name); } }
在 OnTick 中轮询与构建请求体
每一次报价跳动时,EA 会检查是否生成了新 K 线(如果开启 PollOnNewBarOnly),以及距离上一次请求是否已超过最小间隔 MinSecsBetweenReq。满足条件后,通过 CopyRates 获取最近 InpBufferBars 根 K 线,按序列排序,并调用BuildJSON() 将收盘价与时间戳序列化为 JSON 请求体。如果开启调试模式,会在发送前将原始 JSON 打印到 EA 日志。
void OnTick() { datetime barTime = iTime(_Symbol, _Period, 0); if(barTime == lastBarTime) return; lastBarTime = barTime; if(TimeCurrent() - lastReqTime < MinSecsBetweenReq) return; MqlRates rates[]; if(CopyRates(_Symbol, _Period, 0, InpBufferBars, rates) != InpBufferBars) return; ArraySetAsSeries(rates, true); string payload = BuildJSON(rates); if(DebugPrintJSON) PrintFormat("[SpikeEA] >>> %s", payload); SServerMsg msg; if(CallServer(payload, msg)) ActOnSignal(msg); lastReqTime = TimeCurrent(); }
在 BuildJSON 中构建请求数据
辅助函数 BuildJSON() 接收 MqlRates 数组,构建紧凑的 JSON 字符串,包含:品种名称、收盘价数组(按正确小数位格式化)、对应的 UNIX 时间戳数组。函数会自动处理品种名称中的特殊字符,确保输出合法有效的 JSON。
string BuildJSON(const MqlRates &r[]) { string j = StringFormat("{\"symbol\":\"%s\",\"prices\":[", _Symbol); for(int i = 0; i < InpBufferBars; i++) j += DoubleToString(r[i].close, _digits) + (i+1<InpBufferBars?",":""); j += "],\"timestamps\":["; for(int i = 0; i < InpBufferBars; i++) j += IntegerToString(r[i].time) + (i+1<InpBufferBars?",":""); j += "]}"; return j; }
在 CallServer 中与服务器通信
CallServer() 将 JSON 字符串转换为字节数组 uchar[],然后通过 WebRequest() 向InpServerURL 发送 HTTP POST 请求。函数内置超时处理、非 200 状态码重试机制,最大重试次数为 MaxRetry,请求失败时输出错误日志。请求成功后,捕获原始返回文本(可选择打印日志),并传递给 ParseJSONLite() 进行解析。
bool CallServer(const string &payload, SServerMsg &out) { uchar body[]; int len = StringToCharArray(payload, body, 0, WHOLE_ARRAY, CP_UTF8); ArrayResize(body, len); string hdr = "Content-Type: application/json\r\n"; uchar reply[]; string resp_hdr; int status = WebRequest("POST", InpServerURL, hdr, InpTimeoutMs, body, reply, resp_hdr); if(status <= 0) { PrintFormat("WebRequest error %d (retry %d/%d)", GetLastError(), retryCount+1, MaxRetry); ResetLastError(); if(++retryCount >= MaxRetry) retryCount = 0; return false; } retryCount = 0; string resp = CharArrayToString(reply); if(DebugPrintReply) PrintFormat("[SpikeEA] <<< HTTP %d – %s", status, resp); if(status != 200) return false; return ParseJSONLite(resp, out); }
轻量级 JSON 解析:ParseJSONLite
ParseJSONLite() 并未使用完整的 JSON 解析库,而是通过简单字符串查找(StringFind) 识别关键字,如交易信号 "signal":"BUY",以及置信度、止损、止盈等数值键 "conf":、"sl":、"tp":。
bool ParseJSONLite(const string &txt, SServerMsg &o) { o.code = SIG_WAIT; o.conf = o.sl = o.tp = 0.0; if(StringFind(txt, "\"signal\":\"BUY\"") >= 0) o.code = SIG_BUY; if(StringFind(txt, "\"signal\":\"SELL\"") >= 0) o.code = SIG_SELL; if(StringFind(txt, "\"signal\":\"CLOSE\"") >= 0) o.code = SIG_CLOSE; // extract numeric values ParseJSONDouble(txt, "\"conf\":", o.conf); ParseJSONDouble(txt, "\"sl\":", o.sl); ParseJSONDouble(txt, "\"tp\":", o.tp); return true; }该函数将解析出的子字符串提取并转换为 SServerMsg 结构体,用于设置 EA 的交易信号代码、置信度数值、止损价位与止盈价位。
void ParseJSONDouble(const string &txt, const string &key, double &out) { int p = StringFind(txt, key); if(p >= 0) out = StringToDouble(StringSubstr(txt, p + StringLen(key))); }
信号执行:ActOnSignal
当新信号到达时,ActOnSignal() 会先通过前缀匹配清除上一次生成的箭头与线段,避免图表残留。随后在当前买价(bid) 位置绘制新箭头 —— 根据信号类型自动选择图标编码、颜色与尺寸;若开启可视化,还会添加带标签的水平止损(SL)、止盈(TP)线。最后,若开启实盘交易,函数将通过 trade 对象,根据信号执行交易:Buy() 买入、Sell() 卖出或 PositionClose() 平仓。
void ActOnSignal(const SServerMsg &m) { static ESignal last = SIG_WAIT; if(m.code == SIG_WAIT || m.code == last) return; last = m.code; // remove old objects for(int i=ObjectsTotal(0)-1;i>=0;--i) if(StringFind(ObjectName(0,i),objPrefix)==0) ObjectDelete(0,ObjectName(0,i)); // draw arrow int arrow = (m.code==SIG_BUY ? 233 : m.code==SIG_SELL ? 234 : 158); color clr = (m.code==SIG_BUY ? ColorBuy : m.code==SIG_SELL ? ColorSell : ColorClose); string id = objPrefix + "Arr_" + TimeToString(TimeCurrent(),TIME_SECONDS); double y = SymbolInfoDouble(_Symbol, SYMBOL_BID); if(ObjectCreate(0,id,OBJ_ARROW,0,TimeCurrent(),y)) { ObjectSetInteger(0,id,OBJPROP_ARROWCODE,arrow); ObjectSetInteger(0,id,OBJPROP_COLOR,clr); ObjectSetInteger(0,id,OBJPROP_WIDTH,ArrowSize); PlaySound("alert.wav"); } // draw SL/TP lines if(DrawSLTPLines && m.sl>0) ObjectCreate(0,objPrefix+"SL_"+id,OBJ_HLINE,0,0,m.sl); if(DrawSLTPLines && m.tp>0) ObjectCreate(0,objPrefix+"TP_"+id,OBJ_HLINE,0,0,m.tp); // execute trade if(EnableTrading) { bool hasPos = PositionSelect(_Symbol); if(m.code==SIG_BUY && !hasPos) trade.Buy(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_SELL && !hasPos) trade.Sell(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_CLOSE&& hasPos) trade.PositionClose(_Symbol,SlippagePoints); } }
编译与部署
最后,将 EA 代码粘贴到 MetaEditor 中,保存到 Experts 目录下,按下 F7 进行编译。确认显示 “0 错误,0 警告” 后,切换回 MetaTrader 5,在导航栏中找到你的 EA,将其拖拽到图表上,并在弹出的参数窗口中配置输入项。之后,专家和日志标签页会实时显示 JSON 发送、信号解析、图形绘制以及所有交易执行的日志。
Python 实现
文件头部与依赖声明
在 engine.py 文件的最顶部,我们加入 Unix 脚本声明(#!/usr/bin/env python3)以及一段描述性注释,总结后端核心功能 —— 向量化历史数据接入、CSV 标准化、Prophet 模型缓存、模型训练、回测与命令行模式,同时附上安装所有依赖的 pip 命令。这个头部不仅能让人一眼看懂脚本功能,还能让任何开发者直接获得运行系统所需的完整库列表,开箱即用。
#!/usr/bin/env python3 # engine.py – Boom/Crash/Vol-75 ML back-end # • vectorised /upload_history # • /upload_spike_csv # • Prophet cache (1h) # • robust CSV writer # • train() drops bad rows # • SL/TP with ATR or fallback # • backtest defaults to 30 days # • CLI: collect · history · train · backtest · serve · info # # REQS: pip install numpy pandas ta prophet cmdstanpy pykalman \ # scikit-learn flask MetaTrader5 joblib pytz
用户可配置参数
头部之后,我们定义终端登录相关常量(终端路径、账号、密码、服务器)以及系统要处理的品种列表。同时设置用于标注数据的预测偏移参数 (LOOKAHEAD, THRESH_LABEL)、轮询间隔(STEP_SECONDS)、开仓 / 平仓阈值(THR_BC_OPEN, THR_O_OPEN, THR_O_CLOSE),以及基于 ATR 的止损、止盈倍数参数(ATR_PERIOD, SL_MULT, TP_MULT, ATR_FALLBACK_P)。将这些值集中管理,用户无需深入代码逻辑,即可快速调整策略风险参数、数据窗口和交易品种。
TERM_PATH = r"" LOGIN = 123456 PASSWORD = "passwd" SERVER = "DemoServer" SYMBOLS = [ "Boom 900 Index", "Crash 1000 Index", "Volatility 75 (1s) Index" ] LOOKAHEAD = 10 # minutes THRESH_LABEL = 0.0015 # 0.15 % STEP_SECONDS = 60 # live collect interval ATR_PERIOD = 14 SL_MULT = 1.0 TP_MULT = 2.0 ATR_FALLBACK_P = 0.002
文件路径与 CSV 表头
接下来定义文件系统常量:根分析目录、训练集 CSV 文件路径、品种模型保存目录、通用模型文件。同时定义固定的 CSV 表头,确保每一行数据都拥有统一的 12 个字段。这一部分统一了数据存储位置,并保证 CSV 文件格式一致,对后续流畅的模型训练与分析至关重要。
BASE_DIR = r"C:\Analysis EA" CSV_FILE = rf"{BASE_DIR}\training_set.csv" MODEL_DIR = rf"{BASE_DIR}\models" GLOBAL_PKL = rf"{MODEL_DIR}\_global.pkl" CSV_HEADER = [ "timestamp","symbol","price","spike_mag","macd","rsi", "atr","slope","env_low","env_up","delta","label" ]
模块导入与日志配置
我们导入标准库(文件、系统、时间、线程等)、数据分析包、预测与滤波模块、Flask API 框架以及 MT5 Python 接口。为了界面整洁,屏蔽警告信息,并将日志配置为带时间戳、日志等级的易读格式。最后确保模型目录存在,并将工作目录切换到BASE_DIR目录,让所有相对文件操作都在统一位置执行。
import os,sys,time,logging,warnings,argparse,threading,io import datetime as dt from pathlib import Path import numpy as np, pandas as pd, ta, joblib, pytz from flask import Flask, request, jsonify, abort from prophet import Prophet from pykalman import KalmanFilter import MetaTrader5 as mt5 warnings.filterwarnings("ignore") logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)-7s %(message)s", datefmt="%H:%M:%S") Path(MODEL_DIR).mkdir(parents=True, exist_ok=True) os.chdir(BASE_DIR)
MetaTrader 5 初始化工具函数
init_mt5() 函数安全初始化 MT5 连接,优先使用默认方式登录,失败则使用配置的账号密码;连接失败会输出错误信息并安全退出。ensure_symbol(sym) 简单封装了 mt5.symbol_select 品种选择函数,确保在请求数据前对应品种已被激活。线程锁 (_mt5_lock) 用于保护所有多线程调用 MT5 的操作,确保服务器在后台任务运行时保持线程安全。
_mt5_lock = threading.Lock() def init_mt5(): if mt5.initialize(): return if not mt5.initialize(path=TERM_PATH, login=LOGIN, password=PASSWORD, server=SERVER): sys.exit(f"MT5 init failed {mt5.last_error()}") def ensure_symbol(sym): return mt5.symbol_select(sym, True)
Prophet 模型缓存与预测差值
为避免每次请求都重新训练 Prophet 模型,我们维护一个线程安全的字典 _PROP,将品种映射为 None(待训练)或(模型,时间戳)元组。_compile_prophet(df, sym) 使用历史数据训练新的 Prophet 模型并记录时间。prophet_delta(prices, times, sym) 检查缓存,若模型不存在或已过期(超过 1 小时),则在后台启动重新训练;若模型有效,则预测下一秒价格并返回预测差值。这种设计保证预测响应迅速,且不会阻塞前端请求。
_PROP_LOCK = threading.Lock()
_PROP = {} # sym -> (model, timestamp) or None
def _compile_prophet(df, sym):
mdl = Prophet(daily_seasonality=False, weekly_seasonality=False)
mdl.fit(df)
with _PROP_LOCK:
_PROP[sym] = (mdl, time.time())
def prophet_delta(prices, times, sym):
if len(prices) < 20: return 0.0
with _PROP_LOCK:
entry = _PROP.get(sym)
if entry is None:
_PROP[sym] = None
df = pd.DataFrame({"ds": pd.to_datetime(times, unit='s'),
"y": prices})
threading.Thread(target=_compile_prophet, args=(df, sym), daemon=True).start()
return 0.0
mdl, ts = entry
if time.time() - ts > 3600:
with _PROP_LOCK: _PROP[sym] = None
return 0.0
fut = mdl.make_future_dataframe(periods=1, freq='s')
return float(mdl.predict(fut).iloc[-1]["yhat"] - prices[-1])
特征辅助函数
我们定义了一系列轻量函数 ——z_spike、macd_div、rsi_val、combo_spike,及其他工具函数,用于分别计算各类技术信号,例如标准化脉冲得分、MACD 背离、RSI 指标,以及一个综合脉冲评分。每个辅助函数都会先检查历史数据是否充足,数据不足时返回默认值,避免计算报错。
def z_spike(prices, win=20): if len(prices) < win: return False, 0.0 r = np.diff(prices[-win:]) z = (r[-1] - r.mean())/(r.std()+1e-6) return abs(z) > 2.5, float(z) def macd_div(prices): if len(prices) < 35: return 0.0 return float(ta.trend.macd_diff(pd.Series(prices)).iloc[-1]) def rsi_val(prices, l=14): if len(prices) < l+1: return 50.0 return float(ta.momentum.rsi(pd.Series(prices), l).iloc[-1]) def combo_spike(prices): _, z = z_spike(prices) m = macd_div(prices) v = prices[-1] - prices[-4] if len(prices) >= 4 else 0.0 s = abs(z) + abs(m) + abs(v)/(np.std(prices[-20:])+1e-6) return s > 3.0, s
CSV 追加辅助函数与 gen_row
append_rows(rows) 接收一个由12 个元素列表组成的数据集,并将其写入 training_set.csv。首次写入时会自动创建文件并添加表头,后续则以追加模式写入。gen_row(i, closes, times, sym, highs=None, lows=None)用于构建单条训练数据行,它会根据截至索引 i 的历史价格计算特征(如果传入最高价 / 最低价数组,则同时计算 ATR 和轨道带),调用 prophet_delta 获取预测值,并根据未来价格波动打上 BUY/SELL/WAIT 标签。将行数据生成与数据接入逻辑分离,让 gen_row 可以在实时采集和历史导入中复用。
def append_rows(rows): if not rows: return pd.DataFrame(rows, columns=CSV_HEADER)\ .to_csv(CSV_FILE, mode="a", index=False, header=not Path(CSV_FILE).exists()) def gen_row(i, closes, times, sym, highs=None, lows=None): if i < LOOKAHEAD or i+LOOKAHEAD >= len(closes): return None seq = closes[:i] _, mag = combo_spike(seq) atr = ta.volatility.average_true_range(pd.Series(highs[:i+1]), pd.Series(lows[:i+1]), pd.Series(seq)).iloc[-1] if highs else 0.0 row = [ times[i], sym, closes[i], mag, macd_div(seq), rsi_val(seq), atr, 0.0, 0.0, 0.0, prophet_delta(seq, times[:i], sym) ] ch = (closes[i+LOOKAHEAD] - closes[i]) / closes[i] row.append("BUY" if ch > THRESH_LABEL else "SELL" if ch < -THRESH_LABEL else "WAIT") return row
实时数据采集循环
collect_loop() 会先确保 CSV 文件存在,然后进入无限循环:对每个交易品种,通过 mt5.copy_rates_from_pos 请求最新的 LOOKAHEAD+1 根 K 线,根据时间戳跳过重复数据,并调用 gen_row 生成带标签的训练样本,最后追加写入文件。通过 time.sleep(STEP_SECONDS) 控制稳定的轮询频率。这个实盘数据循环会持续不断地用最新行情扩充训练集,直到用户手动终止程序。
def collect_loop(): if not Path(CSV_FILE).exists(): append_rows([]) last = {} print("Collecting… CTRL-C to stop") init_mt5() while True: for sym in SYMBOLS: if not ensure_symbol(sym): continue bars = mt5.copy_rates_from_pos(sym, mt5.TIMEFRAME_M1, 0, LOOKAHEAD+1) if bars is None or len(bars) < LOOKAHEAD+1: continue if last.get(sym) == bars[-1]['time']: continue last[sym] = bars[-1]['time'] closes = bars['close'].tolist() times = bars['time'].tolist() row = gen_row(len(closes)-LOOKAHEAD-1, closes, times, sym) if row: append_rows([row]) time.sleep(STEP_SECONDS)
历史数据导入(MT5 与本地文件)
history_from_mt5(sym, start, end) 和 history_from_file(sym, path) 支持从 MT5 内置历史数据或本地 CSV 文件批量补全训练集。两个函数都会遍历每根带时间戳的 K 线,调用 gen_row 生成特征与标签,按批次(例如 5000 条一批)处理,并通过 append_rows 批量写入。history_cli(args) 是命令行封装,可解析参数(天数、起止时间、文件路径),自动完成指定品种与时间段的全量数据集导入。
def history_from_mt5(sym, start, end): init_mt5() r = mt5.copy_rates_range(sym, mt5.TIMEFRAME_M1, start.replace(tzinfo=UTC), end.replace(tzinfo=UTC)) if r is None or len(r)==0: return closes, times = r['close'].tolist(), r['time'].tolist() highs, lows = r['high'].tolist(), r['low'].tolist() rows = [gen_row(i, closes, times, sym, highs, lows) for i in range(len(closes)-LOOKAHEAD) if gen_row(i, closes, times, sym, highs, lows)] append_rows([rw for rw in rows if rw]) print(sym, "imported", len(rows), "rows")
训练模型
train_models() 读取 training_set.csv,将特征列强制转换为数值型(自动剔除格式错误的行),然后按交易品种分别训练:如果某个品种的数据量至少达到 400 行,就构建一个 scikit-learn 流水线(标准化 + 梯度提升分类器),用带标签的数据训练模型,并保存为 .pkl 模型文件。同时,它也会训练一个覆盖所有品种的全局通用模型并保存。最终输出一个包含可直接部署的分类器模型目录。
def build_pipe(X, y): pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, random_state=42)) ]) return pipe.fit(X, y) def train_models(): df = pd.read_csv(CSV_FILE) df = df.dropna(subset=FEATURES) for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: continue model = build_pipe(d[FEATURES], d.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(model, Path(MODEL_DIR)/f"{sym.replace(' ','_')}.pkl") global_model = build_pipe(df[FEATURES], df.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(global_model, GLOBAL_PKL)
Flask 服务接口
我们启动一个 Flask 应用,并设置三个核心接口:
/upload_history 解析 JSON 格式的 K 线数据块,计算与 gen_row 完全一致的特征,为每一行数据打上标签,然后调用 append_rows 写入训练集。
/upload_spike_csv 接收来自 EA 的原始日志(支持 CSV 文本或 JSON 数组),将其映射成我们统一的 12 列标准格式,然后追加写入训练集。
/analyze 通过 load_model() 加载对应品种的模型,根据传入的实时价格与时间戳计算在线特征,预测分类概率,应用开仓 / 平仓阈值,最终返回一个 JSON 对象,包含:交易信号、置信度、止损 / 止盈价位、仓位强度。
app = Flask(__name__) app.config["MAX_CONTENT_LENGTH"] = 32*1024*1024 @app.route("/upload_history", methods=["POST"]) def upload_history(): j = request.get_json(force=True) close, ts = np.array(j["close"]), np.array(j["time"],dtype=int) high = np.array(j.get("high", close)) low = np.array(j.get("low", close)) df = pd.DataFrame({"timestamp": ts, "price": close}) # compute features as in gen_row… append_rows(df.assign(symbol=j["symbol"]).values.tolist()) return jsonify(status="ok", rows_written=len(df)) @app.route("/upload_spike_csv", methods=["POST"]) def upload_spike_csv(): j = request.get_json(force=True) df_ea = pd.read_csv(io.StringIO(j.get("csv","")), sep=",") # map EA columns → CSV_HEADER append_rows(mapped_rows) return jsonify(status="ok", rows_written=len(mapped_rows)) @app.route("/analyze", methods=["POST"]) def api_analyze(): j = request.get_json(force=True) mdl = load_model(j["symbol"]) feats = [...] # compute from j["prices"], j["timestamps"] proba = mdl.predict_proba([feats])[0] signal = decide_open(proba[1], proba[2], j["symbol"]) # build sl, tp, manage _trades… return jsonify(signal=signal, sl=sl, tp=tp, strength=max(proba))
这些接口为 MQL5 EA提供数据接入、历史回填与实时决策能力。
回测与信息查询工具
backtest_one(sym, df) 复用离线特征辅助函数与模型推理逻辑,在历史数据框 df 上模拟交易,并在触发止损、止盈或提前平仓条件时记录盈亏。backtest_cli(args) 汇总所有品种的回测结果,并输出总体盈亏摘要。info() 函数仅用于报告 CSV 数据行数、标签分布以及每个模型的特征数量,便于快速检查数据健康状态。
def backtest_one(sym, df): mdl = load_model(sym) for i in range(len(df)): feats = [...] # offline feature calcs pr = mdl.predict_proba([feats])[0] # open/close logic identical to /analyze return trades def info(): df = pd.read_csv(CSV_FILE) print("Rows:", len(df), "Labels:", df.label.value_counts()) for pkl in Path(MODEL_DIR).glob("*.pkl"): mdl = joblib.load(pkl) print(pkl.name, "features", mdl.named_steps["sc"].n_features_in_)
命令行界面
最后,__name__ == "__main__":代码块通过 argparse 定义了一套命令行交互界面(CLI),包含六个子命令:collect(实时采集)、history(历史导入)、train(训练模型)、backtest(回测)、serve(启动服务)、info(数据信息),每个命令都会自动调用对应的功能函数。这种设计让整个脚本统一且易用。例如:运行 python engine.py history --days 180 可导入最近 6 个月的历史数据。运行 python engine.py serve 可启动实时 API 服务供 EA 调用。
if __name__ == "__main__": parser = argparse.ArgumentParser() subs = parser.add_subparsers(dest="mode", required=True) subs.add_parser("collect") subs.add_parser("history") subs.add_parser("train") subs.add_parser("backtest") subs.add_parser("serve") subs.add_parser("info") args = parser.parse_args() if args.mode == "collect": init_mt5(); collect_loop() elif args.mode == "history": history_cli(args) elif args.mode == "train": train_models() elif args.mode == "backtest": backtest_cli(args) elif args.mode == "serve": init_mt5(); app.run("0.0.0.0", 5000, threaded=True) elif args.mode == "info": info()
在Python中训练模型
现在,我们的 CSV 文件已经通过 MQL5 历史数据采集脚本 + Python 接收服务 积累了充足的历史数据,接下来进入模型训练阶段。请确保已完成 MQL5 与 Python 脚本中所有交易品种的数据接入工作。数据采集完成后,我们将依次执行:- 训练机器学习模型
- 在历史数据上回测模型表现
- 部署训练完成的模型用于实盘推理
在本环节中,我们会为每个交易品种单独训练一个梯度提升分类器(同时训练一个全局通用模型),用于预测价格在设定的前瞻周期后会出现 买入、卖出或观望 信号。梯度提升算法(Gradient Boosting) 的原理是:按顺序构建一组决策树集成模型,每一棵新树都会修正前一棵树的预测误差。这使得该算法对金融市场中的噪声数据具有强鲁棒性,并能有效捕捉特征集中的非线性规律。我们将模型封装在 scikit-learn 流水线中,搭配 StandardScaler(标准化处理器),在训练前对所有特征进行归一化处理。
# 3) TRAIN MODELS def build_pipe(X, y): """ Construct and fit a pipeline: StandardScaler → GradientBoostingClassifier. """ pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier( n_estimators=400, # number of boosting rounds learning_rate=0.05, # shrinkage factor per tree max_depth=3, # depth of each tree random_state=42 # reproducibility )) ]) pipe.fit(X, y) return pipe def train_models(): """ Load the CSV, clean it, train per-symbol and global Gradient Boosting models, and save to disk. """ if not Path(CSV_FILE).exists(): sys.exit("No training_set.csv") # Read and sanitize df = pd.read_csv(CSV_FILE) if "symbol" not in df.columns: sys.exit("CSV missing 'symbol' column") # Ensure numeric features for col in FEATURES: df[col] = pd.to_numeric(df[col], errors="coerce") bad = df[FEATURES].isna().any(axis=1).sum() if bad: print(f"Discarding {bad} malformed rows") df = df.dropna(subset=FEATURES) # Train a Gradient Boosting model for each symbol for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: print("Skip", sym, "(few rows)") continue model = build_pipe( d[FEATURES], d.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(model, Path(MODEL_DIR) / f"{sym.replace(' ', '_')}.pkl") print("model", sym, "saved") # Train and save a global Gradient Boosting model global_model = build_pipe( df[FEATURES], df.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(global_model, GLOBAL_PKL) print("global model saved")使用以下命令启动训练:
python engine.py train执行训练脚本后,你将看到如下控制台输出:
C:\Users\hp\Pictures\Saved Pictures\Analysis EA>python engine.py train Discarding 1152650 malformed rows model Boom 900 Index saved model Boom 1000 Index saved model Boom 500 Index saved model Crash 500 Index saved model Boom 300 Index saved .................................... .................................... All models saved
鉴于数据量较大,训练与保存过程可能需要一段时间。训练完成后,你可以进入下一步:要么在历史数据上回测新训练的模型,要么直接进入部署环节。在本例中,我直接进行了模型部署,这部分内容将在下一节讲解。
模型部署与实时推理
按 Ctrl+C 终止训练进程。然后使用以下命令启动实时推理服务:python engine.py serve
该命令会加载已训练好的模型,并开始对外提供实时交易信号服务。
在 MetaTrader 5 中,将编写好的 EA 附加到已完成模型训练的每个交易品种。在 MT5 中打开:工具 → 选项 → 智能交易系统,勾选允许 WebRequest 请求,并将你的 Python 服务地址加入白名单。
HTTP 状态码 200 表示请求正常 —— 服务已成功接收、解析并处理请求。
在实盘服务测试中,每个 EA 实例都能成功连接 Python 后端(返回 200),并在 50 毫秒内返回交易建议。日志内容如下:
Crash 1000 Index (M1)
在 00:31:59.717,模型给出:买入概率:0%,卖出概率:2.6%,综合置信度(信号强度):仅 3%。由于未突破任何阈值,EA 正确返回观望(WAIT) 信号。
Boom 1000 Index (M1)
仅 37 毫秒后(00:31:59.754),该品种模型给出:买入概率:99.4%,卖出概率:0%。超高置信度立即触发开多(OPEN BUY)信号。
这些日志证实:整套部署流程已实现端到端正常运行。
2025.07.30 00:31:59.717 Spike DETECTOR (Crash 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.0,"Psell":0.026,"scale_in":null ,"side":"NONE","signal":"WAIT","strength":0.03 2025.07.30 00:31:59.754 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.994,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN" , "strength":0.99
早期系统测试记录。有时 EA 会发出入场信号 —— 这类 OPEN 指令会出现在 MT5 日志中,但图表上不一定显示箭头。是否显示视觉标记取决于信号强度。
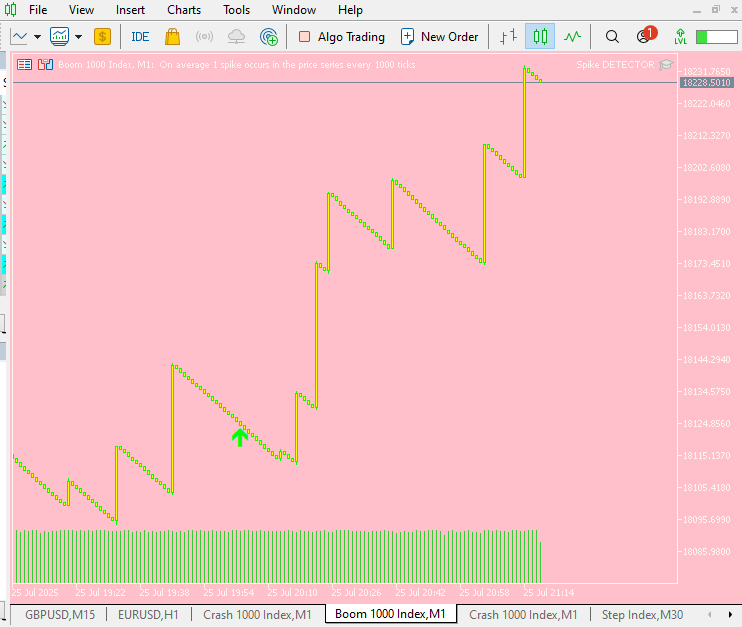
MT5 日志
2025.07.25 19:55:01.445 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.999,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN","strength":1.0
MT5图表
结论
将 MQL5 与 Python 结合,为我们打造了一套强大且灵活的量化交易框架 —— 充分融合了两者的优势。在MQL5 端:EA 无缝采集价格脉冲、MACD 背离、RSI、ATR、卡尔曼滤波斜率、Prophet 预测差值等特征,并将指标实时传入 Python。在Python 端:仅靠一个 engine.py 脚本(支持 collect/history/train/backtest/serve 命令),即可完成模型训练与实时服务的核心工作。在本套系统中,我们依靠 MQL5 的 EA 提供全部所需特征数据,因此只需运行两条命令:
python engine.py train python engine.py serve
可以跳过 collect(实时采集)和 history(历史导入),因为 EA 已经为我们维护并提供了完整数据集。
最终效果?启动服务后,梯度提升模型会在 50 毫秒内将实时 BUY/SELL/WAIT 信号返回给 MT5,EA 可直接根据信号执行下单逻辑。无论你是刚开始学习 MQL5 丰富的文档与社区案例,还是资深量化开发者希望接入新的特征生成器或算法,这套端到端流水线都能轻松跨品种、跨策略扩展。
感谢 MQL5 社区以及网站提供的大量代码示例与论坛见解,正是这些资源让本次集成变得简单高效。我鼓励大家进一步探索:调优超参数,添加新指标,甚至将 Python 服务容器化用于生产环境最重要的是:将你的成果分享给社区,让我们共同推动数据驱动型算法交易持续发展。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18985
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

