
价格走势角度分析:用于预测金融市场的混合模型

想象一下,一位经验丰富的登山者站在山脚下,在开始攀登之前仔细观察着山坡。他能看到什么?不仅仅是岩石和岩架的杂乱无章,还有路线几何形状 — 上升角度、坡度陡峭程度、山脊曲线。正是这些地形的几何特征决定了通往山顶的道路有多难走。
金融市场的世界与山景有着惊人的相似之处。价格图表也会形成自己的“地形”,有高峰、低谷、缓坡和陡峭的悬崖。正如登山者通过几何形状来解读山峰,经验丰富的交易者也能凭直觉感知价格变动角度所蕴含的价值。但如果这种直觉能够转化为一门精确的科学呢?如果价格变动角度不仅仅是视觉图像,而是具有数学意义的未来指标,那会怎么样?
在算法交易者安静的房间里,远离交易平台的喧嚣,我正是问了自己这个问题。而答案却如此引人入胜,以至于它改变了我对市场本质的理解。
价格波动的剖析
货币对、股票和期货图表上每天都会产生成千上万根 K 线。它们构成形态,形成趋势,并产生阻力和支撑。然而,在这些熟悉的图表背后,隐藏着一个我们很少注意到的数学实体,即连续价格点之间的角度。
请查看常规的 EURUSD 图表。你看到了什么?线条和柱?现在想象一下,连接两个相邻点的每条线段都与水平轴形成一定的夹角。这个角度具有精确的数学值。正角度表示向上运动,负角度表示向下运动。角度越大,价格变动的斜率就越陡。
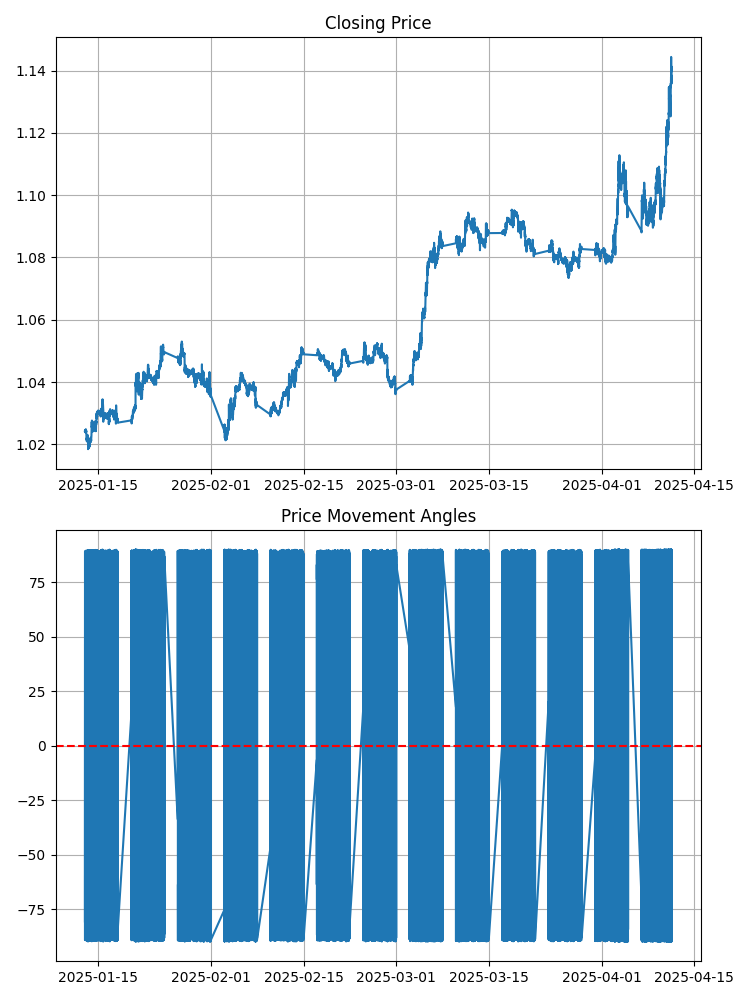
听起来很简单?但这种简洁之下却蕴藏着惊人的深度。因为角度并不彼此相等。它们形成了自己的模式,自己的旋律。事实证明,这首旋律蕴含着未来市场走势的关键。
交易员研究趋势线斜率已有数十年,但这仅是一种粗略的估计。我们正在讨论的是每两个连续价格点之间精确的数学角度。这就像是山峰的粗略草图和标明每个坡面精确角度的详细地形图之间的区别。
江恩角度分析:从经典到创新
利用角度分析价格走势的想法并不新鲜。其起源可追溯至传奇交易员和分析师威廉·德尔伯特·江恩的著作。早在 20 世纪初,他就提出了针对金融市场的角度分析体系。我们根据它创建了一个指标。
许多年前,我在研究技术分析的经典著作时,首次接触到了江恩的概念。这个想法本身就让我着迷:江恩认为,价格与时间之间存在一种数学关系,这种关系可以通过图表上特殊线的角度斜率来表达。他认为这些角度具有近乎神秘的预测能力,并发展出一整套“江恩角度线”体系:从图表上的重要点位以特定角度绘制的线条。
然而,江恩的经典方法存在两个重大缺陷。首先,它过于主观:不同的分析师可能会以完全不同的方式解读相同的角结构。其次,他的系统是为具有一定比例尺的纸质图表设计的,这使得其难以应用于现代数字分析。
我不禁思考:如果江恩的基本理念是正确的,只是当时没有现代计算工具可用,那会怎么样?如果他对角度重要性的直觉是正确的,但需要采用一种不同的、更严谨的数学方法来证明呢?
在看一部关于粒子物理的纪录片时,灵感意外地迸发出来。科学家通过测量基本粒子碰撞后的偏转角度来分析它们的轨迹。这些角度包含了关于粒子特性以及作用在它们之间的力的关键信息。
然后我恍然大悟:市场上的价格变动也是一种轨迹,是市场力量“碰撞”的结果!如果我们不是主观地绘制江恩线,而是精确测量价格图表上每两个连续点之间的角度,那会怎么样?如果我们利用机器学习将其转化为严谨的数学分析,会怎么样呢?
与经典江恩理论中从某些重要点出发绘制角度线的方法不同,我决定测量每两个连续价格点之间的角度。这为我们提供了连续的角度数据流,类似于市场“心电图”。解决比例尺问题至关重要,因为图表上的时间轴和价格轴的计量单位不同。
解决方案是对轴进行归一化处理,使它们在每个变量的变化范围内具有可比的尺度。这使我们能够获得数学上正确的角度,而与绝对价格值或时间间隔无关。
与基于几何构造和直觉进行分析的江恩不同,我决定依靠客观的数学方法和机器学习算法。我们没有寻找 45° 或 26.25°(江恩偏爱的角度)的“神奇”角度,而是让算法来确定哪些角度模式对于预测未来走势最为重要。
有趣的是,对结果的分析表明,算法识别出的一些模式确实与江恩的观察相呼应,但它们也获得了严谨的数学形式和统计验证。例如,江恩特别强调1:1(45°)线,而我们的模型也揭示,当角度符号从接近零值变为接近 45° 的正值时,往往预示着市场将出现强劲的定向波动。
因此,本文提出的角度分析方法建立在江恩经典思想之上,但又借助现代数学与机器学习对其进行了重新诠释。正是在这种基础上,这一方法得以形成。它保留了江恩方法的哲学精髓,即在价格与时间的交汇处寻找几何模式。这种方法将其从一门艺术转变为一门严谨的科学。
或许江恩本人也会乐于看到,他的思想在他那个时代不存在的技术的帮助下得以发展。正如艾萨克·牛顿所说:“如果我看得比别人更远,那是因为我站在巨人的肩膀上。”我们的现代角度分析系统更进一步,但要感谢技术分析巨头的启发,正是他的思想启发了我们采用这种方法。
角度之舞
掌握了精确测量角度的方法后,我们进入了研究的下一个里程碑 — 观测。我们观察了 EURUSD 图表上几个月以来的角度变化,记录了它们的每一次移动、每一次转向。
渐渐地,从杂乱无章的数据中开始浮现出规律。角度并非随机变化。它们反复形成先于某些价格走势的序列。我们注意到,在价格显著上涨之前,通常会观察到一系列特定的角度变化 — 先是出现小幅度的负向角度,接着是中性角度,最后是一系列幅度逐渐增大的正向角度。
这让我想起了一种儿童玩具 — 陀螺。在它向上冲之前,它会先微微摇晃,仿佛在积蓄力量。市场似乎也是按照同样的原则运作的。在剧烈波动之前,它会“摇摆”,形成一系列特有的角度变化。
然而,观察结果无论多么引人入胜,都不足以构建一个可靠的交易策略。我们需要用数学上的精确性来验证我们的猜测。这就是机器学习发挥作用的地方,它是我们解读复杂模式的得力助手。
从构思到代码:创建角度分析器
理论是件好事,但若没有付诸实践,它就只是华丽的辞藻。首先,我们必须获取市场数据,并学习如何处理这些数据。作为工具,我们选择了 Python 和 MetaTrader 5 库,这样我们就可以直接从交易终端获取数据。
以下是加载报价历史记录的代码:
import MetaTrader5 as mt5 from datetime import datetime, timedelta import pandas as pd import numpy as np import math def get_mt5_data(symbol='EURUSD', timeframe=mt5.TIMEFRAME_M5, days=60): if not mt5.initialize(): print(f"Initialization error MT5: {mt5.last_error()}") return None # Determine period for downloading data start_date = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_range(symbol, timeframe, start_date, datetime.now()) mt5.shutdown() # Transform data into convenient format df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return df
这段简短的代码片段将带你进入市场数据的世界。它连接到 MetaTrader 5,下载指定天数的报价历史记录,并将其转换为便于分析的格式。
现在我们需要计算连续点之间的角度。但这里出现了一个问题:在时间轴和价格轴的刻度完全不同的图表上,如何才能正确测量角度呢?如果你只是照原样使用这些点的坐标,那么角度将毫无意义。
解决方法是对坐标轴进行归一化。我们必须使时间和价格达到可比的水平:
def calculate_angle(p1, p2): # p1 и p2 - tuples (time_normalized, price) x1, y1 = p1 x2, y2 = p2 # Handling vertical lines if x2 - x1 == 0: return 90 if y2 > y1 else -90 # Calculating an angle in radians and convert it to degrees angle_rad = math.atan2(y2 - y1, x2 - x1) angle_deg = math.degrees(angle_rad) return angle_deg def create_angular_features(df): # Create copy DataFrame angular_df = df.copy() # Normalizing time series for correct calculation of angles angular_df['time_num'] = (angular_df['time'] - angular_df['time'].min()).dt.total_seconds() # Find ranges for normalization time_range = angular_df['time_num'].max() - angular_df['time_num'].min() price_range = angular_df['close'].max() - angular_df['close'].min() # Normalization for comparable scales scale_factor = price_range / time_range angular_df['time_scaled'] = angular_df['time_num'] * scale_factor # Calculate angles between sequential points angles = [] angles.append(np.nan) # Angle not defined for the first point for i in range(1, len(angular_df)): current_point = (angular_df['time_scaled'].iloc[i], angular_df['close'].iloc[i]) prev_point = (angular_df['time_scaled'].iloc[i-1], angular_df['close'].iloc[i-1]) angle = calculate_angle(prev_point, current_point) angles.append(angle) angular_df['angle'] = angles return angular_df
这些函数是我们方法的核心。第一个函数计算两点之间的角度,第二个函数准备数据并计算整个时间序列的角度。处理后,图表上的每个点都会获得其自身的角度 — 这是价格斜率的数学特征。
我们不仅对过去感兴趣,也对未来充满好奇。必须了解这些角度与即将到来的价格走势之间的关系。为此,请将未来价格变化的信息添加到我们的 DataFrame 中:
def add_future_price_info(angular_df, prediction_period=24): # Add future price direction future_directions = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): # 1 = growth, 0 = fall future_dir = 1 if angular_df['close'].iloc[i + prediction_period] > angular_df['close'].iloc[i] else 0 future_directions.append(future_dir) else: future_directions.append(np.nan) angular_df['future_direction'] = future_directions # Calculate magnitude of the future change (in percent) future_changes = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): pct_change = (angular_df['close'].iloc[i + prediction_period] - angular_df['close'].iloc[i]) / angular_df['close'].iloc[i] * 100 future_changes.append(pct_change) else: future_changes.append(np.nan) angular_df['future_change_pct'] = future_changes return angular_df
现在,对于图表上的每个点,我们不仅知道其角度,还知道在未来的指定柱数之后价格会发生什么变化。这是训练机器学习模型的理想数据集。
但一个角度是不够的。角度序列 — 它们的模式、趋势、统计特征 — 起着关键作用。对于图表上的每个点,我们都应该构建一组丰富的特征来描述角度行为:
def prepare_features(angular_df, lookback=15): features = [] targets_class = [] # For classification (direction) targets_reg = [] # For regression (percent change) # Discard strings with NaN filtered_df = angular_df.dropna(subset=['angle', 'future_direction', 'future_change_pct']) # Check if there is enough data if len(filtered_df) <= lookback: print("Not enough data for analysis") return None, None, None for i in range(lookback, len(filtered_df)): # Get latest lookback of bars window = filtered_df.iloc[i-lookback:i] # Take last angles as a sequence feature_dict = { f'angle_{j}': window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics of angles feature_dict.update({ 'angle_mean': window['angle'].mean(), 'angle_std': window['angle'].std(), 'angle_min': window['angle'].min(), 'angle_max': window['angle'].max(), 'angle_last': window['angle'].iloc[-1], 'angle_last_3_mean': window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (window['angle'] > 0).mean(), 'current_price': window['close'].iloc[-1], 'price_std': window['close'].std(), 'price_change_pct': (window['close'].iloc[-1] - window['close'].iloc[0]) / window['close'].iloc[0] * 100, 'high_low_range': (window['high'].max() - window['low'].min()) / window['close'].iloc[-1] * 100, 'last_tick_volume': window['tick_volume'].iloc[-1], 'avg_tick_volume': window['tick_volume'].mean(), 'tick_volume_ratio': window['tick_volume'].iloc[-1] / window['tick_volume'].mean() if window['tick_volume'].mean() > 0 else 1, }) features.append(feature_dict) targets_class.append(filtered_df.iloc[i]['future_direction']) targets_reg.append(filtered_df.iloc[i]['future_change_pct']) return pd.DataFrame(features), np.array(targets_class), np.array(targets_reg)
这一特性将简单的时间序列转化为丰富的数据集,以供机器学习使用。对于图表上的每个点,它会生成 30 多个特征,这些特征描述了最近几个柱上角度的行为特征。这张角度特征的“肖像”将成为我们模型的输入数据。
机器学习揭示角度的秘密
既然我们已经有了数据和特征,那么是时候训练模型来寻找其中的模式了。我们决定使用 CatBoost 库,这是一种现代的梯度提升算法,特别适用于时间序列分析。
我们方法的一个特点是,我们训练的不是一个模型,而是两个模型:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, mean_squared_error def train_hybrid_model(X, y_class, y_reg, test_size=0.3): # Splitting data into training and test X_train, X_test, y_class_train, y_class_test, y_reg_train, y_reg_test = train_test_split( X, y_class, y_reg, test_size=test_size, random_state=42, shuffle=True ) # Parameters for classification model params_class = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'Logloss', 'random_seed': 42, 'verbose': False } # Parameters for regression model params_reg = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'RMSE', 'random_seed': 42, 'verbose': False } # Training classification model (directional prediction) print("Training classification model...") model_class = CatBoostClassifier(**params_class) model_class.fit(X_train, y_class_train, eval_set=(X_test, y_class_test), early_stopping_rounds=50, verbose=False) # Checking classification accuracy y_class_pred = model_class.predict(X_test) accuracy = accuracy_score(y_class_test, y_class_pred) print(f"Classification accuracy: {accuracy:.4f} ({accuracy*100:.2f}%)") # Training regression model (forecast of percentage change) print("\nTraining regression model...") model_reg = CatBoostRegressor(**params_reg) model_reg.fit(X_train, y_reg_train, eval_set=(X_test, y_reg_test), early_stopping_rounds=50, verbose=False) # Checking regression accuracy y_reg_pred = model_reg.predict(X_test) rmse = np.sqrt(mean_squared_error(y_reg_test, y_reg_pred)) print(f"RMSE regressions: {rmse:.4f}") # Print importance of features print("\nImportance of features for classification:") feature_importance = model_class.get_feature_importance(prettified=True) print(feature_importance.head(5)) return model_class, model_reg
第一个模型(分类器)预测价格走势方向 — 上涨或下跌。第二个模型(回归器)以百分比的形式估计这种波动的幅度。它们共同提供了对未来价格走势的完整预测。
经过训练,我们可以利用这些模型进行实时预测:
def predict_future_movement(model_class, model_reg, angular_df, lookback=15): # Get latest data if len(angular_df) < lookback: print("Not enough data for forecast") return None # Get latest lookback of bars last_window = angular_df.tail(lookback) # Form features as during training feature_dict = { f'angle_{j}': last_window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics feature_dict.update({ 'angle_mean': last_window['angle'].mean(), 'angle_std': last_window['angle'].std(), 'angle_min': last_window['angle'].min(), 'angle_max': last_window['angle'].max(), 'angle_last': last_window['angle'].iloc[-1], 'angle_last_3_mean': last_window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': last_window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': last_window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (last_window['angle'] > 0).mean(), 'current_price': last_window['close'].iloc[-1], 'price_std': last_window['close'].std(), 'price_change_pct': (last_window['close'].iloc[-1] - last_window['close'].iloc[0]) / last_window['close'].iloc[0] * 100, 'high_low_range': (last_window['high'].max() - last_window['low'].min()) / last_window['close'].iloc[-1] * 100, 'last_tick_volume': last_window['tick_volume'].iloc[-1], 'avg_tick_volume': last_window['tick_volume'].mean(), 'tick_volume_ratio': last_window['tick_volume'].iloc[-1] / last_window['tick_volume'].mean() if last_window['tick_volume'].mean() > 0 else 1, }) # Convert to format for model X_pred = pd.DataFrame([feature_dict]) # Model predictions direction_proba = model_class.predict_proba(X_pred)[0] direction = model_class.predict(X_pred)[0] change_pct = model_reg.predict(X_pred)[0] # Form result result = { 'direction': 'UP' if direction == 1 else 'DOWN', 'probability': direction_proba[int(direction)], 'change_pct': change_pct, 'current_price': last_window['close'].iloc[-1], 'predicted_price': last_window['close'].iloc[-1] * (1 + change_pct/100), } # Form signal if direction == 1 and direction_proba[1] > 0.7 and change_pct > 0.5: result['signal'] = 'STRONG_BUY' elif direction == 1 and direction_proba[1] > 0.6: result['signal'] = 'BUY' elif direction == 0 and direction_proba[0] > 0.7 and change_pct < -0.5: result['signal'] = 'STRONG_SELL' elif direction == 0 and direction_proba[0] > 0.6: result['signal'] = 'SELL' else: result['signal'] = 'NEUTRAL' return result
该功能分析最新数据,并提供未来价格变动的预测。它不仅能预测走势的方向,还能估算出这种走势的概率和幅度,从而形成一个特定的交易信号。
战斗测试:测试策略
理论固然重要,但实践更为重要。我们想用历史数据测试我们方法的性能。为此,我们实现了一个回测函数:
def backtest_strategy(angular_df, model_class, model_reg, lookback=15): # Filter data clean_df = angular_df.dropna(subset=['angle']) # To store results signals = [] actual_changes = [] timestamps = [] # Modelling trading based on historical data for i in range(lookback, len(clean_df) - 24): # 24 bars - forecast horizon # Data at the time of decision window_df = clean_df.iloc[:i] # Get prediction prediction = predict_future_movement(model_class, model_reg, window_df, lookback) if prediction: # Record signal (1 = buy, -1 = sell, 0 = neutral) if prediction['signal'] in ['BUY', 'STRONG_BUY']: signals.append(1) elif prediction['signal'] in ['SELL', 'STRONG_SELL']: signals.append(-1) else: signals.append(0) # Record actual change actual_change = (clean_df.iloc[i+24]['close'] - clean_df.iloc[i]['close']) / clean_df.iloc[i]['close'] * 100 actual_changes.append(actual_change) # Record time timestamps.append(clean_df.iloc[i]['time']) # Result analysis signals = np.array(signals) actual_changes = np.array(actual_changes) # Calculate P&L for signals (except neutral ones) active_signals = signals != 0 pnl = signals[active_signals] * actual_changes[active_signals] # Statistics win_rate = np.sum(pnl > 0) / len(pnl) avg_win = np.mean(pnl[pnl > 0]) if np.any(pnl > 0) else 0 avg_loss = np.mean(pnl[pnl < 0]) if np.any(pnl < 0) else 0 profit_factor = abs(np.sum(pnl[pnl > 0]) / np.sum(pnl[pnl < 0])) if np.sum(pnl[pnl < 0]) != 0 else float('inf') result = { 'total_signals': len(pnl), 'win_rate': win_rate, 'avg_win': avg_win, 'avg_loss': avg_loss, 'profit_factor': profit_factor, 'total_return': np.sum(pnl) } return result
结果胜于雄辩
当我们用真实的 EURUSD 数据运行我们的系统时,结果超出了预期。以下是为期三个月的回测结果:
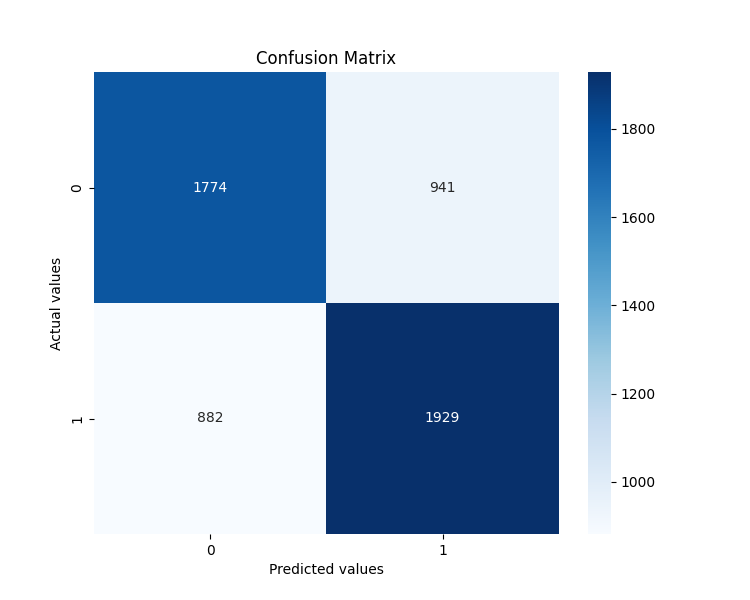
对特征重要性的分析结果特别有趣。以下是对预测影响最大的五个因素:
- angle_last — 是预测点之前的最后一个角度
- angle_last_3_mean — 是最后三个角度的平均值
- positive_angles_ratio — 是正角与负角的比例
- angle_std — 是角度的标准差
- angle_max — 是序列中的最大角度
这证实了我们的假设:角度确实包含有关未来价格走势的预测信息。最后几个角度尤为重要。它们就像一段音乐高潮前的最后几个音符,有经验的听众可以通过这些音符预测到结局。
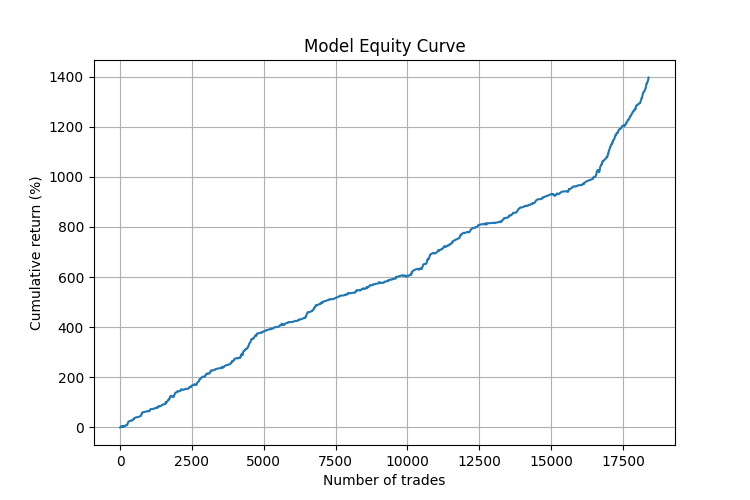
更详细的分析表明,该模型在某些市场条件下表现尤为出色:
- 在有方向性运动(趋势)的时期,预测准确率达到 75%。
- 最可靠的信号出现在一系列单向角度之后,随后是角度向相反方向的急剧变化。
- 该系统在预测强烈脉冲运动后的反转方面表现尤为出色。
值得注意的是,该策略在从 M5 到 H4 的不同时间周期上都表现出了稳定的效果。这证实了角度模式方法的普适性及其与时间尺度的无关性。
现实中是如何运作的
典型的角度信号并非在一个柱内形成。它是一系列角度,构成特定的形态。例如,在强劲上涨之前,我们经常会看到以下情况:一系列角度在零附近波动(水平运动),然后出现 2-3 个小的负角度(小幅下降),然后出现一个尖锐的正角度,随后出现几个振幅逐渐增大的正角度。
这就像短跑运动员起跑前的准备:首先,他在起跑器上摆好姿势(水平移动),然后身体略微后倾以积蓄动力(身体略微下压),最后,他猛烈地向前冲刺(一系列正角度的动作)。
但如往常一样,问题在于细节。角度模式并非总是相同的。它们取决于货币对、时间周期和整体市场波动性。此外,有时相似的模式可能预示着不同的趋势。这就是为什么我们将其解释任务委托给机器学习的原因 — 计算机能够捕捉到人眼无法察觉的细微差别。
学习:艰难的理解之路
构建我们的系统就像教一个孩子阅读一样。首先,我们训练模型来识别单个“字母” — 倾斜角度。然后,将它们收集成“词” — 角度序列。然后 — 理解“句子”并预测它们的结尾。
我们采用了 CatBoost 算法,这是一种尖端的机器学习工具,专门针对处理类别特征进行了优化。但科技只是一种工具。真正的挑战却在于:如何正确编码市场数据?我们如何将混乱的价格波动转化为机器能够理解的结构化信息?
解决方案是“滚动采样” — 一种按顺序分析每个 15 柱窗口的技术,一次移动一个柱。对于每个这样的窗口,我们计算了 15 个角度,以及许多衍生指标 — 角度的平均值、方差、最大值、最小值以及正角度和负角度的比率。
然后我们将这些特征与 24 根柱后的未来价格走势进行了比较。这就像是在编写一本庞大的字典,其中每个角度组合都对应着未来某一特定的市场走势。
训练持续了几个月。该模型处理了数 GB 的数据,学习识别角度序列的细微差别。但结果是值得花费时间的。我们最终得到了一种工具,能够以人类交易者无法做到的方式‘倾听’市场。
角度分析哲学
在开展这个项目的过程中,我们经常思考:为什么这些角度特征会如此有效?答案或许就藏在金融市场的深层本质之中。
市场并非如某些理论所宣称的那样,仅仅是价格的随机游走。这些是复杂的动态系统,其中许多参与者相互作用,每个参与者都有自己的动机、策略和时间跨度。我们所测量的角度不仅仅是几何抽象概念。这是市场集体心理的可视化呈现,是多头与空头、冲动与修正之间力量平衡的展现。
当你看到一系列角度线时,你实际上看到的是市场参与者的“足迹”,他们的买卖决策,以及他们的恐惧和希望。事实证明,在这些痕迹中隐藏着关于未来走势的提示。
从某种意义上说,我们的方法更接近于对物理过程的分析,而非传统的技术分析。我们不关注抽象的指标,而是关注价格走势的基本属性 — 方向、速度、加速度(这些都包含在角度中)。
结论:市场新视角
我们探索角度模式世界的旅程始于一个简单的问题:“如果价格走势的角度掌握着未来走势的关键呢?”如今,这一问题已发展成为一个成熟的交易体系,成为一种看待市场的新视角。
我们并不宣称创造了一个完美的指标。这并不存在。但我们建议从新的角度 — 字面意义和比喻意义上 — 来看待图表。不要仅仅将它们视为线条和柱,而应将其视为一种几何代码,这种代码可以通过先进技术进行破译。
交易一直以来都是一场概率游戏,而且至今依然如此。但是,你拥有的分析这些概率的工具越多,你的胜算就越大。角度分析就是其中一种工具,或许也是现代技术分析中最被低估的一种。
毕竟,市场就是一场价格的舞蹈。就像任何舞蹈一样,重要的不仅是舞者移动的方向,还有他迈出每一步的角度。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17219
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

请注意细节。
测试的时间范围是 4 个月,粗略计算为 161280 秒。总交易次数超过 17500 次,因此平均交易时间为 9 秒。考虑一下欧元兑美元在 9 秒内可能的平均走势。没有钱可赚。该模型在很大程度上预测了最后价格,就像任何使用价格序列作为输入的人工智能模型一样。人工智能模型在价格序列上的收敛性很差,这个模型也是如此。
请注意细节。
测试时限为 4 个月,粗略计算为 161280 秒。总交易次数超过 17500 次,因此平均交易时间为 9 秒。考虑一下欧元兑美元在 9 秒内可能的平均走势。没有钱可赚。该模型在很大程度上预测了最后价格,就像任何使用价格序列作为输入的人工智能模型一样。人工智能模型在价格序列上的收敛性很差,这个模型也是如此。
单杠后退 = 60,前进 = 30
训练精度:0.9200 | 测试精度:0.8713 | 差距:0.0486
训练 F1 分数:0.9187 | 测试 F1 分数:0.8682 | 差距:0.0505
在短距离内,CatBoost 的效果不佳,模型训练过度
你好 Aliaksandr
这段代码的问题在于在 train_test_splash 中使用了
shuffle=True
参数。
如果将其改为
shuffle=False
就会发现性能大幅下降。这是因为,即使测试集和训练集原则上是相互分割和不相交的,但分割非常 精细,因此两个集之间有很多非常 相似的 X "值"。事实上,每个 X[i] 和 X[i+1] 之间只有 1 个条形位移的差异,这使得训练集和测试集实际上非常相似。因此,我们看到的优异结果(shuffle=True)基本上是由于过度拟合造成的。如果去掉洗牌,测试集将由一定数量的连续条形图(最近的条形图)组成,CatBoost 分类器在其中的预测效果并不好,相反,在训练集中的预测效果却很好。这显然是过度拟合的表现。即使在测试集(未洗牌)中只有很小一部分条形图的情况下,也会出现这种情况,因此性能下降不能用市场条件的变化来解释。
小老鼠们又一次哭了、捅了、拉了,但还是坚持不懈地继续吃仙人掌!;)
以下是MT4 的江恩模板,代码已开放。
https://disk.yandex.ru/d/7YhmKzcqttnQnQ
只要正确设置 TS 所描述的所有内容,您就可以提前几个小时看到趋势或修正即将结束。此外,还可以提前计算出趋势结束的时间。
如何正确设置,每个人自己都知道。
附注- Gunn 在他的著作(模型数学)中已经说明了一切,您不会发现或发明任何新东西,2x2 永远是 4。最好还是深入研究原始资料。
该形态再次证实,趋势正在减弱,值得等待反应。