
Нейросети в трейдинге: Оптимизация Cross-Attention для анализа длинных последовательностей рынка (Окончание)

Введение
Мы продолжаем ранее начатую работу по переносу подходов, предложенных авторами исследования "Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin", в финансовую среду средствами MQL5. Ранее мы подробно рассматривали, как саму концепцию фреймворка STCA, так и особенности его адаптации к задачам анализа финансовых временных рядов. Затем последовательно перенесли ключевые механизмы, уделив особое внимание вычислительной эффективности и практической реализуемости. Поэтому на данном этапе нет необходимости возвращаться к детальному разбору исходных положений, куда важнее удержать в фокусе их смысловую связку и аккуратно перенести её в прикладную плоскость.
В основе фреймворка STCA лежит идея целенаправленного извлечения информации из истории. В отличие от классических архитектур, стремящихся описать всю структуру последовательности целиком, STCA исходит из более сдержанной и, в некотором смысле, более прикладной логики: значимость прошлого определяется исключительно в контексте текущего решения. Такой взгляд хорошо согласуется с природой финансовых рынков, где история сама по себе не несёт ценности вне момента её использования. Механизм Target-to-History Cross Attention, подробно разобранный ранее, выступает здесь как средство дисциплинированной работы с данными, позволяющее выделять действительно релевантные участки последовательности без избыточного усложнения модели.

Не менее важным оказалось и то, что подобная организация вычислений естественным образом снимает ряд ограничений, характерных для классических моделей внимания. Линейная по длине последовательности сложность делает возможной работу с существенно более длинной историей без потери устойчивости и без чрезмерного роста вычислительных затрат. В контексте финансовых данных это открывает доступ к более глубоким временным зависимостям, которые довольно часто игнорируются или искусственно обрезаются. В предыдущей статье мы показали, что подобные архитектурные преимущества могут быть не только теоретически обоснованы, но и практически реализованы в рамках существующих инструментов.
С инженерной точки зрения проделанная работа позволила сформировать полноценный вычислительный контур. Реализация основных компонентов фреймворка средствами MQL5 в связке с OpenCL потребовала внимательного подхода к организации памяти, синхронизации вычислений и оптимизации ключевых операций. Интеграция подходов, предложенных авторами фреймворка STCA, в реализованные ранее механизмы FlashAttention дала возможность существенно снизить накладные расходы при работе с длинными последовательностями, обеспечив при этом стабильность прямого и обратного проходов. В результате мы получили рабочий инструмент, готовый к использованию в более сложных прикладных сценариях.
Именно этот переход — от аккуратно собранной архитектуры к её практическому применению — и определяет содержание текущей статьи. До настоящего момента основное внимание было сосредоточено на том, как должна быть устроена модель и каким образом обеспечить ее эффективную реализацию, теперь же акцент смещается на использование реализованных решений в торговых моделях и оценку их эффективности в условиях реального рынка.
Объект верхнего уровня
Авторы фреймворка STCA предлагают достаточно сложную архитектурную схему, в которой поток данных организован как многоуровневая система взаимодействующих блоков. Подобная организация даёт ощутимый выигрыш с точки зрения выразительности модели, но одновременно усложняет ее практическое применение. Чем богаче внутренняя логика, тем выше требования к аккуратности интеграции и согласованности вычислений.
В чистом виде такая архитектура требует от разработчика постоянного контроля за формами данных, синхронизацией операций и порядком прохождения сигналов. На уровне исследовательского прототипа это допустимо, но в прикладной торговой системе быстро превращается в источник нестабильности. Сложность начинает работать против нас: малейшее рассогласование на одном из этапов способно исказить итоговый результат, причём обнаружить причину бывает непросто.
Чтобы сохранить сильные стороны подхода и одновременно сделать его удобным для практического использования, мы строим объект верхнего уровня CNeuronSTCA, инкапсулирующий всю внутреннюю механику фреймворка. Он берёт на себя управление потоком данных, скрывая за единым интерфейсом все этапы обработки — от подготовки исходных данных до формирования итогового представления. Таким образом, сложная архитектура остается внутри системы, а на прикладном уровне мы получаем предсказуемый и воспроизводимый инструмент.
При этом важно подчеркнуть, что в рамках данного проекта мы не ограничиваемся прямым воспроизведением оригинальной архитектуры STCA. Существенным дополнением становится интеграция с ранее рассмотренным фреймворком OneTrans, но уже в строго определённой роли. Если STCA отвечает за выбор релевантной информации из последовательности в контексте текущего момента, то OneTrans решает задачу согласования разнородных исходных данных.
Речь идет о принципиально важном для финансовых моделей аспекте. Помимо временных рядов, торговая система оперирует множеством несинхронных и зачастую непоследовательных признаков. OneTrans позволяет привести такие разнородные источники к единому представлению и, что особенно важно, обрабатывать их параллельно с временными последовательностями в рамках одной модели. Это снимает необходимость искусственно встраивать непоследовательные признаки в последовательность или, наоборот, упрощать временной ряд до табличного формата. В результате каждая группа данных сохраняет свою природу, а модель получает возможность работать с ними в наиболее адекватной форме.
Структура объекта верхнего уровня на первый взгляд выглядит компактной. Однако за этим минимализмом скрывается достаточно насыщенная внутренняя архитектура.
class CNeuronSTCA : public CNeuronSpikeConvBlock { protected: CLayer cPrepare; CNeuronBaseOCL cLastSequence; CNeuronBaseOCL cLastNonSequence; CNeuronAddToStack cStackSequence; CFieldAwareParams cScenarios; CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSTCA(void) {}; ~CNeuronSTCA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronSTCA; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
Наследование от CNeuronSpikeConvBlock выбрано не случайно. Родительский класс берет на себя финальную обработку данных на последнем слое SwiGLU-FFN и одновременно обеспечивает готовые интерфейсы для передачи итогового представления на следующий слой модели. Благодаря этому подходу исчезает необходимость создавать отдельный внутренний блок, а формирование финального результата становится проще, чище и удобнее в управлении, сохраняя при этом всю функциональность оригинальной архитектуры.
Отдельного внимания заслуживает метод инициализации объекта, в котором сосредоточена конфигурация архитектуры. Здесь проявляется вся гибкость подхода: один и тот же базовый класс может быть адаптирован под различные задачи за счет изменения конфигурации, без необходимости переписывания логики.
bool CNeuronSTCA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { uint count = dimensions.Size(); if(units_s <= 0 || units_out <= 0 || count < (units_s + 2)) ReturnFalse; uint dimension_out = dimensions[count - 1]; uint units_ns = count - units_s - 1; uint bottleneck = (embed_size + topK - 1) / topK;
Алгоритм метода начинает с проверки корректности входных параметров. Сначала определяется количество элементов в массиве dimensions, который нам дает информацию о структуре анализируемых данных. Мы убеждаемся, что количество анализируемых последовательностей и размерность тензора результатов положительны, и что в структуре анализируемых данных есть хотя бы один элемент контекста. Это важно, потому что в финансовых моделях ошибки в согласовании размеров эмбеддингов и последовательностей могут привести к некорректной агрегации сигналов и потере ценной информации о рынке.
Далее вычисляются базовые параметры:
- dimension_out — размер вектора признаков на выходе модуля,
- units_ns — количество контекстных признаков,
- bottleneck задает компрессию эмбеддингов внутри модуля.
Это ключевой шаг для балансировки объёма данных и вычислительной нагрузки. В финансовом анализе нам важно сохранить информативность признаков, но не перегружать вычислительный контур лишними измерениями.
Следующий шаг — инициализация родительского класса, который будет использоваться для финальной обработки данных. Это обеспечивает готовые интерфейсы для передачи итогового представления на следующий слой модели.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, bottleneck * topK, bottleneck * topK, dimension_out, units_out, 1, optimization_type, batch)) ReturnFalse;
После чего подготавливаем динамические массивы для записи указателей на объекты создаваемой внутренней архитектуры.
//--- Prepare arrays
cPrepare.Clear();
cFlow.Clear();
cPrepare.SetOpenCL(OpenCL);
cFlow.SetOpenCL(OpenCL);
Затем переходим к блоку подготовки данных. Слой пакетной нормализации отвечает за выравнивание распределения анализируемых данных.
CNeuronBaseOCL* neuron = NULL; CNeuronBatchNormOCL* norm = NULL; CNeuronMultiWindowsConvOCL* mwc = NULL; CNeuronFieldPatternEmbedding* emb = NULL; CNeuronAutoToken* select = NULL; CNeuronSwiGLUOCL* swiglu = NULL; CNeuronSpikeConvBlock* conv = NULL; CNeuronMHTHCrossAttention* attention = NULL; //--- Prepare inputs uint windows[]; if(ArrayCopy(windows, dimensions, 0, 0, count - 1) < int(count - 1)) ReturnFalse; uint index = 0; norm = new CNeuronBatchNormOCL(); uint total_windows = 0; for(uint i = 0; i < windows.Size(); i++) total_windows += windows[i]; if(!norm || !norm.Init(0, index, OpenCL, total_windows, iBatch, optimization) || !cPrepare.Add(norm)) DeleteObjAndFalse(norm); norm.SetActivationFunction(None);
В торговых системах это критично. Индикаторы и метрики могут иметь разные масштабы, и нормализация предотвращает доминирование одних признаков над другими.
Следующий слой многооконной свертки позволяет модели привести разрозненные мультимодальные данные к единому представлению.
index++; mwc = new CNeuronMultiWindowsConvOCL(); if(!mwc || !mwc.Init(0, index, OpenCL, windows, embed_size, 1, 1, optimization, iBatch) || !cPrepare.Add(mwc)) DeleteObjAndFalse(mwc); mwc.SetActivationFunction(SIGMOID);
Далее CNeuronFieldPatternEmbedding формирует эмбеддинги признаков.
index++; emb = new CNeuronFieldPatternEmbedding(); if(!emb || !emb.Init(0, index, OpenCL, embed_size, windows.Size(), embed_size, candidates, topK, optimization, iBatch) || !cPrepare.Add(emb)) DeleteObjAndFalse(emb); emb.SetActivationFunction(TANH);
Для финансового анализа это означает, что каждая метрика или индикатор преобразуется в представление, которое удобно комбинировать с другими признаками без потери смысла, сохраняя значимые паттерны для последующего внимания.
После подготовки данных мы инициализируем блоки для работы с последовательными (cLastSequence) и контекстными (cLastNonSequence) признаками.
//--- Sequence/NonSequence index++; if(!cLastSequence.Init(0, index, OpenCL, units_s * embed_size, optimization, iBatch)) ReturnFalse; cLastSequence.SetActivationFunction(None); index++; if(!cLastNonSequence.Init(0, index, OpenCL, units_ns * embed_size, optimization, iBatch)) ReturnFalse; cLastNonSequence.SetActivationFunction(None);
Объект cStackSequence создает стек исторических последовательностей — своего рода память модели.
index++; if(!cStackSequence.Init(0, index, OpenCL, stack_size, embed_size, units_s, optimization, iBatch)) ReturnFalse;
В финансовом анализе это позволяет удерживать контекст прошлых цен и индикаторов, чтобы внимание THCA могло выбирать релевантные моменты для прогноза текущего состояния рынка.
А cScenarios отвечает за параметризацию разных сценариев обработки данных. В реальном рынке условия постоянно меняются, и эта адаптивность позволяет модели варьировать обработку признаков в зависимости от состояния рынка, повышая устойчивость прогноза.
index++; if(!cScenarios.Init(0, index, OpenCL, embed_size, scenarios, bottleneck, candidates, topK, optimization_type, batch)) ReturnFalse; cScenarios.SetActivationFunction(TANH);
Основной поток cFlow строится как повторяющаяся последовательность блоков SwiGLUFFN → THCA → SwiGLU-FFN, каждый из которых выполняет определенную роль в формировании представления об анализируемых данных. На начальном этапе объединяются контекстные признаки окружающей среды и эмбеддинги возможных сценариев последующего движения рынка.
//--- Flow index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * (scenarios + units_ns), optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Эти признаки создают базовый каркас будущего анализа, позволяя модели учитывать текущие условия и вероятные варианты развития ситуации.
Далее компонент CNeuronAutoToken формирует группы наиболее релевантных признаков из объединённого контекста и эмбеддингов сценариев.
index++; select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, embed_size, bottleneck, scenarios + units_ns, units_out, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select);
По сути, AutoToken выполняет роль фильтра и селектора. Он выделяет комбинации признаков, которые с наибольшей вероятностью окажут влияние на прогнозируемые события. Именно эти сгруппированные токены затем передаются в SwiGLU-блок, который формирует из них запросы к историческим данным. То есть к временным рядам цен и индикаторов.
for(uint l = 0; l < layers; l++) { index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, units_out * topK, 1, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, swiglu.GetWindowOut() * topK, swiglu.GetWindowOut() * topK, embed_size, units_out, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv);
На этом этапе фактически формируются возможные сценарии, которые будут анализироваться в контексте всей исторической информации с помощью механизма кросс-внимания.
Блок THCA получает эти запросы и извлекает из истории финансового инструмента релевантные зависимости, создавая структурированное представление того, как контекстные признаки и прогнозные сценарии соотносятся с прошлым поведением рынка.
index++; attention = new CNeuronMHTHCrossAttention(); if(!attention || !attention.Init(0, index, OpenCL, embed_size, units_out, heads, embed_size, stack_size, bottleneck, candidates, topK, optimization, iBatch) || !cFlow.Add(attention)) DeleteObjAndFalse(attention);
Полученные результаты проходят через второй SwiGLU-блок для формирования итогового представления текущего слоя, подготавливая его к конкатенации с предыдущими результатами.
index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, embed_size, embed_size, bottleneck, units_out, 1, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, swiglu.GetWindowOut(), swiglu.GetWindowOut(), embed_size, units_out, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv);
После этого промежуточное представление соединяется с начальным запросом и с накопленными результатами анализа всех предшествующих слоев.
if(l < layers - 1) { index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * (l + 2) * units_out, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, embed_size, bottleneck, neuron.Neurons() / embed_size, units_out, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select); } }
На основе этой конкатенации снова используется AutoToken, который формирует новые группы запросов — уточнённые сценарии для следующего слоя SwiGLUFFN → THCA → SwiGLU-FFN. Таким образом, каждый слой не только анализирует текущие признаки и историю, но и уточняет и перераспределяет сценарии, создавая многоуровневую структуру внимания и агрегации.
В результате мы получаем цепочку, где каждый слой последовательно анализирует данные, уточняет сценарии возможного движения рынка и интегрирует исторические закономерности, при этом полностью сохраняя различие между последовательными и контекстными признаками.
После того как каждый внутренний слой завершил свою работу, мы конкатенируем результаты всех этих блоков, формируя единый набор промежуточных представлений.
index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, embed_size * layers * units_out, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
С помощью CNeuronAutoToken снова производится отбор наиболее релевантных элементов — фактически это фильтр, который выбирает из всего накопленного контекста ключевые признаки и сценарии для финального прогноза.
index++; select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, embed_size, bottleneck, neuron.Neurons() / embed_size, units_out, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select);
Отобранные токены затем проходят через последний SwiGLU-блок, который выполняет окончательную агрегацию и формирует итоговое представление данных.
index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, units_out * topK, 1, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); //--- return true; }
На этом этапе модель превращает всю накопленную информацию о контексте, исторических зависимостях и сценариях в готовый к использованию в торговой модели сигнал. Такой подход позволяет аккуратно интегрировать многослойный анализ, не теряя значимых деталей и при этом минимизируя шум, что особенно важно для финансовых прогнозов на реальных исторических данных.
Алгоритм прямого прохода реализован в методе feedForward.
bool CNeuronSTCA::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; CNeuronBaseOCL* stack_querys = NULL;
В нем сначала создаются локальные указатели prev и curr. Первый хранит предыдущий активный нейрон, а второй — текущий. Дополнительно объявляется stack_querys для хранения промежуточного контекста, необходимого для последовательной агрегации информации.
На этапе подготовки исходных данных (cPrepare) происходит последовательный проход по всем компонентам блока подготовки.
//--- Inputs for(int i = 0; i < cPrepare.Total(); i++) { curr = cPrepare[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Каждый нейронный модуль получает данные от предыдущего и передает результат дальше.
Далее метод вычисляет размер эмбеддинга и делит признаки на последовательные (units_s) и контекстные (units_ns) блоки.
uint embedding_size = cStackSequence.GetDimension(); uint units_s = cLastSequence.Neurons() / embedding_size; uint units_ns = cLastNonSequence.Neurons() / embedding_size; uint scenarios = cScenarios.GetFields(); uint units_out = GetUnits(); //--- Sequence/NonSequence if(!DeConcat(cLastSequence.getOutput(), cLastNonSequence.getOutput(), prev.getOutput(), embedding_size * units_s, embedding_size * units_ns, 1)) ReturnFalse;
Этот шаг позволяет отделить временные ряды от дискретных или агрегированных признаков, что особенно важно для финансового анализа.
Следующий шаг аккуратно формирует стек исторических данных.
if(!cStackSequence.FeedForward(cLastSequence.AsObject()))
ReturnFalse;
Таким образом, модель создает память прошлого рынка, которую будут использовать механизмы внимания. Это обеспечивает возможность извлекать релевантные зависимости из истории и прогнозировать будущее движение с учётом контекста.
После подготовки контекста формируются эмбеддинги возможных сценариев.
//--- Flow if(!cScenarios.FeedForward()) ReturnFalse;
Они представляют собой гипотезы будущих рыночных движений и вместе с контекстными признаками служат основой для группировки наиболее релевантных токенов с помощью AutoToken. Эти токены затем становятся запросами к историческим данным через THCA.
prev = cFlow[0]; if(!prev || !Concat(cLastNonSequence.getOutput(), cScenarios.getOutput(), prev.getOutput(), embedding_size * units_ns, embedding_size * scenarios, 1)) ReturnFalse;
Основной поток cFlow обрабатывает все слои модели. На каждом шаге текущий нейрон curr либо конкатенирует результаты предыдущего слоя с накопленным контекстом (stack_querys), либо выполняет анализ исходных данных алгоритмами собственного метода FeedForward.
bool attention_flag = false; for(int i = 1; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr) ReturnFalse; if(curr.Type() == defNeuronBaseOCL) { if(!stack_querys || !prev || !Concat(prev.getOutput(), stack_querys.getOutput(), curr.getOutput(), embedding_size, curr.Neurons() / units_out - embedding_size, units_out)) ReturnFalse; stack_querys = curr; } else if(!curr.FeedForward(prev, cStackSequence.getOutput())) ReturnFalse; if(!stack_querys && curr.Type() == defNeuronMHTHCrossAttention) stack_querys = prev; prev = curr; }
Это позволяет каждому слою уточнять сценарии, формировать новые комбинации токенов и извлекать из истории именно те зависимости, которые имеют наибольшую прогностическую ценность. В финансовой модели это критично. Просматривая исторические данные, мы формируем структурированные сценарии, которые отражают реальные закономерности рынка.
После прохода всех внутренних слоёв результирующее представление передается в родительский класс, где формируется итоговое представление всего модуля.
if(!CNeuronSpikeConvBlock::feedForward(prev)) ReturnFalse; //--- return true; }
На этом финальном шаге сохраняется структурированная информация о текущем состоянии рынка, всех возможных сценариях и релевантных исторических зависимостях, готовая к использованию для принятия торговых решений.
В итоге CNeuronSTCA выступает как концентрированное выражение всей ранее проделанной работы. Он объединяет в себе механизмы согласования данных, организацию исторического контекста и направленное внимание, при этом оставаясь достаточно компактным с точки зрения интерфейса. Именно такая форма позволяет органично встроить сложную архитектуру в торговую модель, не перегружая ее избыточными деталями и сохраняя контроль над процессом обучения и применения.
Модификация программы онлайн-обучения
После того как объект верхнего уровня построен, интеграция реализованных подходов в торговую модель становится удивительно простой. Достаточно заменить существующий слой анализа данных на CNeuronSTCA, и модель сразу получает возможность работать с комплексными сценариями, эмбеддингами и механизмами внимания, которые мы детально разобрали выше. Однако вопрос усложняется, когда речь заходит о программах онлайн использования модели, будь то обучение или эксплуатация в реальном времени. Здесь появляется ключевой нюанс, связанный с накоплением исторического движения в латентном состоянии модели.
Если мы работали с короткими последовательностями или ограниченными историческими окнами, этот момент практически не ощущался. Модель быстро накапливает необходимый контекст в процессе работы и сразу начинает давать информативные результаты. Глубина истории была небольшой, и период разогрева модели можно было не учитывать. Однако когда мы увеличиваем глубину анализируемой истории, период накопления контекста становится более значимым. Модели требуется время, чтобы обработать длинные последовательности, правильно интегрировать все предыдущие движения рынка в стек последовательностей и сформировать полноценное представление текущей ситуации.
Для финансового анализа это особенно важно. Если модель начинает работать на новых, ещё не охваченных исторических данных, первые сигналы могут быть менее точными. Ведь пока не накопился полный контекст, прогноз основывается на частичной информации. При больших исторических окнах этот период разогрева может занимать значительное время, и его необходимо учитывать при онлайн-применении, чтобы не принимать поспешных торговых решений.
С целью сокращения времени накопления контекста при онлайн-использовании было принято решение об организации прогрева модели на исторических данных. Основная идея проста: перед началом реальной торговли или онлайн-обучения модель проходит по историческим барам, формируя полное латентное состояние и накапливая контекст, который иначе формировался бы постепенно в процессе работы.
bool FillStack(void) { int start = StackSize + HistoryBars; int end = 0; int bars = CopyRates(Symb.Name(), TimeFrame, 2, start, Rates);
Сначала определяется диапазон исторических данных. Переменная start указывает на начало накопления с учетом глубины стека и количества исторических баров, анализируемых на каждом шаге, а end — на конец участка.
Метод CopyRates загружает данные о котировках, после чего производится проверка и подготовка объектов индикаторов.
if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) ReturnFalse; //--- if(RSI.BarsCalculated() < bars || CCI.BarsCalculated() < bars || ATR.BarsCalculated() < bars || MACD.BarsCalculated() < bars) ReturnFalse; RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- if(!ArraySetAsSeries(Rates, true)) ReturnFalse; bars -= end + HistoryBars; if(bars < 0) ReturnFalse;
Они нужны, чтобы модель получала обогащённые признаки, отражающие как текущую динамику цен, так и состояние рынка с точки зрения волатильности, тренда и импульса. Проверка количества вычисленных баров и их обновление гарантирует, что данные корректны и готовы к дальнейшему анализу.
Далее массивы котировок приводятся к виду, удобному для обработки временных рядов, а длина анализируемого окна корректируется с учётом анализируемой истории на каждом шаге. Если доступных баров недостаточно, метод завершает работу — это защищает модель от ошибок.
После подготовки данных производится очистка латентных состояний моделей Актеров и Критиков, чтобы новая итерация разогрева начиналась с чистого листа.
vector<float> result, target, neg_target; //--- uint ticks = GetTickCount(); //--- for(uint i = 0; i < cActor.Size(); i++) if(!cActor[i].Clear()) ReturnFalse; for(uint i = 0; i < cCritic.Size(); i++) if(!cCritic[i].Clear()) ReturnFalse;
Каждое положение в историческом окне формирует тензор отдельного среза рыночной информации, включающий данные о движении цены, показатели индикаторов, нормализованный баланс, открытые позиции и признаки времени.
for(int posit = start - HistoryBars - 1; posit >= end; posit--) { if(!CreateBuffers(posit, GetPointer(bState), GetPointer(bTime), NULL)) ReturnFalse; vector<float> account = vector<float>::Zeros(AccountDescr); account[0] = float(AccountInfoDouble(ACCOUNT_BALANCE) / EtalonBalance); account[2] = 1; double time = (double)bTime[0]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); account[9] = (float)MathSin(x != 0 ? 2.0 * M_PI * x : 0); x = time / (double)PeriodSeconds(PERIOD_MN1); account[10] = (float)MathCos(x != 0 ? 2.0 * M_PI * x : 0); x = time / (double)PeriodSeconds(PERIOD_W1); account[11] = (float)MathSin(x != 0 ? 2.0 * M_PI * x : 0); x = time / (double)PeriodSeconds(PERIOD_D1); account[12] = (float)MathSin(x != 0 ? 2.0 * M_PI * x : 0); //--- if(!bState.AddArray(account)) ReturnFalse;
Такие признаки позволяют модели учитывать сезонность, временные паттерны и регулярные колебания рынка.
Затем метод последовательно прогоняет эти исходные данные через Актёров (cActor) и Критиков (cCritic).
//--- Feed Forward for(uint i = 0; i < cActor.Size(); i++) if(!cActor[i].feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) ReturnFalse; for(uint i = 0; i < cCritic.Size(); i++) if(!cCritic[i].feedForward(GetPointer(cActor[int(i > 0)]), -1, GetPointer(cActor[int(i > 0)]), LatentLayer)) ReturnFalse;
На этом этапе модель накапливает латентное состояние. Каждый проход формирует промежуточные представления, которые впоследствии будут использоваться для анализа текущей рыночной ситуации и прогноза движения цен.
Для удобства пользователя в процессе работы отображается прогресс в процентах.
if(GetTickCount() - ticks > 500) { double percent = (1.0 - double(posit - end) / (start - end - HistoryBars - NForecast)) * 100.0; string str = StringFormat("%-12s %6.2f%%", "Fill stack", percent); Comment(str); ticks = GetTickCount(); } } Comment(""); //--- return true; }
Обновление комментариев каждые 500 миллисекунд позволяет наблюдать, насколько близка модель к завершению разогрева на исторических данных.
По завершении цикла весь накопленный стек историй готов к использованию. Модель обладает полной памятью о прошлых событиях и сразу способна давать корректные прогнозы и рекомендации, без длительного периода адаптации.
В контексте финансового анализа этот метод крайне важен. Он позволяет экономить время и ресурсы при работе с глубокими историческими рядами. Обеспечивает полноту контекста для прогнозов и снижает риск ошибок на ранних этапах онлайн-эксплуатации модели.
Тестирование
Обучение модели можно представить как путешествие через весь спектр рыночной динамики. Сначала она шагает по историческим данным, шаг за шагом изучая, как формировались цены и какие сценарии оказывались успешными. На этапе офлайн-обучения модель буквально проходит по всей истории EURUSD за 2025 год, постепенно формирует собственное понимание рынка. Каждое движение цены, каждый импульс, каждая консолидация превращаются в структурированное знание. Последовательные ряды цен, контекстные признаки и эмбеддинги сценариев объединяются в единый поток, который модель аккуратно складывает в свои внутренние стеки. AutoToken помогает выбирать ключевые комбинации признаков, а THCA и SwiGLU-блоки смотрят на историю и извлекают закономерности, превращая их в понятные сигналы для следующего слоя.
Затем модель выходит на этап онлайн-обучения в тестере стратегий MetaTrader 5. Здесь начинается настоящее взаимодействие с живым рынком: поступающие данные становятся сигналами для адаптации, параметры модели корректируются практически в реальном времени, внутренние стеки обновляются, сценарии уточняются, а накопленный опыт аккуратно интегрируется в новые прогнозы. Модель учится различать краткосрочные импульсы и долгосрочные тренды, учитывать периоды коррекции и менять стратегию в зависимости от нового контекста. Этот этап можно представить как тренировки мастера: каждое событие на рынке обрабатывается мгновенно, анализируются последствия и создается обновленное понимание текущей рыночной ситуации.
Финальная проверка стала кульминацией этого путешествия. На данных за Январь–Февраль 2026 года модель сталкивалась с полностью новыми условиями, где привычные сценарии не могли быть повторены. Здесь проявилась истинная сила архитектуры STCA: модель выделяла ключевые паттерны, согласовывала последовательные и контекстуальные признаки, строила прогнозы и принимала торговые решения.
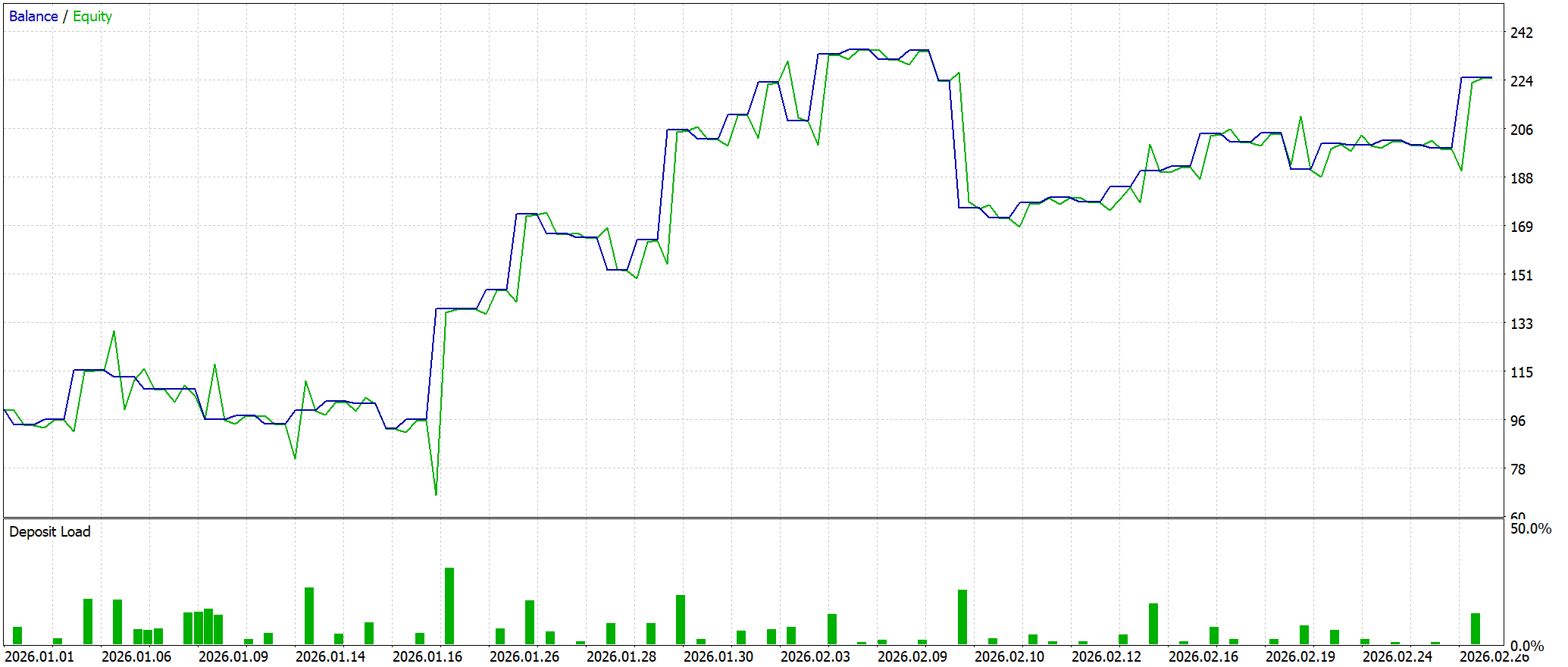
Полученные результаты тестирования демонстрируют, что на протяжении всего периода система уверенно наращивала капитал. Депозит в 100.0 USD превращается в 225.22 USD. Кривая баланса движется ступенчато. Модель зарабатывает не хаотично, а сериями, последовательно отрабатывая выявленные сценарии. После фазы накопления следует уверенный рост, затем просадка и восстановление с обновлением максимумов — признак того, что внутренняя логика принятия решений действительно работает.
При этом более глубокий взгляд через эквити показывает обратную сторону стратегии. Существенные отклонения от баланса указывают на удержание позиций в убытке. Модель не спешит фиксировать отрицательный результат, если сценарий остаётся актуальным. Это напрямую связано с архитектурой STCA и использованием сценарного анализа. Система доверяет своим гипотезам и дает рынку время их реализовать. В результате формируется повышенная просадка, особенно на уровне эквити. Это требует аккуратного контроля при практическом применении.
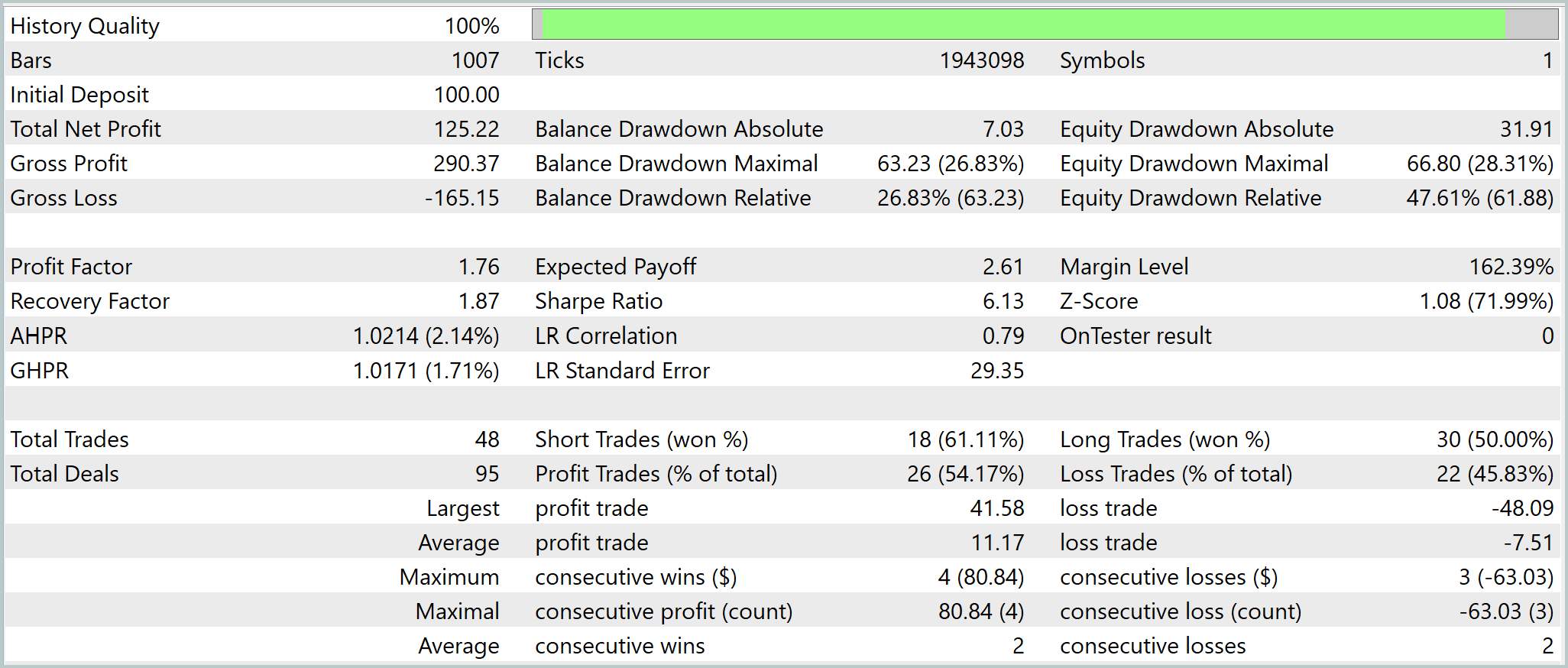
С точки зрения статистики система выглядит устойчиво. Profit Factor на уровне 1.76. Положительное математическое ожидание и сбалансированное соотношение прибыли и убытков. Модель выигрывает чуть чаще, чем проигрывает. Но ключевая прибыль формируется за счет качества сделок, а не их количества. Доходность обеспечивается не частотой входов, а их обоснованностью.
В итоге система демонстрирует рабочую стратегию с выраженным сценарным подходом и глубокой интеграцией исторического контекста. Однако её поведение ближе к агрессивным стратегиям. Высокая загрузка депозита и значительные плавающие просадки требуют дополнительной настройки риск-менеджмента. При этом сама архитектура уже подтверждает свою эффективность, она не просто реагирует на рынок, а интерпретирует его, формируя и отрабатывая вероятностные сценарии движения цены.
Заключение
В рамках данного проекта был последовательно реализован и доведён до практического применения полный цикл построения модели на основе архитектуры STCA с интеграцией механизмов согласования данных OneTrans. Ключевым результатом стало воспроизведение отдельных компонентов и их системная интеграция в единую вычислительную схему, способную одновременно обрабатывать временные ряды и контекстуальные признаки финансового рынка. Особое внимание было уделено упрощению архитектуры без потери функциональности. Отказ от избыточных внутренних блоков в пользу использования возможностей родительских классов позволил сохранить выразительность модели и повысить её инженерную прозрачность.
Разработан механизм предварительного накопления исторического контекста, устраняющий проблему разогрева модели при работе с глубокими временными окнами. Это решение переводит архитектуру из теоретической плоскости в прикладную, делая ее пригодной для использования в реальных торговых системах. Параллельно была выстроена двухэтапная схема обучения, которая обеспечивает формирование базового понимания рынка и последующую адаптацию к изменяющимся условиям.
Проведённое тестирование подтвердило работоспособность реализованных решений. Модель демонстрирует устойчивую прибыльность и способность извлекать значимые закономерности из сочетания исторических и контекстных данных. При этом выявлены характерные особенности поведения, включая повышенные просадки на уровне эквити. Это логично вытекает из сценарной природы архитектуры и открывает пространство для дальнейшей оптимизации риск-менеджмента.
Ссылки
- Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен по ссылке.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Добрый день, Дмитрий!
Опробовал последний вариант модели.
На машине в конфигурации:
2026.03.20 17:26:15.127 Terminal MetaTrader 5 x64 build 5687 started for MetaQuotes Software Corp.
2026.03.20 17:26:15.127 Terminal Windows 10 build 19045, 8 x Intel Core i7-9700F @ 3.00GHz, AVX2, 37 / 47 Gb memory, 55 / 465 Gb disk, UAC, GMT+3
2026.03.20 17:26:37.809 OpenCL device #0: GPU 'GeForce RTX 2070' with OpenCL 1.2 (36 units, 1620 MHz, 8192 Mb, version 457.51, rating 8000)
Происходит ошибка инициализации:
2026.03.20 17:26:38.027 Experts initializing of StudySTCA (EURUSD,H1) failed with code 1
2026.03.20 17:26:38.033 Experts expert StudySTCA (EURUSD,H1) removed
На десктопе с Intel и видеокартой 4090 и ноутбуке с AMD работает нормально.
Протокол из тестера:
2026.03.20 17:42:04.739 device #0: GPU 'GeForce RTX 2070' with OpenCL 1.2 (36 units, 1620 MHz, 8192 Mb, version 457.51, rating 8000)
2026.03.20 17:42:04.827 2024.01.01 00:00:00 OpenCL: GPU device 'GeForce RTX 2070' selected
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:7273:20: warning: comparison of unsigned expression >= 0 is always true
2026.03.20 17:42:04.952 2024.01.01 00:00:00 if((pos - s) >= 0)
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ~~~~~~~~~ ^ ~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:7308:20: warning: comparison of unsigned expression >= 0 is always true
2026.03.20 17:42:04.952 2024.01.01 00:00:00 if((pos - s) >= 0)
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ~~~~~~~~~ ^ ~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13346:61: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 out = IsNaNOrInf(exp(prev_max - max) * out + val[idx], 0.0f);
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13348:22: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 out = val[idx];
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13538:61: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 out = IsNaNOrInf(exp(prev_max - max) * out + val[idx], 0.0f);
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13540:22: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 out = val[idx];
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13662:26: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 grad_q += q_dg[idx];
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00 <kernel>:13749:26: error: subscripted access is not allowed for OpenCL vectors
2026.03.20 17:42:04.952 2024.01.01 00:00:00 grad_X += x_dg[idx];
2026.03.20 17:42:04.952 2024.01.01 00:00:00 ^ ~~~
2026.03.20 17:42:04.952 2024.01.01 00:00:00
2026.03.20 17:42:04.971 2024.01.01 00:00:00 OpenCL program create failed, error code=5105
2026.03.20 17:42:04.971 2024.01.01 00:00:00 Error at COpenCLMy::Initialize line 2795
2026.03.20 17:42:04.971 2024.01.01 00:00:00 Error at CNet::OpenCLInit line 27756
2026.03.20 17:42:04.971 2024.01.01 00:00:00 Error at CNet::Create line 12004
2026.03.20 17:42:04.971 tester stopped because OnInit returns non-zero code 1
Протокол из тестера:
2026.03.20 17:42:04.739 device #0: GPU 'GeForce RTX 2070' with OpenCL 1.2 (36 units, 1620 MHz, 8192 Mb, version 457.51, rating 8000)
......
Добрый день, Андрей.
Проверьте версию из вложения. Если все Ok, заменим в статье.
С уважением,
Дмитрий.
Добрый день, Андрей.
Проверьте версию из вложения. Если все Ok, заменим в статье.
С уважением,
Дмитрий.
Добрый день, Дмитрий!
Файл скачал, протестировал - всё Ок!
С уважением,
Андрей.