
Моделирование рынка (Часть 22): Первые шаги на SQL (V)

Введение
Здравствуйте, и добро пожаловать в очередную статью из серии о том, как построить систему репликации/моделирования.
В предыдущей статье «Моделирование рынка (Часть 21): Первые шаги на SQL (IV)», мы объяснили в абстрактной форме, как можно отделить реляционную базу данных от нереляционной. Но, в первую очередь (и это было причиной написания предыдущей статьи), мы попытались показать, как можно понять принцип работы базы данных. Это делалось для того, чтобы вы могли понять, что, хотя может показаться целесообразным запрограммировать некоторые вещи, в некоторых случаях можно использовать уже существующую реализацию, чтобы добиться ожидаемого результата в приложении.
То, что мы тратим время на объяснение SQL, а не на программирование в MQL5, объясняется именно этим. Нужно немного выровнять ситуацию, чтобы все могли понять, почему мы будем использовать SQL, когда мы могли бы создавать подпрограммы и ещё подпрограммы для создания какой-то реализации.
В данном случае реализация позволит нам разработать подходящий и простой способ, чтобы система репликации/моделирования имела систему команд. То есть нам нужен какой-то способ сохранить систему ордеров и позиций, чтобы проводить исследования в системе репликации/моделирования. Создавать для этого много подпрограмм, на мой взгляд, совершенно не нужно, так как MQL5 позволяет нам использовать определенную поддержку SQL через SQLite. Но для тех, кто стремится постоянно создавать код за кодом, мы покажем лучшую альтернативу. Это связано с тем, что время, которое ушло бы на внедрение, тестирование и настройку процедур для создания какой-либо базы данных, можно с большей пользой потратить на другие моменты.
Таким образом, когда мы начнем реально разрабатывать систему, необходимую для того, чтобы система репликации/моделирования могла фактически использоваться в качестве альтернативы демо-счетам для изучения какой-либо стратегии, это будет сделано гораздо быстрее и без многих проблем, связанных с должной работой. Причина этого заключается в том, что мы будем использовать SQL для обеспечения необходимого пути для создания системы ордеров.
Однако то, что объяснялось в предыдущей статье, является чем-то очень абстрактным, если оставить всё как есть и остаться в области теории. Но поскольку данная тема может представлять интерес и в других областях, например, если вы хотите создать советника, который использует базу данных для обучения торговле, вам понадобится применить на практике то, что было описано в предыдущей статье. Важная деталь, и я сразу скажу: я не планирую (по крайней мере на данный момент) объяснять, как создать базу данных, чтобы советник, созданный в MQL5, начал учиться торговать определенным символом.
Объяснение такого рода вещей потребовало бы и объяснения многих других понятий и принципов работы базы данных. Но если вы действительно хотите научиться этому, я вам рекомендую углубиться в изучение игровых алгоритмов. Это связано с тем, что создание базы данных является тривиальной задачей, как и программирование советника в MQL5. Но чтобы база данных была действительно полезна и советник буквально научился работать на рынке, нужно будет знать, как добавлять некоторые данные в создаваемую базу. Чтобы научиться создавать такие данные, проще всего изучить игровые алгоритмы.
Однако существуют и другие, более сложные пути, такие как, например, изучение движения волн или даже концепции распределения тепла. Но эти направления значительно сложнее, хотя результаты будут очень похожи на результаты игровых алгоритмов.
Давайте начнем с просмотра на практике того, что объяснялось в предыдущей статье. И поскольку я люблю всё разделять по темам, чтобы облегчить понимание, перейдем к первой теме этой статьи.
Создание простой базы данных
Здесь мы не будем долго распространяться. Это связано с тем, что эта тема уже рассматривалась в нескольких статьях, в которых обсуждалось SQL. Однако, поскольку в предыдущей статье мы предложили использовать другую программу, чтобы работа выполнялась непосредственно в SQLite, являющейся реализацией, которую мы будем использовать через MQL5, нам необходимо рассмотреть некоторые детали, касающиеся исключительно использования SQLite.
А первое, что мы рассмотрим, — это соотношение типов данных в SQLite и данных, которые мы поместим в базу данных. Одной из особенностей SQLite, которая привлекает внимание, когда речь заходит о типах данных, является то, что он содержит меньшее количество типов. Но это не является недостатком; наоборот, в зависимости от того, что мы разрабатываем, это большое преимущество, помимо другого плюса, который SQLite имеет перед другими реализациями.
Другим преимуществом, о котором я только что упомянул, является тот факт, что в SQLite данные являются динамическими, а не статическими, как во многих других реализациях. «Но подождите минутку. Как это данные в SQLite являются динамическими? И почему это является преимуществом?» Чтобы понять это, нужно взглянуть на небольшую таблицу, которая находится чуть ниже:
| Тип данных в SQLite | Объяснение |
|---|---|
| NULL | Включает любые значения NULL. |
| INTEGER | Целые числа со знаком, хранящиеся в 1, 2, 3, 4, 6 или 8 байтах, в зависимости от величины значения. |
| REAL | Вещественные числа или значения с плавающей запятой, хранящиеся в виде 8-байтовых чисел с плавающей запятой. |
| TEXT | Текстовые строки, хранящиеся с использованием кодировки базы данных (может быть UTF-8, UTF-16BE или UTF-16LE). |
| BLOB | Любой блок данных, причем каждый блок хранится точно так, как он был вставлен. |
Прошу заметить, что в этой таблице приведены типы SQLite. Теперь, просто из интереса, давайте посмотрим, как обстоят дела в других реализациях SQL. Начнем с MySQL, у которого таблица типов, как видно ниже:
| Тип данных в MySQL | Объяснение |
|---|---|
| TINYINT | Очень маленькое целое число. Диапазон знаковых значений для этого типа числовых данных составляет от -128 до 127, а диапазон беззнаковых значений — от 0 до 255. |
| SMALLINT | Небольшое целое число. Диапазон знаковых значений для этого числового типа составляет от -32768 до 32767, а диапазон беззнаковых значений — от 0 до 65535. |
| MEDIUMINT | Целое число среднего размера. Диапазон знаковых значений для этого типа числовых данных составляет от -8388608 до 8388607, а диапазон беззнаковых значений — от 0 до 16777215. |
| INTEGER | Целое число нормального размера. Диапазон знаковых значений для этого типа числовых данных составляет от -2147483648 до 2147483647, а диапазон беззнаковых значений — от 0 до 4294967295. |
| BIGINT | Большое целое число. Диапазон знаковых значений для этого типа числовых данных составляет от -9223372036854775808 до 9223372036854775807, а диапазон беззнаковых значений — от 0 до 18446744073709551615. |
| FLOAT | Небольшое число с плавающей запятой (одинарная точность). |
| DOUBLE | Число с плавающей запятой нормального размера (двойная точность). |
| DECIMAL | Упакованное число с фиксированной запятой. Длина отображения записей для этого типа данных определяется при создании столбца, и каждая запись приводится к данной длине. |
| BOOLEAN | Булево значение — это тип данных, который может принимать только два значения: «true» или «false». |
| BIT | Тип значения в битах, для которого можно указать количество битов на значение от 1 до 64. |
| DATE | Дата, представленная в формате YYYY-MM-DD. |
| DATETIME | Запись даты и времени, отображающая дату и время в формате YYYY-MM-DD HH:MM:SS. |
| TIMESTAMP | Временная метка, указывающая количество времени с момента начала эпохи Unix (00:00:00 1 января 1970 года). |
| TIME | Час дня, отображаемый в формате HH:MM:SS. |
| YEAR | Год, выраженный в формате 2 или 4 цифр, причем 4 цифры являются стандартом. |
| CHAR | Строка фиксированной длины; входы этого типа заполняются пробелами справа, чтобы соответствовать указанной длине при хранении. |
| VARCHAR | Строка переменной длины. |
| BINARY | Аналогично типу char, но представляет собой строку из бинарных байтов заданной длины, а не строку из небинарных символов. |
| VARBINARY | Аналогично типу varchar, но представляет собой строку из бинарных байтов переменной длины, а не строку из небинарных символов. |
| BLOB | Бинарная строка с максимальной длиной 65535 (2^16 - 1) байт данных. |
| TINYBLOB | Столбец BLOB с максимальной длиной 255 (2^8 - 1) байт данных. |
| MEDIUMBLOB | Столбец BLOB с максимальной длиной 16777215 (2^24 - 1) байт данных. |
| LONGBLOB | Столбец BLOB с максимальной длиной 4294967295 (2^32 - 1) байт данных. |
| TEXT | Строка с максимальной длиной 65535 (2^16 - 1) символов. |
| TINYTEXT | Текстовый столбец максимальной длиной 255 (2^8 - 1) символов. |
| MEDIUMTEXT | Текстовый столбец с максимальной длиной 16777215 (2^24 - 1) символов. |
| LONGTEXT | Текстовый столбец с максимальной длиной 4294967295 (2^32 - 1) символов. |
| ENUM | Перечисление — это объект в виде строки символов, который получает единственное значение из списка значений, объявленных при создании таблицы. |
| SET | Подобно перечислению, это объект строки, у которого может быть ноль или более значений, каждое из которых должно быть выбрано из списка допустимых значений, которые указываются при создании таблицы. |
Прошу заметить, что существует гораздо больше типов, и мы должны правильно выбрать подходящий тип, чтобы избежать проблем в будущем. Как и в PostgreSQL, у которого есть своя таблица типов, показанная ниже.
| Типы данных в PostgreSQL | Объяснение |
|---|---|
| BIGINT | 8-байтовое целое число со знаком. |
| BIGSERIAL | 8-байтовое целое число с автоматическим инкрементом. |
| DOUBLE PRECISION | 8-байтовое число с плавающей запятой двойной точности. |
| INTEGER | 4-байтовое целое число со знаком. |
| NUMERIC | Выбираемое число точности, рекомендуемое для использования в случаях, когда точность имеет решающее значение, например, при работе с денежными значениями. |
| REAL | Число с плавающей запятой простой точности, занимающее 4 байта. |
| SMALLINT | 2-байтовое целое число со знаком. |
| SMALLSERIAL | 2-байтовое целое число с автоматическим инкрементом. |
| SERIAL | 4-байтовое целое число с автоматическим инкрементом. |
| CHARACTER | Строка символов с заданной фиксированной длиной. |
| VARCHAR | Строка символов переменной, но ограниченной длины. |
| TEXT | Строка символов переменной и неограниченной длины. |
| DATE | Дата календаря, состоящая из дня, месяца и года. |
| INTERVAL | Промежуток времени. |
| TIME WITHOUT TIME ZONE | Час дня, без указания часового пояса. |
| TIME WITH TIME ZONE | Время суток, включая часовой пояс. |
| TIMESTAMP WITHOUT TIME ZONE | Дата и время без указания часового пояса. |
| TIMESTAMP WITH TIME ZONE | Дата и время, включая часовой пояс. |
| BOX | Прямоугольная «коробка» на плоскости. |
| CIRCLE | Окружность на плоскости. |
| LINE | Бесконечная линия на плоскости. |
| LSEG | Отрезок прямой на плоскости. |
| PATH | Геометрическая линия на плоскости. |
| POINT | Геометрическая точка на плоскости. |
| POLYGON | Закрытый геометрический путь на плоскости. |
| CIDR | Сетевой адрес IPv4 или IPv6. |
| INET | Адрес хоста IPv4 или IPv6. |
| MACADDR | Адрес Media Access Control (MAC). |
| BIT | Строка битов фиксированной длины. |
| BIT VARYING | Строка битов переменной длины. |
| TSQUERY | Поисковая строка для текста. |
| TSVECTOR | Документ для поиска текста. |
| JSON | Текстовые данные JSON. |
| JSONB | Разложенные двоичные данные JSON. |
| BOOLEAN | Логическое значение, представляющее собой «true» или «false». |
| BYTEA | Сокращение от «array of bytes»; этот тип используется для двоичных данных. |
| MONEY | Сумма валюты. |
| PG_LSN | Номер последовательности записи PostgreSQL. |
| TXID_SNAPSHOT | Снимок ID транзакции на уровне пользователя. |
| UUID | Универсальный уникальный ID. |
| XML | Данные XML. |
Прошу заметить, что в PostgreSQL доступно ещё больше типов. Можно подумать: Но всё это может превратиться в кошмар для тех, кто хочет использовать SQL. Но это не совсем так. SQL удается адаптироваться к нашим нуждам. Это необходимо для того, чтобы база данных могла использоваться в другом приложении, также созданном в SQL. Тот факт, что у нас есть больше или меньше типов, делает выбор типа более или менее сложным. Это связано с тем, что, если выбрать неправильный тип, когда нам понадобится его изменить, всю базу данных придется перестраивать заново. Хотя это довольно простая задача, поскольку мы используем специально созданные для этого скрипты, она может оказаться довольно сложной для тех, кто хочет изучить SQL и не знает, с чего начать.
Однако, глядя на эти таблицы, сразу становится заметным, что благодаря тому, что SQLite использует мало типов, присутствующие в нем типы, требуют меньше усилий в обслуживании. Но это поднимает другие вопросы, которые не имеют отношения к делу. Что нас действительно интересует в данный момент, так это то, что, имея меньше типов, SQLite обладает динамическими типами; то есть они растут в зависимости от потребностей, которые предъявляет хранимая информация.
Но как это применяется на практике? Чтобы понять это, нам необходимо создать две разные базы данных. Одна будет создана с помощью MySQL, а другая будет создана с помощью SQLite. Обе используют SQL в качестве базового языка. Давайте посмотрим, как это сделать. Анимация ниже показывает, как данный процесс выполняется в MySQL.
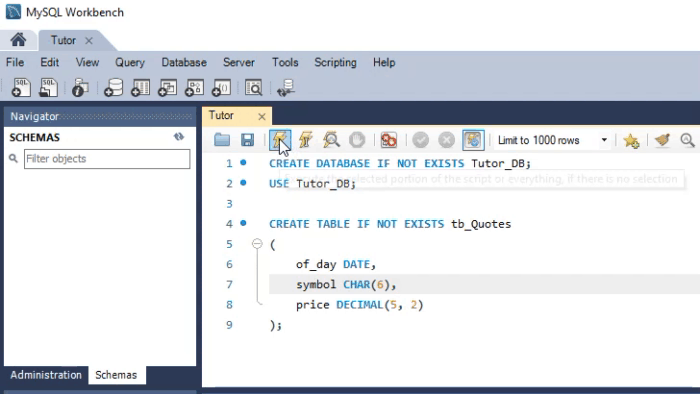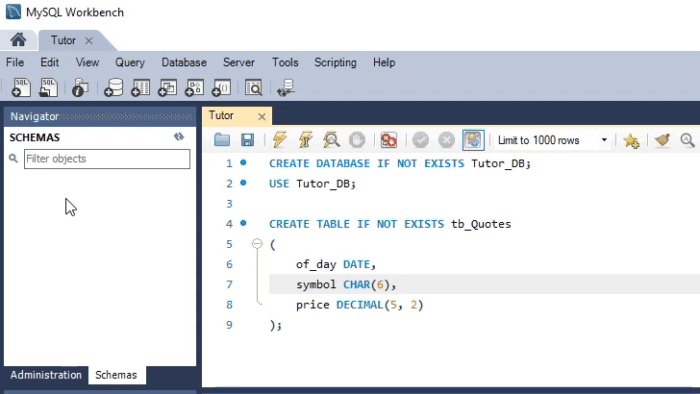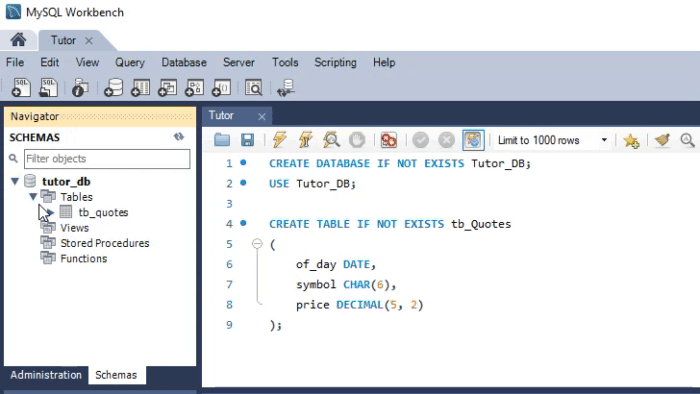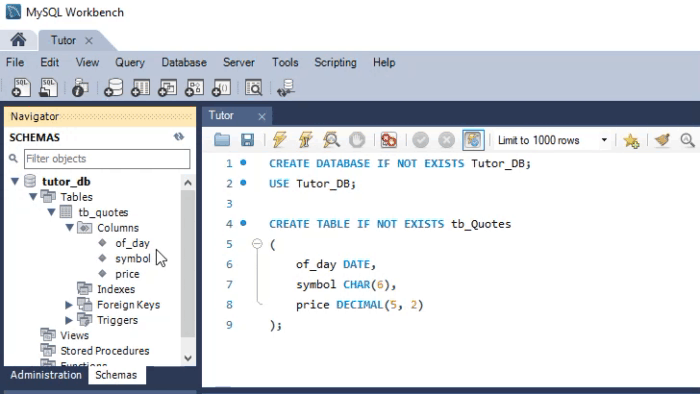
Прошу внимательнее посмотреть на используемые типы. Анимация, которую вы видите ниже, выполняет практически ту же процедуру, только в SQLite.
Обратите внимание на типы, определенные во второй анимации. Хотя в анимации, показанной в MySQL, скрипт создает базу данных, в SQLite этого не происходит. В этом случае у нас должна быть уже созданная и открытая база в DB Browser. Наверное, вы думаете: «Хорошо, типы разные, поэтому код не будет работать перекрестно». Если вы так думаете, то это потому, что случайно попали на эту статью. Я рекомендую прочитать предыдущие статьи, в которых мы показали, как использовать один и тот же код как в MySQL, так и в SQLite. Только в этом случае мы использовали MetaEditor для запуска SQLite.
Однако, в данном случае нас интересует тот факт, что в коде MySQL при создании столбцов мы определяем их размер. В случае с SQLite такого не сделали. Такой динамизм можно реализовать и в MySQL. Но это не является чем-то, что часто встречается в реализациях, отличающихся от SQLite. Причина в том, что зачастую программист SQL предпочитает определять тип или даже размер полей, чтобы оптимизировать некоторые характеристики базы данных. Поэтому у нас больше работы по обслуживанию баз данных в различных реализациях.
Но здесь может возникнуть сомнение: сможет ли MySQL понять столбцы, созданные SQLite, или наоборот? Что касается этого, вам беспокоиться не о чем. Да, любая реализация SQL сможет понять размерность, используемую в столбцах. По этой причине мы показали таблицы выше, чтобы облегчить понимание того, что между типами данных существует определенное пересечение. Однако в зависимости от реализации программист может принять решение использовать тот или иной конкретный тип, чтобы оптимизировать некоторые моменты в базе данных.
Хорошо. Теперь, когда мы представили необходимые элементы, давайте посмотрим на практике, как в эту историю вписываются первичные и посторонние ключи.
Основные и внешние ключи в практике
На анимациях выше можно увидеть, что мы создаем очень простую базу данных. Её цель — сохранить название символа вместе с котировкой и датой, когда была получена котировка. Однако на практике программист баз данных вряд ли создаст базу таким образом. Это связано с тем, что можно захотеть добавить больше одного символа или дополнительную информацию в саму базу данных, например, торговое название компании, символ которой представлен в таблице.
Но может также случиться, что символ изменит свое название. Хотя это довольно редкое явление, иногда оно всё же имеет место время от времени. Пример этого мы видим в B3, где в течение некоторого времени компания VIA VAREJO имела тикер: VVAR3. По какой-то причине символ изменил тик на VIIA3. Тогда представьте всю работу, которую придется проделать, чтобы изменить в каждой из прошлых записей название символа с VVAR3 на VIIA3. Но всё это можно было бы сделать очень легко, если бы основание было построено по-другому.
Хотя данный пример очень прост, он достаточно практичен, чтобы можно было понять многое другое. Многие люди считают, что создание и ведение базы данных — это простая задача, но когда они действительно собираются это сделать, в итоге совершают кучу ошибок, которые потом требуют огромных усилий, чтобы их исправить.
Давайте сначала посмотрим, как создать базовое решение с помощью SQLite. Чтобы упростить задачу и объяснение, можно посмотреть код скрипта SQL чуть ниже. Он будет использовать то, что мы собираемся внедрить.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. -- symbol TEXT, 13. price NUMERIC, 14. fk_id INTEGER, 15. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 16. );
Код в SQLite
Прошу заметить, что этот код уже содержит некоторые элементы, которые НЕ относятся к SQL. В данном случае речь идет о строке 01, где мы используем внутреннюю инструкцию SQLite. Но зачем мы используем данную инструкцию здесь? Причина в том, что в документации по SQLite, которую мы оставили в конце этой статьи в разделе ссылок, указано, что до версии 3.6.19 SQLite по умолчанию не использует внешние ключи, поэтому необходимо указать их. Иначе он не будет их использовать. Хотя упомянутая версия довольно старая, возможно, кто-то по какой-то причине всё ещё её использует. За исключением этого факта, давайте проверим, что происходит в этом скрипте. Помните, что для правильного выполнения скрипта в SQLite в DB Browser должна быть открыта база данных.
В строке 03 мы создаем (если она не существует) таблицу с названием tb_Symbols. В этой таблице мы объявляем в строке 05 уникальную идентичность. В строке 06 мы определяем название символа. Здесь мы пока не ограничиваем количество записей, которые будет содержать данная таблица. Причина в том, что мы всё ещё хотим показать, как мы пришли к гораздо более подходящей модели построения базы данных. Таким образом, хотя значение id всегда уникально, один и тот же символ может быть определен в нескольких id. Но это очень просто решается. Однако, прежде чем посмотреть, как мы это сделаем, давайте сначала разберемся, как здесь работают ключи.
После создания таблицы tb_Symbols мы можем изменить (или, точнее, создать) новую таблицу. Она начинается в строке 09, где мы указываем, что хотим создать таблицу tb_Quotes. Прошу заметить, что строка 12 является исходной, как показано в анимации выше. Однако, в отличие от того, что было показано в анимации, здесь это отображается в виде комментария. Причина заключается в том, что название символа больше не будет присутствовать в этой таблице. В связи с этим мы добавили в код строки 14 и 15. Теперь будьте очень внимательны при объяснении, это важно. В строке 14 мы определяем значение, которое должно иметь тот же тип, что и первичный ключ таблицы tb_Symbols. В некоторых случаях программист, использующий SQLite, не определяет тип, оставляя это дело программе. Поскольку мы хотим поддерживать определенный стандарт в коде, мы определим тип.
Это будет наш внешний ключ в таблице tb_Quotes. А сейчас действительно важный момент в этом скрипте, показанном выше. В строке 15 мы указываем, что такое внешний ключ и к чему он будет относиться. Прошу заметить, что нам нужно указать название таблицы, а также название ключа или столбца, который будет использоваться. Этот ключ берет свое начало в таблице tb_Symbols.
Таким образом, мы создаем референциальную, или реляционную, систему, в которой информация о котировке отделена от названия символа. Однако данное разделение не является реальным, поскольку существует связь между регистрацией котировки и названием символа. И эта связь возникает именно благодаря созданию первичного и внешнего ключей. Если вы поняли эту связь, то вы поймете, что можно создать настоящую базу данных, связывая между собой различную информацию таким образом, что она будет иметь некую связь, которая в то же время позволит нам добавлять больше или меньше данных в одну и ту же запись. Всё это при минимальных затратах на обслуживание или модификацию исходной базы данных.
Приведенный выше код можно создать так, как показано ниже, что будет гораздо ближе к возможной реальности. Хотя мы ещё не решили вопрос о том, что название символа повторяется более чем в одном месте в таблице tb_Symbols.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. price NUMERIC, 13. fk_id INTEGER REFERENCES tb_Symbol (id) 14. );
Код в SQLite
Прошу заметить, что сейчас мы внесли небольшое изменение. Оно находится в строке 13 и имеет ту же цель, заключающуюся в том, чтобы связать с помощью внешнего ключа таблицу tb_Quotes с таблицей tb_Symbols. Ещё один момент: Хотя мы говорили, что мы связываем таблицы, правильнее сказать, что мы связываем запись из таблицы tb_Quotes с другой записью из таблицы tb_Symbols. Хорошо, теперь обратите внимание: неважно, что мы храним в каждой из таблиц. Мы можем добавить больше или меньше полей или столбцов данных в таблицы, и это не повлияет напрямую на поиск и результаты, которые мы получим при поиске.
Но, в зависимости от необходимости, можно добавить дополнительную информацию в одну из таблиц. Однако при этом все другие таблицы, связанные с этой таблицей, также получат преимущества от этого, но нам не придется переписывать базу данных полностью. Возможно, вы не осознаете весь масштаб данного факта. Но если вы начнете использовать SQL, то вскоре поймете, что это очень помогает, когда мы хотим расширить базу данных или создать реляционную систему между различными типами информации.
Хорошо, но как мы можем решить проблему возможных продублированных данных в базе данных? Сделать это очень просто. При создании таблицы мы указываем, что столбец не должен содержать определенные значения или что значения не могут продублироваться. Например, давайте изменим показанный выше код, таким образом, чтобы в столбцах не было нулевых значений. Но мы также не хотим, чтобы название символа появлялось более чем в одной записи в одном и том же столбце. Таким образом, исправленный код выглядит так:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY NOT NULL, 06. symbol TEXT NOT NULL UNIQUE 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT NOT NULL, 12. price NUMERIC NOT NULL, 13. fk_id INTEGER NOT NULL, 14. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 15. );
Код в SQLite
Теперь, если запустить этот скрипт, то мы заметим, что обе таблицы будут созданы, как и ожидалось, и как показано в объяснении выше. Однако, в отличие от того, что происходило раньше, теперь у нас не будет продублированных записей. Если попытаемся дублировать какую-либо запись, SQL не допустит этого. Точно так же в нашей таблице больше не будет значений, равных нулю. Прошу заметить, что код для этого очень прост и понятен.
Как понять последний скрипт
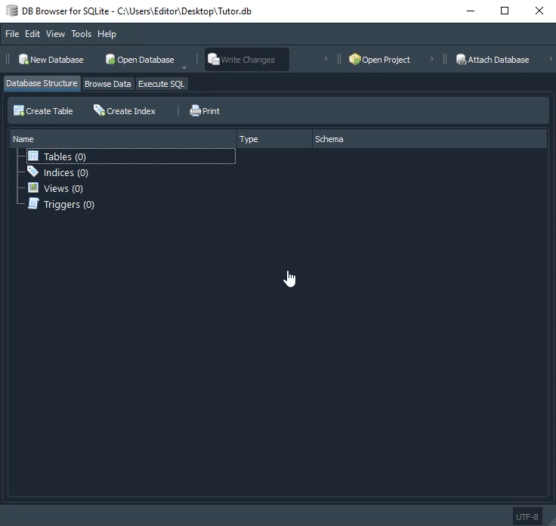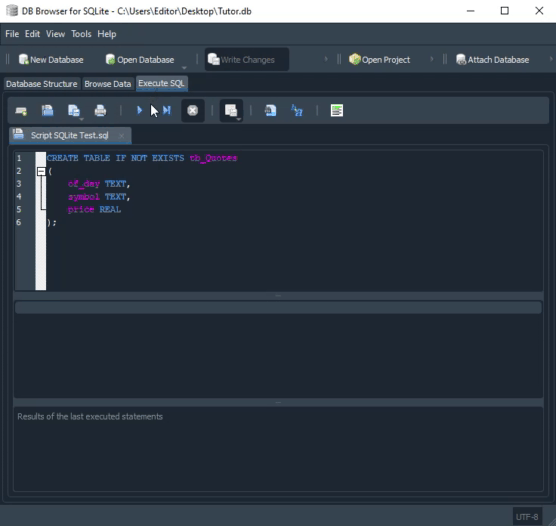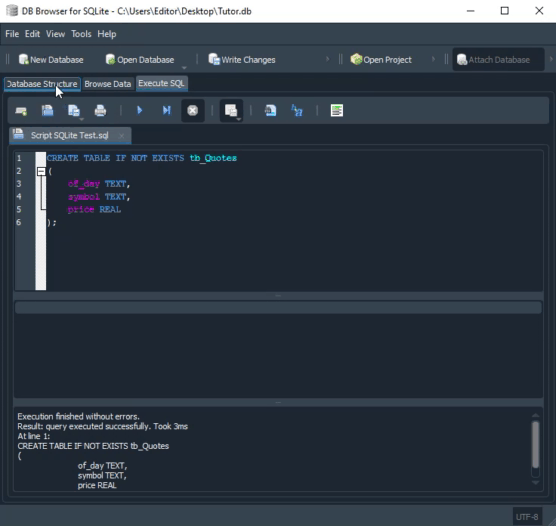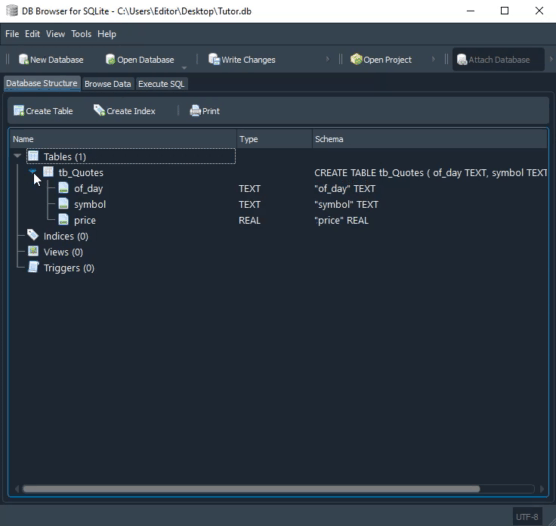
Перед тем, как отправляться в новые области, очень важно разобраться в том, как работает последний скрипт. Действительно, нам необходимо попробовать и понять, что здесь происходит. Иначе мы будем полностью потеряны. Таким образом, после выполнения последнего кода скрипта в SQL, показанного выше, в BD Browser мы получим следующий результат:
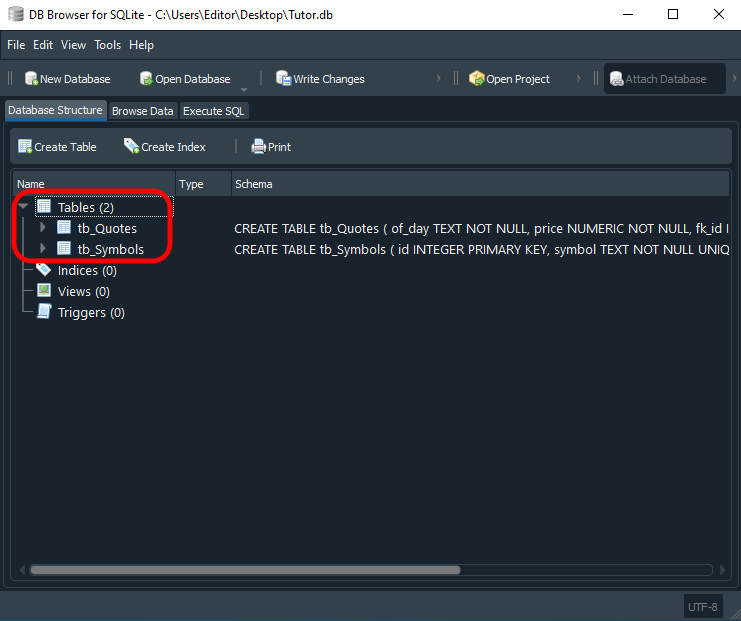
Обратите внимание, что мы выделили две таблицы, показанные здесь. Но как же нам их действительно использовать? Это кажется чем-то сложным и возможным только для великих мастеров компьютерных технологий. Вовсе нет. Использовать данную схему проще, чем идти вперед. Мы уже показали, как добавлять информацию в таблицу с помощью скрипта. Это в предыдущих статьях, посвященных SQL. Здесь мы будем использовать нечто очень похожее на то, что уже видели.
Для этого, чтобы посмотреть, как все происходит, добавим некоторые данные только для примера взаимодействия с этим типом моделирования. И, поскольку мы также показали базовую команду выделения, мы можем использовать её и здесь. Но сначала добавим несколько записей в нашу базу данных. Давайте заменим приведенный выше скрипт другим, немного отличающимся от него.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes;
Скрипт в SQLite
Возможно, вы смотрите на это и думаете: Ух ты, какой сложный код, я никогда не смогу это понять. Думаю, я сдамся и сделаю всё по другому. Но я говорю вам: вы собираетесь сдаться сейчас? Именно сейчас, когда всё стало интереснее? Ведь в приведенном выше коде нет ничего сложного. Абсолютно всё, что в нем содержится, уже объяснялось на этом начальном этапе, где мы дали некоторые пояснения о том, как использовать язык SQL.
Возможно, единственная часть, которая может вызвать у вас некоторое замешательство, — это строки 03 и 04, где мы говорим SQL, что, если таблицы tb_Quotes и tb_Symbol существуют, они должны быть удалены. Но почему мы удаляем таблицы, не успев их использовать? И главный вопрос: зачем удалить их? Разве нельзя просто сохранить их и добавлять новые данные в базу?
На все эти вопросы есть один ответ. Нам нужно удалить таблицы по той простой причине, что между строками 20 и 29 мы будем добавлять в них значения. Однако, при каждом запуске этого же скрипта, SQL будет сообщать нам об ошибке в момент добавления значений в таблицы. Причиной появления данной ошибки является именно тот факт, что мы не можем дублировать некоторые поля в базе данных.
После запуска этого скрипта мы получим следующий результат:
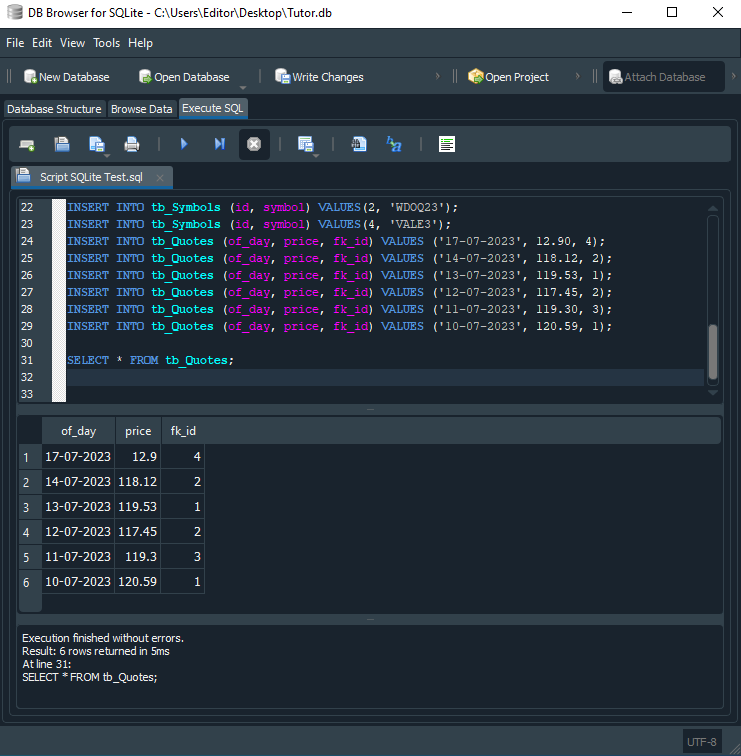
Прошу заметить, что в результате мы получаем именно содержимое таблицы tb_Quotes. Это связано с тем, что в строке 31 мы просим SQL предоставить нам эту информацию. Но, глядя на это, можно немного расстроиться. Это связано с тем, что если у нас есть очень обширная база данных с котировками различных символов, то трудно понять, где каждый из них, поскольку мы не получаем в ответ название символа или какую-либо другую информацию, которая помогла бы лучше понять, что мы ищем в базе данных. Но вскоре мы увидим, как это можно улучшить, внеся небольшое изменение в код в строке 31, где мы используем команду SELECT.
Заключительные идеи
Прежде, чем вы сдадитесь и решите отказаться от изучения SQL, позвольте мне напомнить вам, уважаемые читатели, что здесь мы всё ещё используем только самые базовые элементы. Мы ещё не рассмотрели некоторые возможности SQL. Как только вы их усвоите, вы увидите, что SQL гораздо практичнее, чем кажется. Хотя, скорее всего, мы в конечном итоге изменим направление того, что мы создаем, потому, что процесс создания является динамичным. Мы покажем немного больше о создании разных вещей в SQL, ведь это по настоящему важно и нужно вам. Просто думать, что вы более способны, чем целое сообщество программистов и разработчиков, приведет только к потере времени и возможностей. Не переживайте, потому что дальше будет ещё интереснее.
Как я уже сказал, я ещё не уверен, буду ли использовать SQLite или другую реализацию SQL. Это связано с тем, что разработка тех элементов, которые нужны для системы репликации/моделирования, является полностью динамичным процессом. Мы ещё не решили, в каком направлении, собственно, мы будем двигаться дальше. Но независимо от того, как будут развиваться события на следующих этапах, когда мы вернемся к MQL5, мы наверняка будем использовать SQL для решения различных задач. Я не собираюсь создавать никаких подпрограммных процедур для выполнения того, что SQL позволяет нам делать и в чем нам помогает. Но то, как мы будем использовать SQL на практике, ещё не определено окончательно.
В следующей статье мы рассмотрим, как выполнять некоторые другие действия в SQL. Ведь теперь дело действительно начинает набирать обороты, и то, что мы собираемся рассмотреть и объяснить, уже почти полностью определилось. Однако хочу подчеркнуть, что эти статьи не являются курсом по SQL. Я просто хочу показать несколько моментов, которые могут пригодиться в будущем, поскольку нет смысла использовать MQL5 или любой другой язык для того, что может сделать за нас сам SQL. И мы говорим не только о создании и ведении базы данных. Мы говорим о программировании как таковом.
Многие знают лишь несколько команд SQL, но забывают их или не проявляют должного интереса к углублению своих знаний в этой области, упуская таким образом возможность использовать настоящего помощника, поскольку многие из процедур, которые некоторые создают на языке, интегрированном с SQL, можно выполнять непосредственно в SQL. И умение делать такие вещи очень поможет в ваших разработках. Так что постарайтесь углубить свои знания по этой теме. Используйте эти статьи только в качестве ориентира: не считайте их единственным источником информации или чем-то окончательным. Всех обнимаю, до встречи в следующей статье.
| Файл | Описание |
|---|---|
| Experts\Expert Advisor.mq5 | Демонстрирует взаимодействие между Chart Trade и советником (для взаимодействия требуется Mouse Study). |
| Indicators\Chart Trade.mq5 | Создает окно для настройки отправляемого ордера (для взаимодействия требуется Mouse Study). |
| Indicators\Market Replay.mq5 | Создает элементы управления для взаимодействия с сервисом репликации/моделирования (для взаимодействия требуется Mouse Study) |
| Indicators\Mouse Study.mq5 | Обеспечивает взаимодействие между графическими элементами управления и пользователем (необходимо как для работы системы репликации/моделирования, так и на реальном рынке). |
| Services\Market Replay.mq5 | Создает и поддерживает сервис репликации/моделирования рынка (главный файл всей системы) |
| Code VS C++\Servidor.cpp | Создает и поддерживает серверный сокет, разработанный на C++ (версия MiniChat) |
| Code in Python\Server.py | Создает и поддерживает сокет в Python для связи между MetaTrader 5 и Excel |
| Indicators\Mini Chat.mq5 | Позволяет реализовать мини-чат через индикатор (для работы требуется использование сервера) |
| Experts\Mini Chat.mq5 | Позволяет реализовать мини-чат с помощью советника (для работы требуется сервер). |
| Scripts\SQLite.mq5 | Демонстрирует использование скрипта SQL с помощью MQL5 |
| Files\Script 01.sql | Демонстрирует создание простой таблицы с внешним ключом. |
| Files\Script 02.sql | Показывает добавление значений в таблицу |
Ссылка
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/12986
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования