
Создание самооптимизирующихся советников на MQL5 (Часть 10): Факторизация матриц

В вводной части этой серии (ссылка приведена здесь) мы стремились совместно построить модель линейной регрессии, используя только нативный код MQL5 и "сырые" данные из терминала MetaTrader 5. После прочтения комментариев и отзывов к первой статье многие читатели отметили проблемы, с которыми они столкнулись при использовании предложенного решения. Они сообщали о многочисленных багах и ошибках, а некоторые указали, что модель открывала только один тип позиций. В целом несколько пользователей отметили проблемы нестабильности в нашей первоначальной попытке построить линейную модель.
Напомним, линейные модели — это предсказательные инструменты, позволяющие приложению обучаться непосредственно на наблюдениях за поведением рынка и использовать полученные знания для открытия сделок, которые, по его мнению, с наибольшей вероятностью окажутся успешными. Наша цель — выйти за рамки явных указаний приложению, когда покупать или продавать. Вместо этого мы хотим, чтобы оно самостоятельно обучалось на основе прошлых данных.
В этой статье мы рассмотрим проблемы нестабильности, с которыми столкнулись пользователи в первой части, и покажем, как строить столь же мощные предсказательные модели на основе "сырых" данных, описывающих любой рынок, которым вы хотите торговать. Для этого мы введём семейство алгоритмов, известное как факторизация матриц.
Факторизация матриц — это математический метод разложения большой матрицы на произведение меньших и более простых матриц. Эти методы имеют множество преимуществ. Однако прежде чем рассматривать их, давайте сначала поймём мотивацию их использования.
В повседневной жизни существуют общие переживания, выходящие за рамки культурных различий. Например, я полагаю, что большинству читателей знакома идея: разговаривая с ребёнком и слушая, как он описывает своего родителя, мы можем получить представление о том, каким является этот родитель. Эти описания могут даже помочь нам предположить, как родитель поведёт себя в ситуациях, которые ребёнок напрямую не описывал. Аналогично, факторизация матриц разбивает большую матрицу на меньшие — её "детей". Эти дочерние матрицы описывают различные аспекты исходной матрицы, помогая нам понять её внутреннюю структуру. Подобно тому как взгляд ребёнка может раскрыть сущность родителя, эти меньшие матрицы могут дать глубокое понимание анализируемого рынка.
Результаты факторизации матриц часто обеспечивают численно устойчивые решения для линейных моделей, которые мы рассматривали ранее. В этой статье мы также познакомимся с численной библиотекой OpenBLAS — сокращение от Basic Linear Algebra Subprograms. OpenBLAS — это открытое ответвление (fork) библиотеки BLAS, переработанное для эффективной работы на современных вычислительных архитектурах, переработанным для эффективной работы на современных вычислительных архитектурах. Изначально BLAS был написан на Fortran и вручную оптимизирован на ассемблере.
В линейной алгебре существует фундаментальное положение: любой набор данных можно разложить на более мелкие компоненты, и эти компоненты могут использоваться для построения предсказательных моделей исходных данных. Представления, полученные из этих меньших наборов данных, также могут выявить характеристики исходных данных, которые в противном случае остались бы скрытыми.
В этой статье вы познакомитесь с мощными командами линейной алгебры, используемыми для построения предсказательных моделей на основе "сырых" данных. И это только начало. Методы факторизации матриц дают гораздо больше, чем просто предсказательную силу — они помогают сжимать данные, выявлять скрытые тенденции и оценивать стабильность или хаотичность рынка. Удивительно, сколько полезной информации можно извлечь из любого набора данных, просто разложив его на составляющие. Давайте начнём.
Начало работы с MQL5
Первым шагом при работе с MQL5 является определение системных констант, которые мы будем использовать на протяжении всей демонстрации. Эти константы используются в скрипте, который я подготовил, чтобы помочь нам начать работу с факторизацией матриц.
//+------------------------------------------------------------------+ //| Solve.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define HORIZON 10 #define START 0Далее мы задаём пользовательские входные параметры скрипта — в частности, сколько баров данных мы хотим получить.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int FETCH = 10;//How many bars should we fetch?
После этого объявляем глобальные переменные, включая обучающие и тестовые данные, а также несколько других переменных для хранения коэффициентов, которые наше приложение извлечёт из предоставленных данных.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ROWS = 5; //Dependent variable matrix y,y_test; //Indenpendent variable matrix X = matrix::Ones(ROWS,FETCH); matrix X_test = matrix::Ones(ROWS,FETCH); //Coefficients matrix b; vector temp; //Row Norms vector row_norms = vector::Zeros(4); vector error_vector = vector::Zeros(4);
Для начала мы выводим матрицу входных данных X в её текущем состоянии. Как показано на рисунке 1, эта матрица изначально заполнена единицами. Это сделано намеренно: в линейной модели первая строка входных данных представляет свободный член (intercept). Реальные рыночные данные — такие как цены открытия, максимума, минимума и закрытия — будут заполнять матрицу, начиная со второй строки.
Важно отметить структуру данных. Если вы следили за нашей серией, например за "Переосмыслением классических стратегий", где мы извлекаем данные из MetaTrader 5 и обрабатываем их в Python, вы могли привыкнуть к формату, в котором столбцы представляют рыночные характеристики (open, high, low, close), а строки — время (например, дни). Однако в данном случае структура транспонирована: время располагается по столбцам, а рыночные характеристики — по строкам.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Observe the input matrix in its original form PrintFormat("Input Matrix Gathered From %s",Symbol()); Print(X);
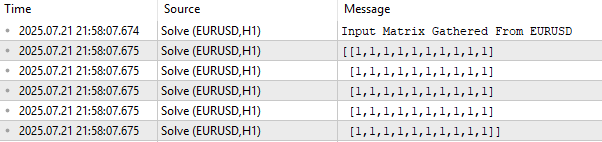
Рисунок 1: Визуализация текущих входных данных EURUSD
Разобравшись с этим, переходим к части скрипта, отвечающей за получение исторических рыночных данных. После получения мы вычисляем норму каждого вектора и делим каждый вектор на его норму. Этот этап нормализации гарантирует, что длина каждого вектора равна 1 — это важное условие перед применением любых методов факторизации матриц.
Зачем нужна нормализация? Факторизация матриц стремится определить направление роста матрицы и сравнивает темпы роста по строкам и столбцам. Чтобы такие сравнения были корректными, мы преобразуем каждую строку в единичный вектор, деля её на норму.
//--- Fetch the data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH*2),FETCH); row_norms[0] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH*2),FETCH); row_norms[1] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH*2),FETCH); row_norms[2] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH*2),FETCH); row_norms[3] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[3],4); //--- Fetch the test data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[3],4);
При выводе обучающих данных первая строка содержит единицы — это свободный член — затем идут строки для open, high, low и close. Значения начинаются примерно с 0.3 из-за нормализации.
//--- The train data Print("Input"); Print(X);

Рисунок 2: Визуализация обучающих данных после нормализации
Далее мы задаём целевые значения. В этом примере целью является цена закрытия, которую мы копируем в матрицу y. Таким образом, X содержит входные признаки, а y — значения, которые мы хотим предсказать.
//--- Fill the target y.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+(FETCH*2),FETCH); y_test.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START,FETCH); Print("Target"); Print(y);
![]()
Рисунок 3: Целевые значения, которые мы пытаемся предсказать на основе прошлых наблюдений рынка
Как же найти коэффициенты, которые связывают X и y? Оказывается, существует бесконечно много наборов коэффициентов, которые могут это сделать, поэтому нам нужен способ выбрать наиболее подходящий. Обычно выбирают те коэффициенты, которые минимизируют ошибку между предсказанными и фактическими значениями. Один из известных методов для этого — использование псевдообратной матрицы.
Чтобы вычислить коэффициенты, мы умножаем псевдообратную матрицу X на y. Это матричное умножение даёт оптимальные коэффициенты в замкнутой форме. К счастью, в MQL5 есть встроенная функция для этого — PInv() (псевдообратная матрица).
Не позволяйте простоте этого решения вас обмануть. Можно посвятить оставшуюся часть всей статьи объяснению значимости этой одной строки кода. Коэффициенты, полученные с помощью функции PInv() в MQL5, гарантированно минимизируют ошибку RMSE между предсказаниями и прошлыми наблюдениями. Более того, такие решения всегда существуют. Алгоритм является численно устойчивым и позволяет создавать компактный и легко поддерживаемый код для построения собственных предсказательных моделей на основе "сырых" данных. Однако это не тот метод, который рекомендуется использовать.
//--- More Penrose Psuedo Inverse Solution implemented by MQL5 Developers b = y.MatMul(X.PInv()); Print("Pseudo Inverse Solution: "); Print(b);
![]()
Рисунок 4: Коэффициенты, полученные путём умножения псевдообратной матрицы на целевые значения, минимизируют ошибку
Цель этой статьи — познакомить вас с OpenBLAS и другими методами факторизации матриц. Так зачем изучать OpenBLAS, если в MQL5 уже есть простой способ построения предсказательных моделей с помощью функции PInv()? Причин несколько, и главная из них — скорость. OpenBLAS работает значительно быстрее, чем встроенная реализация псевдообратной матрицы в MQL5. Освоение этой библиотеки существенно ускорит выполнение ваших бэктестов.
Факторизация матриц без учителя: сингулярное разложение
Как упоминалось во введении, любую матрицу данных можно разложить в произведение более мелких матриц. Эти меньшие матрицы можно рассматривать как "детей" исходной матрицы, каждая из которых даёт своё уникальное описание "родителя".
Алгоритм сингулярного разложения (SVD, Singular Value Decomposition) — один из способов факторизации матриц. SVD разбивает любую матрицу на произведение трёх более простых, элементарных матриц. Каждая из этих трёх матриц отражает отдельную характеристику исходной матрицы. В этом разделе мы познакомимся с каждым из этих трёх "детей" SVD-разложения, разберём мотивацию использования SVD и поймём, какую информацию о исходной матрице несёт каждый компонент.
Прежде чем углубляться, важно уточнить терминологию. Возможно, вы встречали термин "факторизация матриц без учителя", используемый вместе с факторизацией матриц, однако это не одно и то же. Неподконтрольная факторизация — это частный вид факторизации, который отличается тем, что фокусируется только на наиболее значимых компонентах данных.
По сути, неподконтрольная факторизация не возвращает нам всех «детей» — она возвращает только наиболее важные. Алгоритм разлагает матрицу, а затем, используя собственные внутренние критерии, определяет, какие факторы (или "дети") наиболее ценны. Это решение принимается без учителя, то есть алгоритм не опирается на размеченные данные или человеческое вмешательство для определения значимости. Мы не выбираем, с какими "детьми" познакомиться — алгоритм делает этот выбор за нас.
Как показано на рисунке 5, SVD — один из таких методов факторизации, который разлагает любую матрицу A в произведение 3 её "дочерних матриц.
Библиотека OpenBLAS позволяет методу SVD возвращать либо все "дочерние" матрицы, либо только наиболее важные — всё зависит от параметров, переданных при вызове SVD.
В данном обсуждении мы настроим библиотеку OpenBLAS так, чтобы она возвращала только наиболее значимые "дочерние" матрицы, что и объясняет название раздела — "Факторизация матриц без учителя". Как уже было сказано, SVD разлагает исходную матрицу на произведение 3 более простых матриц. Теперь мы последовательно рассмотрим каждую из этих 3 составляющих.
![]()
Рисунок 5: Визуализация SVD-разложения
Матрица U описывает скрытые рыночные силы, которые, по-видимому, "двигают" наблюдаемое поведение рынка. Эти скрытые силы корректнее называть факторами. Так, первый столбец U показывает рыночную силу, которая приводит к снижению всех четырёх цен OHLC, когда она доминирует. Вторая сила характеризуется положительными коэффициентами, что означает её общий бычий эффект на рынок. Поскольку мы работаем с историческими рыночными данными, анализируемые силы могут отражать настроение инвесторов.
//--- Native MQL5 SVD Solution are also possible without relying on OpenBLAS Print("Computing Singular Value Decomposition using MQL5"); matrix U,VT; vector S; X.SVD(U,VT,S); Print("U"); Print(U);

Рисунок 6: Понимание компонента "U" в SVD
Матрица V показывает, насколько сильно каждая из сил из U проявляется во времени — на всех наблюдениях исходного набора данных. Например, если рассмотреть первую строку V, можно увидеть, что наибольшее значение равно 0.4262. Оно находится в третьем столбце первой строки V, что означает: 3 столбец U описывает силу, которая доминировала на первом дне торгов. Этот столбец U отражает смешанную силу, которая отрицательно влияет на одни компоненты цены и положительно — на другие. Такие силы могут быть временными или слабо выраженными.
Print("VT"); Print(VT);
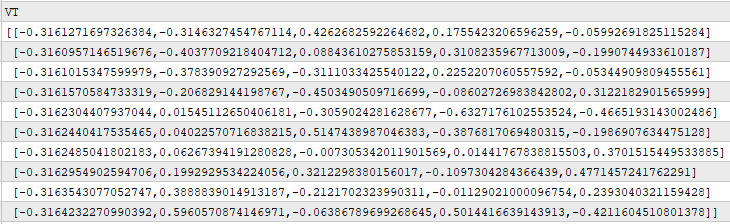
Рисунок 7: Понимание силы проявления факторов во времени
Матрица Сигма показывает значимость каждой рыночной силы, описанной в U. Сила, которая доминирует в исторических данных, получает наибольшее значение в Сигме, а менее выраженные силы — меньшие значения. Например, значение 3.741 является наибольшим и находится в первом столбце Сигма, что означает: первый столбец U описывает наиболее доминирующую рыночную силу в данных.
Print("S"); Print(S);
![]()
Рисунок 8: Понимание матрицы Сигма в SVD
Это обсуждение не является исчерпывающим — о 3 компонентах U, S и V можно сказать гораздо больше. На рисунках 6, 7 и 8 мы рассмотрели результаты, полученные с использованием встроенной функции SVD в MQL5. Эти результаты практически совпадают с теми, которые возвращает функция SingularValueDecompositionDC() из библиотеки OpenBLAS.
На рисунке 9 показан фактор U, вычисленный с помощью OpenBLAS. Сравнивая рисунки 9 и 6, можно убедиться, что встроенная функция MQL5 и OpenBLAS дают практически одинаковые результаты. Из-за различий в реализации значения могут немного отличаться в последних знаках после запятой, что является нормальным.
//--- OpenBLAS SVD Solution, considerably powerful substitute to the closed solution provided by the MQL5 developers matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; //--- Perform truncated SVD, we will explore what 'truncated' means later. PrintFormat("Computing Singular Value Decomposition of %s Data using OpenBLAS",Symbol()); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); //--- U is a unitary matrix that is of dimension (m,r) Print("Open BLAS U"); Print(OB_U);

Рисунок 9: Матрица U, вычисленная с помощью OpenBLAS
Ранее, на рисунке 4, мы показали, что функция PInv() в MQL5 всегда даёт коэффициенты, которые наилучшим образом связывают входные данные с целевыми значениями, минимизируя ошибку. Ещё раз подчеркнём: не стоит недооценивать простоту этого решения. Это мощный математический инструмент, который гарантированно существует для любой матрицы A и минимизирует L2-норму выражения Ax − b.
Однако ранее мы не упомянули, что функция PInv() на самом деле может использовать SVD "под капотом". С математической точки зрения псевдообратная матрица обычно вычисляется через сингулярное разложение исходной матрицы. Давайте убедимся в этом.
В приведённом ниже фрагменте кода используются 3 "дочерние" матрицы, полученные при разложении SVD наших рыночных данных. Мы не будем подробно разбирать все правила линейной алгебры или вывод формул — цель лишь показать, что с помощью этих матриц можно легко получить линейные коэффициенты, связывающие входные данные и целевые значения.
Print("Comparing OLS Solutions"); Print("Native MQL5 Solution"); //--- We will always benchmark the native solution as the truth, the MQL5 developers implemented an extremely performant benchmark for us Print(b); //--- The OpenBLAS solution came closest to the native solution implemented for us Print("OpenBLAS Solution"); matrix ob_solution = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); Print(ob_solution); //--- Our manual solution was not even close! We will therefore rely on the OpenBLAS solution. Print("Manual SVD Solution"); matrix svd_solution = y.MatMul(VT).MatMul(SIGMA.Inv()).MatMul(U.Transpose()); Print(svd_solution);
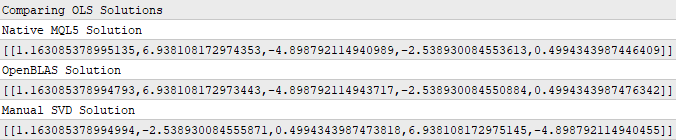
Рисунок 10: Коэффициенты, полученные с помощью SVD
Внимательные читатели могли заметить, что ни один из наборов коэффициентов на рисунке 10 не совпадает полностью. Это ожидаемо, поскольку использовались 3 разные функции для их получения. Это похоже на ситуацию, когда 3 студента решают одну задачу разными способами. Однако для нас важнее не совпадение коэффициентов, а ошибка, которую они дают при прогнозировании на новых данных.
Как видно на рисунке 11, решение SVD из OpenBLAS показало наименьшую ошибку при прогнозировании тестовых данных. Однако важно не делать из этого неверных выводов.
Обратите внимание, что все 3 значения ошибки достаточно близки. Если повторить эксперимент на разных рынках и с разными объёмами данных, OpenBLAS не всегда будет давать наименьшую ошибку. Его главное преимущество — это высокая скорость, оптимизация и надёжность, а не гарантированно лучший результат в каждом случае. Ни одна библиотека не может дать такой гарантии.
//--- Measuring the amount of error //--- Information lost by MQL5 PsuedoInverse solution //--- The Frobenius norm squares all PrintFormat("Information Loss in Forcasting %s Market : ",Symbol()); Print("PInv: "); matrix pinv_error = ((b.MatMul(X_test)) - y_test); Print(pinv_error.Norm(MATRIX_NORM_FROBENIUS)); //--- Let the MQL5 implementation be our benchmark double benchmark = pinv_error.Norm(MATRIX_NORM_FROBENIUS); //--- Information lost by Manual SVD solution Print("Manual SVD: "); matrix svd_error = ((svd_solution.MatMul(X_test)) - y_test); Print(svd_error.Norm(MATRIX_NORM_FROBENIUS)); //--- Information lost by OpenBLAS SVD solution Print("OpenBLAS SVD: "); matrix ob_error = ((ob_solution.MatMul(X_test)) - y_test); Print(ob_error.Norm(MATRIX_NORM_FROBENIUS));
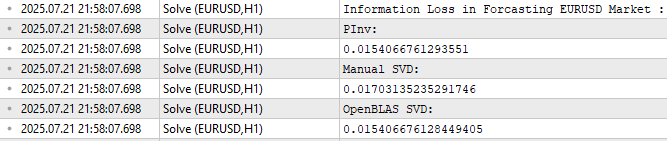
Рисунок 11: Ошибка различных наборов коэффициентов при прогнозировании вне обучающего периода
Применение неподконтрольной факторизации матриц за пределами предсказательного моделирования
Надеюсь, к этому моменту мой простой стиль изложения помог вам понять, что такое факторизация матриц и почему она может быть полезна при анализе финансовых рынков. Как я уже отмечал ранее, предсказательные модели — это лишь небольшая часть возможностей, которые открывает факторизация матриц. В этом разделе я покажу другие полезные применения и то, как эти идеи можно использовать в торговых системах и стратегиях.
Факторизация матриц для неподконтрольной фильтрации рынков
Предположим, у вас уже есть некоторый опыт торговли. Тогда попробуем задать простой вопрос: какой рынок более волатилен — валютный или криптовалютный?
Надеюсь, ответ для всех нас был очевиден. Криптовалюты гораздо более волатильны, чем традиционные валютные рынки. Для читателей, которые могут не знать, как обстоят дела на самом деле, мы применили индикатор Average True Range (ATR) на одном графике к минутному графику Биткоина, выраженному в Эфириуме (Рисунок 12), а на втором графике снизу показано Евро, выраженное в долларах США (Рисунок 13). Индикатор ATR измеряет волатильность рынка: более высокие значения ATR означают более высокую волатильность рынка. Значение ATR на графике BTCETH примерно на 6000% выше, чем значение ATR на графике EURUSD. Следовательно, это помогает всем читателям понять, почему рынки криптовалют обычно считаются гораздо более волатильными, чем традиционные валютные рынки.
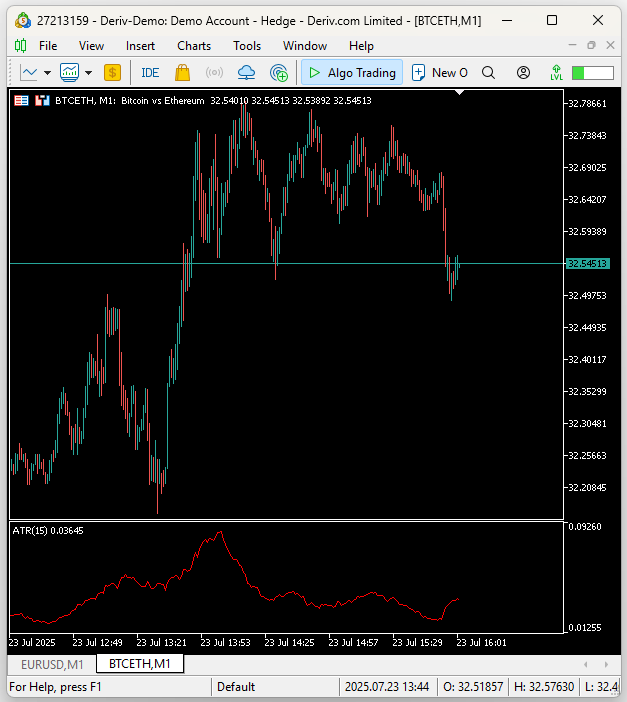
Рисунок 12: Показатель волатильности BTCETH значительно выше, чем у EURUSD
Напомним, что EURUSD — самая ликвидная валютная пара в мире, это самая активно торгуемая валютная пара из известных человечеству, однако её уровни волатильности меркнут по сравнению с волатильностью, которую мы наблюдаем на рынках криптовалют.
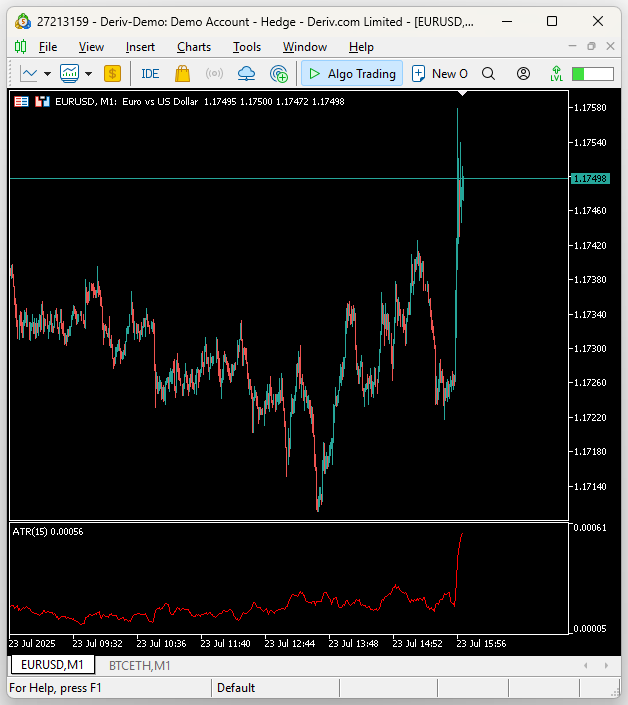
Рисунок 13: Волатильность традиционных классов активов не идет ни в какое сравнение с волатильностью, создаваемой рынками криптовалют
Матричные факторизации, которые мы выполнили ранее, могли бы легко сообщить нам ту же самую информацию. Напомним, что на Рисунке 8 мы объясняли, что фактор Sigma обозначает уровни важности каждой из движущих сил рынка, присутствующих в данных. На стабильных рынках в факторе S будет только одно большое значение, а все остальные будут близки к нулю. Чем больше значений в S далеки от нуля, тем более хаотичным и волатильным, согласно данным, выглядит рынок.
Мы можем применить наш скрипт дважды: один раз для рынка EURUSD, а второй раз для рынка BTCETH. Однако на Рисунках 14 и 15 оба рынка выглядят стабильными. Похоже, что на обоих рынках есть только 1 большое ненулевое значение в S. Это могло бы означать, что BTCETH демонстрирует устойчивую динамику, как и EURUSD. Однако это не вся правда. Чтобы получить достоверную картину, мы должны изучить еще одно применение матричной факторизации.
//+------------------------------------------------------------------+ //| What are we demonstrating here? | //| 1) We have shown you that any matrix of market data you have, | //| can be analyzed intelligently, to build a linear regression | //| model, using just the raw data. | //| 2) We have demonstrated that the solution to such Linear | //| regression problems, can be obtained through effecient and | //| dedicated functions available in MQL5 or through matrix | //| factorization. | //|__________________________________________________________________| //| I now ask the reader the following question: | //| "If dedicated functions exist, why bother learning matrix | //| factorization?" | //+------------------------------------------------------------------+ //--- Matrix factorization gives us a description of the data and it properties //--- Questions such as: "How stable/chaotic is the market we are in?" can be answered by the factorization we have just performed //--- Or even questions such as: "How best can I expose the hidden trends in all of this market data?" can still be answered by the factorization we have just performed //--- I'm only trying to give you a few examples of why you should bother learning these factorizations, even though dedicated functions exist. //--- Any given matrix A can be represented as the sum of smaller matrices A = USV, this is theorem behind the Singular Value Decomposition. //--- Each factor is special because each describes different charectersitics of its parent. //--- Let's get to know Sigma, represented as the S in A = USV. //--- Sigma technically tells us how many different modes our market appears to exist in, and how important each mode is. //--- However, reintepreted in terms of market data, these modes may correspond to investor sentiment. PrintFormat("Taking a closer look at The Eigenvalues of %s Market Data: ",Symbol()); Print(OB_S/OB_S.Sum()); Print("If sigma has a only few values that are far from 0, then investor's sentiment in this market appears well established and hardly changes"); //--- If Sigma has a lot values that are all far away from 0, then the market is chaotic and it appears investor's sentiment and expectations constantly change //--- If Sigma has a few, or even just one value that is far away from 0, then investor sentiment in that market appears stable, and hardly changes. //--- Traders explicitly looking for fast-action scalping oppurtunities may use Sigma as a filter of how much energy the market has. //--- Quiet market will have a few dominant values in Sigma, not ideal for scalpers, better suited for long-term trend traders.
![]()
Рисунок 14: Визуализация уровня энергии рынка EURUSD
![]()
Рисунок 15: Визуализация уровня энергии рынка BTCETH
Матричная факторизация для сжатия данных и извлечения доминирующего сигнала
Матричная факторизация также может использоваться для сжатия данных и извлечения доминирующего сигнала в данных. Поскольку дочерние матрицы меньше родительской, эти алгоритмы могут эффективно уплотнять данные. Эти свойства матричной факторизации хорошо известны любым членам нашего сообщества, имеющим опыт в таких областях, как сетевое взаимодействие, обработка сигналов, электротехника или другие смежные дисциплины. Мы можем сжать наши исходные данные, перемножив дочерние матрицы S и V. Обратите внимание, что перед умножением мы вызываем метод Diag() для S, чтобы преобразовать её в диагональную матрицу. Результат этого умножения представляет собой новое и компактное представление родительской матрицы.
Читатель, возможно, уже знаком с этим алгоритмом, который широко известен как метод главных компонент (Principal Component Analysis, PCA). Мы не будем глубоко погружаться в PCA; я лишь пытаюсь продемонстрировать, сколько полезной информации мы получаем от использования матричной факторизации. Существует множество способов вычисления главных компонент ваших рыночных данных; матричная факторизация с использованием OpenBLAS, вероятно, является одним из самых быстрых методов, доступных вам в MQL5 из коробки.
//--- Fetch the data and prepare to perform PCA temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH*2),FETCH); row_norms[0] = temp.Mean(); X.Row(temp-row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH*2),FETCH); row_norms[1] = temp.Mean(); X.Row(temp-row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH*2),FETCH); row_norms[2] = temp.Mean(); X.Row(temp-row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH*2),FETCH); row_norms[3] = temp.Mean(); X.Row(temp-row_norms[3],4); //--- Fetch the test data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[3],4); //--- Perform truncated SVD, we will explore what 'truncated' means later. Print("Computing Singular Value Decomposition using OpenBLAS"); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); //--- Calculating Principal Components Print("Principal Components"); matrix pc = OB_SIGMA.MatMul(OB_VT); Print(pc);

Рисунок 16: Умножая факторы S и V, мы получаем компактное представление нашего исходного набора данных
Мы можем обсудить еще гораздо больше о произведении, полученном в результате умножения "дочерних" матриц S и V. Результат этого умножения дает новое представление нашего набора данных, в котором корреляций значительно меньше. Чтобы доказать это, мы сравним норму корреляционной матрицы нашего исходного набора данных с нормой корреляционной матрицы, полученной из произведения S и V. Напомним, что норма в линейной алгебре аналогична вопросу "насколько большим" что-либо является. Как мы видим на Рисунке 17, норма корреляционной матрицы значительно снизилась после факторизации исходных рыночных данных.
Цель этого — проиллюстрировать читателю, что матричная факторизация с использованием SVD может применяться для удаления избыточных коррелированных признаков в исходном наборе данных, и, как надеется автор, благодаря этому мы сможем лучше выявить доминирующие тренды и закономерности в данных.
//--- PCA reduces the amount of correlation in our dataset Print("How correlated is our new representation of the data?"); //--- First we will measure the size of our original correlation matrix Print(X.Norm(MATRIX_NORM_FROBENIUS)); //--- Then, we will measure the size of our new correlation matrix produced by factorizing the data Print(pc.CorrCoef().Norm(MATRIX_NORM_FROBENIUS));

Рисунок 17: Матричная факторизация может помочь нам значительно снизить степень корреляции в нашем наборе данных
Имея эту информацию, мы можем построить модель рынка, используя только 3 строки данных вместо исходных 5 строк, с которых мы начинали. Есть надежда, что эти 3 менее коррелированных строки позволят лучше объяснить взаимосвязь между рынком и целевой переменной, чем исходные данные. Это называется извлечением признаков, поскольку мы получаем новые признаки из исходных данных. Но, как и в большинстве практик, связанных с оптимизацией, нет гарантии, что это улучшит нашу эффективность в будущем, как показано на Рисунке 18.
//--- Main principal components matrix mpc; mpc.Row(pc.Row(0),0); mpc.Row(pc.Row(1),1); mpc.Row(pc.Row(2),2); //--- The factor VT describes the correlational structure across the columns of our data Print("Performing PCA"); matrix pca_coefs = y.MatMul(mpc.PInv()); //--- Performing PCA on the test data X_test.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); Print("Principal Components of Test Data"); pc = OB_SIGMA.MatMul(OB_VT); Print(pc); PrintFormat("Most Important Principal Components in %s Market Test Data",Symbol()); Print(OB_S / OB_S.Sum()); //--- Main principal components mpc.Row(pc.Row(0),0); mpc.Row(pc.Row(1),1); mpc.Row(pc.Row(2),2); matrix pca_error = pca_coefs.MatMul(mpc) - y_test; Print("PCA Error: "); Print(pca_error.Norm(MATRIX_NORM_FROBENIUS)); Print("OpenBLAS Error: "); Print(ob_error.Norm(MATRIX_NORM_FROBENIUS)); Print("Manual Error: "); Print(svd_error.Norm(MATRIX_NORM_FROBENIUS));
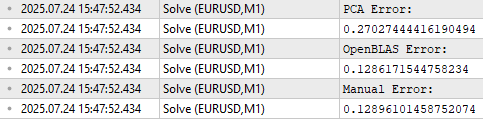
Рисунок 18: Извлечение признаков — это мощный численный метод, но он не гарантирует улучшения производительности
На Рисунках 14 и 15 мы попытались проиллюстрировать, что матричную факторизацию можно использовать для различия стабильных и волатильных рынков. В нашей первой попытке оба рынка, казалось, имели только 1 большое значение в факторе S. Однако после тщательного изучения данных я понял, что это было справедливо только для обучающего набора. Если мы факторизуем тестовый набор наших рыночных данных, а затем проанализируем полученный фактор S, мы сможем увидеть, что действительно BTCETH имеет больше "энергии", чем EURUSD, поскольку BTCETH имеет 2 значения в S, далеких от 0, в то время как EURUSD — только 1.
//--- Performing PCA on the test data X_test.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); Print("Principal Components of Test Data"); pc = OB_SIGMA.MatMul(OB_VT); PrintFormat("Most Important Principal Components in %s Market Test Data",Symbol()); Print(OB_S / OB_S.Sum());
![]()
Рисунок 19: Анализ уровня энергии рынка EURUSD
![]()
Рисунок 19-1: Анализ уровня энергии рынка BTCETH. Напомним, что чем больше отдельных значений, далеких от 0, вы наблюдаете, тем более хаотичным является рынок
Это скрипт MQL5, который я подготовил для нашего обсуждения матричной факторизации без обучения.
//+------------------------------------------------------------------+ //| Solve.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define HORIZON 10 #define START 0 //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int FETCH = 10;//How many bars should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ROWS = 5; //Dependent variable matrix y,y_test; //Indenpendent variable matrix X = matrix::Ones(ROWS,FETCH); matrix X_test = matrix::Ones(ROWS,FETCH); //Coefficients matrix b; vector temp; //Row Norms vector row_norms = vector::Zeros(4); vector error_vector = vector::Zeros(4); //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Observe the input matrix in its original form PrintFormat("Input Matrix Gathered From %s",Symbol()); Print(X); //--- Fetch the data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH*2),FETCH); row_norms[0] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH*2),FETCH); row_norms[1] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH*2),FETCH); row_norms[2] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH*2),FETCH); row_norms[3] = temp.Norm(VECTOR_NORM_P); X.Row(temp/row_norms[3],4); //--- Fetch the test data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH),FETCH); X_test.Row(temp/row_norms[3],4); //--- The train data Print("Input"); Print(X); //--- Fill the target y.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+(FETCH*2),FETCH); y_test.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START,FETCH); Print("Target"); Print(y); //--- More Penrose Psuedo Inverse Solution implemented by MQL5 Developers, enterprise level effeciency! b = y.MatMul(X.PInv()); Print("Pseudo Inverse Solution: "); Print(b); //--- Native MQL5 SVD Solution are also possible without relying on OpenBLAS Print("Computing Singular Value Decomposition using MQL5"); matrix U,VT; vector S; X.SVD(U,VT,S); Print("U"); Print(U); Print("VT"); Print(VT); Print("S"); Print(S); matrix SIGMA; SIGMA.Diag(S); //--- OpenBLAS SVD Solution, considerably powerful substitute to the closed solution provided by the MQL5 developers matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; //--- Perform truncated SVD, we will explore what 'truncated' means later. PrintFormat("Computing Singular Value Decomposition of %s Data using OpenBLAS",Symbol()); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); //--- U is a unitary matrix that is of dimension (m,r) Print("Open BLAS U"); Print(OB_U); //--- VT is a mathematically a symmetrical matrix that is (r,r), for effeciency in software it is represented as a vector that is (1,r) Print("Open BLAS VT"); Print(OB_VT); //--- We need it in its intended form as an (r,r) matrix, we will explore what this means later. Print("Open BLAS S"); Print(OB_S); OB_SIGMA.Diag(OB_S); Print("Comparing OLS Solutions"); Print("Native MQL5 Solution"); //--- We will always benchmark the native solution as the truth, the MQL5 developers implemented an extremely performant benchmark for us Print(b); //--- The OpenBLAS solution came closest to the native solution implemented for us Print("OpenBLAS Solution"); matrix ob_solution = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); Print(ob_solution); //--- Our manual solution was not even close! We will therefore rely on the OpenBLAS solution. Print("Manual SVD Solution"); matrix svd_solution = y.MatMul(VT).MatMul(SIGMA.Inv()).MatMul(U.Transpose()); Print(svd_solution); //--- Measuring the amount of error //--- Information lost by MQL5 PsuedoInverse solution //--- The Frobenius norm squares all PrintFormat("Information Loss in Forcasting %s Market : ",Symbol()); Print("PInv: "); matrix pinv_error = ((b.MatMul(X_test)) - y_test); Print(pinv_error.Norm(MATRIX_NORM_FROBENIUS)); //--- Let the MQL5 implementation be our benchmark double benchmark = pinv_error.Norm(MATRIX_NORM_FROBENIUS); //--- Information lost by Manual SVD solution Print("Manual SVD: "); matrix svd_error = ((svd_solution.MatMul(X_test)) - y_test); Print(svd_error.Norm(MATRIX_NORM_FROBENIUS)); //--- Information lost by OpenBLAS SVD solution Print("OpenBLAS SVD: "); matrix ob_error = ((ob_solution.MatMul(X_test)) - y_test); Print(ob_error.Norm(MATRIX_NORM_FROBENIUS)); //+------------------------------------------------------------------+ //| What are we demonstrating here? | //| 1) We have shown you that any matrix of market data you have, | //| can be analyzed intelligently, to build a linear regression | //| model, using just the raw data. | //| 2) We have demonstrated that the solution to such Linear | //| regression problems, can be obtained through effecient and | //| dedicated functions available in MQL5 or through matrix | //| factorization. | //|__________________________________________________________________| //| I now ask the reader the following question: | //| "If dedicated functions exist, why bother learning matrix | //| factorization?" | //+------------------------------------------------------------------+ //--- Matrix factorization gives us a description of the data and it properties //--- Questions such as: "How stable/chaotic is the market we are in?" can be answered by the factorization we have just performed //--- Or even questions such as: "How best can I expose the hidden trends in all of this market data?" can still be answered by the factorization we have just performed //--- I'm only trying to give you a few examples of why you should bother learning these factorizations, even though dedicated functions exist. //--- Any given matrix A can be represented as the sum of smaller matrices A = USV, this is theorem behind the Singular Value Decomposition. //--- Each factor is special because each describes different charectersitics of its parent. //--- Let's get to know Sigma, represented as the S in A = USV. //--- Sigma technically tells us how many different modes our market appears to exist in, and how important each mode is. //--- However, reintepreted in terms of market data, these modes may correspond to investor sentiment. PrintFormat("Taking a closer look at The Eigenvalues of %s Market Data: ",Symbol()); Print(OB_S/OB_S.Sum()); Print("If sigma has a only few values that are far from 0, then investor's sentiment in this market appears well established and hardly changes"); //--- If Sigma has a lot values that are all far away from 0, then the market is chaotic and it appears investor's sentiment and expectations constantly change //--- If Sigma has a few, or even just one value that is far away from 0, then investor sentiment in that market appears stable, and hardly changes. //--- Traders explicitly looking for fast-action scalping oppurtunities may use Sigma as a filter of how much energy the market has. //--- Quiet market will have a few dominant values in Sigma, not ideal for scalpers, better suited for long-term trend traders. //--- Fetch the data and prepare to perform PCA temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH*2),FETCH); row_norms[0] = temp.Mean(); X.Row(temp-row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH*2),FETCH); row_norms[1] = temp.Mean(); X.Row(temp-row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH*2),FETCH); row_norms[2] = temp.Mean(); X.Row(temp-row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH*2),FETCH); row_norms[3] = temp.Mean(); X.Row(temp-row_norms[3],4); //--- Fetch the test data temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_OPEN,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[0],1); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_HIGH,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[1],2); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_LOW,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[2],3); temp.CopyRates(Symbol(),PERIOD_CURRENT,COPY_RATES_CLOSE,START+HORIZON+(FETCH),FETCH); X_test.Row(temp-row_norms[3],4); //--- Perform truncated SVD, we will explore what 'truncated' means later. Print("Computing Singular Value Decomposition using OpenBLAS"); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); //--- Calculating Principal Components Print("Principal Components"); matrix pc = OB_SIGMA.MatMul(OB_VT); Print(pc); PrintFormat("Most Important Principal Components of %s Market Data",Symbol()); Print(OB_S / OB_S.Sum()); //--- Main principal components matrix mpc; mpc.Row(pc.Row(0),0); mpc.Row(pc.Row(1),1); mpc.Row(pc.Row(2),2); //--- The factor VT describes the correlational structure across the columns of our data Print("Performing PCA"); matrix pca_coefs = y.MatMul(mpc.PInv()); //--- Performing PCA on the test data X_test.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); Print("Principal Components of Test Data"); pc = OB_SIGMA.MatMul(OB_VT); Print(pc); PrintFormat("Most Important Principal Components in %s Market Test Data",Symbol()); Print(OB_S / OB_S.Sum()); //--- Main principal components mpc.Row(pc.Row(0),0); mpc.Row(pc.Row(1),1); mpc.Row(pc.Row(2),2); matrix pca_error = pca_coefs.MatMul(mpc) - y_test; Print("PCA Error: "); Print(pca_error.Norm(MATRIX_NORM_FROBENIUS)); Print("OpenBLAS Error: "); Print(ob_error.Norm(MATRIX_NORM_FROBENIUS)); Print("Manual Error: "); Print(svd_error.Norm(MATRIX_NORM_FROBENIUS)); } //+------------------------------------------------------------------+
Создание нашего приложения
Мы начнем объединять то, что обсудили до сих пор, в единую торговую стратегию. Наша стратегия стремится определить справедливую рыночную цену путем прогнозирования будущего значения индикатора скользящей средней. Это ожидаемое значение поможет нам открывать сделки в том смысле, что когда уровни цены будут выше наших ожиданий, мы будем продавать, полагая, что рынок переоценен; обратное справедливо для наших длинных позиций.Давайте применим 10-периодную скользящую среднюю на дневном графике EURUSD и сдвинем ее вперед, чтобы представить ее сдвинутое значение как наш прогноз.
Рисунок 20: В иллюстративных целях мы просто сдвинули индикатор скользящей средней на 10 шагов вперед
Наша торговая стратегия по существу предполагает, что текущие уровни цены в конечном итоге будут соответствовать ожидаемому значению. В ситуации, изображенной на Рисунке 21, ожидаемая цена низкая, в то время как текущая цена высокая. Предположим, что Рисунок 21 был сгенерирован нашим прогнозом рынка — это и будет наш сигнал.
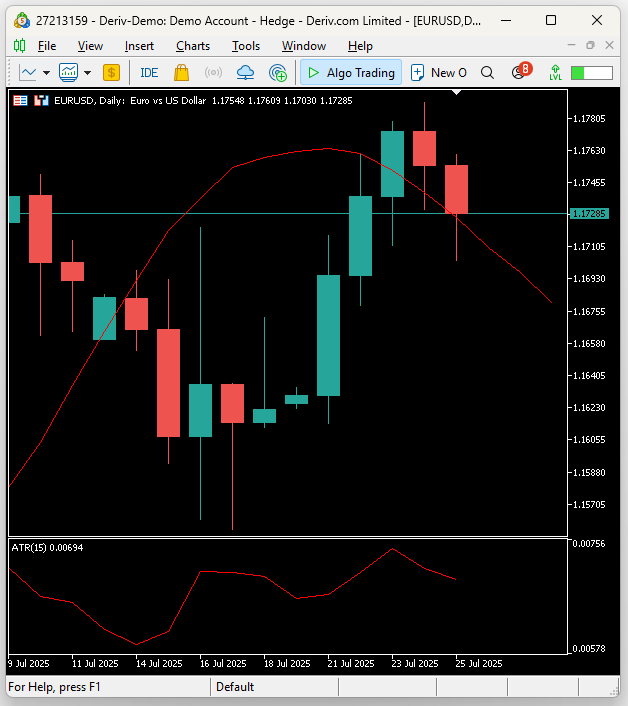
Рисунок 21: Визуализация нашей торговой стратегии. Сдвинутая скользящая средняя означает, что мы будем торговать на основе того, где, по прогнозам нашей модели, будет находиться скользящая средняя
Установление базового уровня
Прежде чем создавать наше приложение, мы должны установить базовый уровень для оценки производительности нашей модели ИИ. Этот базовый уровень покажет ожидаемый результат без использования ИИ. Поскольку мы рассмотрим полную реализацию нашего приложения в следующих разделах, сейчас я кратко выделю ключевые элементы базового уровня.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { y.CopyIndicatorBuffer(ma_close_handler,0,0,bars); Print("Training Target"); Print(y); //--- Get a prediction prediction = y.Mean(); Print("Prediction"); Print(prediction); } //+------------------------------------------------------------------+
Базовый уровень делает свои прогнозы, воспроизводя значения индикатора скользящей средней — вычисляя их среднее значение и совершая сделки на его основе. Если среднее значение индикатора скользящей средней превышает текущую цену, мы покупаем; в противном случае — продаем.
if(prediction > c) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),proposed_buy_sl,0); state = 1; } if(prediction < c) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),proposed_sell_sl,0); state = -1; }Теперь мы применим наше приложение к паре USD/UL, как показано на Рисунке 22, используя два года исторических данных с января 2023 по март 2025 года.
Рисунок 22: Тестирование нашего базового приложения на исторических рыночных данных
Рисунок 23 отображает настройки приложения, которые мы используем. Важно сохранять эти входные параметры неизменными во всех тестах, чтобы обеспечить честное сравнение.

Рисунок 23: Мы сохраним наши базовые параметры фиксированными для обеспечения честного сравнения
Рисунок 24 показывает кривую доходности, полученную нашей торговой стратегией. Результаты показывают, что наш подход является надежным, а баланс счета имеет положительную динамику с течением времени.
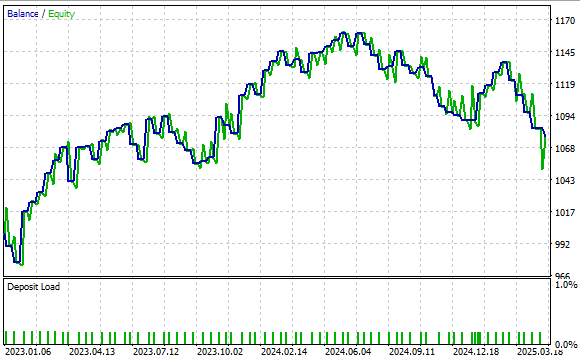
Рисунок 24: Наше базовое приложение установило высокий уровень производительности, который мы должны превзойти благодаря нашему новому пониманию матричной факторизации
Рисунок 25 предоставляет детальные показатели производительности. Стратегия достигла 51% доли выигрышных сделок, что демонстрирует стабильную прибыльность. Она обеспечила положительный коэффициент Шарпа 0,47 — это здоровое значение. Хотя дальнейшие улучшения могут повысить этот коэффициент, система уже обеспечивает надежный базовый уровень. Даже с помощью наивных прогнозов будущих значений скользящей средней мы можем построить прибыльную стратегию. Теперь давайте рассмотрим преимущества более обоснованных прогнозов.
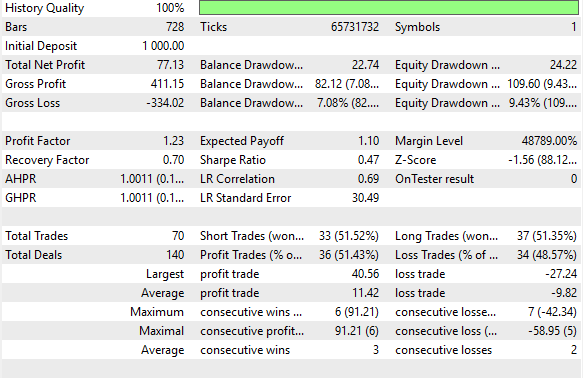
Рисунок 25: Детальный анализ нашего базового уровня производительности
Улучшение наших результатов
Теперь мы готовы приступить к созданию нашего приложения в MQL5. Начнем с определения ключевых системных констант, необходимых на данный момент. Эти константы будут управлять техническими индикаторами, на которые будет полагаться наша система, а также определять общее количество входных данных, требуемых приложению.
//+------------------------------------------------------------------+ //| Linear Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define TOTAL_INPUTS 6
Далее мы определим входные параметры системы, которые пользователи могут настраивать для изменения поведения системы.
//+------------------------------------------------------------------+ //| System Inputs | //+------------------------------------------------------------------+ input int bars = 10;//Number of historical bars to fetch input int horizon = 10;//How far into the future should we forecast input int MA_PERIOD = 24; //Moving average period input ENUM_TIMEFRAMES TIME_FRAME = PERIOD_H1;//User Time Frame
Мы также объявим набор важных глобальных переменных для отслеживания всех параметров, используемых нашей моделью линейной регрессии.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
В ходе последовательности инициализации нашего советника мы присвоим всем глобальным переменным их значения по умолчанию и инициализируем соответствующие технические индикаторы.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ int ma_close_handler; double ma_close[]; Time *Timer; TradeInfo *TradeInformation; vector bias,temp,Z1,Z2; matrix X,y,prediction,b; int time; CTrade Trade; int state; int atr_handler; double atr[];
В последовательности деинициализации мы освободим всю память, ранее выделенную под глобальные переменные, включая все технические индикаторы, которые больше не нужны.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Timer = new Time(Symbol(),TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),TIME_FRAME); ma_close_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_CLOSE); bias = vector::Ones(TOTAL_INPUTS); Z1 = vector::Ones(TOTAL_INPUTS); Z2 = vector::Ones(TOTAL_INPUTS); X = matrix::Ones(TOTAL_INPUTS,bars); y = matrix::Ones(1,bars); time = 0; state = 0; atr_handler = iATR(Symbol(),TIME_FRAME,14); //--- return(INIT_SUCCEEDED); }
Когда наше приложение получает обновленные уровни цен, мы хотим соответствующим образом скорректировать веса коэффициентов нашей модели и поддерживать их в актуальном состоянии, отслеживая текущие рыночные условия. Это означает, что в ходе нашего бэк-теста мы будем вычислять SVD-факторизацию значительное количество раз. Однако в этом и заключается преимущество простой реализации, предоставленной нам командой OpenBLAS. Многократные вызовы практически не замедляют скорость наших исторических бэк-тестов.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(Timer.NewCandle()) { setup(); double c = iClose(Symbol(),TIME_FRAME,0); CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_close_handler,0,0,1,ma_close); if(PositionsTotal() == 0) { state = 0; if(prediction[0,0] > c) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),(TradeInformation.GetBid() - (2 * atr[0])),0); state = 1; } if(prediction[0,0] < c) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),(TradeInformation.GetAsk() + (2 * atr[0])),0); state = -1; } } if(PositionsTotal() > 0) { if(((state == -1) && (prediction[0,0] > c)) || ((state == 1)&&(prediction[0,0] < c))) Trade.PositionClose(Symbol()); if(PositionSelect(Symbol())) { double current_sl = PositionGetDouble(POSITION_SL); if((state == 1) && ((ma_close[0] - (2 * atr[0]))>current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] - (2 * atr[0])),0); } else if((state == -1) && ((ma_close[0] + (1 * atr[0]))<current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] + (2 * atr[0])),0); } } } } }
Наконец, мы определяем функцию, используемую для получения прогнозов от нашей модели линейной регрессии, с помощью стандартизированных и масштабированных Z-значений, отслеживаемых в векторах с именами Z1 (для среднего значения) и Z2 (для стандартного отклонения). Каждый из этих масштабированных векторов-строк сохраняется в матрице X_inputs, а соответствующее значение скользящей средней, которое мы стремимся предсказать, сохраняется в Y. Затем мы обучаем модель, используя описанные ранее методы факторизации, и применяем полученные коэффициенты для прогнозирования.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { //--- OpenBLAS SVD Solution, considerably powerful substitute to the closed solution provided by the MQL5 developers matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; //--- Reshape the matrix X = matrix::Ones(TOTAL_INPUTS,bars); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,horizon,bars); Z1[0] = temp.Mean(); Z2[0] = temp.Std(); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,horizon,bars); Z1[1] = temp.Mean(); Z2[1] = temp.Std(); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,horizon,bars); Z1[2] = temp.Mean(); Z2[2] = temp.Std(); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); Z1[3] = temp.Mean(); Z2[3] = temp.Std(); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_close_handler,0,horizon,bars); Z1[4] = temp.Mean(); Z2[4] = temp.Std(); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); temp.CopyIndicatorBuffer(ma_close_handler,0,0,bars); y.Row(temp,0); Print("Training Input Data: "); Print(X); Print("Training Target"); Print(y); //--- Perform truncated SVD, we will explore what 'truncated' means later. PrintFormat("Computing Singular Value Decomposition of %s Data using OpenBLAS",Symbol()); X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); //--- Fit the model //--- More Penrose Psuedo Inverse Solution implemented by MQL5 Developers, enterprise level effeciency! b = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); Print("OLS Solutions: "); Print(b); //--- Prepare to get a prediction //--- Reshape the data X = matrix::Ones(TOTAL_INPUTS,1); //--- Get a prediction temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,0,1); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,0,1); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,0,1); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,1); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); temp.CopyIndicatorBuffer(ma_close_handler,0,0,1); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); Print("Prediction Inputs: "); Print(X); //--- Get a prediction prediction = b.MatMul(X); Print("Prediction"); Print(prediction[0,0]); } //+------------------------------------------------------------------+
Теперь мы готовы приступить к тестированию улучшенной версии нашего торгового алгоритма. Напомним, что данная реализация предназначена для предоставления более обоснованных прогнозов ожидаемого значения цены. Мы сохраним даты тестирования такими же, как и в нашем первоначальном тесте, как показано на Рисунке 26. Кроме того, как проиллюстрировано на Рисунке 23, настройки приложения остаются неизменными. Таким образом, читатель может продолжать использовать ту же самую конфигурацию.
Рисунок 26: Приготовьтесь к тестированию улучшений, реализованных нашим новым торговым приложением
Анализируя новые результаты, мы можем ясно наблюдать значительные улучшения. Наивная стратегия принесла общую чистую прибыль в размере $77, тогда как наша улучшенная стратегия достигла чистой прибыли в $101 — заметное увеличение. Это представляет собой рост общей чистой прибыли на 31%. Кроме того, коэффициент Шарпа, который изначально составлял 0,47 в первой реализации, увеличился до 0,63. Это означает 34-процентное улучшение доходности с поправкой на риск, что указывает на значимое повышение производительности системы.
Процент прибыльных сделок также вырос с 51,4% в наивной системе до 51,8% в улучшенной версии. Более того, общее количество совершенных сделок увеличилось с 70 до 83, что говорит о том, что новая система обнаруживает больше торговых сигналов.
Хотя средний размер как выигрышных, так и проигрышных сделок уменьшился, система в целом стала более активной и эффективной. Всё это достигнуто с использованием нативного кода MQL5 и путем надлежащего применения матричных факторизаций к доступным данным.
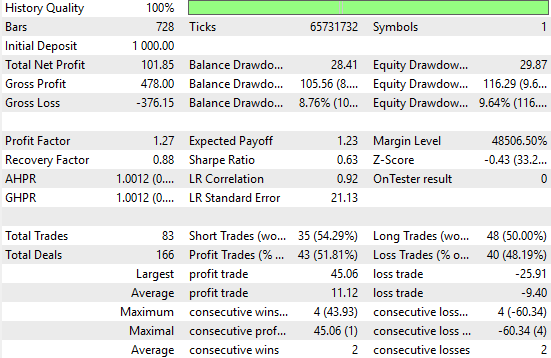
Рисунок 27: Детальный анализ результатов, достигнутых нашими обоснованными прогнозами будущих уровней цены
Мы также включили кривую прибыли, полученную улучшенной версией нашего торгового приложения. Наша новая торговая система демонстрирует положительную динамику баланса счета на исторических данных, что вдохновляет нас на дальнейший поиск улучшений.
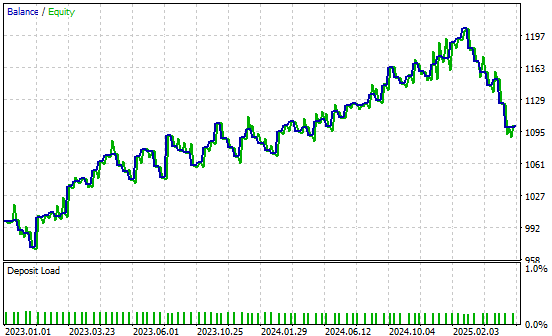
Рисунок 28: Кривая прибыли, полученная улучшенным торговым приложением
Заключение
Эта статья познакомила читателя с многочисленными преимуществами матричного API MQL5. Этот API предоставляет мощные математические инструменты, которые расширяют наши возможности для принятия обоснованных торговых решений.
Матричные факторизации позволяют нам выявлять скрытые закономерности в коррелированных данных — закономерности, которые могут быть не очевидны при использовании традиционных методов рыночного анализа. Теперь читатели обладают надежными альтернативами традиционным подходам к анализу временных рядов, которые обычно преподаются в финансах. Например, типичный анализ временных рядов начинается с дифференцирования данных для измерения периодических изменений. В отличие от этого, наш подход полностью избегает дифференцирования и вместо этого полагается на факторизацию данных.
Такой сдвиг в подходе открывает целый ряд практических применений. Мы продемонстрировали, как матричная факторизация обеспечивает быстрое и численно устойчивое статистическое моделирование. Она также уменьшает размерность данных, упрощая их до более компактных форм, которые лучше раскрывают глубинные тренды.
Хотя о преимуществах матричных факторизаций можно сказать еще многое, эта статья обеспечивает прочную основу. Важно отметить, что методы факторизации могут снизить потребность в явно определенных торговых правилах, позволяя системе изучать оптимальные стратегии непосредственно из данных.
Поистине замечательно, как много мы можем получить, интегрируя матричный API MQL5 в наши повседневные торговые рабочие процессы.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18873
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования