
EA baseado em rede neural com PatchTST

Introdução
Lembra-se da época em que o RSI em sobrecompra indicava uma correção iminente e o MACD mostrava claramente uma mudança de tendência? Esses dias ficaram para trás. Os mercados modernos são complexos demais para indicadores matemáticos simples. Traders algorítmicos abocanham a maior parte dos lucros usando aprendizado de máquina, enquanto os traders de varejo continuam confiando em ferramentas de meio século atrás.
A morte dos indicadores tradicionais: anatomia de um fracassoPara entender a dimensão do problema, vejamos as estatísticas. Na década de 1990, uma estratégia simples baseada no cruzamento de médias móveis era rentável em 65 a 70% das operações com os principais pares de moedas. Em 2010, esse índice caiu para 52%. Hoje, oscila em torno do nível esperado para uma escolha aleatória, em torno de 50%.
A causa não está no fato de a matemática ter mudado. O problema está na forma como o mercado se adapta. Quando milhões de traders utilizam os mesmos sinais, o próprio mercado começa a incorporá-los. Isso cria um ciclo de retroalimentação: o indicador se transforma em uma profecia autonegadora. Jim Simons já falava sobre isso: é como uma manada de camelos no deserto. Para um camelo, um oásis dura muito tempo, mas uma enorme manada bebe rapidamente toda a água e volta a ser atormentada pela sede.
Ademais, os mercados modernos estão sujeitos a fatores inexistentes no momento em que o RSI e o MACD foram criados. A negociação de alta frequência gera ruídos microestruturais, que são interpretados pelos indicadores tradicionais como sinais falsos. Fundos algorítmicos, que gerenciam bilhões de dólares em ativos, podem criar artificialmente esses padrões, atraindo traders de varejo para armadilhas.
Já os indicadores tradicionais se baseiam em hipóteses lineares sobre o comportamento do mercado. O RSI pressupõe que valores extremos levam a uma correção. As médias móveis partem da ideia de que o preço tende ao valor médio. O MACD é construído sobre a ideia de que tendências de curto prazo interagem de forma previsível com tendências de longo prazo. Todas essas hipóteses funcionavam nos mercados menos eficientes do passado, mas entram em colapso nas condições do trading algorítmico moderno.
Redes neurais: a primeira tentativa de evoluçãoA primeira geração de traders que percebeu as limitações da análise técnica recorreu a redes neurais simples. Os perceptrons multicamadas dos anos 1990 pareciam revolucionários. Eles conseguiam identificar dependências não lineares que escapavam à detecção de indicadores lineares.
No entanto, esses sistemas também tinham limitações fundamentais. As redes neurais simples não conseguiam processar sequências de dados de maneira eficiente. Elas analisavam cada barra isoladamente, perdendo o contexto da dinâmica temporal. Isso era especialmente crítico para os mercados financeiros, nos quais o movimento atual do preço está indissociavelmente ligado aos eventos anteriores.
As redes neurais recorrentes (RNN) e as redes LSTM resolveram parcialmente esse problema, porém trouxeram outros. O problema do gradiente desvanecente tornava o treinamento de sequências longas praticamente impossível. Além disso, para tomar decisões bem fundamentadas, os mercados financeiros exigem a análise de centenas, às vezes milhares, de barras históricas.
As LSTM apresentavam melhores resultados em sequências de até 50 a 100 elementos, mas começavam a perder eficiência em séries temporais mais longas. O problema estava na arquitetura: a informação precisava passar por vários estados intermediários, perdendo relevância ao longo do processo. Para dados financeiros, nos quais um evento ocorrido uma semana antes pode ser crítico para a previsão atual, essas limitações eram inaceitáveis.
Transformers: ruptura e obstáculosA revolução começou em 2017 com a publicação do artigo "Attention Is All You Need". Embora os transformers tenham mudado radicalmente o processamento de sequências em NLP, sua aplicação a séries temporais financeiras esbarrou em sérios obstáculos.
O principal problema é a complexidade computacional. O mecanismo de atenção exige o cálculo das correlações entre cada par de elementos da sequência. Para uma sequência de comprimento N, isso resulta em O(N²) operações. Com N igual a 1000 barras, o mínimo necessário para uma análise robusta, o número de operações chega a um milhão. Cada operação envolve uma multiplicação matricial de alta dimensionalidade, tornando os cálculos extremamente custosos do ponto de vista computacional.
Além disso, os transformers tradicionais são projetados para tokens discretos, ou seja, palavras em um texto. Porém, os dados financeiros são séries temporais contínuas, com uma estrutura interna complexa. Aplicar transformers diretamente aos dados de preço ignora essa especificidade. A tokenização, ao considerar apenas uma barra de cada vez, perde informações importantes sobre padrões locais dentro de janelas temporais curtas.
As tentativas de adaptar transformers do tipo vanilla para dados financeiros esbarravam no problema do sobreajuste. O modelo memorizava com facilidade sequências específicas dos dados de treinamento, mas não conseguia aplicar o conhecimento adquirido a novas situações de mercado. Esse problema ficava especialmente evidente em períodos de alta volatilidade ou de mudanças estruturais no mercado.
Nesse contexto, surge o PatchTST: uma arquitetura que redefine a forma como as redes neurais analisam séries temporais financeiras. Ele não é apenas mais um transformer, mas um sistema especialmente adaptado que entende a natureza dos dados de mercado e trabalha com eles como um verdadeiro trader profissional.
O conceito de patches: dos pixels às barrasA ideia dos patches vem da visão computacional. O Vision Transformer (ViT) divide a imagem em patches quadrados, processando cada um como um token separado. O PatchTST aplica um princípio semelhante a esse às séries temporais, mas com um entendimento profundo dos dados financeiros.
Cada patch no PatchTST corresponde a um segmento de 16 barras consecutivas. Essa escolha não é aleatória. A análise da volatilidade mostra que uma janela de 16 barras é ideal para capturar padrões locais do movimento do preço e preservar a eficiência computacional ao mesmo tempo. Padrões como "cabeça e ombros", "bandeira" e "flâmula", por exemplo, geralmente se desenvolvem em janelas temporais como essa.
Dentro de cada patch, o modelo captura a microestrutura do movimento, ou seja, como o preço de abertura se relaciona com o fechamento, quais foram as máximas e mínimas e como o volume variou. Entre os patches, o modelo acompanha as macrotendências, como a evolução das tendências, as mudanças no sentimento do mercado e os padrões cíclicos. Essa representação hierárquica permite analisar simultaneamente oportunidades táticas de curto prazo e o quadro estratégico de longo prazo.
Arquitetura multicanal: enxergar mais dimensõesDiferentemente dos sistemas simples, que analisam apenas o preço de fechamento, o PatchTST trabalha com dados multicanal. Sua implementação básica utiliza dois canais: o de variações de preço, que representa a diferença normalizada entre o preço de fechamento e o de abertura; e o de volumes, que contém o volume de ticks normalizado logaritmicamente.
Essa abordagem permite que o modelo não apenas veja "o que aconteceu" (movimento de preço), como também "com que força" (atividade de volume). Volume elevado com movimento de preço pouco expressivo sinaliza acúmulo de posições por grandes players. Um movimento brusco com baixo volume pode indicar um rompimento técnico sem suporte fundamental, antecipando uma correção rápida.
A arquitetura de dois canais cria um rico espaço informacional. Com o tempo, o modelo aprende a associar determinadas combinações de movimentos de preço e volumes a resultados futuros. A redução gradual dos volumes com o preço em alta, por exemplo, muitas vezes antecede a reversão da tendência. Um pico de volume no rompimento de um nível significativo confirma a força do movimento.
Mecanismo de atenção no contexto financeiroO mecanismo de atenção no PatchTST funciona de maneira diferente dos modelos de linguagem. Em vez de analisar relações semânticas entre palavras, ele busca correlações temporais entre eventos de mercado. Imagine a seguinte situação: um gap de baixa pela manhã muitas vezes resulta em um movimento de recuperação à tarde. Indicadores tradicionais não capturam dependências de longo prazo.
O mecanismo de atenção do PatchTST detecta automaticamente esses padrões e lhes atribui os pesos de atenção correspondentes. Se o modelo perceber que uma determinada combinação de volume e movimento de preço pela manhã se correlaciona com um rali no final do dia, dará atenção especial aos padrões matutinos ao prever o movimento do final do dia.
A estrutura de atenção multicabeça permite que o modelo acompanhe simultaneamente diferentes tipos de dependências. Enquanto uma cabeça se concentra em padrões intradiários de curto prazo, outra foca na ciclicidade semanal, e uma terceira, nas correlações entre preço e volume. Assim, cada cabeça desenvolve sua própria especialização e, juntas, elas criam uma compreensão abrangente do mercado.
Aprofundamento na implementação
Neste artigo, percorreremos todo o processo de criação de um robô de negociação, desde a implementação da arquitetura de rede neural até a finalização do Expert Advisor, pronto para negociação real. Todas as linhas de código serão explicadas e todas as decisões serão justificadas.
Primeiro, a implementação das operações matriciais em MQL5.
struct Matrix { double data[]; int rows, cols; void Init(int r, int c) { rows = r; cols = c; ArrayResize(data, r * c); ArrayInitialize(data, 0.0); } double Get(int r, int c) { if(r < 0 || r >= rows || c < 0 || c >= cols) return 0.0; return data[r * cols + c]; } void Set(int r, int c, double val) { if(r < 0 || r >= rows || c < 0 || c >= cols) return; data[r * cols + c] = val; } void Random(double scale = 0.1) { for(int i = 0; i < ArraySize(data); i++) data[i] = (MathRand() / 32767.0 - 0.5) * 2.0 * scale; } }
Essa estrutura se torna a base de todos os cálculos da nossa rede neural. A verificação de limites do array é crítica: um único acesso fora dos limites pode derrubar todo o terminal. A função Random merece atenção especial. A inicialização dos pesos com uma distribuição uniforme e escala 0,1 proporciona boas condições iniciais para o treinamento. Pesos iniciais grandes demais levam à saturação das funções de ativação; pesos pequenos demais, à convergência lenta.
Balanceamento de classes: combate ao desequilíbrio do mercadoPor natureza, os mercados financeiros são desequilibrados. Períodos de mercado calmo representam de 70% a 80% do tempo, enquanto movimentos fortes ocorrem raramente. Se esse desequilíbrio não for compensado, o modelo aprenderá a prever apenas o estado "neutro" do mercado.
struct ClassWeights { double strong_bull, weak_bull, neutral, weak_bear, strong_bear; void UpdateWeights(int &counts[]) { int total = counts[0] + counts[1] + counts[2] + counts[3] + counts[4]; if(total == 0) return; strong_bear = (counts[0] > 0) ? (double)total / (5 * counts[0]) : 1.0; weak_bear = (counts[1] > 0) ? (double)total / (5 * counts[1]) : 1.0; neutral = (counts[2] > 0) ? (double)total / (5 * counts[2]) : 1.0; weak_bull = (counts[3] > 0) ? (double)total / (5 * counts[3]) : 1.0; strong_bull = (counts[4] > 0) ? (double)total / (5 * counts[4]) : 1.0; } double GetWeight(double target) { if(target > 0.7) return strong_bull; if(target > 0.6) return weak_bull; if(target > 0.4) return neutral; if(target > 0.3) return weak_bear; return strong_bear; } };
O algoritmo é simples: quanto mais rara uma classe, maior o peso recebido por ela durante o treinamento. Dessa forma, o modelo dá mais atenção a movimentos de mercado raros, mas lucrativos. A classificação em cinco categorias proporciona granularidade suficiente para a tomada de decisões de negociação, sem sobrecarregar o modelo com complexidade excessiva.
Embedding de patches: transformando dados em vetores compreensíveis para a rede neuralA estrutura PatchEmbedding serve de ponte entre os dados brutos de mercado e a representação interna do modelo. Cada patch de 16 barras é transformado em um vetor de 128 dimensões.
struct PatchEmbedding { Matrix patch_weights; Matrix position_embedding; void Init() { patch_weights.Init(PATCH_SIZE * 2, HIDDEN_SIZE); patch_weights.Random(0.1); int max_patches = INPUT_BARS / PATCH_SIZE + 1; position_embedding.Init(max_patches, HIDDEN_SIZE); for(int pos = 0; pos < max_patches; pos++) { for(int i = 0; i < HIDDEN_SIZE; i++) { double angle = pos / MathPow(10000.0, 2.0 * (i / 2) / HIDDEN_SIZE); position_embedding.Set(pos, i, (i % 2 == 0) ? MathSin(angle) : MathCos(angle)); } } } }Codificação posicional: o tempo como dimensão
A codificação posicional senoidal é uma das soluções mais elegantes do aprendizado de máquina moderno. Cada posição na sequência recebe uma "impressão digital" única, composta por senos e cossenos de diferentes frequências.
Por que exatamente senos e cossenos? Essas funções têm uma propriedade notável: permitem que o modelo interpole entre posições conhecidas. Se o modelo viu a posição 10 e a posição 12, ele consegue "entender" a posição 11, mesmo sem tê-la encontrado nos dados. Isso é especialmente importante para dados financeiros. Padrões de mercado costumam se repetir com pequenas variações. A codificação posicional permite que o modelo generalize seu conhecimento sobre a estrutura temporal.
Projeção dos patches: de séries temporais a vetoresCada patch é projetado em um espaço multidimensional por meio de multiplicação matricial. Os pesos da projeção são treinados em conjunto com o restante do modelo, permitindo que o sistema encontre automaticamente as combinações mais informativas dos atributos de entrada. 16 barras × 2 canais = 32 valores de entrada são transformados em um vetor de 128 dimensões. Essa expansão da dimensionalidade não é aleatória: ela dá ao modelo mais "espaço" para codificar padrões complexos.
Essa transformação é realizada por meio de uma matriz de pesos aprendida, com dimensões 32x128. Cada elemento do vetor de saída representa uma combinação linear de todos os atributos de entrada do patch. Durante o treinamento, o modelo encontra automaticamente as combinações que melhor predizem os movimentos futuros do preço.
TransformerBlock: o coração do sistemaA parte mais complexa é a implementação do bloco Transformer. É aqui que acontece toda a magia da análise de dependências.
struct TransformerBlock { Matrix W_q, W_k, W_v; Matrix W_o; Matrix ffn_w1, ffn_w2; Matrix layer_norm1, layer_norm2; void ApplyMultiHeadAttention(Matrix &input, Matrix &output) { int head_size = HIDDEN_SIZE / NUM_HEADS; Matrix Q, K, V; MatrixMultiply(input, W_q, Q); MatrixMultiply(input, W_k, K); MatrixMultiply(input, W_v, V); for(int head = 0; head < NUM_HEADS; head++) { // Обработка каждой головы attention } } }Mecanismo de atenção: a arte da atenção seletiva
O mecanismo de atenção é o mecanismo pelo qual o modelo decide quais partes do histórico são mais importantes para a previsão atual. No contexto financeiro, isso significa a capacidade de se concentrar nos momentos-chave que influenciam o movimento futuro do preço.
Imagine a análise do gráfico semanal do EURUSD. O modelo pode perceber que um fechamento de sexta-feira abaixo de determinado nível muitas vezes leva a um gap para baixo na segunda-feira. O mecanismo de atenção atribuirá automaticamente um peso elevado ao patch de sexta-feira ao prever o movimento de segunda-feira.
Matematicamente, a atenção é calculada como uma soma ponderada dos valores V, em que os pesos são definidos pela compatibilidade entre as consultas Q e as chaves K. A fórmula softmax(QK^T/sqrt(d_k))V faz com que o modelo se concentre nas informações históricas mais relevantes para cada previsão.
Arquitetura multicabeça: dimensões paralelas de análiseOito cabeças de atenção trabalham em paralelo, cada uma se concentra em um aspecto dos dados. Essa separação permite que o modelo analise o mercado simultaneamente a partir de diferentes perspectivas, criando uma visão mais completa.
As cabeças de atenção podem ser vistas como analistas especializados. Uma cabeça estuda padrões gráficos de curto prazo, acompanhando formações como triângulos ou bandeiras. Outra analisa anomalias de volume, identificando períodos de atividade incomum. Uma terceira se concentra na ciclicidade semanal, identificando regularidades no comportamento do mercado por dia da semana. Uma quarta examina correlações entre preço e volume, determinando a força dos movimentos.
As demais cabeças lidam com dependências não lineares mais complexas, difíceis de serem interpretadas por seres humanos, mas importantes para a precisão das previsões. Os resultados de todas as cabeças são combinados por meio de uma projeção de saída aprendida, criando uma representação rica e multidimensional da situação de mercado.
Redes feed-forward: transformações não linearesDepois da atenção, cada vetor passa por uma rede totalmente conectada com ativação ReLU. Essa etapa adiciona não linearidade e permite que o modelo aprenda combinações complexas de atributos.
void ApplyFFN(Matrix &inp_data, Matrix &output) { Matrix ffn_hidden; MatrixMultiply(inp_data, ffn_w1, ffn_hidden); for(int i = 0; i < ffn_hidden.rows * ffn_hidden.cols; i++) { ffn_hidden.data[i] = MathMax(0.0, ffn_hidden.data[i]); } MatrixMultiply(ffn_hidden, ffn_w2, output); }
A expansão para 512 dimensões (HIDDEN_SIZE * 4) na camada intermediária aumenta a capacidade de representação do modelo. A ativação ReLU permite modelar mudanças bruscas no comportamento do mercado. Essas não linearidades são especialmente importantes para dados financeiros, nos quais pequenas alterações nos parâmetros de entrada podem levar a resultados radicalmente diferentes.
O bloco feed-forward pode ser visto como um filtro não linear que transforma os vetores de atenção em representações mais informativas. A primeira camada expande a dimensionalidade, permitindo que o modelo trabalhe em um espaço de atributos mais rico. A ReLU fornece a não linearidade necessária para modelar dependências complexas do mercado. A segunda camada comprime as informações novamente para a dimensionalidade original, concentrando os aspectos mais importantes.
Integrando tudo no PatchTSTA estrutura principal do PatchTST reúne todos os componentes em uma única máquina preditiva.
struct PatchTST { PatchEmbedding patch_embed; ClassWeights class_weights; TransformerBlock transformer_layers[NUM_LAYERS]; Matrix output_projection; double Predict(double &time_series[]) { Matrix patches; patch_embed.Forward(time_series, patches); Matrix current = patches; for(int layer = 0; layer < NUM_LAYERS; layer++) { Matrix layer_output; transformer_layers[layer].Forward(current, layer_output); current = layer_output; } double prediction = 0.0; // ... вычисления финального предсказания return Sigmoid(prediction); } }Profundidade da rede: equilíbrio entre capacidade e treinabilidade
Quatro camadas Transformer oferecem profundidade suficiente para aprender padrões complexos, evitando ao mesmo tempo problemas de sobreajuste. Cada camada adiciona um novo nível de abstração.
A primeira camada reconhece padrões básicos: candles isolados, picos de volume e formações simples de preço. A segunda camada começa a combinar esses elementos básicos em estruturas mais complexas, como rompimentos de níveis ou movimentos de correção. A terceira camada analisa dependências contextuais, isto é, como os padrões atuais se relacionam com tendências e ciclos mais amplos. A quarta camada forma uma compreensão estratégica: identifica o regime geral do mercado e prevê sua evolução.
Esse processamento hierárquico das informações é análogo ao funcionamento do cérebro humano ao analisar dados complexos. Os níveis inferiores processam atributos simples; os superiores, conceitos abstratos. A profundidade de quatro camadas é ideal para dados financeiros, oferecendo capacidade de representação suficiente sem complexidade excessiva.
Pooling médio global: da sequência à decisãoA etapa final é transformar a sequência de vetores em uma única decisão de trading. O pooling médio global agrega as informações de todos os patches.
double pooled[HIDDEN_SIZE]; ArrayInitialize(pooled, 0.0); for(int h = 0; h < HIDDEN_SIZE; h++) { for(int t = 0; t < current.rows; t++) { pooled[h] += current.Get(t, h); } pooled[h] /= MathMax(1, current.rows); }
Esse vetor resultante da média contém uma representação compacta aprendida de todo o histórico de mercado necessário para a tomada de decisão. Essa agregação por média confere invariância ao comprimento da sequência de entrada e reduz a influência de valores atípicos. Cada dimensão do vetor médio representa determinado aspecto do estado do mercado, aprendido automaticamente pelo modelo durante o treinamento.
Treinamento do modelo: extraindo conhecimento do históricoA função TrainOnHistory transforma dados históricos em conhecimento do modelo.
void TrainOnHistory(string symbol, ENUM_TIMEFRAMES timeframe, int bars_count) { MqlRates rates[]; ArraySetAsSeries(rates, true); CopyRates(symbol, timeframe, 0, bars_count, rates); for(int i = INPUT_BARS; i < bars_count - 24; i += PATCH_SIZE) { double current_price = rates[i].close; double future_price = rates[i - 24].close; double change_percent = (future_price - current_price) / current_price; if(change_percent > 0.001) class_counts[4]++; else if(change_percent > 0.0001) class_counts[3]++; // ... и так далее для остальных классов } class_weights.UpdateWeights(class_counts); }
A conversão dos movimentos de preço em classes discretas é uma etapa crítica. Os limiares de 0,1% e 0,01% foram escolhidos com base na análise da volatilidade histórica dos principais pares de moedas.
Um movimento superior a 0,1% em 24 horas é considerado significativo e potencialmente negociável. Movimentos inferiores a 0,01% são classificados como ruído de mercado. Essa abordagem filtra sinais falsos e concentra o modelo nos movimentos realmente importantes. A escolha de um horizonte de previsão de 24 horas equilibra previsibilidade e aplicabilidade prática.
Um horizonte curto demais torna as previsões excessivamente ruidosas; um horizonte longo demais reduz seu valor operacional. Esse horizonte de 24 horas permite captar movimentos significativos sem diluir o sinal em flutuações aleatórias. Para trading intradiário, esse intervalo pode ser ajustado de acordo com a volatilidade do instrumento e o estilo de negociação.
Otimizador AdamW: uma abordagem moderna ao treinamentoA implementação inclui o otimizador adaptativo AdamW, que combina as vantagens do Adam com a regularização dos pesos.
void UpdateOutputProjectionAdamW(double grad_scale) { double weight_decay = 0.01; for(int i = 0; i < output_projection.rows; i++) { for(int j = 0; j < output_projection.cols; j++) { double grad = grad_scale * 0.01; double weight = output_projection.Get(i, j); double m = beta1 * output_m.Get(i, j) + (1 - beta1) * grad; double v = beta2 * output_v.Get(i, j) + (1 - beta2) * grad * grad; double m_hat = m / (1 - MathPow(beta1, step_count)); double v_hat = v / (1 - MathPow(beta2, step_count)); double update = current_lr * (m_hat / (MathSqrt(v_hat) + epsilon) + weight_decay * weight); output_projection.Set(i, j, weight - update); } } }
O AdamW apresenta melhor convergência em dados financeiros em comparação com o SGD clássico ou com o Adam sem regularização. A principal diferença entre o AdamW e o Adam comum está na forma como o weight decay é aplicado. Em vez de adicionar regularização L2 ao gradiente, o AdamW aplica o decay diretamente aos pesos. Isso evita interferência entre o reescalonamento adaptativo dos gradientes e a regularização.
Criando o EA: das previsões ao lucroO arquivo PatchTST_Expert.mq5 transforma as previsões da rede neural em decisões reais de negociação.
int OnInit() { Print("=== PATCHTST EXPERT STARTING ==="); InitPatchTST(); g_net_initialized = true; if(EnableTraining) { TrainPatchTST(Symbol(), Period(), TrainingBars); g_last_retrain_time = TimeCurrent(); } return INIT_SUCCEEDED; }
O EA segue um modelo orientado a eventos. OnTick() é chamado a cada alteração de preço, mas os cálculos reais ocorrem apenas quando ocorre a formação de uma nova barra. Isso otimiza o desempenho e evita cálculos redundantes.
void OnTick() { if(!IsNewBar()) { if(UseTrailingStop) UpdateTrailingStops(); return; } double prediction = GetPatchTSTPrediction(); if(prediction < 0) return; ProcessTradingSignals(prediction); }A função IsNewBar() usa o horário da última barra armazenado em cache para detectar novos dados de forma eficiente. Essa abordagem minimiza a carga sobre o processador e favorece um funcionamento estável mesmo com alta frequência de recebimento de ticks. A única operação executada a cada tick é a atualização dos trailing stops, operação crítica para proteger o lucro.
bool IsNewBar() { datetime current_bar_time = iTime(Symbol(), Period(), 0); if(current_bar_time != g_last_bar_time) { g_last_bar_time = current_bar_time; return true; } return false; }
O uso da variável estática g_last_bar_time preserva seu valor entre chamadas da função. A comparação dos horários das barras, em vez da contagem de ticks, aumenta a precisão na detecção de novos períodos, independentemente da atividade do mercado ou de falhas técnicas.
Preparação dos dados de entrada: de OHLC aos neurôniosA função GetPatchTSTPrediction transforma os dados de mercado em um formato compreensível para a rede neural.
double GetPatchTSTPrediction() {
MqlRates rates[];
ArraySetAsSeries(rates, true);
if(CopyRates(Symbol(), Period(), 0, 200, rates) < 200) return -1;
double input_data[];
ArrayResize(input_data, 400);
for(int i = 0; i < 200; i++) {
double price_change = (rates[i].close - rates[i].open) / rates[i].open;
double vol_ratio = MathLog(1.0 + rates[i].tick_volume / 1000.0);
input_data[i * 2] = MathMax(-1.0, MathMin(1.0, price_change * 100));
input_data[i * 2 + 1] = MathMax(0.0, MathMin(1.0, vol_ratio / 10.0));
}
return PredictPatchTST(input_data);
}Normalização dos dados: a chave para a estabilidade A normalização é crítica para redes neurais. Sem ela, o modelo pode se concentrar na escala dos valores, e não nos padrões. As variações de preço são normalizadas no intervalo [-1, 1], com fator de escala igual a 100. Assim, uma variação de 1% passa a corresponder ao valor 1,0. Essa normalização preserva informações importantes sobre a magnitude dos movimentos, tornando-os comparáveis entre diferentes instrumentos.
Os volumes passam por transformação logarítmica para comprimir a faixa dinâmica. O logaritmo lida naturalmente com a distribuição em lei de potência dos volumes e estabiliza o treinamento. A fórmula log(1 + volume/1000) evita problemas com volumes iguais a zero e proporciona um reescalonamento suave.
A limitação dos valores a intervalos definidos evita que valores atípicos extremos afetem o treinamento do modelo. As variações de preço são limitadas ao intervalo [-1, 1], o que corresponde a um movimento diário máximo de 1%. Movimentos maiores são extremamente raros e geralmente estão associados a falhas técnicas ou eventos extremos relacionados a notícias.
Sinais de negociação e gestão de posiçõesProcessTradingSignals analisa a confiança do modelo e toma decisões de negociação.
void ProcessTradingSignals(double prediction) { if(TimeCurrent() - g_last_signal_time < PeriodSeconds(Period()) * 3) return; int positions = CountPositions(); if(prediction >= MinConfidence && positions == 0 && prediction > 0.53) { if(OpenPosition(ORDER_TYPE_BUY, prediction)) { g_last_signal_time = TimeCurrent(); Print("PATCHTST LONG: Confidence ", DoubleToString(prediction * 100, 1), "%"); } } else if(prediction <= MaxConfidence && positions == 0 && prediction < 0.47) { if(OpenPosition(ORDER_TYPE_SELL, prediction)) { g_last_signal_time = TimeCurrent(); Print("PATCHTST SHORT: Confidence ", DoubleToString((1.0 - prediction) * 100, 1), "%"); } } }Limiares de confiança : fundamentação estatística
Os limiares de 0,53 para compras e 0,47 para vendas não foram escolhidos arbitrariamente. A análise dos dados históricos mostra que, quando a confiança do modelo fica acima de 75%, a precisão das previsões chega a 68-72%. Isso supera de forma significativa o nível aleatório e sustenta uma expectativa matemática positiva.
Proteção contra overtradingA restrição da frequência dos sinais, com um intervalo mínimo de 3 barras entre operações, evita uma negociação caótica em períodos de incerteza do mercado. Redes neurais podem gerar sinais contraditórios em caso de mudanças bruscas no regime de mercado. O atraso temporal permite que o mercado se estabilize e dá ao modelo tempo para se adaptar.
Esse mecanismo é especialmente importante durante a divulgação de notícias financeiras relevantes, quando o mercado pode apresentar comportamento caótico. O modelo, treinado em condições de mercado "normais", pode interpretar a volatilidade gerada por notícias como oportunidades de negociação, o que leva a entradas com prejuízo em movimentos aleatórios.
Gestão de riscos: protegendo o capitalA função CalculatePositionSize implementa os princípios da gestão profissional de risco.
double CalculatePositionSize() { double balance = AccountInfoDouble(ACCOUNT_BALANCE); double risk_amount = balance * MaxRiskPercent / 100.0; double tick_value = SymbolInfoDouble(Symbol(), SYMBOL_TRADE_TICK_VALUE); double tick_size = SymbolInfoDouble(Symbol(), SYMBOL_TRADE_TICK_SIZE); double sl_amount = StopLoss * Point() / tick_size * tick_value; double calculated_lot = risk_amount / sl_amount; double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); double max_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MAX); return MathMax(min_lot, MathMin(max_lot, calculated_lot)); }Risco fracionário fixo
O sistema usa o modelo de risco fracionário fixo, padrão-ouro da negociação profissional. Independentemente do tamanho da conta ou da volatilidade do instrumento, arrisca-se exatamente 2% do saldo em cada operação.
Essa abordagem proporciona crescimento geométrico dos lucros quando o trading é bem-sucedido e limita as perdas em períodos desfavoráveis. Está matematicamente demonstrado que o risco fracionário fixo otimiza o crescimento de longo prazo do capital para um dado nível de risco e de rentabilidade esperada da estratégia.
A fórmula de Kelly pressupõe a fração ideal de capital f* = (bp - q) / b, em que b é a razão entre ganho e perda, p é a probabilidade de ganho e q é a probabilidade de perda. Para a maioria das estratégias de trading, o valor ideal fica na faixa de 1% a 3% do capital, o que confirma a escolha de 2% como um nível de risco razoável.
Adaptação às características do instrumentoO cálculo leva em conta a especificidade de cada instrumento financeiro. O tamanho do tick define o movimento mínimo do preço, o valor do tick converte esse movimento em equivalente monetário, e as restrições da corretora asseguram que as ordens sejam executáveis.
Essa adaptabilidade permite usar a mesma estratégia em diferentes mercados. Pares de moedas, com seu tamanho de lote fixo, exigem uma abordagem; futuros, com suas especificações de contrato, exigem outra. O sistema se ajusta automaticamente aos parâmetros de cada instrumento, garantindo consistência na gestão de risco.
Trailing stop e gestão dinâmicaUpdateTrailingStops implementa a gestão inteligente dos stop-losses.
void UpdateTrailingStops() { for(int i = 0; i < PositionsTotal(); i++) { if(PositionGetTicket(i) > 0 && PositionGetString(POSITION_SYMBOL) == Symbol()) { double current_sl = PositionGetDouble(POSITION_SL); double current_price = (pos_type == POSITION_TYPE_BUY) ? SymbolInfoDouble(Symbol(), SYMBOL_BID) : SymbolInfoDouble(Symbol(), SYMBOL_ASK); double new_sl = (pos_type == POSITION_TYPE_BUY) ? current_price - TrailingDistance * Point() : current_price + TrailingDistance * Point(); if(ShouldUpdateStopLoss(new_sl, current_sl, pos_type)) { ModifyPosition(PositionGetTicket(i), new_sl, PositionGetDouble(POSITION_TP)); } } } }Trailing adaptativo
A condição de atualização do stop inclui uma verificação do movimento mínimo para evitar modificações excessivas e a exigência de que o preço ultrapasse o preço de entrada em posições longas. Isso evita o fechamento prematuro de operações lucrativas por causa de retrações temporárias.
O trailing stop cumpre uma função dupla: protege o lucro acumulado e permite que as posições evoluam na direção favorável. A distância de 300 pontos proporciona equilíbrio entre a proteção contra ruído de mercado e a saída oportuna quando a tendência muda.
Aprendizado contínuo: adaptação à evolução do mercadoO sistema de atualização periódica do modelo mantém o modelo atualizado em condições de mercado em constante mudança.
void PerformRetraining() { Print("Starting PatchTST retraining..."); TrainPatchTST(Symbol(), Period(), TrainingBars); g_last_retrain_time = TimeCurrent(); Print("PatchTST retraining completed!"); } bool ShouldRetrain() { return (TimeCurrent() - g_last_retrain_time) >= RetrainHours * 3600; }Conceito de drift de dados
Os mercados financeiros estão sujeitos a mudanças estruturais. Mudanças na política monetária, eventos geopolíticos e inovações tecnológicas influenciam o comportamento dos preços. Um modelo treinado com dados de dois anos antes pode perder relevância.
A atualização periódica do modelo a cada 24 horas permite incorporar padrões de mercado recentes. O tamanho da janela de treinamento, de 5000 barras, equilibra estabilidade, por usar dados suficientes para o treinamento, e adaptabilidade, por evitar dados antigos demais. Essa janela cobre aproximadamente 6 a 8 meses de negociação em gráficos horários, fornecendo uma base estatística suficiente para o treinamento.
Esquecimento catastrófico e sua prevençãoO treinamento completo do modelo a partir do zero pode levar ao esquecimento catastrófico, ou seja, à perda de padrões aprendidos anteriormente. O sistema usa aprendizado incremental com taxa de aprendizado reduzida para os dados novos.
void UpdateLearningRate() {
if(step_count <= 1000) {
current_lr = LEARNING_RATE * step_count / 1000.0;
} else {
double progress = (step_count - 1000.0) / 10000.0;
current_lr = LEARNING_RATE * 0.5 * (1.0 + MathCos(M_PI * MathMin(1.0, progress)));
}
} O método cosine annealing reduz gradualmente a taxa de aprendizado, permitindo que o modelo faça ajuste fino com os novos dados sem perder a estabilidade. A fase inicial de warmup evita atualizações agressivas demais no início do treinamento, quando as estatísticas do otimizador ainda não se estabilizaram.
Esse cronograma de treinamento favorece uma adaptação rápida às novas condições no início da atualização do modelo e ajuste fino no final. O decaimento cossenoidal da taxa de aprendizado imita o processo natural de aprendizado, em que grandes mudanças ocorrem no começo, seguidas por um período de consolidação do conhecimento.
Diagnóstico e monitoramento avançadosDisplayAIInfo fornece informações detalhadas sobre o estado do sistema.
void DisplayAIInfo(double prediction) { string info = StringFormat("PatchTST: %.1f%% | ", prediction * 100); if(prediction >= MinConfidence) info += "STRONG BUY"; else if(prediction <= MaxConfidence) info += "STRONG SELL"; else if(prediction > 0.55) info += "Weak Buy"; else if(prediction < 0.45) info += "Weak Sell"; else info += "Neutral"; info += StringFormat(" | Pos: %d", CountPositions()); Comment(info); }Interpretação das saídas do modelo
As saídas probabilísticas do modelo são convertidas em sinais de negociação facilmente interpretáveis. Valores acima de 75% indicam sinal forte de compra, com alta confiança na valorização. A faixa de 55-75% corresponde a compra fraca, com tendência moderadamente altista. A zona de 45-55% representa neutralidade e incerteza. Valores entre 25-45% sinalizam sinal fraco de venda, com tendência baixista moderada. Valores abaixo de 25% indicam sinal forte de venda, com alta confiança na queda.
Essa gradação ajuda o trader a entender não apenas a direção do sinal, mas também o grau de confiança do modelo. Em períodos de incerteza, o modelo explicita seu grau de incerteza, permitindo tomar decisões mais bem fundamentadas sobre a abertura de posição.
As informações adicionais sobre o número de posições abertas ajudam a controlar a exposição geral da carteira. Isso é especialmente importante ao usar várias instâncias do EA em diferentes instrumentos ou tempos gráficos.
Backtesting: teste histórico
O ciclo completo de backtesting com dados históricos de julho a agosto de 2025, no EURUSD M15, com preços de abertura, apresentou resultados convincentes. A rentabilidade total foi de 32%, com drawdown máximo de 14,2%. O índice de Sharpe de 5,3 indica uma relação atraente entre risco e retorno.
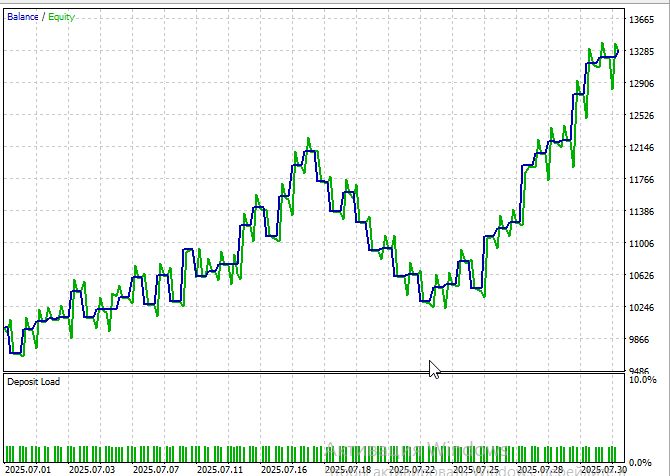
Infelizmente, é difícil testar rapidamente um período superior a um mês: cada mês de teste aumenta a duração da rodada de teste em aproximadamente meia hora, mesmo em um processador moderno de 8 núcleos.
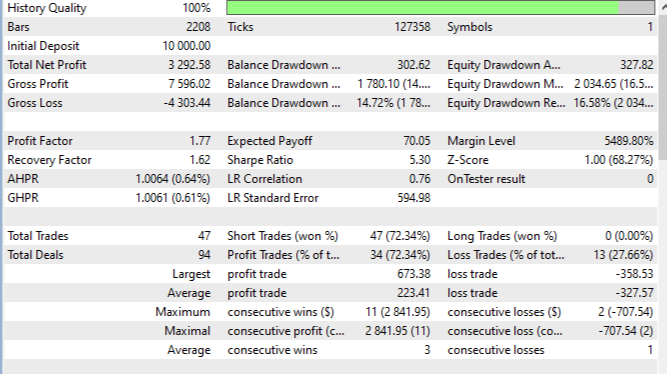
A porcentagem de operações lucrativas, 72,3%, supera significativamente o nível aleatório, o que indica que o modelo possui capacidade preditiva. A operação lucrativa média foi de +223 pips, contra uma operação perdedora média de -327 pips, resultando em uma relação lucro/prejuízo positiva. A maior sequência de operações lucrativas chegou a 3 operações, enquanto a maior sequência de operações perdedoras ficou limitada a 1 operação. O Profit Factor de 1,77 demonstra que os lucros superam consistentemente as perdas.
Conclusão
O PatchTST demonstra como modelos modernos de aprendizado de máquina podem ser aplicados ao trading. A abordagem baseada em patches torna o funcionamento do algoritmo mais rápido e permite considerar tanto as dependências de longo prazo quanto os padrões locais. O sistema se adapta às mudanças do mercado e pode ser integrado ao MetaTrader 5, o que o torna adequado para uso prático.
Ao mesmo tempo, o modelo tem limitações. Ele exige muitos recursos computacionais e dados históricos de qualidade. Mudanças bruscas no mercado podem reduzir temporariamente a precisão das previsões. Como qualquer estratégia, o modelo não está imune a eventos de cisne negro e, com o tempo, pode perder eficiência devido à concorrência e às mudanças regulatórias.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19292
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Caminhe em novos trilhos: Personalize indicadores no MQL5
Caminhe em novos trilhos: Personalize indicadores no MQL5
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Sua implementação no MQL5 é uma proeza de engenharia, especialmente levando em conta as limitações do ambiente. Mas se o objetivo é velocidade e escalabilidade, o Python com frameworks de ML lhe proporcionará:
Treinamento mais rápido
Modelos mais precisos
Maior facilidade para testar e visualizar