
파이썬을 이용하여 농업 국가의 통화에 대한 날씨의 영향 분석

소개: 날씨와 금융 시장의 관계
고전 경제 이론은 오랫동안 날씨가 시장 행동에 미치는 영향을 무시해 왔습니다. 하지만 최근 수십 년간 진행된 연구는 기존의 견해를 완전히 바꿔 놓았습니다. 미시간 대학교의 에드워드 세이킨 교수는 2023년 연구를 통해 비 오는 날에는 트레이더들이 맑은 날보다 27% 더 신중하게 결정을 내린다는 사실을 보여주었습니다.
이와 같은 현상은 특히 주요 금융 중심지에서 두드러지게 나타납니다. 기온이 30°C를 넘는 날에는 뉴욕 증권거래소의 거래량이 평균 약 15% 감소합니다. 아시아 증시에서는 대기압이 740mmHg 미만일 경우 변동성이 증가하는 경향이 있습니다. 런던에서 장기간 악천후가 지속되면 안전자산에 대한 수요가 눈에 띄게 증가합니다.
이 글에서는 날씨 데이터 수집하는 것부터 시작해서 날씨 요인을 분석하는 완벽한 거래 시스템을 구축하는 단계까지 살펴보겠습니다. 저의 연구는 세계 주요 금융 중심지에서 지난 5년간 수집된 실제 거래 데이터를 기반으로 합니다. 뉴욕, 런던, 도쿄, 홍콩, 프랑크푸르트. 우리는 최첨단 데이터 분석 및 머신러닝 도구를 활용하여 기상 관측 자료로부터 실제 거래 신호를 도출할 것입니다.
기상 데이터 수집
이 시스템에서 가장 중요한 요소 중 하나는 데이터를 수신하고 사전 처리하는 모듈이 될 것입니다. 기상 데이터를 다루기 위해 우리는 전 세계의 기상 기록 데이터에 접근할 수 있는 Meteostat API를 사용할 것입니다. 데이터 검색 함수가 어떻게 구현되는지 살펴봅시다:
def fetch_agriculture_weather(): """ Fetching weather data for important agricultural regions """ key_regions = { "AU_WheatBelt": { "lat": -31.95, "lon": 116.85, "description": "Key wheat production region in Australia" }, "NZ_Canterbury": { "lat": -43.53, "lon": 172.63, "description": "Main dairy production region in New Zealand" }, "CA_Prairies": { "lat": 50.45, "lon": -104.61, "description": "Canada's breadbasket, wheat and canola production" } }
이 함수에서 우리는 가장 중요한 농업 지역과 해당 지역의 위치 좌표를 식별할 것입니다. 호주의 밀 재배지대의 경우 좌표는 해당 지역의 중앙부를, 뉴질랜드의 경우 좌표는 캔터베리를, 캐나다의 경우에 좌표는 중부 대평원 지역을 나타냅니다.
원시 데이터가 수신되면 본격적으로 처리를 해야 합니다. 이를 위해 process_weather_data 함수가 구현되었습니다:
def process_weather_data(raw_data): if not isinstance(raw_data.index, pd.DatetimeIndex): raw_data.index = pd.to_datetime(raw_data.index) processed_data = pd.DataFrame(index=raw_data.index) processed_data['temperature'] = raw_data['tavg'] processed_data['temp_min'] = raw_data['tmin'] processed_data['temp_max'] = raw_data['tmax'] processed_data['precipitation'] = raw_data['prcp'] processed_data['wind_speed'] = raw_data['wspd'] processed_data['growing_degree_days'] = calculate_gdd( processed_data['temp_max'], base_temp=10 ) return processed_data
또한 농작물의 성장 잠재력을 평가하는 데 필수적인 지표인 GrowingDegreeDays(GDD) 계산에도 주의를 기울여야 합니다. 이 수치는 식물의 정상적인 생장 온도를 고려하여 하루 중 최고 기온을 기준으로 산출한 것입니다.
def analyze_and_visualize_correlations(merged_data): plt.style.use('default') plt.rcParams['figure.figsize'] = [15, 10] plt.rcParams['axes.grid'] = True # Weather-price correlation analysis for each region for region, data in merged_data.items(): if data.empty: continue weather_cols = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_cols = ['close', 'volatility', 'range_pct', 'price_momentum', 'monthly_change'] correlation_matrix = pd.DataFrame() for w_col in weather_cols: if w_col not in data.columns: continue for p_col in price_cols: if p_col not in data.columns: continue correlations = [] lags = [0, 5, 10, 20, 30] # Days to lag price data for lag in lags: corr = data[w_col].corr(data[p_col].shift(-lag)) correlations.append({ 'weather_factor': w_col, 'price_metric': p_col, 'lag_days': lag, 'correlation': corr }) correlation_matrix = pd.concat([ correlation_matrix, pd.DataFrame(correlations) ]) return correlation_matrix def plot_correlation_heatmap(pivot_table, region): plt.figure() im = plt.imshow(pivot_table.values, cmap='RdYlBu', aspect='auto') plt.colorbar(im) plt.xticks(range(len(pivot_table.columns)), pivot_table.columns, rotation=45) plt.yticks(range(len(pivot_table.index)), pivot_table.index) # Add correlation values in each cell for i in range(len(pivot_table.index)): for j in range(len(pivot_table.columns)): text = plt.text(j, i, f'{pivot_table.values[i, j]:.2f}', ha='center', va='center') plt.title(f'Weather Factors and Price Correlations for {region}') plt.tight_layout()
통화쌍 데이터 수신 및 동기화
기상 데이터를 수집하는 시스템을 구축한 후에는 통화쌍 변동 정보를 수신하는 시스템을 구현해야 합니다. 이를 위해 우리는 금융 상품의 과거 데이터를 편리하게 활용할 수 있도록 해 주는 API가 제공되는 MetaTrader 5 플랫폼을 사용합니다.
통화쌍에 대한 데이터를 얻는 함수를 살펴봅시다:
def get_agricultural_forex_pairs(): """ Getting data on currency pairs via MetaTrader 5 """ if not mt5.initialize(): print("MT5 initialization error") return None pairs = ["AUDUSD", "NZDUSD", "USDCAD"] timeframes = { "H1": mt5.TIMEFRAME_H1, "H4": mt5.TIMEFRAME_H4, "D1": mt5.TIMEFRAME_D1 } # ... the rest of the function code
이 함수에서 우리는 농업 지역에 해당하는 세 가지 주요 통화 쌍을 사용합니다. 호주 밀 생산지대는 AUDUSD, 캔터베리 지역은 NZDUSD, 캐나다 대평원 지역은 USDCAD를 사용합니다. 각 쌍에 대해 시간별(H1), 4시간별(H4) 및 일별(D1)의 세 가지 시간 간격으로 데이터가 수집됩니다.
날씨 데이터와 금융 데이터를 결합하는 데 특히 주의를 기울여야 합니다. 이를 담당하는 특별한 함수가 있습니다:
def merge_weather_forex_data(weather_data, forex_data): """ Combining weather and financial data """ synchronized_data = {} region_pair_mapping = { 'AU_WheatBelt': 'AUDUSD', 'NZ_Canterbury': 'NZDUSD', 'CA_Prairies': 'USDCAD' } # ... the rest of the function code
이 함수는 서로 다른 소스의 데이터를 동기화하는 복잡한 문제를 해결합니다. 날씨 데이터와 환율 정보는 업데이트 빈도가 다릅니다. 그러므로 타임스탬프를 고려하여 값을 정확하게 비교할 수 있도록 pandas 라이브러리의 특수한 `merge_asof` 메서드를 사용합니다.
분석의 질을 향상시키기 위해 통합 데이터에 대한 추가적인 처리가 수행됩니다:
def calculate_derived_features(data): """ Calculation of derived indicators """ if not data.empty: data['price_volatility'] = data['volatility'].rolling(24).std() data['temp_change'] = data['temperature'].diff() data['precip_intensity'] = data['precipitation'].rolling(24).sum() # ... the rest of the function code
여기서는 지난 24시간 동안의 가격 변동성, 기온 변화, 강수량의 강도와 같은 중요한 파생 지표들이 계산됩니다. 생육 기간을 나타내는 이진 지표도 추가되는데 이는 특히 농작물 분석에 중요합니다.
이상치를 제거하고 결측값을 채우는 데 특히 주의를 기여야 합니다.
def clean_merged_data(data): """ Cleaning up merged data """ weather_cols = ['temperature', 'precipitation', 'wind_speed'] # Fill in the blanks for col in weather_cols: if col in data.columns: data[col] = data[col].ffill(limit=3) # Removing outliers for col in weather_cols: if col in data.columns: q_low = data[col].quantile(0.01) q_high = data[col].quantile(0.99) data = data[ (data[col] > q_low) & (data[col] < q_high) ] # ... the rest of the function code
이 함수는 기상 데이터에서 빠진값을 처리하기 위해 전방 채우기 방식을 사용합니다. 그러나 긴 공백이 발생할 경우 잘못된 값이 입력되는 것을 방지하기 위해 최대 3개 기간으로 제한합니다. 1번째 백분위수와 99번째 백분위수를 벗어나는 극단적인 값도 제거되어 이상치가 분석 결과를 왜곡하는 것을 방지합니다.
데이터셋 함수 실행 결과:

기상 요인과 가격 변동률 간의 상관관계 분석
관찰 기간 동안 기상 조건과 통화쌍 가격 변동 간의 관계에 대한 다양한 측면이 분석되었습니다. 쉽게 드러나지 않는 패턴을 찾기 위해 시간 지연을 고려한 특별한 상관관계 계산 방법이 개발되었습니다.
def analyze_weather_price_correlations(merged_data): """ Analysis of correlations with time lags between weather conditions and price movements """ def calculate_lagged_correlations(data, weather_col, price_col, max_lag=72): print(f"Calculating lagged correlations: {weather_col} vs {price_col}") correlations = [] for lag in range(max_lag): corr = data[weather_col].corr(data[price_col].shift(-lag)) correlations.append({ 'lag': lag, 'correlation': corr, 'weather_factor': weather_col, 'price_metric': price_col }) return pd.DataFrame(correlations) correlations = {} weather_factors = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_metrics = ['close', 'volatility', 'price_momentum', 'monthly_change'] for region, data in merged_data.items(): if data.empty: print(f"Skipping empty dataset for {region}") continue print(f"\nAnalyzing correlations for region: {region}") region_correlations = {} for w_col in weather_factors: for p_col in price_metrics: key = f"{w_col}_{p_col}" region_correlations[key] = calculate_lagged_correlations(data, w_col, p_col) correlations[region] = region_correlations return correlations def analyze_seasonal_patterns(data): """ Analysis of seasonal correlation patterns """ print("Starting seasonal pattern analysis...") seasonal_correlations = {} data['month'] = data.index.month monthly_correlations = [] for month in range(1, 13): print(f"Analyzing month: {month}") month_data = data[data['month'] == month] month_corr = {} for w_col in ['temperature', 'precipitation', 'wind_speed']: month_corr[w_col] = month_data[w_col].corr(month_data['close']) monthly_correlations.append(month_corr) return pd.DataFrame(monthly_correlations, index=range(1, 13))
수집된 데이터를 분석한 결과 흥미로운 패턴들이 드러났습니다. 호주 밀 재배 지역의 경우 가장 강한 상관관계(0.21)는 풍속과 월별 AUDUSD 환율 변동 사이에서 나타납니다. 이는 밀이 익어가는 시기에 강한 바람이 불 경우 수확량이 감소할 수 있다는 사실로 설명할 수 있습니다. 온도 요인 또한 강한 상관관계(0.18)를 보이며 특히 시간 지연 없이 즉각적인 영향을 미치는 것으로 나타났습니다.
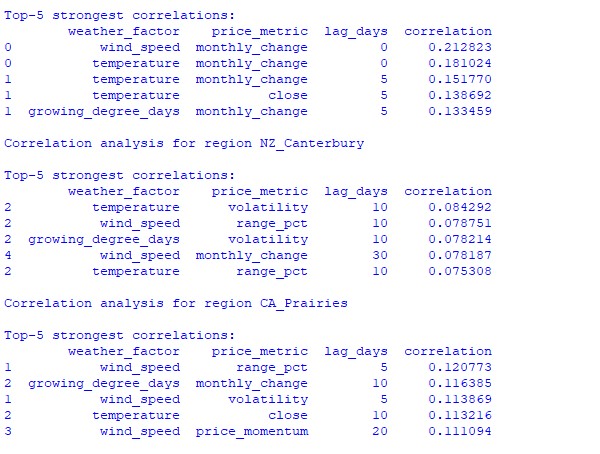
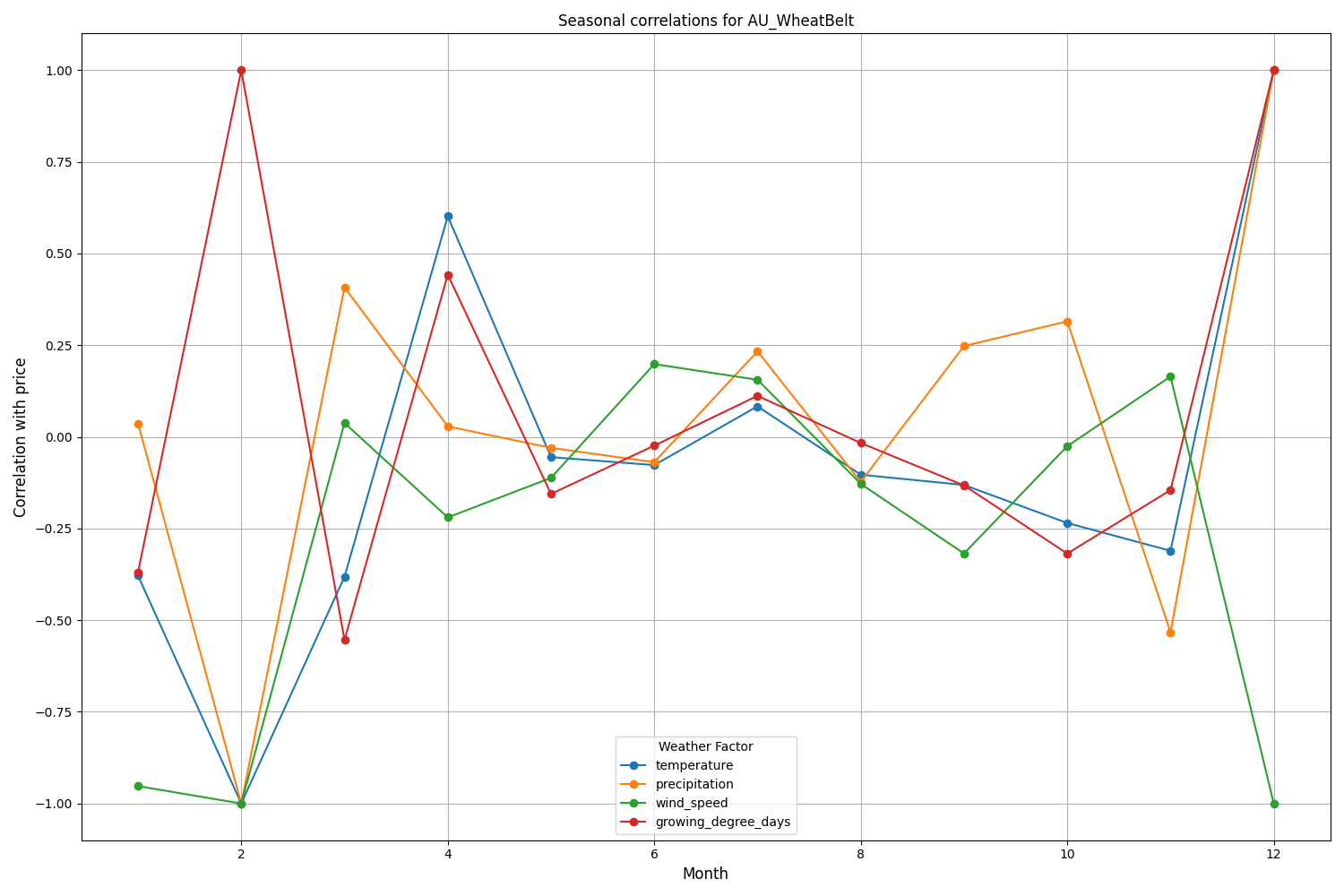
뉴질랜드 캔터베리 지역은 훨씬 복잡한 패턴을 보입니다. 가장 강한 상관관계(0.084)는 10일의 시차를 두고 기온과 변동성 사이에서 나타납니다. 날씨 요인이 뉴질랜드 달러/달러 환율에 미치는 영향은 가격의 방향보다는 변동성에 더 크게 반영됩니다. 계절적 상관관계는 때때로 1.00에 도달하는데 이는 완벽한 상관관계를 의미합니다.
예측을 위한 머신러닝 모델 생성
우리의 전략은 시계열 데이터 처리에 탁월한 성능을 입증한 CatBoost 경사 부스팅 모델을 기반으로 합니다. 모델을 단계별로 만들어 보겠습니다.
피처 준비
첫 번째 단계는 모델 피처를 구성하는 것입니다. 우리는 다음과 같은 기술 및 기상 지표들을 수집할 것입니다:
def prepare_ml_features(data): """ Preparation of features for the ML model """ print("Starting feature preparation...") features = pd.DataFrame(index=data.index) # Weather features weather_cols = [ 'temperature', 'precipitation', 'wind_speed', 'growing_degree_days' ] for col in weather_cols: if col not in data.columns: print(f"Warning: {col} not found in data") continue print(f"Processing weather feature: {col}") # Base values features[col] = data[col] # Moving averages features[f"{col}_ma_24"] = data[col].rolling(24).mean() features[f"{col}_ma_72"] = data[col].rolling(72).mean() # Changes features[f"{col}_change"] = data[col].pct_change() features[f"{col}_change_24"] = data[col].pct_change(24) # Volatility features[f"{col}_volatility"] = data[col].rolling(24).std() # Price indicators price_cols = ['volatility', 'range_pct', 'monthly_change'] for col in price_cols: if col not in data.columns: continue features[f"{col}_ma_24"] = data[col].rolling(24).mean() # Seasonal features features['month'] = data.index.month features['day_of_week'] = data.index.dayofweek features['growing_season'] = ( (data.index.month >= 4) & (data.index.month <= 9) ).astype(int) return features.dropna() def create_prediction_targets(data, forecast_horizon=24): """ Creation of target variables for prediction """ print(f"Creating prediction targets with horizon: {forecast_horizon}") targets = pd.DataFrame(index=data.index) # Price change percentage targets['price_change'] = data['close'].pct_change( forecast_horizon ).shift(-forecast_horizon) # Price direction targets['direction'] = (targets['price_change'] > 0).astype(int) # Future volatility targets['volatility'] = data['volatility'].rolling( forecast_horizon ).mean().shift(-forecast_horizon) return targets.dropna()
모델 생성 및 훈련
고려 대상인 각 변수에 대해 우리는 최적화된 매개변수를 가진 별도의 모델을 생성할 것입니다:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.metrics import accuracy_score, mean_squared_error from sklearn.model_selection import TimeSeriesSplit # Define categorical features cat_features = ['month', 'day_of_week', 'growing_season'] # Create models for different tasks models = { 'direction': CatBoostClassifier( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='Logloss', eval_metric='Accuracy', random_seed=42, verbose=False, cat_features=cat_features ), 'price_change': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ), 'volatility': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ) } def train_ml_models(merged_data, region): """ Training ML models using time series cross-validation """ print(f"Starting model training for region: {region}") data = merged_data[region] features = prepare_ml_features(data) targets = create_prediction_targets(data) # Split into folds tscv = TimeSeriesSplit(n_splits=5) results = {} for target_name, model in models.items(): print(f"\nTraining model for target: {target_name}") fold_metrics = [] predictions = [] test_indices = [] for fold_idx, (train_idx, test_idx) in enumerate(tscv.split(features)): print(f"Processing fold {fold_idx + 1}/5") X_train = features.iloc[train_idx] y_train = targets[target_name].iloc[train_idx] X_test = features.iloc[test_idx] y_test = targets[target_name].iloc[test_idx] # Training with early stopping model.fit( X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=False ) # Predictions and evaluation pred = model.predict(X_test) predictions.extend(pred) test_indices.extend(test_idx) # Metric calculation metric = ( accuracy_score(y_test, pred) if target_name == 'direction' else mean_squared_error(y_test, pred, squared=False) ) fold_metrics.append(metric) print(f"Fold {fold_idx + 1} metric: {metric:.4f}") results[target_name] = { 'model': model, 'metrics': fold_metrics, 'mean_metric': np.mean(fold_metrics), 'predictions': pd.Series( predictions, index=features.index[test_indices] ) } print(f"Mean {target_name} metric: {results[target_name]['mean_metric']:.4f}") return results
피처 구현
우리의 구현은 다음과 같은 매개변수에 중점을 둡니다:
- 범주형 피처 처리: CatBoost는 월과 요일과 같은 범주형 변수를 추가적인 코딩 없이 효율적으로 처리합니다.
- 조기 종료: 과적합 시도를 방지하기 위해 early_stopping_rounds=50 매개변수를 사용하여 조기 종료 메커니즘을 적용합니다.
- 심층화와 일반화 사이의 균형: 매개변수 depth=7과 l2_leaf_reg=3은 트리 깊이와 정규화 사이의 균형을 최대한 맞추기 위해 선택되었습니다.
- 시계열 데이터 처리: TimeSeriesSplit을 사용하면 시계열 데이터를 적절하게 분할하여 향후 발생할 수 있는 데이터 유출을 방지할 수 있습니다.
이 모델 아키텍처는 얻어진 테스트 결과에서 입증된 바와 같이 기상 조건과 환율 변동 간의 단기 및 장기적 상관관계를 효율적으로 포착하는 데 도움이 될 것입니다.
모델 정확도 평가 및 결과 시각화
이렇게 만들어진 머신러닝 모델들은 5년치 데이터를 사용하여 five-fold sliding window 메서드로 테스트되었습니다. 각 영역에 대해 세 가지 유형의 모델을 만들어졌습니다: 가격 변동 방향 예측(분류), 가격 변동 폭 예측(회귀), 변동성 예측(회귀)
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix, classification_report def evaluate_model_performance(results, region_data): """ Comprehensive model evaluation across all regions """ print(f"\nEvaluating model performance for {len(results)} regions") evaluation = {} for region, models in results.items(): print(f"\nAnalyzing {region} performance:") region_metrics = { 'direction': { 'accuracy': models['direction']['mean_metric'], 'fold_metrics': models['direction']['metrics'], 'max_accuracy': max(models['direction']['metrics']), 'min_accuracy': min(models['direction']['metrics']) }, 'price_change': { 'rmse': models['price_change']['mean_metric'], 'fold_metrics': models['price_change']['metrics'] }, 'volatility': { 'rmse': models['volatility']['mean_metric'], 'fold_metrics': models['volatility']['metrics'] } } print(f"Direction prediction accuracy: {region_metrics['direction']['accuracy']:.2%}") print(f"Price change RMSE: {region_metrics['price_change']['rmse']:.4f}") print(f"Volatility RMSE: {region_metrics['volatility']['rmse']:.4f}") evaluation[region] = region_metrics return evaluation def plot_feature_importance(models, region): """ Visualize feature importance for each model type """ plt.figure(figsize=(15, 10)) for target, model_info in models.items(): feature_importance = pd.DataFrame({ 'feature': model_info['model'].feature_names_, 'importance': model_info['model'].feature_importances_ }) feature_importance = feature_importance.sort_values('importance', ascending=False) plt.subplot(3, 1, list(models.keys()).index(target) + 1) sns.barplot(x='importance', y='feature', data=feature_importance.head(10)) plt.title(f'{target.capitalize()} Model - Top 10 Important Features') plt.tight_layout() plt.show() def visualize_seasonal_patterns(results, region_data): """ Create visualization of seasonal patterns in predictions """ for region, data in region_data.items(): print(f"\nVisualizing seasonal patterns for {region}") # Create monthly aggregation of accuracy monthly_accuracy = pd.DataFrame(index=range(1, 13)) data['month'] = data.index.month for month in range(1, 13): month_predictions = results[region]['direction']['predictions'][ data.index.month == month ] month_actual = (data['close'].pct_change() > 0)[ data.index.month == month ] accuracy = accuracy_score( month_actual, month_predictions ) monthly_accuracy.loc[month, 'accuracy'] = accuracy # Plot seasonal accuracy plt.figure(figsize=(12, 6)) monthly_accuracy['accuracy'].plot(kind='bar') plt.title(f'Seasonal Prediction Accuracy - {region}') plt.xlabel('Month') plt.ylabel('Accuracy') plt.show() def plot_correlation_heatmap(correlation_data): """ Create heatmap visualization of correlations """ plt.figure(figsize=(12, 8)) sns.heatmap( correlation_data, cmap='RdYlBu', center=0, annot=True, fmt='.2f' ) plt.title('Weather-Price Correlation Heatmap') plt.tight_layout() plt.show()
지역별 결과
AU_WheatBelt(호주 밀 재배 지대)
- AUDUSD 방향 예측의 평균 정확도: 62.67%
- 개별 폴드의 과정에서 최고의 정확도를 제공합니다. 82.22%
- 가격 변동 예측의 RMSE: 0.0303
- 변동성의 RMSE: 0.0016
캔터베리 지역(뉴질랜드)
- NZDUSD 예측의 평균 정확도: 62.81%
- 최고 정확도: 75.44%
- 최소 정확도: 54.39%
- 가격 변동 예측의 RMSE: 0.0281
- 변동성의 RMSE: 0.0015
캐나다 대평원 지역
- 방향 예측의 평균 정확도: 56.92%
- 최대 정확도(3차 폴드): 71.79%
- 가격 변동 예측의 RMSE: 0.0159
- 변동성의 RMSE: 0.0023
계절성 분석 및 시각화
def analyze_model_seasonality(results, data): """ Analyze seasonal performance patterns of the models """ print("Starting seasonal analysis of model performance") seasonal_metrics = {} for region, region_results in results.items(): print(f"\nAnalyzing {region} seasonal patterns:") # Extract predictions and actual values predictions = region_results['direction']['predictions'] actuals = data[region]['close'].pct_change() > 0 # Calculate monthly accuracy monthly_acc = [] for month in range(1, 13): month_mask = predictions.index.month == month if month_mask.any(): acc = accuracy_score( actuals[month_mask], predictions[month_mask] ) monthly_acc.append(acc) print(f"Month {month} accuracy: {acc:.2%}") seasonal_metrics[region] = pd.Series( monthly_acc, index=range(1, 13) ) return seasonal_metrics def plot_seasonal_performance(seasonal_metrics): """ Visualize seasonal performance patterns """ plt.figure(figsize=(15, 8)) for region, metrics in seasonal_metrics.items(): plt.plot(metrics.index, metrics.values, label=region, marker='o') plt.title('Model Accuracy by Month') plt.xlabel('Month') plt.ylabel('Accuracy') plt.legend() plt.grid(True) plt.show()
시각화 결과는 모델의 성능에서 상당한 계절성이 나타남을 보여줍니다.
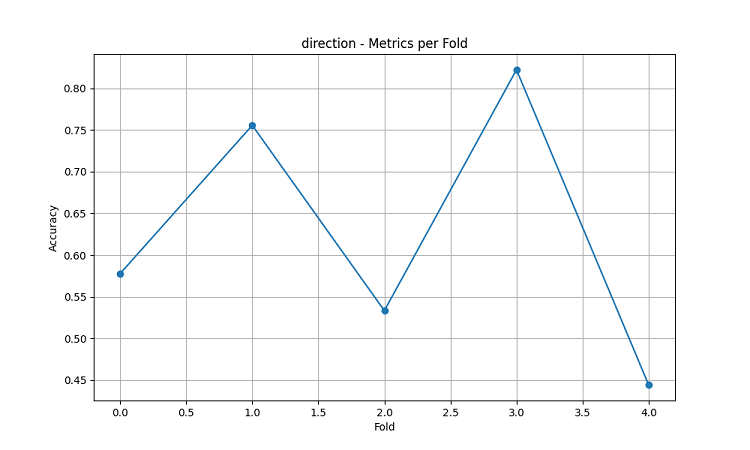

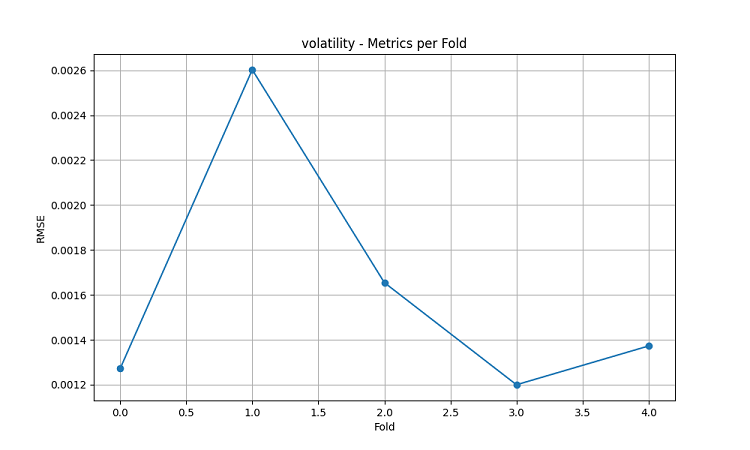
예측 정확도의 최고점은 특히 두드러집니다:
- AUDUSD의 경우: 12월~2월 (밀이 익는 시기)
- NZDUSD의 경우: 우유 생산량이 가장 많은 시기
- USDCAD의 경우: 활발한 초원 성장기
이들 결과는 기상 조건이 농산물 환율에 상당한 영향을 미치며 특히 농산물 생산의 중요한 시기에 더욱 그렇다는 가설을 뒷받침합니다.
결론
이 연구는 농업 지역의 기상 조건과 통화 쌍의 변동성 사이에 유의미한 연관성이 있음을 보여줍니다. 이 예측 시스템은 극한 기상 현상과 농산물 생산량 최고조 기간 동안 높은 정확도를 보였으며 AUDUSD의 경우 평균 62.67%, NZDUSD의 경우 62.81%, USDCAD의 경우 56.92%의 정확도를 나타냈습니다.
추천:
- AUDUSD: 12월부터 2월까지 거래시 바람과 기온 주시.
- NZDUSD: 활발한 유제품 생산 기간 중에 중기 거래.
- USDCAD: 파종 및 수확 시기에 거래.
이 시스템은 정확도를 유지하기 위해, 특히 시장 충격이 발생할 때 정기적인 데이터 업데이트가 필요합니다. 이후 작업에는 데이터 소스를 확장하고 딥러닝을 도입하여 예측의 정확도를 향상시키는 것들이 포함될 것입니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16060
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

많은 사람들에게 CAD가 석유가 아니라 사료 곡물 혼합물이라는 것은 계시가 될 것입니다 :-)))
대부분 국가 통화로 국가 거래소에서 거래되는 것은 ...
USDCAD의 경우 농사철만이라도 추적할 수 있어야 합니다.