
Моделирование рынка (Часть 23): Первые шаги на SQL (VI)

Введение
В предыдущей статье Моделирование рынка (Часть 22): Первые шаги на SQL (V) мы рассмотрели вопрос о том, как использовать, или, точнее, как связать первичный ключ с внешним ключом. Если вы не поняли, о чём я говорю, советую вам сначала прочитать предыдущие статьи. Это необходимо для того, чтобы вы действительно поняли, что мы будем здесь делать.
Понимание результатов поиска
Так вот, в предыдущей статье мы создали небольшую базу данных, целью которой было проиллюстрировать использование первичных ключей вместе с внешними ключами. Однако, при выполнении поиска с использованием данной конфигурации мы, скорее всего, получим результат, сильно отличающийся от ожидаемого. Чтобы было понятнее, мы воспользуемся следующим кодом для поиска в базе данных.
SELECT * FROM tb_Quotes;
Код 01
Результат показан ниже.
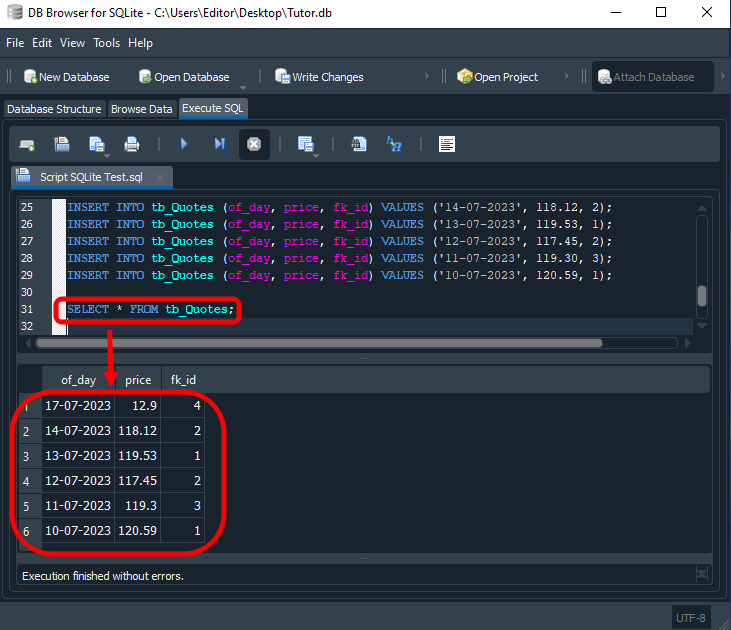
Изображение 01
В итоге можно задаться вопросом: "Что я сделал не так?" Ответ: НИЧЕГО. Многие не используют внешние ключи в своих базах данных именно потому, что не понимают концепцию, лежащую в основе данного типа ключей. Именно поэтому они в итоге создают нереляционные базы данных, что значительно усложняет их обслуживание и саму структуру. Из-за этого объём обработки и нагрузка на SQL становятся заметно выше, чем могли бы быть.
Одно из величайших достижений SQL заключается в возможности создания таблиц, кажущихся изолированными. Однако вам всё же удается каким-то образом связать эти таблицы, или, точнее, значения, содержащиеся в этих таблицах. Это позволяет избежать одной из самых больших проблем, существовавших до появления SQL: дублирования данных. Возможно, вы не понимаете, насколько это вредоносно для базы данных. Но это, по сути, полностью сводит на нет огромное преимущество, которое дает использование SQL при создании баз данных для нашего приложения.
Визуализация диаграммы базы данных
Для визуализации диаграмм существуют различные альтернативы, одни из которых обладают большим или меньшим набором возможностей. В случае с DB Browser, который используется здесь для объяснения некоторых моментов, мы, по сути, не сможем получить подобную диаграмму. Это, по крайней мере, на момент написания данной статьи, так как, поскольку программа с открытым исходным кодом получает обновления через GitHub, вполне возможно, что к тому моменту, когда вы будете читать эту статью, данный ресурс уже появится в DB Browser. Таким образом, альтернативным вариантом может быть использование DBeaver. Это программа с бесплатной версией, которую можно скачать и использовать без особых проблем. Итак, после того, как у нас появится DBeaver, нужно будет выполнить следующие шаги, чтобы просмотреть диаграмму:
Изображение 02
Это откроет новое окно, как показано ниже.
Изображение 03
Здесь нам нужно будет выбрать тип базы данных, которая будет отображаться. Помните, что наша база данных относится к типу SQLite. Затем найдем и выберем её, как показано ниже.

Изображение 04
Отлично, теперь мы увидим следующее окно.
Изображение 05
Здесь необходимо ввести путь и имя открываемой базы данных, как показано ниже.
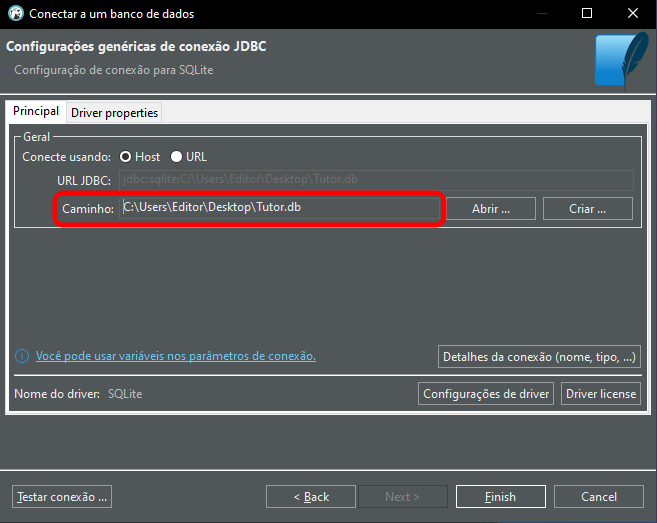
Изображение 06
После этого нажмем "Finish", и перед нами появится последний экран.
Изображение 07
Если всё было сделано правильно, то будет так, как показано на изображении 07, где наша база данных готова к работе. Таким образом, наконец, мы можем открыть диаграмму, щелкнув по выделенным точкам ниже:
Изображение 08
Откроется окно, которое показано ниже:
Изображение 09
Теперь дайте название создаваемой диаграмме, как показано на изображении: Мы можем дать ей любое имя, какое захотим.
Изображение 10
И наконец, нажав кнопку "Finish", мы получим такой результат:
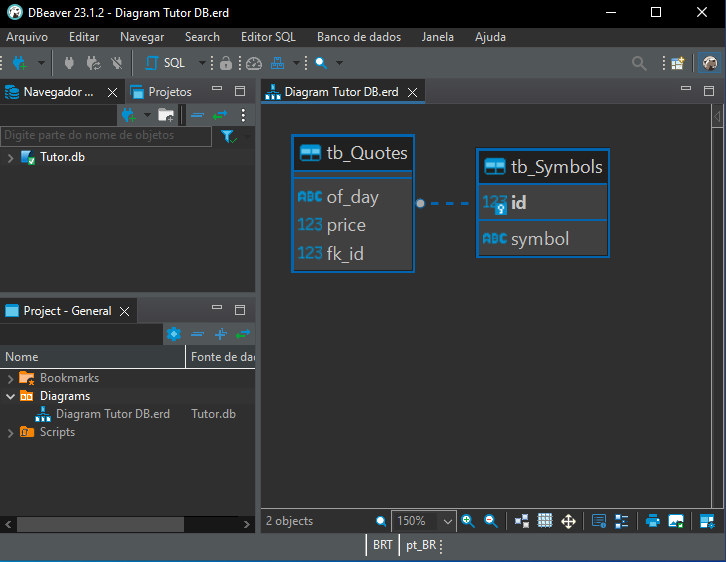
Изображение 11
Понимание смысла диаграммы
На изображении 11 отчетливо видна взаимосвязь между таблицами tb_Quotes и tb_Symbols. Но, возможно, вы считаете, что это отношение типа "один к одному". Иными словами, для каждой записи в таблице tb_Symbols будет соответствующая запись в таблице tb_Quotes. Такое может произойти даже в некоторых ситуациях. Но обратите внимание на одну деталь этой диаграммы. Это тонкий, но важный момент. На изображении ниже выделен именно тот момент, на который стоит обратить внимание.
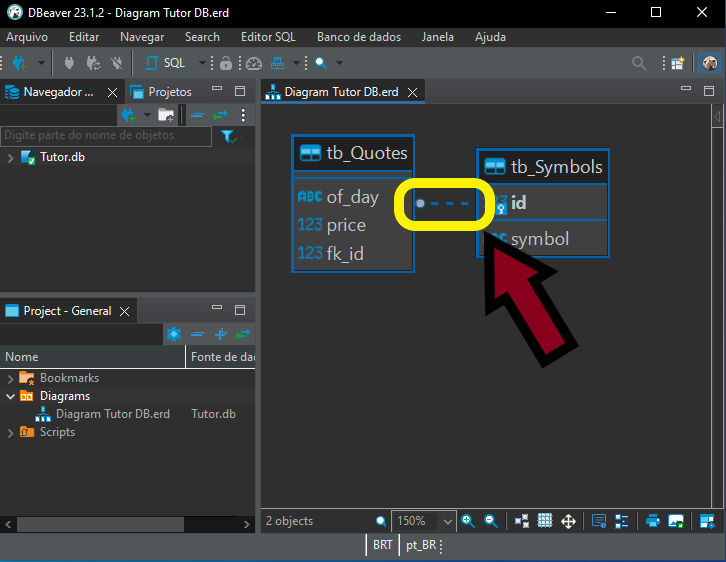
Изображение 12
Прошу заметить, что с одной стороны у нас маленький шарик, а с другой — ничего. Обратите на это самое пристальное внимание. Но что это значит? Это указывает на связь "один ко многим". Иными словами, на той стороне или таблице, где находится шарик, у нас может быть множество записей для каждой из записей в таблице, к которой привязана данная строка. Умение правильно интерпретировать подобные вещи позволит нам более грамотно составлять поисковые запросы. Это также позволит нам вносить изменения в базу данных гораздо проще и без ошибок.
Это связано с тем, что наличие в таблице записи, которая может повторяться многократно в одной или нескольких других таблицах, поможет нам понять и правильно спроектировать работу триггеров — будь то добавление новых данных, удаление записи или даже обновление информации в базе данных. Но это тема для другого разговора. На этом этапе нам необходимо понять, как данный тип связи может помочь нам правильно визуализировать содержимое базы данных.
Перевод данных в SQL
Итак, мы пока только рассмотрели создание диаграммы базы данных. Теперь мы вернемся к DB Browser, помня при этом, что мы также можем использовать MetaEditor, чтобы увидеть тот же результат, что и здесь, и использовать немного другой код для выполнения поиска в базе данных Код, о котором идёт речь, приведён ниже:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes, tb_Symbols;
Код 02
Таким образом, при выполнении этого скрипта SQL вернет 24 записи. Но почему? Давайте посмотрим, что здесь произошло. Обратите внимание на результат выполнения кода на изображении ниже:
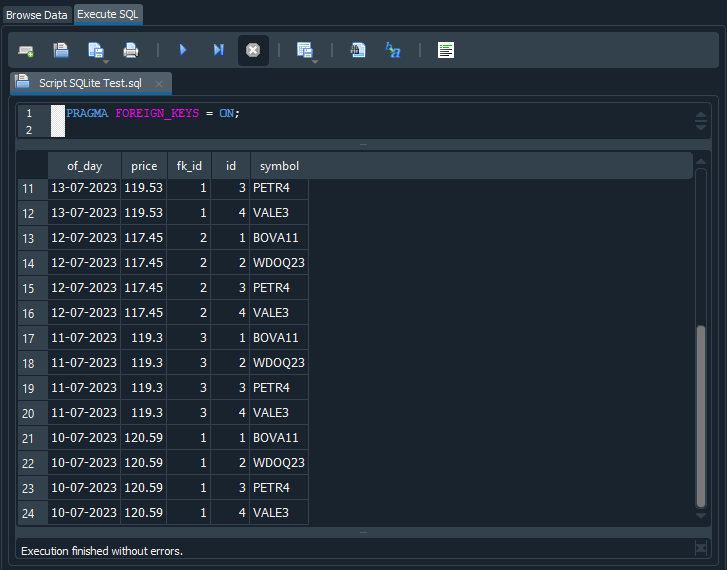
Изображение 13
Можно заметить, что между записями в строках 17 и 20 повторяется одно и то же значение, как котировка, так и дата. То есть SQL интерпретировал это так, что он должен выполнить команду SELECT и каким-то образом объединить содержимое таблиц tb_Quotes и tb_Symbols. По этой причине мы получаем повторяющиеся значения из таблицы tb_Quotes, в то время как значения в таблице tb_Symbols меняются, так как у нас есть шесть записей в таблице tb_Quotes и четыре записи в таблице tb_Symbols. Таким образом, объединив обе таблицы, SQL генерирует представленные нам 24 записи. Теперь понятно, почему SQL выдает нам 24 записи?
Но обратите внимание на кое-что на изображении 13. В некоторых случаях значение fk_id совпадает со значением id. Интересно, не правда ли? Но почему это происходит? Дело в том, что значение записи в fk_id указывает, какое значение нам следует искать. Теперь вернёмся к нашей диаграмме из изображения 12. Там мы видим, что значение id находится в таблице tb_Symbols, а значение fk_id — в таблице tb_Quotes.
Итак, теперь нам нужно использовать нечто, известное как псевдоним. Другими словами, нам нужно придумать псевдоним, чтобы иметь возможность связать одну таблицу с другой. Это нужно для того, чтобы SQL знал, как скомпоновать данные, чтобы они были представлены нам правильно. При использовании псевдонима следует проявлять осторожность и не использовать зарезервированные слова. Некоторые реализации справляются с этим, однако, в целом, и даже во избежание путаницы со стороны других SQL-программистов, следует избегать использования зарезервированных слов в качестве псевдонимов в SQL-коде. Таким образом, новый код, который будет выполнен, показан ниже:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * 32. FROM tb_Quotes AS tq, tb_Symbols AS ts 33. WHERE tq.fk_id = ts.id;
Код 03
При выполнении данного кода мы получим результат, показанный на изображении ниже:
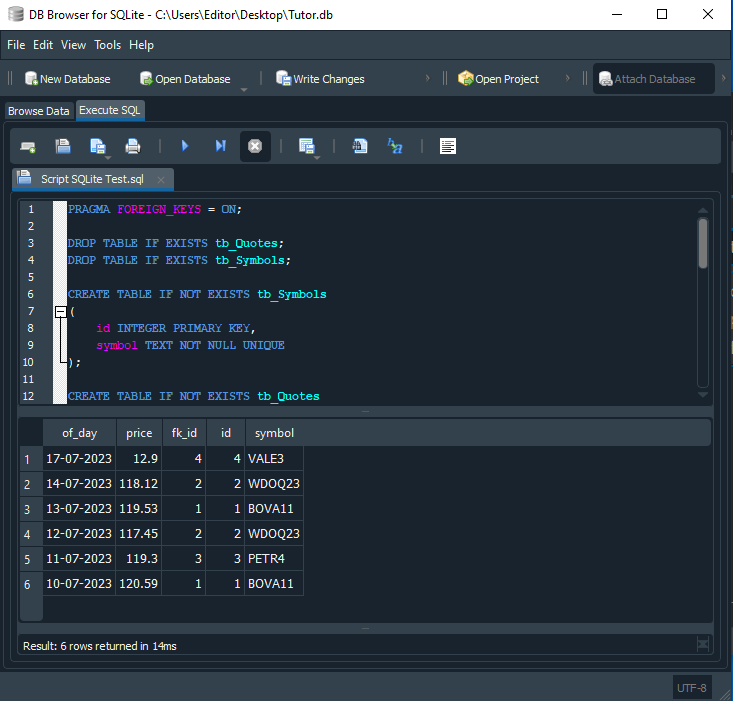
Изображение 14
Как по волшебству, теперь у нас есть именно то, что мы ожидали. То есть мы видим шесть записей котировок с указанием символа, даты и цены инструмента. Теперь давайте разберемся, почему это происходит. Прошу заметить, что в строке 32 скрипта после имени каждой из таблиц мы добавляем псевдоним для работы с этими таблицами.
Для того чтобы SQL понимал, как связать каждую из этих таблиц и предоставить нам правильный результат, мы используем строку 33. В этом контексте мы используем инструкцию WHERE, которая определяет критерии, используемые для фильтрации или формирования результата. В данном случае мы хотим, чтобы, когда значение fk_id в таблице tb_Quotes совпадает со значением id в таблице tb_Symbol, этот результат фиксировался SQL для его последующего вывода. Таким образом, команда SELECT переберет все возможные комбинации, как показали ранее. Однако из-за фильтра SQL вернет только то, что было фактически запрошено.
Небольшое уточнение к приведенному выше объяснению. Строго говоря, SQL не обязательно физически перебирает все возможные комбинации строк; движок выбирает более эффективный способ выполнения запроса между таблицами. Такие действия приведут к очень быстрому снижению общей производительности системы. На самом деле происходит следующее: SQL использует одну из таблиц для начала формирования результатов, а затем ищет в другой таблице необходимые поля для проведения соответствующих сравнений и сопоставлений. Таким образом, поиск осуществляется гораздо эффективнее.
Мы можем ещё больше улучшить результаты, которые возвращает SQL-запрос. Нередко случается так, что названия столбцов кажутся довольно странными, а иногда, как вы видели на изображении 14, SQL возвращает столбцы, которые нам не нужны. Как нам отфильтровывать подобную информацию? Всё очень просто. Достаточно указать в SQL, какие столбцы нам нужны и какие названия они должны иметь. Таким образом, мы переходим к скрипту, представленному ниже:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id;
Код 04
В результате мы видим это:
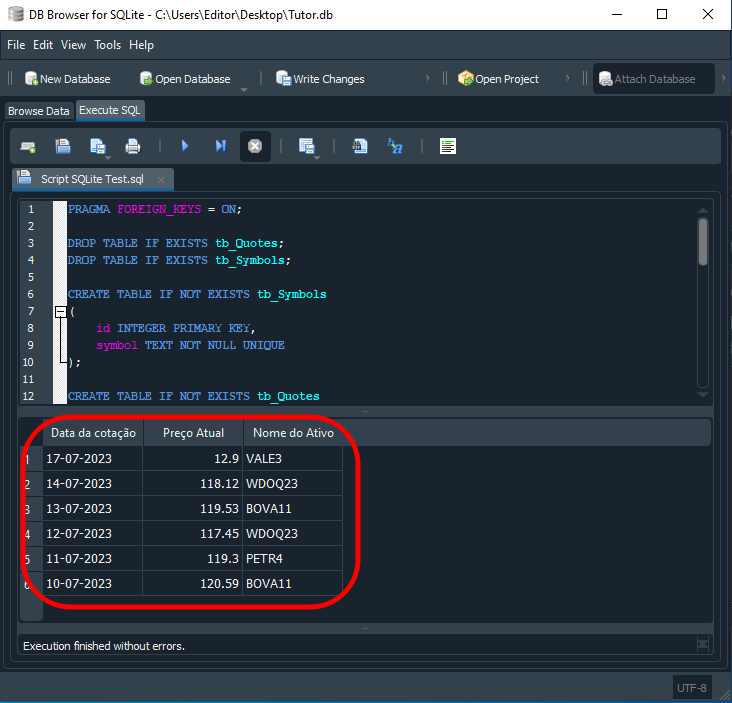
Изображение 15
"Ух ты! Значит, SQL оказался не совсем таким, каким я его себе представлял? Мне всегда казалось, что это просто набор бессмысленных инструкций, но теперь я понимаю, что на самом деле это может быть очень интересно". Но это всего лишь разминка. Многие считают, что нам необходимы внешние программы для дальнейшей обработки информации, которая будет нам предоставлена, но это можно сделать непосредственно в SQL. Например: Допустим, нам нужны данные в определенном порядке, с самыми высокими ценами в начале и самыми низкими в конце. Для этого мы используем код, подобный показанному ниже:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id 36. ORDER BY price DESC;
Код 05
Результатом выполнения кода 05 с помощью SQL будет то, что мы видим далее:
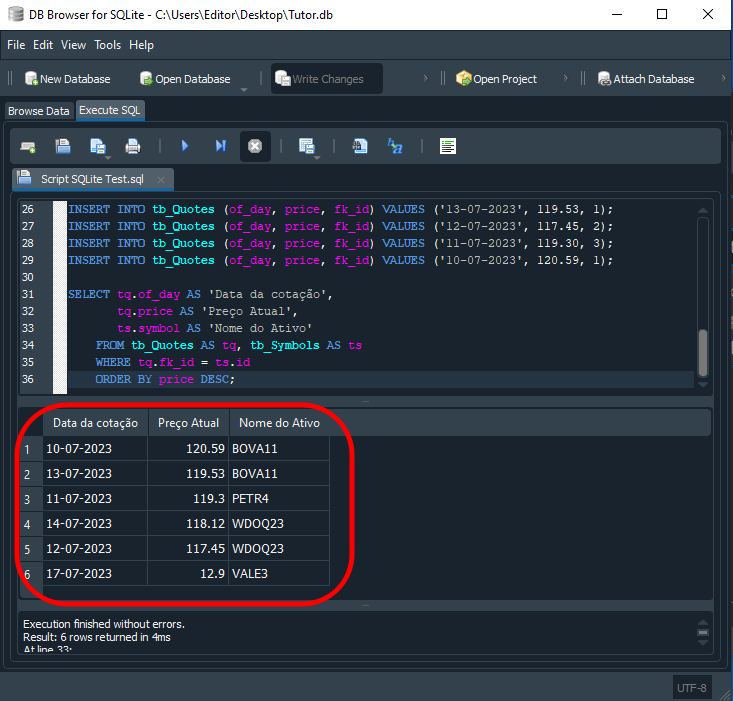
Изображение 16
Осторожнее с записями
В статье Моделирование рынка (Часть 19): Первые шаги на SQL (II) мы объяснили, как можно изменять или обновлять записи с помощью команд UPDATE и DELETE. Хотя всё работает, это не лучший способ работы с реляционной базой данных, так как данный подход чреват ошибками при наличии нескольких связанных между собой таблиц. Чтобы понять проблему, вернёмся к коду 05, где мы сделаем нечто очень простое. Обратите внимание: до строки 29 мы создаём базу данных и добавляем в неё данные. Неважно, корректны ли данные; мы просто хотели создать базу. Таким образом, при выполнении запроса SELECT в строке 31 мы получаем результат, показанный ниже:
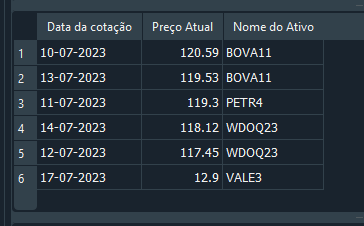
Изображение 17
И в этот момент замечаем, что в записи содержится некорректная информация. Но вместо того, чтобы пересоздавать всю базу данных или удалять запись, решаем использовать команду UPDATE для обновления значения до правильного. Это делается таким образом:
1. UPDATE tb_Quotes SET price = 29.58 WHERE fk_id = 3; 2. 3. SELECT tq.of_day AS 'Data da cotação', 4. tq.price AS 'Preço Atual', 5. ts.symbol AS 'Nome do Ativo' 6. FROM tb_Quotes AS tq, tb_Symbols AS ts 7. WHERE tq.fk_id = ts.id 8. ORDER BY price DESC;
Код 06
И получаем результат, представленный ниже:
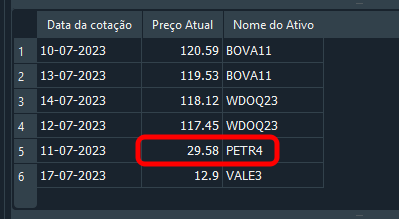
Изображение 18
Хорошо. Запись обновлена, и вы чувствуете себя счастливо, воображая, что уже умеете работать с SQL. Однако, если взглянуть на код 05, где мы включаем данные в базу данных, можно заметить, что существует только одна запись о PETR4. В таком случае информацию можно было бы легко изменить или даже удалить. Давайте теперь немного подумаем. А что, если вместо PETR4 нам понадобится изменить запись для WDOQ23? Как бы мы внесли это изменение? Можно сразу сказать: "Всё просто, я бы использовал следующую команду":
01. UPDATE tb_Quotes 02. SET price = 119 03. WHERE fk_id = 2 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Код 07
Вы снова правы, так как результат — тот, что мы видим ниже: Это произошло так, потому что мы умело отфильтровали результаты на основе fk_id и of_day.
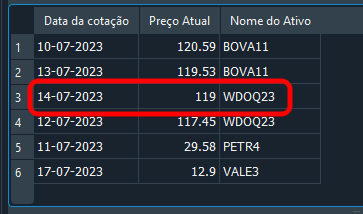
Изображение 19
Обновление записи в реляционной базе данных
Хороший (хотя и не единственный) способ редактирования реляционной базы данных — это понимание того, что именно делает каждая SQL-команда. Или, лучше сказать: если вы не понимаете SQL-команды, вы решите, что SQL — крайне ограниченный язык. Но, если вы его поймете, вы сможете многое сделать. И когда я говорю "много", имею в виду, по сути, очень много вещей. Я уже видел, как люди используют внешнее программирование для решения задач, которые можно было бы решить напрямую с помощью SQL. Причина, по которой так поступают, заключается в том, что они неправильно понимают, как работает SQL. Исходя из этого, давайте разберем, как внести те же изменения, что и в предыдущей теме, но на этот раз нам не придется прописывать значение fk_id вручную.
На этом этапе вы, должно быть, думаете: "Итак, будем ли мы использовать нереляционную табличную систему?" Нет, уважаемый читатель. Мы сохраним реляционную основу. Таким образом, чтобы достичь той же цели, что и в предыдущем разделе, мы обновим код 07 следующим образом.
01. UPDATE tb_Quotes 02. SET price = 4985.5 03. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Код 08
"Брат, что это за безумие такое? Ты уверен, что это сработает? Ну, я никогда не видел, чтобы кто-то делал что-то настолько безумное". Ваш скептицизм вполне оправдан, уважаемый читатель. Но посмотрите на результат ниже:
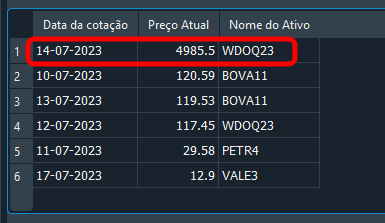
Изображение 20
Прошу заметить, что мы использовали несколько иное значение именно для того, чтобы показать, что это работает. Итак, вопрос: как работает приведенный выше код? Обратите внимание, что мы ни в коем случае не указываем, что такое fk_id или по какому идентификатору следует искать. Тем не менее, правильная запись изменена. Мы сообщаем название символа, а также соответствующую дату. Поскольку мы указываем название символа, а также дату, о которой идёт речь. Важный момент: хотя каждая запись содержит свою дату, вам стоит мыслить более реалистично. Иными словами, даже в одну и ту же дату в базе данных могут встречаться символы с разными ценами. Таким образом, использование двойной фильтрации, при которой мы указываем дату и символ, существенно повышает точность поиска и возвращает именно ту информацию, которая была запрошена.
Не знаю, заметили ли вы, но мы только что объяснили, как работает показанный выше код. Если вы не поняли или не усвоили смысл, не расстраивайтесь. На самом деле, подобные вещи сложно понять с первой минуты. Но давайте внимательно разберемся с тем, что происходит в коде 18. Прошу заметить, что команда UPDATE размещена на нескольких строках. Мы так сделали специально, чтобы объяснить происходящее.
Итак, в строке 01 мы указываем, что хотим обновить запись в таблице tb_Quotes. Если бы вместо UPDATE мы указали DELETE, запись была бы удалена из таблицы. Таким образом, всё, что мы объясняем, также применимо к удалению записей. Уже в строке 02 мы точно указываем, какой столбец будет обновлен, а также значение, которое должно остаться в столбце после обновления. Думаю, до этого момента всем удается следовать за ходом мысли. Теперь, в строке 03 с использованием зарезервированного слова WHERE, мы можем указать критерии фильтрации, чтобы SQL знал, как найти нужную запись. Итак, теперь слушайте очень внимательно, потому что именно здесь кроется то, что многие новички не могут понять.
Каждая из этих команд, по сути, является функцией, иными словами, они возвращают значения. Это может быть как одиночное значение, так и составное, содержащее в данном случае несколько других значений или полей. Таким образом, при использовании команды SELECT мы можем получить в результате только одно значение, как в этом случае. Но мы также можем получить возврат со множеством значений, содержащихся в структуре, подобной таблице, — именно так, как это происходит при выполнении команды SELECT в строке 06.
Когда фильтрация выполняется очень специфическим образом и в столь же специфичной таблице, команда SELECT возвращает нечто уникальное, и, следовательно, данный результат можно рассматривать как переменную. "Но подождите секунду. SQLite не позволяет нам использовать переменные, верно?" ? Ну, более или менее. Однако, если мы умеем работать с SQL, а не только с SQLite, можно фактически использовать переменные внутри SQL-кода. Данная проблема станет более понятной позже, поскольку нам потребуется предпринять дополнительные действия при использовании связанных таблиц для обеспечения согласованности базы данных.
Но, возвращаясь к объяснению: заметьте, что в этой строке 03 мы указываем название символа — в данном случае WDOQ23. Это заставляет SQL искать что-то в таблице tb_Symbols, которую мы указываем в команде SELECT, когда ищем что-то. Что же это за "что-то"? Это "что-то" — значение ts.id. Иными словами, когда поиск завершится, SELECT вернет значение ID из той строки, где название символа — WDOQ23. Интересно. Затем SQL выполнит поиск в одной таблице значения, которое укажет нам, в какой таблице следует искать нужную запись, чтобы найти именно ту, в которой мы хотим внести нужные изменения. И это всё? Так и есть, именно этим мы здесь и занимаемся, уважаемый читатель. Следует отметить, что вероятность ошибки в данном случае значительно ниже.
Однако не всё так идеально. Возможно, мы сообщим об имени символа, идентификатор которого не найден. Хотя это может показаться странным, такие ситуации довольно распространены в повседневной жизни. Следовательно, код 08 не сможет должным образом обработать подобную ситуацию. Или, чтобы было понятнее: мы можем попытаться что-то сделать, и SQL не скажет нам, что это ошибка или что команда была понята неправильно. И нам остаётся лишь представлять, что всё прошло идеально, поскольку в результате мы получим представление о результатах выполнения команды SELECT из строки 06.
На данном этапе мы можем не понимать, почему это проблематично, поскольку, если реализация не указывает на какие-либо ошибки, у нас останется иллюзия, что всё идеально. Но когда в будущем мы решим найти или даже использовать те данные, которые, как мы думали, там есть, нас ждет неприятный сюрприз: информация окажется совсем не в том виде, в каком ожидалось. И зачастую получить необходимую информацию для правильного устранения подобных сбоев оказывается невозможно.
Проверка обновления записи
Чтобы проверить, было ли успешно обновлено значение записи, которую мы хотим обновить, в SQLite есть относительно простой способ это сделать. Для этого нам понадобится небольшой фрагмент кода. Но прежде чем мы перейдем к коду, нам нужно кое о чем подумать. Нередко можно услышать мнение, что после обновления или даже добавления записи в базу данных следует выполнить оператор SELECT, чтобы проанализировать, всё ли прошло успешно. Но в этом подходе есть небольшая проблема. Если мы работаем с небольшой базой или с той, в которой по какой-то причине было внесено мало изменений, использование SELECT для проверки того, всё ли прошло как надо, — это действительно подходящий способ анализа того, успешно ли обновилась база Однако, особенно в базах данных с общим доступом, если нам нужно обновить несколько записей, проверить это с помощью оператора SELECT будет не так-то просто.
К счастью, эти общие базы данных используют серверы. Следовательно, SQLite не попадает под эту ситуацию. Но даже в базе данных, использующей SQLite, может возникнуть необходимость обновить сотни или даже тысячи записей. Только представьте, сколько работы потребуется, чтобы проверять всё по одному, используя SELECT для подтверждения того, правильно ли обновилась база. Именно данный вопрос заставляет нас принять несколько иные меры. Проверка каждой обновленной записи по отдельности вполне допустима, если мы вносим лишь незначительные изменения в базу данных.
Однако, по мере увеличения рабочей нагрузки и количества операций, нам необходимо внедрить иной подход к работе. Помимо метода, который мы вам покажем чуть позже, есть ещё один, почти эквивалентный способ, но мы рассмотрим его позже. На данном этапе давайте сосредоточимся на первой задаче. То есть, как мы можем тем или иным способом, используя SQLite, узнать, были ли выполнены все запросы на обновление записей или нет.
Для этого есть довольно простое решение. Однако вам следует быть осторожными, чтобы избежать каких-либо сбоев из-за неправильного использования того, что мы показываем. Демонстрационный код показан ниже:
1. UPDATE tb_Quotes 2. SET price = 4987.5 3. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 4. AND of_day = '14-07-2023'; 5. 6. SELECT changes() 'Updated Records';
Код 09
При выполнении этого кода мы увидим следующий результат:
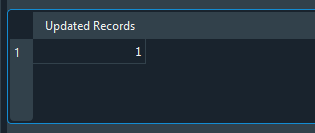
Изображение 21
Прошу заметить, что в результате мы получаем значение, равное единице. Почему? Причина в том, что оператор UPDATE выполняет однократное обновление или изменение базы данных. Если бы мы выполнили сотни или даже тысячи обновлений, отображаемое значение точно соответствовало бы количеству успешных выполнений оператора UPDATE. Однако обратите внимание на следующий факт: если бы тот же самый код, показанный выше, был изменен в соответствии с тем, что показано на рисунке ниже, результат был бы другим, как можно увидеть на том же изображении:
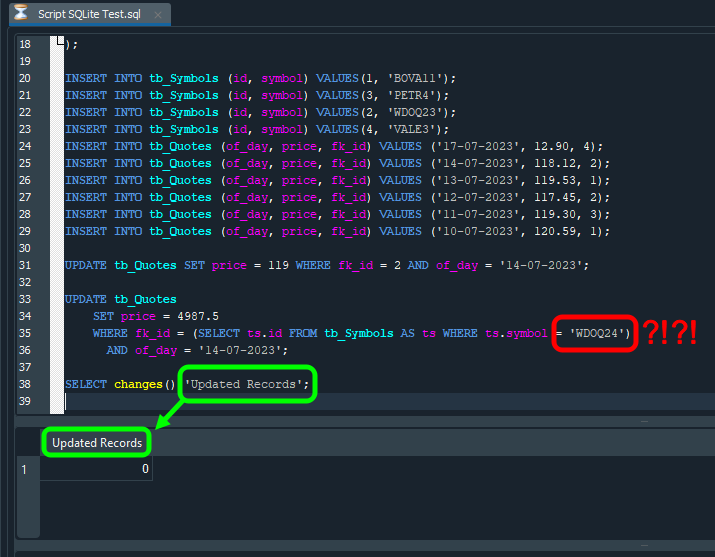
Изображение 22
На этом изображении мы выделили красным цветом то, что было изменено по сравнению с тем, что было сделано ранее. Обратите внимание, что единственное изменение коснулось названия символа. А поскольку такого имени идентификатора не существует, команда SELECT не сможет определить, какой следует использовать. Следовательно, команду UPDATE нельзя выполнять с помощью SQL. Наконец, при использовании команды SELECT, цель которой — проверить количество успешно выполненных операций UPDATE, она вернет число, отличающееся от ожидаемого нами. В данном случае — это ноль, поскольку мы ожидали выполнения операции UPDATE. Однако, поскольку мы указали имя символа, которого нет в таблице, команда UPDATE не была выполнена.
На изображении выше есть ещё одна деталь. Она выделена зелёным цветом. В данном случае мы имеем в виду, что заголовок сообщения, которое будет отправлено SQL, — это именно та информация, которая содержится в команде SELECT. Не зная этого, мы можем поддаться искушению поступить иначе. Но, как видите, мы можем контролировать некоторые вещи с относительной легкостью.
Однако, как мы уже упоминали, используемая нами команда предназначена только для проверки того, сколько раз команда была выполнена правильно или нет. Поскольку SQLite позволяет нам разрабатывать локальные и пользовательские базы данных, мы можем делать всё совершенно по-другому.
Да, и для тех, кто не знал, SQLite можно загрузить непосредственно из репозитория GitHub и модифицировать его исходный код, так что мы можем заставить его работать немного иначе, чем обычно. Поскольку цель данной серии статей, по сути, не в том, чтобы показать, как это сделать, мы лишь упоминаем этот факт, в зависимости от используемой реализации SQLite она может обрабатывать ошибки обновления или добавления новых записей совершенно иначе, чем тот способ, который мы показываем. Другими словами, чтобы найти наилучший способ решения задачи, мы предлагаем изучить документацию той реализации, которую вы хотите использовать.
Но прежде чем перейти к следующей теме, давайте рассмотрим подробнее представленный нами метод проверки обновления базы данных. В данном случае комбинация SELECT changes() покажет только результат последнего выполнения команды UPDATE. Итак, предположим следующее: мы используем фрагмент кода, показанный ниже:
1. UPDATE tb_Quotes SET price = 119 WHERE fk_id = 2 AND of_day = '14-07-2023'; 2. 3. UPDATE tb_Quotes SET price = 4987.5 WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ24') AND of_day = '14-07-2023'; 4. 5. SELECT changes() 'Updated Records';
Код 10
Обратите внимание, что теперь у нас запущены две команды UPDATE. Разумеется, мы ожидаем получить совокупный результат или что-то репрезентативное, поскольку, теоретически, мы используем один и тот же скрипт. Но так это не работает. Если внимательно изучить код в строке 03, мы заметим, что он в точности совпадает с кодом, показанным на изображении 22. Таким образом, всё, что было добавлено в этом коде 10, находится в строке 01. Хорошо. Таким образом, даже если строка 03 завершится ошибкой (а это обязательно произойдет), при выполнении строки 05 вернется ненулевое значение. Но при запуске кода мы заметим, что значение, выданное SQL, равно нулю. Что пошло не так? Возможно, обе строки (01 и 03) не выполнились должным образом? Нет, они не потерпели неудачу. Ошибка фактически произошла только в строке 03.
Но как? Поскольку перед анализом результата выполнения строки 01 мы сделали новый запрос к SQL в строке 03, то когда мы попросим SQL сообщить нам о произошедшем, он выдаст результат только последней операции. То есть, именно ошибка в строке 03. Некоторые люди сходят с ума, пытаясь понять, почему скрипт работает (или не работает) так, как ожидалось. Но в конечном итоге всё сводится к тому, что мы, скорее всего, делаем предположения. Когда мы начинаем делать предположения в программировании, дела обычно идут не очень хорошо, потому что предположения означают, что мы просто ожидаем, что что-то произойдет, а не гарантируем, что это произойдет. Поэтому никогда не делайте предположений. Убедитесь, что всё работает, прежде чем начинать проклинать всех.
Заключительные идеи
Но, так или иначе, есть еще один факт (или сложность), с которым нам нужно разобраться при использовании связанных баз или таблиц — таких, как в нашей системе, где в одной таблице хранятся названия символов, а в другой — данные о котировках. Подобная схема могла бы быть гораздо более сложной и иметь несколько связей, используя несколько таблиц, которые поддерживали бы тесную взаимосвязь друг с другом. Всё это осуществляется с помощью первичных и внешних ключей.
Чтобы понять масштаб проблемы или сложность задачи, с которой нам предстоит столкнуться, я хочу, чтобы вы подумали и представили себе следующий сценарий: в какой-то момент в будущем будет принято решение о прекращении использования определенного символа. Это происходит так, потому что его больше неинтересно хранить или наблюдать за ним. Хорошо. Такое решение может произойти рано или поздно. Главная проблема, и именно здесь мы столкнулись с трудностями, заключается в следующем: как удалить записи о символах из базы данных? Многие скажут, что решение весьма простое. Нам просто нужно создать какой-либо цикл или запрос к SQL, чтобы удалить записи за нас. Да, на самом деле, это было бы примерно так, если бы мы работали с базой данных, где у нас есть одна огромная таблица записей, что, на мой взгляд, является полнейшим безумием. Но ничего страшного, все знают, или должны знать, что делают.
Запрос к SQL на удаление всех записей определенного символа был бы очень простой задачей. Всё, что вам нужно будет сделать, — это выполнить DELETE. Сама команда будет выглядеть очень похоже на команду UPDATE. Нечто незначительное, о чём мы не будем здесь подробно рассказывать. Но что, если база данных использует не одну таблицу, а несколько таблиц, которые так или иначе связаны друг с другом? Как можно удалить все записи, которые относятся к определенному символу? Да, теперь всё стало немного сложнее, не так ли?
Теперь я хочу, чтобы вы подумали о схеме, которую мы используем: если бы вы удалили имя символа из таблицы tb_Symbols, вы бы непременно получили определенный результат при поиске в базе данных. Это делается с помощью команды, показанной ниже.
SELECT tq.of_day AS 'Data da cotação', tq.price AS 'Preço Atual', ts.symbol AS 'Nome do Ativo' FROM tb_Quotes AS tq, tb_Symbols AS ts WHERE tq.fk_id = ts.id ORDER BY price DESC;
Код 11
| Файл | Описание |
|---|---|
| Experts\Expert Advisor.mq5 | Демонстрирует взаимодействие между Chart Trade и советником (для взаимодействия требуется Mouse Study). |
| Indicators\Chart Trade.mq5 | Создает окно для настройки отправляемого ордера (для взаимодействия требуется Mouse Study) |
| Indicators\Market Replay.mq5 | Создает элементы управления для взаимодействия с сервисом репликации/моделирования (для взаимодействия требуется Mouse Study). |
| Indicators\Mouse Study.mq5 | Обеспечивает взаимодействие между графическими элементами управления и пользователем (необходимо как для работы системы репликации/моделирования, так и на реальном рынке). |
| Services\Market Replay.mq5 | Создает и поддерживает сервис репликации/моделирования рынка (основной файл всей системы). |
| Code VS C++\Servidor.cpp | Создает и поддерживает серверный сокет, разработанный на C++ (версия Mini Chat) |
| Code in Python\Server.py | Создает и поддерживает сокет Python для связи между MetaTrader 5 и Excel. |
| Indicators\Mini Chat.mq5 | Позволяет реализовать мини-чат через индикатор (для работы требуется использование сервера) |
| Experts\Mini Chat.mq5 | Позволяет реализовать мини-чат с помощью советника (для работы требуется сервер). |
| Scripts\SQLite.mq5 | Демонстрирует использование скрипта SQL с помощью MQL5 |
| Files\Script 01.sql | Демонстрирует создание простой таблицы с внешним ключом. |
| Files\Script 02.sql | Показывает добавление значений в таблицу |
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/12987
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования