
Нейросети в трейдинге: От трансформеров к спайковым нейронам (Окончание)

Введение
Финансовые рынки можно сравнить с огромным океаном, где волны поднимаются и опускаются каждую секунду. Иногда море спокойно и предсказуемо, иногда оно бурлит и угрожает перевернуть корабль, а порой играет обманчивой гладью, скрывая под поверхностью мощные течения. Трейдер в этом океане подобен шкиперу, который должен различать не каждую рябь на воде, а именно тот порыв ветра, что способен задать верное направление движению. Ошибка в восприятии или неверное толкование сигналов — и судно пойдёт ко дну. В этой метафоре заключена вся суть поиска эффективных аналитических инструментов. Важно не количество информации, а её качество, способность извлечь смысл из хаоса.
Именно здесь фреймворк SpikingBrain открывает новые горизонты. Он основан на принципах событийной обработки. Система реагирует не на непрерывный поток данных, а лишь на те импульсы, которые несут в себе подлинный смысл. Для трейдера это означает одно: модель не тонет в море рыночного шума, а учится улавливать подлинные сигналы, способные изменить ход торгов.
Для практики финансовых рынков это даёт целый ряд преимуществ. Во-первых, сокращаются вычислительные затраты, что особенно важно при работе с высокочастотными данными. Модель становится легче, быстрее, и её можно без труда интегрировать в торговые платформы, не опасаясь чрезмерной нагрузки на систему. Во-вторых, возрастает устойчивость к шуму, что позволяет получать более чистые торговые сигналы и уменьшать вероятность ложных входов. И наконец, в-третьих, SpikingBrain делает возможным адаптивное реагирование — способность модели быстро перестраиваться в условиях, когда рынок неожиданно меняет направление.
Фреймворк SpikingBrain интересен не только своей философией событийного восприятия, но и архитектурой, которая делает эту философию рабочим инструментом. В её основе лежит идея представления потока данных, которую можно представить в виде серии дискретных импульсов — своеобразных спайков. Каждый такой импульс появляется не постоянно, а только при возникновении события, которое нарушает предыдущее равновесие. Это позволяет перейти от непрерывного анализа к работе с компактными, но насыщенными информацией точками.
Архитектура SpikingBrain складывается из нескольких ключевых модулей, каждый из которых отвечает за свою грань восприятия рынка. Первое, что бросается в глаза, — это спайковые нейроны с адаптивным порогом. Они реагируют только на события, выходящие за рамки привычного. Порог активации динамически меняется в зависимости от того, как ведут себя данные, благодаря чему модель становится более чувствительной или, напротив, отсекает мелкие колебания.
Второй фундаментальный элемент — модуль внимания. Классические трансформеры славятся своей способностью работать с контекстом. Но эта сила стоит дорого. Чем длиннее последовательность, тем тяжелее расчёты. SpikingBrain решает эту задачу иначе. Он использует линейное внимание и стратегию скользящего окна. А в более сложных версиях — гибридный подход, где разные типы внимания работают сообща. Это позволяет модели обрабатывать длинные ряды цен и объёмов без чудовищных затрат, не теряя при этом способности видеть общую картину.
Особое место занимает механизм смеси экспертов. В версии с расширенной архитектурой не все блоки модели работают одновременно. Активируются только нужные в конкретной ситуации. По сути, это отражает стратегию самого трейдера, который в будни ведёт размеренную торговлю, а во время сильных движений действует с особой концентрацией.
Но пожалуй, самое элегантное решение SpikingBrain — это система кодирования событий в виде спайков. Исходные данные преобразуются в серию импульсов, где каждая вспышка отражает не просто факт изменения цены, а его значимость. Частота и интенсивность спайков становятся своеобразным языком, с помощью которого модель описывает рынок. Если движение слабое — сигнал редкий и тихий. Если рынок взрывается — спайки превращаются в громкий звон колоколов, и система отвечает мгновенно.
Следовательно, SpikingBrain — это не просто набор математических трюков, а попытка построить модель, которая мыслит событиями. Она умеет слушать рынок. И именно поэтому её архитектура заслуживает внимательного изучения, особенно в контексте применения на финансовых рынках.
Авторская визуализация фреймворка SpikingBrain представлена ниже.

Каждая архитектура в науке и технике остаётся лишь схемой на бумаге, пока её линии и блоки не оживают в конкретной реализации. Именно поэтому наш разговор о SpikingBrain мы строим последовательно. Шаг за шагом, чтобы идеи не повисали в воздухе, а превращались в живые инструменты анализа. Архитектура, о которой мы говорили выше, задаёт направление, очерчивает каркас. Но любая конструкция обретает смысл только тогда, когда её детали становятся частью практической работы, а теоретические модули — частью кода, реагирующего на рыночный поток.
Наш путь начался с первого знакомства с SpikingBrain. Вначале мы рассмотрели замыслы авторов фреймворка и постарались объяснить их сквозь призму финансовых рынков. Там, где исходный текст исследователей звучал академично, мы искали прикладной смысл. По сути, это была подготовка почвы. Мы очертили перспективу и показали, что SpikingBrain имеет потенциал выйти за пределы чистой теории.
Затем мы показали, как идеи событийной логики можно перевести в код, и сделали важный шаг — научили модель превращать непрерывный поток чисел в дискретные спайки. Здесь ключевым элементом стало преобразование сигнала через порог. Нейрон молчит, пока значение не достигает критической отметки, и только тогда даёт короткий импульс. Такой приём сразу отделил шум от действительно значимых изменений и позволил взглянуть на котировки под другим углом. Но чтобы этот механизм не превратился в тупик, мы добавили возможность обучения — сделали пороги адаптивными и обеспечили прохождение градиентов даже через молчащие нейроны. В результате сеть получила способность со временем подстраиваться под рынок, а не застывать в статичной форме.
Однако мы пошли дальше и развернули эти идеи в полноценную архитектуру. На первый план вышли основные компоненты, которые должны держать систему в рабочем состоянии. Мы встроили спайковые преобразования в привычную структуру слоёв, показали, как они могут соседствовать со свёрточными блоками и другими классическими элементами нейросети. Практическая реализация в MQL5 потребовала внимательного подхода к памяти и вычислительным ресурсам. Нейроны не должны работать одновременно, иначе теряется сама суть событийного подхода. Поэтому мы предусмотрели механизм, при котором значительная часть нейронов остаётся в тишине, а вычислительные мощности сосредоточены там, где действительно происходит движение. По сути, мы выстроили основу для того, чтобы SpikingBrain мог органично вписаться в торговую экосистему, не разрушая привычную архитектуру, но обогащая её новым, событийным измерением.
Модуль разреженного внимания
Продолжаем наш путь от общей философии событийности к конкретной реализации предложенной архитектуры. Спускаемся с высоты схем прямо на палубу корабля — в код и исполнительную логику. Ранее мы объяснили, почему SpikingBrain видит рынок как цепочку значимых эпизодов и показали первые практические шаги по переводу непрерывных активаций в спайки. Теперь встает естественный вопрос: как эта событийная логика должна вести себя там, где традиционно действуют локальные окна внимания? Какие изменения потребуются, чтобы локальное внимание работало в духе спайков и выдерживало натиск рыночного шума?
Авторы фреймворка предлагают смещаемое окно, но рынок капризен. Расстояние между важными вспышками динамично, а шум заполняет окна обычно плотнее, чем хотелось бы, поэтому мы выбираем иной путь — сохраняем разреженную логику внимания на основе графонов. Но строим её так, чтобы она уважала саму суть спайков — асинхронность, адаптивность порогов и информационную ценность молчания нейрона. Речь идёт о реплике модуля CNeuronSparseGraphAttention, которая не просто копирует старую реализацию, а становится её эволюцией. CNeuronSpikeSparseAttention — наш настороженный страж внимания, приспособленный к ритму рынка и к языку спайков.
class CNeuronSpikeSparseAttention : public CNeuronSpikeConv { protected: CNeuronConvOCL cValue; CNeuronGraphons cGraphs; CNeuronSparseSoftMax cScores; CNeuronBaseOCL cAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeSparseAttention(void) {}; ~CNeuronSpikeSparseAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint experts, float dropout, uint emb_dimension, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeSparseAttention; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
Прежде всего стоит отметить, что новый объект наследуется от CNeuronSpikeConv — нашего механизма преобразования непрерывного сигнала в спайки. Это уже многое говорит о назначении класса. Он не придумывает спайки заново, он продолжает их грамотно обрабатывать. Наследование гарантирует, что базовая логика свёртки и первичного кодирования событий унаследована, а в потомке мы сосредотачиваемся исключительно на логике внимания в духе спайков.
При первом взгляде на тело класса бросается в глаза знакомый набор внутренних объектов: cValue, cGraphs, cScores, cAttention. Их названия привычны — но важно, что их меньше, чем в оригинальной реализации. Мы сознательно отказались от магистрали остаточных связей и от отдельного модуля FeedForward. Причина проста, она та же, что мы уже озвучивали при работе с линейным вниманием с гейтами: в событийной парадигме лишние пути размывают импульс и ведут к избыточным вычислениям. Вместо этого, остаточный путь и общий FFN находятся на уровне блока, там, где собираются результаты разных ветвей внимания, и где имеет смысл единожды согласовать и усилить сигнал.
Отмечу важный конструктивный момент. Все внутренние объекты объявлены статично, как члены класса. Это позволяет оставить конструктор и деструктор пустыми — инициализация переносится в отдельный метод Init.
bool CNeuronSpikeSparseAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint experts, float dropout, uint emb_dimension, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeConv::Init(numOutputs, myIndex, open_cl, window, window, window, units, 1, optimization_type, batch)) return false; activation = None;
Метод Init — это акт подготовки модуля к реальной работе на рынке. Сигнатура метода содержит всё, что нужно для управления размерностями и поведением разреженного внимания. Внутри метода сначала делегируем часть инициализации родительскому классу, чтобы сохранить совместимость с кодировщиком спайков.
Дальше идёт поочерёдная инициализация внутренних модулей. cValue первым берёт на себя функцию сбора локального представления — это свёртка, которая готовит значения V для последующего взвешивания.
int index = 0; if(!cValue.Init(0, index, OpenCL, window, window, window, units, 1, optimization, iBatch)) return false; cValue.SetActivationFunction(None);
Обратите внимание, мы сразу снимаем с cValue активацию. Причина практическая: спайковые представления уже несут в себе нелинейность и разреженность, и дополнительная точечная активация в затылке только смазывает импульс. Нам нужны сырые V-векторы, чтобы внимание могло правильно взвесить вклад каждого спайка.
Затем инициализируется смесь графонов cGraphs — это ядро нашей разреженности. Он изучает структуру данных, учитывая временные дистанции, объёмы и плотность спайков.
index++; if(!cGraphs.Init(0, index, OpenCL, units, window, emb_dimension, experts, dropout, optimization, iBatch)) return false;
cScores — это наш Sparse SoftMax. Он принимает структуру данных, предложенную графонами, и акцентирует внимание только на наиболее значимых соседях, создавая тем самым разреженность локального внимания. Такой подход снижает вычислительную сложность до уровня, близкого к оконному вниманию, но сохраняет гибкость — само окно здесь динамично и зависит от текущей активности и статистик спайков.
index++; if(!cScores.Init(0, index, OpenCL, units, units, sparse_dimension, optimization, iBatch)) return false;
cAttention аккумулирует итоговый результат α·V.
index++; if(!cAttention.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cAttention.SetActivationFunction(None); //--- return true; }
Практический смысл всех этих решений очевиден — мы заранее избавляемся от лишнего, потому что в спайковой логике это чаще мешает, чем помогает. Оставляем только те элементы, которые реально влияют на отбор импульсов. Организуем память так, чтобы OpenCL-ядро работало с компактными, сжатыми структурами. Это даёт выигрыш по латентности и по энергопотреблению — два критических показателя для торговли в реальном времени.
Спускаемся с уровня инициализации прямо к исполнению. Метод feedForward — это тот самый рабочий ритуал, где теория встречается с данными. Алгоритм прост по структуре и выразителен по смыслу. Ничего лишнего. Всё направлено на одно: полученный результат должен отражать важные спайк-импульсы, а не шум.
bool CNeuronSpikeSparseAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cValue.FeedForward(NeuronOCL)) return false;
Сначала вызывается метод прямого прохода объекта cValue. Это свёрточная ступень, которая собирает локальные признаки и формирует матрицу значений V. Здесь мы готовим то, что будет взвешено вниманием.
Далее осуществляется генерация graphon-масок, список соседей и их относительных весов. Маска отражает не статическое окно, а динамическое соседство, зависящее от времени, объёма и плотности спайков. На этом шаге мы решаем, с кем именно сравниваем анализируемую позицию.
if(!cGraphs.FeedForward(NeuronOCL)) return false; if(!cScores.FeedForward(cGraphs.AsObject())) return false;
cScores используется для получения разреженной матрицы весов внимания из сгенерированных графонов. Реально cScores выдаёт два ключевых артефакта: compact-indexes (neighbor lists) и массив весов для каждой пары позиция — сосед.
Ключевой вычислительный шаг — SparseMatMul. Эта функция умножает разреженную матрицу весов (scores) на плотную матрицу значений V. Результатом становится плотная матрица внимания с непрерывными значениями.
if(!SparseMatMul(cScores.GetIndexes(), cScores.getOutput(), cValue.getOutput(), cAttention.getOutput(), cScores.Heads(), cScores.DimensionOut(), cValue.GetUnits(), cValue.GetFilters())) return false; //--- return CNeuronSpikeConv::feedForward(cAttention.AsObject()); }
Завершает алгоритм прямого прохода вызов одноименного метода родительского класса. Это возврат в пространство спайков. Мы передаём агрегированный attention-вектор дальше в систему спайкового кодирования. Здесь будут применены механизмы порога, формирования спайков и подготовка выхода модуля к объединению на верхнем уровне блока внимания.
В целом, feedForward — это узел синхронизации между разрежённой логикой graphon и спайковым кодированием. Он аккуратно переводит динамический, локальный контекст в плотные представления внимания и возвращает их в мир спайков.
С алгоритмами обратного прохода я предлагаю ознакомиться самостоятельно. Все детали, включая полный код класса и реализации каждого метода, представлены во вложении.
Вариант смеси экспертов
После того как модули внимания реализованы, переходим к построению модуля смеси экспертов. Подобные конструкции нам уже встречались в предыдущих работах, но ни одна из них не была лишена компромиссов. Баланс между вычислительной эффективностью и выразительностью модели всегда оставался непростым. Философия спайковой архитектуры добавляет свои особенности — молчание нейронов, разреженность сигналов и динамическая активность экспертов делают задачу ещё более тонкой. Поэтому в рамках этой работы мы создаём новый объект, учитывающий эти реалии.
И снова на первый план выходит вопрос экономии вычислительных ресурсов и эффективной параллельной работы экспертов. Сложность усугубляется тем, что каждый элемент последовательности может задействовать свой набор экспертов. И обычный подход каждому эксперту свой вход быстро ведёт к дублированию вычислений.
Чтобы понять, как это обойти, взглянем на авторскую визуализацию блока MoE.
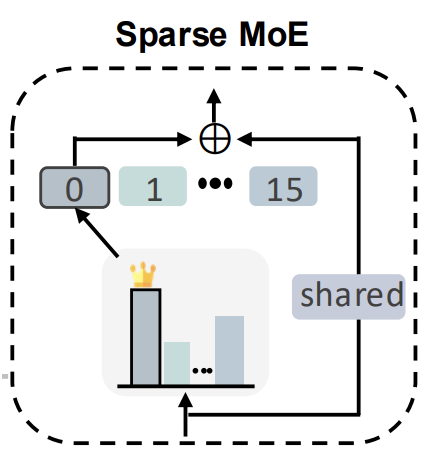
Результаты работы экспертов просто суммируются. И здесь открывается важная возможность оптимизации. На вход всех активных экспертов подаётся один и тот же набор данных. С математической точки зрения, это позволяет вынести вход за скобки и, вместо множества отдельных проекций, выполнить единственную линейную проекцию на сумму параметров экспертов. Такой трюк сохраняет корректность вычислений, но значительно снижает нагрузку на память и процессор, что особенно важно при работе с длинными временными рядами финансовых инструментов и высокой частотой обновления данных.
В результате мы получаем экономичный, но при этом выразительный MoE-модуль, который вписывается в философию спайковой архитектуры и готов к работе с параллельными потоками внимания и сигналов рынка.
Предложенный подход мы реализуем в виде нового класса CNeuronMoEConv. Это полноценный модуль, который аккуратно интегрируется в спайковую архитектуру и обеспечивает эффективное распределение нагрузки между экспертами. Класс наследуется от базового CNeuronBaseOCL, что позволяет ему работать в едином OpenCL-контексте с остальными слоями и легко взаимодействовать с другими модулями.
class CNeuronMoEConv : public CNeuronBaseOCL { protected: CLayer acProbability; CParams cExperts; CNeuronBaseOCL cWeightsConv; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMoEConv(void) {}; ~CNeuronMoEConv(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint experts, float dropout, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMoEConv; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
Внутри класса выделены несколько ключевых компонентов. acProbability отвечает за вероятностное распределение активности экспертов, задавая, какие из них будут участвовать в обработке каждого элемента последовательности. cExperts хранит параметры всех экспертов, которые в совокупности формируют богатый функциональный набор модели. cWeightsConv используется для формирования совокупности параметров активных экспертов. Здесь и реализуется идея вынесения входа за скобки, о которой говорилось ранее. Такой приём значительно снижает количество вычислений и сокращает использование памяти, не теряя при этом выразительности модели.
Инициализация нового объекта осуществляется в методе Init, который тщательно подготавливает все внутренние компоненты и гарантирует корректную работу слоя.
bool CNeuronMoEConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint experts, float dropout, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units * window_out, optimization_type, batch)) return false;
Сначала вызывается базовая инициализация родительского класса.
Далее поочерёдно создаются и настраиваются ключевые элементы модуля. В первую очередь формируется цепочка для расчёта вероятностей активации экспертов — acProbability.
//--- int index = 0; //--- CNeuronConvOCL *conv = NULL; CNeuronDropoutOCL *dout = NULL; CNeuronSparseSoftMax *softmax = NULL; //--- Probability acProbability.Clear(); acProbability.SetOpenCL(OpenCL); index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(experts, index, OpenCL, window, window, 2 * experts, units, 1, optimization, iBatch) || !acProbability.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(experts, index, OpenCL, 2 * experts, 2 * experts, experts, units, 1, optimization, iBatch) || !acProbability.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); index++; dout = new CNeuronDropoutOCL(); if(!dout || !dout.Init(0, index, OpenCL, conv.Neurons(), dropout, optimization, iBatch) || !acProbability.Add(dout)) { DeleteObj(dout); return false; } index++; softmax = new CNeuronSparseSoftMax; if(!softmax || !softmax.Init(0, index, OpenCL, units, experts, topK, optimization, iBatch) || !acProbability.Add(softmax)) { DeleteObj(softmax); return false; } softmax.SetHeads(units);
Здесь создаётся последовательность из двух свёрточных слоев с активацией SoftPlus между ними. Такая организация обеспечивает плавное и стабильное распределение значений, что особенно важно для работы с динамическими финансовыми сигналами, где резкие всплески и шум могут легко заглушить модель. Свёрточные слои формируют распределения актуальности экспертов для каждого элемента последовательности, оценивая, кто из экспертов наиболее релевантен в данный момент. Завершает цепочку объект разреженной функции SoftMax, который выбирает заданное число самых значимых экспертов и присваивает каждому коэффициент значимости, позволяя модели концентрироваться на действительно важных сигналах рынка, игнорируя шум и малозначимые паттерны.
Добавление Dropout перед SoftMax регулирует случайное выключение элементов, предотвращая переобучение и повышая устойчивость модели к шуму рынка.
Параллельно инициализируются объект cExperts, который хранит параметры всех экспертов, объединяя их в единое пространство.
index++; if(!cExperts.Init(0, index, OpenCL, window * window_out * experts, optimization, iBatch)) return false; index++; if(!cWeightsConv.Init(0, index, OpenCL, window * window_out * units, optimization, iBatch)) return false; //--- return true; }
А cWeightsConv выполняет функцию сводного набора параметров активных экспертов.
Каждый шаг инициализации внутренних компонентов сопровождается проверкой успешности выполнения операций. При неудаче объект удаляется, и метод возвращает false. Это обеспечивает надёжность и предсказуемость работы слоя, даже при сложных комбинациях параметров.
Метод feedForward — это основной рабочий цикл, где теория смеси экспертов превращается в конкретные вычисления.
bool CNeuronMoEConv::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* current = NULL; CNeuronConvOCL *conv = NULL; CNeuronSparseSoftMax *softmax = NULL; //--- Probability for(int i = 0; i < acProbability.Total(); i++) { current = acProbability[i]; if(!current || !current.FeedForward(prev)) return false; prev = current; } conv = acProbability[0]; softmax = prev;
Сначала прогоняются все слои цепочки вероятностей acProbability. Каждый свёрточный слой и слой разреженной SoftMax последовательно обрабатывают исходный сигнал, формируя распределение актуальности экспертов для каждого элемента последовательности. При этом проверяется корректность выполнения каждого шага. Если какой-либо слой не смог обработать вход, метод аккуратно возвращает false, что гарантирует устойчивость работы.
Далее происходит работа с экспертами. В режиме обучения (bTrain==true) вызывается метод прямого прохода объекта cExperts, формируя параметры всех экспертов. В процессе эксплуатации параметры экспертов статичны, и данный шаг пропускается, снижая вычислительную сложность модели.
//--- Experts if(bTrain) if(!cExperts.FeedForward()) return false;
Следующий ключевой шаг — генерация смеси параметров с помощью SparseMatMul. Разреженная матричная операция аккуратно комбинирует выбранные активные эксперты (top-K) с их параметрами, создавая итоговую матрицу весов cWeightsConv. Такой подход позволяет экономить вычислительные ресурсы, одновременно учитывая динамическую активность экспертов и разреженность данных — критически важный момент при анализе финансовых временных рядов с шумными и редкими сигналами.
uint units = conv.GetUnits(); uint window_in = conv.GetWindow(); uint window_out = Neurons() / units; uint topK = softmax.DimensionOut(); uint experts = cExperts.Neurons() / (window_in * window_out); //--- Generate Weights if(!SparseMatMul(softmax.GetIndexes(), softmax.getOutput(), cExperts.getOutput(), cWeightsConv.getOutput(), units, topK, window_in * window_out, experts)) return false;
Наконец, результирующая матрица весов применяется к исходным данным методом MatMul, формируя выход слоя.
//--- Result if(!MatMul(NeuronOCL.getOutput(), cWeightsConv.getOutput(), Output, 1, window_in, window_out, units, true)) return false; if(activation != None) if(!Activation(Output, Output, activation)) return false; //--- return true; }
Если задана функция активации, она применяется к выходу, добавляя нелинейность и стабилизируя распределение сигналов.
Таким образом, метод feedForward аккуратно соединяет три уровня логики: формирование вероятностей экспертов, выбор активных участников и их агрегированное влияние на выходной сигнал. Всё это обеспечивает гибкую, экономичную и адаптивную обработку временных рядов, что особенно важно для анализа финансовых рынков с их высокой динамикой и шумностью.
В результате мы получаем модуль MoE, который не только экономит ресурсы, но и сохраняет гибкость распределения внимания на уровне экспертов, позволяя каждому элементу временного ряда активировать свой уникальный набор экспертов.
С алгоритмами методов обратного прохода предлагается ознакомиться самостоятельно, чтобы получить полное понимание работы слоя и его взаимодействия с другими компонентами модели. Весь код класса и реализация каждого метода представлены во вложении, что позволяет изучить их детально и по шагам.
Объект верхнего уровня
После того как мы детально разобрали работу отдельных компонентов фреймворка, настало время перейти на следующий уровень и объединить всё это в единый объект верхнего уровня — CNeuronSpikingBrain. Этот класс реализует синхронизацию и взаимодействие нескольких ключевых модулей: параллельной работы двух алгоритмов внимания, последующей обработки результатов смесью экспертов, а также интеграцию residual-связей. Такой подход позволяет объединить локальные и глобальные контексты, учитывая динамическую активность спайков и разреженность сигналов, что особенно важно для анализа финансовых временных рядов с высокой волатильностью.
Реализованный нами объект верхнего уровня не ограничивается строгими рамками авторского фреймворка, а опирается на более широкое контекстуальное решение. Мы используем разрежённое внимание не просто как механизм локального анализа, а как инструмент выявления наиболее значимых временных шагов в контексте всей анализируемой последовательности. Это позволяет сфокусироваться на тех моментах, где действительно происходят изменения, способные повлиять на рыночное поведение.
В то же время, модули линейного внимания, которые изначально ориентированы на глобальную агрегацию признаков, мы применяем для независимого анализа динамики отдельных унитарных последовательностей. Такой подход даёт возможность построить баланс между глубиной локальной выборки и широтой глобального охвата. Локальные механизмы выделяют значимые импульсы, а линейные механизмы собирают целостную картину динамики. В совокупности это формирует более устойчивое представление данных и усиливает способность модели противостоять шуму, присущему финансовым временным рядам.
class CNeuronSpikingBrain : public CNeuronBaseOCL { protected: CNeuronSpikeSparseAttention cTimeAttention; CLayer caSpatialAttention; CNeuronBaseOCL cResidual; CLayer caFFN; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikingBrain(void) {}; ~CNeuronSpikingBrain(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint experts, float dropout, uint emb_dimension, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikingBrain; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
Внутри класса выделены несколько центральных объектов:
- cTimeAttention реализует локальное разрежённое внимание во временной области, акцентируя сигнал только на значимых моментах последовательности;
- caSpatialAttention обеспечивает независимый анализ унитарных последовательностей, формируя параллельное представление контекста;
- cResidual аккуратно суммирует выходы обоих модулей внимания, обеспечивая стабильность и предотвращая деградацию сигналов при объединении результатов;
- caFFN выполняет пост-обработку смесью экспертов, усиливая выражение наиболее значимых признаков и позволяя подготовить вход для последующего модуля.
Инициализация объекта осуществляется в методе Init, который фактически является его сердцем. Здесь последовательно собираем все ключевые компоненты и задаём архитектуру верхнего уровня.
bool CNeuronSpikingBrain::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint experts, float dropout, uint emb_dimension, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units, optimization_type, batch)) return false; activation = None;
Сначала вызывается инициализация родительского класса, в которой фиксируются размеры пространства результатов и тип оптимизации. На этом этапе задаётся нейтральная активация, так как итоговое преобразование будет формироваться более сложной комбинацией модулей.
Далее конфигурируем модуль временного внимания cTimeAttention, построенный на основе спайковой разрежённой архитектуры. Его задача — выделять наиболее значимые временные шаги в последовательности, что напрямую отвечает специфике анализа рыночных сигналов, где важен не каждый тик, а лишь ключевые моменты динамики.
int index = 0; if(!cTimeAttention.Init(0, index, OpenCL, units, window, experts, dropout, emb_dimension, sparse_dimension, optimization, iBatch)) return false;
Следующим блоком идёт пространственное внимание caSpatialAttention, где используется пара объектов транспонирования данных и модуль линейного внимания CNeuronGateLineAttention.
CNeuronTransposeOCL* transp = NULL; CNeuronGateLineAttention* line_att = NULL; caSpatialAttention.Clear(); caSpatialAttention.SetOpenCL(OpenCL); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units, window, optimization, iBatch) || !caSpatialAttention.Add(transp)) { DeleteObj(transp) return false; } index++; line_att = new CNeuronGateLineAttention(); if(!line_att || !line_att.Init(0, index, OpenCL, window, units, emb_dimension, experts, optimization, iBatch) || !caSpatialAttention.Add(line_att)) { DeleteObj(line_att) return false; } index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, window, units, optimization, iBatch) || !caSpatialAttention.Add(transp)) { DeleteObj(transp) return false; }
Такая комбинация позволяет проанализировать зависимости между признаками в разных проекциях, сохраняя баланс между скоростью вычислений и полнотой учёта глобального контекста. Слои добавляются в контейнер поочерёдно, что обеспечивает гибкость и возможность расширения архитектуры.
Затем в схему включается объект cResidual, выполняющий роль стабилизатора. Он аккумулирует результаты параллельных блоков внимания и обеспечивает корректную передачу сигналов дальше, без потери информации и деградации градиентов.
index++; if(!cResidual.Init(0, index, OpenCL, window * units, optimization, iBatch)) return false; cResidual.SetActivationFunction(None);
Особое внимание уделено построению блока caFFN, где реализуется комбинация слоя смеси экспертов (CNeuronMoEConv) и преобразования спайков через CNeuronSpikeConv. Первым создаётся MoE-модуль, который динамически распределяет нагрузку между несколькими экспертами, сохраняя вычислительную эффективность за счёт разрежённой SoftMax.
CNeuronSpikeConv* conv = NULL; CNeuronMoEConv* moe = NULL; caFFN.Clear(); caFFN.SetOpenCL(OpenCL); index++; moe = new CNeuronMoEConv(); if(!moe || !moe.Init(0, index, OpenCL, units, window, 2 * window, experts, dropout, sparse_dimension, optimization, iBatch) || !caFFN.Add(moe)) { DeleteObj(moe) return false; } moe.SetActivationFunction(SoftPlus);
Затем добавляется свёрточный слой преобразования, обеспечивающий финальную обработку последовательности. Важно, что между слоями в качестве функции активации используется SoftPlus, которая сглаживает динамику и хорошо подходит для анализа нестабильных финансовых сигналов.
index++; conv = new CNeuronSpikeConv(); if(!conv || !conv.Init(0, index, OpenCL, 2 * window, 2 * window, window, units, 1, optimization, iBatch) || !caFFN.Add(conv)) { DeleteObj(conv) return false; } if(!Clear()) return false; //--- return true; }
Завершается процесс вызовом метода Clear, что гарантирует корректную инициализацию состояния всех внутренних объектов перед началом работы.
В итоге, метод Init аккуратно собирает воедино все компоненты, создавая из них единую структуру. Здесь чётко прослеживается идея параллельной работы локальных и глобальных механизмов внимания с последующей интеграцией и фильтрацией через MoE-блок.
Метод feedForward, реализованный в классе CNeuronSpikingBrain, играет ключевую роль в формировании целостного вычислительного цикла фреймворка. Представим, что перед нами аналитик, задача которого собрать факты о рынке и превратить их в стройный прогноз. Первым делом он обращает внимание на временное внимание — это словно взгляд на динамику цен за последние часы. Он выделяет ключевые временные шаги: резкие скачки, периоды консолидации, важные отчёты. Всё это фиксируется как набор вех, на которых может строиться дальнейший анализ.
bool CNeuronSpikingBrain::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* current = NULL; //--- if(!cTimeAttention.FeedForward(prev)) return false;
Затем аналитик переходит к пространственному вниманию. Это похоже на распределение событий по секторам или активам. Подобные взаимосвязи не всегда лежат на поверхности, но именно они формируют глобальный контекст, который аналитик должен удерживать.
for(int i = 0; i < caSpatialAttention.Total(); i++) { current = caSpatialAttention[i]; if(!current || !current.FeedForward(prev)) return false; prev = current; }
Чтобы не потеряться в массе сигналов, аналитик применяет механизм остаточной связи. Это способность вернуться к базовым фактам и сопоставить их с новыми выводами. Как опытный эксперт, он всегда сверяет свежие наблюдения с тем, что уже известно, сохраняя здравый баланс между старым знанием и новой информацией.
if(!SumAndNormilize(prev.getOutput(), cTimeAttention.getOutput(), cResidual.getOutput(), cTimeAttention.GetFilters(), false, 0, 0, 0, 1) || !SumAndNormilize(cResidual.getOutput(), NeuronOCL.getOutput(), cResidual.getOutput(), cTimeAttention.GetFilters(), true, 0, 0, 0, 1)) return false;
Финальная стадия — это работа экспертов. Здесь вступает в игру блок Mixture of Experts, который напоминает команду аналитиков разного профиля: один специализируется на технике, другой — на макроэкономике, третий — на потоках капитала. В зависимости от рыночной ситуации система выбирает, чьё мнение весомее в данный момент, и агрегирует их решения. Спайковая свёртка выступает как метод выделения локальных паттернов — технический аналитик, изучающий графики до мельчайших деталей.
prev = cResidual.AsObject(); for(int i = 0; i < caFFN.Total(); i++) { current = caFFN[i]; if(!current || !current.FeedForward(prev)) return false; prev = current; } if(!SumAndNormilize(cResidual.getOutput(), prev.getOutput(), Output, cTimeAttention.GetFilters(), true, 0, 0, 0, 1)) return false; //--- return true; }
Метод feedForward — это не просто алгоритм прямого прохода, а тщательно выстроенная работа аналитического штаба. Он начинает с фиксации ключевых событий, затем углубляется в связи между активами, сопоставляет новые данные с прежними результатами и завершает анализ синтезом экспертных мнений. На выходе формируется стройный прогноз, отражающий как глобальный фон, так и локальные сигналы рынка.
В результате CNeuronSpikingBrain становится мощным объединяющим модулем, способным одновременно учитывать временной и пространственный контексты, адаптироваться к динамическим сигналам рынка и эффективно распределять активность между экспертами. Это делает его центральным компонентом нашей спайковой архитектуры для анализа финансовых данных, обеспечивая гибкость, вычислительную эффективность и устойчивость к шуму. С полным кодом данного класса и всех его методов можно ознакомиться во вложении.
Архитектура моделей
Теперь, когда отдельные модули готовы, пора собрать из них реальные модели: Энкодер состояния окружающей среды, Актера и Критика.
Мы начинаем с Энкодера — это часть, которая читает историю инструмента и переводит её в компактное, многоуровневое представление. Первым идёт базовый слой, содержащий HistoryBars * BarDescr значений. Каждая полоса — это набор признаков свечи. Сырые данные, без акцентов.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее ставим нормализацию с шумовой регуляризацией — BatchNormWithNoise. Такой слой не даёт данным закиснуть. Он выравнивает шкалы и добавляет лёгкий стохастический шум в тренировке, что полезно при плавающей волатильности рынков.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем идёт шаг агрегации ConcatDiff. Мы берём данные и добавляем к ним последовательность разниц — это классический приём, который подчёркивает движение, а не абсолютные уровни.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } uint prev_out = descr.layers * 2 ;
Дальше следует Mamba4CastEmbedding — специфический слой, который строит мультипериодные эмбеддинги. Здесь явно учитываем разные таймфреймы, чтобы дать модели широкий исторический контекст, не теряя локальной чувствительности.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = prev_out; prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_D1), PeriodSeconds(PERIOD_MN1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Ключевая ступень — наш спайковый блок NeuronSpikingBrain. Мы вставляем его AttentionLayers раз — это стек, где локальное разрежённое временное внимание соседствует с линейным/гейтированным пространственным вниманием и потом агрегируется через общий residual и MoE-FFN.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikingBrain; descr.count = prev_count; descr.window = prev_out; descr.variables = NExperts; // Experts descr.window_out = EmbeddingSize; // Inside Dimension descr.step = TopK; // Top-K descr.probability = 0.3f; descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; for(int i = 0; i < AttentionLayers; i++) if(!encoder.Add(descr)) { delete descr; return false; } uint window = descr.window; uint count = prev_count;
После слоя внимания мы сжимаем представление до исходного пространства признаков и заданного горизонта планирования.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count; //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Заканчивает Энкодер RevInDenorm, который раскладывает предсказания обратно в исходные шкалы и возвращает значения к виду, удобному для трейдинга.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Результаты работы Энкодера состояния окружающей среды служат исходными данными для моделей Актера и Критика, которые отвечают за формирование торговых решений и их последующую оценку. Архитектура этих моделей в целом опирается на наработки из предыдущих исследований, однако в неё внесены существенные штрихи — элементы спайковых решений, позволяющие повысить адаптивность и чувствительность системы к рыночной динамике. Эти изменения создают более гибкий механизм принятия решений, где классическая структура обогащена дополнительными слоями нейронной обработки. Для тех, кто хочет глубже разобраться в технических деталях, мы предлагаем ознакомиться с полным кодом архитектуры моделей, приведённым во вложении.
Тестирование
Прежде чем доверить модели реальные средства, мы тщательно проверяем стратегию на исторических данных, словно тренируя навыки оценки риска и принятия решений в самых разных рыночных условиях. Каждый этап имитировал живой рынок, позволяя модели постепенно нарабатывать опыт и вырабатывать устойчивые алгоритмы поведения.
Первый этап — офлайн-обучение — проходил на исторических данных по валютной паре EURUSD с таймфреймом H1 за период с Января 2024 по Июнь 2025 года. Этот временной отрезок стал настоящей тренировочной площадкой. Модель училась воспроизводить исторические паттерны, понимать динамику рынка, выявлять закономерности в движении цен и объёме сделок, адаптируясь к изменчивости рынка. Можно сказать, что она развивала интуицию трейдера, совмещённую с точной стратегической оценкой.
Следующий этап — онлайн-настройка в тестере стратегий MetaTrader 5 — позволил модели работать с потоками данных в реальном времени, свеча за свечой. Здесь она осваивала динамику реального рынка, училась сохранять стабильность на фоне шума, корректировать действия при низкой ликвидности и мгновенно реагировать на резкие ценовые всплески. Этот этап стал доводкой стратегии: базовая структура, сформированная на исторических данных, оставалась неизменной, но модель училась гибко адаптироваться к текущей рыночной обстановке, минимизируя риск переобучения и повышая точность прогнозов в непредсказуемой среде.
Финальная проверка проводилась на данных за Июль–Август 2025 года — полностью новых и ранее не использованных. Все параметры, полученные на предыдущих этапах, загружались без изменений, что обеспечивало честную оценку способности модели к обобщению и проверке её устойчивости к новым рыночным ситуациям. Результаты тестирования представлены ниже, демонстрируя эффективность пошагового подхода к обучению и адаптации модели к реальным условиям финансового рынка.
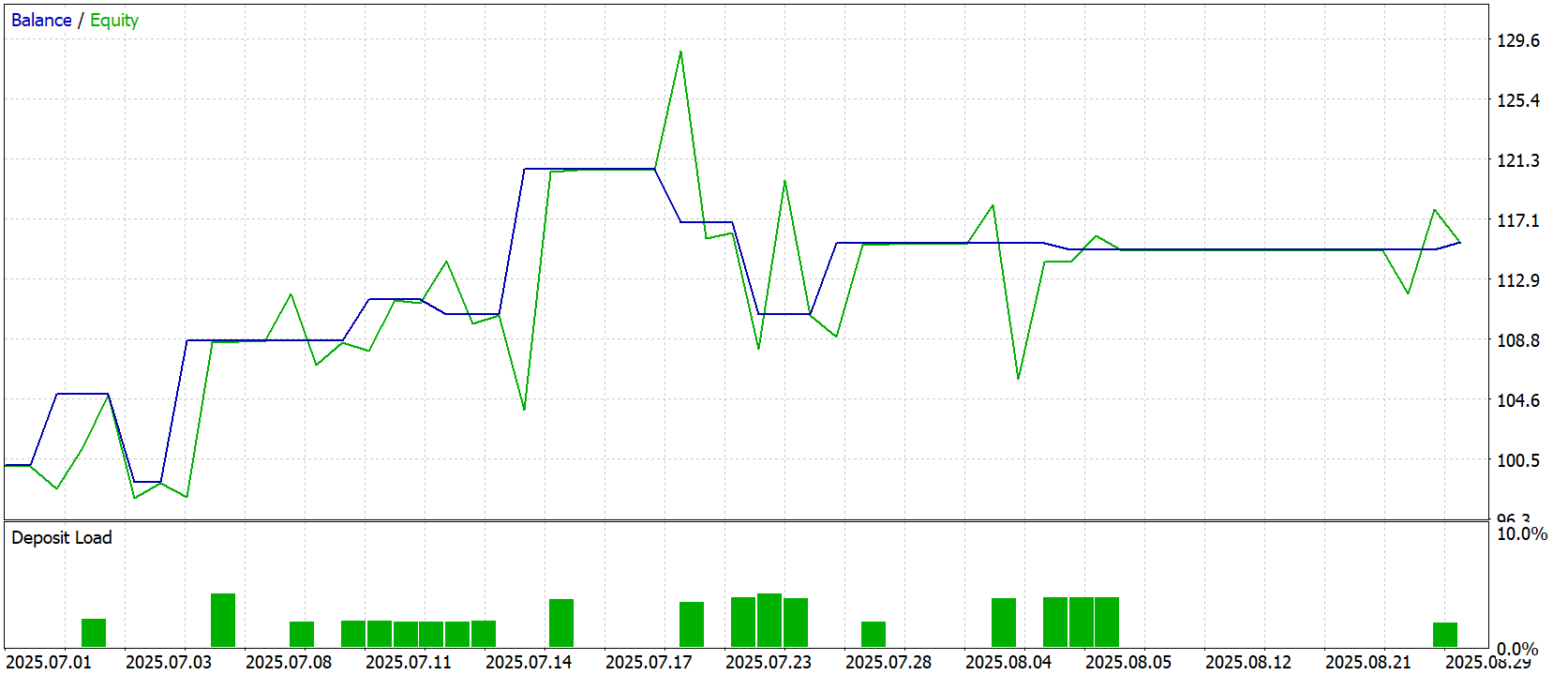
Результаты тестирования демонстрируют эффективность модели на ранее неиспользованных данных. График баланса и эквити показывает плавное, управляемое увеличение капитала. При этом баланс демонстрирует относительно стабильную траекторию, а эквити отражает краткосрочные колебания, характерные для реальной рыночной среды. Наблюдаются отдельные всплески и коррекции, что говорит о способности модели адаптироваться к неожиданным рыночным событиям, сохраняя общий положительный тренд.
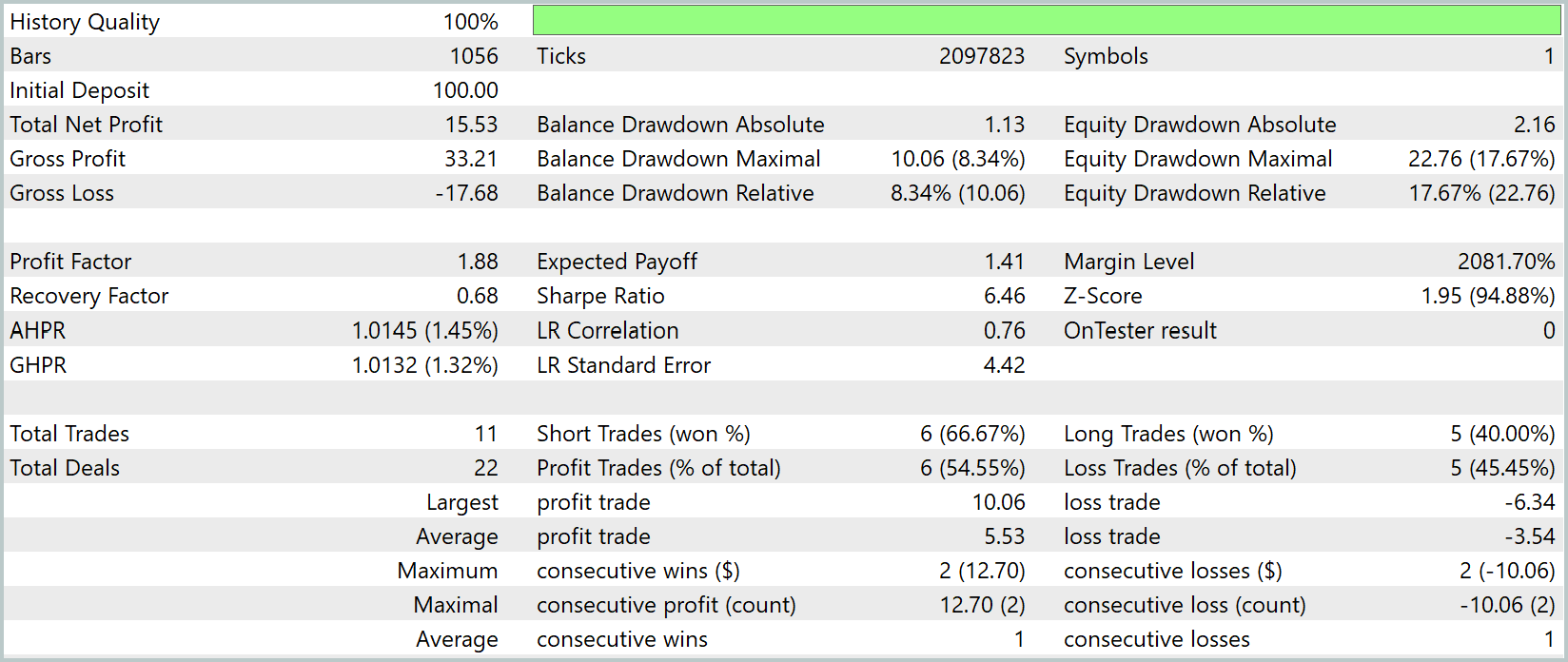
Статистические показатели подкрепляют визуальное впечатление. Общая прибыль составила 15,53 USD при исходном депозите 100 USD, что соответствует умеренной доходности с контролируемым риском. Максимальная просадка по эквити достигла 22,76% — относительно значимо, но в пределах допустимого для тестовой стратегии уровня риска. Коэффициент прибыли (Profit Factor) составляет 1,88, подтверждая преобладание прибыльных сделок над убыточными.
Модель совершила всего 11 торговых операций (22 сделки), из которых 54,55% оказались прибыльными. Средняя прибыль на сделку составила 5,53 USD, а средний убыток — 3,54 USD, что демонстрирует разумное соотношение прибыль/риск. Максимальная прибыльная серия составила 2 сделки на 12,70 USD, а максимальная убыточная серия — 2 сделки на -10,06 USD. Эти показатели подтверждают, что модель способна удерживать баланс между агрессивностью и стабильностью, не подвергая капитал чрезмерному риску.
В целом, результаты тестирования показывают, что модель успешно интегрирует подходы SpikingBrain, способна обрабатывать динамические финансовые сигналы и принимать управляемые решения в условиях реального рынка, сохраняя стабильность и управляемую доходность.
Заключение
Эволюция нейросетевых архитектур до спайковых моделей открывает новые горизонты для трейдинга. Если трансформеры доказали свою эффективность в анализе больших массивов рыночных данных и генерации устойчивых сигналов, то спайковые нейроны приближают нас к более биологически правдоподобным и энергоэффективным системам. Их способность работать с временными паттернами и шумными потоками информации делает их перспективными для высокочастотной торговли и адаптивных стратегий.
Однако ключевой вызов остаётся прежним: интеграция этих моделей в реальные торговые системы требует строгого тестирования, учёта рисков и понимания ограничений каждой архитектуры.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования