
От начального до среднего уровня: Приоритеты операторов

Введение
Представленные здесь материалы предназначены только для обучения. Ни в коем случае нельзя рассматривать это приложение как окончательное, цели которого будут иные, кроме изучения представленных концепций.
В предыдущей статье, "От начального до среднего уровня: Оператор FOR", мы рассказали об основах оператора FOR. Основываясь на данный материал, вплоть до предыдущей статьи, вы уже сможете создать неплохой объем кода на MQL5. Даже если это будут простые и относительно скромные приложения, это уже будет повод для гордости и наслаждения для многих.
Дело в том, что для других программистов небольшие фрагменты кода, созданные новичком, могут показаться тривиальными, но если этому новичку удается придумать решение проблемы, с которой он сталкивается, это на самом деле является предметом гордости. Не питая ложных надежд, скажу, что всё, что рассматривалось до настоящего момента, позволит вам создавать только скрипт-подобный код. Даже если это довольно просто и не требует особого взаимодействия, если вы добились этого собственными усилиями, значит, вы уже начали применять базовые знания и находитесь на правильном пути.
Пора немного сменить тему. Данная тема позволит нам создавать еще более интересные коды. Сегодня мы рассмотрим операторы. Хотя мы уже говорили о них раньше, сейчас мы продвинемся еще дальше, ведь то, что мы проходили раньше, было довольно простым и понятным. Здесь мы рассмотрим правила приоритета на практике, а также тернарный оператор, который может быть довольно запутанным для многих, но очень полезен во многих ситуациях, так как экономит нам труд и усилия при выполнении некоторых операций программирования.
Чтобы понять, о чем пойдет речь в этой статье, необходимо разобраться с объявлением и использованием переменных в MQL5-коде. Данный вопрос уже обсуждался в предыдущих статьях. Если вы об этом не знаете, мы рекомендуем вам сначала прочитать предыдущие статьи. Давайте теперь приступим к первой теме этой статьи.
Правила приоритета
Понимание и знание правил приоритета очень важно, я уже упоминал об этом в другой статье. Здесь мы немного углубимся в этот вопрос.
В документации при поиске правил приоритета и порядка операций, мы находим таблицу с ними. Однако многие люди не могут правильно понять их смысл или информацию, которую они содержат. Если это так, дорогой читатель, вам не стоит стыдиться или бояться, ведь это очень распространенное явление, и поначалу, столкнувшись с подобной информацией, мы, как правило, приходим в замешательство. Это происходит, потому что в школе мы изучаем материалы не так, как используем их здесь, в качестве программистов.
Хотя в некоторых случаях определенные факторизации, выполняемые некоторыми программистами, вызывают некоторое недоумение, они часто оказываются правильными. Даже если кажется, что они дают не тот результат, который ожидался. По этой причине важно понимать правила приоритета. Вам не нужно их учить наизусть. С практикой и постоянным использованием вы привыкнете к ним. Но самое главное:
Если вы не понимаете свой собственный код, то и другие не поймут.
По этой причине всегда старайтесь думать о том, как другие могут интерпретировать ваши разработки. Начнем со следующего факта: таблицу, упомянутую в начале этой темы, следует читать сверху вниз. Операторы, расположенные сверху, имеют более высокий приоритет выполнения. По мере продвижения вниз приоритет постепенно снижается.
Однако здесь есть небольшой момент на который стоит обратить внимание. Чтобы объяснить это, мы рассмотрим таблицу на рисунке ниже:
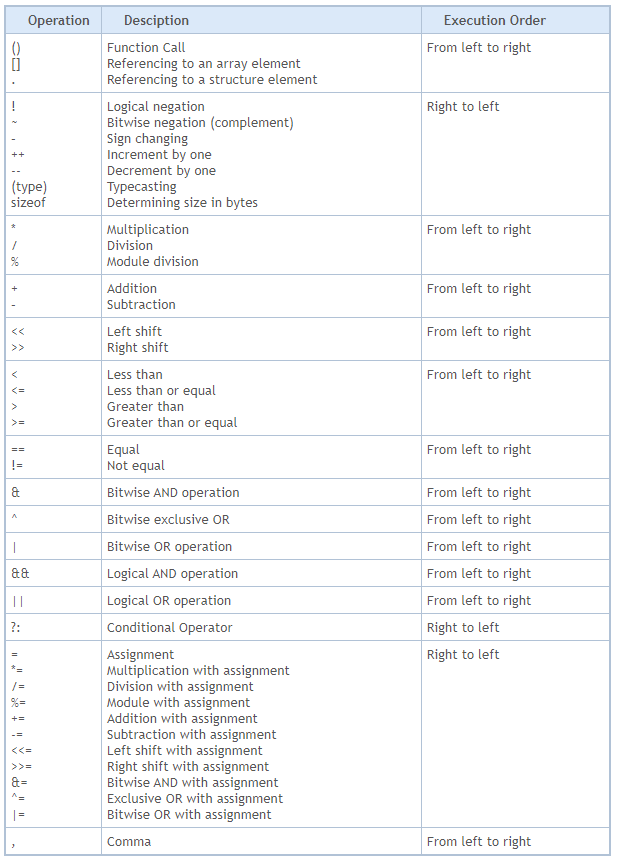
Рисунок 01
Здесь видно, что операторы объявляются в определенном порядке. Очень важно соблюдать данную последовательность. Также можно заметить, что они разделены на группы. И вот тут-то многие и запутались. А всё потому что, сталкиваясь с определенными кодами, мы не знаем, каким будет результат факторизации, если не понимаем этого разделения, показанного на рисунке 01. Подобное разделение очень легко понять и оно значительно упрощает работу, поскольку избавляет от необходимости запоминать правила приоритета. Во-первых, у нас есть операторы ссылки. Они имеют приоритет над всеми остальными, поскольку указывают нам, как получить доступ к определенному элементу. Далее идут бинарные операторы или операторы типов. В данном случае мы всегда должны читать код справа налево. Но почему так? Не волнуйтесь, мы дойдем до этого. Я объясню, как следует читать код в этих случаях. Обратите внимание, что это отличается от операторов ссылки, где код нужно читать слева направо.
Да, я знаю, это звучит безумно. Теперь можно остановиться и спросить себя: "Почему они всё так усложняют?" Но речь идет не о сложностях, дорогой читатель: на практике вы убедитесь, что в этом есть смысл. Не зная его применения, кажется, что мы попадаем в сумасшедший дом. Однако именно в третьем разделе мы начинаем говорить о том, что более привычно для многих. Это первые операторы арифметических функций, и в этом случае код нужно читать слева направо. Так продолжается до конца рисунка 01.
Сейчас мы рассмотрим практический пример. Для этого мы используем несколько довольно простых и понятных кодов, в которых мы просто выводим некоторые значения. Это самая простая и веселая часть.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(++value * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
Код 01
Теперь я вас спрашиваю: какой результат будет выведен на терминал? Не обращая внимания на приоритет операторов, можно сказать, что результат будет равен 46, поскольку мы умножаем переменную, значение которой равно девяти, на константу, равную пяти, а затем прибавляем одну единицу. Однако вы ОШИБАЕТЕСЬ. Результат выполнения данного кода 01 равен 50, как показано на следующем рисунке:
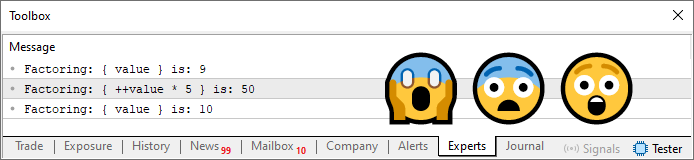
Рисунок 02
Вас это не смутило? Хорошо, а если провести еще один небольшой тест, просто изменяя небольшую деталь в коде? Можете увидеть это чуть ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(value++ * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
Код 02
Результат кода 02 показан ниже:
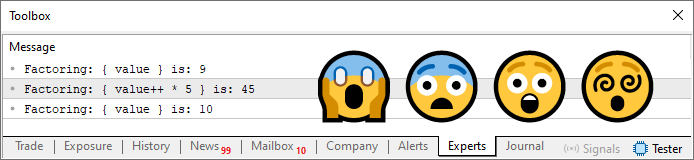
Рисунок 03
Разве я не говорил в предыдущей статье, что мы весело проведем время? Я мог бы еще долго играть с этими правилами приоритета и показать вам, что когда вы думаете, что всё понимаете и готовы к любым испытаниям, на самом деле вы только встали и пытались сделать свой первый шаг.
Я знаю, не надо говорить мне, что это звучит совершенно безумно, и что я, скорее всего, сумасшедший. Но поверьте, самое интересное только начинается. Всё станет еще лучше. Как насчет чего-нибудь поинтереснее? Мы можем начать с кода чуть ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 & 1 * v2); 14. PrintX((v1 & 1) * v2); 15. } 16. //+------------------------------------------------------------------+
Код 03
Отличный код. Он замечательный, особенно когда он работает внутри цикла. Ниже можно увидеть результат, который он выдает.
Рисунок 04
А теперь признайтесь: вам, как и мне, весело наблюдать за тем, как всё это происходит, не так ли? Обратите внимание, что разница между одним ответом и другим заключается именно в скобках, которые появляются в одном выражении и не появляются в другом.
На самом деле, существует общее правило написания факторизации данного типа. Хотя это и не явно, оно существует неявно среди программистов. Правило гласит:
При программировании факторизации нужно по возможности разделять условия на уровни выполнения и разграничивать каждый уровень круглыми скобками. Это облегчит другим программистам его интерпретацию.
На самом деле, даже если результат очевиден и подчиняется правилам приоритета операторов, если разделить элементы по уровням факторизации, будет гораздо проще понять, какой результат мы ожидаем получить. В некоторых случаях даже компилятор не может однозначно интерпретировать то, что мы попытались запрограммировать. Давайте рассмотрим один пример. Приведенный ниже код - пример ситуации, когда результат совершенно непредсказуем, поскольку даже компилятор не может понять, что нужно делать.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1++ & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
Код 04
В данном случае при попытке скомпилировать код 04 компилятор выдаст предупреждение, которое видно чуть ниже:

Рисунок 05
Обратите внимание: несмотря на предупреждение, компилятор сгенерировал код. Но существует значительная опасность того, что в некоторых ситуациях этот код может не дать ожидаемого результата. Поэтому слепо полагаться на данный код рискованно, особенно когда компилятор выдает предупреждение о возможном сбое факторизации. В таких случаях необходимо использовать круглые скобки. Однако, даже не делая этого и используя только правила приоритета, можно проверить, будет ли результат правильным в данном конкретном случае.
Для этого мы запускаем код и получаем следующий результат:
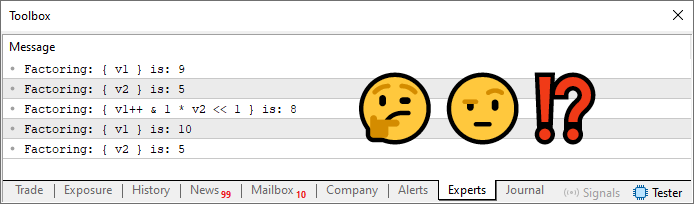
Рисунок 06
В этом случае ответом было значение восемь. Но действительно ли это значение правильное? Чтобы понять это, нам нужно вручную определить, что сделал код. Подобные ситуации довольно часто встречаются в программировании. Часто, вопреки мнению многих людей, программист не создает код без понимания того, какой результат он должен сгенерировать. Хороший программист ВСЕГДА знает, каким будет результат выполнения кода. НИКОГДА не создавайте код, если неуверены заранее в его результате. Другими словами, хороший программист проводит бэктест собственного кода, а затем форвардтест, где результаты анализируются один за другим. Только после полной батареи тестов он начинает доверять своему коду, но никогда не доверяет слепо всем ответам. В программисте всегда должен сохраняться определенный уровень сомнений. Причины скептического отношения к конкретному ответу рассмотрим в другой статье. А пока давайте посмотрим, должно ли значение восемь быть правильным ответом на код 04.
Чтобы определить правильность ответа, нужно понять, как компилятор интерпретировал то, что его попросили считать. Поскольку компилятор следует строгим правилам, определенным в таблице приоритета операторов, мы можем выполнить ручную факторизацию вычисления в строке 13 и проверить правильна ли она.
Для этого мы сначала определяем оператор с наивысшим приоритетом. В данном случае, это будет оператор ++, который применяется к переменной v1. Но этот оператор работает справа налево. То есть в данной ситуации его приоритет будет изменен и применен к переменной v1 только после выполнения самого правого оператора с наивысшим приоритетом. В нашем случае таким оператором является оператор умножения, который имеет приоритет перед оператором сдвига влево и оператором AND. Поэтому первой выполняемой операцией является умножение значения 1 на значение v2, в результате чего получаем значение пять. Затем мы применяем оператор сдвига влево, который сдвигает значение пять на один бит влево, генерируя новое значение, равное десяти. Затем выполняется операция AND между v1 и данным значением 10. Поскольку v1 равно девяти, то при применении операции AND результат равен восьми. Наконец, когда все операторы справа будут выполнены, значение v1 увеличится на единицу. Поэтому при факторизации мы получаем значение восемь, а по завершении факторизации - значение десять для v1.
Можно подумать: "Я понимаю, всё это очень просто и понятно". Но так ли это на самом деле? Вы действительно смогли понять, как работает данная процедура? Давайте посмотрим. Каким будет результат факторизации, выполненной в приведенном ниже коде?
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(++v1 & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
Код 05
Отвечайте без колебаний. Если вы действительно смогли ответить на этот вопрос правильно, наверное вы понимаете, как работает приоритет операторов. В любом случае, я покажу вам ответ ради веселья, и хочу, чтобы вы сказали, правильный он или нет.
Когда я запустил этот код, то получил такой ответ:
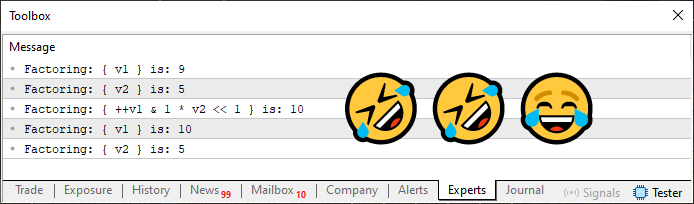
Рисунок 07
А теперь скажите мне: почему мой ответ - десять, а не восемь? На это есть конкретная причина, и она связана с правилом приоритета операторов. Поскольку я не люблю вводить людей в заблуждение, давайте посмотрим, почему ответы на эти вопросы отличаются. Но перед этим, нам стоит обратиться к новому вопросу. В этой статье я не хочу нагружать память читателя, поскольку есть еще один вопрос, который необходимо рассмотреть.
BackTest и ForwardTest
Первое, что нужно понять, это следующее: прежде чем что-то программировать, мы должны знать, каким будет ответ, который выдаст наш код. Программирование - это не генерация кода для получения неизвестного ответа, в программировании всё с точностью до наоборот. Мы создаем код, чтобы получить ответ, который нам уже известен. И в этом случае, как в коде 04, так и в коде 05, мы уже знали, каким будет ответ. Даже зная, что это может быть неправильно, именно из-за предупреждения компилятора. Но как я могу узнать ответ еще до написания кода? Это кажется бессмысленным. На самом деле многие люди говорят, что нужно программировать, чтобы узнать ответ, но, зная правила приоритета, можно предвидеть ответ до того, как он будет вам дан.
Чтобы прояснить ситуацию, давайте сделаем следующее: как уже говорилось в приложении, я предоставлю вам данные коды, чтобы вы могли сделать то же самое, что я покажу здесь. Таким образом, вы поймете, почему так важно знать ответ, прежде чем написать код, который даст вам этот ответ.
На самом деле вопрос заключается в следующем: Какой ответ правильный: рисунок 06 или рисунок 07? А что, если я скажу, что оба? Как бы вы ответили на это? Вы, наверное, подумаете, что я сумасшедший, ведь одно и то же выражение не может давать два правильных ответа. Но, как бы безумно это ни звучало, оба ответа верны. Однако гораздо более вероятно, что вы искали ответ на рисунке 07, в то время как ответ на рисунке 06 был бы просто побочным эффектом неправильного использования приоритета операторов. Если мы используем круглые скобки в коде 04, чтобы исправить приоритет операторов, то ответ, который выдаст код, будет точно таким, как показано на рисунке 07. Для этого не нужно ничего особенного: просто настроим всё так, чтобы у оператора инкремента был более высокий приоритет. В случае с кодом 05 тот факт, что оператор находится перед переменной, ставит его выше оператора умножения. Однако, как объяснялось в предыдущей теме, то, что он находится после переменной, как в коде 04, приводит к тому, что оператор будет выполнен позже.
Не верите? А если сделаем тест, чтобы проверить это? Давайте заменим строку 13 кода 04, чтобы она выглядела так, как показано ниже:
PrintX((v1++ & 1) * (v2 << 1));
И даже при таком изменении компилятор больше не будет указывать на неверность результата. Однако тот же самый код 04, прошедший через эту простую модификацию, даст нам ответ, показанный на рисунке 07. Именно это делает программирование таким сложным, часто люди изучают программирование по неправильным причинам. На самом деле, наша истинная цель - заставить компьютер быстрее дать нам известный ответ. Когда нам нужно узнать что-то, на что мы не знаем ответа, мы можем считать ответ компьютера подходящим. Однако даже у такого доверия есть предел. Но в этих пределах ответ, полученный после серии тестов, как с ранее известными значениями, так и с теми, которые мы умеем вычислять, позволяет нам окончательно утверждать: "МОЯ ПРОГРАММА МОЖЕТ РАССЧИТАТЬ ОДНО И ДРУГОЕ". До проведения всех этих тестов вероятность того, что наш код будет содержать ошибки именно потому что он не был должным образом протестирован, довольно велика.
Хорошо, на этом можно спокойно изучить код и поразмыслить над ним. Однако прежде чем завершить данную статью, я хотел бы затронуть еще один вопрос. Это еще один оператор, который не вписывается в ряд тех, что мы рассматривали до сих пор. Давайте перейдем к последнему вопросу.
Тернарный оператор
Сейчас поговорим о моем любимом операторе. Те, кто следят и изучают мои коды (их можно найти в различных статьях в этом сообществе) должно быть, устали видеть, как я использую этот оператор. Но почему он стал моим любимым? Всё просто: это позволяет мне создавать выражения без использования оператора IF. Во многих случаях нам необходимо использовать оператор IF для изменения потока выполнения кода. Однако есть ситуации, когда мы можем использовать тернарный оператор, даже если оператор IF не подходит. На мой взгляд, данный оператор относится к среднему уровню. Другими словами, чтобы в полной мере использовать преимущества тернарного оператора, необходимо хорошо владеть другими операторами. Кроме того, при его использовании необходимо хорошо понимать, как осуществится изменение потока, поскольку оно редко используется в одиночку. Оно почти всегда связано с оператором присваивания или логическим оператором. По этой причине я объясню лишь то, как его следует интерпретировать, на данный момент мы не будем его использовать, или, по крайней мере, я постараюсь этого не делать до поры до времени.
Давайте рассмотрим простой код, в котором можно использовать данный оператор. Как-то это можно было бы сделать и по-другому, но цель здесь чисто дидактическая. Поэтому не обращайте внимания на то, можно ли использовать другой метод. Просто постарайтесь понять показанную здесь концепцию.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 14. PrintX(v2++); 15. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 16. PrintX(v1); 17. PrintX(v2); 18. } 19. //+------------------------------------------------------------------+
Код 06
Когда код 06 будет выполнен, вы увидите такой результат:
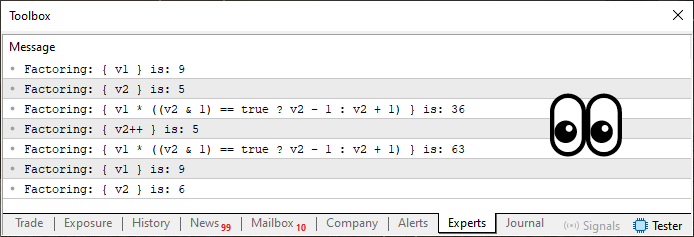
Рисунок 08
Поскольку этот тернарный оператор может быть довольно запутанным для многих людей, особенно для новичков, давайте объясним, что здесь происходит. Однако для того, чтобы полностью усвоить содержание статьи, необходимо изучить ее целиком. Сделайте это спокойно и обратите внимание на изложенный материал. Поскольку тема довольно глубокая, на ее полное понимание может потребоваться некоторое время.
Давайте вернемся к коду 06. Большую его часть легко понять. Конечно, у нас есть макрос, который мы еще не рассмотрели в плане использования в ваших кодах. Но даже данный макрос довольно прост для понимания. Поскольку в этой статье он использовался в других кодах, то, что я объясню здесь, применимо к другим кодам. Макрос, определенный в строке 04, позволяет нам отправлять на терминал ту или иную информацию, в зависимости от того, что используется в коде. Но как это делается? Для этого мы отправляем ему аргумент. Данный аргумент, которому предшествует символ ( # ), указывает компилятору принять аргумент и представить его как реализованный. По этой причине мы можем отобразить выполняемое вычисление, а также значение результата и, в некоторых случаях, имя используемой переменной. Это хороший способ отладки некоторых типов кода.
Но это лишь часть истории. Нас действительно интересует, как работают строки 13 и 15, так как в них содержится тернарный оператор. Чтобы объяснить это проще, возьмем за основу только одну из строк, поскольку другая работает очень похожим образом.
Давайте возьмем строку 13 и разберем ее так, чтобы использовать не тернарный оператор, а оператор IF. Но зачем использовать оператор IF для объяснения тернарного оператора? Причина в том, что тернарный оператор - это, по сути, оператор IF, но со способностью быть выражением, что позволяет поместить его в часть кода, как будто это была переменная. Однако, несмотря на такое сходство с оператором IF, тернарный оператор не заменяет его, поскольку не позволяет реализовать в нем кодовые блоки. Это отличается от оператора IF, который позволяет использовать блоки кода, но не может быть использован в качестве выражения внутри оператора.
Хорошо. Тогда при переводе строки 13 мы получим нечто похожее на это:
if ((v2 & 1) == true) value = v1 * (v2 - 1); else value = v1 * (v2 + 1); Print("Factoring: { v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1) } is: ", value);
Единственным моментом здесь является переменная value, которой на самом деле не существует. Я просто использую ее, чтобы объяснить, как компилятор интерпретирует вещи. Поэтому воспринимаем значение переменной как временную переменную, к которой мы не сможем получить никакого доступа.
Таким образом, усвоив данную концепцию, легко понять, как компилятор интерпретирует тернарный оператор. Обратите внимание, что при использовании оператора IF весь код становится намного понятнее. Однако в некоторых случаях, когда тернарный оператор действительно необходим, сделать это будет практически невозможно. Но для учебных целей это подходит. То же самое можно сказать по отношению к оператору Print, представленного в этом коротком фрагменте перевода. Этот оператор выполняет перевод кода макроса.
На самом деле, на первый взгляд, это кажется довольно сложным. Тем более что, уже говорилось, что этот тип написания кода, на мой взгляд, является реализацией промежуточного уровня. Так что не спешите усваивать всё, что происходит. Старайтесь учиться и практиковаться понемногу. Однако, когда вы действительно поймете, что тернарный оператор - это специальный оператор if, всё будет гораздо проще усвоить по мере изложения материала в следующих статьях.
Заключительные идеи
В этой статье я просто попытался объяснить то, что, честно говоря, является одной из самых сложных тем в программировании, если ограничиться теоретической областью. На практике данная тема об операторах гораздо проще и легче для понимания и изучения. Это происходит так, потому что, глядя на результат каждого действия или способа реализации разных элементов, становится более очевидным, что программисты не пытаются создать что-то неизвестное. Каждая программа направлена на то, чтобы ответить на что-то заведомо известное нам. Однако по мере тестирования и отладки приложения со временем мы сможем использовать его для получения более быстрого ответа на конкретный вопрос.
В заключение даю вам совет: учитесь и практикуйтесь в различных видах испытаний интенсивно. Только тогда вы сможете правильно освоить использование каждого из них. Не думайте, что теоретических знаний по предмету будет достаточно, потому что это не так. При работе с операторами опыт будет гораздо важнее теории. Так что приступайте к практике.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15440
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования