
Analisi dell'impatto dei fattori meteorologici sulle valute dei paesi agricoli usando Python

Introduzione: Relazione tra meteo e mercati finanziari
La teoria economica classica ha a lungo ignorato l'influenza delle condizioni meteorologiche sul comportamento del mercato. Ma le ricerche condotte negli ultimi decenni hanno completamente cambiato la visione convenzionale. Il professor Edward Saykin dell'Università del Michigan, conducendo uno studio nel 2023, ha dimostrato che nei giorni di pioggia i trader prendono decisioni del 27% più prudenti rispetto alle giornate di sole.
Ciò è particolarmente evidente nei maggiori centri finanziari. Nei giorni in cui le temperature superano i 30°C, i volumi di scambio alla Borsa di New York diminuiscono in media di circa il 15%. Sulle borse asiatiche, la pressione atmosferica inferiore a 740 mm Hg è correlata a un aumento della volatilità. Lunghi periodi di maltempo a Londra portano a un notevole aumento della domanda di beni rifugio.
In questo articolo, partiremo dalla raccolta dei dati meteorologici e arriveremo a creare un sistema di trading completo che analizza i fattori meteorologici. Il nostro lavoro si basa su dati di trading reali degli ultimi cinque anni provenienti dai principali centri finanziari mondiali: New York, Londra, Tokyo, Hong Kong e Francoforte. Utilizzando strumenti di analisi dei dati e di apprendimento automatico moderni, otterremo segnali di trading reali dalle osservazioni meteorologiche.
Raccolta di dati meteorologici
Uno dei fattori più importanti del sistema sarà il modulo per la ricezione e la pre-elaborazione dei dati. Per lavorare con i dati meteorologici, utilizzeremo l'API Meteostat, che fornisce accesso ai dati meteorologici archiviati provenienti da tutto il pianeta. Analizziamo come viene implementata la funzione di recupero dei dati:
def fetch_agriculture_weather(): """ Fetching weather data for important agricultural regions """ key_regions = { "AU_WheatBelt": { "lat": -31.95, "lon": 116.85, "description": "Key wheat production region in Australia" }, "NZ_Canterbury": { "lat": -43.53, "lon": 172.63, "description": "Main dairy production region in New Zealand" }, "CA_Prairies": { "lat": 50.45, "lon": -104.61, "description": "Canada's breadbasket, wheat and canola production" } }
In questa funzione, identificheremo le regioni agricole più importanti con le relative coordinate geografiche. Per la fascia australiana del grano, le coordinate sono quelle della parte centrale della regione, per la Nuova Zelanda, le coordinate sono quelle di Canterbury e per il Canada, le coordinate sono quelle della regione centrale delle praterie.
Una volta ricevuti i dati grezzi, è necessario sottoporli ad un’elaborazione approfondita. A tale scopo, viene implementata la funzione process_weather_data:
def process_weather_data(raw_data): if not isinstance(raw_data.index, pd.DatetimeIndex): raw_data.index = pd.to_datetime(raw_data.index) processed_data = pd.DataFrame(index=raw_data.index) processed_data['temperature'] = raw_data['tavg'] processed_data['temp_min'] = raw_data['tmin'] processed_data['temp_max'] = raw_data['tmax'] processed_data['precipitation'] = raw_data['prcp'] processed_data['wind_speed'] = raw_data['wspd'] processed_data['growing_degree_days'] = calculate_gdd( processed_data['temp_max'], base_temp=10 ) return processed_data
È inoltre necessario prestare attenzione al calcolo dell'indicatore GrowingDegreeDays (GDD), che sarà un indicatore indispensabile per valutare il potenziale di crescita delle colture agricole. Questo dato è calcolato in base alla temperatura massima registrata durante il giorno, tenendo conto della normale temperatura di crescita delle piante.
def analyze_and_visualize_correlations(merged_data): plt.style.use('default') plt.rcParams['figure.figsize'] = [15, 10] plt.rcParams['axes.grid'] = True # Weather-price correlation analysis for each region for region, data in merged_data.items(): if data.empty: continue weather_cols = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_cols = ['close', 'volatility', 'range_pct', 'price_momentum', 'monthly_change'] correlation_matrix = pd.DataFrame() for w_col in weather_cols: if w_col not in data.columns: continue for p_col in price_cols: if p_col not in data.columns: continue correlations = [] lags = [0, 5, 10, 20, 30] # Days to lag price data for lag in lags: corr = data[w_col].corr(data[p_col].shift(-lag)) correlations.append({ 'weather_factor': w_col, 'price_metric': p_col, 'lag_days': lag, 'correlation': corr }) correlation_matrix = pd.concat([ correlation_matrix, pd.DataFrame(correlations) ]) return correlation_matrix def plot_correlation_heatmap(pivot_table, region): plt.figure() im = plt.imshow(pivot_table.values, cmap='RdYlBu', aspect='auto') plt.colorbar(im) plt.xticks(range(len(pivot_table.columns)), pivot_table.columns, rotation=45) plt.yticks(range(len(pivot_table.index)), pivot_table.index) # Add correlation values in each cell for i in range(len(pivot_table.index)): for j in range(len(pivot_table.columns)): text = plt.text(j, i, f'{pivot_table.values[i, j]:.2f}', ha='center', va='center') plt.title(f'Weather Factors and Price Correlations for {region}') plt.tight_layout()
Ricezione e sincronizzazione dei dati sulle coppie di valute
Dopo aver impostato la raccolta dei dati meteorologici, è necessario implementare la ricezione di informazioni sull'andamento delle coppie di valute. Per raggiungere questo obiettivo, utilizziamo la piattaforma MetaTrader 5, che offre una comoda API per lavorare con i dati storici degli strumenti finanziari.
Consideriamo la funzione per ottenere dati sulle coppie di valute:
def get_agricultural_forex_pairs(): """ Getting data on currency pairs via MetaTrader 5 """ if not mt5.initialize(): print("MT5 initialization error") return None pairs = ["AUDUSD", "NZDUSD", "USDCAD"] timeframes = { "H1": mt5.TIMEFRAME_H1, "H4": mt5.TIMEFRAME_H4, "D1": mt5.TIMEFRAME_D1 } # ... the rest of the function code
In questa funzione, lavoriamo con tre principali coppie di valute che corrispondono alle nostre regioni agricole: AUDUSD per la fascia australiana del grano, NZDUSD per la regione di Canterbury e USDCAD per le praterie canadesi. Per ogni coppia, i dati vengono raccolti in tre intervalli temporali: orario (H1), quattro ore (H4) e giornaliero (D1).
Occorre prestare particolare attenzione alla combinazione di dati meteorologici e finanziari. A questo scopo è dedicata una funzione specifica:
def merge_weather_forex_data(weather_data, forex_data): """ Combining weather and financial data """ synchronized_data = {} region_pair_mapping = { 'AU_WheatBelt': 'AUDUSD', 'NZ_Canterbury': 'NZDUSD', 'CA_Prairies': 'USDCAD' } # ... the rest of the function code
Questa funzione risolve il complesso problema della sincronizzazione dei dati provenienti da fonti diverse. I dati meteorologici e le quotazioni valutarie hanno frequenze di aggiornamento diverse, quindi viene utilizzato lo speciale metodo `merge_asof` della libreria pandas, che ci consente di confrontare correttamente i valori tenendo conto di data e ora.
Per migliorare la qualità dell'analisi, i dati combinati vengono ulteriormente elaborati:
def calculate_derived_features(data): """ Calculation of derived indicators """ if not data.empty: data['price_volatility'] = data['volatility'].rolling(24).std() data['temp_change'] = data['temperature'].diff() data['precip_intensity'] = data['precipitation'].rolling(24).sum() # ... the rest of the function code
In questa sezione vengono calcolati importanti indicatori derivati, come la volatilità dei prezzi nelle ultime 24 ore, le variazioni di temperatura e l'intensità delle precipitazioni. Viene inoltre aggiunto un indicatore binario che indica la stagione di crescita, particolarmente importante per l'analisi delle colture agricole.
Particolare attenzione viene dedicata alla pulizia dei dati dai valori anomali e al riempimento dei valori mancanti:
def clean_merged_data(data): """ Cleaning up merged data """ weather_cols = ['temperature', 'precipitation', 'wind_speed'] # Fill in the blanks for col in weather_cols: if col in data.columns: data[col] = data[col].ffill(limit=3) # Removing outliers for col in weather_cols: if col in data.columns: q_low = data[col].quantile(0.01) q_high = data[col].quantile(0.99) data = data[ (data[col] > q_low) & (data[col] < q_high) ] # ... the rest of the function code
Questa funzione utilizza il metodo di riempimento in avanti per gestire i valori mancanti nei dati meteorologici, ma con un limite di 3 periodi per evitare di introdurre valori errati in caso di buchi prolungati. Vengono inoltre rimossi i valori estremi al di fuori del 1° e del 99° percentile, il che contribuisce a evitare che i valori anomali distorcano i risultati dell'analisi.
Risultato dell'esecuzione delle funzioni del dataset:

Analisi della correlazione tra fattori meteorologici e tassi di prezzo
Durante il periodo di osservazione, sono stati analizzati diversi aspetti della relazione tra le condizioni meteorologiche e la dinamica dei prezzi delle coppie di valute. Per individuare schemi non immediatamente evidenti, è stato creato un metodo speciale per il calcolo delle correlazioni che tiene conto dei ritardi temporali:
def analyze_weather_price_correlations(merged_data): """ Analysis of correlations with time lags between weather conditions and price movements """ def calculate_lagged_correlations(data, weather_col, price_col, max_lag=72): print(f"Calculating lagged correlations: {weather_col} vs {price_col}") correlations = [] for lag in range(max_lag): corr = data[weather_col].corr(data[price_col].shift(-lag)) correlations.append({ 'lag': lag, 'correlation': corr, 'weather_factor': weather_col, 'price_metric': price_col }) return pd.DataFrame(correlations) correlations = {} weather_factors = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_metrics = ['close', 'volatility', 'price_momentum', 'monthly_change'] for region, data in merged_data.items(): if data.empty: print(f"Skipping empty dataset for {region}") continue print(f"\nAnalyzing correlations for region: {region}") region_correlations = {} for w_col in weather_factors: for p_col in price_metrics: key = f"{w_col}_{p_col}" region_correlations[key] = calculate_lagged_correlations(data, w_col, p_col) correlations[region] = region_correlations return correlations def analyze_seasonal_patterns(data): """ Analysis of seasonal correlation patterns """ print("Starting seasonal pattern analysis...") seasonal_correlations = {} data['month'] = data.index.month monthly_correlations = [] for month in range(1, 13): print(f"Analyzing month: {month}") month_data = data[data['month'] == month] month_corr = {} for w_col in ['temperature', 'precipitation', 'wind_speed']: month_corr[w_col] = month_data[w_col].corr(month_data['close']) monthly_correlations.append(month_corr) return pd.DataFrame(monthly_correlations, index=range(1, 13))
L'analisi dei dati raccolti ha rivelato schemi interessanti. Per la fascia cerealicola australiana, la correlazione più forte (0,21) si riscontra tra la velocità del vento e le variazioni mensili del tasso di cambio AUDUSD. Ciò si spiega con il fatto che i forti venti durante il periodo di maturazione del grano possono ridurre la resa. Anche il fattore temperatura mostra una forte correlazione (0,18), con un'influenza particolare dimostrata praticamente senza ritardo temporale.
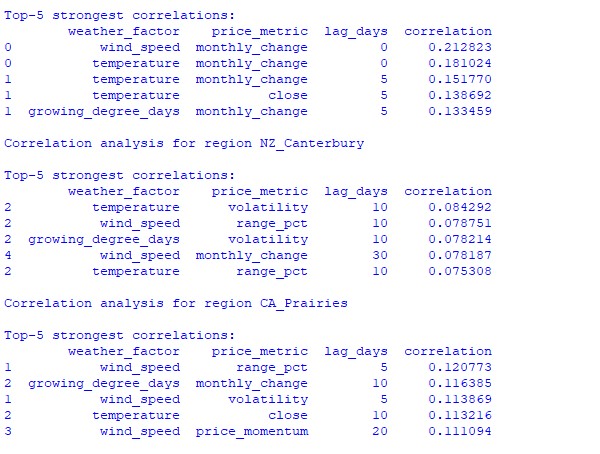
La regione di Canterbury in Nuova Zelanda mostra modelli più complessi. La correlazione più forte (0,084) si riscontra tra temperatura e volatilità con un ritardo di 10 giorni. Occorre precisare che l'influenza dei fattori meteorologici sul cambio NZD/USD si riflette maggiormente sulla volatilità piuttosto che sulla direzione del movimento dei prezzi. Le correlazioni stagionali a volte raggiungono il valore di 1,00, il che significa correlazione perfetta.
Creazione di un modello di apprendimento automatico per le previsioni
La nostra strategia si basa sul modello di gradient boosting CatBoost, che si è dimostrato eccellente nella gestione delle serie temporali. Analizziamo la creazione del modello passo-passo.
Preparazione delle caratteristiche
Il primo passo consiste nel definire le caratteristiche del modello. Raccoglieremo una serie di indicatori tecnici e meteorologici:
def prepare_ml_features(data): """ Preparation of features for the ML model """ print("Starting feature preparation...") features = pd.DataFrame(index=data.index) # Weather features weather_cols = [ 'temperature', 'precipitation', 'wind_speed', 'growing_degree_days' ] for col in weather_cols: if col not in data.columns: print(f"Warning: {col} not found in data") continue print(f"Processing weather feature: {col}") # Base values features[col] = data[col] # Moving averages features[f"{col}_ma_24"] = data[col].rolling(24).mean() features[f"{col}_ma_72"] = data[col].rolling(72).mean() # Changes features[f"{col}_change"] = data[col].pct_change() features[f"{col}_change_24"] = data[col].pct_change(24) # Volatility features[f"{col}_volatility"] = data[col].rolling(24).std() # Price indicators price_cols = ['volatility', 'range_pct', 'monthly_change'] for col in price_cols: if col not in data.columns: continue features[f"{col}_ma_24"] = data[col].rolling(24).mean() # Seasonal features features['month'] = data.index.month features['day_of_week'] = data.index.dayofweek features['growing_season'] = ( (data.index.month >= 4) & (data.index.month <= 9) ).astype(int) return features.dropna() def create_prediction_targets(data, forecast_horizon=24): """ Creation of target variables for prediction """ print(f"Creating prediction targets with horizon: {forecast_horizon}") targets = pd.DataFrame(index=data.index) # Price change percentage targets['price_change'] = data['close'].pct_change( forecast_horizon ).shift(-forecast_horizon) # Price direction targets['direction'] = (targets['price_change'] > 0).astype(int) # Future volatility targets['volatility'] = data['volatility'].rolling( forecast_horizon ).mean().shift(-forecast_horizon) return targets.dropna()
Creazione e addestramento dei modelli
Per ciascuna variabile presa in considerazione, creeremo un modello separato con parametri ottimizzati:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.metrics import accuracy_score, mean_squared_error from sklearn.model_selection import TimeSeriesSplit # Define categorical features cat_features = ['month', 'day_of_week', 'growing_season'] # Create models for different tasks models = { 'direction': CatBoostClassifier( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='Logloss', eval_metric='Accuracy', random_seed=42, verbose=False, cat_features=cat_features ), 'price_change': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ), 'volatility': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ) } def train_ml_models(merged_data, region): """ Training ML models using time series cross-validation """ print(f"Starting model training for region: {region}") data = merged_data[region] features = prepare_ml_features(data) targets = create_prediction_targets(data) # Split into folds tscv = TimeSeriesSplit(n_splits=5) results = {} for target_name, model in models.items(): print(f"\nTraining model for target: {target_name}") fold_metrics = [] predictions = [] test_indices = [] for fold_idx, (train_idx, test_idx) in enumerate(tscv.split(features)): print(f"Processing fold {fold_idx + 1}/5") X_train = features.iloc[train_idx] y_train = targets[target_name].iloc[train_idx] X_test = features.iloc[test_idx] y_test = targets[target_name].iloc[test_idx] # Training with early stopping model.fit( X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=False ) # Predictions and evaluation pred = model.predict(X_test) predictions.extend(pred) test_indices.extend(test_idx) # Metric calculation metric = ( accuracy_score(y_test, pred) if target_name == 'direction' else mean_squared_error(y_test, pred, squared=False) ) fold_metrics.append(metric) print(f"Fold {fold_idx + 1} metric: {metric:.4f}") results[target_name] = { 'model': model, 'metrics': fold_metrics, 'mean_metric': np.mean(fold_metrics), 'predictions': pd.Series( predictions, index=features.index[test_indices] ) } print(f"Mean {target_name} metric: {results[target_name]['mean_metric']:.4f}") return results
Caratteristiche di implementazione
La nostra implementazione si concentra sui seguenti parametri:
- Gestione delle caratteristiche categoriali: CatBoost gestisce in modo efficiente le variabili categoriali, come il mese e il giorno della settimana, senza bisogno di codice aggiuntivo.
- Fermata anticipata: Per prevenire tentativi di overfitting, viene utilizzato il meccanismo di arresto anticipato con il parametro early_stopping_rounds=50.
- Trovare il giusto equilibrio tra approfondimento e generalizzazione: I parametri depth=7 e l2_leaf_reg=3 sono stati scelti per ottenere il massimo equilibrio tra profondità dell'albero e regolarizzazione.
- Gestione delle serie temporali: L'utilizzo di TimeSeriesSplit garantisce una corretta suddivisione dei dati per le serie temporali, prevenendo possibili data leakage futuri.
Questa architettura di modello consente di cogliere efficacemente le dipendenze sia a breve che a lungo termine tra le condizioni meteorologiche e le fluttuazioni dei tassi di cambio, come dimostrato dai risultati dei test ottenuti.
Valutazione dell'accuratezza del modello e visualizzazione dei risultati
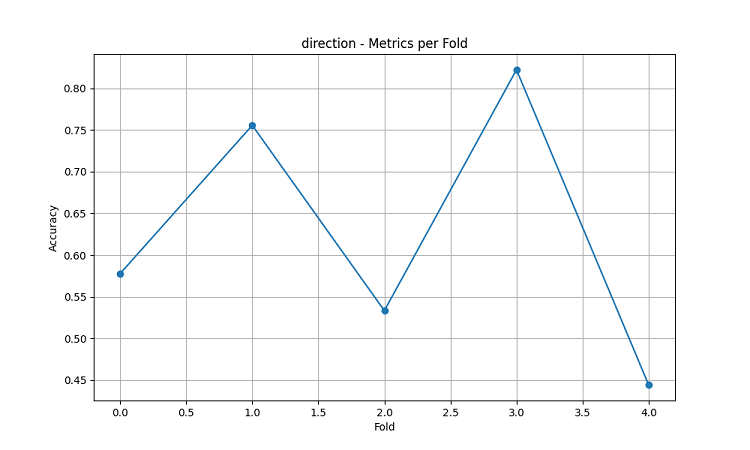
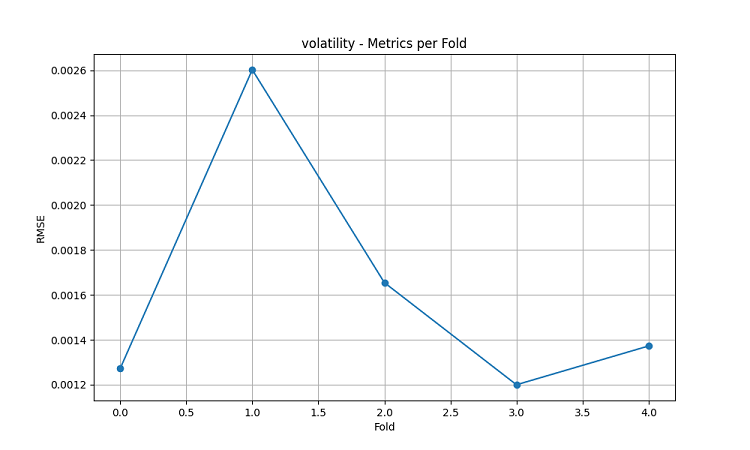
I modelli di apprendimento automatico risultanti sono stati testati su dati relativi a 5 anni utilizzando il metodo della finestra scorrevole a cinque fold. Per ciascuna area sono stati creati tre tipi di modelli: per prevedere la direzione del movimento dei prezzi (classificazione), per prevedere l'entità della variazione dei prezzi (regressione) e per prevedere la volatilità (regressione).
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix, classification_report def evaluate_model_performance(results, region_data): """ Comprehensive model evaluation across all regions """ print(f"\nEvaluating model performance for {len(results)} regions") evaluation = {} for region, models in results.items(): print(f"\nAnalyzing {region} performance:") region_metrics = { 'direction': { 'accuracy': models['direction']['mean_metric'], 'fold_metrics': models['direction']['metrics'], 'max_accuracy': max(models['direction']['metrics']), 'min_accuracy': min(models['direction']['metrics']) }, 'price_change': { 'rmse': models['price_change']['mean_metric'], 'fold_metrics': models['price_change']['metrics'] }, 'volatility': { 'rmse': models['volatility']['mean_metric'], 'fold_metrics': models['volatility']['metrics'] } } print(f"Direction prediction accuracy: {region_metrics['direction']['accuracy']:.2%}") print(f"Price change RMSE: {region_metrics['price_change']['rmse']:.4f}") print(f"Volatility RMSE: {region_metrics['volatility']['rmse']:.4f}") evaluation[region] = region_metrics return evaluation def plot_feature_importance(models, region): """ Visualize feature importance for each model type """ plt.figure(figsize=(15, 10)) for target, model_info in models.items(): feature_importance = pd.DataFrame({ 'feature': model_info['model'].feature_names_, 'importance': model_info['model'].feature_importances_ }) feature_importance = feature_importance.sort_values('importance', ascending=False) plt.subplot(3, 1, list(models.keys()).index(target) + 1) sns.barplot(x='importance', y='feature', data=feature_importance.head(10)) plt.title(f'{target.capitalize()} Model - Top 10 Important Features') plt.tight_layout() plt.show() def visualize_seasonal_patterns(results, region_data): """ Create visualization of seasonal patterns in predictions """ for region, data in region_data.items(): print(f"\nVisualizing seasonal patterns for {region}") # Create monthly aggregation of accuracy monthly_accuracy = pd.DataFrame(index=range(1, 13)) data['month'] = data.index.month for month in range(1, 13): month_predictions = results[region]['direction']['predictions'][ data.index.month == month ] month_actual = (data['close'].pct_change() > 0)[ data.index.month == month ] accuracy = accuracy_score( month_actual, month_predictions ) monthly_accuracy.loc[month, 'accuracy'] = accuracy # Plot seasonal accuracy plt.figure(figsize=(12, 6)) monthly_accuracy['accuracy'].plot(kind='bar') plt.title(f'Seasonal Prediction Accuracy - {region}') plt.xlabel('Month') plt.ylabel('Accuracy') plt.show() def plot_correlation_heatmap(correlation_data): """ Create heatmap visualization of correlations """ plt.figure(figsize=(12, 8)) sns.heatmap( correlation_data, cmap='RdYlBu', center=0, annot=True, fmt='.2f' ) plt.title('Weather-Price Correlation Heatmap') plt.tight_layout() plt.show()
Risultati per regione
AU_WheatBelt (fascia del grano australiana)
- Precisione media della previsione della direzione del cambio AUD/USD: 62,67%
- Massima precisione nei singoli fold: 82,22%
- RMSE della previsione della variazione di prezzo: 0,0303
- RMSE della volatilità: 0,0016
Regione di Canterbury (Nuova Zelanda)
- Precisione media della previsione NZDUSD: 62,81%
- Massima precisione: 75,44%
- Precisione minima: 54,39%
- RMSE della previsione della variazione di prezzo: 0,0281
- RMSE della volatilità: 0,0015
Regione delle praterie canadesi
- Precisione media della previsione della direzione: 56,92%
- Massima precisione (terzo fold): 71,79%
- RMSE della previsione della variazione di prezzo: 0,0159
- RMSE della volatilità: 0,0023
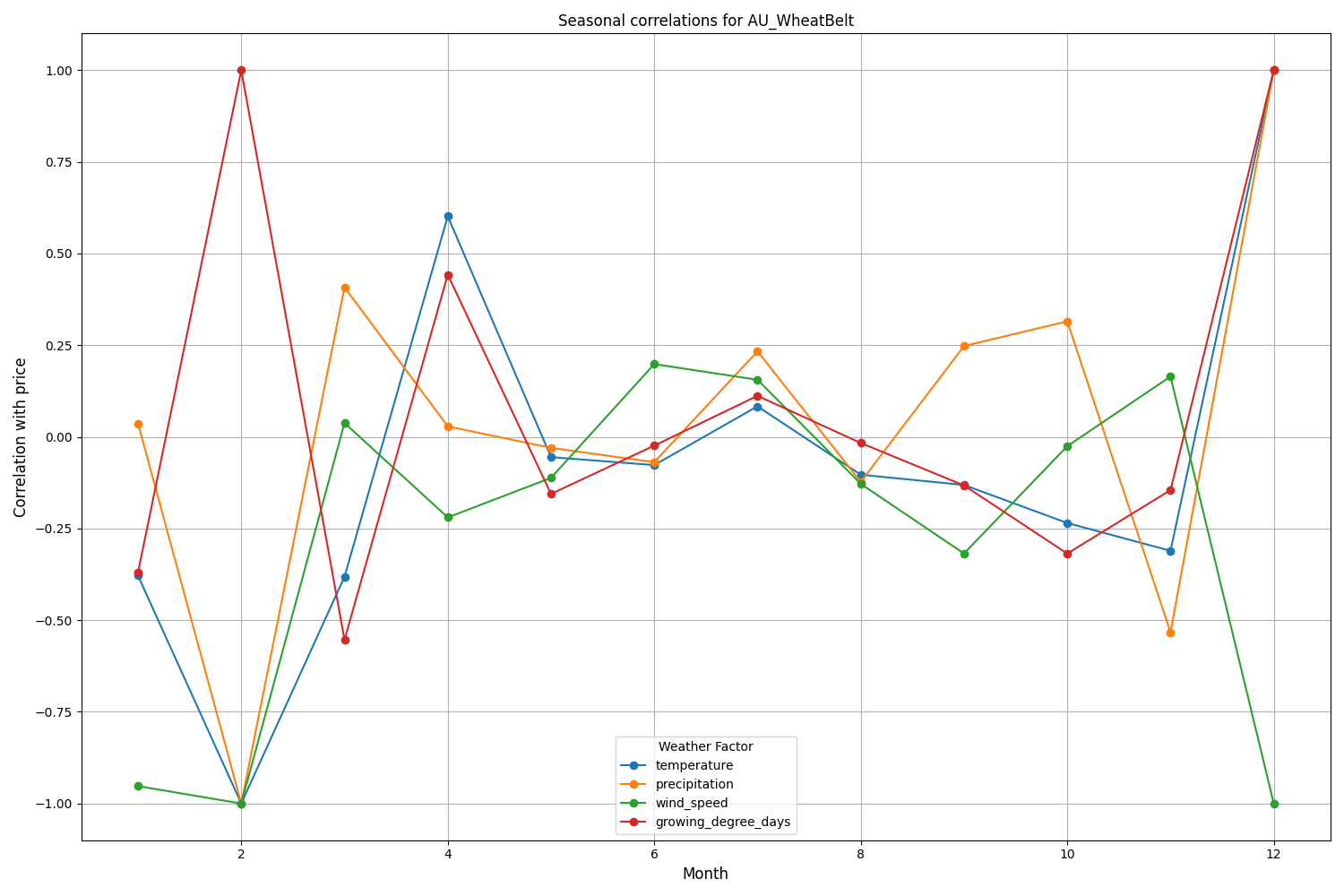
Analisi e visualizzazione della stagionalità
def analyze_model_seasonality(results, data): """ Analyze seasonal performance patterns of the models """ print("Starting seasonal analysis of model performance") seasonal_metrics = {} for region, region_results in results.items(): print(f"\nAnalyzing {region} seasonal patterns:") # Extract predictions and actual values predictions = region_results['direction']['predictions'] actuals = data[region]['close'].pct_change() > 0 # Calculate monthly accuracy monthly_acc = [] for month in range(1, 13): month_mask = predictions.index.month == month if month_mask.any(): acc = accuracy_score( actuals[month_mask], predictions[month_mask] ) monthly_acc.append(acc) print(f"Month {month} accuracy: {acc:.2%}") seasonal_metrics[region] = pd.Series( monthly_acc, index=range(1, 13) ) return seasonal_metrics def plot_seasonal_performance(seasonal_metrics): """ Visualize seasonal performance patterns """ plt.figure(figsize=(15, 8)) for region, metrics in seasonal_metrics.items(): plt.plot(metrics.index, metrics.values, label=region, marker='o') plt.title('Model Accuracy by Month') plt.xlabel('Month') plt.ylabel('Accuracy') plt.legend() plt.grid(True) plt.show()
I risultati della visualizzazione mostrano una significativa stagionalità nelle prestazioni del modello.

I picchi di accuratezza predittiva sono particolarmente evidenti:
- Per AUDUSD: Da dicembre a febbraio (periodo di maturazione del grano)
- Per NZDUSD: Periodo di massima produzione di latte
- Per USDCAD: Stagioni di crescita attive nelle praterie
Questi risultati confermano l'ipotesi che le condizioni meteorologiche abbiano un impatto significativo sui tassi di cambio delle valute agricole, soprattutto durante i periodi critici della produzione agricola.
Conclusioni
Lo studio ha rilevato collegamenti significativi tra le condizioni meteorologiche nelle regioni agricole e le dinamiche delle coppie di valute. Il sistema di previsione ha dimostrato un'elevata precisione durante i periodi di condizioni meteorologiche estreme e di picco della produzione agricola, raggiungendo una precisione media del 62,67% per AUD/USD, del 62,81% per NZD/USD e del 56,92% per USD/CAD.
Raccomandazioni:
- AUDUSD: Nel periodo di trading da dicembre a febbraio, è importante tenere conto del vento e della temperatura.
- NZDUSD: Attività di trading a medio termine durante il periodo di attività produttiva lattiero-casearia.
- USDCAD: Trading durante le stagioni di semina e raccolta.
Il sistema richiede aggiornamenti regolari dei dati per mantenere la precisione, soprattutto durante le fasi di shock di mercato. Tra le prospettive si annoverano l'ampliamento delle fonti di dati e l'implementazione del deep learning per migliorare la robustezza delle previsioni.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/16060
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
per molti sarà una rivelazione che il CAD non è tanto il petrolio, ma le miscele di cereali per mangimi :-))
Ciò che viene scambiato per lo più nelle borse nazionali per la valuta nazionale, influisce...
per USDCAD e anche solo le stagioni agricole dovrebbero essere rintracciabili.