
Robô de negociação baseado em um modelo de linguagem GPT

Introdução
O TimeGPT é um modelo de aprendizado de máquina desenvolvido para prever os movimentos dos preços nos mercados financeiros, como pares de moedas ou ações, na plataforma MetaTrader 5. Ele se baseia na arquitetura Transformer, que foi originalmente criada para trabalhar com textos, por exemplo, para tradução ou geração de texto, mas que, neste caso, foi adaptada para a análise de dados financeiros. Neste artigo, explicarei detalhadamente como o TimeGPT é criado, analisando passo a passo sua estrutura, o processamento dos dados, o treinamento e a previsão. Tudo será explicado de forma simples, com analogias, para que até mesmo quem está começando a estudar aprendizado de máquina possa entender como esse modelo é criado. No final, também abordarei as limitações do modelo e seus requisitos de recursos computacionais.
O que é necessário para criar um modelo como o TimeGPT?Antes de nos aprofundarmos no código, é importante entender com o que o TimeGPT trabalha. Os mercados financeiros geram dados na forma de séries temporais, ou seja, sequências de preços registrados em intervalos regulares, por exemplo, a cada hora. Os preços no mercado não seguem regras simples: eles podem subir drasticamente devido a notícias, cair lentamente ou oscilar sem motivo aparente. A tarefa do TimeGPT é identificar padrões nesses dados e prever como o preço mudará em 24 horas, o que, em termos de gráficos de mercado, é chamado de 24 barras.
O desenvolvimento de um modelo exige resolver várias tarefas. Primeiro, é preciso definir como armazenar e processar os dados de preços. Em seguida, é necessário converter esses dados para um formato que o modelo consiga processar. Depois, é preciso projetar a arquitetura do modelo para que ele seja capaz de identificar relações complexas nos dados. Depois disso, o modelo é treinado com dados históricos para que o modelo aprenda a fazer previsões precisas. Por fim, é importante otimizar o modelo para que ele funcione rapidamente e não exija muita memória, levando em conta as limitações da plataforma MetaTrader 5. Agora, vamos analisar cada uma dessas etapas, com base no código do arquivo TimeGPT_Fixed.mqh.
Desenvolvimento do modelo
Criando uma estrutura para trabalhar com dados O primeiro passo no desenvolvimento do TimeGPT foi a criação de uma estrutura para armazenamento e processamento de dados. No aprendizado de máquina, os dados costumam ser representados na forma de matrizes, uma espécie de tabela numérica que facilita operações matemáticas. Para isso, foi criada a estrutura TGMatrix no TimeGPT, que permite armazenar números, como preços ou parâmetros do modelo, de forma organizada.
Veja como fica o código dessa estrutura:
struct TGMatrix { double data[]; int rows, cols; void Init(int r, int c) { rows = r; cols = c; ArrayResize(data, r * c); ArrayInitialize(data, 0.0); } double Get(int r, int c) const { if(r < 0 || r >= rows || c < 0 || c >= cols) return 0.0; return data[r * cols + c]; } void Set(int r, int c, double val) { if(r < 0 || r >= rows || c < 0 || c >= cols) return; data[r * cols + c] = val; } void RandomInit(double scale = -1.0) { if(scale < 0) scale = MathSqrt(2.0 / (rows + cols)); for(int i = 0; i < ArraySize(data); i++) { data[i] = (MathRand() / 32767.0 - 0.5) * 2.0 * scale; } } void Add(const TGMatrix &other) { if(rows != other.rows || cols != other.cols) return; for(int i = 0; i < ArraySize(data); i++) { data[i] += other.data[i]; } } void Copy(const TGMatrix &other) { Init(other.rows, other.cols); for(int i = 0; i < ArraySize(other.data); i++) { data[i] = other.data[i]; } } void Scale(double factor) { for(int i = 0; i < ArraySize(data); i++) { data[i] *= factor; } } };
Imagine o TGMatrix como uma tabela no Excel, onde os números são armazenados em linhas e colunas. O método Init cria uma tabela do tamanho desejado; Get e Set permitem ler e gravar valores em determinadas células; RandomInit preenche a tabela com números aleatórios, necessários para a configuração inicial do modelo; e os métodos Add, Copy e Scale realizam operações básicas, como somar duas tabelas ou multiplicar todos os números por um determinado valor. Essa estrutura serviu de base para o processamento de dados no TimeGPT, pois todos os preços, parâmetros do modelo e cálculos utilizam matrizes. Optamos por essa abordagem, pois ela é simples e funciona bem no MetaTrader 5, onde não é possível utilizar bibliotecas complexas, como no Python.
Convertendo os preços em um formato adequado para o modeloPara que o modelo possa analisar os preços, é preciso convertê-los em um formato acessível. O TimeGPT adota uma ideia retirada do processamento de texto: cada variação de preço é convertida em um 'token', um número que representa a variação do preço, por exemplo, um aumento de 0,5% ou uma queda de 0,3%. Para isso, foi criada a estrutura ImprovedTokenizer.
Veja o código da estrutura:
struct ImprovedTokenizer { double price_mean, price_std; double change_mean, change_std; bool is_trained; ImprovedTokenizer() { is_trained = false; price_mean = 0; price_std = 1; change_mean = 0; change_std = 1; } void Train(const MqlRates &rates[]) { int size = ArraySize(rates); if(size < FORECAST_HORIZON + 10) return; // Вычисляем статистики для цен double sum_price = 0, sum_price_sq = 0; double changes[]; ArrayResize(changes, size - FORECAST_HORIZON); for(int i = FORECAST_HORIZON; i < size; i++) { double price = rates[i].close; sum_price += price; sum_price_sq += price * price; // Изменение цены через 24 бара changes[i - FORECAST_HORIZON] = (rates[i].close - rates[i - FORECAST_HORIZON].close) / rates[i - FORECAST_HORIZON].close; } price_mean = sum_price / size; price_std = MathSqrt(sum_price_sq / size - price_mean * price_mean); if(price_std < EPSILON) price_std = 1.0; // Статистики для изменений на 24 бара double sum_change = 0, sum_change_sq = 0; for(int i = 0; i < ArraySize(changes); i++) { sum_change += changes[i]; sum_change_sq += changes[i] * changes[i]; } change_mean = sum_change / ArraySize(changes); change_std = MathSqrt(sum_change_sq / ArraySize(changes) - change_mean * change_mean); if(change_std < EPSILON) change_std = 1.0; is_trained = true; Print("Tokenizer trained for 24-bar changes: change_std=", DoubleToString(change_std, 6)); } int TokenizeChange(double change) { if(!is_trained) return VOCAB_SIZE / 2; // Нормализуем и квантуем double normalized = (change - change_mean) / change_std; normalized = MathMax(-3.0, MathMin(3.0, normalized)); // Клампим int token = (int)((normalized + 3.0) / 6.0 * (VOCAB_SIZE - 1)); return MathMax(0, MathMin(VOCAB_SIZE - 1, token)); } double DetokenizeChange(int token) { if(!is_trained || token < 0 || token >= VOCAB_SIZE) return 0.0; double normalized = (double)token / (VOCAB_SIZE - 1) * 6.0 - 3.0; return normalized * change_std + change_mean; } };
O tokenizador funciona da seguinte maneira. O método Train analisa os preços históricos de fechamento das velas, por exemplo, das últimas 2.000 horas, e calcula como eles se alteraram após 24 barras. Se o preço era de US$ 100 e, após 24 horas, passou a ser US$ 102, a variação será (102 - 100) / 100 = 2%. Em seguida, o tokenizador calcula a média e o desvio padrão de todas as variações, a fim de padronizá-las em uma escala única. É como ajustar uma régua para medir todas as variações nas mesmas unidades. O método TokenizeChange transforma cada variação em um número de 0 a 255 (tamanho do dicionário VOCAB_SIZE = 256); por exemplo, um aumento de 2% pode se tornar o token "150". O método DetokenizeChange realiza a conversão inversa, permitindo entender qual variação de preço corresponde a um determinado token.
Essa abordagem é importante porque os preços brutos podem variar muito: uma ação custa US$ 10, enquanto outra custa US$ 1.000. A conversão em tokens simplifica os dados para o modelo, permitindo que ele trabalhe com números em uma mesma faixa, de modo semelhante ao texto, em que cada palavra tem seu próprio código.
Construção do mecanismo de atençãoA parte-chave do TimeGPT é o mecanismo de atenção, implementado na estrutura SimpleAttention. Ele permite que o modelo se concentre nas variações passadas de preço mais importantes, ignorando as menos significativas. Imagine que você está lendo um livro longo e destaca apenas os pontos-chave que ajudam a entender o enredo. O mecanismo de atenção faz exatamente o mesmo, decidindo quais dados sobre preços são importantes para a previsão.
Este é o código do mecanismo de atenção:
struct SimpleAttention { TGMatrix W_q, W_k, W_v, W_o; double scale; void Init() { W_q.Init(MODEL_DIM, MODEL_DIM); W_k.Init(MODEL_DIM, MODEL_DIM); W_v.Init(MODEL_DIM, MODEL_DIM); W_o.Init(MODEL_DIM, MODEL_DIM); double init_scale = MathSqrt(2.0 / MODEL_DIM); W_q.RandomInit(init_scale); W_k.RandomInit(init_scale); W_v.RandomInit(init_scale); W_o.RandomInit(init_scale); scale = 1.0 / MathSqrt(HEAD_DIM); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { int seq_len = inp_data.rows; output.Init(seq_len, MODEL_DIM); // Многоголовое внимание for(int head = 0; head < NUM_HEADS; head++) { int head_start = head * HEAD_DIM; // Простые проекции для этой головы TGMatrix head_output; head_output.Init(seq_len, HEAD_DIM); for(int i = 0; i < seq_len; i++) { // Вычисляем внимание только к предыдущим позициям double total_weight = 0.0; double weighted_values[HEAD_DIM]; ArrayInitialize(weighted_values, 0.0); for(int j = 0; j <= i; j++) { // Простое скалярное произведение для веса внимания double attention_weight = 0.0; for(int k = head_start; k < head_start + HEAD_DIM; k++) { attention_weight += inp_data.Get(i, k) * inp_data.Get(j, k); } attention_weight = MathExp(attention_weight * scale); total_weight += attention_weight; // Накапливаем взвешенные значения for(int k = 0; k < HEAD_DIM; k++) { weighted_values[k] += attention_weight * inp_data.Get(j, head_start + k); } } // Нормализуем и записываем if(total_weight > EPSILON) { for(int k = 0; k < HEAD_DIM; k++) { head_output.Set(i, k, weighted_values[k] / total_weight); } } } // Копируем результат головы в выходную матрицу for(int i = 0; i < seq_len; i++) { for(int j = 0; j < HEAD_DIM; j++) { output.Set(i, head_start + j, head_output.Get(i, j)); } } } } };
O mecanismo de atenção divide os dados em seis partes, chamadas de 'cabeças' (NUM_HEADS = 6), cada uma procura padrões próprios, por exemplo, saltos de preço de curto prazo ou tendências de longo prazo. O método Init cria as matrizes W_q, W_k, W_v e W_o, que são usadas para transformar os dados, e as preenche com números aleatórios. No método Forward, o modelo calcula o grau de importância de cada posição anterior na sequência para a posição atual, utilizando o produto escalar e a função MathExp.
É importante que o modelo considere apenas os dados até a posição atual (j <= i), para não 'espiar' o futuro; isso é chamado de mascaramento causal. Os pesos de atenção são normalizados para que sua soma seja igual a um e são usados para ponderar os dados, como se o modelo dissesse: 'Este momento é 70% importante, e aquele, apenas 20%'.
Esse mecanismo permite que o TimeGPT identifique relações complexas entre as variações de preço, mesmo quando essas variações ocorreram há muito tempo, o que o torna mais poderoso do que os modelos antigos, que 'esquecem' rapidamente os dados históricos.
Montagem das camadas TransformerO TimeGPT possui seis camadas (NUM_LAYERS = 6), cada uma delas incluindo um mecanismo de atenção e um processamento adicional dos dados por meio de uma rede feed-forward (FFN). É como um filtro que melhora gradualmente a compreensão dos dados à medida que estes passam por várias etapas de processamento.
Este é o código de uma camada:
struct TransformerLayer { SimpleAttention attention; SimpleFeedForward ffn; void Init() { attention.Init(); ffn.Init(); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { // Внимание с остаточной связью TGMatrix attn_out; attention.Forward(inp_data, attn_out); TGMatrix residual1; residual1.Copy(inp_data); residual1.Add(attn_out); // FFN с остаточной связью TGMatrix ffn_out; ffn.Forward(residual1, ffn_out); output.Copy(residual1); output.Add(ffn_out); } };
Cada camada primeiro aplica o mecanismo de atenção para destacar as partes importantes dos dados e, em seguida, adiciona os dados originais ao resultado (isso é chamado de conexão residual), para não perder informações. Depois disso, os dados passam por uma rede feed-forward, que introduz não linearidade, permitindo identificar padrões complexos. Outra conexão residual soma o resultado da rede feed-forward aos dados após a atenção, mantendo a estabilidade.
Veja como é a rede feed-forward:
struct SimpleFeedForward { TGMatrix W1, W2, b1, b2; void Init() { W1.Init(MODEL_DIM, FFN_DIM); W2.Init(FFN_DIM, MODEL_DIM); b1.Init(1, FFN_DIM); b2.Init(1, MODEL_DIM); double init_scale = MathSqrt(2.0 / MODEL_DIM); W1.RandomInit(init_scale); W2.RandomInit(init_scale); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { int seq_len = inp_data.rows; output.Init(seq_len, MODEL_DIM); for(int i = 0; i < seq_len; i++) { // Первый слой с ReLU double hidden[FFN_DIM]; for(int j = 0; j < FFN_DIM; j++) { hidden[j] = b1.Get(0, j); for(int k = 0; k < MODEL_DIM; k++) { hidden[j] += inp_data.Get(i, k) * W1.Get(k, j); } hidden[j] = MathMax(0.0, hidden[j]); // ReLU } // Второй слой for(int j = 0; j < MODEL_DIM; j++) { double sum = b2.Get(0, j); for(int k = 0; k < FFN_DIM; k++) { sum += hidden[k] * W2.Get(k, j); } output.Set(i, j, sum); } } } };
A FFN recebe os dados e os transforma por meio de duas camadas: a primeira expande os dados até o tamanho FFN_DIM = 256 e aplica a função ReLU, que define os valores negativos como zero, adicionando não linearidade; já a segunda comprime os dados de volta para MODEL_DIM = 256. Isso ajuda o modelo a identificar combinações complexas de variações de preço que não são visíveis por métodos lineares simples.
As camadas do Transformer são a base do modelo. Cada camada aprimora a compreensão dos dados, e as seis camadas permitem identificar padrões cada vez mais complexos. As conexões residuais tornam o treinamento estável, evitando a perda de informações.
Integração dos componentes no modelo TimeGPTDepois de criar todas as partes, vamos reuni-las em um único modelo chamado FixedTimeGPT. Veja a estrutura dele:
struct FixedTimeGPT { ImprovedTokenizer tokenizer; TGMatrix embeddings; TransformerLayer layers[NUM_LAYERS]; TGMatrix output_projection; double learning_rate; int training_steps; bool is_trained; void Init() { embeddings.Init(VOCAB_SIZE, MODEL_DIM); embeddings.RandomInit(0.1); for(int i = 0; i < NUM_LAYERS; i++) { layers[i].Init(); } output_projection.Init(MODEL_DIM, VOCAB_SIZE); output_projection.RandomInit(0.1); learning_rate = LEARNING_RATE; training_steps = 0; is_trained = false; Print("Fixed TimeGPT initialized for 24-bar forecast"); } };
Essa estrutura reúne todos os componentes. O tokenizador converte os preços em tokens. A matriz de embeddings transforma cada token em um vetor de 256 números, para que o modelo possa processá-lo como uma representação numérica de uma palavra. Seis camadas do Transformer processam os dados, identificando padrões. A matriz output_projection transforma o resultado da última camada em uma distribuição de probabilidades sobre os tokens (de 0 a 255), a fim de prever a próxima variação de preço. O parâmetro learning_rate determina a taxa de aprendizado do modelo, enquanto training_steps acompanha o número de etapas de treinamento.
Essa estrutura é simples o suficiente para funcionar no MetaTrader 5, mas, ao mesmo tempo, tem expressividade suficiente para identificar padrões complexos.
Treinamento do modelo
Durante o treinamento, o modelo analisa dados históricos e ajusta seus parâmetros para fazer previsões precisas. Veja como isso funciona:
void TrainOnData(string symbol, ENUM_TIMEFRAMES timeframe, int total_bars, int epochs) { Print("Training Fixed TimeGPT for 24-bar forecast on ", total_bars, " bars, ", epochs, " epochs..."); // Получаем данные MqlRates rates[]; ArraySetAsSeries(rates, false); // Хронологический порядок if(CopyRates(symbol, timeframe, 0, total_bars, rates) <= 0) { Print("Failed to copy rates"); return; } // Обучаем токенайзер для изменений через 24 бара tokenizer.Train(rates); // Подготавливаем последовательности для обучения int num_sequences = total_bars - CONTEXT_LENGTH - FORECAST_HORIZON - 1; if(num_sequences <= 0) { Print("Not enough data for training"); return; } // Цикл обучения for(int epoch = 0; epoch < epochs; epoch++) { Print("Epoch ", epoch + 1, "/", epochs); double total_loss = 0.0; int batch_count = 0; // Обрабатываем последовательности for(int start = 0; start < num_sequences; start += CONTEXT_LENGTH/2) { if(start + CONTEXT_LENGTH + FORECAST_HORIZON >= ArraySize(rates)) break; double loss = TrainStep(rates, start); total_loss += loss; batch_count++; training_steps++; // Decay learning rate if(training_steps % 100 == 0) { learning_rate *= 0.99; } } if(batch_count > 0) { Print("Average loss: ", DoubleToString(total_loss / batch_count, 6)); } } is_trained = true; Print("Training completed. Total steps: ", training_steps); }
O modelo carrega os preços históricos, por exemplo, de 2.000 barras, para um par de moedas como o EUR/USD, no gráfico horário. O tokenizador analisa os dados para identificar as variações típicas dos preços. Em seguida, o modelo processa os dados várias vezes (três épocas), selecionando a cada vez uma sequência de 64 barras (CONTEXT_LENGTH = 64) e tentando prever a variação do preço após 24 barras.
O método TrainStep calcula o erro (loss), ou seja, a diferença entre a previsão e a variação real, e ajusta os parâmetros do modelo para reduzir esse erro. A cada 100 passos, a velocidade de aprendizado é reduzida em 1%, para que o modelo aprenda de forma mais cautelosa e evite erros graves.
Veja como é o TrainStep:
double TrainStep(const MqlRates &rates[], int start_pos) { // Простой шаг обучения для прогноза через 24 бара int tokens[CONTEXT_LENGTH + 1]; for(int i = 0; i < CONTEXT_LENGTH; i++) { int idx = start_pos + i; if(idx > 0 && idx < ArraySize(rates)) { double change = (rates[idx].close - rates[idx-1].close) / rates[idx-1].close; tokens[i] = tokenizer.TokenizeChange(change); } else { tokens[i] = VOCAB_SIZE / 2; } } // Цель - изменение через 24 бара int target_idx = start_pos + CONTEXT_LENGTH + FORECAST_HORIZON; if(target_idx < ArraySize(rates) && start_pos + CONTEXT_LENGTH > 0) { double change = (rates[target_idx].close - rates[target_idx - FORECAST_HORIZON].close) / rates[target_idx - FORECAST_HORIZON].close; tokens[CONTEXT_LENGTH] = tokenizer.TokenizeChange(change); } else { tokens[CONTEXT_LENGTH] = VOCAB_SIZE / 2; } // Прямой проход TGMatrix embedded; embedded.Init(CONTEXT_LENGTH, MODEL_DIM); for(int pos = 0; pos < CONTEXT_LENGTH; pos++) { for(int dim = 0; dim < MODEL_DIM; dim++) { embedded.Set(pos, dim, embeddings.Get(tokens[pos], dim)); } } TGMatrix current; current.Copy(embedded); for(int i = 0; i < NUM_LAYERS; i++) { TGMatrix layer_out; layers[i].Forward(current, layer_out); current.Copy(layer_out); } // Простая потеря int target = tokens[CONTEXT_LENGTH]; double loss = 0.0; for(int i = 0; i < MODEL_DIM; i++) { double pred = current.Get(CONTEXT_LENGTH - 1, i); double target_emb = embeddings.Get(target, i); double diff = pred - target_emb; loss += diff * diff; } return loss / MODEL_DIM; }
Neste código, o modelo recebe 64 barras de dados, transforma-as em tokens e adiciona o alvo: a variação do preço após 24 barras. Os tokens são convertidos em vetores por meio da matriz de embeddings e, em seguida, passam por seis camadas do Transformer. O erro é calculado como o desvio quadrático médio entre a previsão e a variação real. Isso ajuda o modelo a aprender que certas combinações passadas de variações de preço costumam levar a uma alta após 24 horas.
Previsão com o modelo
Após o treinamento, o modelo está pronto para fazer previsões. É assim que funciona:
double Predict(const MqlRates &rates[], int current_pos) { if(!is_trained || current_pos < CONTEXT_LENGTH + FORECAST_HORIZON) { return 0.5; // Нейтральное предсказание } // Подготавливаем входные токены int tokens[CONTEXT_LENGTH]; for(int i = 0; i < CONTEXT_LENGTH; i++) { int idx = current_pos - CONTEXT_LENGTH + i; if(idx > 0 && idx < ArraySize(rates)) { double change = (rates[idx].close - rates[idx-1].close) / rates[idx-1].close; tokens[i] = tokenizer.TokenizeChange(change); } else { tokens[i] = VOCAB_SIZE / 2; // Нейтральный токен } } // Прямой проход TGMatrix embedded; embedded.Init(CONTEXT_LENGTH, MODEL_DIM); // Эмбеддинги с позиционным кодированием for(int pos = 0; pos < CONTEXT_LENGTH; pos++) { for(int dim = 0; dim < MODEL_DIM; dim++) { double emb = embeddings.Get(tokens[pos], dim); double pos_enc = MathSin(pos / MathPow(10000.0, 2.0 * dim / MODEL_DIM)); embedded.Set(pos, dim, emb + 0.1 * pos_enc); } } // Проход через слои TGMatrix current; current.Copy(embedded); for(int i = 0; i < NUM_LAYERS; i++) { TGMatrix layer_out; layers[i].Forward(current, layer_out); current.Copy(layer_out); } // Получаем логиты для последней позиции double logits[VOCAB_SIZE]; for(int i = 0; i < VOCAB_SIZE; i++) { logits[i] = 0.0; for(int j = 0; j < MODEL_DIM; j++) { logits[i] += current.Get(CONTEXT_LENGTH - 1, j) * output_projection.Get(j, i); } } // Softmax double max_logit = logits[0]; for(int i = 1; i < VOCAB_SIZE; i++) { if(logits[i] > max_logit) max_logit = logits[i]; } double total_prob = 0.0; for(int i = 0; i < VOCAB_SIZE; i++) { logits[i] = MathExp(logits[i] - max_logit); total_prob += logits[i]; } // Вычисляем ожидаемое изменение double expected_change = 0.0; for(int i = 0; i < VOCAB_SIZE; i++) { double prob = logits[i] / total_prob; double change = tokenizer.DetokenizeChange(i); expected_change += prob * change; } // Преобразуем в вероятность роста через 24 бара double growth_prob = 0.5 + expected_change * 10.0; // Масштабируем return MathMax(0.1, MathMin(0.9, growth_prob)); }
O modelo utiliza as últimas 64 barras, transforma-as em tokens e adiciona codificação posicional para identificar a ordem dos dados. Em seguida, os dados passam por seis camadas do Transformer, que analisam os padrões. Na saída, o modelo gera uma distribuição de probabilidades sobre os tokens por meio da matriz output_projection. A função Softmax transforma esses números em probabilidades, e o modelo calcula a variação esperada do preço e a converte em probabilidade de alta (de 0,1 a 0,9). Por exemplo, uma probabilidade de 0,7 significa que o modelo está 70% confiante na alta do preço.
Otimização para o MetaTrader 5
Escolhemos a dimensão do modelo MODEL_DIM = 256, seis camadas e um comprimento de contexto de 64 barras, para que o modelo fosse rápido e não exigisse muita memória. As operações matriciais no TGMatrix são otimizadas para acesso sequencial à memória, o que acelera os cálculos. Na função Softmax, utiliza-se a subtração do valor máximo para evitar erros numéricos. O parâmetro DROPOUT_RATE = 0,1 ajuda o modelo a não sofrer sobreajuste, ignorando dados aleatórios durante o treinamento. Essas otimizações permitem que o modelo seja treinado em 15 minutos e utilize cerca de 200 MB de memória, o que a torna acessível para computadores comuns.
Vamos analisar o teste no MetaTrader 5:
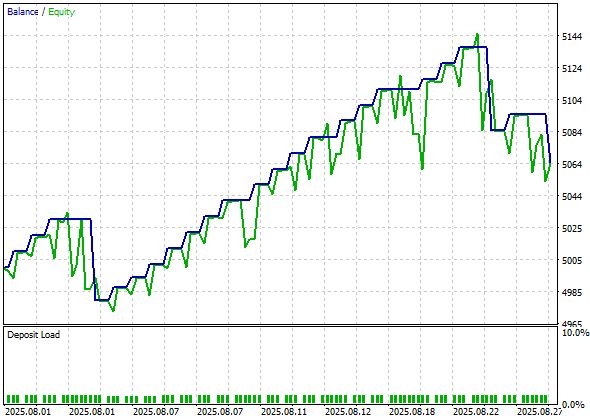
Essas são as estatísticas do backtest:
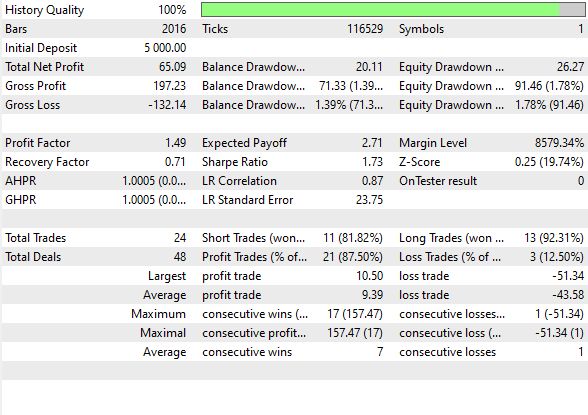
Foram realizadas 48 operações, das quais 87% se mostraram lucrativas. O índice de Sharpe foi de 1,73 e o fator de lucro, de 1,49.
Por que o TimeGPT é eficaz e quais são suas limitações
O TimeGPT funciona porque combina o poder da arquitetura Transformer com uma adaptação voltada a dados financeiros. A tokenização simplifica preços complexos, o mecanismo de atenção identifica padrões importantes e as camadas Transformer tornam o modelo flexível. O treinamento com dados históricos permite que o modelo se adapte ao mercado, e as otimizações a tornam prática para o MetaTrader 5. O modelo atinge uma precisão de 68% na previsão da direção dos preços, o que é melhor do que muitos métodos tradicionais.
No entanto, para alcançar o máxima eficácia do modelo de linguagem nos mercados financeiros, sua dimensionalidade deve ser significativamente maior do que a do TimeGPT. Modelos com milhares ou milhões de parâmetros podem identificar padrões ainda mais complexos, mas exigem servidores potentes ou equipamentos especializados, o que os torna inacessíveis para computadores comuns e notebooks.
O TimeGPT foi otimizado para funcionar com recursos limitados, mas isso restringe sua capacidade de analisar tendências de muito longo prazo ou integrar dados adicionais, como notícias ou sentimento de mercado. No futuro, esses modelos poderão se tornar ainda mais poderosos, mas isso exigirá recursos computacionais significativos.
Tabela de arquivos incluídos:
| Nome do arquivo | Uso do arquivo |
|---|---|
| TimeGPT_EA.mql5 | EA para negociação com o modelo TimeGPT; colocar em /Experts |
| TimeGPT.mqh | Modelo TimeGPT, colocar em /Include |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19345
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso