
Redes neurais em trading: treinamento de metaparâmetros com base na heterogeneidade (Final)

Introdução
O trading algorítmico raramente perdoa a complexidade excessiva ou a simplicidade injustificada das soluções. Qualquer modelo, seja um ensemble neural extremamente complexo ou um filtro autorregressivo minimalista, no fim das contas precisa passar pelo teste do tempo e do mercado. Foi justamente a partir dessa perspectiva que o HimNet foi concebido: um framework que não tenta impressionar pela quantidade de parâmetros treináveis nem pelo exotismo dos cálculos. Pelo contrário, ele se concentra em entregar um resultado robusto, reproduzível e economicamente justificável.
Desde os primeiros passos, o HimNet manifesta três qualidades que o diferenciam de muitas outras abordagens. Em primeiro lugar, a racionalidade da arquitetura: não há nele camadas sobrecarregadas que apenas criam a ilusão de profundidade analítica. Cada módulo é funcional e justificado. Em segundo lugar, uma adaptabilidade controlada: em vez de se ajustar cegamente ao ruído de cada oscilação do mercado, o framework constrói um equilíbrio entre flexibilidade e robustez. Em terceiro lugar, o minimalismo na gestão dos parâmetros. HimNet é construído de modo que o número de coeficientes treináveis seja reduzido ao mínimo necessário. Isso permite evitar o ajuste excessivo aos dados históricos e preservar a força preditiva mesmo em trechos mais distantes das séries temporais.
Nos artigos anteriores, fomos revelando gradualmente a mecânica interna desse framework. Começando pelos fundamentos teóricos, estudamos em detalhes as formas de geração dos embeddings e analisamos como os elementos recorrentes e convolucionais se complementam. A arquitetura do HimNet se parece com um mecanismo bem ajustado, no qual cada engrenagem, seja o bloco de polinômios de Chebyshev ou o mecanismo GCRU, tem sua função precisa. Não se trata de um acúmulo de tecnologias, mas de uma construção cuidadosamente calculada, que permite obter uma representação informativa do mercado sem perda de velocidade de processamento nem complexidade excessiva da cadeia computacional.

O framework HimNet é construído segundo a arquitetura clássica Codificador-Decodificador, em grande parte já consolidada ao longo do tempo. Esse esquema se mostrou eficaz em tarefas de processamento de sequências complexas, nas quais é importante não apenas registrar o estado atual do mercado, mas também extrair dele padrões estáveis para as previsões subsequentes. O Codificador e o Decodificador se apoiam na mesma base: ambos usam embeddings treináveis e blocos recorrentes em grafos (GCRU). No entanto, há entre eles uma diferença sutil, mas importante: a própria forma de gerar os embeddings.
No Codificador, os embeddings temporais e espaciais são extraídos diretamente de dicionários previamente preparados e aplicados como uma espécie de vetores de consulta aos pools de metaparâmetros. Isso permite que o Codificador se adapte ao contexto.
O Decodificador, por sua vez, forma os embeddings de maneira indireta, com base na representação latente formada a partir dos resultados do Codificador. Ele projeta a representação oculta em um embedding espaço-temporal, que se torna o vetor de consulta para o modelo ST de metaparâmetros, permitindo que o Decodificador gere os pesos.
Já realizamos uma preparação considerável: implementamos os componentes fundamentais do modelo, incluindo blocos recorrentes em grafos capazes de considerar com eficiência as dependências espaço-temporais dos dados. Agora chegou a hora de avançar para o próximo nível da hierarquia: construir a estrutura completa do Codificador e do Decodificador. Esta etapa será o elo entre os elementos individuais do framework e sua aplicação prática. É justamente aqui que os blocos abstratos passam a se conectar entre si, e o fluxo de dados começa a formar uma representação significativa dos estados futuros do mercado.
Codificador
Os autores do framework HimNet projetaram um mecanismo de processamento de dados em dois fluxos, em que cada tipo de dependência, espacial e temporal, fica a cargo de um Codificador separado. Essa abordagem permite não misturar diferentes estruturas de sinais em um único bloco, mas analisá-las em ramificações paralelas, garantindo uma extração mais precisa e limpa dos principais padrões. Seguindo as ideias propostas, hoje começaremos pela construção do Codificador de dependências temporais. Afinal, o tempo é o fio sobre o qual se estrutura qualquer dinâmica de mercado.
Codificador temporal
O objeto CNeuronHimNetTempEncoder é uma espécie de filtro temporal do framework, destinado a extrair regularidades ocultas na sequência de cotações e nos padrões de mercado. Ele faz isso em várias escalas ao mesmo tempo.
class CNeuronHimNetTempEncoder : public CNeuronBaseOCL { protected: uint aTimeframes[2]; CCircleParams caEmbeddings[2]; CNeuronBaseOCL cConcatEmbeddings; CLayer cGRCUs; CBufferFloat bSupportAccum; public: CNeuronHimNetTempEncoder(void) {}; ~CNeuronHimNetTempEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support, int label); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); //--- virtual int Type(void) const { return defNeuronHimNetTempEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; //--- virtual uint GetCount(void) const; virtual uint GetWindowIn(void) const; virtual uint GetWindowOut(void) const; virtual uint GetChebK(void) const; //--- virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Os elementos principais são dois dicionários de embeddings, representados pelo array caEmbeddings. Cada um desses dicionários armazena não os dados completos, mas apenas representações compactas de passos temporais específicos: embeddings que atuam como vetores de consulta para os pools de parâmetros do modelo. Isso significa que cada passo temporal, na prática, acessa seu próprio subespaço de parâmetros, extraindo o valor necessário e, assim, ajustando o fluxo de dados posterior.
É importante destacar que os dois dicionários de embeddings operam de forma coordenada, mas independente. Graças a isso, o modelo observa simultaneamente duas escalas temporais e não mistura o ruído de curto prazo com a inércia de longo prazo. Ao longo da implementação dos métodos, veremos em detalhes como esses vetores de consulta interagem com o fluxo de dados e quais tarefas os demais componentes do Codificador temporal assumem.
Todos os objetos internos são declarados estaticamente, portanto o construtor e o destrutor permanecem minimalistas. A inicialização real de todo o conjunto de componentes declarados e objetos herdados é executada de forma centralizada no método Init.
bool CNeuronHimNetTempEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch) { if(layers <= 0) return false;
O algoritmo do método começa com um pequeno bloco de controle: verificamos a quantidade de camadas internas do codificador. E, se o valor do parâmetro layers for menor ou igual a "0", o método retorna falha imediatamente. Isso protege contra configurações sem sentido: sem camadas, não há o que aprender.
Em seguida, é chamado o método homônimo da classe pai, ao qual são passados os parâmetros básicos do objeto. Nesta etapa, definimos a forma do tensor de resultados do Codificador e reservamos os recursos básicos. Se a inicialização da classe base falhar, não faz sentido executar as operações seguintes: o método retorna false.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
Depois vem a preparação dos dicionários de embeddings, e o tamanho temporal do passo é imediatamente fixado nos elementos correspondentes do array aTimeframes.
int index = 0; if(!caEmbeddings[0].Init(0, index, OpenCL, embed_dim, period1, optimization, iBatch)) return false; aTimeframes[0] = MathMax(1, timeframe1); index ++; if(!caEmbeddings[1].Init(0, index, OpenCL, embed_dim, period2, optimization, iBatch)) return false; aTimeframes[1] = MathMax(1, timeframe2); if(!cConcatEmbeddings.Init(numOutputs, myIndex, open_cl, 2 * embed_dim, optimization_type, batch)) return false;
Cada dicionário de embeddings é configurado para sua própria granularidade temporal: o tamanho do embedding e o período definem quais vetores de consulta temporais serão usados para acessar o pool de parâmetros. Se qualquer uma dessas inicializações falhar, o método é interrompido. Não permitimos um Codificador montado apenas parcialmente.
Depois da definição dos dicionários, é criado cConcatEmbeddings, o objeto que combinará dois embeddings em um único vetor.
Em seguida, começa a construção das camadas GCRU. Primeiro, limpamos o contêiner cGRCUs e vinculamos explicitamente o contexto OpenCL.
cGRCUs.Clear(); cGRCUs.SetOpenCL(OpenCL); index++; CNeuronHimNetGCRU *temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) return false;
Depois, é criado o primeiro objeto CNeuronHimNetGCRU, inicializado com os parâmetros da primeira camada: para ele, a dimensão dos atributos na entrada é definida como igual à dimensão correspondente da série temporal analisada, enquanto na saída é definida como a representação latente. Essa primeira camada é a base da pilha.
Se a inicialização for bem-sucedida, a camada é adicionada ao contêiner cGRCUs. Caso a adição ou a inicialização falhe, retornamos false.
Para todas as camadas seguintes, a lógica fica um pouco mais simples. No laço, são criados objetos CNeuronHimNetGCRU adicionais, mas agora os tensores de entrada e de saída têm as mesmas dimensões. Essa é uma técnica padrão: a primeira camada expande e reúne o contexto, enquanto as seguintes refinam esse contexto em profundidade. Em qualquer falha, seja na criação, na inicialização ou na adição, encerramos cuidadosamente o método retornando false, para não deixar o sistema em um estado inconsistente.
for(uint i = 1; i < layers; i++) { index++; temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window_out, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) return false; }
Depois que o stack GCRU é formado, inicializamos o buffer auxiliar bSupportAccum, que será usado para acumular os gradientes do erro dos polinômios de Chebyshev recebidos das diferentes camadas do Codificador.
bSupportAccum.BufferFree(); bSupportAccum.Clear(); if(!bSupportAccum.BufferInit(units * units * cheb_k, 0) || !bSupportAccum.BufferCreate(OpenCL)) return false;
Em seguida, vem uma etapa prática importante: o resultado do Codificador é a saída do último objeto no contêiner cGRCUs. Para evitar cópias desnecessárias de tensores grandes, sincronizamos as funções de ativação, bem como os ponteiros para os buffers de resultados e gradientes. Ou seja, o Codificador assume a semântica de ativação da última camada e direciona suas interfaces externas diretamente para os buffers internos da última GCRU. Isso proporciona uma economia significativa de memória e tempo.
SetActivationFunction((ENUM_ACTIVATION)temp.Activation()); if(!SetOutput(temp.getOutput(), true) || !SetGradient(temp.getGradient(), true)) return false; //--- return true; }
Da inicialização do objeto, passamos à funcionalidade principal do Codificador temporal: criaremos o método de propagação feedForward.
bool CNeuronHimNetTempEncoder::feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support, int label) { for(uint i = 0; i < caEmbeddings.Size(); i++) { int position = (label / int(aTimeframes[i])) % caEmbeddings[i].GetPeriod(); if(!caEmbeddings[i].SetPosition(position) || !caEmbeddings[i].FeedForward()) return false; } if(!Concat(caEmbeddings[0].getOutput(), caEmbeddings[1].getOutput(), cConcatEmbeddings.getOutput(), 1, 1, caEmbeddings[0].Neurons())) return false;
Seu algoritmo começa com a obtenção dos embeddings a partir dos nossos dicionários. A execução é estruturada em um laço que percorre sequencialmente os dicionários no array. Para cada dicionário, calculamos a posição atual com base na marca de tempo recebida do programa externo. Em seguida, geramos o embedding temporal específico chamando o método FeedForward do dicionário correspondente.
Em essência, este é o ponto em que o tempo se transforma em um endereço para obter pesos especializados. Em uma analogia com trading: quando chega uma determinada janela temporal, escolhemos a configuração correspondente do modelo sem treiná-lo novamente, apenas usando outro vetor de consulta.
Depois que os dois embeddings são obtidos, seus resultados são combinados em um único tensor.
Em seguida, começa a parte central: a passagem pelo contêiner GCRU. A variável local inputs é inicializada com um ponteiro para o objeto dos dados de entrada. No laço pelos elementos do contêiner cGRCUs, percorremos cada camada em sequência e chamamos seu método de propagação.
CNeuronBaseOCL *inputs = NeuronOCL; CNeuronHimNetGCRU *current = NULL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current || !current. Feedforward(inputs, Support, cConcatEmbeddings.AsObject())) return false; inputs = current; } //--- return true; }
É importante entender o contrato: a primeira GCRU recebe os dados brutos da sequência analisada e o embedding de consulta comum. Ela forma sua própria representação oculta. Depois disso, o ponteiro em inputs é substituído pelo objeto atual, ou seja, a saída da primeira camada se torna a entrada da próxima. Assim é construída uma pilha de transformações sequenciais: a primeira camada expande o contexto, enquanto as seguintes refinam e comprimem a representação. Na prática de trading, isso se parece com uma primeira passagem analítica, na qual todos os detalhes são coletados, enquanto as camadas seguintes, como analistas mais experientes, filtram, agregam e preparam o sinal para a saída.
O buffer dos polinômios de Chebyshev (Support) serve como núcleo da agregação em grafos (K-hop). Passar o mesmo objeto para cada camada garante uma visão unificada da estrutura de conexões entre as sequências individuais ao longo de toda a pilha, enquanto cada GCRU usa seus próprios metaparâmetros, gerados a partir do embedding, para interpretar esse suporte.
Depois de analisarmos a propagação, é natural passar à etapa reversa: o momento em que o modelo é posto à prova e a responsabilidade pelo erro é cuidadosamente distribuída entre todas as suas partes. O método calcInputGradients é justamente esse procedimento, no qual os erros acumulados na saída do Codificador retornam pela pilha GCRU e pelos dicionários de embeddings, ajustando o comportamento de cada componente.
bool CNeuronHimNetTempEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support) { if(!NeuronOCL || !Support) return false;
Primeiro, por meio de uma verificação defensiva, o método confirma que recebeu ponteiros válidos como entrada. Em seguida, é definida a fonte de entrada para a última camada. Se houver mais de uma camada na pilha, usamos a penúltima GCRU; caso contrário, usamos o objeto dos dados de entrada. Começamos a distribuição dos gradientes do erro pela última GCRU, exatamente o objeto cujo resultado, durante a inicialização, foi atribuído como saída externa do Codificador. Isso é lógico: o gradiente primeiro chega ao topo da pilha e, a partir daí, começa a se propagar para baixo.
CNeuronBaseOCL *inputs = (cGRCUs.Total() > 1 ? cGRCUs[-2] : NeuronOCL); CNeuronHimNetGCRU* current = cGRCUs[-1]; if(!current || !current.calcInputGradients(inputs, Support, cConcatEmbeddings.AsObject())) return false; if(!DeConcat(caEmbeddings[0].getGradient(), caEmbeddings[1].getGradient(), cConcatEmbeddings.getGradient(), 1, 1, caEmbeddings[0].Neurons())) return false;
Aqui ocorre o processamento local principal: a última GCRU distribui o gradiente recebido entre sua entrada, seus metaparâmetros internos e o buffer de gradientes dos polinômios de Chebyshev (Support). É importante entender que, nesse ponto, Support atua como um mapa comum de conexões, e cada camada na pilha pode contribuir para ele. Por isso, precisamos de um mecanismo de acumulação cuidadoso.
Na etapa seguinte, decompomos o gradiente do embedding combinado novamente em duas partes: os gradientes dos dois dicionários de embeddings. Devolvemos a cada ramificação sua própria contribuição para o erro, para que depois os dicionários possam ajustar seus vetores de consulta aos pools de parâmetros.
Se a pilha tiver mais de uma camada, começa a acumulação cuidadosa dos gradientes de Support. Primeiro, salvamos o ponteiro para o buffer de gradientes atual na variável local temp, para não perder o buffer anterior com os valores já acumulados. Em seguida, redirecionamos temporariamente os gradientes do erro para o buffer bSupportAccum, que foi alocado previamente.
if(cGRCUs.Total() > 1) { CBufferFloat *temp = Support.getGradient(); if(!Support.SetGradient(GetPointer(bSupportAccum), false)) return false; for(int i = cGRCUs.Total() - 2; i >= 0; i--) { current = cGRCUs[i]; inputs = (i > 0 ? cGRCUs[i - 1] : NeuronOCL); if(!current || !current.calcInputGradients(inputs, Support, cConcatEmbeddings.AsObject())) return false; if(!SumAndNormilize(temp, Support.getGradient(), temp, 1, false, 0, 0, 0, 1)) return false; if(!DeConcat(caEmbeddings[0].getPrevOutput(), caEmbeddings[1].getPrevOutput(), cConcatEmbeddings.getGradient(), 1, 1, caEmbeddings[0].Neurons())) return false; for(uint i = 0; i < caEmbeddings.Size(); i++) if(!SumAndNormilize(caEmbeddings[i].getGradient(), caEmbeddings[i].getPrevOutput(), caEmbeddings[i].getGradient(), 1, false, 0, 0, 0, 1)) return false; } if(!Support.SetGradient(temp, false)) return false; } //--- return true; }
No laço que percorre os objetos da pilha em ordem inversa, chamamos, para cada camada, o método de distribuição dos gradientes do erro. Depois, agregamos a nova contribuição ao que já estava acumulado no buffer temp. Em seguida, decompomos novamente o gradiente do embedding combinado em dois fluxos de informação. Por fim, para cada dicionário, somamos os valores obtidos aos que já haviam sido acumulados anteriormente.
Após percorrer todas as camadas, restauramos os ponteiros para os buffers de dados ao estado inicial. Isso é importante: somente assim os otimizadores externos verão o sinal correto para atualizar os parâmetros que servem de base à agregação em grafos.
Após a execução bem-sucedida de todas as iterações, o método retorna true, o que significa que o gradiente foi distribuído com sucesso por todos os componentes do Codificador até o nível dos dados de entrada.
Depois da coleta cuidadosa dos gradientes, chega a etapa de atualização dos parâmetros. O método updateInputWeights aqui é simples em sua estrutura, mas conceitualmente importante: ele passa sequencialmente o controle aos componentes internos que contêm os pesos treináveis. E faz isso na mesma ordem em que a sequência computacional está implementada.
bool CNeuronHimNetTempEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support) { for(uint i = 0; i < caEmbeddings.Size(); i++) if(!caEmbeddings[i].UpdateInputWeights()) return false;
Primeiro, no laço, são atualizados os dois dicionários de embeddings. Cada chamada de UpdateInputWeights aplica aos parâmetros do dicionário correspondente os gradientes acumulados na etapa anterior.
Em seguida, o método percorre a pilha GCRU em ordem direta: cada camada fica responsável pela atualização local dos parâmetros de seus embeddings e pools de metaparâmetros.
CNeuronBaseOCL* inputs = NeuronOCL; CNeuronHimNetGCRU* current = NULL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current.updateInputWeights(inputs, Support, cConcatEmbeddings.AsObject())) return false; inputs = current; } //--- return true; }
O código-fonte completo dessa classe, com a implementação de todos os métodos, está anexado. Nele, é possível ver todos os detalhes discutidos até aqui. Com isso, a análise do Codificador temporal pode ser considerada concluída, e estamos prontos para avançar.
Codificador espacial
Antes de seguir adiante, vamos deixar claro o que é o Codificador espacial e em que ele difere do temporal, pois compreender essa diferença é importante para a integração correta à arquitetura geral do HimNet.
O Codificador temporal operava com um conjunto de dicionários de embeddings, que atuavam como vetores de consulta aos pools de parâmetros para diferentes granularidades temporais. O Codificador espacial, por sua vez, não precisa de múltiplas chaves periódicas: a estrutura dos dados espaciais na tarefa analisada é estável. Por isso, em vez de dicionários, usamos um único conjunto de parâmetros treináveis, encapsulado no objeto cEmbedding. Isso permite que o modelo tenha uma representação espacial do mercado, ajustada durante o treinamento e depois usada como uma fonte constante de vetores de consulta contextuais para a GCRU.
class CNeuronHimNetSpatEncoder : public CNeuronBaseOCL { protected: CParams cEmbedding; CLayer cGRCUs; CBufferFloat bSupportAccum; CBufferFloat bEmbeddingAccum; public: CNeuronHimNetSpatEncoder(void) {}; ~CNeuronHimNetSpatEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); //--- virtual int Type(void) const { return defNeuronHimNetSpatEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; //--- virtual uint GetCount(void) const; virtual uint GetWindowIn(void) const; virtual uint GetWindowOut(void) const; virtual uint GetChebK(void) const; //--- virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Arquiteturalmente, o objeto CNeuronHimNetSpatEncoder é muito parecido com o Codificador temporal. Ele usa a mesma pilha de blocos recorrentes em grafos cGRCUs, um acumulador análogo para os gradientes dos polinômios de Chebyshev e um conjunto de métodos para a propagação para frente e a retropropagação. A principal diferença é que, em vez de dois dicionários de embeddings, temos um único módulo parametrizado cEmbedding e um buffer adicional bEmbeddingAccum. Esse buffer é necessário para acumular as contribuições do gradiente do embedding vindas de todas as camadas da pilha.
Como o Codificador espacial difere do temporal apenas em algumas nuances, focar na lógica arquitetural e no fluxo de dados permite não sobrecarregar o texto com repetições desnecessárias. O código completo da classe e de todos os seus métodos, apresentado no anexo, permite ao leitor acompanhar por conta própria as diferenças mais sutis e compreender exatamente como os parâmetros de embedding e os gradientes são atualizados dentro das camadas GCRU.
Codificador consolidado
Nesta etapa, passamos ao módulo central, que conecta o funcionamento dos dois Codificadores paralelos em uma representação única e consistente. A classe CNeuronHimNetEncoder atua como coordenadora, garantindo a integração das representações espaciais e temporais. O Codificador temporal registra a dinâmica das mudanças ao longo do tempo, identificando tendências de curto e longo prazo, enquanto o espacial analisa as relações entre diferentes objetos. Os resultados dos dois fluxos são cuidadosamente consolidados dentro da classe, formando uma representação latente completa do estado do sistema.
class CNeuronHimNetEncoder : public CNeuronBaseOCL { protected: CParams cEmbedding; CNeuronTransposeOCL cEmbeddingT; CNeuronBaseOCL cSupport; CNeuronSoftMaxOCL cNormSupport; CChebPolinom cPolinomSupport; CNeuronHimNetTempEncoder cTempEncoder; CNeuronHimNetSpatEncoder cSpatEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHimNetEncoder(void) {}; ~CNeuronHimNetEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHimNetEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Arquiteturalmente, o objeto contém seu próprio conjunto de parâmetros treináveis (cEmbedding), que serve de base para a formação dos polinômios de Chebyshev.
Assim como nos módulos anteriores do framework, a estrutura da classe é construída de modo a minimizar overhead e eliminar operações dinâmicas desnecessárias. Todos os objetos internos aqui são declarados estaticamente, portanto o construtor e o destrutor permanecem vazios. Sua tarefa é apenas demarcar formalmente o ciclo de vida do objeto, sem interferir na lógica de alocação de recursos. Toda a preparação efetiva dos componentes fica concentrada no método Init, que atua como uma espécie de maestro: ele configura sequencialmente cada elemento interno, distribui as funções entre os Codificadores e os conecta em uma cadeia computacional unificada.
bool CNeuronHimNetEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
A inicialização começa com a passagem do controle para a classe pai, na qual já está estruturado o algoritmo de criação das interfaces básicas. Em seguida, é formada a sequência de componentes conectados: os parâmetros treináveis do embedding, a camada de transposição, os objetos que criam a matriz diagonal de correlação e normalizam as dependências obtidas, além do objeto de construção dos polinômios de Chebyshev para as transformações em grafos.
int index = 0; if(!cEmbedding.Init(0, index, OpenCL, units * embed_dim, optimization, iBatch)) return false; SetActivationFunction(TANH); index++; if(!cEmbeddingT.Init(0, index, OpenCL, units, embed_dim, optimization, iBatch)) return false; index++; if(!cSupport.Init(0, index, OpenCL, units * units, optimization, iBatch)) return false; cSupport.SetActivationFunction(None); index++; if(!cNormSupport.Init(0, index, OpenCL, cSupport.Neurons(), optimization, iBatch)) return false; cNormSupport.SetHeads(units); cNormSupport.SetActivationFunction(None); index++; if(!cPolinomSupport.Init(0, index, OpenCL, units, cheb_k, optimization, iBatch)) return false;
Cada elemento recebe seu próprio índice no pipeline computacional, e as funções de ativação são definidas exatamente onde são necessárias. Para o objeto de formação dos embeddings, usamos a tangente hiperbólica, que permite definir de forma normalizada as dependências diretas e inversas.
A sincronização dos dois fluxos merece atenção especial: o temporal (cTempEncoder) e o espacial (cSpatEncoder). O primeiro é responsável por extrair padrões temporais considerando períodos multiescala e janelas de previsão; o segundo, pelo mapeamento das relações entre as unidades de análise. Ao final, os buffers de gradientes desses fluxos são sincronizados, o que evita cópias redundantes de dados e garante uma retropropagação suave do erro.
index++; if(!cTempEncoder.Init(0, index, OpenCL, units, window, window_out, cheb_k, layers, (embed_dim + 1) / 2, period1, timeframe1, period2, timeframe2, optimization, iBatch)) return false; index++; if(!cSpatEncoder.Init(0, index, OpenCL, units, window, window_out, cheb_k, layers, embed_dim, optimization, iBatch)) return false; //--- if(!SetGradient(cTempEncoder.getGradient(), true)) return false; //--- return true; }
Assim, o método Init atua como ponto de integração de todo o módulo, transformando componentes dispersos em uma arquitetura única e consistente, pronta para treinamento e operação com dados financeiros reais.
Depois de concluída a inicialização do objeto, passamos à construção do algoritmo de propagação.
bool CNeuronHimNetEncoder::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
Começamos pelas verificações mais básicas: confirmamos que foi recebido um ponteiro válido para o objeto dos dados de entrada do segundo fluxo de informação. Nele, esperamos obter a marca de tempo da sequência analisada. Se o ponteiro estiver ausente, saímos imediatamente, sem arriscar corromper o estado do grafo e dos buffers.
Em seguida, surge uma ramificação importante. No modo de treinamento, reconstruímos o grafo adaptativo do zero. Primeiro, geramos o embedding. Depois, preparamos sua representação transposta.
if(bTrain) { if(!cEmbedding.FeedForward()) return false; if(!cEmbeddingT.FeedForward(cEmbedding.AsObject())) return false; if(!MatMul(cEmbedding.getOutput(), cEmbeddingT.getOutput(), cSupport.getOutput(), cEmbeddingT.GetCount(), cEmbeddingT.GetWindow(), cEmbeddingT.GetCount(), 1, false)) return false; if(!cNormSupport.FeedForward(cSupport.AsObject())) return false; if(!cPolinomSupport.FeedForward(cNormSupport.AsObject())) return false; }
A operação MatMul realiza a multiplicação matricial do embedding obtido por sua cópia transposta, formando a matriz bruta de correlação diagonal entre os nós. No contexto de trading, isso significa que pares de instrumentos com assinaturas comportamentais semelhantes ficarão mais fortemente conectados.
Normalizamos o grafo bruto com a função SoftMax, aplicando um pós-processamento estável. Como resultado, obtemos uma matriz de adjacência estocástica, adequada para a convolução em grafos.
Depois, construímos os polinômios de Chebyshev. Esse é o nosso telescópio K-hop, que permite acumular a influência dos vizinhos a uma distância de até K arestas sem diagonalizar o laplaciano: de forma rápida, numericamente estável e totalmente na GPU.
No modo de inferência, essa seção é ignorada. Usamos os embeddings e os polinômios já obtidos no treinamento, para não desperdiçar tempo computacional e preservar o determinismo.
Em seguida, chega a vez dos dois Codificadores. Primeiro, passamos para o fluxo temporal a sequência multimodal dos dados analisados, o conjunto de polinômios de Chebyshev e a marca de tempo.
if(!cTempEncoder.feedForward(NeuronOCL, cPolinomSupport.AsObject(), int(SecondInput[0]))) return false;
O Codificador combina o que está acontecendo agora com o momento exato em que isso ocorre, sobrepondo o regime temporal à dinâmica em grafos.
Em paralelo, iniciamos o Codificador espacial.
if(!cSpatEncoder.feedForward(NeuronOCL, cPolinomSupport.AsObject())) return false;
Ele não precisa de um marcador temporal: aqui operam embeddings nodais estacionários. A via espacial é responsável pelo mapa estável do mercado. Os dois fluxos enxergam a mesma base K-hop, mas a observam por ângulos diferentes: pelo tempo e pelo espaço.
A etapa final é a agregação cuidadosa dos resultados. Somamos as saídas dos Codificadores.
if(!SumAndNormilize(cTempEncoder.getOutput(), cSpatEncoder.getOutput(), Output, cTempEncoder.GetWindowOut(), false, 0, 0, 0, 1)) return false; //--- return true; }
Na prática, isso funciona como um ensemble simples, mas confiável: o canal temporal captura regimes de sessão e efeitos de calendário, enquanto o espacial captura clusters estáveis. Na saída, obtemos uma representação latente que se comporta com a mesma segurança tanto em um mercado calmo quanto durante picos provocados por notícias. O modelo não se sobreajusta a um único tipo de sinal, porque o sinal vem de duas fontes coordenadas.
Se cada elo for executado sem erros, o método retorna true. Caso contrário, saímos imediatamente, sem deixar estados inconsistentes nos buffers. Esse controle conservador do fluxo é especialmente importante no trading real: quando o modelo é executado em ticks ou em barras de 1 minuto, não há margem para se recuperar a partir de dados parcialmente corrompidos. Ou a previsão é correta e oportuna, ou ela simplesmente não deve existir.
Depois de concluída a propagação, o modelo passa a uma das etapas mais críticas: a distribuição dos gradientes do erro. É aqui que se decide até que ponto cada elemento da arquitetura receberá corretamente o sinal de feedback e conseguirá ajustar seus pesos. O método calcInputGradients, nesta classe, é estruturado para que essa etapa ocorra de forma sequencial, sem custos computacionais desnecessários e com custo mínimo de cópia de dados.
bool CNeuronHimNetEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cTempEncoder.calcInputGradients(prevLayer, cPolinomSupport.AsObject())) return false;
Primeiro, os gradientes são extraídos do Codificador temporal e cuidadosamente transferidos para os buffers de suporte polinomial e da camada anterior.
Em seguida, o procedimento é repetido para o Codificador espacial, mas antes precisamos preservar os dados já obtidos. E aqui não se trata apenas dos componentes internos, mas também do objeto dos dados de entrada. Afinal, na propagação, os dois Codificadores analisam o mesmo conjunto de dados de entrada.
CBufferFloat* temp = cPolinomSupport.getGradient(); CBufferFloat* prev = prevLayer.getGradient(); if(!cPolinomSupport.SetGradient(cPolinomSupport.getPrevOutput(), false) || !prevLayer.SetGradient(prevLayer.getPrevOutput(), false) || !cSpatEncoder.calcInputGradients(prevLayer, cPolinomSupport.AsObject()) || !SumAndNormilize(temp, cPolinomSupport.getGradient(), temp, cSpatEncoder.GetCount(), false, 0, 0, 0, 1) || !SumAndNormilize(prev, prevLayer.getGradient(), prev, cSpatEncoder.GetCount(), false, 0, 0, 0, 1) || !cPolinomSupport.SetGradient(temp, false) || !prevLayer.SetGradient(prev, false)) return false; if(prevLayer.Activation() != None) if(!DeActivation(prevLayer.getOutput(), prev, prev, prevLayer.Activation())) return false;
Os dados dos dois fluxos de informação são cuidadosamente somados.
Depois, a retropropagação avança para os níveis inferiores da cadeia: precisamos distribuir os gradientes do erro dos polinômios de Chebyshev até o nível dos embeddings, preservando a continuidade do fluxo de informação.
//--- if(!cNormSupport.CalcHiddenGradients(cPolinomSupport.AsObject())) return false; if(!cSupport.CalcHiddenGradients(cNormSupport.AsObject())) return false; if(!MatMulGrad(cEmbedding.getOutput(), cEmbedding.getPrevOutput(), cEmbeddingT.getOutput(), cEmbeddingT.getGradient(), cSupport.getGradient(), cEmbeddingT.GetCount(), cEmbeddingT.GetWindow(), cEmbeddingT.GetCount(), 1, false)) return false; if(!cEmbedding.CalcHiddenGradients(cEmbeddingT.AsObject())) return false; if(!SumAndNormilize(cEmbedding.getGradient(), cEmbedding.getPrevOutput(), cEmbedding.getGradient(), cEmbeddingT.GetWindow(), false, 0, 0, 0, 1)) return false; if(cEmbedding.Activation() != None) if(!DeActivation(cEmbedding.getOutput(), cEmbedding.getGradient(), cEmbedding.getGradient(), cEmbedding.Activation())) return false; //--- return true; }
Como resultado, o método percorre um percurso de feedback cuidadosamente estruturado, no qual cada camada recebe exatamente a parcela de sinal corretivo que lhe corresponde. Isso reduz o risco de divergência dos gradientes, aumenta a estabilidade do treinamento e torna a otimização mais controlável.
O método de atualização dos parâmetros é implementado de forma extremamente concisa, e é justamente aí que está sua força. Ele não tenta interferir nos cálculos de cada bloco, apenas delega a responsabilidade aos componentes correspondentes.
bool CNeuronHimNetEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cEmbedding.UpdateInputWeights()) return false; if(!cTempEncoder.updateInputWeights(NeuronOCL, cPolinomSupport.AsObject())) return false; if(!cSpatEncoder.updateInputWeights(NeuronOCL, cPolinomSupport.AsObject())) return false; //--- return true; }
Para quem quiser se aprofundar nos detalhes, o código completo da classe e de todos os seus métodos está anexado e pode ser estudado no ritmo desejado.
Decodificador
Ao concluir a aplicação das abordagens do framework HimNet, passamos ao componente final e igualmente importante: o Decodificador. Se o Codificador atuava como coletor de informações, condensando e estruturando os dados em uma representação compacta, o Decodificador atua como um restaurador habilidoso: camada após camada, ele reconstrói o conteúdo original a partir do espaço latente, devolvendo aos dados sua forma habitual, mas agora enriquecida e livre de ruído excessivo.
class CNeuronHimNetDecoder : public CNeuronBaseOCL { protected: CNeuronConvOCL cProjection; CNeuronTransposeOCL cProjectionT; CNeuronConvOCL cEmbedding; CNeuronBaseOCL cSupport; CNeuronSoftMaxOCL cNormSupport; CChebPolinom cPolinomSupport; CLayer cGRCUs; CBufferFloat bSupportAccum; CBufferFloat bEmbeddingAccum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHimNetDecoder(void) {}; ~CNeuronHimNetDecoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHimNetDecoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; };
Do ponto de vista arquitetural, o Decodificador preserva a continuidade arquitetural e a simetria com o Codificador, o que torna a estrutura geral da rede equilibrada e fácil de interpretar. No entanto, diferentemente do Codificador, no qual os embeddings espaciais e temporais podiam ser formados separadamente e se complementar, no Decodificador é usado um embedding espaço-temporal unificado, gerado com base na representação latente obtida na saída do Codificador. Essa mesma representação latente serve de base para a construção dos polinômios de Chebyshev, usados para aproximar a dinâmica complexa durante a reconstrução das séries temporais.
Depois de analisarmos a arquitetura do Decodificador, a etapa seguinte é a inicialização sequencial de todos os seus componentes internos. O método Init começa com a passagem do controle para a classe pai, que realiza a inicialização das interfaces básicas.
bool CNeuronHimNetDecoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
Em seguida, é criada a camada de projeção dos dados de entrada cProjection e o objeto de transposição da projeção obtida, cProjectionT.
int index = 0; if(!cProjection.Init(0, index, OpenCL, window, window, embed_dim, units, 1, optimization, iBatch)) return false; SetActivationFunction(TANH); index++; if(!cProjectionT.Init(0, index, OpenCL, units, embed_dim, optimization, iBatch)) return false;
À camada cProjection é atribuída a função de ativação TANH, o que permite formar corretamente representações espaço-temporais com base na representação latente recebida do Codificador.
Depois disso, é criada a camada de geração de embeddings cEmbedding, cujas dimensões correspondem à quantidade de neurônios e à dimensão dos atributos. Esses embeddings são usados nos cálculos posteriores dos blocos recorrentes.
index++; if(!cEmbedding.Init(0, index, OpenCL, units, units, 1, 1, embed_dim, optimization, iBatch)) return false; SetActivationFunction(SIGMOID); index++; if(!cSupport.Init(0, index, OpenCL, units * units, optimization, iBatch)) return false; cSupport.SetActivationFunction(None); index++; if(!cNormSupport.Init(0, index, OpenCL, cSupport.Neurons(), optimization, iBatch)) return false; cNormSupport.SetHeads(units); cNormSupport.SetActivationFunction(None); index++; if(!cPolinomSupport.Init(0, index, OpenCL, units, cheb_k, optimization, iBatch)) return false;
Os objetos cSupport e cNormSupport desempenham um papel central na preparação dos dados para os polinômios de Chebyshev. Primeiro, cSupport forma a matriz diagonal de correlação, que reflete as relações entre diferentes atributos ou fluxos temporais. Em seguida, cNormSupport normaliza os valores dessa matriz em uma escala comum, garantindo a estabilidade dos cálculos e a correção das operações posteriores. É justamente essa matriz normalizada que serve de base para o bloco cPolinomSupport, no qual são construídos os polinômios de Chebyshev que serão usados posteriormente nos cálculos dos blocos recorrentes GCRU. Essa abordagem permite modelar dependências complexas entre os atributos, preservando precisão e consistência no fluxo computacional.
A etapa seguinte é a criação do contêiner cGRCUs para os blocos recorrentes GCRU. Nele, os blocos são adicionados em sequência: o primeiro recebe a dimensão do espaço de atributos correspondente aos dados de entrada, enquanto todos os seguintes usam um tamanho fixo de tensor.
//--- cGRCUs.Clear(); cGRCUs.SetOpenCL(OpenCL); index++; CNeuronHimNetGCRU *temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window, window_out, cheb_k, embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) { DeleteObj(temp); return false; } for(uint i = 1; i < layers; i++) { index++; temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window_out, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) { DeleteObj(temp); return false; } }
Todos os blocos são vinculados ao contexto OpenCL, o que garante a aceleração dos cálculos.
Para armazenar os resultados intermediários dos gradientes do erro, são alocados os buffers bSupportAccum e bEmbeddingAccum.
bSupportAccum.BufferFree(); bSupportAccum.Clear(); if(!bSupportAccum.BufferInit(cPolinomSupport.Neurons(), 0) || !bSupportAccum.BufferCreate(OpenCL)) return false; bEmbeddingAccum.BufferFree(); bEmbeddingAccum.Clear(); if(!bEmbeddingAccum.BufferInit(cEmbedding.Neurons(), 0) || !bEmbeddingAccum.BufferCreate(OpenCL)) return false; //--- SetActivationFunction((ENUM_ACTIVATION)temp.Activation()); if(!SetOutput(temp.getOutput(), true) || !SetGradient(temp.getGradient(), true)) return false; //--- return true; }
A inicialização é concluída com a sincronização das funções de ativação do último bloco para todo o Decodificador, bem como dos ponteiros para os buffers de saída e para os gradientes do erro. Isso elimina cópias desnecessárias de dados e garante que o modelo esteja pronto para treinamento e para a propagação. Cada etapa é cuidadosamente verificada: em caso de qualquer erro, o método retorna false, evitando um estado inconsistente do modelo e garantindo a estabilidade dos cálculos posteriores.
Depois da inicialização bem-sucedida de todos os componentes do Decodificador, passamos à construção do método de propagação, que é o núcleo do processamento do sinal. Nesta etapa, a informação analisada percorre sequencialmente vários blocos interconectados, cada um executando sua própria função específica e garantindo o funcionamento preciso e coordenado do modelo.
bool CNeuronHimNetDecoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cProjection.FeedForward(NeuronOCL)) return false; if(!cProjectionT.FeedForward(cProjection.AsObject())) return false; if(!MatMul(cProjection.getOutput(), cProjectionT.getOutput(), cSupport.getOutput(), cProjectionT.GetCount(), cProjectionT.GetWindow(), cProjectionT.GetCount(), 1, false)) return false; if(!cNormSupport.FeedForward(cSupport.AsObject())) return false;
Na etapa inicial, o sinal é processado nos módulos cProjection e cProjectionT, que transformam os dados de entrada em uma representação latente com a dimensão especificada. Os tensores resultantes passam por multiplicação matricial, formando uma matriz diagonal de correlação. Em seguida, essa matriz é normalizada com a função SoftMax. Essa normalização é criticamente importante para a construção dos polinômios de Chebyshev no bloco cPolinomSupport, pois garante a estabilidade dos cálculos e o ajuste correto da escala de influência de cada elemento sobre as camadas posteriores.
if(!cPolinomSupport.FeedForward(cNormSupport.AsObject())) return false; //--- if(!cEmbedding.FeedForward(cProjectionT.AsObject())) return false;
Depois, são gerados embeddings no bloco cEmbedding, criando uma representação compacta e informativa das características ocultas dos dados.
Após a preparação dos dados, o sinal entra no primeiro bloco GCRU do contêiner cGRCUs, onde ocorre o processamento recorrente em grafos da informação. Cada bloco GCRU seguinte recebe como entrada a saída do anterior, permitindo que o Decodificador acumule dependências temporais e espaciais e identifique padrões complexos nos dados históricos.
CNeuronHimNetGCRU* current = NULL; CNeuronBaseOCL* inputs = NeuronOCL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current || !current. Feedforward(NeuronOCL, cPolinomSupport.AsObject(), cEmbedding.AsObject())) return false; inputs = current; } //--- return true; }
Como resultado dessas transformações sequenciais, é formada a saída final do Decodificador. Essa abordagem garante o funcionamento coordenado do modelo e o uso eficiente dos recursos computacionais, o que é especialmente importante no processamento de grandes volumes de dados financeiros e no treinamento em séries temporais históricas.
Você provavelmente já percebeu como a lógica de execução do Decodificador segue naturalmente a lógica demonstrada nos Codificadores analisados acima. Por isso, sugiro deixar o estudo detalhado dos métodos de retropropagação do erro para uma leitura independente. O código completo da classe, com todos os seus métodos, está apresentado no anexo.
Teste
Depois de reunirmos todos os componentes principais do framework HimNet, chega a hora de passar à etapa mais interessante: o treinamento e o teste do modelo. Nosso objetivo permanece o mesmo: criar um sistema de trading capaz de analisar o mercado de forma autônoma e tomar decisões. Nesse esquema, o HimNet atua como Codificador do estado do ambiente, formando uma representação compacta, mas informativa, da situação atual do mercado. O Ator se apoia nessa representação ao escolher ações, enquanto o Crítico avalia sua qualidade, fornecendo feedback e ajustando a estratégia.
O treinamento é estruturado em duas etapas complementares, o que oferece, ao mesmo tempo, uma base sólida e flexibilidade para operar em condições reais de mercado. Na primeira etapa, offline, realizamos um treinamento aprofundado com dados históricos do par EURUSD no timeframe H1 ao longo de todo o ano de 2024. Esse período incluiu um espectro completo de regimes de mercado: lateralizações tranquilas, tendências sustentadas, saltos bruscos de volatilidade e períodos de ruído intensificado, servindo como um excelente conjunto de aprendizado para o modelo.
A segunda etapa é o ajuste fino online. O modelo processou sequencialmente o fluxo de candles no testador de estratégias do MetaTrader 5, em um ambiente o mais próximo possível do trading real. Essa etapa revela propriedades completamente diferentes das observadas no treinamento offline: a capacidade de tolerar ruído, reagir adequadamente a mudanças de liquidez, considerar atrasos e o efeito do slippage. Simulamos cuidadosamente condições reais de execução para que o comportamento do modelo permanecesse previsível ao ser transferido para condições reais de mercado.
A etapa final e mais rigorosa da validação foi realizada em uma amostra totalmente externa: cotações de janeiro a março de 2025. Todos os parâmetros do modelo permaneceram congelados durante esse teste. Essa validação apresenta um panorama objetivo da eficiência prática: a capacidade do algoritmo de manter robustez e previsibilidade em novas condições.
Os resultados do teste são apresentados abaixo.
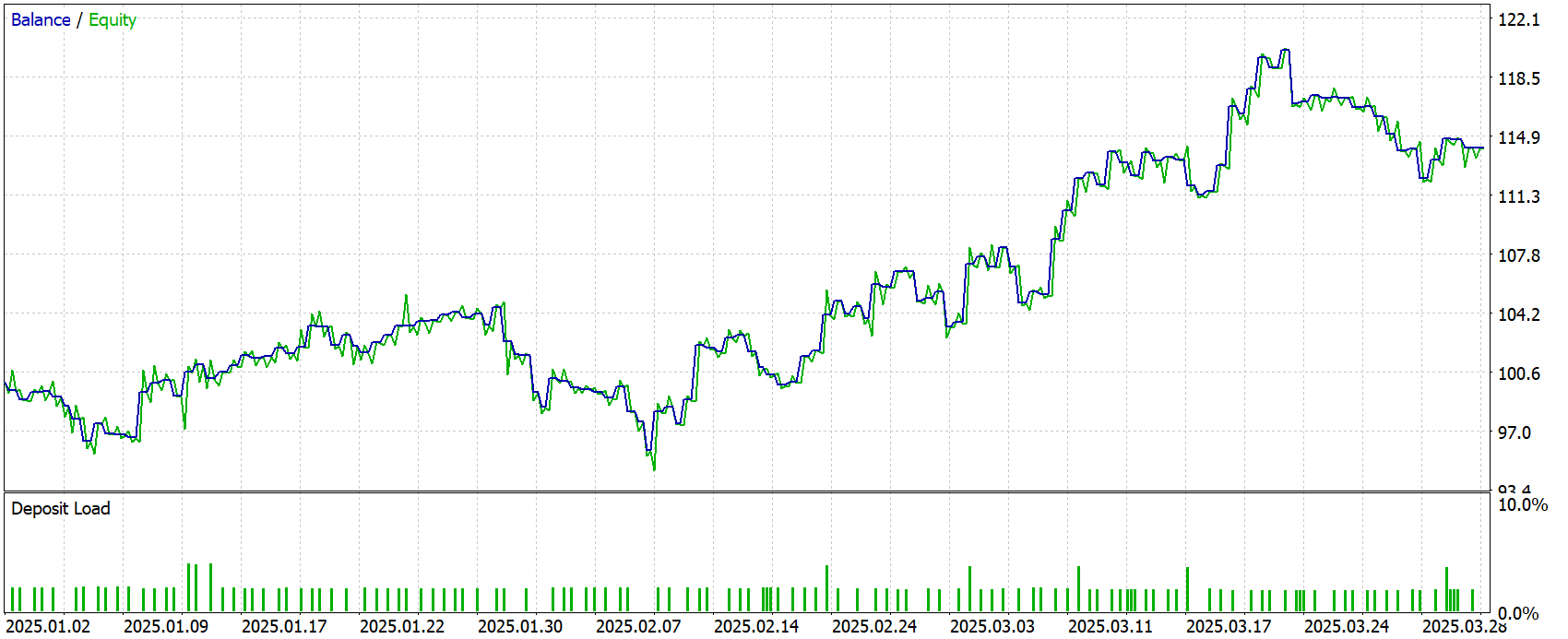
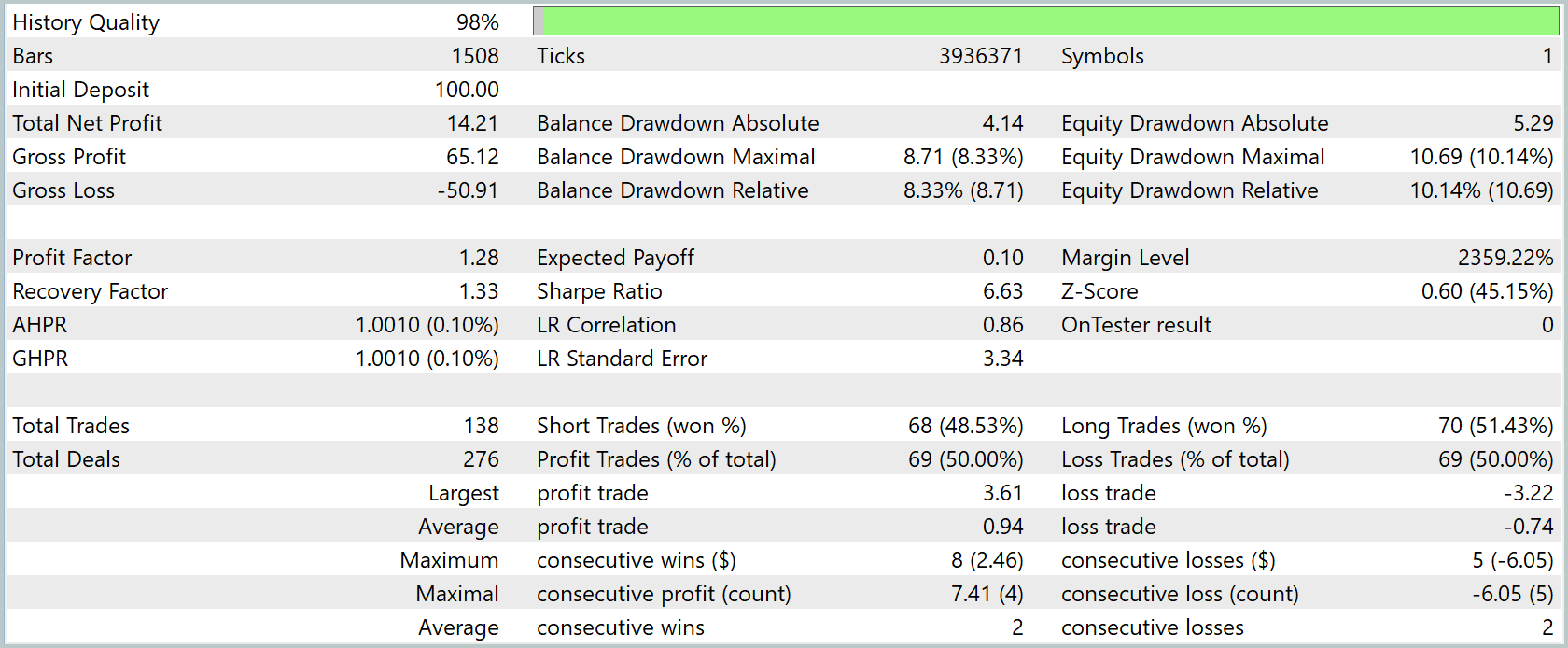
Ao longo dos três meses do período de teste, o lucro líquido atingiu 14,21% em relação ao capital inicial. O lucro para cada dólar de perda foi de US$1,28, enquanto a expectativa matemática média por operação foi de apenas US$0,10. O fator de recuperação de 1,33 indica que o lucro final superou o drawdown máximo pelo saldo.
Os drawdowns permaneceram moderados: o absoluto foi de US$4,14 pelo saldo e US$5,29 pelo equity, enquanto o relativo máximo foi de 8,33% e 10,14%, respectivamente. Ao mesmo tempo, a curva de lucro demonstrou crescimento consistente, o que é confirmado pela correlação da tendência ao longo do tempo no nível de 0,86.
Durante todo o teste, o EA realizou 138 operações, distribuídas quase igualmente entre compras e vendas, e o percentual de operações lucrativas ficou próximo de 50% em ambas as direções. O lucro médio por operação vencedora foi de US$0,94, a perda média foi de US$0,74, o maior ganho chegou a US$3,61 e a maior perda foi de US$3,22. Em média, as posições foram mantidas por pouco mais de uma hora, e as variações no tempo de manutenção oscilaram de 57 minutos a duas horas, o que indica um estilo de operação claramente curto-prazista e intradiário.
Em conjunto, os resultados apontam para uma estratégia bastante estável, embora moderadamente lucrativa. Seus pontos fortes são os drawdowns controlados, a atuação equilibrada nos dois lados do mercado e a expectativa matemática positiva. Seus pontos fracos são a margem limitada no fator de lucro e o pequeno lucro médio por operação, o que pode torná-la sensível a spreads e comissões em uma conta real.
Conclusão
Neste artigo, concluímos o desenvolvimento das abordagens do framework HimNet em MQL5. As principais vantagens do framework são sua flexibilidade arquitetural e sua capacidade de adaptação a diversas tarefas relacionadas à previsão e à análise de séries temporais.
Os resultados do teste final em novas cotações, que não faziam parte da amostra de treinamento, mostraram uma dinâmica positiva. O saldo do modelo apresentou crescimento estável, o que indica sua capacidade de se adaptar com eficiência a condições de mercado em mudança.
Referências
- Heterogeneity-Informed Meta-Parameter Learning for Spatiotemporal Time Series Forecasting
- Outros artigos da série
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA para treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação da rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19286
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Caminhe em novos trilhos: Personalize indicadores no MQL5
Caminhe em novos trilhos: Personalize indicadores no MQL5
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso