
取引アルゴリズムにおけるゲーム理論的アプローチの活用

意思決定の速度が極めて重要であり、市場が高い不確実性を持つ状況においては、従来とは異なるトレードシステムの設計アプローチが必要となります。
AdaptiveQ Enhancedは、ディープ強化学習(DQN)手法、ゲーム理論、および因果分析に基づいて開発されたEAです。本EAは、7つの主要通貨ペア間の相互関係を考慮しながら、531,441個のユニークな市場状態をモデル化して市場を分析します。アルゴリズムの中核にはナッシュ均衡があり、これは銘柄同士が相互に影響を及ぼす市場環境において最適戦略を選択するために使用されます。
本システムの新バージョンでは、拡張されたアクションセットが実装されています。従来の買いと売りの操作に加えて、ポジション構築および含み益のあるポジションの選択的決済機能が追加されています。これにより、さまざまな市場シナリオにおいて適応性と柔軟性が確保されます。本記事では、これらのアプローチのMQL5における実装方法を解説し、自己学習、ゲーム理論、AIの組み合わせによって、より高精度で安定したトレード戦略を構築できることを示します。
理論的基礎:強化学習からナッシュ均衡へ
深層強化学習(DQN)
技術的な詳細に入る前に、まず理論的基盤を整理します。本システムは深層強化学習(DQN, Deep Q-Network)に基づいています。これは強化学習アルゴリズムの現代的な拡張であり、ゲームAI分野だけでなく複雑な金融問題の解決においても有効性が実証されています。
古典的な強化学習では、エージェント(本ケースではトレードシステム)が環境(市場)と相互作用しながら特定の行動(ポジションの新規建てや決済)を実行します。各行動に対してエージェントは報酬を受け取り、新しい状態へ遷移します。エージェントの目的は、時間経過とともに累積報酬を最大化することです。
数学的には、これはQ関数として表現され、状態 s における行動 a の期待価値を評価します。
Q(s, a) = r + γ max Q(s', a')
ここで、rは即時報酬、γは割引率(将来の報酬をどの程度重視するか)、s'は新しい状態、a'はその新しい状態における可能な行動を表します。
ゲーム理論とナッシュ均衡
従来のトレードシステムでは、各銘柄は独立したものとして扱われます。本アプローチはこれとは本質的に異なり、ゲーム理論を適用することで通貨ペア間の相互関係を考慮します。
ナッシュ均衡とは、いずれのプレイヤーも自分の戦略を単独で変更しても利益を増やせないを指します。本システムにおいては、他のすべての銘柄の戦略を所与としたうえで、各銘柄にとって最適な戦略を導出することを意味します。
コード上では、この処理はDetermineActionNash()関数として実装されています。本関数は拡張された6つの行動空間に対応しており、各行動は特定の銘柄のデータのみならず、他の銘柄との相関関係も考慮して評価されます。
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Get basic estimates of actions from Q-matrix for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Correction based on correlation with other symbols (Nash) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Take correlation into account only if there is significant relationship if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
相関の扱いには細かなチューニングが施されており、絶対値が0.3を超える場合にのみ相関を考慮する設計となっています。これによりノイズとなる弱い関係を除外し、通貨ペア間の意味のある相関関係のみに焦点を当てることができます。
多次元行動空間における因果推論
AdaptiveQ Enhancedの更新版では、システムの行動空間が大幅に拡張されています。
- 買いエントリー
- 売りエントリー
- 既存の買いポジションへの買い増し
- 既存の売りポジションへの買い増し
- 含み益のあるロングポジションのみの決済
- 含み益のあるショートポジションのみの決済
これにより、システムの戦略的可能性は大幅に向上しています。現在のシステムでは、単純な新規ポジションのオープンや決済だけでなく、トレンドが有利方向へ進行した際のポジション増加、含み益のあるポジションのみの選択的利確、損失ポジションを維持したままのポジション管理といった柔軟な運用が可能です。
特に興味深いのは、「含み益のあるポジションのみを決済する」メカニズムです。この仕組みにより、システムは損失を確定させることなく利益のみを確保でき、全体的な収益性の改善につながります。
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Close only if position is in profit if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
技術実装:AdaptiveQ Enhancedの構造
巨大な状態空間と複数時間足分析
本システムの主要な特徴の一つは、531,441個に及ぶ巨大な状態空間です。これにより、市場状況を詳細に分析でき、幅広い市場シナリオへの適応が可能になります。
更新版では、各状態がさらに多くの情報を持つよう改良されています。現在のシステムは、単一時間足だけでなく、M15、H1、H4という3種類の時間足を同時に分析します。この複数時間足分析により、AdaptiveQ Enhancedは、短期的な価格変動と中期的なトレンドを含む、市場ダイナミクス全体を包括的に把握できます。
各時間足に対して、システムは以下のパラメータ群を監視しています。
- 20種類の移動平均線(MA10〜MA200)と価格との差分
- 価格が主要MA水準より上にあるか下にあるかを示すバイナリフラグ
- RSIおよびストキャスティクスの値
- 価格モメンタム
これらすべてのデータは、最終的に一意の状態インデックスへ変換され、その後Q行列へのアクセスに利用されます。
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Basic components from prices int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Basic index from main components int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Add components from difference with MA for current timeframe int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Add components from indicators for each timeframe ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Binary flags for MA: selecting key MAs (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Hash base index and indicators together ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Reduce to range TOTAL_STATES through hash return (int)(hash % TOTAL_STATES); }
この機能について詳しく見てみましょう。ここで特に重要なのは、多次元の市場パラメータ空間が、一意の状態識別子へ圧縮変換されている点です。まるで、価格、インジケーター、モメンタムなどの組み合わせに対応する多次元的な市場状態空間を構築し、それをハッシュ関数によって一次元インデックスへ圧縮しているかのようです。
キャッシュ機構と性能最適化
本システムは計算量が非常に大きいため、性能最適化にも特別な注意が払われています。更新版では、価格データや相関係数だけでなく、使用されるすべてのインジケーター値についてもキャッシュ機構が追加されています。
// Cache for prices and correlations (performance optimization) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Cache for Point // Cache for indicators double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];さらに、呼び出し間でインジケーターハンドルが保存されるようになったため、インジケーターハンドルの重複作成を回避できます。
// Indicator handles to avoid multiple creation int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];また、計算リソースを節約するために、指標を定期的に更新する仕組みが追加されました。
// Time of last update of indicators datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Update indicators every minute void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... indicator update code ... lastIndicatorsUpdate = currentTime; }
この技術自体は一見すると単純に見えるかもしれませんが、実運用では大幅な性能向上をもたらします。特に、7つの通貨ペアを3つの時間足上で同時運用するシステムにおいては、これは極めて重要です。
機会費用メカニズムを備えた適応学習
本システムの中核は適応学習エンジンです。 そして現在のAdaptiveQ Enhancedでは、この機構がさらに高度化されています。従来のQ学習とは異なり、AdaptiveQ Enhancedでは「機会費用(Opportunity Cost)」の概念が導入されており、これによりシステムは自身の誤った判断からより高速に学習できるようになっています。
システムが意思決定をおこなう際、選択した行動による実際の報酬だけでなく、他の行動を選択した場合に得られた可能性のある結果についても同時に評価します。そして、別の行動の方がより大きな利益をもたらした可能性があると判定された場合、システムは戦略更新をより強く実行します。// Check whether an action resulted in a loss and whether it was possible to make a reward with an alternative action bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Apply adaptive learning rate for cases of opportunity cost if(wasLoss && couldProfit) { // Increase learning rate to quickly adapt to incorrect decisions double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Additionally, reduce the Q-value in proportion to the opportunity cost newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
これは、熟練トレーダーが単に損失から学習するだけでなく、「別の選択をしていれば、より良い結果になっていた」という機会損失まで分析し、その結果に応じて戦略を積極的に修正するプロセスに近い考え方です。また、adaptiveMultiplierパラメータにより、ユーザーは「機会費用からどれほど強く学習するか」を調整できます。
学習機構におけるもう一つの革新的要素は、通貨ペア間の因果学習です。
// Update Q-values for other symbols based on correlation (causal learning) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Apply update only if correlation is significant if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
システムがある通貨ペアで獲得した学習結果は、相関関係の強さに応じて、他の関連通貨ペアへも転移されます。さらに、この更新は、相関係数が一定以上の場合にのみ適用されます。これにより、ある通貨ペアで得られた知識と市場構造に関する学習結果を他銘柄へ共有できるようになり、クロスラーニング効果が生まれます。
AdaptiveQ Enhancedの実用面
高度なカスタマイズ機能とリスク管理機能
AdaptiveQ Enhancedは、トレーダー個々の設定に応じてシステムを詳細にチューニングできる多数のパラメータを備えています。
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // System operating mode input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Close strategy input POSITION_MODE PositionMode = MODE_MULTI; // Position mode input double TradeVolume = 0.01; // Base volume of trade input double AddVolumePercent = 50.0; // Percentage of base volume to add to position input int TakeProfit = 2500; // Take Profit (points) input int StopLoss = 1500; // Stop Loss (points) input double LearningRate = 0.1; // Learning rate input double DiscountFactor = 0.9; // Discount factor input double AdaptiveMultiplier = 1.5; // Adaptive learning rate multiplier input double OpportunityCostWeight = 0.2; // Opportunity cost weight input int MaxPositionsPerSymbol = 5; // Maximum number of positions per symbol
システムは3種類のポジションモードをサポートしています。MODE_SINGLEは、各銘柄につき1つのポジションのみを保有できるモードです。MODE_MULTIは、MaxPositionsPerSymbolで指定された上限まで、同一方向の複数ポジションを保有できるモードです。MODE_OPPOSITEは、ロングとショートの両方向ポジションを同時に保有できるモードです。
AddVolumePercentパラメータは特に注意を払うべき項目です。ACTION_ADD_BUYおよびACTION_ADD_SELLが実行される際に、既存ポジションにどれだけの取引量(ボリューム)を追加するかを決定します。これにより、システムが有利に進行しているトレンドの方向に沿ってポジションサイズを増加させる、ポジション構築戦略の実装が可能になります。
インテリジェントなポジション管理
含み益のあるポジションのみを選択的に決済する機能は、AdaptiveQ Enhancedにおける最も興味深い革新の一つです。これによりシステムは、損失ポジションに回復の余地を与えながら、利益を確定することが可能になります。
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Close only profitable BUY positions ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
複数ポジション機能と組み合わせることで、この仕組みは興味深いダイナミクスを生み出します。すなわち、トレンドの進行に応じて徐々にポジションを構築し、反転の初期兆候で部分的に利益を確定しつつ、残りのポジションはさらなるトレンド継続の可能性に備えて保持するという挙動です。
学習済みモデルの定期保存と読み込み
本システムの重要な特徴は、学習済みQ行列を保存・読み込みできる点です。新バージョンではこの仕組みが強化され、新しいバーが形成されるたびに定期的な自動保存がおこなわれます。
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Periodic saving of Q-matrix..."); SaveQMatrix(); } }
これにより、システムは新しいバーの発生を検知するとQ行列を保存し、蓄積された学習結果を維持します。この仕組みにより、予期しない停止が発生した場合でも学習データの損失を防ぐことができます。
システム全体は次のように動作します。
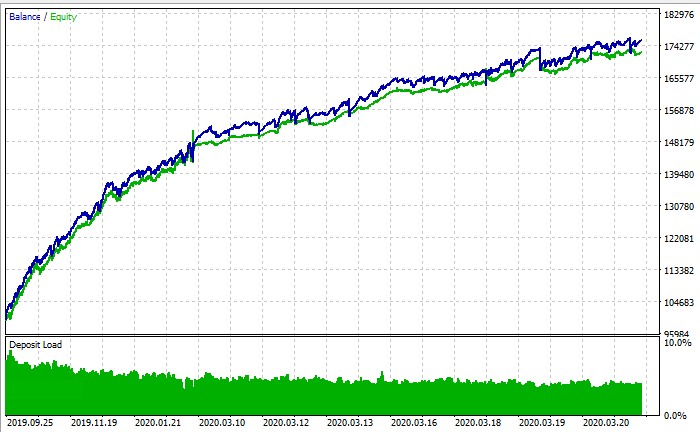
結論:アルゴリズム取引の新たな展望
AdaptiveQ EnhancedのEAは、単なるアルゴリズム取引ツールではなく、金融市場の分析と予測に対する根本的に新しいアプローチです。深層強化学習、ゲーム理論、因果推論を組み合わせ、拡張された取引アクション群と複数時間足分析を統合することで、異なる通貨ペア間の複雑な関係性を捉え、最適な取引判断をおこなうシステムを実現しています。
特に機会費用に基づく適応学習率のメカニズムは非常に効果的です。システムが誤った判断を下し、かつ別の行動が利益をもたらした可能性がある場合、AdaptiveMultiplier(デフォルト1.5倍)に応じて学習率を増加させます。これは一種の「高強度な学習」であり、システムは成功よりも失敗からより速く学習するよう設計されており、人間の認知プロセスとも類似しています。
アルゴリズム取引の未来は、市場とともに学習し進化する適応型システムにあります。AdaptiveQ Enhancedはその実験段階にとどまらず、人工知能とゲーム理論に基づくより高度な取引システム開発への実用的な一歩です。本記事で提供されているコードは、実験およびさらなる改良のために利用可能です。MQL5コミュニティに対して、このコンセプトの発展および人工知能とゲーム理論に基づく、さらに高度な取引システムの開発への参加を呼びかけます。
金融の世界はますます複雑化し、相互に強く結びついています。そして、この複雑性を認識し、それに適応できるシステムだけが、将来の市場において競争に勝つことができるようになります。AdaptiveQ Enhancedはその方向性を示す一歩であり、よりスマートで適応的、そして最終的にはより収益性の高いアルゴリズム取引へ向かうための一歩です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17546
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
はじめまして、あなたのプロジェクトにとても興味がありますが、私はこの分野では初心者です。戦略テスターで Expert Advisorを実行する方法がわかりません。私が理解しているように、テスターを通してそれを完全に設定し、訓練することは不可能なのでしょうか?それとも何か間違っているのでしょうか?OSを教えていただけるとありがたいです。
オランダの親戚はどこにいますか?
どうしてオランダに親戚がいるんだろう👀?
アハハハハ、オランダにはいないよ))))VPNなんてあるんだ))))
PS:ストラテジーテスターの一番下の行は、トレーニングを実行することが可能かどうか?バランスチャートのスクリーンショットを見る限り、ストラテジーテスターのようですが、何をやっても+にすらなりません。
著者は、DQN、ナッシュ均衡、因果分析、7つの主要通貨ペア、6つのアクション、531,441の 状態を組み合わせたと主張するマルチシンボルFX EA「AdaptiveQ Enhanced」を紹介する。アクション・セットには、買い、売り、買いの追加、売りの追加、利益の出る買いまたは売りのみの決済が含まれる。
私の主な問題点は、この記事は実質よりも派手なラベルを使って いることだ。その「ナッシュ均衡」は実際の均衡解ではない。あるシンボルのQスコアをとり、|corr|>0.3のときにローリング相関で重み付けした他のシンボルのQスコアでナッジしているだけである。これはゲーム理論ではない。同じ問題が「因果関係」の言語にも存在する。シンボル間の更新は文字通り、|corr| > 0.2 のとき、報酬×相関関係に基づいている。相関関係は因果関係ではない。
状態デザインも不安定に見える。記事によると、価格、MA差、RSI、ストキャスティクス、MAフラグから豊富なマルチタイムフレーム状態を構築し、その多次元情報をハッシュ化 し、ハッシュ% TOTAL_STATES で縮小する。そのため、異なる相場状況が同じバケツに収まる可能性がある。これを「531,441のユニークな状態」と呼ぶと、実際よりも印象的に聞こえる。
ポジションロジックは最も醜い部分です。EAはマルチポジションまたは反対ポジションモードで実行でき、既存のポジションに数量を追加 し、シンボルごとに最大5つのポジションを 許可し、"回復するために "負けたポジションを残したまま、利益の出るポジションだけを選択的に閉じることができる。それはスマートな在庫管理ではなく、醜いエクスポージャーへの着飾った道だ。
良い点:エンジニアリング面は、平均的なMQL5のフワフワしたものよりも真面目だ。インジケーター・ハンドルのキャッシュ、定期的な更新、Qマトリックスの保存と読み込みは、実用的な実装の詳細である。
私の意見では、興味深い実験であり、取引デザインとしては弱い。AI/ゲーム理論/因果推論」にまつわるブランディングが多すぎ、本当の優位性を証明するには不十分だ。私はこのロジックを直接構築することはしない。