
Разрабатываем мультивалютный советник (Часть 32): Секреты шага создания проекта оптимизации (II)
Введение
Разложив ранее весь процесс создания мультивалютного советника по вполне конкретным шагам в предпоследней части 30, мы приступили к более детальной проработке каждого шага. В предыдущей части 31 мы успели рассмотреть первую часть шага создания проекта оптимизации. Напомним, что этот шаг идёт вторым после разработки простой торговой стратегии. На нём мы хотим создать так называемый конвейер оптимизации. Под этим мы подразумеваем базу данных с информацией о большом количестве заданий на оптимизацию определённых советников, которые должны быть последовательно запущены в тестере стратегий. В рамках одного конвейера может быть созданы один или несколько проектов оптимизации. Каждый проект после запуска будет на выходе получать итоговый мультивалютный советник.
Так вкратце выглядит методология, инструменты автоматизации которой мы разрабатываем. Сейчас у нас уже систематизирована и автоматизирована большая часть операций, которая ранее выполнялась вручную. Например, выделены три этапа однотипных задач оптимизации, которые должны быть выполнены в одном проекте и сделан инструмент, позволяющий сгенерировать нужное количество заданий на проведение оптимизации для сохранения в базе данных. Это советник-скрипт создания проекта. Скриптом он назван потому, что не предназначен для торговли, и, выполнив свою задачу по наполнению базы данных по заданным параметрам, этот советник автоматически завершает свою работу.
В прошлый раз мы начали рассмотрение, как можно сформировать или выбрать значения параметров запуска советника создания проекта. Параметры, определяющие создание задач оптимизации первого этапа мы уже рассмотрели. Но ещё остались параметры второго и третьего этапа. Давайте посмотрим, что входит в их состав, какие значения в них надо задавать и как осуществить их обоснованный выбор.
Намечаем путь
Вспомнив немного про выполненную подготовку к первому этапу, приступим к детальному рассмотрению всех параметров второго этапа оптимизации. Будем использовать такие же имена файлов советников создания проекта, советников этапов и базы данных оптимизации, как и в прошлой части. Подопытным проектом будет выступать первый проект, в котором мы планируем получить на выходе мультивалютный советник, работающий на трёх торговых инструментах (GBPUSD, EURUSD, EURGBP). Его торговые стратегии работают на трёх таймфреймах (M3, M5, M12). Интервал оптимизации — первые 9 месяцев 2025 года.
Этот проект достаточно небольшой. Он сделан таким специально, чтобы на нём отработать вопросы запуска и прохождения всех этапов, а потом приступить к его расширению.
В процессе заодно посмотрим, что ещё могло бы послужить причиной отсутствия базы данных итогового советника после завершения выполнения всех задач на конвейере автоматической оптимизации. Для этого мы попробуем поменять некоторые настройки проекта и проследить, как они влияют на успешность получения результатов.
Параметры первого этапа
Советник первого этапа в прошлой части запускался до создания проекта оптимизации. В его параметрах мы не указывали ни название актуальной базы данных оптимизации, ни идентификатор текущей задачи оптимизации, под которым следовало бы сохранять информацию о проходах в базу данных. Поэтому результаты оптимизации первого этапа мы могли посмотреть только в процессе её работы или используя возможность повторно загружать в тестер стратегий результаты проведённых ранее оптимизаций. В базу данных оптимизации, хотя она и создавалась с именем по умолчанию, информация о проходах не попадала.
Проведя предварительное исследование, мы выбрали для параметров первого этапа желаемые значения и указали их в файле советника создания проекта оптимизации, расположенном в проектном репозитории по адресу Optimization/CreateProject.1968401.mq5:
sinput group "::: Этап 1. Поиск" sinput string stage1ExpertName_ = "Stage1.ex5"; // - Советник этапа sinput string stage1Criterions_ = "6,6,6,6,6,6"; // - Критерии оптимизации для задач sinput long stage1MaxDuration_ = 120; // - Макс. продолж. задач (с) //... // Шаблон параметров оптимизации на первом этапе string paramsTemplate1(COptimizationProject *p) { string params = StringFormat( "symbol_=%s\n" "period_=%d\n" "; === Параметры сигнала к открытию\n" "signalSeqLen_=6||4||1||8||Y\n" "periodATR_=28||28||2||210||N\n" "; === Параметры отложенных ордеров\n" "stopLevel_=25000.0||1||0.01||5||Y\n" "takeLevel_=3630.0||1||0.01||5||Y\n" "; === Параметры управление капиталом\n" "maxCountOfOrders_=10||1||1||10||N\n" "maxSpread_=100||10||1||100||N\n", p.m_symbol, p.StringToTimeframe(p.m_timeframe)); return params; }
Они позволяли получать достаточное количество проходов. Почему достаточное? Так можно сказать на основе уже имеющегося предыдущего опыта. Однако если бы такого опыта ещё не было, то только дальнейшие шаги позволят нам подтвердить или опровергнуть гипотезу о достаточности количества проходов. То есть оно вполне может оказаться и недостаточным. В этом случае, нам придется вернуться к подбору параметров первого этапа.
Параметры второго этапа
Как при подготовке к выбору параметров первого этапа оптимизации мы делали пробные запуски оптимизации, так и для планирования второго этапа конвейера автоматической оптимизации нам придётся выполнить несколько предварительных запусков как бы вне конвейера.
Хотя для второго этапа это сделать уже просто так не получится, так как на нём должны использоваться результаты оптимизации первого этапа. Поэтому мы будем либо создавать пробный небольшой проект (с небольшим количеством торговых инструментов и таймфреймов, небольшим интервалом оптимизации и ограниченным временем выполнения одной задачи оптимизации), либо сделаем так, что результаты проходов оптимизации советника первого этапа будут попадать в базу данных.
Всё это нужно для того, чтобы не тратя сильно много времени, получить возможность перейти к моделированию запуска второго этапа. Может показаться странным, почему в рамках шага создания проекта оптимизации мы должны его уже по сути создать, запустить и посмотреть на результаты. Но ничего странного в этом нет, данная методология подразумевает итеративное выполнение. Это значит, что мы сначала как бы пробуем и тренируемся, накапливая информацию, на основе которой вносим корректировки в параметры создаваемых проектов оптимизации, снова создаём, пробуем запускать и возвращаемся на шаг назад при необходимости. Давайте посмотрим вживую, как у нас может возникнуть такая необходимость.
Напомним, что на втором этапе оптимизации мы будем соединять параметры нескольких хороших проходов, полученных в результате первого этапа, в одну группу, работающую вместе в одном советнике. Каждый проход оптимизации на втором этапе будет давать нам результаты совместной работы стратегий в таких группах.
Для второго этапа при создании проекта оптимизации мы должны указать значения параметров в следующем блоке кода:
sinput group "::: Этап 2. Группировка" sinput string stage2ExpertName_ = "Stage2.ex5"; // - Советник этапа sinput string stage2Criterion_ = "6"; // - Критерий оптимизации для задач sinput long stage2MaxDuration_ = 300; // - Макс. продолж. задач (с) //sinput bool stage2UseClusters_= false; // - Использовать кластеризацию? sinput double stage2MinCustomOntester_ = 500; // - Мин. значение норм. прибыли sinput uint stage2MinTrades_ = 20; // - Мин. кол-во сделок sinput double stage2MinSharpeRatio_ = 0.7; // - Мин. коэфф. Шарпа sinput uint stage2Count_ = 8; // - Кол-во стратегий в группе (1 - 16)
Посмотрим подробнее на каждый параметр. Сначала идут три параметра, которые задают, что, как и насколько долго будет оптимизироваться:
- stage2ExpertName_ — советник этапа. Название скомпилированного файла советника первого этапа. Как и для имени советника первого этапа, его можно оставлять равным Stage2.ex5 для всех проектов, если мы не будем специально переименовывать файл Stage2.mq5 в проектном репозитории.
- stage2Criterions_ — критерий оптимизации для задач. Как и в аналогичном параметре для первого этапа, этот строковый параметр может содержать одну или несколько чисел в диапазоне от 0 до 7, разделённых запятыми. Количество цифр определяет сколько раз будет запускаться процесс оптимизации для одного набора входных параметров. Сами числа задают используемый критерий оптимизации для каждой задачи оптимизации в соответствии со следующей таблицей:
Исходя из практики, на втором этапе нам вполне достаточно запустить одну задачу оптимизации, позволив ей работать более продолжительное время. Насколько большим можно поставить это время мы оценим немного позже. В качестве критерия оптимизации тоже будем использовать нормированную среднегодовую прибыль, реализованный как пользовательский критерий (Custom max).Значение Критерий 0 Balance max 1 Profit Factor max 2 Expected Payoff max 3 Drawdown min 4 Recover Factor max 5 Sharpe Ratio max 6 Custom max 7 Complex Criterion max - stage2MaxDuration_ — максимальная продолжительность задачи оптимизации в секундах. При пробных запусках на имеющихся мощностях агентов тестирования мы получаем возможность оценить время, затрачиваемое на один процесс оптимизации (или задачу оптимизации). Наблюдая за процессом после запуска в тестере стратегий, можно заметить, что достаточно хорошие результаты начинают попадаться гораздо раньше, чем тестер решит завершить оптимизацию. Поэтому мы можем сократить время второго этапа автоматической оптимизации, если ограничим время выполнения его задачи оптимизации. Сделать это можно, указав в этом параметре число, большее 0. Если будет указан 0, то это означает отсутствие ограничения по времени.
Сейчас в мы указали значение 300 секунд, то есть 5 минут. Далее посмотрим, будет ли достаточным такое время для процесса оптимизации на втором этапе.
- stage2MinCustomOntester_ — Минимальное значение нормированной прибыли. На второй этап будут попадать только те проходы, которые превысили указанное значение нормированной прибыли. Но если на первом этапе мы будем использовать другой критерий (например, максимальный баланс), то в этом параметре следует указывать пороговое значение для максимального баланса. Как уже было сказано ранее, мы используем при оптимизации только пользовательский критерий нормированной среднегодовой прибыли, поэтому и здесь речь идет именно про него.
Указав значение 500, мы подразумеваем, что на второй этап попадут все проходы, показавшие прибыль более $500 для начального депозита $10000. Это довольно щадящее значение, отсекающее убыточные проходы и проходы с относительно низкой прибылью менее 5% годовых. Однако несмотря на наличие проходов с существенно большей прибылью, мы обычно ставим этот фильтр достаточно низко, чтобы количество взятых проходов не оказалось слишком маленьким. - stage2MinTrades_ — минимальное количество сделок. Проходы, которые совершили меньшее количество сделок, чем указано в этом параметре, не будут попадать на второй этап. Разумное значение этого параметра зависит от длительности интервала оптимизации и используемой торговой стратегии. Для коротких интервалов или стратегий с редкими входами этот параметр надо ставить поменьше, а для более длинных интервалов или высокочастотных стратегий — побольше.
Обычно его подбор выполняется также эмпирическим путём: провели пробный запуск первого этапа, посмотрели на количество сделок у проходов и выбрали значение так, чтобы у довольно большого количества проходов количество сделок было выше выбранного значения. Следует иметь в виду, что даже для одной торговой стратегии, запускаемой на разных инструментах и таймфреймах, среднее количество сделок может сильно отличаться.
В этом параметре мы указываем единое значение, которое будет применяться ко всем проходам первого этапа. Поэтому при выборе следует ориентироваться на результаты первого этапа на том символе и таймфрейме, где сделок было меньше всего. В противном случае может получиться так, что для данного символа и таймфрейма на втором этапе не будет найдена ни одна группа. Хотя с другой стороны, это тоже неплохо — исключение из итогового советника каких-то неудачных торговых инструментов или таймфреймов может повысить устойчивость. - stage2MinSharpeRatio_ — минимальный коэффициент Шарпа. На второй этап попадут проходы со значением коэффициента Шарпа больше, чем указанное значение. К выбору значения этого параметра применимы те же правила, что и к двум предыдущим: ориентируемся по результатам первого этапа, стараясь не уменьшить слишком сильно количество подходящих проходов.
- stage2Count_ — количество стратегий в группе. Мы можем указать здесь число в пределах от 2 до 16. Менее двух экземпляров не будет образовывать группу, а более 16 не позволяет использовать текущая реализация советника второго этапа. При желании, верхний предел можно легко увеличить, внеся изменения в библиотечной части, но мы пока не увидели в этом необходимости.
Выбор значения этого параметра зависит от того, насколько много проходов первого этапа у нас пройдут через заданные фильтры на второй этап. Чем больше их будет, тем больше можно ставить количество стратегий, объединяемых в одну группу. Например, если мы поставим значение 16, то для успешной работы генетической оптимизации нужно, чтобы при случайном выборе 16 проходов из всех доступных с высокой вероятностью все 16 оказались разными. Если среди них выпадет хотя бы два одинаковых, то эта комбинация будет отброшена. Если будет отбрасываться слишком много комбинаций, то генетический алгоритм может выродиться, решив, что подходящих комбинаций вообще нет.
Мы использовали грубую прикидку, что для количества проходов в районе 10000 и более можно использовать значение 16, а для меньшего количества проходов — 8.
Приступим теперь к проверке предварительно выбранных параметров второго этапа.
Запуск второго этапа в пробном проекте
Для чистоты эксперимента, создадим проект заново и базу данных заново. Для этого нам достаточно в общей папке данных терминала удалить файл article.19684.db.sqlite. Если ваша база данных будет называться по-другому, то удаляйте именно её. После этого запустим на любом графике терминала советник создания проекта оптимизации. Мы договорились работать с первым проектом оптимизации, для которого советник создания назван Optimization/CreateProject.1968401.ex5:
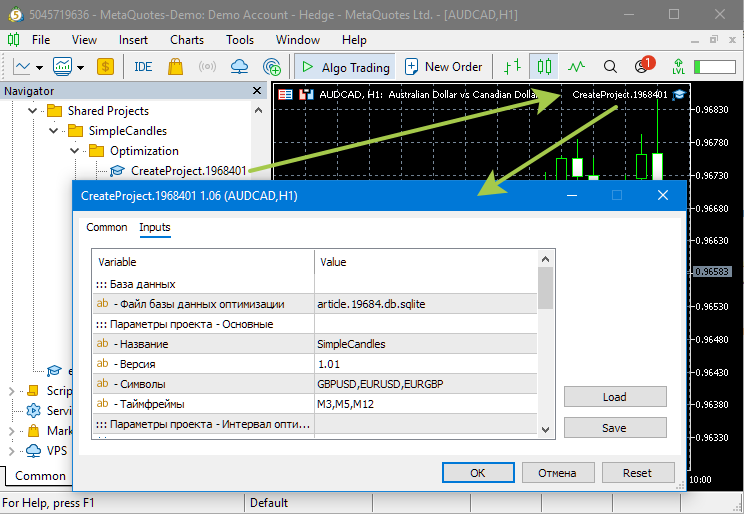
После того как проект оптимизации создан, запустим советник оптимизации. Он одинаковый для всех проектов и называется Optimization/Optimization.ex5:
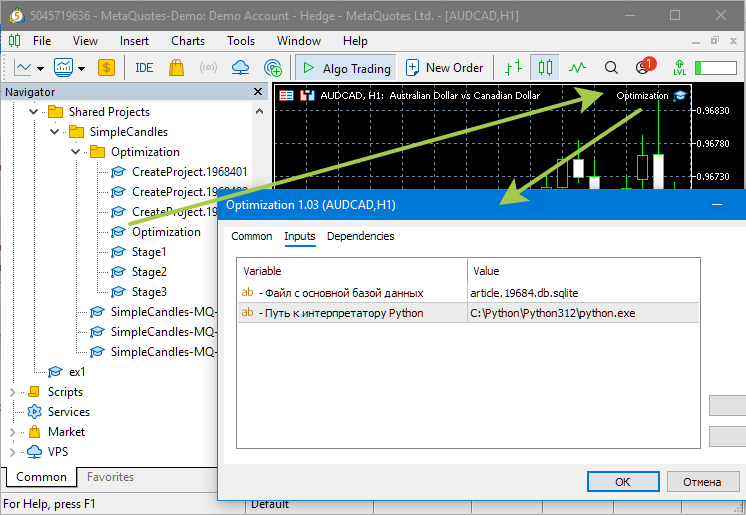
Мы должны увидеть примерно такую картину, свидетельствующую о том, что оптимизация началась:
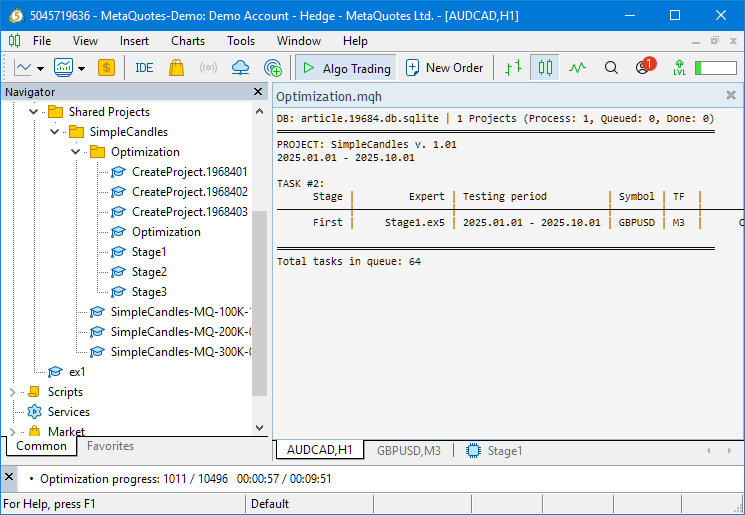
Как видно, в текущей базе данных у нас имеется один проект, который сейчас находится в состоянии Process, то есть запущен. Текущая задача оптимизации является задачей первого этапа для символа GBPUSD и таймфрейма M3. Всего в рамках проекта остаётся выполнить 64 задачи оптимизации, включая все три этапа.
Подождём окончания первого этапа. С учетом заданных параметров, на его прохождение понадобится около 108 минут (3 символа * 3 таймфрейма * 6 задач * 2 минуты = 108). Это не так уж и долго.
В процессе такого пробного запуска удалось поймать ошибку, приводящую к тому, что оптимизация не стартует, а задача считается выполненной. Похоже, что именно она была причиной того, что в прошлый раз у нас не создался итоговый советник для первого проекта. После остановки конвейера путём удаления с графика советника автоматической оптимизации, мы выполнили несколько ручных запусков процесса оптимизации в тестере с последними подставленными настройками.
Это потребовалось сделать потому, что при работе конвейера автоматической оптимизации перед запуском каждой задачи оптимизации логи очищаются для экономии места. С учётом того, что новая задача автоматически запускалась сразу после неудачного запуска предыдущей, было сложно увидеть в логе мелькающее описание ошибки. Вот какие результаты были получены при двух последовательных ручных запусках:
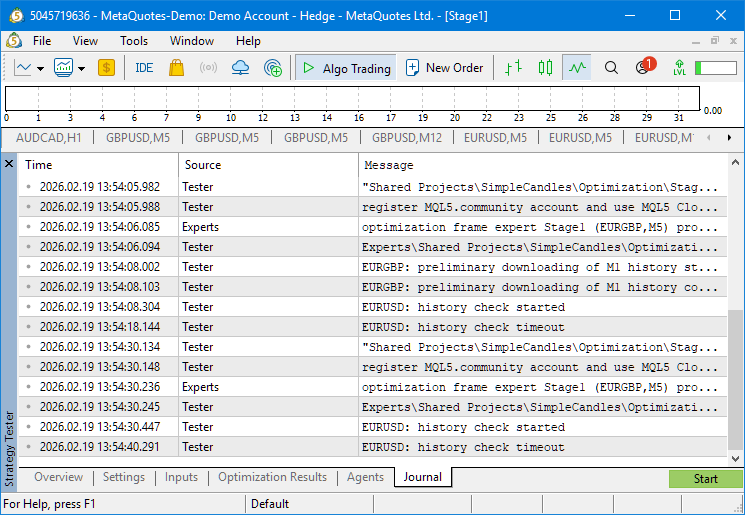
Похоже, что причина ошибки в недоступности торговой истории для нужного символа. Это выглядит несколько странно. Но посмотрим как это выглядит в базе данных. Откроем её в SQLite Studio и прейдём к просмотру содержимого таблицы задач (tasks):
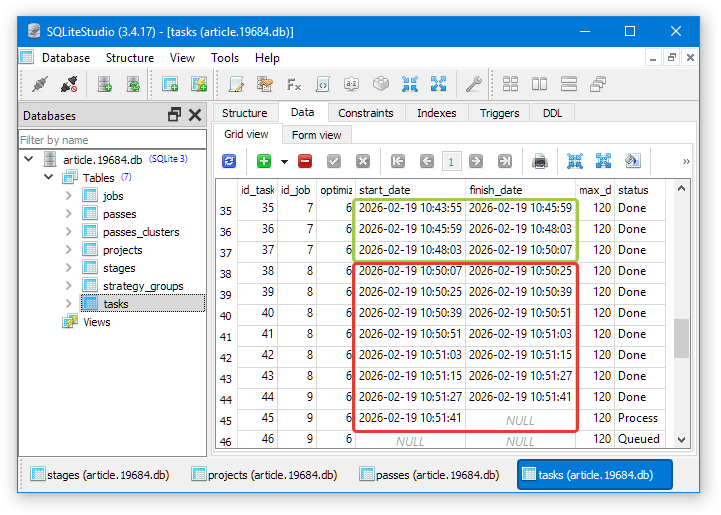
Зелёной границей обведены задачи оптимизации, которые выполнились нормально, то есть их время выполнения составило около двух минут. Красной границей обведены задачи оптимизации, для которых время выполнения было существенно меньше (около 15 секунд). Видно, что ошибка проявилась после перехода на работу с идентификатором id_job=8. Посмотрим на эту работу в таблице работ (jobs):
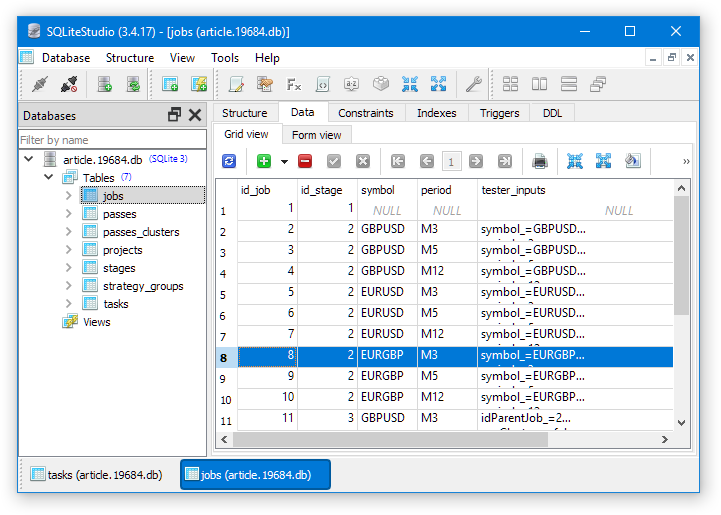
Как видно, в этой работе впервые начинается оптимизация по символу EURGBP. Для этого почему-то должна была снова скачиваться история по символу EURUSD, хотя чуть раньше у нас успешно завершились оптимизации на этом символе и на том же временном интервале. Видимо, дело было в потере связи терминала с торговым демо-серверов MetaQuotes.
Откатим статусы тех работ, которые не смогли выполниться. Для этого надо в столбце status таблицы работ (jobs) поменять значение на Queued. Такое изменение автоматически сменит статусы всех задач, входящих в состав данных работ:
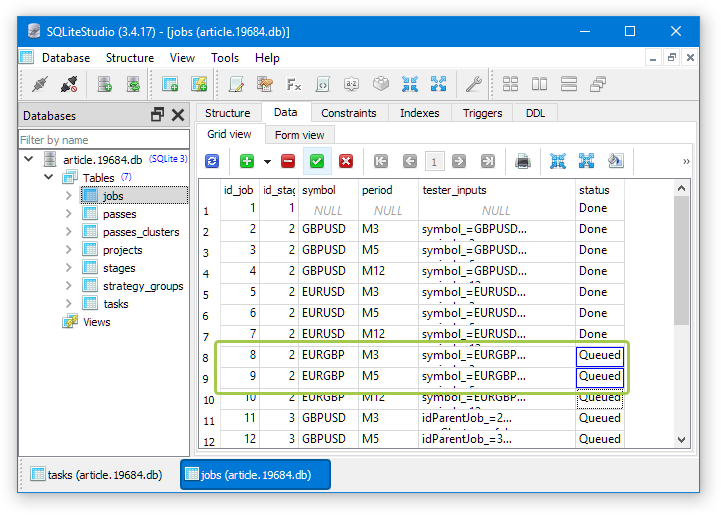
Какое-то время терминал не мог подключиться к серверу, но потом связь снова восстановилась. Мы увидели это при очередном ручном запуске оптимизации, когда сообщение об ошибках проверки истории сменилось на сообщения о нормальном старте генетической оптимизации:
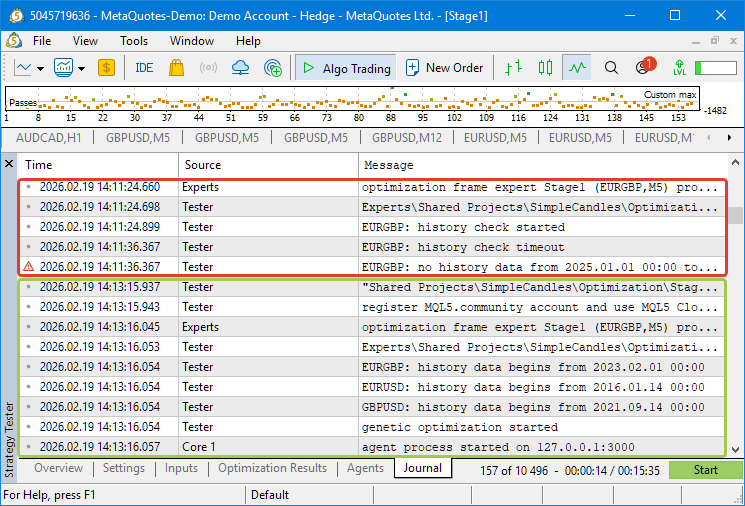
Запустим советник оптимизации заново и будем надеяться, что в этот раз всё закончится успешно. Но с учётом полученного опыта в ближайшем будущем надо будет подумать над защитой от подобных ситуаций. Если причина в том, что терминал не может подключиться к серверу, то можно добавить проверку статуса подключения при запуске и окончании прохода. Если терминал оказывается в статусе "не подключен", то очередная задача оптимизации или не запускается, или не помечается как выполненная. При этом советник оптимизации не будет сразу пытаться запустить задачу заново, а будет периодически проверять, но восстановилось ли подключение терминала к серверу.
К счастью, на этот раз первый этап оптимизации завершился успешно, и очередь наконец-то дошла до задач второго этапа:
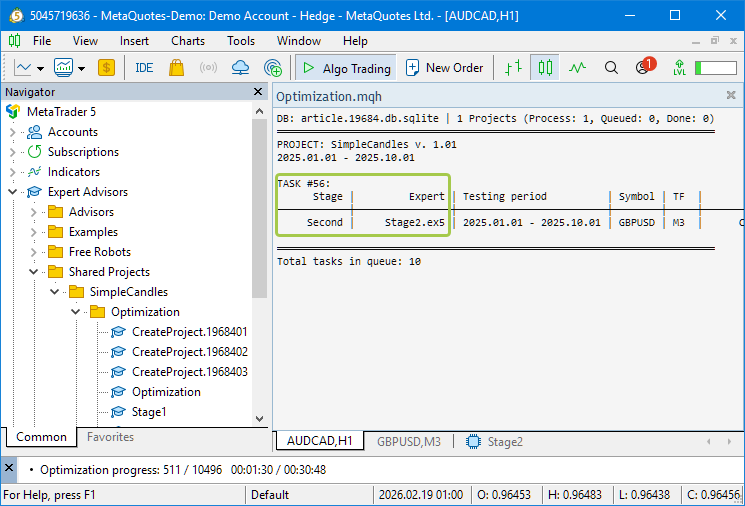
Переключимся на вкладку Inputs, чтобы посмотреть, как выглядят параметры оптимизации советника второго этапа:
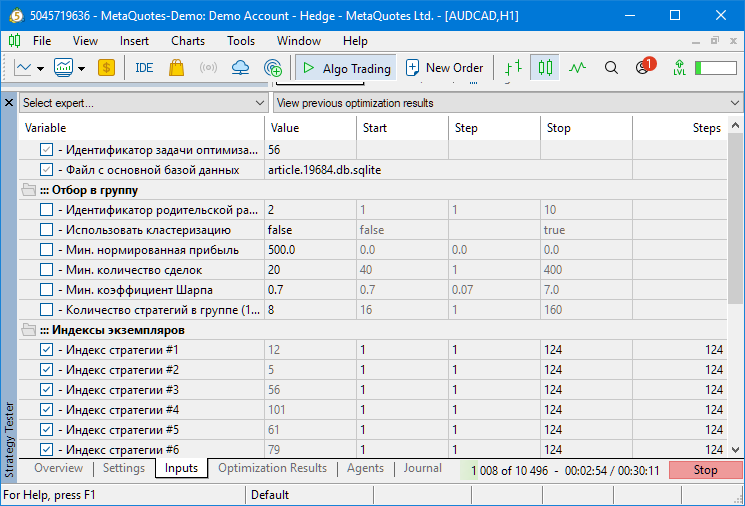
Как видно, там есть уже знакомые нам параметры идентификатора задачи оптимизации и имени используемой базы данных. Их мы уже видели в советнике первого этапа и ещё раз увидим в советнике третьего этапа. Далее идут параметры фильтрации проходов первого этапа (отбора в группу). Их мы тоже уже описали выше. А дальше идут 16 параметров, в которых задаются индексы проходов первого этапа, выбранные из полученных после фильтрации.
Поскольку в результате запуска первого этапа оптимизации у наз от раза к разу может получаться разное количество подходящих проходов, то диапазон этих параметров мы не задаём их вручную. Они устанавливаются самим советником второго этапа через функцию ParameterSetRange(). Из-за этого в тестере на вкладке Inputs реальные используемые там значения не видны.
Если мы переключимся на вкладку результатов оптимизации, то видно, что номера проходов принимают значения вплоть до 5000 и более:
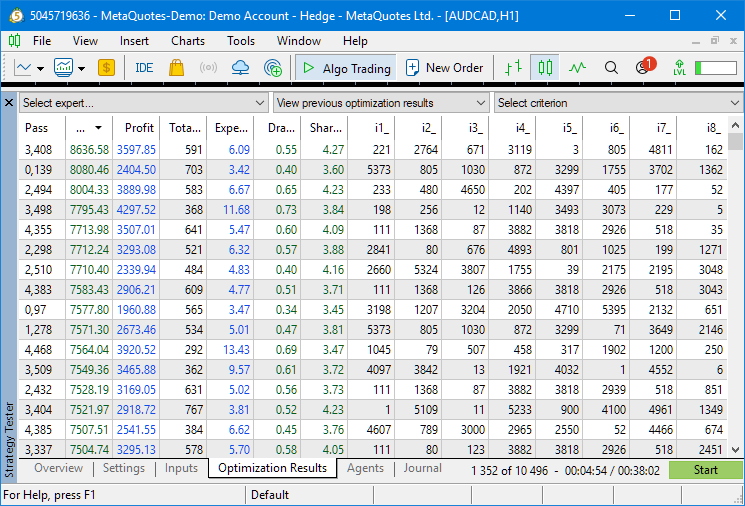
Это значит, что для задачи GBPUSD M3 у нас выбралось на второй этап конвейера автоматической оптимизации более 5000 проходов. Этого вполне достаточно для организации групп из 8 экземпляров. Переключившись на вкладку визуализации результатов процесса оптимизации, видно, что оптимизация бодро находит хорошие группы:
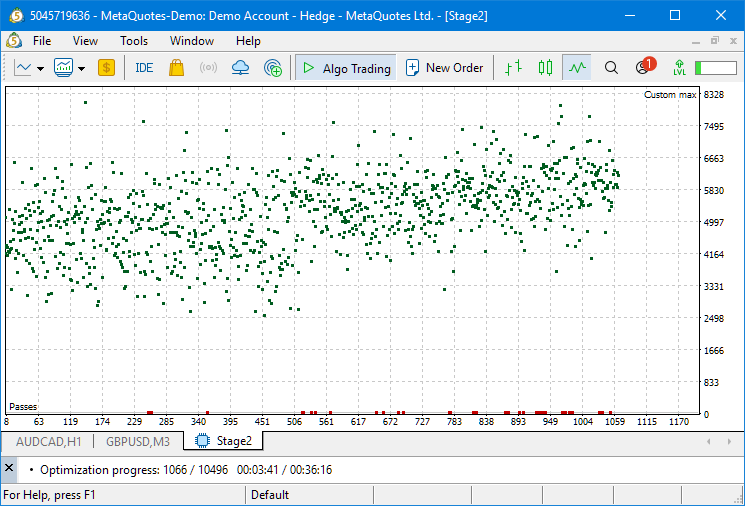
Менее чем за четыре минуты выполнено более тысячи проходов. Каждый проход — это проход советника с какой-то группой из 8 экземпляров. Нормированная прибыль для удачно протестированных групп сосредоточена в диапазоне от $3000 до $8000. Количество неудачных групп, когда среди восьми индексов встретились одинаковые (красные точки внизу графика) довольно мало.
Но не будем ожидать окончания процесса оптимизации и остановим его. Для этого мы сначала удалим советник оптимизации с того графика, к которому он был прикреплён, а только потом нажмём кнопку "Стоп" в тестере стратегий. Если сделать наоборот, то можно не успеть удалить советник оптимизации до того, как он выдаст тестеру новое задание и запустит следующую задачу оптимизации.
Теперь, когда в базе данных оптимизации уже есть результаты первого прохода, мы можем посмотреть, как влияют параметры второго этапа на его прохождение.
Попробуем ужесточить критерии отбора и поставить больше стратегий в группе: 16 вместо 8. Чтобы лучше понять, как влияют остальные параметры, посмотрим на SQL-запрос, который в советнике второго этапа получает результаты первого этапа оптимизации (проходы одиночных экземпляров торговой стратегии с разными значениями параметров):
// Запрос на получение необходимой информации из основной базы данных string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_);
Этот SQL-запрос можно перенести SQLite Studio и там его запускать, подставляя разные значения параметров. Например, такой запрос покажет, сколько будет взято проходов первого этапа для родительской работы с id_job=2 (первый этап для GBPUSD, M3)
SELECT DISTINCT p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job WHERE (j.id_job = 2 AND p.custom_ontester >= 500 AND trades >= 20 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
При запуске такого запроса у нас получилось 5544 строки. Но если повысить минимальный коэффициент Шарпа в запросе до 3 (p.sharpe_ratio >= 3), то остаётся уже только 577 строк. Это уже существенно меньше. При других запусках проекта оптимизации у нас могут получиться другие точные значения количества отобранных проходов, но соотношение будет похожим.
Но можно пойти и другим путём: менять значения параметров советника второго этапа в тестере стратегий после остановки конвейера автоматической оптимизации и смотреть как будет изменяться процесс оптимизации. В этом случае нам не надо самим выяснять в базе данных идентификатор родительской работы. Советник второго этапа сам определит его по идентификатору текущей задачи, указанному в первом входном параметре.
Попробуем поставить больше стратегий в группе, увеличив это значение до 16. Одновременно повысим минимальную нормированную прибыль до $6000 и минимальный коэффициент Шарпа до 3 (в этом случае число отобранных проходов составило 266):
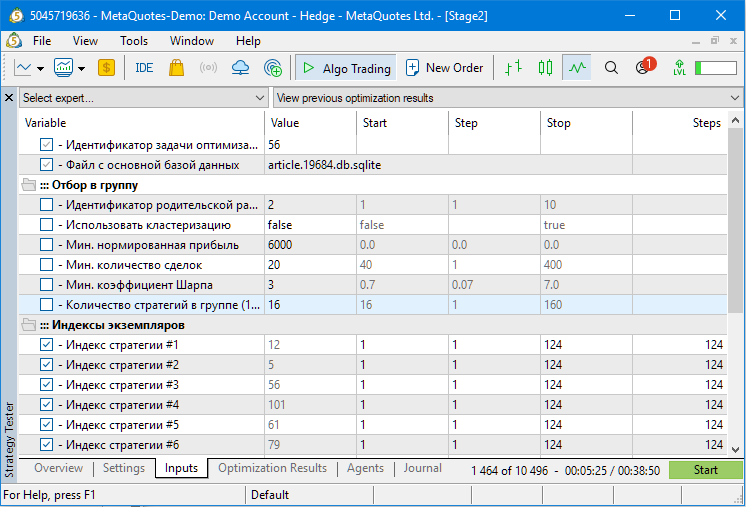
Запускаем оптимизацию и наблюдаем такую картину:
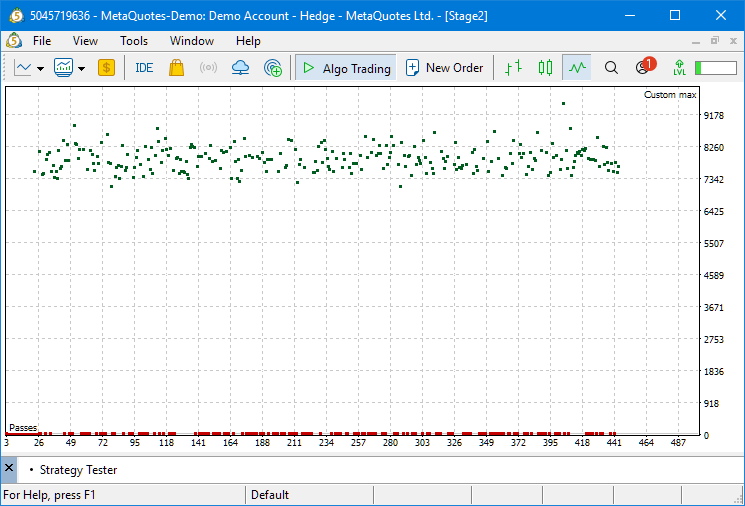
Теперь неудачных запусков проходов тестера гораздо больше, но из-за более высоких требований к качеству проходов первого этапа удачные запуски дают сразу более высокие результаты нормированной прибыли, минимальное значение которой начинается от $7000, а не от $3000, как раньше:
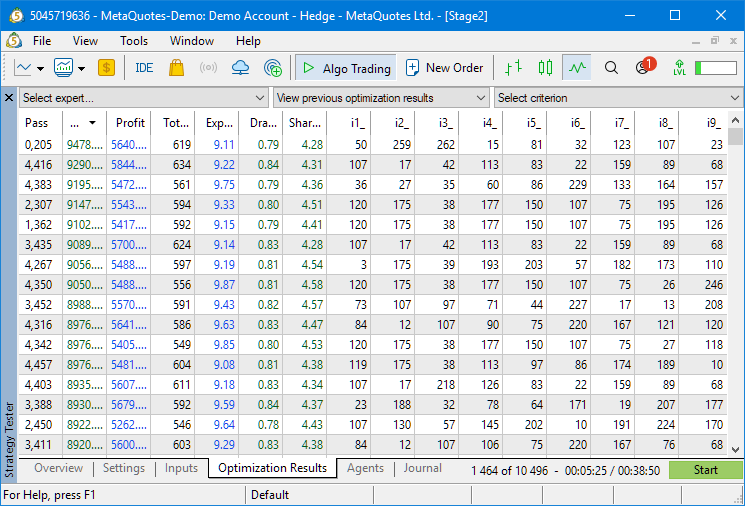
Попробуем ещё увеличить значение минимальной нормированной прибыли до $8000, но уменьшив количество стратегий в группе до 8:
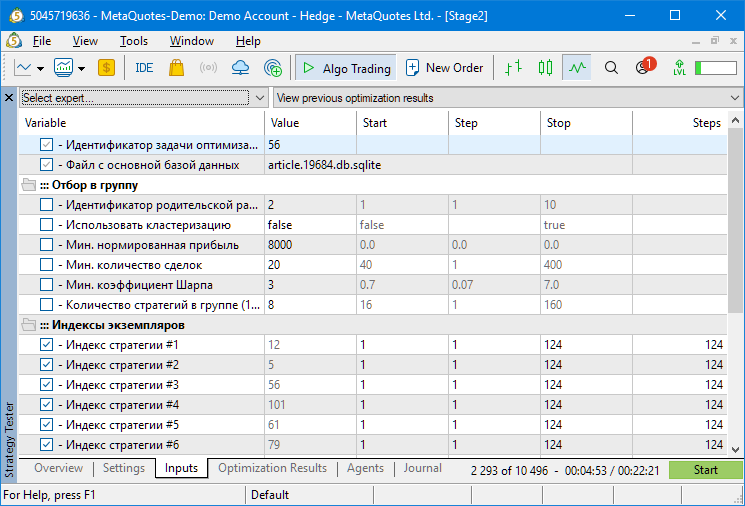
В этом случае у нас берётся только 46 проходов первого этапа, поэтому оставь мы количество стратегий в группе, равное 16, генетическая оптимизация с высокой вероятностью не смогла бы найти ни одной комбинации, где все 16 индексов проходов первого этапа в одной группе были бы разными. Но для восьми стратегий в группе такие комбинации нашлись:
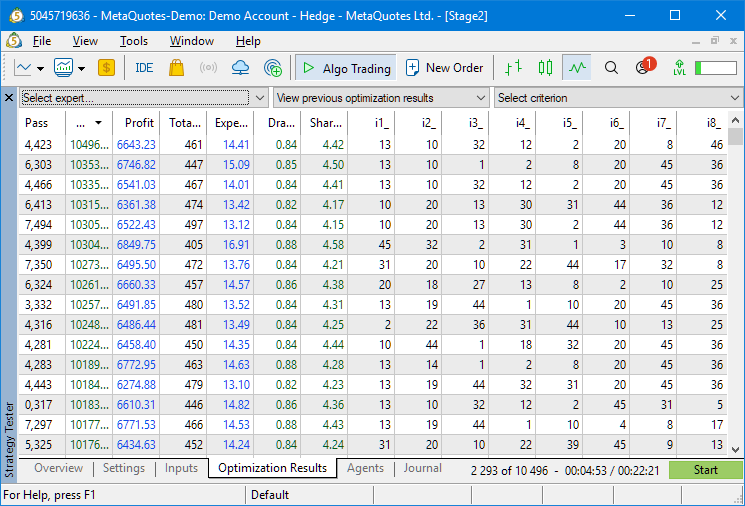
Но здесь надо проявлять осторожность. Как уже было сказано выше, слишком высокие первоначальные требования к результатам первого прохода могут привести к тому, что для некоторых пар символ-таймфрейм у нас может не оказаться достаточного количества проходов для успешного прохождения второго этапа. А для диверсификации желательно обеспечить как можно более широкое разнообразие одиночных экземпляров торговых стратегий. Пусть на каких-то участках будет получена меньшая прибыль, но зато на других участках удастся избежать большего убытка.
Поэтому вернёмся к уже установленным ранее значениям по умолчанию для второго этапа и запустим конвейер автоматической оптимизации до конца. Пока что просто посмотрим на результаты третьего этапа, получившиеся в этот раз:
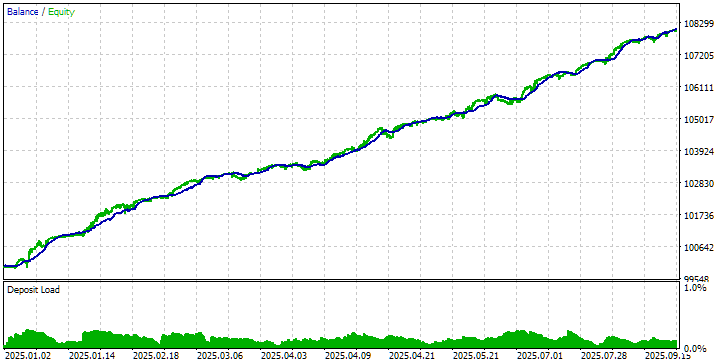
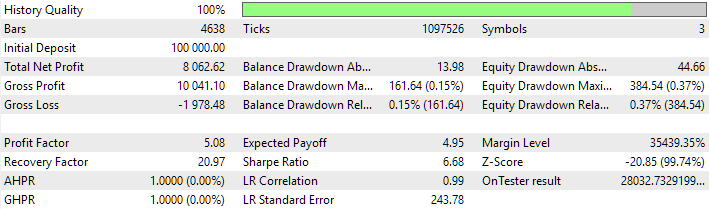
Весьма обнадёживающие результаты. Судя по значению параметра OnTester result, ожидаемая среднегодовая прибыль при просадке 10% составит около 280%. Но не будем забывать, что одно дело получить красивые результаты в тестере на истории и совсем другое — смочь повторить их в будущем на торговом счёте.
Заключение
В данной части мы завершили рассмотрение параметров второго этапа конвейера автоматической оптимизации мультивалютного советника. Были детально разобраны настройки, отвечающие за фильтрацию проходов первого этапа и формирование групп торговых стратегий. Практические запуски показали, что успешная работа генетического алгоритма требует баланса: излишне мягкие критерии отбора снижают качество итоговых комбинаций, тогда как чрезмерно жёсткие требования могут оставить недостаточно кандидатов для эффективного поиска.
Важным аспектом методологии остаётся итеративность процесса. Пробные запуски на уменьшенных проектах позволяют быстро накопить статистику и скорректировать параметры до полномасштабной оптимизации, экономя время и вычислительные ресурсы. Кроме того, в ходе тестирования была выявлена уязвимость конвейера при потере связи с сервером истории, что подчёркивает необходимость внедрения дополнительных проверок статуса подключения для обеспечения надёжности автоматизированного процесса.
На этом мы в целом закончили рассмотрение шага создания проекта. Первый и второй этап были подробно описаны. И хотя есть ещё и третий этап, которого мы пока особо не касались, логичнее будет рассмотреть его уже в рамках следующего шага — запуска проекта оптимизации. Но к его написанию приступим уже в следующей части.
Спасибо за внимание, и до новых встреч!
Важное предупреждение
Все результаты, изложенные в этой статье и всех предшествующих статьях цикла, основываются только на данных тестирования на истории и не являются гарантией получения хоть какой-то прибыли в будущем. Работа в рамках данного проекта носит исследовательский характер. Все опубликованные результаты могут быть использованы всеми желающими на свой страх и риск.
| # | Имя | Версия | Описание | Последние изменения |
|---|---|---|---|---|
| SimpleCandles | Рабочая папка проекта (внутри MQL5/Shared Projects) | |||
| 1 | SimpleCandles-MQ-100K-10.mq5 SimpleCandles-MQ-200K-07.mq5 SimpleCandles-MQ-300K-05.mq5 | 1.05 | Итоговые советники для параллельной работы нескольких групп модельных стратегий. Параметры будут браться из встроенной библиотеки групп. Их может быть больше, каждый из них может использоваться как шаблон | Часть 30 |
| └ Optimization | Папка советников оптимизации проекта | |||
| 2 | CreateProject.1968401.mq5 CreateProject.1968401.mq5 CreateProject.1968401.mq5 | 1.06 1.05 1.05 | Советник-скрипт создания проекта с этапами, работами и задачами оптимизации. | Часть 31 |
| 3 | Optimization.mq5 | 1.03 | Советник для автоматической оптимизации проектов | Часть 29 |
| 4 | Stage1.mq5 | 1.04 | Советник оптимизации одиночного экземпляра торговой стратегии (Этап 1) | Часть 30 |
| 5 | Stage2.mq5 | 1.04 | Советник оптимизации группы экземпляров торговых стратегий (Этап 2) | Часть 30 |
| 6 | Stage3.mq5 | 1.04 | Советник, сохраняющий сформированную нормированную группу стратегий в базу данных эксперта с заданным именем. | Часть 30 |
| └ Strategies | Папка стратегий проекта | Часть 25 | ||
| 7 | SimpleCandlesStrategy.mqh | 1.03 | Класс торговой стратегии SimpleCandles | Часть 30 |
| Adwizard | Папка библиотеки Adwizard (внутри MQL5/Shared Projects) | |||
| └ Base | Базовые классы, от которых наследуются другие классы проекта | |||
| 8 | Advisor.mqh | 1.04 | Базовый класс эксперта | Часть 10 |
| 9 | Factorable.mqh | 1.06 | Базовый класс объектов, создаваемых из строки | Часть 28 |
| 10 | FactorableCreator.mqh | 1.00 | Класс создателей, связывающих названия и статические конструкторы классов-наследников CFactorable | Часть 24 |
| 11 | Interface.mqh | 1.01 | Базовый класс визуализации различных объектов | Часть 4 |
| 12 | Receiver.mqh | 1.04 | Базовый класс перевода открытых объемов в рыночные позиции | Часть 12 |
| 13 | Strategy.mqh | 1.04 | Базовый класс торговой стратегии | Часть 10 |
| └ Database | Файлы для работы со всеми типами баз данных, используемых советниками проекта | |||
| 14 | Database.mqh | 1.13 | Класс для работы с базой данных | Часть 29 |
| 15 | db.adv.schema.sql | 1.00 | Схема базы данных итогового советника | Часть 22 |
| 16 | db.cut.schema.sql | 1.00 | Схема урезанной базы данных оптимизации | Часть 22 |
| 17 | db.opt.schema.sql | 1.06 | Схема базы данных оптимизации | Часть 29 |
| 18 | Storage.mqh | 1.01 | Класс работы с хранилищем Key-Value для итогового советника в базе данных эксперта | Часть 23 |
| └ Experts | Файлы с общими частями используемых советников разного типа | |||
| CreateProject.mqh | 1.07 | Библиотечный файл для советника-скрипта создания проекта с этапами, работами и задачами оптимизации | Часть 30 | |
| 19 | Expert.mqh | 1.24 | Библиотечный файл для итогового советника. Параметры групп могут браться базы данных эксперта | Часть 28 |
| 20 | Optimization.mqh | 1.06 | Библиотечный файл для советника, управляющего запуском задач оптимизации | Часть 29 |
| 21 | Stage1.mqh | 1.19 | Библиотечный файл для советника оптимизации одиночного экземпляра торговой стратегии (Этап 1) | Часть 23 |
| 22 | Stage2.mqh | 1.04 | Библиотечный файл для советника оптимизации группы экземпляров торговых стратегий (Этап 2) | Часть 23 |
| 23 | Stage3.mqh | 1.04 | Библиотечный файл для советника, сохраняющего сформированную нормированную группу стратегий в базу данных эксперта с заданным именем. | Часть 23 |
| └ Optimization | Классы, отвечающие за работу автоматической оптимизации | |||
| 24 | OptimizationJob.mqh | 1.00 | Класс для работы этапа проекта оптимизации | Часть 25 |
| 25 | OptimizationProject.mqh | 1.00 | Класс для проекта оптимизации | Часть 25 |
| 26 | OptimizationStage.mqh | 1.00 | Класс для этапа проекта оптимизации | Часть 25 |
| 27 | OptimizationTask.mqh | 1.01 | Класс для задачи оптимизации (для создания) | Часть 29 |
| 28 | Optimizer.mqh | 1.04 | Класс для менеджера автоматической оптимизации проектов | Часть 29 |
| 29 | OptimizerTask.mqh | 1.06 | Класс для задачи оптимизации (для конвейера) | Часть 29 |
| └ Strategies | Примеры торговых стратегий, используемые для демонстрации работы проекта | |||
| 24 | HistoryStrategy.mqh | 1.00 | Класс торговой стратегии воспроизведения истории сделок | Часть 16 |
| 25 | SimpleVolumesStrategy.mqh | 1.11 | Класс торговой стратегии с использованием тиковых объемов | Часть 22 |
| └ Utils | Вспомогательные утилиты, макросы для сокращения кода | |||
| 26 | ConsoleDialog.mqh | 1.01 | Класс для вывода текстовой информации на график | Часть 28 |
| 26 | ExpertHistory.mqh | 1.00 | Класс для экспорта истории сделок в файл | Часть 16 |
| 27 | Macros.mqh | 1.07 | Полезные макросы для операций с массивами | Часть 26 |
| 28 | MTTester.mqh | — | Файл для работы с тестером стратегий из библиотеки MultiTester | Часть 28 |
| 29 | NewBarEvent.mqh | 1.00 | Класс определения нового бара для конкретного символа | Часть 8 |
| 30 | SymbolsMonitor.mqh | 1.01 | Класс получения информации о торговых инструментах (символах) | Часть 28 |
| └ Virtual | Классы для создания различных объектов, объединённых использованием системы виртуальных торговых ордеров и позиций | |||
| 31 | Money.mqh | 1.01 | Базовый класс управления капиталом | Часть 12 |
| 32 | TesterHandler.mqh | 1.07 | Класс для обработки событий оптимизации | Часть 23 |
| 33 | VirtualAdvisor.mqh | 1.12 | Класс эксперта, работающего с виртуальными позициями (ордерами) | Часть 28 |
| 34 | VirtualChartOrder.mqh | 1.02 | Класс графической виртуальной позиции | Часть 28 |
| 35 | VirtualCloseManager.mqh | 1.00 | Класс менеджера закрытия | Часть 28 |
| 36 | VirtualHistoryAdvisor.mqh | 1.00 | Класс эксперта воспроизведения истории сделок | Часть 16 |
| 37 | VirtualInterface.mqh | 1.00 | Класс графического интерфейса советника | Часть 4 |
| 38 | VirtualOrder.mqh | 1.09 | Класс виртуальных ордеров и позиций | Часть 22 |
| 39 | VirtualReceiver.mqh | 1.04 | Класс перевода открытых объемов в рыночные позиции (получатель) | Часть 23 |
| 40 | VirtualRiskManager.mqh | 1.06 | Класс управления риском (риск-менеждер) | Часть 28 |
| 41 | VirtualStrategy.mqh | 1.09 | Класс торговой стратегии с виртуальными позициями | Часть 23 |
| 42 | VirtualStrategyGroup.mqh | 1.04 | Класс группы торговых стратегий или групп торговых стратегий | Часть 28 |
| 43 | VirtualSymbolReceiver.mqh | 1.00 | Класс символьного получателя | Часть 3 |
Также исходный код доступен в публичных репозиториях SimpleCandles и Adwizard
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования