
Моделирование рынка (Часть 20): Первые шаги на SQL (III)

Введение
Приветствую всех в очередной статье из серии о создании системы репликации/моделирования.
В этой статье мы начнем рассматривать довольно-таки сложную тему. Но если вы сможете понять то, что мы увидим дальше, ты сможете значительно продвинуться в своей карьере. Это будет нелегкая задача. Тем не менее, мы постараемся изложить это как можно проще.
Подготовка сценария
В предыдущей статье « Моделирование рынка (Часть 19): Первые шаги на SQL (II)» мы объяснили, как с помощью скриптов можно добавлять, изменять и даже удалять записи в базе данных. Однако, чтобы продвинуться в объяснении, нам нужна база данных с минимальным количеством элементов. Так вы сможете по-настоящему понять то, что будет объяснено.
Хотя мы можем работать с базой данных, которая содержит около 10 записей, но легче будет понять, когда мы используем файл с более чем 15 тысячами записей. То есть, если бы мы попытались создать такое вручную, то эта задача была бы огромной. Однако трудно найти такую базу данных, даже для учебных целей, доступную для скачивания. Но в этом нет необходимости: мы можем использовать MetaTrader 5 для ее генерации. Может быть, она не будет идеальной, но, по крайней мере, в ней будет много записей, а это именно то, что нам нужно.
Чтобы понять, как мы будем использовать MetaTrader 5 для создания базы данных и изучения нашей темы, нам нужно немного вернуться назад во времени.
Есть люди и даже небольшие организации, которые используют Excel как базу данных. Многие из вас, возможно, не верят в это, либо не замечают, что это происходит. И это не только Excel: есть и другие программы, которые также используются таким образом. Но пока мы ограничимся Excel. Когда мы используем Excel для работы с базой данных, на ленте настроек появляется дополнительная опция. На изображении ниже можно увидеть, что имеется в виду.

Чтобы эта вкладка появилась, нам нужно сделать несколько вещей. Одна из них, и, возможно, самая простая, — это открыть файл, который имеет определенный формат или структуру. Это делается из того места, которое показано на изображении ниже.
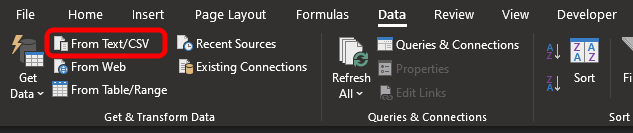
Помните, что мы показываем один из способов, но он не единственный. Теперь возникает вопрос: какой тип файла мы собираемся использовать здесь? Вы, скорее всего, будете использовать различные типы файлов. Когда я говорю это, я имею в виду, что внутренняя структура файла может быть любой, но, чтобы упростить и лучше понять материал, давайте перейдем к MetaTrader 5. На изображении ниже мы видим то, к чему я веду.
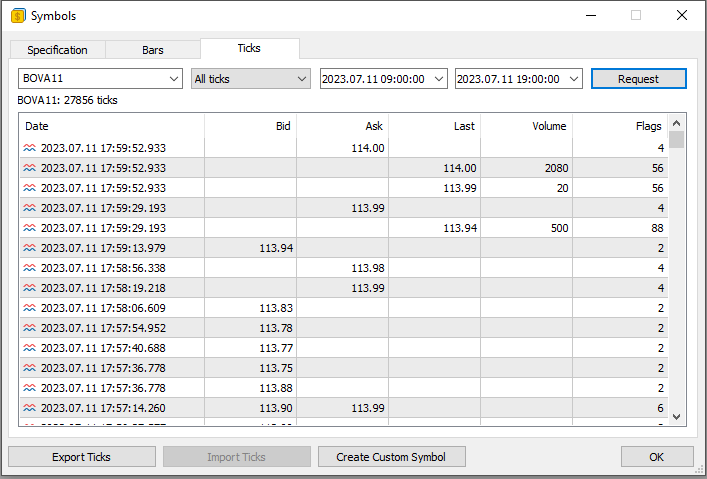
Прошу заметить, что здесь мы отправили запрос на торговый сервер, чтобы получить все тики, торгуемые в определенный день для конкретного символа. То, что показано на изображении выше, является именно набором информации из базы данных. Однако в этом окне мы не можем манипулировать данными, как это возможно при использовании специальной программы. Тем не менее, мы можем экспортировать эту информацию в файл. Он может иметь формат CSV.
После того, как данный файл будет сохранен на локальном диске, мы сможем использовать его в программе, которая обрабатывает файлы баз данных. Однако, и это важно понять, прежде чем приступить к обработке содержимого файла и интерпретации его как таблицы данных, нам необходимо преобразовать его в базу данных. Именно в этом заключается магия процесса. И это именно то, к чему мы хотим прийти.
Первый контакт вне WorkBench
Затем, после сохранения в файле информации, показанной на изображении выше, мы сможем сначала загрузить её в Excel. В результате Excel больше не будет обрабатывать файл так, как вы, возможно, представляете. Excel фактически преобразует файл в эквивалент базы данных. Таким образом, интерфейс Excel изменится и будет выглядеть следующим образом:
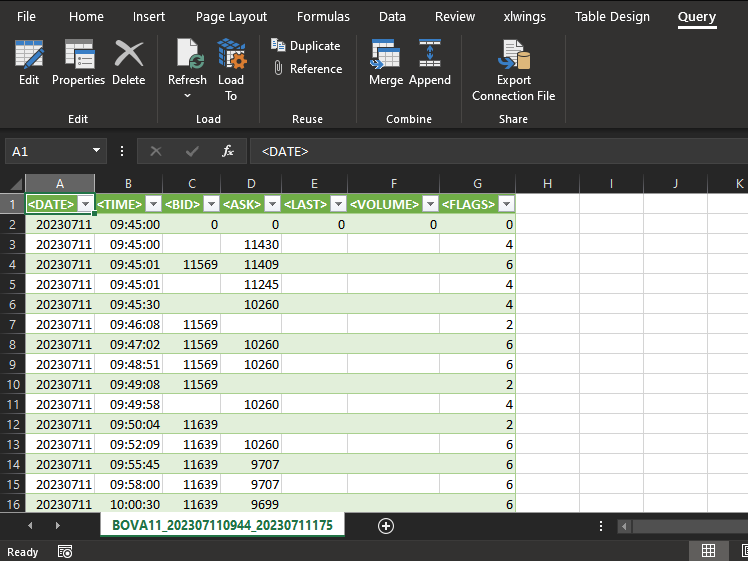
Хорошо. Вы можете подумать, что здесь можно будет работать так же, как если бы вы использовали команды SQL. На самом деле, это не совсем так, когда используем Excel или другую программу, которая предоставляет определенный доступ к базе данных. Хотя на самом деле можно сделать здесь многое, опыт будет далеко не таким, как при использовании чистого SQL. Тогда давайте забудем об Excel и пойдем в другом направлении. Это необходимо для того, чтобы мы могли понять команду, которая будет объяснена.
Использование MetaEditor для исследования базы данных
Скорее всего, вы думаете, что у нас большая проблема, поскольку в большинстве случаев файл, загруженный MetaTrader 5 и сохраненный в формате CSV, может занимать несколько мегабайт. А превратить что-то подобное в приемлемый формат (чтобы можно было использовать SQL-запросы к этим загруженным данным) кажется очень сложной задачей, которую могут решить только великие мастера компьютерного дела. Однако правда заключается в том, что, если вы не понимаете предоставленные в ваше распоряжение инструменты, у вас всегда будет проблема, которую нужно решить, даже если решение находится прямо перед вами.
Таким образом, самый простой способ преображения всех данных, загруженных MetaTrader 5, в более удобный формат без использования программирования — это использовать MetaEditor. Это фактически превратит загруженный CSV-файл в настоящий файл базы данных. Но как это сделать? Как преобразовать файл CSV, сохраненный MetaTrader 5, в файл базы данных с помощью MetaEditor? Это кажется чем-то невероятно сложным, но это далеко не так, мои дорогие читатели. Всё дело в том, чтобы понять, какой инструмент у вас в руках.
Сначала сделаем следующее: давайте начнем с создания новой, полностью чистой базы данных. Мы уже объясняли, как это сделать с помощью MetaEditor. После создания данного файла базы данных нам необходимо выполнить следующие действия.
Сначала выберем опцию, указанную на изображении ниже:
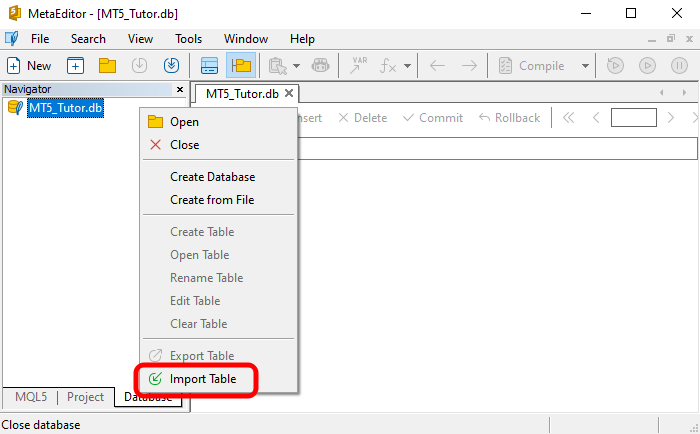
Данная опция позволяет импортировать таблицу в базу данных. Помните, что таблица — это набор записей. А поскольку файл CSV представляет собой набор записей, мы импортируем его как если бы это была таблица. После выбора нужного параметра откроется окно, в котором необходимо настроить параметры импорта данных для MetaEditor для создания окончательной таблицы. Это окно можно увидеть на изображении ниже.
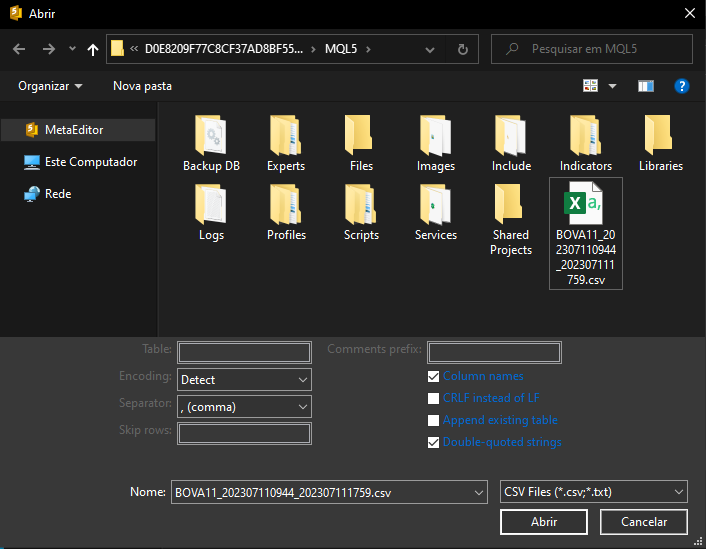
Для максимального упрощения мы поместили файл CSV в каталог MQL5. Но, в конце концов, главное, чтобы мы выбрали правильный файл. Однако, если мы просто выберем файл, как показано на изображении выше, и сразу же нажмем кнопку ОТКРЫТЬ, MetaEditor не отобразит никакого ответа. Это связано с тем, что мы только выбрали файл, но ещё не импортировали его. Необходимо выполнить некоторые дополнительные настройки в этом же окне. Каждая из настроек зависит от конкретного случая, нет жестких правил.
Вы должны понимать, по крайней мере в общих чертах, что содержит файл, который будет импортирован. Бесполезно просто открыть MetaEditor и запросить импорт данных и полагаться на то, что MetaEditor поймет, что содержится в файле. Так не бывает. Итак, первое, что нам нужно настроить, - это разделитель информации. Помните, что эти данные были загружены MetaTrader 5. И, если вы не изменили формат файла, в качестве разделителя используется символ табуляции. Изменив эту информацию, мы получаем изображение ниже.
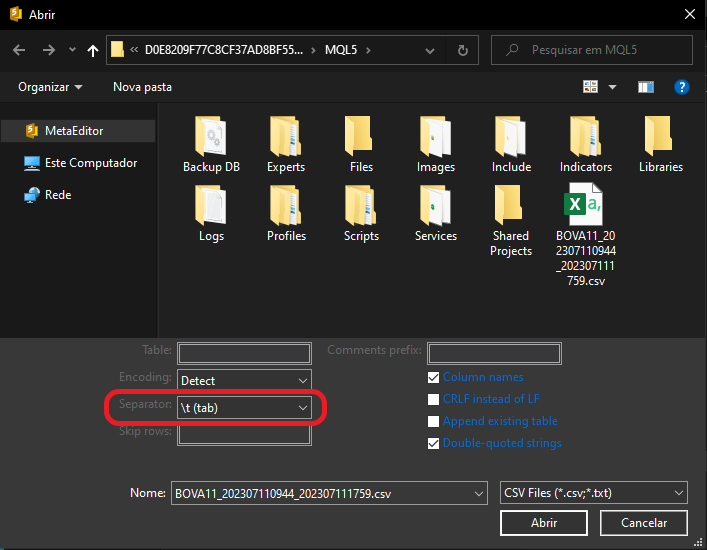
Хорошо, это первый пункт, который нужно настроить. Теперь у нас есть ещё один момент, учитывая, что вы только что скачали файл и импортируете его сюда, в MetaEditor. Речь идет о названии таблицы, которая будет использоваться. Сейчас многие могут быть сбиты с толку, потому что в MetaEditor у нас нет никаких таблиц, включенных в базу данных. Можно увидеть это, посмотрев на изображения выше, где в момент запроса на импорт файла не указано ни одной таблицы.
Но тогда какую информацию мы должны указать в качестве названия таблицы? Нам просто нужно указать название таблицы, которое будет присвоено ей при создании. Поэтому мы и предложили использовать абсолютно чистый файл. Таким образом, данный шаг станет более понятным. Затем введем название поля, как показано на изображении ниже.
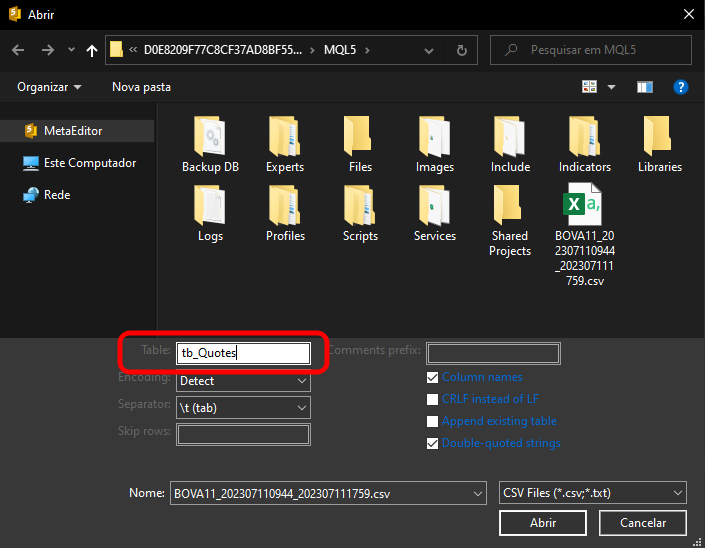
Можно дать ему любое имя. После этого мы сможем нажать кнопку ОТКРЫТЬ. Помните, что в зависимости от содержимого импортируемого файла нам может понадобиться настроить здесь дополнительные параметры. Однако, поскольку мы только что скачали файл с MetaTrader 5 и импортируем его с помощью MetaEditor, этих шагов будет достаточно для нашей цели.
Как только мы нажмем «ОТКРЫТЬ», нам нужно будет полностью забыть то, что вы, возможно, уже видели при использовании этого же файла в Excel. Здесь всё будет совершенно отличаться от того, что вы видели до прочтения этих статей о базах данных. Итак, глядя на экран MetaEditor, мы сначала увидим следующее изображение.
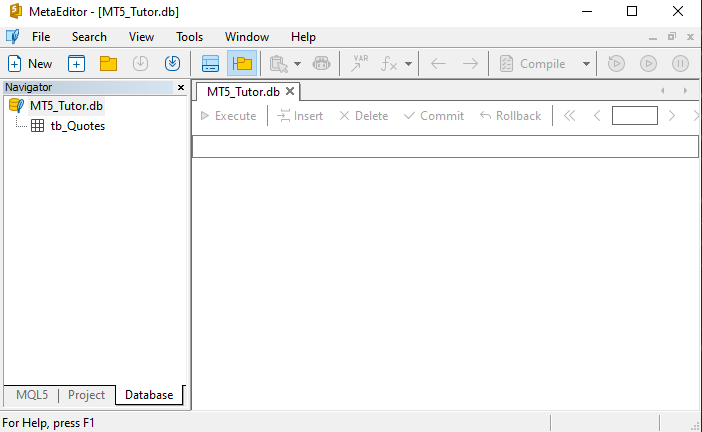
Идеально. Если вы видите это, значит MetaEditor преобразовал файл CSV в таблицу в базе данных с именем MT5_Tutor.db. Скорее всего, в данный момент вы находитесь в состоянии полной растерянности и абсолютно не понимаете, что произошло только что. Но давайте разберемся, потому что это важное понятие.
Вся информация, которая была загружена MetaTrader 5, когда мы запросили у сервера данные по символу на определенную дату, теперь больше не представляет собой беспорядочный набор данных. Всё это было систематизировано и представлено в виде таблицы. Данная таблица содержит в заголовке тот же заголовок, что и в файле CSV. Итак, если мы хотим, чтобы у столбцов в нашей базе данных было другое название, перед импортом данных из CSV достаточно отредактировать только строку 01, чтобы столбцы получили другое название.
Но делайте это только в том случае, если вы действительно понимаете то, что делаете, потому что при ошибке можно получить совершенно бесполезную базу данных. Даже если эти названия вам не нравятся, можно изменить их с помощью команды SQL, так как теперь мы будем иметь дело не с файлом CSV, а с базой данных.
«Всё это очень хорошо, но как мне получить доступ к информации в этой базе данных? Я думал, что это будет что-то похожее на Excel или другую программу для работы с таблицами, но то, что я вижу в MetaEditor, для меня совершенно бесполезно и не имеет никакой ценности».
Ну, если вы так думаете, то это связано с тем, что вы не имеете представления, насколько мощным инструментом является база данных, а умение работать с ней требует обучения и усердия. Но я не хочу обидеть или унизить вас, мои уважаемые читатели. Я знаю, что многие, увидев изображение выше, будут полностью разочарованы, предполагая, что увидят некое волшебство, полное интересных вещей. Если смотреть с этой точки зрения, конечно, кажется чем-то бессмысленным и бесполезным, что не стоит изучения и углубления знаний в области SQL.
Но позвольте мне попытаться немного изменить ваше представление о SQL. Теперь, наконец, мы рассмотрим одну из команд, которая, без сомнения, потребует от нас больше всего усилий при изучении. Но, чтобы четко разделить понятия, давайте посмотрим на это в новой теме.
Наконец, команда SELECT
Команда SELECT в своей наиболее простой форме имеет следующий синтаксис:
SELECT * FROM table;
Прошу заметить, что это точно такая же команда, которая используется в анимации ниже.
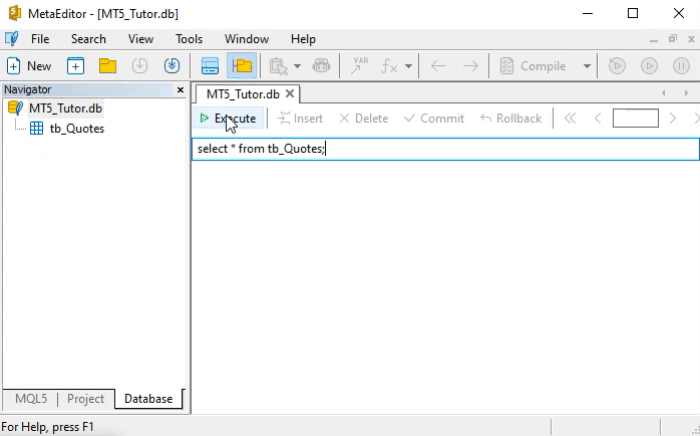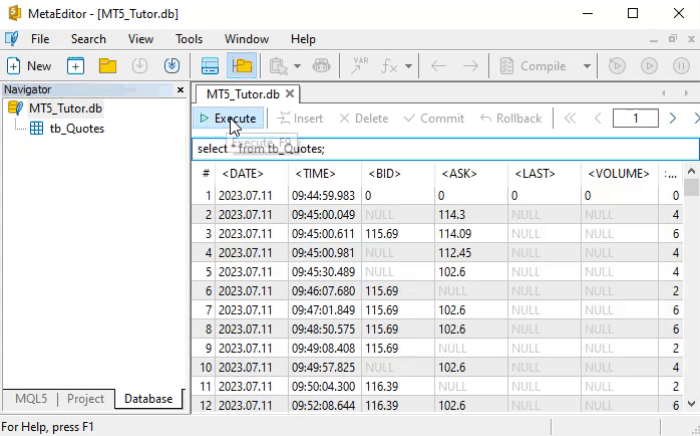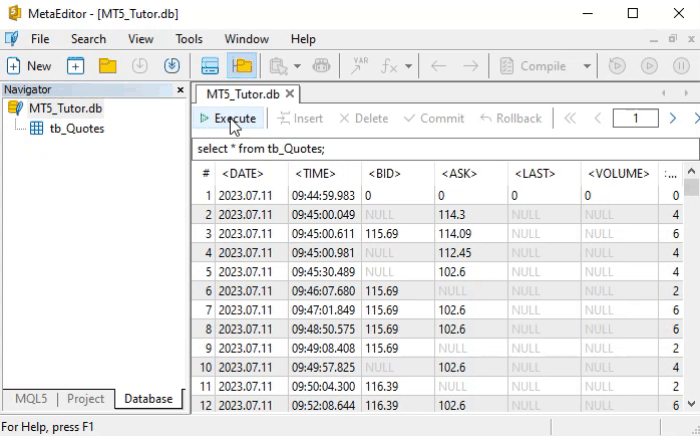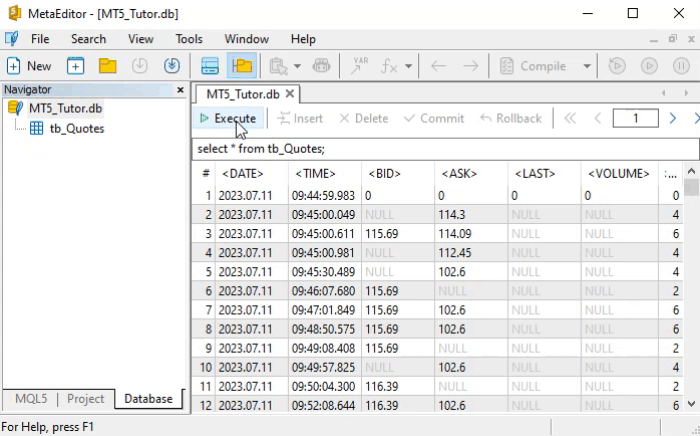
Но как интерпретировать данную команду SELECT? Это проще простого. И не только эту команду: все команды в SQL были продуманы с умом, чтобы их синтаксис был легко усвоен. Чтобы понять и осознать то, что мы только сказали, давайте посмотрим, как читать приведенную выше команду.
Мы должны прочитать это следующим образом: выбираем все данные, источником которых является таблица с названием table. Это буквальный способ прочтение данной команды. Если вы действительно поняли, как это читать, то наверняка уже догадываетесь, что мы можем делать довольно интересные вещи. Здесь мы приводим пример буквального способа прочтения, но попробуйте сделать то же самое с другими командами SQL. Вскоре вы заметите, что скорость их усвоения будет довольно высокой, потому что понять каждую из команд очень просто.
Но, возвращаясь к тому, что нас интересует в данный момент, давайте посмотрим на результат анимации. Там у нас довольно большое количество возвращаемых записей. Именно этого мы и добивались. Это связано с тем, что, если использовать команду SELECT в таблице с небольшим количеством записей, мы подумаем, что нет смысла использовать SQL. Однако, когда количество записей достаточно велико, нам может быть интереснее изучить программирование на SQL.
В чем заключается реальная проблема, с которой мы здесь сталкиваемся? Проблема заключается в объеме возвращаемой информации. Однако, если вы поняли, как буквально читать команду SELECT, вы, наверное, уже думаете о том, как уменьшить объем данных, применив какой-то фильтр. Хорошо, если вы начали так думать, это уже хороший знак. И тем более, если вы подумали о замене звездочки чем-то другим, поскольку звездочка будет универсальным символом. Тот, кто использует командную консоль, знает, о чем идет речь. Однако, если вы думали так, как мы только что упомянули, то вы на правильном пути. Вам просто нужно, чтобы вас как-то направляли, чтобы вы делали всё правильнее.
Давайте теперь немного подумаем. «Если бы мы заменили звездочку в команде, почему нам нужно было бы её заменить, чтобы отфильтровать результаты, которые вернет SQL?» Это тот же вопрос, на который должны были ответить разработчики языка SQL, когда SQL ещё находился в стадии разработки. Подумайте немного и скажите мне: как бы вы выполнили данную фильтрацию, имея огромный объем данных и много столбцов?
Но прежде, чем объяснить, как дизайнеры и разработчики блестяще решили эту проблему, хочу обратить ваше внимание на ещё одну деталь, которая присутствует здесь, в MetaEditor. Это связано с тем, что данная деталь может оказаться важной в будущем. Посмотрите на изображение ниже.

Прошу заметить, что мы выделили область изображения. Причина в том, что, если посмотреть на правый угол выделенной области, то заметим, что было загружено некоторое количество записей. В некоторых случаях может потребоваться переход между этими записями для просмотра найденных данных, когда мы проводим более тщательную фильтрацию. Нажав на стрелки в отмеченной области, можно перейти к следующему блоку загруженных записей. Обратите внимание, что блоки загружаются с шагом в тысячу.
Таким образом, значение, указанное в отмеченной области, представляет тысячу блоков. Итак, если мы хотим перейти к блоку восемь тысяч, достаточно изменить значение с одного на девять, и блок с номером восемь тысяч загрузится для отображения в MetaEditor. Но почему девять? Разве значение не должно быть восемь? Причина в том, что подсчет ведется от единицы. Однако значение «один» указывает, что блок закончится значением «тысяча». Сначала это может показаться немного запутанным, но немного практики всё исправит, и вы скоро поймете логику.
Попробуйте поработать с интерфейсом MetaEditor, чтобы понять, как здесь всё устроено; он мне кажется гораздо более легким, чем WorkBench. Тем не менее, мы можем сделать некоторые вещи без необходимости использования более мощного WorkBench, особенно когда мы только исследуем базу данных.
Хорошо. Теперь вернемся к нашему вопросу о том, как фильтровать результаты поиска. Возможно, вы всё ещё ломаете голову над решением, которое было бы легко принять. Но решение, разработанное дизайнерами, на мой взгляд, является лучшим из всех возможных. Данная звездочка может быть заменена на что-то другое. Мы покажем это в другой раз. Но для фильтрации поиска разработчики добавили ещё одну вещь к команде SELECT. Однако здесь есть небольшой трюк, который, в зависимости от того, что мы хотим найти и как мы это сделаем, приведет к небольшому изменению синтаксиса команды SELECT.
Первое, что нужно понять: как использовать названия столбцов в поиске. Это может показаться немного странным. Но если вы уже фильтровали результаты в таблице Excel, то знаете, что нужно выбрать столбец, а затем указать, как будет выполняться фильтрация: по значению, которое будет больше, меньше или равно определенному значению или критерию. То же самое происходит и здесь, в SQL. Только здесь мы не делаем вещи так, как это делается в Excel. Мы отправляем команду для выполнения SQL. Таким образом, фильтрация будет правильно выполнена.
Например, предположим, что мы хотим, чтобы SQL показал нам все записи, значение FLAGS которых равно 88. Тогда мы знаем, что в команде SELECT нам нужно будет ввести что-то вроде:
FLAGS = 88
Это кажется очевидным, но для этого нужно добавить одну маленькую деталь к команде. Таким образом, предыдущая команда, представленная в начале темы, будет выглядеть таким образом:
SELECT * FROM tb_Quotes WHERE "<FLAGS>" = 88;
Помните, что название нашей таблицы — tb_Quotes. Хорошо, при выполнении приведенной выше команды все записи со значением столбца FLAGS которых равно 88, будут отображены в области результатов. Теперь обратите внимание: почему название столбца взято в кавычки? Причина в том, что это строка. Всякий раз, когда мы собираемся использовать строку в SQL, она должна быть заключена в кавычки. Кроме того, прошу заметить, что рядом с названием столбца находятся символы «больше» и «меньше». Если мы не будем использовать кавычки, SQL может спутать эти символы имени с какой-либо внутренней командой самого SQL.
В этот момент можно подумать: «но зачем мне это делать в SQL? Если бы я использовал Excel или другую подобную программу, я бы получил те же результаты, и даже более простым способом. Я не вижу смысла в изучении SQL». Действительно, то, что мы только что показали, можно сделать в Excel, причем даже проще, но дело в том, что вы что-то упускаете из виду. На данный момент мы только начинаем понимать, как работает SQL. На самом деле, все эти начальные действия можно выполнить в других программах, причем многие из них гораздо более простые.
Однако, когда мы работаем с реальными базами данных, мы часто используем связанные таблицы и связанные поиски. Такого рода вещи нельзя делать в Excel и других программах на его подобии. Ладно, это было бы возможно, но гораздо более трудоемко и дорого, чем в SQL.
Помимо этого факта, существует ещё один, который заставляет многих опытных программистов не программировать определенные вещи. Они просто предпочитают использовать SQL или что-то подобное для выполнения определенных работ. Чтобы понять, о чем идет речь, нам нужно вернуться к первой статье о SQL. Там мы упомянули, что зачастую предпочтительнее использовать уже существующий инструмент или технологию, чем программировать ряд процедур и подпрограмм для выполнения определенных задач. Итак, на данном этапе, когда вы уже знаете, как создавать, вставлять, изменять, удалять и просматривать записи в базе данных, мы можем немного углубиться в то, о чем говорилось в той статье.
Давайте подумаем о пройденном материале. Чтобы сделать всё то, что мы делали, используя минимальные знания SQL, вам, даже при использовании языка, позволяющего работать с различными данными (например Python), потребовалось бы гораздо больше времени для получения тех же результатов, что и у нас. Это связано с тем, что вместо SQL вы решили бы сделать то же самое с помощью Python. Я не говорю, что вы не смогли бы этого сделать. Я просто говорю, что вам понадобится гораздо больше времени, чтобы создать, протестировать и разработать подпрограммы для выполнения того, что мы видели до настоящего момента.
И помните, что пока мы представили только самые основные аспекты SQL. И всё же, даже если вы являетесь компетентным программистом с хорошими знаниями Python, вам понадобится несколько дней или даже недель, чтобы получить что-то хотя бы отдаленно похожее или, как многие хотели бы, аналогичное тому, что можно сделать в SQL. Мы вернемся к этой теме, потому что не хотелось бы, чтобы вы тратили время на попытки изобрести велосипед. Если вы изучите хотя бы самые основы SQL, но с акцентом на его использование по прямому назначению, то поймете, что нет смысла программировать что-то, что делает то же самое, что и SQL.
Заключительные идеи
На данный момент мы не показали один из основных моментов SQL. Хотя мы упоминали об этом в предыдущих статьях, мы ещё не использовали то, что делает базы данных такой обширной темой. Но, поскольку в сегодняшней статье мы представили базовую команду, которая позволяет нам искать информацию в базе данных, мы можем немного углубиться в вопросы, которые делают SQL чем-то, что вы действительно должны учитывать, если хотите стать хорошим профессионалом. В следующей статье мы поговорим ещё немного о программировании на SQL, потому что есть одно понятие, которое ещё предстоит изучить и объяснить.
Это понятие включает в себя первичные ключи и внешние ключи, что имеет большое значение при создании системы связанных таблиц. Умение использовать связанные таблицы имеет огромное значение, прежде всего потому, что они очень помогают при поиске в базе данных, но также позволяют нам делать и создавать некоторые вещи, которые иначе были бы невозможны. Итак, если вас действительно заинтересовала тема баз данных, не пропустите следующую статью, там материалы станут немного серьезнее.
| Файл | Описание |
|---|---|
| Experts\Expert Advisor.mq5 | Демонстрирует взаимодействие между Chart Trade и советником (для взаимодействия требуется Mouse Study). |
| Indicators\Chart Trade.mq5 | Создает окно для настройки отправляемого ордера (для взаимодействия требуется Mouse Study) |
| Indicators\Market Replay.mq5 | Создает элементы управления для взаимодействия с сервисом репликации/моделирования (для взаимодействия требуется Mouse Study) |
| Indicators\Mouse Study.mq5 | Обеспечивает взаимодействие между графическими элементами управления и пользователем (необходимо как для работы системы репликации/моделирования, так и на реальном рынке). |
| Services\Market Replay.mq5 | Создает и поддерживает сервис репликации/моделирования рынка (главный файл всей системы) |
| Code VS C++\Servidor.cpp | Создает и поддерживает серверный сокет, разработанный на C++ (версия Mini Chat) |
| Code in Python\Server.py | Создает и поддерживает сокет Python для связи между MetaTrader 5 и Excel. |
| Indicators\Mini Chat.mq5 | Позволяет реализовать мини-чат через индикатор (для работы требуется использование сервера) |
| Experts\Mini Chat.mq5 | Позволяет реализовать мини-чат с помощью советника (для работы требуется сервер). |
| Scripts\SQLite.mq5 | Демонстрирует использование скрипта SQL с помощью MQL5 |
| Files\Script 01.sql | Демонстрирует создание простой таблицы с внешним ключом. |
| Files\Script 02.sql | Показывает добавление значений в таблицу |
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/12928
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования