
Моделирование рынка (Часть 21): Первые шаги на SQL (IV)

Введение
Здравствуйте и добро пожаловать в очередную статью из серии о системе репликации/моделирования.
В предыдущей статье « Моделирование рынка (Часть 20): Первые шаги в SQL (III)» мы немного рассказали о команде SELECT. Нам нужно рассмотреть ещё одно понятие для более эффективного использования SQL или, точнее, чтобы мы могли воспользоваться всем тем, что делает SQL. Это лучшая альтернатива вместо того, чтобы программировать приложение, которое выполняло бы ту же работу, а именно поддерживало и позволяло нам манипулировать базами данных. Это другое понятие является ключевым, когда речь идет о базах данных. Мы говорим о ключах, которые могут быть первичными или внешними.
Хотя MetaEditor позволяет нам выполнять задачи с помощью SQLite, но если вы только начинаете и хотите более последовательно изучить работу с SQL, то понадобится более сложный инструмент. Один важный момент: я не говорю, что MetaEditor не функциональный. Но для понимания некоторых моментов MetaEditor не подходит, и это связано с тем, что его назначение другое, а именно редактирование и компиляция кодов, написанных на MQL5. То, что он предоставляет нам существенную помощь в использовании SQLite недостаточно для того, что нам действительно нужно, когда речь идет об обучении.
Поэтому в данном случае я позволю себе предложить другой инструмент. И это связано с тем, что он фактически ориентирован на работу с SQLite. Хотя при использовании MySQL или любой другой платформы для работы с SQL, на практике мы получим тот же результат. Это связано с тем, что в предыдущих статьях мы достаточно ясно дали понять, что не имеет значения, какую систему мы будем использовать для доступа к SQL. Все смогут сделать то же самое, при условии, конечно, что мы будем использовать только и исключительно синтаксис SQL, не прибегая к чему-либо, что присутствует только в этой конкретной разновидности SQL.
Итак, предлагаю вам использовать инструмент DB Browser. Он имеет открытый исходный код, написан на C++ и доступен для бесплатной загрузки на GitHub. В конце сегодняшней статьи мы оставим ссылку, по которой вы сможете получить доступ к установщику инструмента. Одним из преимуществ DB Browser является то, что он значительно облегчает понимание различных понятий, поскольку существуют переводы на другие языки, что будет весьма полезно для многих, кто не владеет английским.
Ещё одна деталь заключается в том, что в отличие от MetaEditor, где нельзя редактировать, сохранять и использовать скрипт SQL, в DB Browser это можно делать. Такие вещи очень помогают в начале обучения. Но для тех, кто уже владеет SQL и использует его только для запросов к базе данных, использование того или иного инструмента ничего не изменит. Таким образом, выбор инструмента остается на собственное усмотрение.
На изображении ниже показан интерфейс DB Browser. Конечно, на этом изображении мы удалили некоторые опции, так как они не нужны для того, что мы будем изучать.
Но прежде, чем мы начнем рассматривать тему первичных ключей и внешних ключей, хочу объяснить то, что, возможно, вызывает вопросы, особенно если мы хотим углубить свои знания в области SQL.
Почему произошла смена стратегии?
Возможно, вы почувствуете себя немного некомфортно и даже разочаруетесь, если попробуете использовать SQL в любой реализации. Некоторые администраторы, нанимая аналитика баз данных, часто требуют, чтобы он умел работать с определенной реализацией. Например: можно изучить SQL Server и не получить работу, потому что вместо этого используется MySQL. Или можно слушать мнения о том, как Oracle лучше других реализаций SQL. В предыдущих статьях мы показали, что люди, которые так думают, на самом деле ничего не знают о базах данных. Они просто представляют, что это или лучше, или хуже. Они не имеют должного представления о том, как всё на самом деле устроено в деталях, и остаются на месте, пытаясь судить о том, чего на самом деле не понимают.
Если мы собираемся использовать базу данных или реализацию, которая использует сервер, то у нас будет способ доступа к базе данных. Наиболее распространенным способом для этого являются сокеты. Прежде, чем говорить о SQL, мы объяснили в нескольких статьях, как работать с сокетами. Там идея заключалась не только в том, чтобы объяснить принцип работы сокетов, но и показать, как настроить двунаправленную связь между Excel и MetaTrader 5. То есть, как Excel, так и MetaTrader 5 могут обмениваться данными друг с другом. Мы не будем ограничены использованием RTD или DDE для передачи данных, потому что в этом случае данные будут приниматься только Excel. Но, зная, как использовать сокеты, мы можем сделать гораздо больше.
Те же знания, которые продемонстрировали там, могут быть использованы для того, чтобы MQL5 или исполняемый файл, запущенный в MetaTrader 5, мог работать с SQL для доступа к базе данных. Всё, что нужно знать, это как работать с командами SQL, а также как отправлять и получать информацию через сокет. Остальное - уже история, так как серверные базы данных гораздо более практичны, когда речь идет о потоке информации. Чтобы было понятнее, поясним: база данных, размещенная на сервере SQL, будет гораздо более расширяемой, чем база данных, размещенная в файле.
Однако при использовании SQLite нашей исходной предпосылкой является размещение базы данных в файле. Это не значит, что мы ограничены только этим. Да, можно использовать сервер SQLite, но обычно мы используем файлы при использовании SQLite. Это создает для нас некоторые ограничения и неудобства. Некоторые из этих ограничений являются приемлемыми, поскольку зачастую база данных будет использоваться только для конкретного приложения. В других случаях данные ограничения вынудят нас изменить стратегию и заставит использовать SQL-сервер.
Однако, поскольку цель данной статьи — просветительская и заключается, прежде всего, в том, чтобы показать вам следующее: нам не нужно программировать определенные вещи и мы должны использовать уже существующие инструменты, когда это возможно. Такие ограничения, которые возникают, когда база данных содержится в файле, на самом деле не будут проблемой. Но имейте в виду: SQL-сервер всегда будет превосходить по ряду параметров реализацию, которая использует файл для хранения базы данных.
Теперь, когда мы объяснили этот момент, мы можем ненадолго отвлечься от MySQL. Хотя мне это очень нравится, нам нужно сначала сосредоточиться на том, что действительно необходимо. Возможно, в будущем, в другой статье, мы объясним, как можно использовать сокеты для программирования базы данных. Но пока давайте рассмотрим кое-что иное, и, чтобы не смешивать одну тему с другой, начнем новую.
Почему существуют первичные и внешние ключи?
Чтобы объяснить то, что довольно сложно понять (по крайней мере для тех, кто не разбирается в базах данных), сначала необходимо объяснить момент, который также довольно сложен для понимания тем, кто совсем не знаком с программированием. Иными словами, одно дело связано с другим. Но давайте посмотрим, смогу ли я объяснить вам, почему существуют первичные и внешние ключи. Однако, если вы ничего не знаете о программировании, я вам советую изучить хотя бы основы какого-либо языка программирования, чтобы понять некоторые концепции, которые мы будем использовать в этом объяснении.
Причина существования первичных и внешних ключей, которые я всегда использую вместе, та же, что и причина, по которой реляционные базы данных отличаются от нереляционных. Теперь всё усложнилось, ведь многие люди думают, что существует только один тип базы данных. То есть, в большинство людей при слове «база данных», сразу начинает думать, что между ключом и значением существует связь. Но это не совсем так. Проблема заключается в неправильном использовании некоторых понятий. Понятие «ключ - значение» ни в коем случае не означает, что база данных является или не является реляционной. На самом деле, понятие «ключ - значение» выходит за рамки некоторых представлений. Чтобы понять это, давайте на мгновение забудем о базах данных и подумаем, как всё было до появления термина «база данных».
Самый простой способ применить понятие «ключ - значение» — это использование массива. Если вы знаете, что такое массив, то вы знаете, что каждый индекс или позиция массива может содержать значение или запись. Хорошо. Затем, используя индекс, который будет эквивалентен ключу, можно получить запись этой позиции, которая будет эквивалентна значению. Зная это, можно изменять, удалять или делать что угодно с этими данными. Это самое основное из всего.
Если поместить данный же массив, который находится в памяти, в файл, то можно будет создать формат, позволяющий легко воссоздать исходный массив при повторном чтении файла в память. И, опять же, это самое основное из всего. На этом этапе можно подумать следующее: «Ну, я, как программист, могу создать целую серию процедур и подпрограмм для изменения, поиска, организации, удаления и т. д. любых записей в массиве». Прошу заметить, что в этот момент вы сами, не осознавая этого, только что создали базу данных. Это связано с тем, что вы используете точно те же вещи, что и база данных.
Затем, чтобы получить доступ к любой записи или значению в том, что теперь является базой данных, вы загрузите файл в массив в памяти, выполните необходимые процедуры и сразу после этого сохраните массив обратно в файл. Подобный вид вещей часто практикуется и объясняется, когда мы начинаем изучать программирование. Однако, насколько я знаю, никто не обрабатывает такого рода вещи как базу данных. Почему? Ну, кто знает. Но правда заключается в том, что вы, даже этого не осознавая, создали личную и частную базу данных.
Однако такого рода решение зачастую не является масштабируемым. То есть, нельзя легко передавать информацию между разными приложениями. И именно в этом месте концепция базы данных начинает обретать смысл, поскольку можно использовать то, что будут использовать и другие, в данном случае SQL, и написать базу данных, которая может быть использована различными приложениями. Поэтому мы с самого начала говорили, что, хотя можно делать что-то новое, иногда лучше использовать то, что уже существует.
Однако всё это объяснение ещё не отвечает на вопрос, с которого начинается тема. Успокойтесь, мы к этому ещё вернемся. Но поскольку теперь у нас уже есть базовое представление о том, что такое база данных, мы можем перейти к следующему пункту. То есть, в чем заключается разница между реляционной и нереляционной базой данных, и почему данная разница существует? Хотя это и простой вопрос, ответ на него не так прост. Некоторые люди, имеющие какой-то опыт, сразу скажут: реляционная база данных использует SQL, а нереляционная — нет. Я бы даже хотел, чтобы ответ был таким простым, но это не так. Разница между реляционной и нереляционной базой данных заключается в том, как набор «ключ - значение» размещается в базе данных.
«Господи! Если раньше всё было сложно, то теперь всё стало окончательно невыносимым. Но как же так? Как может быть разница в том, что набор «ключ - значение» размещается в базе данных? На первый взгляд, в этом нет никакого смысла, но по мере того, как мы будем приобретать опыт и работать с базами данных, в какой-то момент вы это поймете. Однако, чтобы вы хотя бы могли понять, о чем мы говорим, даже если это покажется вам безумием, я постараюсь объяснить этот момент, как бы сложно это не было.
Одной из основных характеристик реляционной базы данных является её целостность, или, точнее, способность базы сохранять свою целостность, даже когда мы пытаемся лишить её этой характеристики. Можете думать, что вся база данных является целостной. Но есть случаи, когда данная целостность не является приоритетом. И когда это происходит, мы получаем нежелательный результат, поскольку база данных должна быть целостной. У нас есть дублирование наборов «ключ - значение». «Но подождите секунду. Это дублирование не должно происходить, поскольку каждый индекс, который будет ключом, будет связан с записью, которая будет значением». На самом деле, если вы так подумали, то вы правы. Однако, если вы так подумали, то это потому, что вы всё ещё думаете о массиве. Теперь дело стало немного сложнее. В случае с массивом каждая позиция представляет собой значение. Таким образом, невозможно занять позицию, представляющую два разных значения. И это, по сути, верно.
Но а если вместо индекса или позиции использовать что-то другое, например, значение или строку, которые в данном случае будут представлять индекс или ключ? Теперь всё начинает выглядеть довольно знакомо. Чтобы понять это, давайте подумаем о чем-то, что в наши дни стало довольно распространенным явлением: программирование на Python. А почему мы будем использовать Python в объяснении? Причина в том, что в Python есть концепция, которая идеально подходит для объяснения разницы между реляционными и нереляционными базами данных. Кроме того, Python также может использовать массивы, и тогда объяснение будет гораздо более логичным.
В Python существует такое понятие, как словарь. Словарь, в общих чертах, представляет собой тип массива, в котором каждый индекс имеет поле, которое является ключом, и другое поле, которое является значением. То есть, теперь не индекс в массиве указывает, к какому значению будет привязан ключ. Можно поместить ключ в любой индекс, и при поиске по ключу мы всё равно найдем соответствующее значение. Эта аналогия идеально подходит, поскольку теперь мы можем иметь одинаковые ключи, которые представляют разные значения, а также одинаковые значения, представленные разными ключами. В данном случае база данных, которая будет создана словарем в Python, будет нереляционной базой данных. Всё просто. Так же, как это было сделано в Python, можно использовать SQL для выполнения той же задачи. То есть, мы создадим столбец, который будет содержать значения, используемые в качестве ключей.
В другой колонке мы бы указали соответствие каждого ключа значению записи. Без надлежащих мер защиты база данных, даже написанная на SQL, превратилась бы в нереляционную базу данных. Видите, что, хотя это и кажется простым, понимание различных элементов может помочь нам лучше понять некоторые концепции? Но всё, что было показано до этого момента, служит лишь для объяснения того, как мы можем просматривать базу данных. И как можно устоять перед соблазном запрограммировать ряд подпрограмм и процедур, только чтобы сделать то, что может сделать SQL. Или вы думаете, что нельзя создать словарь Python, используя для этого SQL?
В этом месте стоит упомянуть один интересный момент, прежде чем перейти к основам реляционных баз данных. Многие люди, в основном энтузиасты с небольшим опытом в программировании, придумали тысячу и один способ создания системы искусственного интеллекта с помощью Python. Я не хочу критиковать или говорить, что эти люди ошибаются. Однако только подумайте о следующем: такие системы искусственного интеллекта по сути используют базу данных. Будь то нереляционная, как та, которую мы только что рассмотрели, или реляционная, которую мы рассмотрим чуть позже. Мой вопрос: зачем создавать такие базы данных на Python, если можно сделать то же самое с помощью SQL?
Таким образом, несмотря на всю эйфорию вокруг этих GPT, которые заставляют многих людей изучать Python, пытаясь создать что-то похожее или, по крайней мере, удовлетворяющее какую-то конкретную потребность, то же самое можно сделать с помощью SQL. Важный момент заключается в следующем: сколько усилий вам потребуется приложить, чтобы сделать что-то на том или ином языке? Когда в раньше я написал серию статей о том, как создать советника, который будет работать в автоматическом режиме, некоторые спросили меня, зачем я это сделал. Но лично я не вижу никаких особых сложностей в создании чего-то подобного, потому что это очень просто в реализации.
Напротив, советник, который использует базу данных, поддерживаемую и написанную на SQL, для обучения торговле на рынке, заслуживает уважения. Хотя это и несложно в реализации, но требует значительных знаний и усилий, особенно для того, чтобы советник мог правильно обучиться и создать базу данных. Скорее всего, что-то подобное уже существует: робот, который, используя MetaTrader 5 вместе с SQL, работает так же, как человек, с полной субъективностью в принятии решений: следует ли ему торговать, покупать или продавать, какой сигнал лучше другого. В конце концов, вещи такого рода могут появиться, если мы изучаем правильные концепты.
Хорошо, теперь мы можем посмотреть, что такое реляционная база данных. Если у вас есть какие-то знания в области программирования, вы наверняка понимаете, как может возникнуть нереляционная база данных. Однако, без понимания первого, вы не сможете понять второго. Опять же, использование или неиспользование SQL не имеет никакого значения. Разница заключается лишь в том, как создается основа.
Чтобы понять реляционный тип, нам нужно немного вернуться назад во времени. На самом деле, нам нужно вернуться к предыдущей статье, где мы объясняли, как изменить и удалить запись из базы данных. Достаточно прочитать предыдущие статьи, чтобы понять, о чем идет речь. Там мы довольно ясно показали, что для поиска определенной записи нужно что-то. Без использования этого «что-то» (это ключ), мы не сможем найти правильное положение. Но чем отличается ключ, используемый в реляционной базе данных, от того же ключа, используемого в нереляционной базе? Одно из отличий заключается в том, что в нереляционной базе данных этот ключ не будет уникальным. Но речь не только об этом. Пока держите это в голове.
Данный ключ не будет повторяться при использовании реляционной базы данных. Для этого мы обычно определяем его как первичный ключ. Но то, что он первичный, не означает, что он не повторится. Можно указать SQL, что в столбце значения не могут повторяться. И всё же это не делает эти данные или записи, относящиеся к этой конкретной колонке, набором первичных ключей.
То, что делает столбец первичным ключом, — это наличие внешних ключей. Именно это определяет и гарантирует, что база данных является реляционной. Это связано с тем, что теперь у нас будет связь между ключом, присутствующим в одной таблице, и другим ключом, присутствующим в другой. Данный тип часто используется для создания базы данных, в которой все записи должны быть уникальными. Но, самое важное, чтобы все они каким-то образом были связаны друг с другом, создавая нечто похожее на схему графа, очень похожую на ту, что показана на изображении ниже.
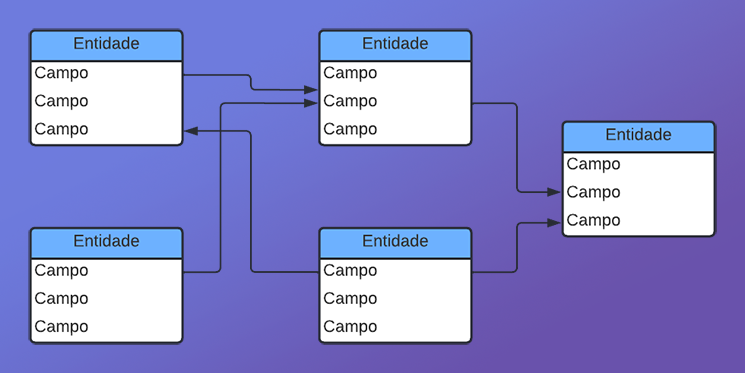
Возможно, просто глядя на это изображение, понятия «первичный ключ» и «внешний ключ» не кажутся особо понятными. Но представьте на мгновение, что мы создали базу данных о своей личной жизни. Данная база не потребует первичного или внешнего ключа. Однако, если мы начнем добавлять в эту же базу данных свои личные контакты, будь то из социальных сетей или своих близких людей, каждый из этих контактов будет иметь ключ, который будет первичным. Но будут моменты, в которых все эти записи будут иметь общие черты. Если бы вы, пытаясь сохранить эту же базу данных, дублировали эти общие точки, при выполнении перекрестного запроса процесс был бы гораздо медленнее и труднее.
Однако, если эти общие точки будут помещены в специальную таблицу, вы сможете, используя другой ключ (в данном случае внешний ключ), гораздо легче сопоставить информацию, ускорив таким образом как запрос, так и любые изменения, которые, в конечном итоге, необходимо внести в базу данных. И вот так возникает реляционная база данных. То есть информация, найденная в одном месте, будет связана с другой информацией, размещенной в другом месте.
Заключительные идеи
Я знаю, что содержание сегодняшней статьи может показаться очень абстрактным и трудным для понимания. Однако я хочу подчеркнуть то, что базы данных, в том виде, в каком они определены и используются в настоящее время, не появились в одночасье. Они были построены и внедрены постепенно, на протяжении многих лет. Многие из вас, возможно, обладают гораздо большим опытом в области работы с базами данных, чем я, и, следовательно, имеют другое мнение.
Поскольку было необходимо дать объяснение, почему базы данных создаются именно так, как они создаются, и нужно объяснить, почему SQL имеет именно такой формат и, прежде всего, почему появились первичные ключи и внешние ключи, поэтому пришлось оставить некоторые вещи немного абстрактными. Опять же, если рассматривать данную тему только с точки зрения объяснения, она может показаться очень абстрактной и без обоснований.
Но, поскольку я хочу показать основы этой темы, чтобы вы, могли делать определенные вещи, не углубляясь слишком в SQL, нам нужно понять такое понятие, как первичные ключи и внешние ключи, и как они на самом деле работают. Это связано с тем, что правильное понимание этого понятия будет иметь большое значение при создании базы данных, даже если она предназначена только для обучения.
Если мы собираемся начать что-то использовать, надо делать это правильно. Изучение разных идей, которые мы на самом деле не понимаем, не помогает нам развиваться как профессионалам. Мы уже ясно дали понять, использование SQL это не то, что делает файл или группу файлов реляционной базой данных. Можете просто создать свой набор процедур, инструкций и подпрограмм для создания базы данных, не только для работы с уже существующей, но и для создания новой. И если вы не понимаете некоторые из задействованных концепций, в конечном итоге создадите систему, которая со временем станет неустойчивой.
Я это понял, потому что долгое время игнорировал использование SQL или уже существующих реализаций. Я всегда настаивал на создании собственных решений, и, даже если они работали, через некоторое время приходилось делать то, что уже существовало в SQL. И все эти усилия и время можно было бы использовать с большей пользой, если бы я просто начал использовать уже существующее решение.
В следующей статье мы рассмотрим на практике, как данные ключи используются в базе данных. Возможно, таким образом концепция, которая в данный момент является абстрактной, станет более конкретной и понятной.
| Файл | Описание |
|---|---|
| Experts\Expert Advisor.mq5 | Демонстрирует взаимодействие между Chart Trade и советником (для взаимодействия требуется Mouse Study). |
| Indicators\Chart Trade.mq5 | Создает окно для настройки отправляемого ордера (для взаимодействия требуется Mouse Study) |
| Indicators\Market Replay.mq5 | Создайте элементы управления для взаимодействия с сервисом репликации/моделирования (для взаимодействия требуется Mouse Study). |
| Indicators\Mouse Study.mq5 | Обеспечивает взаимодействие между графическими элементами управления и пользователем (необходимо как для работы системы репликации, так и на реальном рынке). |
| Services\Market Replay.mq5 | Создает и поддерживает сервис репликации/моделирования рынка (основной файл всей системы). |
| Code VS C++\Servidor.cpp | Создает и поддерживает серверный сокет, разработанный на C++ (версия Mini Chat) |
| Code in Python\Server.py | Создание и поддержка сокета Python для связи между MetaTrader 5 и Excel. |
| Indicators\Mini Chat.mq5 | Позволяет реализовать мини-чат через индикатор (для работы требуется использование сервера) |
| Experts\Mini Chat.mq5 | Позволяет реализовать мини-чат с помощью советника (для работы требуется сервер). |
| Scripts\SQLite.mq5 | Демонстрирует использование скрипта SQL с помощью MQL5 |
| Files\Script 01.sql | Демонстрирует создание простой таблицы с внешним ключом. |
| Files\Script 02.sql | Показывает добавление значений в таблицу |
Ссылка
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/12985
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования