
Использование регрессии Ренко-баров с корректировкой ошибок

В предыдущей статье мы рассматривали классификационный подход к прогнозированию Ренко-баров с помощью CatBoost: модель предсказывала направление следующего бара (вверх или вниз) и давала точность около 59%. В этой работе мы сделаем следующий шаг и перейдём от классификации к регрессии: будем прогнозировать не только направление, но и величину логарифмической доходности следующего Ренко-бара. Это даёт дополнительную информацию для принятия торговых решений — мы получаем не просто бинарный сигнал, а численный прогноз движения цены с доверительным интервалом.
Главная проблема любой регрессионной модели на финансовых данных — систематическая ошибка, или смещение прогноза. Модель, обученная на исторических данных, может систематически переоценивать движения в одном направлении и недооценивать в другом. Мы покажем, как выявить и компенсировать эту ошибку с помощью двухступенчатой схемы. Сначала применяется многостадийный каскад residual-моделей, где каждая следующая модель учится на ошибках предыдущей. Затем выполняется финальная условная коррекция bias. В результате мы получим боевую систему, работающую с реальными дневными данными EURUSD из MetaTrader 5 и выдающую торговый сигнал с рассчитанным объёмом позиции, стоп-лоссом и тейк-профитом в единицах размера Ренко-кирпича.
Ренко-графики обладают важным свойством: величина каждого бара фиксирована и равна brick_size. Это означает, что при прогнозировании следующего бара таргет фактически дискретен. Он принимает три значения: +log(1 + brick_size/close) при движении вверх на один кирпич; -log(1 - brick_size/close) при движении вниз; и редкое нулевое значение в точках разворота, когда close текущего бара совпадает с границей. Казалось бы, это идеальная задача для классификации.
Но регрессия на таком таргете даёт два преимущества, которые важно понимать с самого начала. Модель возвращает не просто класс, а непрерывное значение, которое можно интерпретировать как уверенность прогноза. Прогноз +0.0042 означает «почти наверняка вверх на один кирпич», а прогноз +0.0005 означает «формально вверх, но модель не уверена». Эта градация полезна для фильтрации слабых сигналов. Кроме того, регрессионная формулировка естественным образом расширяется на горизонты больше одного бара: если вместо horizon=1 взять horizon=3 или horizon=5, таргет становится непрерывным и модель начинает оценивать не только направление, но и силу тренда. В этой статье мы рассматриваем horizon=1 и прогнозируем следующий кирпич. Это наиболее чистая постановка задачи, и на ней удобно демонстрировать механизм коррекции ошибок.
Размер кирпича и построение Ренко-баров
Размер кирпича определяет разрешение Ренко-графика. Слишком мелкий brick_size — и график захлёбывается в шуме; слишком крупный — и мы пропускаем значимые движения. Мы используем классический подход: brick_size рассчитывается как ATR(14), умноженный на коэффициент 0.5.
def _calc_atr(df: pd.DataFrame, period: int = 14) -> pd.Series: tr = pd.concat([ df["high"] - df["low"], (df["high"] - df["close"].shift()).abs(), (df["low"] - df["close"].shift()).abs(), ], axis=1).max(axis=1) return tr.rolling(period).mean() def create_renko_bars(df, brick_size=None, atr_multiplier=0.5): if brick_size is None: atr = _calc_atr(df, 14) brick_size = float(atr.mean() * atr_multiplier) # ... построение баров
Для дневного EURUSD за период 2024–2025 получается brick_size около 0.004 — примерно 40 пипсов. Это разумный размер для дневной стратегии: Ренко-график сглаживает внутридневной шум и оставляет структурные движения. Важная деталь реализации — обработка разворотов. В классическом Ренко для смены направления цена должна пройти расстояние 2×brick_size от экстремума, а не один кирпич. Это моделируется добавлением дополнительного кирпича при смене направления через простое условие if current_direction is not None and direction != current_direction: num_bricks += 1 .
Признаки
Для каждой точки данных мы формируем 25 признаков, которые описывают контекст последних 10 Ренко-баров. Признаки охватывают историческую последовательность движений (направления dir_0 ... dir_9), агрегаты по направлениям (долю восходящих баров, длины стриков, число смен направления), объёмные характеристики (последний и средний объём, их соотношение, линейный тренд объёма за окно) и ценовую структуру (диапазон, средний размер движения, последнюю и кумулятивную доходность).
feat = {
**{f"dir_{j}": int(w_dirs[-(j + 1)]) for j in range(lookback)},
"up_ratio": float((w_dirs > 0).mean()),
"last_dir": int(w_dirs[-1]),
"dir_changes": int(np.sum(np.abs(np.diff(w_dirs)) > 0)),
"last_up_streak": int(up_streaks[i - 1]),
"last_down_streak": int(dn_streaks[i - 1]),
"max_up_streak": int(up_streaks[i - lookback:i].max()),
"max_down_streak": int(dn_streaks[i - lookback:i].max()),
"last_volume": float(w_vols[-1]),
"avg_volume": float(avg_vol),
"volume_ratio": float(w_vols[-1] / avg_vol),
"volume_trend": float(np.polyfit(range(lookback), w_vols, 1)[0]),
"price_range": float(w_closes.max() - w_closes.min()),
"range_per_bar": float(brick_proxy),
"last_return": float(np.log(w_closes[-1] / w_closes[-2])),
"cum_return": float(np.log(w_closes[-1] / w_closes[0])),
} Регрессионный таргет — логарифмическая доходность на горизонте horizon Ренко-баров, которая вычисляется как target = float(np.log(closes[i - 1 + horizon] / closes[i - 1])). Логарифмическая форма предпочтительнее простой разности цен: она симметрична по знаку, устойчива к масштабу и естественно суммируется при агрегации прогнозов на разные горизонты.
Каскад residual-моделей
Классическая архитектура каскада выглядит следующим образом. Мы обучаем первую модель M₀ на исходных данных (X, y). Эта модель выдаёт прогноз ŷ₀ = M₀(X) и оставляет остатки r₀ = y - ŷ₀. Затем мы обучаем вторую модель M₁ на тех же признаках X, но предсказываем уже остатки r₀, а не исходный y. Прогноз обновляется: ŷ₁ = ŷ₀ + η × M₁(X), где η — коэффициент shrinkage, меньший 1 (у нас η = 0.6). Новые остатки r₁ = y - ŷ₁ идут в обучение следующей модели M₂, и так далее. Итоговый сырой прогноз каскада записывается как ŷ = M₀(X) + η×M₁(X) + η×M₂(X) + ... + η×Mₖ(X).
Почему это не то же самое, что просто увеличить число итераций в одном CatBoost? Есть три принципиальных отличия.
Каждая residual-модель имеет собственный early stopping. Базовая модель останавливается, когда перестаёт улучшаться валидационная метрика на таргете y. Residual-модели останавливаются на таргетах-остатках, которые имеют другую структуру: они более шумные и менее предсказуемые.
Между стадиями каскада остатки пересчитываются через OOF-прогнозы, полученные на TimeSeriesSplit, что гарантирует отсутствие утечки из будущего: residual-модель учится предсказывать остатки, которые базовая модель не видела во время обучения. Без этого механизма каскад переобучился бы мгновенно.
На уровне каскада действует отдельный early stopping. Если очередная стадия не улучшает OOF-MAE больше чем на min_improvement, стадия отклоняется. После нескольких подряд отклонённых стадий каскад останавливается.
Основной цикл обучения показан ниже:
# Стадия 0 — базовая модель oof_cum, base_model = self._compute_oof(X, y, stage_idx=0) mae_stage = mean_absolute_error(y[valid], oof_cum[valid]) self.stages.append(CascadeStage(model=base_model, oof_mae=mae_stage, shrinkage_applied=1.0)) best_mae = mae_stage no_improve_count = 0 # Итеративные residual-стадии for s in range(1, self.max_stages + 1): residuals = y - oof_cum X_s = X.loc[valid].reset_index(drop=True) r_s = residuals[valid] oof_r, stage_model = self._compute_oof(X_s, r_s, stage_idx=s) oof_cum_updated = oof_cum.copy() oof_cum_updated[idx_valid[mask_inner]] = ( oof_cum[idx_valid[mask_inner]] + self.shrinkage * oof_r[mask_inner] ) mae_new = mean_absolute_error(y[valid_new], oof_cum_updated[valid_new]) improvement = best_mae - mae_new if improvement > self.min_improvement: self.stages.append(CascadeStage( model=stage_model, oof_mae=mae_new, shrinkage_applied=self.shrinkage )) oof_cum = oof_cum_updated best_mae = mae_new no_improve_count = 0 else: no_improve_count += 1 if no_improve_count >= self.patience: break
Параметры CatBoost различаются для базовой и residual-стадий. Базовая модель использует 500 итераций, learning_rate=0.03, depth=6 и L2-регуляризацию со значением 3.0. Residual-модели мельче и сильнее регуляризованы: 300 итераций, learning_rate=0.02, depth=4, L2=5.0. Причина простая: остатки — это шум плюс небольшая остаточная структура, и глубокие деревья на таких данных быстро начнут ловить шум вместо сигнала, поэтому усиленная регуляризация критически важна для сходимости.
def _base_params(self, stage_idx): is_base = (stage_idx == 0) return { "iterations": 500 if is_base else 300, "learning_rate": 0.03 if is_base else 0.02, "depth": 6 if is_base else 4, "loss_function": "RMSE", "l2_leaf_reg": 3.0 if is_base else 5.0, "random_seed": 42 + stage_idx, "early_stopping_rounds": 40, }
Условная коррекция смещения
Даже после каскада на OOF-прогнозах может оставаться систематическая ошибка. Например, модель может в среднем переоценивать bullish-прогнозы (когда raw_pred больше нуля) и недооценивать bearish. Мы обнаруживаем и компенсируем это с помощью conditional bias correction. Алгоритм простой: на OOF-прогнозах считаем остатки residuals = y_pred - y_true. Положительный средний residual означает, что модель переоценивает — значит из прогноза надо вычесть этот bias. Мы считаем bias отдельно для прогнозов со знаком плюс (bull_bias) и со знаком минус (bear_bias).
@dataclass class BiasCorrector: def fit(self, y_true, y_pred_oof): residuals = y_pred_oof - y_true self.global_bias = float(np.mean(residuals)) self.residual_std = float(np.std(residuals, ddof=1)) if self.method == "conditional": bull = y_pred_oof > 0 bear = y_pred_oof < 0 self.bull_bias = float(np.mean(residuals[bull])) if bull.sum() > 5 else self.global_bias self.bear_bias = float(np.mean(residuals[bear])) if bear.sum() > 5 else self.global_bias return self def correct(self, raw_pred): if self.method == "conditional": if raw_pred > 0: return raw_pred - self.bull_bias if raw_pred < 0: return raw_pred - self.bear_bias return raw_pred - self.global_bias
Важный механизм защиты от ухудшения — guard. Если conditional bias correction ухудшает OOF-MAE (иногда бывает, что данные уже почти симметричны и коррекция только добавляет шума), она автоматически отключается: все bias приравниваются к нулю и финальный прогноз равен сырому прогнозу каскада. Параметр residual_std используется для построения 95% доверительного интервала финального прогноза через стандартное выражение pred ± 1.96 × residual_std.
Боевая система на MetaTrader 5
Всё, что мы построили, собирается в один production-скрипт RenkoBattle_EURUSD_D1.py. Он подключается к MetaTrader 5, загружает данные, обучает или загружает сохранённую модель, генерирует торговый сигнал и — при явном разрешении — отправляет ордер. Подключение к терминалу и загрузка данных реализованы через стандартное API MetaTrader5::
def mt5_connect(cfg): if not mt5.initialize(path=cfg.get("mt5_terminal_path")): return False info = mt5.account_info() print(f"[MT5] Счёт: {info.login} @ {info.server}, баланс={info.balance:.2f}") return True def mt5_fetch_ohlc(symbol, timeframe, days): mt5.symbol_select(symbol, True) end = datetime.now() start = end - timedelta(days=days) rates = mt5.copy_rates_range(symbol, timeframe, start, end) df = pd.DataFrame(rates) df["time"] = pd.to_datetime(df["time"], unit="s") return df
Если сохранённая модель становится неактуальной (изменился режим рынка, ATR существенно сдвинулся), скрипт автоматически переобучает её. Соотношение нового brick_size к тому, что был в модели на момент обучения, проверяется при каждом запуске: если это соотношение выходит за пределы коридора 0.7–1.4, запускается полный цикл переобучения и перезапись сохранённой модели.
Прогноз модели преобразуется в конкретный ордер с SL и TP, выраженными в единицах brick_size. Фильтр спреда отсеивает сигналы, которые по ожидаемой величине движения не превышают текущий спред более чем в 1.5 раза — это защита от входов в условиях шума. Стоп-лосс устанавливается на расстоянии двух кирпичей, тейк-профит — трёх, что даёт соотношение риск-прибыль 1:1.5. Объём позиции рассчитывается из фиксированного риска 0,5% от баланса. Размер SL в пунктах умножается на стоимость пункта для 1 лота — получаем убыток на 1 лот. Затем риск в деньгах делится на этот убыток, и получается требуемый объём. Затем объём округляется к шагу брокера и ограничивается минимальным и максимальным допустимым значением.
def build_signal(prediction, symbol, brick_size, cfg): info = mt5.symbol_info(symbol) tick = mt5.symbol_info_tick(symbol) # Фильтр спреда expected_move_abs = abs(prediction["expected_move_pct"]) / 100.0 spread_frac = info.spread * info.point / prediction["last_close"] if expected_move_abs < spread_frac * 1.5: return {"action": "NONE", "reason": "signal_below_spread"} sl_distance = cfg["sl_in_bricks"] * brick_size tp_distance = cfg["tp_in_bricks"] * brick_size if prediction["direction"] == "UP": entry = tick.ask sl = entry - sl_distance tp = entry + tp_distance order_type = mt5.ORDER_TYPE_BUY else: entry = tick.bid sl = entry + sl_distance tp = entry - tp_distance order_type = mt5.ORDER_TYPE_SELL # Position sizing по риску account = mt5.account_info() risk_amount = account.balance * cfg["risk_per_trade_pct"] / 100.0 sl_points = sl_distance / info.trade_tick_size loss_per_lot = sl_points * info.trade_tick_value raw_volume = risk_amount / loss_per_lot volume = max(info.volume_min, min(info.volume_max, round(raw_volume / info.volume_step) * info.volume_step)) return { "action": "BUY" if prediction["direction"] == "UP" else "SELL", "order_type": order_type, "entry_price": entry, "sl": sl, "tp": tp, "volume": volume, "risk_amount": risk_amount, }
В скрипте реализована трёхуровневая защита от случайного запуска реальной торговли. В конфигурации по умолчанию стоит enable_trading=False и dry_run=True, а также требуется явный CLI-флаг --trade. При запуске командой python RenkoBattle_EURUSD_D1.py система только показывает отчёт с прогнозом и метриками модели, ничего не отправляя брокеру. Команда python RenkoBattle_EURUSD_D1.py --retrain принудительно переобучает модель, а реальная торговля включается только явной командой python RenkoBattle_EURUSD_D1.py --trade . Это позволяет безопасно тестировать систему в режиме наблюдения неограниченно долго и включить торговлю только после полной верификации поведения.
Результаты на дневном EURUSD
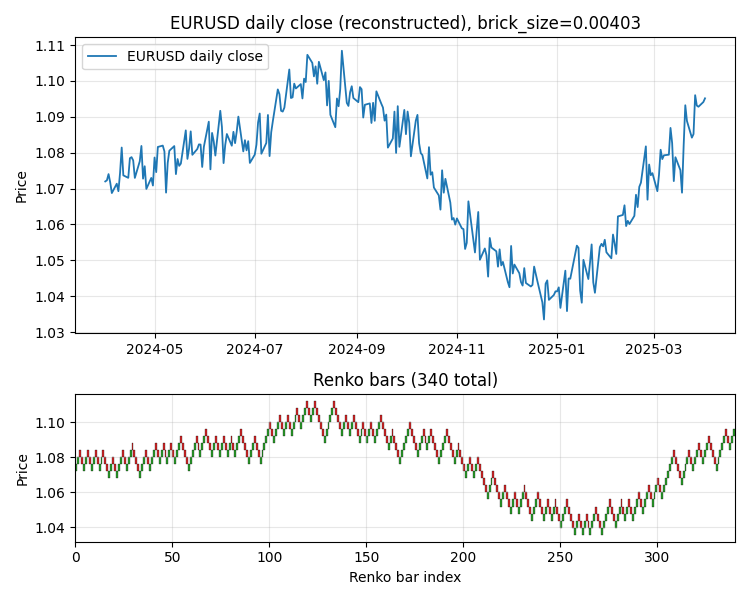
Мы применили полную систему к данным EURUSD D1 за период апрель 2024 — апрель 2025 (около 270 торговых дней). Параметры: lookback=8, horizon=1, atr_multiplier=0.5, max_stages=12, patience=3, shrinkage=0.6. После загрузки D1-данных и построения Ренко с адаптивным brick_size мы получили 340 Ренко-баров из 273 торговых дней. Видно, что Ренко-представление сглаживает дневные колебания и чётко выделяет структурные движения: восходящая фаза лета 2024, коррекция осенью, провал зимой к 1.04, восстановление весной 2025.
Каскад принял только одну residual-стадию. Базовая модель дала OOF MAE = 0.001306; после первой residual-стадии MAE снизилось до 0.001287 (улучшение на 1.9e-5). Следующие три стадии были отклонены — их вклад был меньше min_improvement или даже отрицательным. Early stopping корректно сработал после трёх подряд отклонённых стадий.
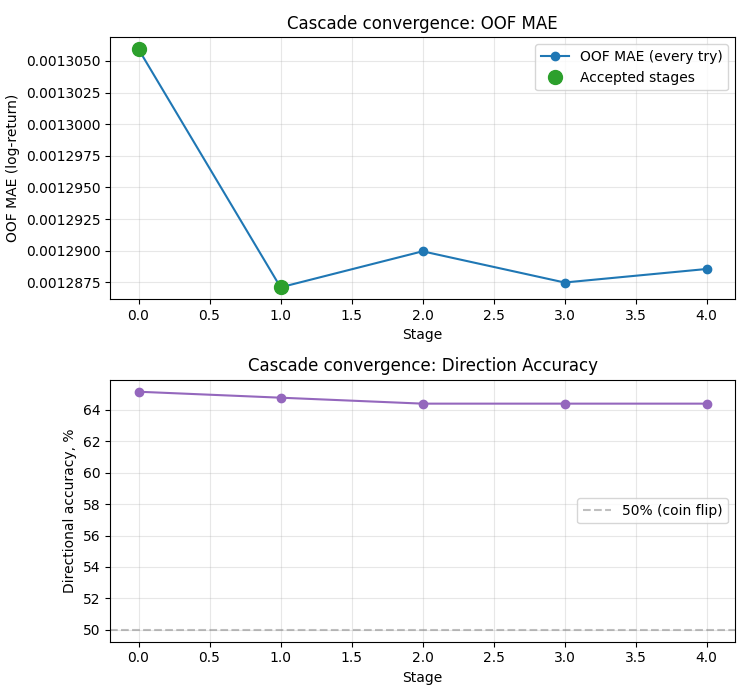
Direction accuracy держится на уровне 64.4% — устойчиво выше 50%-й отметки случайного угадывания. Важно, что эта величина практически не меняется между стадиями: каскад улучшает точность по величине (MAE), но не меняет знак прогноза. Это типичное поведение residual-boosting — он уточняет оценку, а не переворачивает её.
При horizon=1 таргет дискретен, поэтому scatter показывает три чётких кластера: -0.004 (движение вниз на кирпич), 0 (редкие точки разворота) и +0.004 (движение вверх).
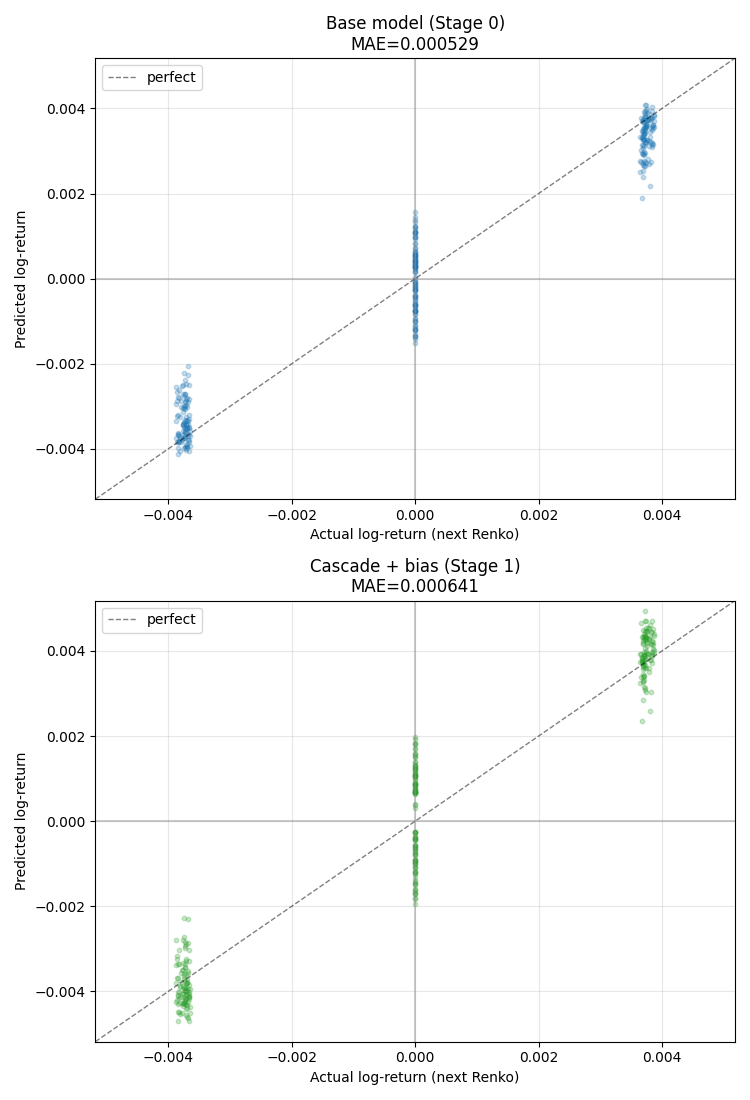
В каждом кластере видно, как модель распределяет свои прогнозы. В правом кластере (actual = +brick) прогнозы группируются выше нуля и тянутся к диагонали "perfect". В левом кластере (actual = -brick) — наоборот, прогнозы ниже нуля. После каскада и bias correction (нижняя картинка) разброс прогнозов шире, но центры групп ближе к диагонали.
Следующий график — самый важный с практической точки зрения. Зелёная линия прогноза почти идеально совпадает с чёрной линией фактической цены следующего бара на протяжении всех 300 последних Ренко-баров.
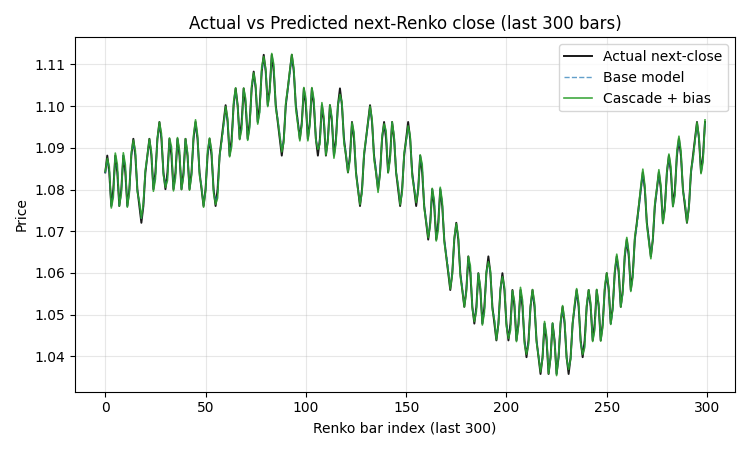
Промахи модели — это точки, где зелёная линия отклоняется от чёрной ровно на один brick_size (на графике около 40 пипсов). Это поведение по построению: если модель правильно угадала направление, прогноз попадает в точку ±1 brick от текущей цены; если ошиблась — промах ровно в один кирпич.
Остатки после каскада остались центрированными в нуле (mean = -7e-5, практически ноль) с σ ≈ 0.0008. Распределение симметрично, без тяжёлых хвостов и без видимого перекоса в одну сторону.

Сводка метрик базовой модели против финальной композиции каскада и bias correction: OOF-MAE снизилось с 0.001306 до 0.001262 (улучшение на 3.35%), OOF-RMSE с 0.001656 до 0.001605, R² вырос с +0.7132 до +0.7183. Direction accuracy осталась практически неизменной (65.15% против 64.77%), residual σ снизился с 0.001655 до 0.001630.
Выявленные коррекции составили: global_bias = -4.7e-5, bull_bias = -3.1e-4, bear_bias = +2.2e-4 — то есть модель систематически недооценивала bull-движения и переоценивала bear-движения.
Direction accuracy после каскада незначительно снизилась, но это компенсируется улучшением MAE и более корректными доверительными интервалами. В торговой практике важнее не угадывание знака, а корректная оценка величины движения и её неопределённости — а именно это каскад улучшает.
Заключение
Мы построили полный пайплайн прогнозирования Ренко-баров с регрессией CatBoost и многоступенчатой коррекцией ошибок. Регрессионная формулировка задачи вместо классификации даёт непрерывный прогноз с оценкой неопределённости, что важнее бинарного сигнала для принятия решений о размере позиции и фильтрации слабых движений. Каскад residual-моделей с честными OOF-остатками через TimeSeriesSplit позволяет итеративно уточнять прогноз без переобучения, а shrinkage и усиленная регуляризация residual-стадий защищают от ловли шума. Conditional bias correction компенсирует систематическую асимметрию между bull- и bear-прогнозами, и механизм защиты от ухудшения автоматически отключает коррекцию, если она ухудшает метрику.
На дневных EURUSD система показала OOF-MAE на уровне 0.001262 и direction accuracy 64.8% — устойчиво выше случайного угадывания. На более коротких таймфреймах (M5, M15, H1), где число Ренко-баров на том же периоде в десятки раз больше, ожидается более глубокая сходимость каскада (5–7 стадий вместо двух) и соответственно более точные прогнозы. Возможные направления дальнейшего развития включают добавление quantile regression для асимметричных доверительных интервалов, обучаемый per-stage shrinkage через оптимизацию OOF-MAE, стэкинг прогнозов стадий через линейную регрессию вместо простого суммирования, а также исследование того, как меняется оптимальная глубина каскада с ростом horizon. Полный код системы — файлы RenkoRegressorCascade.py и RenkoBattle_EURUSD_D1.py — прилагается к статье. Для запуска требуется Python 3.10+, MetaTrader 5 с установленным пакетом MetaTrader5, а также библиотеки catboost, scikit-learn, pandas и numpy.
| Файл | Описание |
|---|---|
| RenkoRegressorCascade.py | Основной модуль: построение Ренко-баров, формирование признаков, каскад residual-моделей CatBoost с OOF-валидацией и условная коррекция смещения |
| RenkoBattle_EURUSD_D1.py | Production-скрипт: подключение к MetaTrader 5, загрузка данных EURUSD D1, обучение/загрузка модели, генерация торгового сигнала с расчётом объёма позиции, SL и TP |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования