
Exploramos modelos de regresión para inferencia causal y operaciones bursátiles
Introducción
A lo largo de varios artículos, hemos explorado diversos métodos para clasificar series temporales, pero no hemos abarcado los modelos de regresión. Los modelos de regresión, a diferencia de la clasificación binaria, nos permiten predecir no la probabilidad de que una observación pertenezca a una clase particular, sino valores continuos, lo cual amplía las posibilidades de su aplicación para la creación de sistemas de negociación automatizados.
La clasificación binaria es una tarea fundamental del aprendizaje automático cuyo objetivo consiste en clasificar los datos de entrada en una de dos categorías o clases diferentes. En el contexto de un bot de trading en Forex, esto generalmente significa predecir una señal de "compra" (representada como 0) o de "venta" (representada como 1). Este enfoque reduce la compleja dinámica del mercado a una decisión direccional simple.
La limitación inherente más significativa de la clasificación binaria para el trading cuantitativo reside en su incapacidad para cuantificar la magnitud o intensidad del movimiento de precios previsto. Un clasificador binario solo indica si el precio subirá o bajará, sin ofrecer ninguna información sobre cuánto se espera que cambie. La falta de este tipo de detalles limita fundamentalmente la complejidad de las decisiones de trading.
La precisión de las predicciones del clasificador por sí sola no considera la magnitud del cambio y, por lo tanto, no resulta muy útil para operar en los mercados financieros. Este aspecto es clave porque pone de relieve que una alta precisión direccional (por ejemplo, predecir la dirección correcta el 70% de las veces) no conduce automáticamente a operaciones rentables.
Debemos señalar que una alta precisión en la dirección no garantiza la rentabilidad. Por ejemplo, podemos acertar el 30% de las veces y obtener rentabilidad, o acertar el 70% de las veces y no obtenerla. Esto demuestra que el resultado neto de una estrategia de negociación está determinado por la cantidad de beneficios en las operaciones ganadoras en comparación con la cantidad de pérdidas en las operaciones perdedoras, y no simplemente por el porcentaje de victorias.
El modelo de clasificación binaria, al tratar todas las predicciones direccionales correctas por igual, independientemente del movimiento real del precio, no puede distinguir entre un movimiento pequeño e insignificante y uno grande y altamente rentable. Esto puede dar lugar a una situación en la que muchas pequeñas ganancias se vean contrarrestadas por unas pocas pérdidas importantes, o viceversa, lo que puede dar como resultado un PnL general negativo a pesar de una precisión aparentemente alta.
La falta de cuantificación del movimiento de precios implica que el bot de trading no puede priorizar las operaciones con mayores beneficios esperados ni evitar aquellas en las que la pérdida potencial supera sustancialmente los beneficios potenciales, incluso si la dirección se predice correctamente. Sin información sobre la magnitud, el bot opera con un punto ciego respecto al impacto financiero real de sus decisiones, lo que resulta en rendimientos acumulados subóptimos o incluso negativos a pesar de un alto porcentaje de victorias basadas en la dirección.
Modificación de la función de etiquetado
Vamos a analizar el siguiente escenario: disponemos de una serie temporal financiera que queremos predecir a partir de un conjunto de características. En el caso de la clasificación binaria, podemos determinar la dirección de una transacción futura (compra o venta), y estas etiquetas siempre son fijas. No podemos etiquetarlas de manera diferente para obtener una estimación más precisa de la magnitud de las futuras desviaciones de precios. Las operaciones son equivalentes independientemente de cuánto haya variado realmente el precio.
Ahora imaginemos que podemos predecir no solo la dirección de una operación comercial, sino también la magnitud del cambio futuro. Esto permitirá ajustar con mayor precisión el sistema de trading mediante la creación de filtros adicionales que ayudarán a identificar únicamente las fluctuaciones de precios previstas que sean significativas para negociar y a excluir las que no lo sean.
Para entrenar un modelo de regresión, debemos preparar las características y las variables objetivo para su entrenamiento. Las características pueden ser comunes al clasificador y al regresor, mientras que las características objetivo serán distintas.
Vamos a escribir una función sencilla que implemente el etiquetado de ejemplos para un modelo de regresión:
@njit def calculate_labels_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): rand = random.randint(min_val, max_val) labels.append(close_data[i + rand] - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values labels = calculate_labels_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
La principal diferencia con respecto al marcado de clasificación binaria es que ahora determinamos los cambios de precio (restamos el precio actual al precio futuro) en lugar de simplemente determinar la dirección (compra o venta). El código se acelera mediante Numba, por lo que el marcado de destino es muy rápido.
La función anterior solo considera la diferencia entre un precio futuro elegido al azar en el rango {min_val; max_val} y el precio actual. Esto puede no ser del todo correcto, ya que no se tienen en cuenta las desviaciones intermedias, que pueden ser sustanciales. Le propongo otra modificación de la función de cálculo de la desviación, que se presenta a continuación.
@njit def calculate_labels_mean_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): # Calculate the average price value in the window from min_val to max_val future_prices = close_data[i + min_val : i + max_val + 1] mean_future_price = np.mean(future_prices) # Calculate the difference between the average future value and the current price labels.append(mean_future_price - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values # Calculate buy/hold labels based on future price movements labels = calculate_labels_mean_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
Ahora la función considera todas las desviaciones en el intervalo dado, calculando el valor promedio. Después de esto, se calcula la diferencia entre el valor promedio de los precios futuros y el precio actual. En consecuencia, la función get_labels_r() ahora llama a la función de etiquetado calculate_labels_mean_r(), en lugar de calculate_labels_r() como antes. Podemos experimentar llamando a diferentes funciones de marcado.
Adición de un sistema de inferencia causal
Para obtener predicciones más precisas, vamos a utilizar un algoritmo similar al descrito en el artículo sobre inferencia de causa y efecto. La principal diferencia radica en que se usa un regresor, no un clasificador.
def meta_learners(data, models_number: int, iterations: int, depth: int): data = data.copy() data = data[(data.index < hyper_params['forward']) & (data.index > hyper_params['backward'])].copy() X = data[data.columns[1:-1]] y = data['labels'] data['meta_labels'] = 0 for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # fit debias model with train and validation subsets meta_m = CatBoostRegressor(iterations = iterations, depth = depth, verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict(X) data['meta_labels'] += abs(coreset['labels'] - coreset['labels_pred']) data['meta_labels'] = data['meta_labels'] / models_number return data
La función entrena múltiples regresores con subconjuntos aleatorios de datos del conjunto de datos de origen y luego compara los valores objetivo reales con los predichos. Por lo tanto, el metamodelo no pronosticará 0 o 1 (negociar o no negociar), sino los valores promedio de las desviaciones de los pronósticos con respecto a los reales. De esta forma podemos filtrar las previsiones que se desvían significativamente de los valores esperados.
Entrenamiento y prueba de modelos entrenados
Para probar modelos de regresión, el simulador ha sido modificado y tiene el sufijo "r". Es hora de entrenar algunos modelos. En este artículo, entrenaremos 10 modelos y seleccionaremos el que sea más de nuestro gusto.
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 100, 30)],
'backward': datetime(2010, 1, 1),
'forward': datetime(2024, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
data = get_labels_r(get_features(get_prices()), min=1, max=15)
dataset = meta_learners(data=data, models_number=5, iterations=15, depth=3)
models.append(fit_final_models(dataset, tol=3e-2)) Aquí debemos prestar atención al parámetro tol, que se transmite a la función de entrenamiento del modelo final. Como queremos que el modelo principal sea lo más robusto posible, no tiene sentido entrenarlo con todos los ejemplos. Solo lo entrenaremos con aquellos ejemplos cuyas predicciones se desvíen de las reales en menos del valor tol.
Dado que las desviaciones de las predicciones se cuentan en puntos, entonces tol=3e-2 significará una diferencia máxima de 0,03, es decir, 300 puntos de cuatro dígitos. Puede parecer un filtro demasiado grande, pero conviene tener en cuenta que se trata de una diferencia en valores absolutos, ya que las predicciones pueden ser tanto positivas como negativas. Podemos experimentar con este parámetro. A continuación se muestra la función en sí.
def fit_final_models(dataset, tol=1e-2) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels'] < tol] X, X_meta = X[X.columns[1:-2]], dataset[dataset.columns[1:-2]] # labels for model\meta models y = dataset[dataset['meta_labels'] < tol] y, y_meta = y[y.columns[-2]], dataset[dataset.columns[-1]] # fit main model with train and validation subsets model = RandomForestRegressor(n_estimators=50, max_depth=10) model.fit(X, y) # fit meta model with train and validation subsets meta_model = RandomForestRegressor(n_estimators=50, max_depth=10) meta_model.fit(X_meta, y_meta) data = get_features(get_prices()) R2 = test_model_r(data, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Ahora vamos a ordenar los modelos y llamar a la función de prueba personalizada:
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_r(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=True)
El modelo está sobreajustado y tiene un rendimiento deficiente con datos nuevos:
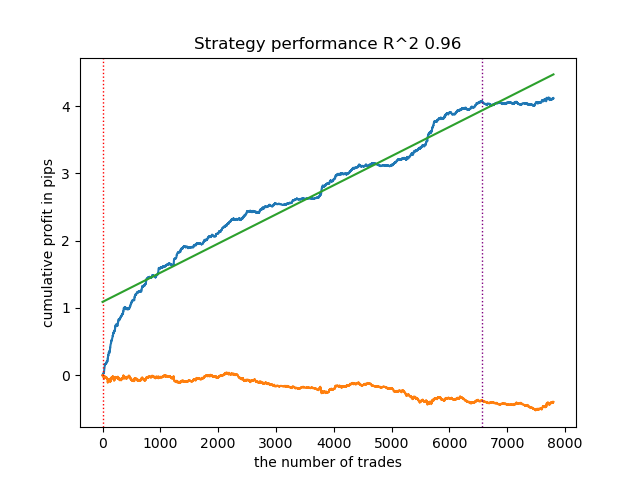
Figura 1. Prueba del modelo con etiquetado básico.
Realizaremos exactamente las mismas manipulaciones, pero tomaremos como base el etiquetador de operaciones calculate_labels_mean_r (), que calcula los precios futuros promedio.
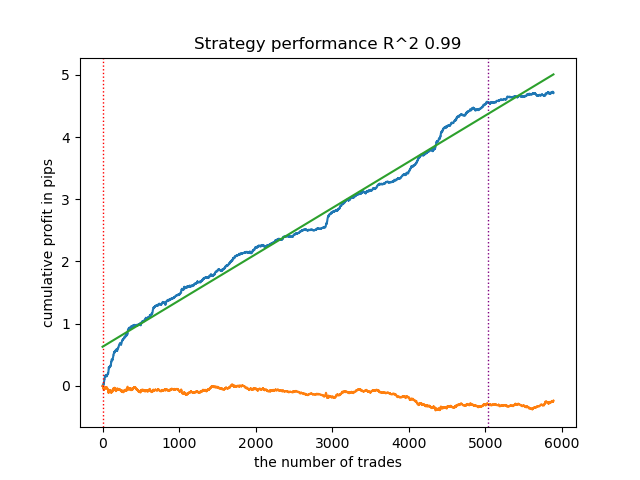
Figura 2. Prueba del modelo con etiquetas promediadas.
El segundo indicador comercial, en promedio, muestra resultados más estables con datos nuevos. Aparentemente, esto se debe a que se tiene en cuenta el valor promedio de los precios futuros.
El simulador personalizado no tiene la capacidad de definir umbrales para el modelo de regresión principal, por lo que simplemente divide las predicciones del modelo en positivas y negativas, lo que significa que las señales siguen siendo bastante imprecisas. Pero lo solucionaremos directamente en la terminal MetaTrader 5.
Exportación de modelos al terminal Meta Trader 5
Ahora necesitamos exportar los modelos al terminal en formato ONNX y configurar el sistema de negociación. La función de exportación resulta familiar:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Cabe señalar que no podemos conectar los modelos de regresión CatBoost en formato ONNX a la terminal, por lo que hemos usado el algoritmo de bosque aleatorio.
La dimensionalidad del tensor de entrada se ajusta automáticamente en función de los hiperparámetros (número de características) que se especifican antes de que comience el entrenamiento. A continuación, los modelos se convierten al formato ONNX usando la función convert_sklearn() y se guardan en el disco en el directorio que especificamos en los hiperparámetros.
def export_model_to_ONNX(**kwargs): model = kwargs.get('model') symbol = kwargs.get('symbol') periods = kwargs.get('periods') periods_meta = kwargs.get('periods_meta') model_number = kwargs.get('model_number') export_path = kwargs.get('export_path') initial_type = [('float_input', FloatTensorType([None, len(hyper_params['periods'])]))] onnx_model = convert_sklearn(model[1], initial_types=initial_type) # save main model to ONNX with open(export_path +'catmodel ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model.SerializeToString()) onnx_model_meta = convert_sklearn(model[2], initial_types=initial_type) # save meta model to ONNX with open(export_path +'catmodel_m ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model_meta.SerializeToString()) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel_' + symbol + '_' + str(model_number) + '[]' code += '\n' code += '#resource "catmodel_m '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel2_' + symbol + '_' + str(model_number) + '[]' code += '\n\n' code += 'int Periods' + symbol + '_' + str(model_number) + '[' + str(len(periods)) + \ '] = {' + ','.join(map(str, periods)) + '};' code += '\n' code += 'int Periods_m' + symbol + '_' + str(model_number) + '[' + str(len(periods_meta)) + \ '] = {' + ','.join(map(str, periods_meta)) + '};' code += '\n\n' # get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(symbol) + ' ONNX include' + ' ' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
Configuración de umbrales en el terminal MetaTrader 5
Ahora que tenemos dos modelos de regresión en lugar de dos clasificadores, podemos establecer umbrales numéricos específicos.
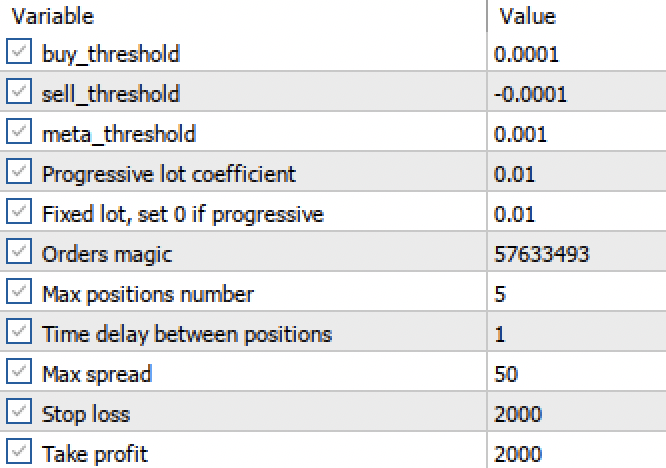
Figura 3. Establecimiento de umbrales de activación de señal en el terminal.
- Los umbrales buy_threshhold y sell_threshhold son los responsables de filtrar las señales del modelo de regresión principal. Si la señal está por debajo de este umbral, no se abrirá ninguna operación. Por ejemplo, si el cambio de precio previsto es inferior a 10 pips, abrir una operación de este tipo no tendrá mucho sentido, ya que no cubrirá el spread ni la comisión.
- El umbral meta_threshhold filtra las señales del modelo principal basándose en la inferencia causal descrita anteriormente. Este comprueba qué tanto podría diferir el pronóstico del cambio real futuro. Si la diferencia es demasiado grande, tampoco se abrirán las operaciones.
Ahora probaremos nuestro modelo en el simulador de MetaTrader 5 con los umbrales dados:
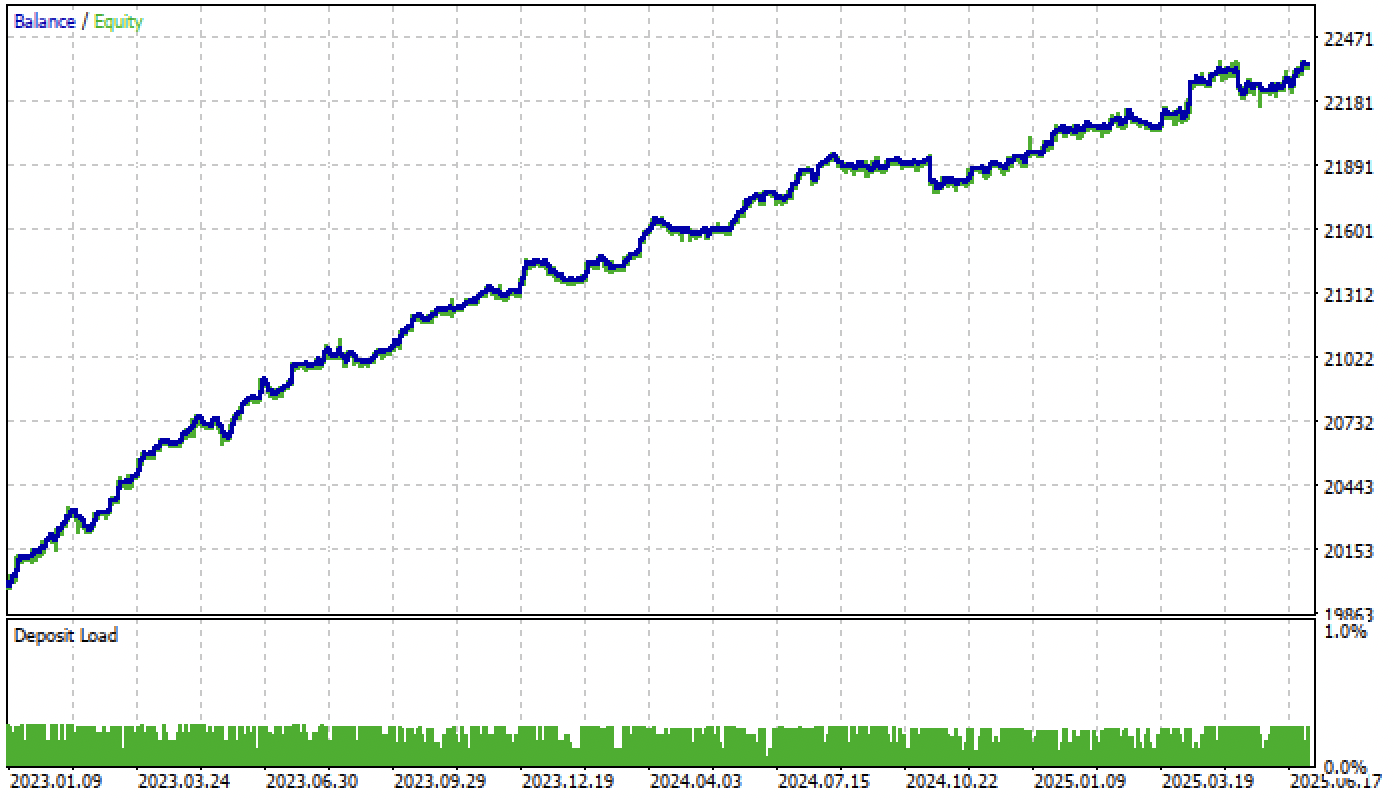
Figura 4. Prueba del modelo con umbrales dados.
Permítame recordarle que el periodo forward comienza a principios de 2024 y que el modelo actualmente lo está ejecutando de manera bastante estable. Esto pone de relieve la importancia de definir y establecer umbrales adecuadamente. Podrá optimizar los valores umbral por sí mismo.
La variedad de modelos puede ser amplia, dependiendo del tipo de características (en este artículo, ambos modelos se entrenan con desviaciones estándar) y de los parámetros de los propios modelos. Por ejemplo, hemos entrenado otro modelo con parámetros diferentes, que funciona bien con datos nuevos incluso sin ajustar los umbrales.
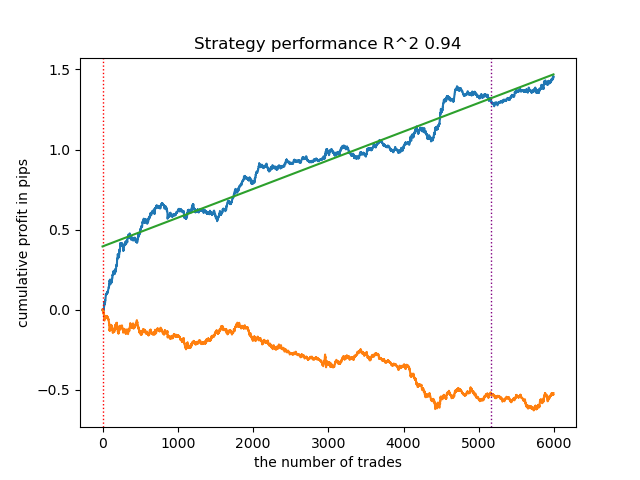
Figura 5. Entrenamiento y prueba de otro modelo con diferentes parámetros de entrenamiento.
Y tras ajustar los umbrales, el modelo ha mostrado un crecimiento constante desde principios de 2024.
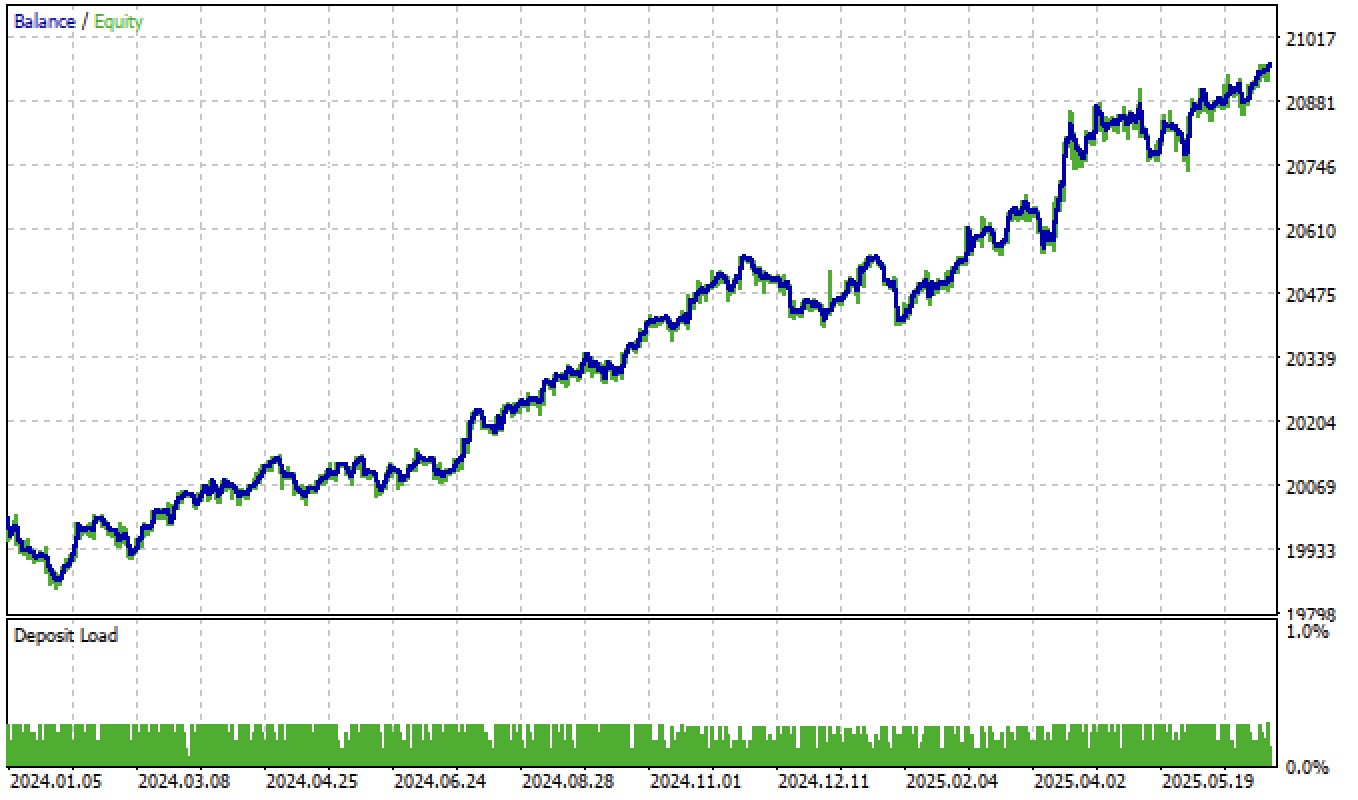
Figura 6. Prueba del modelo en el terminal después de configurar los umbrales.
La prueba de los modelos basados en un segundo etiquetador de operaciones y el filtrado por umbrales produce resultados aún más interesantes y precisos:
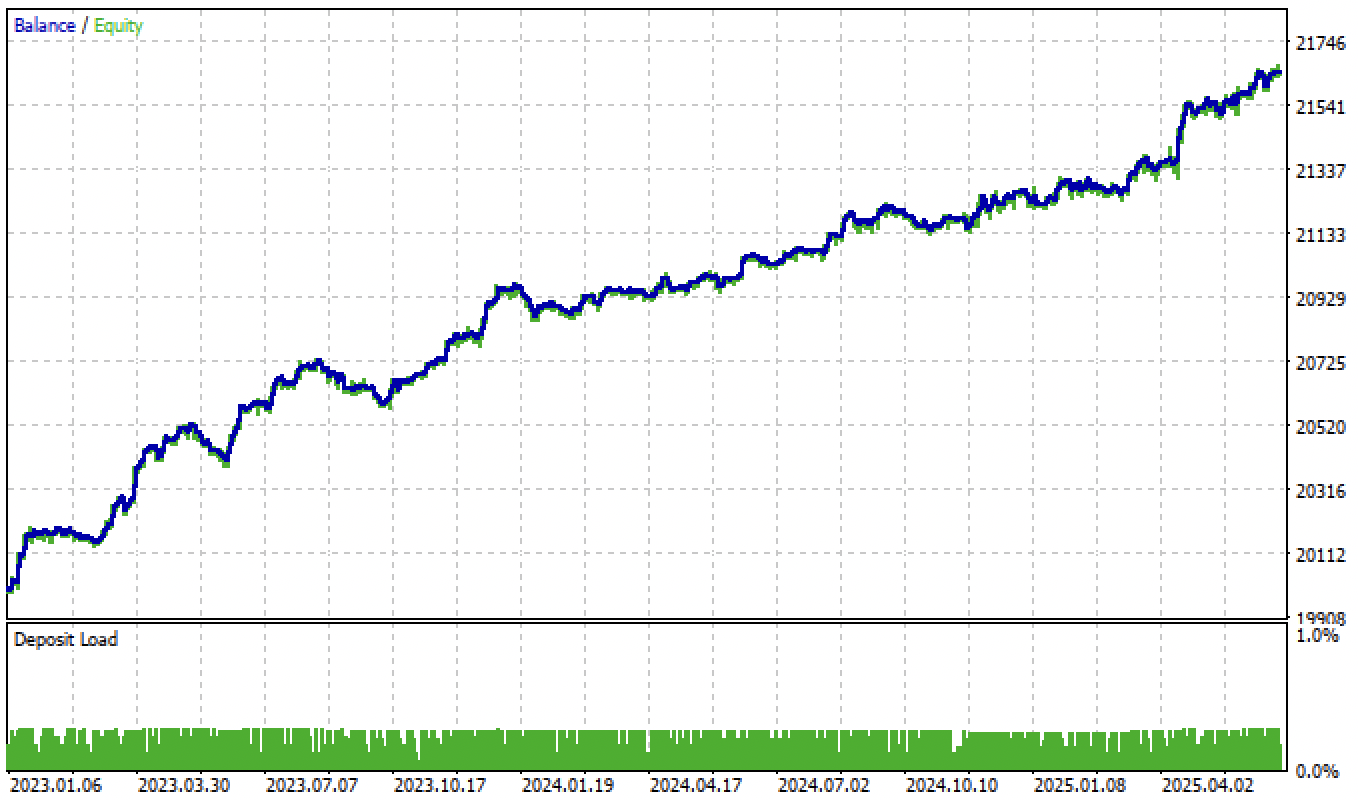
Figura 7. Prueba del modelo basada en el etiquetador de operación promedio y tol = 1e-2
Si cambiamos el parámetro tol durante el entrenamiento de 1e-2 a 1e-3, los resultados serán aún mejores:
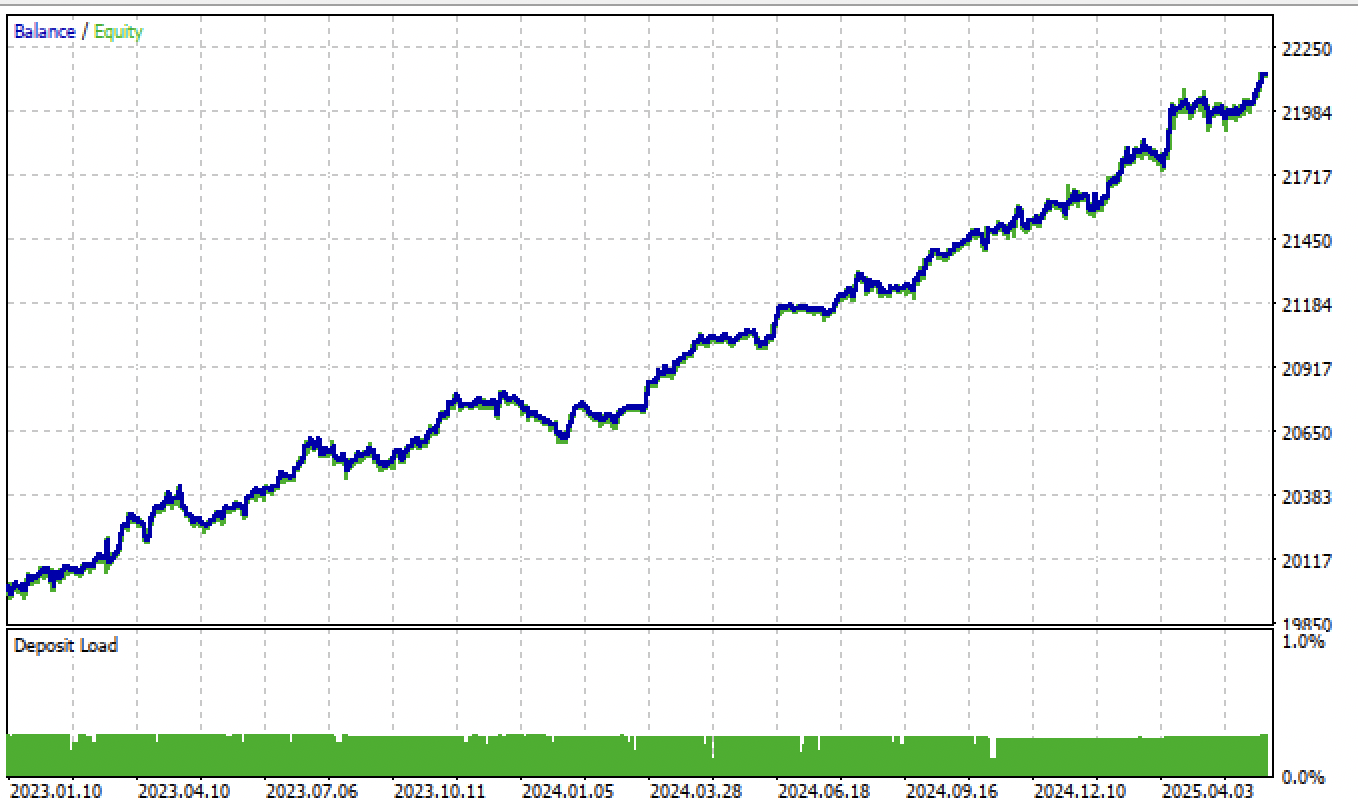
Figura 8. Prueba del modelo basada en el etiquetador de operación promedio y tol = 1e-3
Información adicional
Para exportar modelos, necesitaremos instalar e importar el paquete skl2onnx:
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
El código de inicio del modelo ONNX en el código del bot de trading también se ha modificado para que gestione correctamente los nuevos modelos de regresión:
vectorf y_main(1), y_meta(1); OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, y_main); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f_m, y_meta); float sig = y_main[0]; float meta_sig = y_meta[0];
Hemos añadido nuevas variables "input" para ajustar y optimizar los umbrales:
input double buy_threshold = 0.00001; input double sell_threshold = -0.00001; input double meta_threshold = 0.001;
Ahora se accede a los nombres de los modelos ONNX mediante directivas #define, lo cual facilita la inclusión de modelos con nombres diferentes:
#define model ExtModel_EURUSD_H1_0 #define model_m ExtModel2_EURUSD_H1_0 #define periods PeriodsEURUSD_H1_0 #define periods_m Periods_mEURUSD_H1_0 #define fill_arrays fill_araysEURUSD_H1_0 #define fill_arrays_m fill_arays_mEURUSD_H1_0
Las señales de trading se generan cuando se cumplen ciertas condiciones en función de los umbrales establecidos:
if((Ask-Bid < max_spread*_Point) && MathAbs(meta_sig) < meta_threshold && AllowTrade(OrderMagic)) if(countOrders(OrderMagic) < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(), ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig > buy_threshold && Allow_Buy) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_BUY, l, Ask, stop, take, bot_comment); Sleep(50); } while(res == -1); } else { if(sig < sell_threshold && Allow_Sell) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_SELL, l, Bid, stop, take, bot_comment); Sleep(50); } while(res == -1); } } }
También hemos añadido la herramienta de prueba de estrategias modificada y la función de exportación de modelos a los módulos correspondientes y las hemos adjuntado al artículo.
Conclusión
En este artículo, hemos descrito una posible (aunque no la única) manera de construir sistemas de negociación basados en modelos de regresión. Este enfoque permite un ajuste más preciso de los bots basados en aprendizaje automático. También permite convertir modelos claramente no rentables en rentables mediante el establecimiento de umbrales. Podemos utilizar cualquier indicador y/o etiquetador de posición, y también probar este algoritmo en otros instrumentos de negociación y otros marcos temporales.
El archivo Python files.zip contiene los siguientes archivos para desarrollar en el entorno Python:
| Nombre del archivo | Descripción |
|---|---|
| causal regression.py | Script básico para el entrenamiento de modelos |
| labeling_lib.py | Módulo actualizado con etiquetadores de operaciones |
| tester_lib.py | Simulador personalizado actualizado para estrategias basadas en aprendizaje automático |
| export_lib.py | Módulo de exportación de modelos al terminal |
| EURUSD_H1.csv | Archivo con las cotizaciones exportadas desde el terminal MetaTrader 5 |
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5:
| Nombre del archivo | Descripción |
|---|---|
| regression trader.ex5 | Bot compilado de este artículo |
| regression trader.mq5 | Bot fuente del artículo |
| carpeta Include//Trend following | Asimismo, encontrará los modelos ONNX y el archivo de encabezado para conectarse al bot |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18603
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Utilizo causal_regression_orig.py para producir el archivo de cabecera de ea, luego compilo ea.
El resultado es test_result pic in below.
Hay tan menos oficios que el que ha publicado.
Entonces, ¿cuál es la diferencia entre estos.
¿Hay muchas operaciones en python tester? Si es así, es necesario volver a configurar los umbrales para la apertura de operaciones en el programa mql5, tal vez son demasiado grandes.
Este es el resultado de python tester, uso el mismo código que adjuntaste en este post. He comprobado en mt5 tester config panel, el buy_threshold y sell_threshold son ambos 0.0001 y -0.0001, igual que la configuración en este post.
He comprobado el código, y no sabía lo que es la diferencia entre esto.
Este es el resultado python tester, yo uso el mismo código que adjunta en este post. He comprobado en mt5 tester config panel, el buy_threshold y sell_threshold son 0.0001 y -0.0001, igual que la configuración en este post.
He comprobado el código, y no sabía lo que es la diferencia entre esto.
Saludos Maxim, muchas gracias por compartir con nosotros.
Pregunta. Después de calcular ONNX para un nuevo ticker y colocarlo en la carpeta Trend Following, ¿cómo puedo asegurarme de que el EA comience a utilizar los datos entrenados para el nuevo ticker? Para otros tickers, incluso si borro ONNX_EURUSD y coloco otro, el EA se comporta de forma idéntica. ¿Tengo que cambiar algo en el MQL5 Expert Advisor al cambiar el ticker?
Saludos Maxim, muchas gracias por compartir con nosotros.
Pregunta. Después de calcular ONNX para un nuevo ticker y colocarlo en la carpeta Trend Following, ¿cómo puedo asegurarme de que el EA comience a utilizar los datos entrenados para el nuevo ticker? Para otros tickers, incluso si borro ONNX_EURUSD y coloco otro, el EA se comporta de forma idéntica. ¿Tengo que cambiar algo en el MQL5 Expert Advisor al cambiar el ticker?
Hola, necesitas conectar el archivo .mqh con el nuevo ticker en el código del EA.
Es decir, cambiar el seleccionado a otro archivo con un nombre diferente, que fue generado por el script python.