
数据科学与机器学习(第四十部分):斐波那契回调位在机器学习中的应用

内容
- 斐波那契数列的起源
- 从交易视角理解斐波那契回调位
- 利用斐波那契回调位构建目标变量
- 基于斐波那契目标变量训练分类模型
- 基于由斐波那契构建的目标变量训练回归模型
- 在策略测试器中测试基于斐波那契的机器学习模型
- 后记
斐波那契数列的起源
斐波那契数列可追溯至中世纪数学家比萨的列奥纳多,他更为人熟知的名字是斐波那契。
在他1202年出版的著作《算盘全书》("Liber Abaci")中,斐波那契引入了这一数列,也就是如今广为人知的斐波那契数列。该数列以0和1为起始,此后每一项均为前两项之和。
这一数列十分重要,因为它广泛存在于各类自然现象中,包括动植物的生长模式。
在生物学领域,部分动物与昆虫外壳上呈现的对数螺旋形态近似符合斐波那契数列规律,尽管并非完全精准。
类似斐波那契式的增长规律,同样可见于兔子种群繁衍与蜜蜂家族谱系结构中。
在部分哺乳动物乃至人类的DNA构成中,也能发现斐波那契数列的痕迹。

这些数字无处不在,几乎在所有领域都能见到它们的身影。以下是研究斐波那契数列时常用的几个术语:
斐波那契数列
在数学中,斐波那契数列是指每一项均等于其前两项之和的数列。构成该数列的数字被称为斐波那契数。

斐波那契数列可用以下公式表示:
![]()
其中n大于1(n > 1)。
黄金比例
这是一个描述两个数值之间关系的数学概念:较小值与较大值的比值,等于较大值与两者之和的比值。
黄金比例约等于1.6180339887,用希腊字母φ(Phi) 表示。
黄金比例与φ并不完全相同,但两者非常接近!把斐波那契数列中较大的数除以较小的数,所得结果会越来越接近 φ。
用较大数除以较小数,结果会接近φ。在斐波那契数列中越往后计算,比值就越接近φ。但结果永远不会完全等于φ。因为φ是无法用分数表示的无理数。这似乎很不合常理!

这一数值在各种自然结构与人工建筑中均有体现,被视为体现美与和谐的普适原则。
从交易视角理解斐波那契回调位
斐波那契回调位是一组水平线条,用于标示价格可能出现反转的潜在支撑位与阻力位,其绘制基于我们上文介绍的斐波那契数列原理。
这是交易者们在MetaTrader 5(MT5)中的常用工具,用途广泛,例如设置交易目标(止损与止盈)并且识别支撑和阻力线,以判断价格最有可能发生反转的位置。
在MetaTrader 5中,该工具可通过以下路径找到:插入 → 图形对象 → 斐波那契

下图为在欧元兑美元(EURUSD)1小时周期图表上绘制的斐波那契回调工具。

尽管斐波那契回调工具在提供交易价位、识别市场反转与设置交易目标方面表现可靠,我们仍将从机器学习与人工智能(AI)角度探究斐波那契水平的有效性,特别是黄金比例(61.8%或0.618)。
我们将探究多种通过数学方式构建斐波那契水平的方法,并将其用于制作目标变量,供机器学习模型理解与预测市场方向。
利用斐波那契回调位构建目标变量
在监督式机器学习中,要训练模型理解数据间的关联关系,需要精心构造目标变量。斐波那契水平本身就是代表特定价位的数值,因此我们可以提取对应斐波那契位置的市场价格,将其作为回归任务的目标变量。
对于分类任务,我们则根据价格相对于斐波那契线的运行情况来构建类别标签。例如:在上涨趋势中,如果市场在后续若干K线突破了计算出的斐波那契水平,可将其标记为看涨信号(记为1);反之,如果价格向下跌破设定的斐波那契水平,则标记为看跌信号(记为0)。其他无明显方向的情况可标记为无信号(记为- 1)。
对于分类问题
导入:
import pandas as pd import numpy as np
函数:
def create_fib_clftargetvar(price: pd.Series, lookback_window: int=10, lookahead_window: int=10, fib_level: float=0.618): """ Creates a target variable based on Fibonacci breakthroughs in price data. Parameters: - price: pd.Series of price data (close, open, high, or low) - lookback_window: int - number of past periods to calculate high/low - lookahead_window: int - number of future periods to assess breakout - fib_level: float - Fibonacci retracement level (e.g. 0.618) Returns: - pd.Series: with values 1 => Bullish fib level reached 0 => Bearish fib level reached -1 => False breakthrough or no fib hit """ high = price.rolling(lookback_window).max() low = price.rolling(lookback_window).min() fib_level_value = high - (high - low) * fib_level # calculate the Fibonacci level in market price price_ahead = price.shift(-lookahead_window) # future price values target_var = [] for i in range(len(price)): if np.isnan(price_ahead.iloc[i]) or np.isnan(fib_level_value.iloc[i]) or np.isnan(price.iloc[i]): target_var.append(np.nan) continue # let's detect bull and bearish movement afterwards if price_ahead.iloc[i] > price.iloc[i]: # The market went bullish if price_ahead.iloc[i] >= fib_level_value.iloc[i]: target_var.append(1) # bullish Fibonacci target reached else: target_var.append(-1) # false breakthrough else: # The market went bearish if price_ahead.iloc[i] <= fib_level_value.iloc[i]: target_var.append(0) # bearish Fibonacci target reached else: target_var.append(-1) # false breakthrough return target_var
市场中的斐波那契水平通过以下公式计算:
fib_level_value = high - (high - low) * fib_level
由于这是一个分类问题,我们需要基于前序斐波那契水平预测市场反应,因此必须参考未来行情来识别趋势。随后,我们基于设定的前瞻窗口(lookahead_window)检查未来价格是否向上突破斐波那契水平(对应上升趋势)或向下跌破斐波那契水平(对应下降趋势),以分别生成买入或卖出信号。如果价格在两个方向均未触及斐波那契水平,则标记为无信号。
接下来,我们将通过这个函数构建目标变量,并将计算结果添加到数据帧中。
df["Fib signals"] = create_fib_clftargetvar(price=df["Close"], lookback_window=10, lookahead_window=5, fib_level=0.618) df.dropna(inplace=True) # drop nan(s) caused by the shifting operation df
结果:
| 开盘 | 高 | 低 | 收盘 | 斐波那契信号 | |
|---|---|---|---|---|---|
| 9 | 1.3492 | 1.3495 | 1.3361 | 1.3362 | 0.0 |
| 10 | 1.3364 | 1.3405 | 1.3350 | 1.3371 | 0.0 |
| 11 | 1.3370 | 1.3376 | 1.3277 | 1.3300 | 0.0 |
| 12 | 1.3302 | 1.3313 | 1.3248 | 1.3279 | -1.0 |
| 13 | 1.3279 | 1.3293 | 1.3260 | 1.3266 | 0.0 |
对于回归问题
def create_fib_regtargetvar(price: pd.Series, lookback_window: int=10, fib_level: float=0.618): """ This function helps us in calculating the target variable based on fibonacci breakthroughs given a price price: Can be close, open, high, low """ high = price.rolling(lookback_window).max() low = price.rolling(lookback_window).min() return high - (high - low) * fib_level
对于回归问题,我们不需要偏移数值来获取未来信息。因为在人工交易中,我们是基于回溯窗口(lookback_window)计算出的斐波那契水平,来对比未来价格是否会向上或向下突破它。
我们的目标是训练回归模型,使其能够基于回溯窗口预测下一个斐波那契水平值。
df["Fibonacci Level"] = create_fib_regtargetvar(price=df["Close"], lookback_window=10, fib_level=0.618) df.dropna(inplace=True) df.head(5)
添加斐波那契水平列之后生成的数据帧如下:
| 开盘 | 高 | 低 | 收盘 | 斐波那契水平 | |
|---|---|---|---|---|---|
| 9 | 1.3492 | 1.3495 | 1.3361 | 1.3362 | 1.343840 |
| 10 | 1.3364 | 1.3405 | 1.3350 | 1.3371 | 1.342923 |
| 11 | 1.3370 | 1.3376 | 1.3277 | 1.3300 | 1.339015 |
| 12 | 1.3302 | 1.3313 | 1.3248 | 1.3279 | 1.337717 |
| 13 | 1.3279 | 1.3293 | 1.3260 | 1.3266 | 1.335195 |
基于斐波那契目标变量训练分类模型
我们从名为“斐波那契信号”(Fib signals)的分类目标变量开始,使用简单的随机森林分类器(RandomForestClassifier)模型对此数据进行训练。
导入:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.utils.class_weight import compute_class_weight from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler
训练集-测试集划分:
X = df.drop(columns=[ "Fib signals" ]) y = df["Fib signals"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False)
模型:
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train) weight_dict = dict(zip(np.unique(y_train), class_weights)) model = RandomForestClassifier(n_estimators=100, min_samples_split=2, max_depth=10, class_weight=weight_dict, random_state=42 ) clf_pipeline = Pipeline(steps=[ ("scaler", RobustScaler()), ("rfc", model) ]) clf_pipeline.fit(X_train, y_train)
随机森林属于基于决策树的模型,通常不需要进行特征缩放。但由于开盘价、最高价、最低价、收盘价(OHLC)均为连续变量,会随时间不断变化并产生异常值,因此鲁棒缩放器有助于抑制此类问题。
最后,我们可以在训练集和测试集上分别测试该分类模型。
y_train_pred = clf_pipeline.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred)) y_test_pred = clf_pipeline.predict(X_test) print("Test Classification report\n",classification_report(y_test, y_test_pred))
结果:
Train Classification report precision recall f1-score support -1.0 0.53 0.55 0.54 4403 0.0 0.59 0.64 0.61 7122 1.0 0.67 0.60 0.64 8294 accuracy 0.61 19819 macro avg 0.60 0.60 0.60 19819 weighted avg 0.61 0.61 0.61 19819 Test Classification report precision recall f1-score support -1.0 0.22 0.22 0.22 1810 0.0 0.38 0.60 0.46 3181 1.0 0.42 0.20 0.27 3504 accuracy 0.35 8495 macro avg 0.34 0.34 0.32 8495 weighted avg 0.36 0.35 0.33 8495
训练集上的结果看起来相当不错,但测试集上的表现很差。这表明模型无法理解训练数据之外的样本中存在的市场规律。
造成这一结果的原因可能有多种,例如:缺乏足够的特征来捕捉市场中有价值的规律(仅使用OHLC价格数据可能并不充分);构建目标变量时,仅通过前瞻窗口的下一根 K 线来判断趋势的方法过于粗糙,导致模型忽略了价格可能在中间K线突破斐波那契水平的情况。
由于本文的目的是训练模型预测未来价格是否会突破斐波那契水平,分类报告得出的这一结果可能具有误导性,不必追求完美。我们暂且保留该模型,并将在实盘交易环境中分析它的实际表现。
接下来,我们将训练好的模型保存为ONNX格式,以便在MQL5编程语言中外部调用。
import skl2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
# Define the initial type of the model’s input initial_type = [('input', FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX onnx_model = convert_sklearn(clf_pipeline, initial_types=initial_type, target_opset=13) # Save the ONNX model to a file with open(f"{symbol}.{timeframe}.Fibonnacitarg-RFC.onnx", "wb") as f: f.write(onnx_model.SerializeToString())
基于斐波那契目标变量训练回归模型
训练回归模型可遵循相同的流程,仅模型类型与目标变量有所不同。
导入:
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import r2_score
训练集-测试集划分:
X = df.drop(columns=[ "Fibonacci Level" ]) y = df["Fibonacci Level"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False)
随机森林回归模型:
model = RandomForestRegressor(n_estimators=100, min_samples_split=2, max_depth=10, random_state=42 ) reg_pipeline = Pipeline(steps=[ ("scaler", RobustScaler()), ("rfr", model) ]) reg_pipeline.fit(X_train, y_train)
最后,我们可以在训练集和测试集上分别测试该回归模型。
y_train_pred = reg_pipeline.predict(X_train) print("Train accuracy score:",r2_score(y_train, y_train_pred)) y_test_pred = reg_pipeline.predict(X_test) print("Test accuracy score:",r2_score(y_test, y_test_pred))
结果:
训练集准确率得分: 0.9990321734526452 测试集准确率得分: 0.9565827587164671
我们无法仅凭观测到的R²决定系数对回归模型做出全面的评判,但在测试集上达到0.9565已经是相当不错的结果。
让我们将这个训练好的模型保存为ONNX格式,以便在MQL5编程语言中外部调用。
# Define the initial type of the model’s input initial_type = [('input', FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX onnx_model = convert_sklearn(reg_pipeline, initial_types=initial_type, target_opset=13) # Save the ONNX model to a file with open(f"{symbol}.{timeframe}.Fibonnacitarg-RFR.onnx", "wb") as f: f.write(onnx_model.SerializeToString())
现在,让我们在实盘交易环境中测试这两个模型的预测能力。
在策略测试器中测试基于斐波那契的机器学习模型
我们首先将ONNX格式的随机森林模型作为资源文件,添加到我们的智能交易系统(EA)中。
#resource "\\Files\\EURUSD.PERIOD_H4.Fibonnacitarg-RFC.onnx" as uchar rfc_onnx[] #resource "\\Files\\EURUSD.PERIOD_H4.Fibonnacitarg-RFR.onnx" as uchar rfr_onnx[]
随后导入一个库,以帮助我们加载ONNX格式的随机森林分类器和回归模型。
#include <Random Forest.mqh>
CRandomForestClassifier rfc;
CRandomForestRegressor rfr; 我们需要与训练数据中应用的相同的前瞻和回溯窗口值。这些值在确定持仓时长和何时平仓方面非常有用。
input group "Models configs"; input target_var_type fib_target = CLASSIFIER; //Model type input int lookahead_window = 5; input int lookback_window = 10;
变量fib_target输入将帮助我们选择要使用的模型类型。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe_)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe_)); return INIT_FAILED; } //--- m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); //--- switch(fib_target) { case REGRESSOR: if (!rfr.Init(rfr_onnx)) { printf("%s failed to initialize the random forest regressor",__FUNCTION__); return INIT_FAILED; } break; case CLASSIFIER: if (!rfc.Init(rfc_onnx)) { printf("%s failed to initialize the random forest classifier",__FUNCTION__); return INIT_FAILED; } break; } //--- return(INIT_SUCCEEDED); }
在OnTick函数内部,我们将OHLC值(与训练数据中使用的相同)传入模型以获取信号。
这些信号随后用于开立买入和卖出交易。
void OnTick() { //--- Getting signals from the model if (!isNewBar()) return; vector x = { iOpen(Symbol(), Period(), 1), iHigh(Symbol(), Period(), 1), iLow(Symbol(), Period(), 1), iClose(Symbol(), Period(), 1) }; long signal = 0; switch(fib_target) { case REGRESSOR: { double pred_fib = rfr.predict(x); signal = pred_fib>iClose(Symbol(), Period(), 0)?1:0; //If the predicted fibonacci is greater than the current close price, thats bullish otherwise thats bearish signal } break; case CLASSIFIER: signal = rfc.predict(x).cls; break; } //--- Trading based on the signals received from the model MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid); } //--- Closing trades switch(fib_target) { case CLASSIFIER: CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead_window)*60); //Close the trade after a certain lookahead and according the the trained timeframe break; case REGRESSOR: CloseTradeAfterTime((Timeframe2Minutes(Period())*lookback_window)*60); //Close the trade after a certain lookahead and according the the trained timeframe break; } }
交易的平仓取决于所选的模型类型、前瞻窗口值和回溯窗口值。
当选择分类器模型时,在当前周期上经过等于lookahead_window数量的K线后将平仓。
当选择回归器模型时,在当前周期上经过等于lookback_window数量的K线后将平仓。
这与我们在Python脚本中构建目标变量的逻辑保持一致。
最后,我们可以在策略测试器中对这两个模型进行测试。
由于训练数据取自2005年1月1日至2023年1月1日,我们将使用2023年1月1日至2023年12月31日的数据作为样本外数据来测试模型效果。
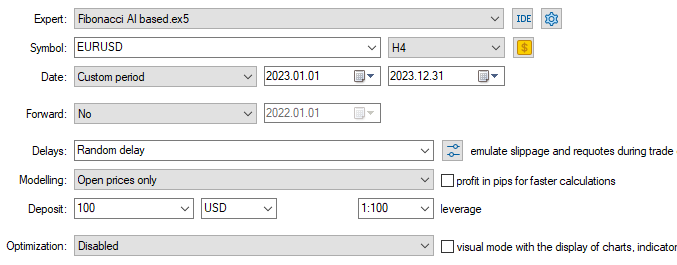
模型类型:分类器
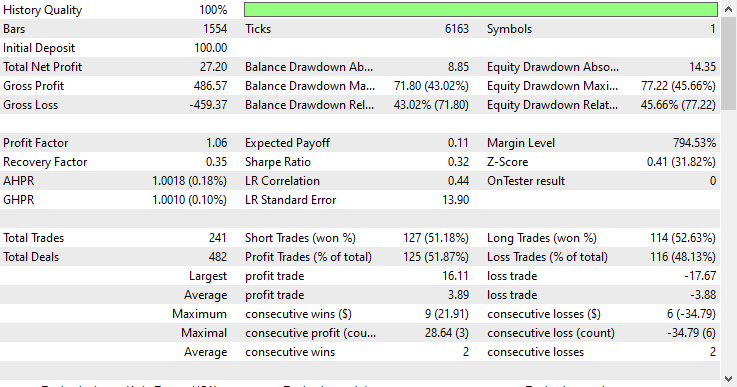
模型类型:回归器
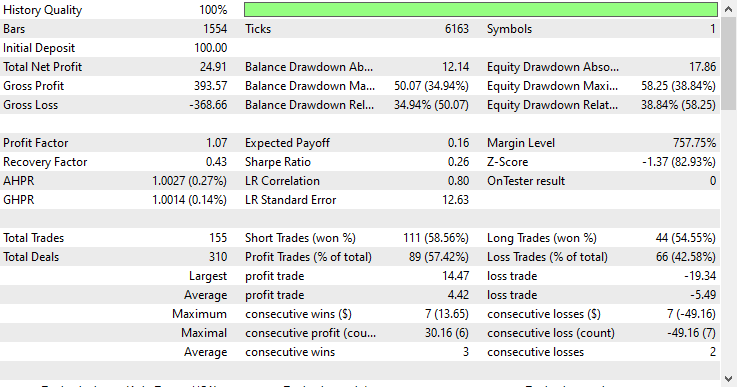
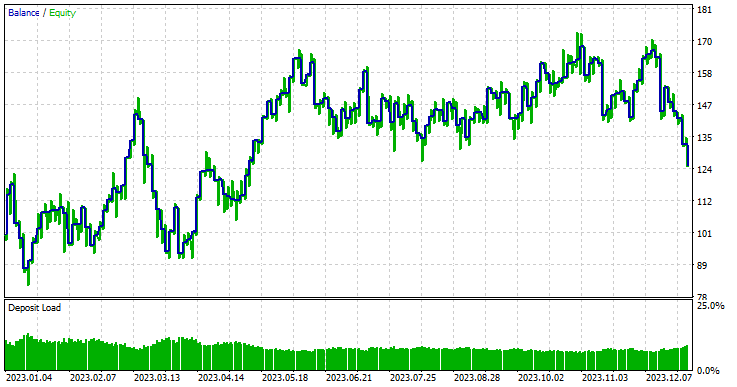
考虑到这是样本外数据,回归模型的表现格外出色,胜率达到57.42%。
为了简化逻辑并让回归模型更具实用价值,我在交易机器人(如EA)内部,将随机森林回归模型输出的连续预测值转换为了二元信号。
signal = pred_fib>iClose(Symbol(), Period(), 0)?1:0; //If the predicted Fibonacci is greater than the current close price, that's bullish otherwise that's bearish signal
这彻底改变了我们对预测斐波那契水平的解读方式。因为与人工交易不同,我们通常在趋势确认信号出现后才开仓,此时往往已处于趋势末期。我们将交易目标设定为某个斐波那契水平(通常为61.8%)。
采用这种方法时,我们假设机器学习模型已经在训练数据的指定回溯窗口与前瞻窗口上学会了这类规律,因此只需直接开仓,并按照设定的K线数量持有即可。
其核心关键在于前瞻窗口与回溯窗口的取值。主要原因是在人工交易中使用斐波那契工具时,我们并不会明确用多少根K线来计算高低点,通常只是凭感觉在合适位置绘制工具。
尽管该工具在手动交易中效果尚可,但它很容易误导我们,让我们以为自己画对了位置,而实际上只是随意绘制,并没有清晰的规则。
如果想要深入研究斐波那契水平在构建目标变量及通用机器学习场景中的有效性,前瞻窗口与回溯窗口这两个参数正是我们需要重点优化的对象。
总结
正如上文策略测试报告中回归模型所展示的,斐波那契回调与水平位是构建机器学习目标变量的高效方法。即便仅使用开盘价、最高价、最低价、收盘价这类特征较少、规律不明显的简单输入,模型依然能从斐波那契水平中学习到有价值的规律,取得的效果远优于随机猜测。
在我看来,无论从哪个角度评判,这一结果都相当出色。
然而,目前的这套思路还不够完善,我们需要为数据加入更多特征,例如指标数值、交易策略确认信号等,以帮助基于斐波那契的模型捕捉市场中更复杂的走势规律。同时,也可以尝试探索其他斐波那契水平位。
我相信,经过进一步优化后,该方法在股票和指数市场会更加有效 —— 这些市场在长期牛市中经常出现规律性回调;同样也适用于日线等更高周期,因为这类周期的数据“噪音更低”。
附件表
| 文件名与路径 | 说明/用法 |
|---|---|
| Experts\Fibonacci AI based.mq5 | 用于测试机器学习模型的主EA。 |
| Include\Random Forest.mqh | 包含用于加载和部署.ONNX格式的随机森林分类器与回归器模型的相关类。 |
| Files\*.onnx | ONNX格式的机器学习模型。 |
| Files\*.csv | 包含用于训练机器学习模型的数据集的CSV文件。 |
| Python\fibbonanci-in-ml.ipynb | 用于数据处理与随机森林模型训练的Python脚本。 |
来源与参考文献
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18078
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
