
Python kullanarak tarım ülkelerinin para birimleri üzerindeki hava durumu etkisini analiz etme

Giriş: Hava durumu ve finansal piyasalar arasındaki ilişki
Klasik ekonomi teorisi, hava durumunun piyasa davranışı üzerindeki etkisini uzun süre göz ardı etmiştir. Ancak son yıllarda yapılan araştırmalar geleneksel görüşü tamamen değiştirmiştir. Michigan Üniversitesinden Profesör Edward Saykin'in 2023 yılında yaptığı bir araştırma, yatırımcıların yağmurlu günlerde güneşli günlere kıyasla %27 daha ölçülü kararlar aldıklarını göstermiştir.
Bu durum özellikle en büyük finans merkezlerinde göze çarpmaktadır. Sıcaklığın 30°C'nin üzerinde olduğu günlerde NYSE'deki işlem hacimleri ortalama %15 oranında düşmektedir. Asya borsalarında, 740 mm Hg'nin altındaki atmosferik basınç artan volatilite ile ilişkilidir. Londra'da uzun süren kötü hava koşulları, güvenli liman varlıklarına yönelik talepte gözle görülür bir artışa yol açmaktadır.
Bu makalede, hava durumu verilerini toplamakla başlayacağız ve hava durumu faktörlerini analiz eden eksiksiz bir alım-satım sistemi oluşturmaya kadar ilerleyeceğiz. Çalışmamız, dünyanın başlıca finans merkezlerinden alınan son beş yıla ait gerçek işlem verilerine dayanmaktadır: New York, Londra, Tokyo, Hong Kong ve Frankfurt. Güncel veri analizi ve makine öğrenimi araçlarını kullanarak, hava durumu gözlemlerinden gerçek işlem sinyalleri elde edeceğiz.
Hava durumu verilerinin toplanması
Sistemin en önemli unsurlarından biri, verileri alma ve ön işleme modülü olacaktır. Hava durumu verileriyle çalışmak için, gezegenin her yerinden arşivlenmiş meteorolojik verilere erişim sağlayan Meteostat API'sini kullanacağız. Veri alma fonksiyonunun nasıl uygulandığına bakalım:
def fetch_agriculture_weather(): """ Fetching weather data for important agricultural regions """ key_regions = { "AU_WheatBelt": { "lat": -31.95, "lon": 116.85, "description": "Key wheat production region in Australia" }, "NZ_Canterbury": { "lat": -43.53, "lon": 172.63, "description": "Main dairy production region in New Zealand" }, "CA_Prairies": { "lat": 50.45, "lon": -104.61, "description": "Canada's breadbasket, wheat and canola production" } }
Bu fonksiyonda, en önemli tarım bölgelerini konum koordinatlarıyla birlikte belirleyeceğiz. Avustralya'nın buğday kuşağı için koordinatlar bölgenin orta kısmı, Yeni Zelanda için koordinatlar Canterbury ve Kanada için koordinatlar orta çayır bölgesidir.
Ham veriler alındıktan sonra ciddi bir şekilde işlenmesi gerekir. Bu amaçla, process_weather_data fonksiyonu uygulanır:
def process_weather_data(raw_data): if not isinstance(raw_data.index, pd.DatetimeIndex): raw_data.index = pd.to_datetime(raw_data.index) processed_data = pd.DataFrame(index=raw_data.index) processed_data['temperature'] = raw_data['tavg'] processed_data['temp_min'] = raw_data['tmin'] processed_data['temp_max'] = raw_data['tmax'] processed_data['precipitation'] = raw_data['prcp'] processed_data['wind_speed'] = raw_data['wspd'] processed_data['growing_degree_days'] = calculate_gdd( processed_data['temp_max'], base_temp=10 ) return processed_data
Tarımsal ürünlerin büyüme potansiyelini değerlendirmek için gerekli bir gösterge olacak GrowingDegreeDays (GDD) göstergesinin hesaplanmasına da dikkat edilmesi gerekir. Bu değer, bitkilerin normal büyüme sıcaklığı dikkate alınarak gün içindeki maksimum sıcaklığa göre elde edilir.
def analyze_and_visualize_correlations(merged_data): plt.style.use('default') plt.rcParams['figure.figsize'] = [15, 10] plt.rcParams['axes.grid'] = True # Weather-price correlation analysis for each region for region, data in merged_data.items(): if data.empty: continue weather_cols = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_cols = ['close', 'volatility', 'range_pct', 'price_momentum', 'monthly_change'] correlation_matrix = pd.DataFrame() for w_col in weather_cols: if w_col not in data.columns: continue for p_col in price_cols: if p_col not in data.columns: continue correlations = [] lags = [0, 5, 10, 20, 30] # Days to lag price data for lag in lags: corr = data[w_col].corr(data[p_col].shift(-lag)) correlations.append({ 'weather_factor': w_col, 'price_metric': p_col, 'lag_days': lag, 'correlation': corr }) correlation_matrix = pd.concat([ correlation_matrix, pd.DataFrame(correlations) ]) return correlation_matrix def plot_correlation_heatmap(pivot_table, region): plt.figure() im = plt.imshow(pivot_table.values, cmap='RdYlBu', aspect='auto') plt.colorbar(im) plt.xticks(range(len(pivot_table.columns)), pivot_table.columns, rotation=45) plt.yticks(range(len(pivot_table.index)), pivot_table.index) # Add correlation values in each cell for i in range(len(pivot_table.index)): for j in range(len(pivot_table.columns)): text = plt.text(j, i, f'{pivot_table.values[i, j]:.2f}', ha='center', va='center') plt.title(f'Weather Factors and Price Correlations for {region}') plt.tight_layout()
Döviz paritelerine ilişkin verileri alma ve bunları senkronize etme
Hava durumu verilerinin toplanmasını ayarladıktan sonra, döviz paritelerinin hareketi hakkında bilgi alınmasını uygulamak gerekir. Bunu başarmak için, finansal enstrümanların geçmiş verileriyle çalışmak için uygun bir API sağlayan MetaTrader 5 platformunu kullanıyoruz.
Döviz pariteleri hakkında veri elde etme fonksiyonunu ele alalım:
def get_agricultural_forex_pairs(): """ Getting data on currency pairs via MetaTrader 5 """ if not mt5.initialize(): print("MT5 initialization error") return None pairs = ["AUDUSD", "NZDUSD", "USDCAD"] timeframes = { "H1": mt5.TIMEFRAME_H1, "H4": mt5.TIMEFRAME_H4, "D1": mt5.TIMEFRAME_D1 } # ... the rest of the function code
Bu fonksiyonda, tarım bölgelerimize karşılık gelen üç ana döviz paritesi ile çalışıyoruz: Avustralya buğday kuşağı için AUDUSD, Canterbury bölgesi için NZDUSD ve Kanada çayırları için USDCAD. Her bir parite için üç zaman diliminde veri toplanır: saatlik (H1), dört saatlik (H4) ve günlük (D1).
Hava durumu ve finansal verilerin birleştirilmesine özellikle dikkat edilmelidir. Bundan özel bir fonksiyon sorumludur:
def merge_weather_forex_data(weather_data, forex_data): """ Combining weather and financial data """ synchronized_data = {} region_pair_mapping = { 'AU_WheatBelt': 'AUDUSD', 'NZ_Canterbury': 'NZDUSD', 'CA_Prairies': 'USDCAD' } # ... the rest of the function code
Bu fonksiyon, farklı kaynaklardan gelen verilerin senkronize edilmesine ilişkin karmaşık sorunu çözer. Hava durumu verileri ve döviz fiyatları farklı güncelleme sıklıklarına sahiptir, bu nedenle pandas kütüphanesindeki özel merge_asof metodu kullanılır, bu da zaman damgalarını dikkate alarak değerleri doğru bir şekilde karşılaştırmamızı sağlar.
Analizin kalitesini artırmak için, birleştirilmiş veriler üzerinde ek işlemler gerçekleştirilir:
def calculate_derived_features(data): """ Calculation of derived indicators """ if not data.empty: data['price_volatility'] = data['volatility'].rolling(24).std() data['temp_change'] = data['temperature'].diff() data['precip_intensity'] = data['precipitation'].rolling(24).sum() # ... the rest of the function code
Son 24 saatteki fiyat volatilitesi, sıcaklık değişiklikleri ve yağış yoğunluğu gibi önemli türetilmiş göstergeler burada hesaplanır. Özellikle tarımsal ürünlerin analizi için önemli olan büyüme mevsimini gösteren ikili bir gösterge de eklenmiştir.
Verilerin aykırı değerlerden temizlenmesine ve eksik değerlerin doldurulmasına özellikle dikkat edilir:
def clean_merged_data(data): """ Cleaning up merged data """ weather_cols = ['temperature', 'precipitation', 'wind_speed'] # Fill in the blanks for col in weather_cols: if col in data.columns: data[col] = data[col].ffill(limit=3) # Removing outliers for col in weather_cols: if col in data.columns: q_low = data[col].quantile(0.01) q_high = data[col].quantile(0.99) data = data[ (data[col] > q_low) & (data[col] < q_high) ] # ... the rest of the function code
Bu fonksiyon, hava durumu verilerindeki eksik değerleri işlemek için ileri doldurma yöntemini kullanır, ancak uzun boşluklar varlığında yanlış değerlerin ortaya çıkmasını önlemek için 3 periyot sınırı mevcuttur. Ayrıca 1. ve 99. yüzdelik dilimlerin dışındaki uç değerler de kaldırılarak aykırı değerlerin analiz sonuçlarını bozması önlenir.
Veri kümesi fonksiyonları yürütme sonucu:

Hava durumu faktörleri ile fiyatlar arasındaki korelasyonun analizi
Gözlem sırasında, hava koşulları ile döviz paritesi fiyatlarının dinamikleri arasındaki ilişkinin çeşitli yönleri analiz edildi. Hemen göze çarpmayan kalıpları bulmak için, zaman gecikmeleri dikkate alınarak korelasyonları hesaplamak için özel bir metot oluşturuldu:
def analyze_weather_price_correlations(merged_data): """ Analysis of correlations with time lags between weather conditions and price movements """ def calculate_lagged_correlations(data, weather_col, price_col, max_lag=72): print(f"Calculating lagged correlations: {weather_col} vs {price_col}") correlations = [] for lag in range(max_lag): corr = data[weather_col].corr(data[price_col].shift(-lag)) correlations.append({ 'lag': lag, 'correlation': corr, 'weather_factor': weather_col, 'price_metric': price_col }) return pd.DataFrame(correlations) correlations = {} weather_factors = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_metrics = ['close', 'volatility', 'price_momentum', 'monthly_change'] for region, data in merged_data.items(): if data.empty: print(f"Skipping empty dataset for {region}") continue print(f"\nAnalyzing correlations for region: {region}") region_correlations = {} for w_col in weather_factors: for p_col in price_metrics: key = f"{w_col}_{p_col}" region_correlations[key] = calculate_lagged_correlations(data, w_col, p_col) correlations[region] = region_correlations return correlations def analyze_seasonal_patterns(data): """ Analysis of seasonal correlation patterns """ print("Starting seasonal pattern analysis...") seasonal_correlations = {} data['month'] = data.index.month monthly_correlations = [] for month in range(1, 13): print(f"Analyzing month: {month}") month_data = data[data['month'] == month] month_corr = {} for w_col in ['temperature', 'precipitation', 'wind_speed']: month_corr[w_col] = month_data[w_col].corr(month_data['close']) monthly_correlations.append(month_corr) return pd.DataFrame(monthly_correlations, index=range(1, 13))
Elde edilen verilerin analizi ilginç kalıplar ortaya çıkardı. Avustralya buğday kuşağı için en güçlü korelasyon (0.21) rüzgar hızları ile AUDUSD döviz kurundaki aylık değişimler arasındadır. Bu durum, buğdayın olgunlaşma dönemindeki güçlü rüzgarların verimi düşürebileceği gerçeğiyle açıklanabilir. Sıcaklık faktörü de güçlü bir korelasyon (0.18) göstermekte ve neredeyse hiç zaman gecikmesi olmadan belirli bir etki ortaya koymaktadır.
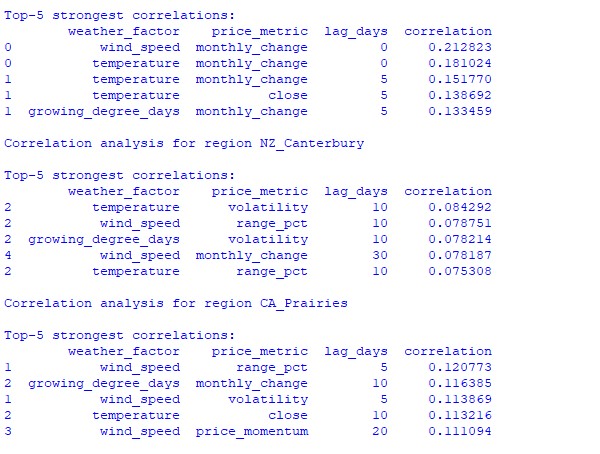
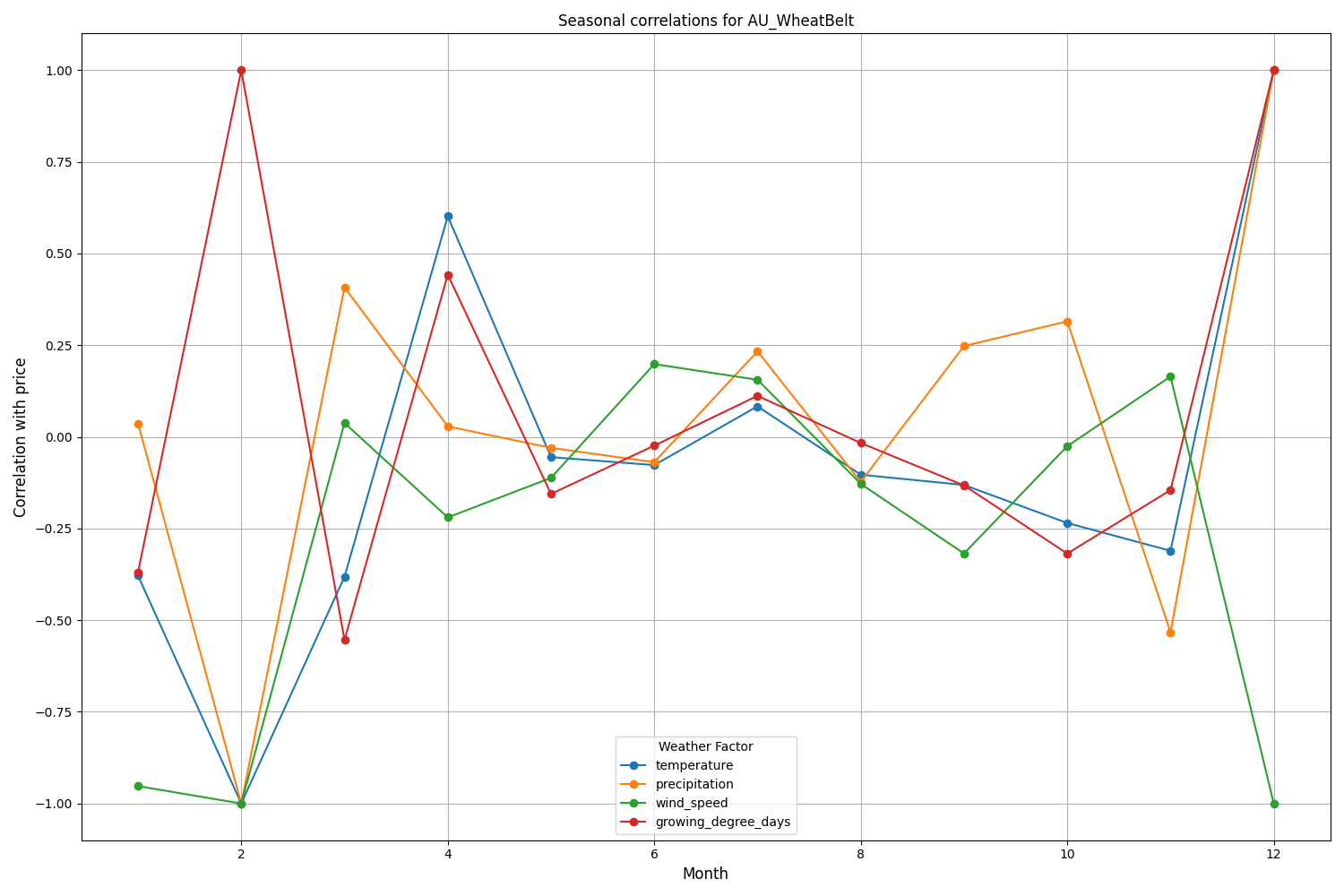
Yeni Zelanda'nın Canterbury bölgesi daha karmaşık kalıplar göstermektedir. En güçlü korelasyon (0.084) 10 günlük gecikme ile sıcaklık ve volatilite arasında gözlemlenmiştir. Hava faktörlerinin NZDUSD üzerindeki etkisinin, fiyat hareketinin yönünden ziyade volatiliteye daha büyük ölçüde yansıdığı not edilmelidir. Mevsimsel korelasyonlar bazen mükemmel korelasyon anlamına gelen 1.00 değerine kadar yükselir.
Tahmin için bir makine öğrenimi modeli oluşturma
Stratejimiz, zaman serilerini işlemede mükemmel olduğunu kanıtlamış olan CatBoost gradyan güçlendirme modeline dayanmaktadır. Şimdi modeli adım adım oluşturmaya bakalım.
Özelliklerin hazırlanması
İlk adım model özelliklerinin oluşturulmasıdır. Teknik ve hava durumu göstergelerinden bir seçki toplayacağız:
def prepare_ml_features(data): """ Preparation of features for the ML model """ print("Starting feature preparation...") features = pd.DataFrame(index=data.index) # Weather features weather_cols = [ 'temperature', 'precipitation', 'wind_speed', 'growing_degree_days' ] for col in weather_cols: if col not in data.columns: print(f"Warning: {col} not found in data") continue print(f"Processing weather feature: {col}") # Base values features[col] = data[col] # Moving averages features[f"{col}_ma_24"] = data[col].rolling(24).mean() features[f"{col}_ma_72"] = data[col].rolling(72).mean() # Changes features[f"{col}_change"] = data[col].pct_change() features[f"{col}_change_24"] = data[col].pct_change(24) # Volatility features[f"{col}_volatility"] = data[col].rolling(24).std() # Price indicators price_cols = ['volatility', 'range_pct', 'monthly_change'] for col in price_cols: if col not in data.columns: continue features[f"{col}_ma_24"] = data[col].rolling(24).mean() # Seasonal features features['month'] = data.index.month features['day_of_week'] = data.index.dayofweek features['growing_season'] = ( (data.index.month >= 4) & (data.index.month <= 9) ).astype(int) return features.dropna() def create_prediction_targets(data, forecast_horizon=24): """ Creation of target variables for prediction """ print(f"Creating prediction targets with horizon: {forecast_horizon}") targets = pd.DataFrame(index=data.index) # Price change percentage targets['price_change'] = data['close'].pct_change( forecast_horizon ).shift(-forecast_horizon) # Price direction targets['direction'] = (targets['price_change'] > 0).astype(int) # Future volatility targets['volatility'] = data['volatility'].rolling( forecast_horizon ).mean().shift(-forecast_horizon) return targets.dropna()
Modellerin oluşturulması ve eğitilmesi
İncelenen her değişken için, optimize edilmiş parametrelerle ayrı bir model oluşturacağız:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.metrics import accuracy_score, mean_squared_error from sklearn.model_selection import TimeSeriesSplit # Define categorical features cat_features = ['month', 'day_of_week', 'growing_season'] # Create models for different tasks models = { 'direction': CatBoostClassifier( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='Logloss', eval_metric='Accuracy', random_seed=42, verbose=False, cat_features=cat_features ), 'price_change': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ), 'volatility': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ) } def train_ml_models(merged_data, region): """ Training ML models using time series cross-validation """ print(f"Starting model training for region: {region}") data = merged_data[region] features = prepare_ml_features(data) targets = create_prediction_targets(data) # Split into folds tscv = TimeSeriesSplit(n_splits=5) results = {} for target_name, model in models.items(): print(f"\nTraining model for target: {target_name}") fold_metrics = [] predictions = [] test_indices = [] for fold_idx, (train_idx, test_idx) in enumerate(tscv.split(features)): print(f"Processing fold {fold_idx + 1}/5") X_train = features.iloc[train_idx] y_train = targets[target_name].iloc[train_idx] X_test = features.iloc[test_idx] y_test = targets[target_name].iloc[test_idx] # Training with early stopping model.fit( X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=False ) # Predictions and evaluation pred = model.predict(X_test) predictions.extend(pred) test_indices.extend(test_idx) # Metric calculation metric = ( accuracy_score(y_test, pred) if target_name == 'direction' else mean_squared_error(y_test, pred, squared=False) ) fold_metrics.append(metric) print(f"Fold {fold_idx + 1} metric: {metric:.4f}") results[target_name] = { 'model': model, 'metrics': fold_metrics, 'mean_metric': np.mean(fold_metrics), 'predictions': pd.Series( predictions, index=features.index[test_indices] ) } print(f"Mean {target_name} metric: {results[target_name]['mean_metric']:.4f}") return results
Uygulama özellikleri
Uygulamamızda aşağıdaki parametrelere odaklanıyoruz:
- Kategorik özelliklerin işlenmesi: CatBoost, ay ve haftanın günü gibi kategorik değişkenleri ek kodlamaya gerek kalmadan verimli bir şekilde işler.
- Erken durma: Aşırı uyum sorunlarını önlemek için early_stopping_rounds=50 parametresi ile erken durma mekanizması kullanılır.
- Derinlik ve genelleme arasındaki denge: depth=7 ve l2_leaf_reg=3 parametreleri ağaç derinliği ve düzenlileştirme arasındaki maksimum denge için seçilmiştir.
- Zaman serilerini işleme: TimeSeriesSplit kullanımı, zaman serileri için uygun veri bölünmesini sağlayarak gelecekteki olası veri sızıntılarını önler.
Bu model mimarisi, elde edilen test sonuçlarının da gösterdiği gibi, hava koşulları ve döviz kuru hareketleri arasındaki hem kısa hem de uzun vadeli bağımlılıkların etkin bir şekilde yakalanmasına yardımcı olacaktır.
Model doğruluğunun değerlendirilmesi ve sonuçların görselleştirilmesi
Elde edilen makine öğrenimi modelleri, beş katlı kayan pencere yöntemi kullanılarak 5 yıllık veriler üzerinde test edildi. Her bir alan için üç tür model oluşturuldu: fiyat hareketinin yönünü tahmin etme (sınıflandırma), fiyat değişiminin büyüklüğünü tahmin etme (regresyon) ve volatiliteyi tahmin etme (regresyon).
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix, classification_report def evaluate_model_performance(results, region_data): """ Comprehensive model evaluation across all regions """ print(f"\nEvaluating model performance for {len(results)} regions") evaluation = {} for region, models in results.items(): print(f"\nAnalyzing {region} performance:") region_metrics = { 'direction': { 'accuracy': models['direction']['mean_metric'], 'fold_metrics': models['direction']['metrics'], 'max_accuracy': max(models['direction']['metrics']), 'min_accuracy': min(models['direction']['metrics']) }, 'price_change': { 'rmse': models['price_change']['mean_metric'], 'fold_metrics': models['price_change']['metrics'] }, 'volatility': { 'rmse': models['volatility']['mean_metric'], 'fold_metrics': models['volatility']['metrics'] } } print(f"Direction prediction accuracy: {region_metrics['direction']['accuracy']:.2%}") print(f"Price change RMSE: {region_metrics['price_change']['rmse']:.4f}") print(f"Volatility RMSE: {region_metrics['volatility']['rmse']:.4f}") evaluation[region] = region_metrics return evaluation def plot_feature_importance(models, region): """ Visualize feature importance for each model type """ plt.figure(figsize=(15, 10)) for target, model_info in models.items(): feature_importance = pd.DataFrame({ 'feature': model_info['model'].feature_names_, 'importance': model_info['model'].feature_importances_ }) feature_importance = feature_importance.sort_values('importance', ascending=False) plt.subplot(3, 1, list(models.keys()).index(target) + 1) sns.barplot(x='importance', y='feature', data=feature_importance.head(10)) plt.title(f'{target.capitalize()} Model - Top 10 Important Features') plt.tight_layout() plt.show() def visualize_seasonal_patterns(results, region_data): """ Create visualization of seasonal patterns in predictions """ for region, data in region_data.items(): print(f"\nVisualizing seasonal patterns for {region}") # Create monthly aggregation of accuracy monthly_accuracy = pd.DataFrame(index=range(1, 13)) data['month'] = data.index.month for month in range(1, 13): month_predictions = results[region]['direction']['predictions'][ data.index.month == month ] month_actual = (data['close'].pct_change() > 0)[ data.index.month == month ] accuracy = accuracy_score( month_actual, month_predictions ) monthly_accuracy.loc[month, 'accuracy'] = accuracy # Plot seasonal accuracy plt.figure(figsize=(12, 6)) monthly_accuracy['accuracy'].plot(kind='bar') plt.title(f'Seasonal Prediction Accuracy - {region}') plt.xlabel('Month') plt.ylabel('Accuracy') plt.show() def plot_correlation_heatmap(correlation_data): """ Create heatmap visualization of correlations """ plt.figure(figsize=(12, 8)) sns.heatmap( correlation_data, cmap='RdYlBu', center=0, annot=True, fmt='.2f' ) plt.title('Weather-Price Correlation Heatmap') plt.tight_layout() plt.show()
Bölgelere göre sonuçlar
AU_WheatBelt (Avustralya buğday kuşağı)
- AUDUSD yön tahmininin ortalama doğruluğu: %62.67
- Her katta maksimum doğruluk: %82.22
- Fiyat değişikliği tahmininin RMSE değeri: 0.0303
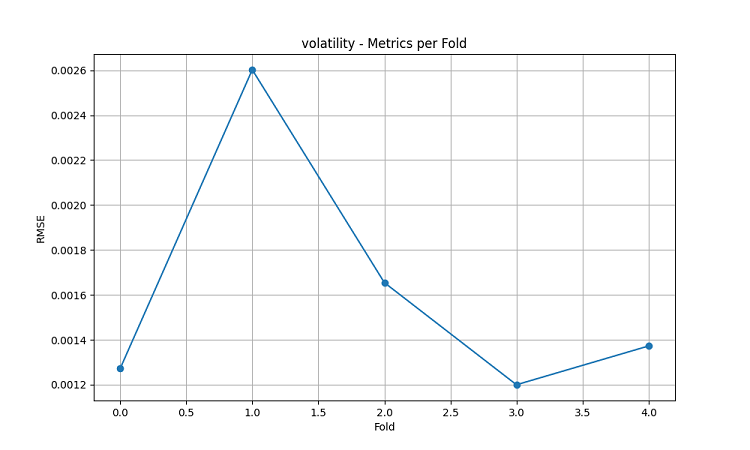
- Volatilitenin RMSE değeri: 0.0016
Canterbury bölgesi (Yeni Zelanda)
- NZDUSD tahmininin ortalama doğruluğu: %62.81
- En yüksek doğruluk: %75.44
- Minimum doğruluk: %54.39
- Fiyat değişikliği tahmininin RMSE değeri: 0.0281
- Volatilitenin RMSE değeri: 0.0015
Kanada çayır bölgesi
- Yön tahmininin ortalama doğruluğu: %56.92
- Maksimum doğruluk (üçüncü kat): %71.79
- Fiyat değişikliği tahmininin RMSE değeri: 0.0159
- Volatilitenin RMSE değeri: 0.0023
Mevsimsellik analizi ve görselleştirme
def analyze_model_seasonality(results, data): """ Analyze seasonal performance patterns of the models """ print("Starting seasonal analysis of model performance") seasonal_metrics = {} for region, region_results in results.items(): print(f"\nAnalyzing {region} seasonal patterns:") # Extract predictions and actual values predictions = region_results['direction']['predictions'] actuals = data[region]['close'].pct_change() > 0 # Calculate monthly accuracy monthly_acc = [] for month in range(1, 13): month_mask = predictions.index.month == month if month_mask.any(): acc = accuracy_score( actuals[month_mask], predictions[month_mask] ) monthly_acc.append(acc) print(f"Month {month} accuracy: {acc:.2%}") seasonal_metrics[region] = pd.Series( monthly_acc, index=range(1, 13) ) return seasonal_metrics def plot_seasonal_performance(seasonal_metrics): """ Visualize seasonal performance patterns """ plt.figure(figsize=(15, 8)) for region, metrics in seasonal_metrics.items(): plt.plot(metrics.index, metrics.values, label=region, marker='o') plt.title('Model Accuracy by Month') plt.xlabel('Month') plt.ylabel('Accuracy') plt.legend() plt.grid(True) plt.show()
Görselleştirme sonuçları, model performansında önemli bir mevsimsellik olduğunu göstermektedir.
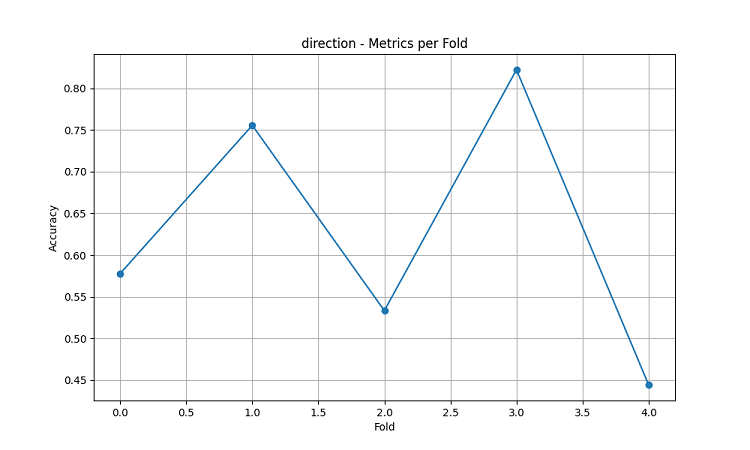

Tahmin doğruluğundaki zirveler özellikle dikkat çekicidir:
- AUDUSD için: Aralık-Şubat (buğdayın olgunlaşma dönemi)
- NZDUSD için: En yüksek süt üretim dönemleri
- USDCAD için: Aktif çayır büyüme mevsimleri
Bu sonuçlar, hava koşullarının özellikle tarımsal üretimin kritik dönemlerinde tarımsal döviz kurları üzerinde önemli bir etkiye sahip olduğu hipotezini doğrulamaktadır.
Sonuç
Çalışma, tarım bölgelerindeki hava koşulları ile döviz paritelerinin hareketleri arasında önemli bağlantılar buldu. Tahmin sistemi, aşırı hava koşulları ve tarımsal üretimin en yoğun olduğu dönemlerde AUDUSD için %62.67, NZDUSD için %62.81 ve USDCAD için %56.92'ye varan ortalama doğruluk oranı sergileyerek yüksek doğruluk gösterdi.
Tavsiyeler:
- AUDUSD: Aralıktan şubata kadar işlem yap, rüzgar ve sıcaklığa odaklan.
- NZDUSD: Süt ürünleri üretiminin aktif olduğu dönemde orta vadeli işlem yap.
- USDCAD: Ekim ve hasat mevsimlerinde işlem yap.
Sistem, özellikle piyasa şokları sırasında doğruluğu korumak için düzenli veri güncellemeleri gerektirir. Gelecekteki planlar arasında, veri kaynaklarının genişletilmesi ve tahminlerin sağlamlığını artırmak için derin öğrenmenin uygulanması yer almaktadır.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/16060
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Birçok kişi için CAD'nin çok fazla yağ değil, yem tahıl karışımları olduğu bir keşif olacaktır :-))
Ulusal para birimi için çoğunlukla ulusal borsalarda işlem gören
USDCAD için ve hatta sadece tarım sezonları için bile izlenebilir olmalıdır.