
Do básico ao intermediário: Acesso aleatório (I)

Introdução
No artigo anterior Do básico ao intermediário: FileSave e FileLoad, falamos e foi dada uma boa introdução e explicação sobre as funções de biblioteca FileLoad e FileSave. Que apesar de muitos as considerarem pouco promissoras devido a algumas dificuldades que as mesmas nos impõem para conseguir fazer certas coisas. São de fato bastante úteis quando o assunto é a geração de arquivos de log. Tais arquivos, para quem desconhece, são arquivos cujo propósito é o de permitir que saibamos como nosso código está de fato trabalhando em determinados cenários. Sendo uma ferramenta de extrema utilidade para todo e qualquer desenvolvedor.
Bem, mas apesar disto, as funções FileSave e FileLoad, são basicamente voltadas a uma implementação, onde o acesso as informações nos arquivos será do tipo sequencial. Isto devido a própria natureza de funcionamento de tais funções. No entanto, muitas das vezes, o que de fato é implementado por grande parte dos desenvolvedores, é um acesso aleatório no arquivo. Apesar do fato de que FileLoad e FileSave poderem fazer isto de maneira indireta. Carregando e salvando o arquivo completamente em memória.
Portanto, apesar de ser possível criar o que seria um acesso aleatório. Ele não estará de fato sendo efetuado da forma como geralmente acontece. Já que neste caso, o objetivo, é apenas carregar partes necessárias do arquivo. Isto em pequenos blocos. E este tipo de coisa, apesar de parecer não fazer muito sentido, em tempos onde a memória do computador é barata o suficiente para podemos manter grandes arquivos nela. Pode ser muito útil em diversos outros cenários. Onde o objetivo é retalhar o arquivo de uma determinada maneira.
Acesso aleatório a arquivos (Parte 1)
Se você observar a documentação de diversas linguagens de programação, visando verificar quais são os procedimentos e funções que esta ou aquela linguagem de programação estará implementando. Isto procurando estudar especificamente a parte relacionada ao trabalho com arquivos. Irá notar que muitas das vezes as linguagens de programação, promovem muito mais funções e procedimentos do que você realmente irá necessitar ou trabalhar. Algumas linguagens como C++, por exemplo tem uma quantidade muito pequena de funções e procedimentos. Isto visando trabalhar com arquivos.
Porém no caso do C++, temos uma promoção de métodos de entrada e saída que são estendidos para outros objetivos. Permitindo assim que tenhamos uma linguagem muito mais simbólica do que seria o natural. No futuro iremos tratar de coisas como estas aqui no MQL5. Mas por hora, vamos ficar no básico da coisa. Já que não faz sentido complicar as coisas antes da hora.
Então se você olhar na documentação do MQL5, irá notar que existem diversas funções e procedimentos voltados, tanto a leitura quanto a escrita de dados em arquivos. Sendo os métodos mais simples, o FileLoad e o FileSave. Que foram explicados e introduzidos no artigo anterior. Mas como foi dito, na introdução deste artigo, tais métodos não são voltados a um acesso aleatório do conteúdo de um arquivo. Justamente por conta disto, que diversos outros métodos aparecem na documentação do MQL5. Já que os mesmos tem como objetivo, promover justamente o acesso aleatório ao conteúdo presente em um arquivo qualquer.
Ok, isto explica parcialmente a presença de tantos métodos diferentes descritos na documentação. No entanto, isto não explica como trabalhar com os mesmos, e tão pouco explica como podemos lidar com tipos de dados implementados pelo programador. E sim meu caro leitor, você como programador não está limitado a trabalhar somente com os tipos definidos na linguagem de programação. As boas linguagens de programação, como é o caso do MQL5, nos permite criar tipos únicos e voltados para situações específicas. Talvez você não esteja entendendo do que estou falando, já que isto parece ser um tanto quanto inusitado.
Porém, nos artigos desta mesma sequência, quando falamos de template e typename, estávamos justamente fazendo isto. Criando tipos únicos e especialmente voltados a um determinado problema. Assim como também podermos utilizar uniões e estruturas de forma a criar um tipo específico, cujo propósito é o de gerar alguma abstração para dados especiais.
Certo, com isto, acabamos criando assim um tipo de restrição para simplificar o que será visto aqui. Já que como o objetivo é mostrar da forma o mais didática possível, como fazer certos tipos de coisas. Mostrar como cada uma daquelas funções e procedimentos vistos na documentação do MQL5, a fim de trabalhar com arquivos, passa a ser um tanto quanto desnecessário. Visto que podemos focar em um tipo modelagem, visando mostrar como cobrir uma ampla e vasta gama de possibilidades de implementação.
Assim, o material que será mostrado aqui, de forma alguma deverá ser pensado como sendo a única forma de se fazer as coisas. Dependendo do caso, fazer uso de uma função, ou procedimento da biblioteca padrão do MQL5, será de longe a melhor maneira de resolver certos tipos de problemas. Visto que o processo passa a ser mais direto, e não um tratado indireto cujo objetivo visa obter outro tipo de solução.
Dito tais coisas, vamos nos limitar a utilizar poucas funções e procedimentos. Porém isto não irá lhe impedir de poder experimentar outras funções ou procedimentos, a fim de entender o funcionamento de operações um tanto quanto mais especificas, presentes na biblioteca padrão do MQL5. Então meu caro leitor, procure ver e imaginar coisas além do que será mostrado aqui. Pois podemos obter os mesmos tipos de resultados, utilizando métodos ligeiramente diferentes. Porém que podem vir a ser mais simples de serem compreendidos por este ou aquele programador. Assim sendo, vamos começar com o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Código 01
Agora, quando executamos este código 01, iremos um certo arquivo sendo criado em uma certa SandBox. Acredito que você, meu caro leitor não deve ter dificuldades em entender que arquivo será este e onde ele será criado. Porém existe um certo detalhe com relação ao conteúdo presente neste arquivo. E esta é a parte interessante.
Observe o seguinte: Neste código 01, estamos dizendo para que um arquivo seja aberto para escrita, isto na linha oito. Caso tenhamos sucesso, teremos na variável um valor que pode ser utilizado para manipular o arquivo. Até aí tudo muito bonito e simples. Tanto que para dizer que as operações a serem efetuadas no arquivo terminaram, usamos a linha 18, cujo objetivo é fechar o arquivo. Permitindo assim que ele possa ser liberado para ser utilizado para outro proposito qualquer. Porém a parte que realmente nos interessa, se encontra entre as linhas 13 e 16. Pois ali, é onde estamos escrevendo no arquivo.
Antes de vermos como pode ser feita a leitura, vamos entender esta questão sobre a escrita. Pois isto é muito mais importante do que possa parecer, à primeira vista.
Claramente você pode observar e entender o que queremos escrever no arquivo. Já que todo o conteúdo é muito simples e fácil de ser compreendido. Porém, toda via e, entretanto, que tipo de coisa realmente está sendo escrita no arquivo? Bem, para responder isto, podemos olhar o conteúdo do arquivo, logo abaixo.

Imagem 01
Nesta imagem 01, podemos ver o resultado das operações de escrita no arquivo. Mas espere, este conteúdo parece um tanto quanto meio estranho. Então vamos olhar este mesmo arquivo visto na imagem 01, só que em formato binário. Isto é mostrado logo abaixo.
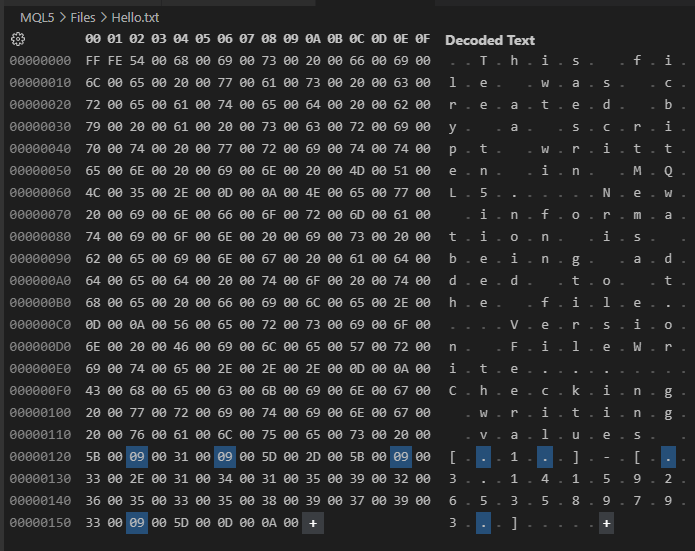
Imagem 02
Agora atenção meu caro leitor, o conteúdo visto nesta imagem 02, é exatamente o mesmo que é visto na imagem 01. Porém, aqui na imagem 02, estamos vendo cada um dos bytes que estão presentes no arquivo que foi escrito pelo código 01. Observe uma coisa interessante, nesta imagem 02, e que pode ser a diferença entre ler um valor correto e ler um valor completamente errado, quando estivermos fazendo a leitura de forma randomizada.
Apesar de não termos dito, absolutamente nada no começo do arquivo, e isto pode ser visto na imagem 01 e no código 01, no início do arquivo que pode ser visto na imagem 02 temos dois bytes estranhos que não fazem muito sentido. Estes bytes tem como objetivo indicar o tipo de formatação, não sendo de modo algum interessantes para nós. Já que no código 01, você claramente nota que eles não existem. Porém, existem outros caracteres aqui, que também não são apresentados, ou estão no código 01. Que são os caracteres de retorno de carro e de nova linha.
Mas nesta mesma imagem 02, existem alguns bytes em destaque. Porque? O motivo é que este estão sendo colocados como forma de tabular as informações da linha 16 do código 01. É muito, para não dizer extremamente importante, que você entenda a presença destes caracteres de tabulação. Pois dependendo do tipo de coisa que você esteja escrevendo. Mas principalmente do propósito para o qual o arquivo está sendo criado. Tais caracteres extras podem acabar destruindo completamente qualquer possibilidade de uma correta leitura do arquivo, posteriormente. Já que você pode não estar esperando a presença de tais caracteres, e eles acabam por destruir o sistema de indexação no momento da leitura dos dados.
Ok, entendi que nem sempre o que vemos sendo colocado no código de fato será representado, da mesma forma quando gravamos em um arquivo. Mas será que é sempre assim? Bem, isto depende meu caro leitor. Veja o seguinte, se mudarmos o código 01 para o que é visto no código logo abaixo, o resultado poderá ser muito diferente.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Código 02
Agora preste atenção, a única diferença entre o código 01 e este código 02, é justamente um valor extra que adicionamos a função FileOpen. E por conta deste simples fato, olhe o que acontece, quando o arquivo é criado pelo código 02. Isto pode ser observado comparando a imagem 03 vista logo abaixo, com a imagem 02.
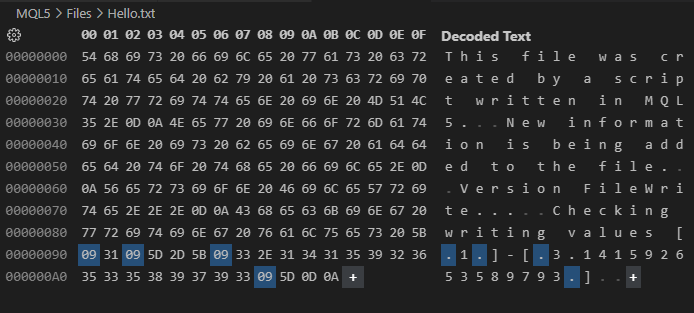
Imagem 03
Caramba. E eu achando que os resultados de pequenas mudanças no código, não faria tanta diferença assim. De fato, meu caro leitor, existem coisas que somente experimentando e vendo acontecer na prática é que você de fato irá conseguir compreender. Uma delas é justamente esta que você acabou de observar acontecendo na sua frente. Por isto que digo para você procurar praticar e estudar o conteúdo dos artigos, buscando tentar fazer as coisas de uma maneira um pouco diferente. Mas principalmente testando o que acontece quando mudamos certas coisas no código.
Mas continuando, note que este resultado visto na imagem 03, está bem mais próximo daquilo que seria de fato o conteúdo esperado ser encontrado no arquivo. Isto olhando o código 02. No entanto, ainda assim temos a questão dos caracteres de tabulação, retorno de carro e de nova linha que ainda insistem em continuar aparecendo. Por que? O motivo é que não estamos pedindo para que o arquivo seja escrito no modo binário.
Mas independente disto, vamos fazer uma pequena mudança no código. Isto a fim de fazer uma leitura de um determinado ponto do arquivo. Apenas para verificar um pequeno detalhe, que é importante que você entenda, antes mesmo de partimos para uma escrita binária do arquivo.
Pois sem saber por que escrever um arquivo de maneira binária ou não binária. Fica um tanto quanto confuso, saber fazer a escolha correta em diferentes momentos de uma implementação real.
Para que possamos visualizar o que desejo mostrar, precisamos criar um novo código. Este é mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 03
Este código 03, além de nos permitir escrever o arquivo, assim como era feito pelo código 02. Também nos permite ler o conteúdo do arquivo. Mas para que as coisas ocorram sem problemas e você entenda o que será visto logo mais. Precisamos primeiramente entender o que esperar como resultado da execução deste código 03.
Basicamente o arquivo que será escrito é o que podemos visualizar na imagem 03. E para garantir que de fato o arquivo irá conter alguma informação, dentro do que é esperado, usamos a linha 18 para fazer uma descarga do buffer para dentro do arquivo em disco. Esta operação vista na linha 18, pode em alguns momentos ser desnecessária. Já que dependendo de como o sistema operacional esteja mais ou menos carregado de operações de escrita ou leitura em disco. A escrita que é feita pelas linhas 13 até 16 podem estar ocorrendo em tempo real. No entanto, pode ser que em algum momento isto não ocorra. E como não quero fechar o arquivo para logo depois tornar a abrir o mesmo arquivo para ler os dados presentes nele. Usamos esta função de biblioteca da linha 18, para "forçar" um despejo imediato das informações para dentro do arquivo.
Ok, uma vez feito isto, temos uma certa garantia de que o arquivo de fato irá conter as informações que podem ser vistas na imagem 03. Agora vem a parte da leitura. Como o ponteiro do arquivo foi modificado e se encontra no final do mesmo, precisamos, reposicionar o ponteiro para algum outro ponto do arquivo. No caso iremos apontar para o início do mesmo. Para fazer isto, usamos a linha 20, onde estamos literalmente movendo o ponto de leitura e escrita para o começo do arquivo em disco. Preste atenção a isto, meu caro leitor. A leitura que estaremos fazendo, não será no conteúdo presente no buffer, mas sim no próprio arquivo.
Como o arquivo que estamos trabalhando se trata de um arquivo, cujo conteúdo sabiamente é composto de texto puro. Podemos utilizar o método de leitura vista na linha 21. Onde iremos ler o arquivo, até que seja indicado o fim do mesmo. Mas o que realmente nos interessa aqui é o que a linha 22 estará fazendo. Nesta linha estamos dizendo para que a aplicação, mostre no terminal do MetaTrader 5, o conteúdo lido do arquivo. Esta é a parte que realmente importa para nós aqui.
Agora preste atenção, no nosso caso, temos o que seria quatro linhas sendo escritas. Estas podem ser vistas na imagem 01. Então obviamente, quando esta linha 22 do código 03 for executada, iremos a princípio, ter um resultado sendo impresso no terminal como sendo algo parecido com o visto na imagem 01. Porém quando olhamos o terminal do MetaTrader 5, iremos nos deparar com algo parecido com a imagem 04 vista logo abaixo.
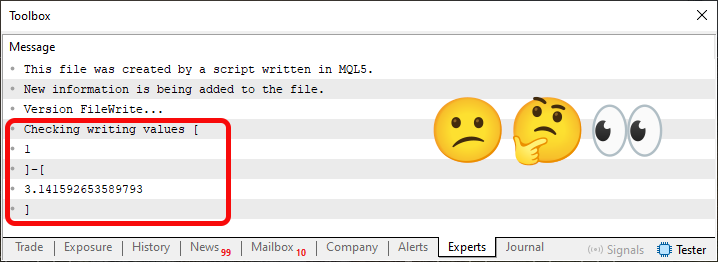
Imagem 04
Hum, estranho. Aparentemente as primeiras três linhas estão sendo mostradas de maneira correta. Porém esta região marcada em vermelho, está nos mostrando uma informação diferente da esperada. Muito estranho isto. Pois bem, meu caro leitor, apesar de aparentemente ser algo estranho, este tipo de resultado que está sendo mostrado. Ele a princípio, é algo muito bom para nós. No entanto, quero lembrar a todos, que aqui estamos fazendo as coisas da maneira o mais simples possível. Visando justamente a buscar um tipo de resposta para algo que todos, a princípio iriam fazer, mas que acabaria dando resultados diferentes do esperado.
Porém, aqui estamos tendo esta apresentação, um tanto quanto estranha, justamente por conta do caractere de tabulação. Mas espere um pouco. Como assim? Bem, meu caro leitor, como estamos fazendo a leitura do arquivo, como sendo um arquivo do tipo não binário. Esta função FileReadString, irá parar a leitura sempre que encontrar a combinação de retorno de carro com uma nova linha. Mas também quanto encontrar um caractere de tabulação. Basta ver a documentação para mais detalhes. Apesar de que a documentação, menciona o uso de arquivos CSV. O que não é a princípio o caso aqui, já que o conteúdo do arquivo, não é voltado a representar o que seria um formato do tipo CSV.
Ok, mais uma vez temos algo a ser aprendido aqui. Isto porque, dentro do que seria os flags de leitura do arquivo, o fato de não termos informado que tipo de informação deveria ser analisada pela operação de leitura da linha 22, faz com que tenhamos uma interpretação onde tabulações são consideradas durante a leitura. Assim, para resolver esta questão, precisamos mudar mais uma vez o código. Usando para isto o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 04
Note que mais uma vez, precisamos mexer em apenas e somente um único ponto do código. Sendo este a linha oito, que pode ser vista neste código 04. Porém, toda via e, entretanto, o resultado é muito diferente do que foi visto na imagem 04. Neste caso, quando o código 04 é executado, poderemos ver no terminal o que é mostrado logo abaixo.
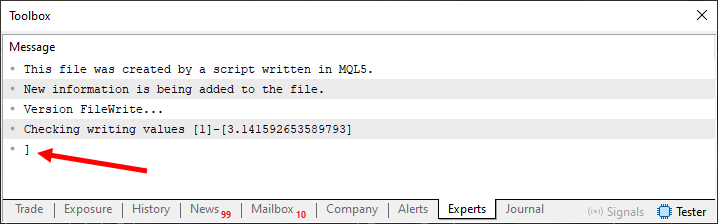
Imagem 05
Note que neste caso o conteúdo se parece e muito com o que seria previsto, ao observarmos a parte de escrita vista no código. Claro que tivemos um pequeno inconveniente que seria justamente este que é apontado pela seta na imagem 05. Mas isto é um problema de menor preocupação, já que o objetivo de certo modo, pode ser considerado como tendo sido alcançado. Que seria justamente ler o arquivo, de forma a ter algo muito parecido com o que seria o texto presente entre as linhas 13 e 16, do código 04.
Muito bem, agora que isto foi feito e mostrado, podemos começar a pensar na questão da leitura e escrita binária. Isto procurando ter um acesso randomizado do conteúdo do arquivo. Porém este tipo de conteúdo, no qual estamos escrevendo e lendo do arquivo. Por ser muito similar e parecido, com o que seria um texto do dia a dia, não é de fato adequado para demonstrar de forma clara e simples, como operações em binárias e randômicas se dão na prática. Para isto, e como uma forma de darmos o que seria o primeiro passo e ter uma primeira visão, inicial e básica, sobre o assunto. Precisamos mudar o conteúdo, para algo um pouco mais simples. Isto é feito utilizando o código que pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 0, SEEK_SET); 19. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 20. 21. FileClose(handle); 22. } 23. //+------------------------------------------------------------------+
Código 05
Ao executarmos este código 05 teremos a criação de um arquivo com valores que irão de zero a nove, como pode ser visto sendo feito na linha 14. Só que tem um pequeno detalhe, e este é extremamente importante que você o entenda muito bem, meu caro leitor. Observe que durante o processo de escrita, estamos dizendo para que o valor a ser escrito seja do tipo CHAR_VALUE. E entender isto é muito importante, pois por padrão, esta função irá escrever valores do tipo INT_VALUE. Mas espere, não sei por que entender isto seria importante para nós? Bem, para o grau de importância desta informação, é preciso relembrar, ou melhor, é preciso que você tenha entendido como trabalhar com uniões.
Nesta sequência, foram feitos, dois artigos básicos sobre uniões, sendo um deles pode ser visto em Do básico ao intermediário: União (I). Sendo que além deste conhecimento, você precisaria entender também sobre como trabalhar com arrays. Que também foi explicado em outros artigos nesta mesma sequência. Mas considerando que você tenha todo o conhecimento necessário, que foi explicado nos artigos anteriores. Podemos procurar entender porque ao executar este código 05, iremos obter o resultado visto na imagem logo abaixo.
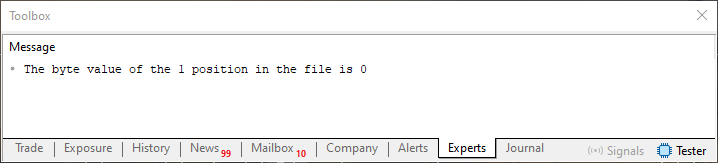
Imagem 06
Ok, quando a linha 19 do código 06 for executada, será mostrado algo parecido com o visto na imagem 06. Mas o que esta mensagem impressa no terminal quer nos dizer? Bem, você pode notar que nesta mensagem temos dois valores numéricos sendo impressos. O primeiro valor se refere a posição atual no arquivo. E o segundo valor se refere ao conteúdo daquela posição específica. Agora preste atenção meu caro leitor. Um arquivo, quando lido desta forma que estamos fazendo, deve ser pensado como sendo um array. Sendo é um array cujo index é incrementado automaticamente. Mas também podemos indicar qual o index dentro deste array. E isto é feito utilizando a linha 18.
Da mesma maneira que a contagem em um array se inicia no index zero. Quando vamos acessar dados em um arquivo, o index também se inicia em zero. No entanto, diferente do que acontecia caso indicássemos um index fora do array. Aqui quando estamos usando arquivos, o sistema irá sempre colocar o index dentro de uma posição válida. Experimente usar este código 05 para entender isto, mudando o valor zero que está sendo usado na função da linha 18, para outros valores. E veja o resultado. Isto irá lhe ajudar a entender como o acesso às informações são efetuadas.
No entanto, é preciso também entender uma outra questão aqui. Observe que FileReadInteger, também está usando CHAR_VALUE. Isto porque, queremos ler apenas e tão somente um único byte. Normalmente seria feita a leitura de quatro bytes, o que iria fazer com que o index, ou posição do arquivo, avançasse estes mesmos quatro bytes. Muita atenção a estes detalhes que estou mencionando. Justamente por conta disto, que entender uniões ajudará bastante a entender esta forma de acesso aos dados presentes em um arquivo.
Antes de passar para o próximo passo, procure experimentar bastante este código 05, até entender como ele de fato trabalha. Isto a ponto de que você de fato consiga entender que arquivos nada mais são que arrays que estão sendo armazenados em disco. Assim que você conseguir entender isto, e consolidar este conceito. Será bem mais simples entender o que iremos fazer logo a seguir.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 4, SEEK_SET); 19. FileWriteInteger(handle, 45, CHAR_VALUE); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 4, SEEK_SET); 24. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 25. 26. FileClose(handle); 27. } 28. //+------------------------------------------------------------------+
Código 06
Agora observe este código 06. Note que ele se parece bastante com o código 05. Porém aqui estamos fazendo algo um pouco além do que seria o código 05. Pois estamos escrevendo no arquivo de maneira completamente randomizada. E aqui é onde mora uma piada, um tanto sem graça, isto se você não conseguiu consolidar o conceito de array, com o conceito de arquivo. Isto porque, neste código 06 podemos fazer algo, que seria impossível de ser feito, caso estivéssemos de fato trabalhando com arrays. Pelo menos, da forma como grande parte dos arrays são trabalhados.
Antes de explicar este código 06, vamos ver o resultado da execução do mesmo. Este pode ser visto logo abaixo.
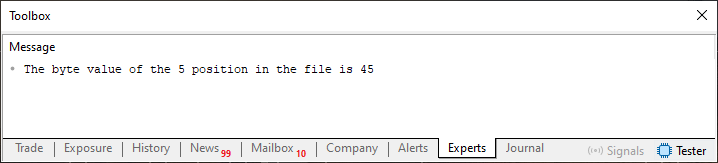
Imagem 07
Agora vem a parte divertida. Entender como esta mensagem da imagem 07 foi conseguida. Primeiramente note que as únicas mudanças neste código 06, frente ao que era o código 05, são as linhas 18 e 19. Estas duas linhas têm como objetivo mudar o valor de uma posição específica dentro do arquivo. Seria como se estivéssemos dizendo qual seria o novo valor, em uma dada posição, dentro de um array. Até aí muito simples de entender, já que a posição indicada está dentro do que seria criado pelo laço da linha 13.
Porém, você pode fazer a mesma coisa sem que necessariamente alguma posição anterior tenha sido criada. Ou melhor dizendo, você não está limitado a criar o que seria o array, antes de atribuir um valor a uma dada posição. Lembre-se de que aqui estamos lidando com arquivos. Neste caso, você poderia indicar uma posição muito além do limite superior do array, e ainda assim, as coisas iriam funcionar.
Talvez isto tenha ficado um tanto quanto confuso. Porém, é bem simples na prática. Mude o valor da função FileSeek da linha 18 para um valor além dos dez elementos criados pelo laço da linha 13. Como por exemplo 14. Mas não se esqueça de mudar também o valor da linha 23, para o mesmo valor usado na linha 18. Isto fará com que o código ao ser executado, gere o que é visto logo abaixo.
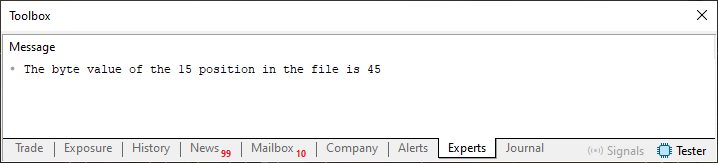
Imagem 08
Mas que coisa estranha. Sempre imaginei que o arquivo precisaria ser escrito byte a byte, posição após posição. Mas então, podemos escrever em qualquer lugar, não importando o tipo de coisa que exista antes? Isto sim é algo curioso. De fato meu caro leitor, este tipo de coisa é que torna o trabalho de programação algo tão memorável e divertido. Apesar de em alguns momentos ser algo um tanto quanto confuso para quem esteja começando a ver isto pela primeira vez.
Considerações finais
Neste artigo começamos a ter o que pode ser considerado a primeira experiência com arquivos de acesso randomizado. Claro que para dizer tal coisa, estou considerando que você, meu caro e estimado leitor, não fazia ideia de que existem tantos detalhes envolvidos a questão de se trabalhar com arquivos.
Como neste artigo, praticamente ficamos concentrados em implementar o que seria a primeira escrita em uma posição arbitrária dentro de um arquivo. Não foi possível explicar alguns detalhes relacionados a questão da indexação de informações dentro do arquivo. E como este tipo de coisa é de extrema importância, já temos algo a ser visto e tratado no próximo artigo. Então procure estudar e praticar o que foi mostrado aqui neste artigo, e para isto faça bom uso dos códigos fontes, presentes no anexo, e nos vemos no próximo artigo.
| Arquivo MQ5 | Descrição |
|---|---|
| Code 01 | Demonstração de acesso a arquivo |
| Code 02 | Demonstração de acesso a arquivo |
| Code 03 | Demonstração de acesso a arquivo |
| Code 04 | Demonstração de acesso a arquivo |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso