
从基础到中级:模板和类型名称(三)

概述
此处提供的材料仅用于教育目的。它不应以任何方式被视为最终应用程序。其目的不是探索所提出的概念。
在上一篇文章:“从基础到中级:模板和类型名称(二) ”中,我们讲解了程序员如何处理一些特定的日常情况。无论是你的临时爱好还是你是一名专业程序员,在某些时候使用函数和过程模板都是非常有用的。尽管这在 MQL5 中并不常见,也并不总是适用,但知道这样的概念可用于应用程序,并且它有自己的要点是有用的,人们应该正确理解,这样在试图修改最终使用这种模拟的代码时就不会感到困惑。
模板不仅适用于函数和过程。事实上,它们有广泛的实际应用,这或多或少取决于你想要开发的应用程序的类型。值得一提的是 —— 再次强调 —— 我们可以不使用模板来实现相同类型的应用程序。然而,使用 MQL5 的这种工具和资源可以使实现阶段更容易、更愉快。此外,它还有助于避免某些类型的复杂和恼人的检测失败。
局部变量中的模式
在前两篇文章中,我们只讨论了函数或过程中的模板,一切都很简单,甚至很有趣。但由于这些解释,很明显,在函数或过程重载的情况下,函数或过程模板是将工作委托给编译器的好方法。然而,所提供的示例非常简单,因为所使用的数据类型仅与函数或过程的输入参数相关。虽然一个人可以提升到更高的知识水平。
为了理解这一点,让我们从一个简单的例子开始:计算平均值。是的,即使这是一件简单的事情,我们也可以看到如何在类似的情况下应用模板。但我想提醒您,这里提供的代码仅用于教育目的。它们不一定代表将在现实世界中使用的代码。
因为我认为您已经了解函数或过程重载的工作原理,所以我们可以通过从代码中删除所有不必要的内容,只关注真正值得关注的部分。这样,我们就有了下面呈现的第一手代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. double Averange(const double &arg[]) 16. { 17. double local = 0; 18. 19. for (uint c = 0; c < arg.Size(); c++) 20. local += arg[c]; 21. 22. return local / arg.Size(); 23. } 24. //+------------------------------------------------------------------+ 25. long Averange(const long &arg[]) 26. { 27. long local = 0; 28. 29. for (uint c = 0; c < arg.Size(); c++) 30. local += arg[c]; 31. 32. return local / arg.Size(); 33. } 34. //+------------------------------------------------------------------+
代码 01
我们面前有一个简单的代码,其目的是计算数据集的平均值。对于那些不理解的人来说,平均计算是将所有值加起来,然后将给定总和的结果除以计算中存在的元素数量。虽然这种计算很简单,但有一个小问题:值可以是正的,也可以是负的。我们可能会得到一个扭曲的平均值,它不能反映我们真正想知道的东西。但这是一件微不足道的事情,在这里并不重要。我们提到这一点只是为了让你知道,即使代码是由其他人创建的,它也并不总是能为我们提供所需的信息。此外,另一位程序员创建了某段代码,这使得代码对该程序员正在搜索的内容做出响应,而不是对我们可能正在搜索的东西做出响应。
但是,我认为没有必要解释代码 01 如何运行,因为它使用重载来以最合适的方式执行分解。您可以在下图中看到此操作的结果。
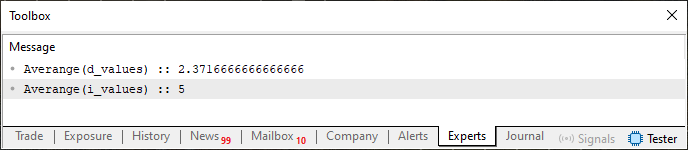
图 01
换句话说,这是一件琐碎而简单的事情。但我希望您仔细看看第 15 行和第 25 行中实现的函数。它们有什么共同点?我们可以说,除了一个具体细节外,它们几乎完全相同。这部分与所使用的数据类型有关。在其他方面,它们是相同的,没有明显的差异。事实上,如果你注意到了这一点,这意味着你正在考虑一些事情:我们可以将代码 01 中显示的这两个函数转换为模板。这将简化任务。“然而,我对此表示怀疑。两个函数都有一个局部变量,可以在第 17 行和第 27 行看到。我知道如何将函数调用声明和实现为模板,因为我在前面的文章中看到过这样做。然而,这个局部变量让我很困扰,我不知道如何处理它。也许,我可以做一些类似于下面的代码的事情。”
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. double local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return (T)(local / arg.Size()); 24. } 25. //+------------------------------------------------------------------+
代码 02
事实上,你可以做代码 02 中所示的操作。但是,在尝试编译此代码时,您将从编译器收到此警告:
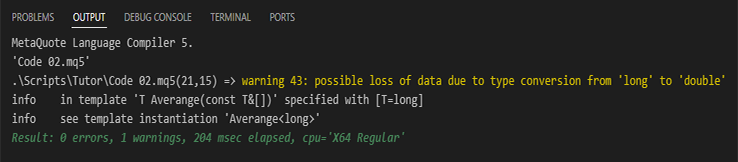
图 02
请注意,这不是错误消息,而是一个警告。这是因为在第 21 行,我们对数组值求和时,会有一个时刻,我们将浮点值与整数值相加。这可能会导致最终结果的失真。然而,当我们执行代码(02)时,最终结果将与图 01 中的结果相同。然而,这个编译器警告可能会让一些程序员有点不安。我该如何解决这个问题?为了解决这个问题,我们需要执行类型转换,就像我们在第 23 行中所做的那样,只有第 21 行中的转换才会应用。但要小心:您不应该使用下面显示的内容。
local += (T)arg[c];
这将无法解决警告的问题,因为我们需要执行转换,使数组中的值与第 18 行中的变量值兼容。虽然看起来很复杂,但实际上非常简单明了。我们需要做的就是将代码 02 的第 21 行更改为您在下面看到的行。
local += (double)arg[c]; 现在我们的问题已经解决了。我们有一个作为模板实现的 Average 函数,并且它运行良好。然而,还有另一种方法可以解决这些问题,这样就不会对代码进行太多更改。让我们回到代码 01。请注意,代码 02 代表代码 01 中实现的内容。如果问题是由局部变量引起的,如上所示,为什么不做一些更复杂的事情呢?因此,编译器将自行处理此类问题。这听起来很大胆,不是吗?
但是,如果你真的了解代码 01 是如何转换为代码 02 的,以及我们如何处理编译器发出的警告,你应该考虑另一种解决方案。其中一种解决方案允许您更改代码 02 第 18 行中声明的变量的类型。这将是一个非常有趣的解决方案,这正是我们在实施过程中看到的。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. T local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return local / arg.Size(); 24. } 25. //+------------------------------------------------------------------+
代码 03
代码 03 产生与图 01 相同的结果,并且不会从编译器发出任何警告。为什么这样?因为当编译器注意到我们想要一个整数类型时,它会调整变量的类型以匹配整数类型。如果编译器注意到我们需要一个浮点类型,它将使第 18 行中声明的变量成为与浮点一起使用的适当类型。
因此,我们将得到一个比代码 01 简单得多的代码,尽管它与代码 02 非常相似,但不需要进行所有各种调整。这可确保发生类型转换,并且不会发出编译器警告。这很棒,不是吗?我认为,如果你已经看过类似于这个的代码,你可能已经想象过它是如何工作的。但是,如果你理解了基本概念,并看到了一切是如何结合在一起的,那么之前看起来很复杂的代码就会变得更简单、更有趣。
好吧,那是最愉快的部分。现在我们将看到一个非常有趣的部分。鉴于代码 03 中给出的用例,我现在想尝试其他数据类型。
由于目前我们只显示了联合使用的数据类型,我们可以尝试使用代码 03 中显示的相同技术来创建更大的模板。但是,为了正确划分任务,我们将在另一个主题中讨论这个问题。
在联合中使用元素
首先,我们将以更简单的形式查看代码 03 中显示的内容,至少在开始时是这样。实际上,我们不会再次更改代码 03,但我们将使用这个概念在联合体内创建一个动态内存区域。换句话说,我们将创建一个模板,用于在数组和任何数据类型之间创建联合。
当我们研究如何定义联合时,我们发现它由一个固定大小的块组成。此块以字节为单位定义,其值为属于联合中存在的最大类型的字节数。我们可以使它不是绝对真理,也就是说,我们可以通过编译器动态配置这个联合,这将允许我们创建一个主要具有动态块大小的联合,因为字节宽度将在编译代码时确定。从那一刻起,它将有一个固定的大小。
现在你可能会想,“对我来说,这似乎是一项非常艰巨的任务。乍一看,我不知道我们将如何告诉编译器如何使用这种方法或实现。我们现在需要这个吗?”好吧,从某种意义上说,有些人可能会认为这个概念很先进,但在我看来,它仍然是每个初学者都应该知道的基本概念,因为它极大地促进了为更广泛的目的创建各种类型的代码。
我知道很多人可能会认为我们行动太快了。然而,我们会尽可能放慢速度,不遗漏任何概念或解释。如果这个知识库结构良好,易于理解,那么接下来的一切都会变得更加自然,更容易理解。虽然,由于我知道未来的材料一开始可能会有点令人困惑,我们将从更简单的代码开始。这将使学习新概念变得更加愉快和容易。以这种方式思考,让我们从下面的代码开始。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ulong info = 0xA1B2C3D4E5F6789A; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. ulong Swap(ulong arg) 13. { 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }info; 19. 20. info.value = arg; 21. 22. PrintFormat("The region is composed of %d bytes", sizeof(info)); 23. 24. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 25. { 26. tmp = info.u8_bits[i]; 27. info.u8_bits[i] = info.u8_bits[j]; 28. info.u8_bits[j] = tmp; 29. } 30. 31. return info.value; 32. } 33. //+------------------------------------------------------------------+
代码 04
此代码尚未使用模板资源。由于我们在介绍联合主题时已经在另一篇文章中对此进行了解释,我认为没有必要再次解释它是如何工作的。然而,在引入代码 04 时,我们对扩展它不感兴趣。因此,第 12 行的函数实际上并不存在。一切都是 OnStart 的一部分。但现在,由于我们将讨论联合中的模板,因此将所有内容分离到一个单独的块中是合适的。这将有助于与联合模板进行初步接触。然后我们将看到,可以像最初那样将所有内容放在一个代码块中。
编译并运行代码 04 后,您将在 MetaTrader 5 终端中看到响应。
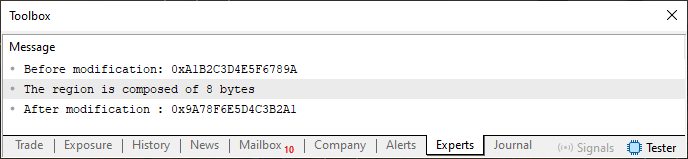
图 03
换句话说,我们移动了位。一切都很简单。我们如何改变其他数据类型中的位?因为如果我们有一个像 ushort 这样的类型,它有 2 个字节,我们把这个类型发送到第 12 行的函数,我们会得到一个错误的结果,或者至少是一些相当奇怪的结果。为了验证这一点,只需将代码 04 中的第 06 行更改为下面显示的行。
const ushort info = 0xCADA;
现在,当我们用上面显示的这一行运行代码 04 时,结果将是我们在 MetaTrader 5 终端屏幕上看到的。
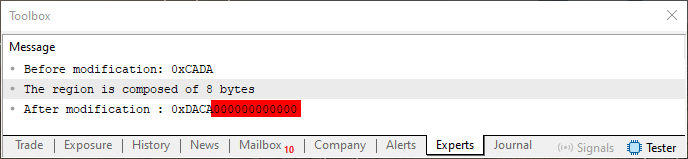
图 04
请注意图 04 中的一件事:我用红色突出显示的区域。这是添加到 ushort 类型值中的不必要数据。即使你注意到轮转确实发生了,这些字节也是一个问题。特别是如果我们需要保存 ushort 类型。在这种情况下,模板就可以发挥作用了。
如前一主题所示,使用各种类型的值非常简单、实用和安全。这使我们能够计算平均值。事实上,我们的应用程序可以毫无问题地处理整数值和浮点值。但是,我们如何在这里做同样的事情,在这里我们使用并需要一个联合来简化代码?嗯,这是最有趣的部分。
首先,我们需要将代码 04 转换为模板友好的代码。根据目前所展示的内容判断,这很容易做到,特别是如果你真的理解了所概述的概念。然后,没有任何问题,我们创建如下所示的代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. ulong value; 18. uchar u8_bits[sizeof(ulong)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
代码 05
但是,当尝试编译代码 05 时,编译器会发出警告。此警告如下图所示。

图 05
现在跟我一起思考一下。您会看到此警告,指出第 32 行中的值与返回值不兼容,因为它们属于不同的类型。您以前在哪里见过这个?如果您在同一篇文章中稍微回顾一下,您会在图 02 中看到类似的内容。基于此,您已经有了解决这个问题的方法。你可以选择任何一种方式。但是,正如您在前一个主题中应该注意到的那样,迫使我们对代码进行更少更改的最佳方法是将错误类型的变量转换为预期类型作为返回。换句话说,您不必更改第 32 行,而是更改第 15 行,其中声明了值的联合。
猜猜我为什么不说我们应该修改第 17 行?毕竟,这就是变量所在的位置,它在第 32 行中用于返回值。原因是我们不打算只更改第 17 行,我们还想更改第 18 行的数组。如果我们只更改第 17 行,我们就能解决部分问题。然而,问题将从一个地方转移到另一个地方,因为我们不会改变联合的宽度。因此,重要的是要注意正在编程的内容。如果我们足够小心,就不会有问题,我们的代码将变得更加有用,以更少的风险和精力覆盖更多的情况。
现在我们已经审查了必要的步骤,我们可以更改代码 05,如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. T value; 18. uchar u8_bits[sizeof(T)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
代码 06
通过执行代码 06(这只是代码 05 的修改),我们将得到下图所示的结果。
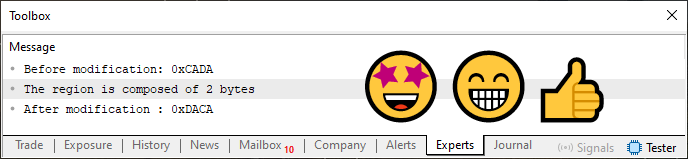
图 06
简直完美,现在我们有了正确的答案。此外,我们已将代码 04 转换为更高级的代码。现在编译器可以为我们创建和生成重载函数或过程,我们可以放心使用任何数据类型。基于代码 06 的模板,编译器将为例程的正确操作创建适当的过程,始终产生与预期结果相匹配的结果。
因为我们已经创建了一个更有趣的模型,你可能会想,“好吧,就是这样。现在我知道如何创建联合模板了。”没错,你已经知道如何在一个非常简单的情况下做到这一点。然而,我们这里展示的并不是联合模板。这只是关于联合在函数或过程中使用模板的适用性。要实现联合模板,正如一些人所说,问题要更加深刻一些。但为了正确地区分问题,我们将在另一个新主题中研究如何做到这一点。因此,我们不会冒险将两者混淆。
联合模板的定义
现在,让我们更深入地了解如何使用模板。与我们迄今为止所看到的不同,在为联合定义模板时,就像我们稍后将讨论的其他类型一样,我们希望做出一些新手程序员关心的决定,即如何实现代码。这是因为我们将创建的代码的一部分可能看起来很奇特。
如果你觉得代码太复杂了,请冷静下来,退一步。理想情况下,我们应该努力学习和实践迄今为止所展示的内容,直到我们对原则和概念有了正确的理解。只有这样,你才能回去,从暂停前停下来的地方开始。
不要试图超越自己,也不要仅仅因为你看到了使用特定资源的代码就认为你已经想通了,因为一切都没有按照应有的方式工作。正确理解这个概念,一切都会变得更简单、更清晰。
在这么早的阶段,我们现在要做的事情实际上相当令人困惑。我们将在下一篇文章中讨论这个困惑。无论如何,有必要做这里显示的事情,你必须了解当你遇到这样的事情或当你需要以显示的方式实现某事时会发生什么。
像往常一样,我们将从一件简单的事情开始。我们的目标与上一节中介绍的代码 06 类似。但是,我们不使用函数或过程。我们稍后再谈,因为这有点难理解。因此,在这个阶段,我们将执行 OnStart 函数中的所有操作。让我们开始吧!首先,下面提供代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }; 19. 20. { 21. un_01 info; 22. 23. info.value = 0xA1B2C3D4E5F6789A; 24. PrintFormat("The region is composed of %d bytes", sizeof(info)); 25. PrintFormat("Before modification: 0x%I64X", info.value); 26. macro_Swap(info); 27. PrintFormat("After modification : 0x%I64X", info.value); 28. } 29. 30. { 31. un_01 info; 32. 33. info.value = 0xCADA; 34. PrintFormat("The region is composed of %d bytes", sizeof(info)); 35. PrintFormat("Before modification: 0x%I64X", info.value); 36. macro_Swap(info); 37. PrintFormat("After modification : 0x%I64X", info.value); 38. } 39. } 40. //+------------------------------------------------------------------+
代码 07
当执行代码 07 时,我们得到的结果与代码 04 非常相似。但是,在这里,我们同时输入两个值以同时显示所有内容。因此,执行代码 07 的实际结果就是我们在下面看到的。
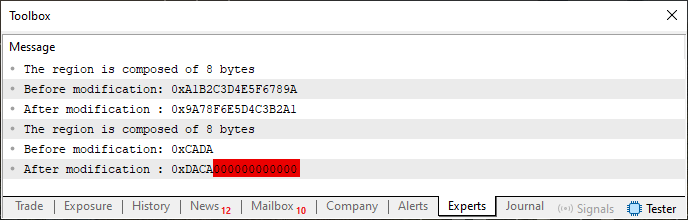
图 07
正如我们在图 04 中注意到的,在最终结果中放置了不适当的值,在图 07 中,我们看到相同的值再次出现。简单来说:我们有一个可能是 ushort 变量的值,但它受到其他不正确值的阻碍。我知道,起初这段代码可能看起来是正确的,甚至可能是正确的。但这项研究的目的是帮助创建一个使用事物的模板,以获得与上一节中获得的结果相似的结果。
但是,不使用函数或过程。请注意另一点:为了避免在这个阶段使用函数或过程,我们将代码的一般部分传递给宏。您可以从第 07 行及以后看到它。由于宏的操作已经描述过了,我将不再赘述,因为我认为在这种特殊情况下没有必要。
好的,让我们继续讨论主要问题。与之前的主题不同,我们现在处理的是不同类型的情况,但目标相似。请注意,以前可以应用的概念现在不再适用。发生这种情况是因为在代码 07 中我们没有可以应用模板的函数或过程。然而,这里应用的基本概念与已经应用的概念非常相似,只是起初有点令人困惑。
亲爱的读者,要小心。我们的目标是创建一种能够处理任何类型数据的代码,就像我们创建后来的代码 06 时所做的那样。然而,为了实现这一目标,我们将不得不采取一种稍微不同的重载方式。到目前为止,重载已经应用于函数或过程,但现在我们需要类型重载。这可能看起来有点令人困惑,但基本概念与对函数或过程使用重载时相同。
然后注意以下几点:我们需要代码 07 第 14 行声明的联合与代码 06 中可用的联合以相同的方式工作。但是我们怎样才能做到呢?这很简单。可以说第 14 行的 union 是一个模板。“我不明白。我们该怎么做呢?”正如我所说,当你第一次了解这种模拟时,可能会有点困惑。首先,我们在第 14 行看到的链接是本地链接。并且每个模板必须是全局的。因此,首先要做的是从 OnStart 过程中删除此声明。然后,我们将声明转换为全局模型。然后,我们只想添加我们已经习惯看到的内容,即将联合转换为模板,就像对函数或过程所做的那样。其结果如代码 08 所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
代码 08
到目前为止,一切都很简单,因为我们正在处理我们已经能做的事情。然而,困难也随之而来:如果您尝试编译代码 08,您将会失败。这是因为,从编译器的角度来看,代码包含一种初学者难以理解的错误。下面显示了当我们尝试编译此代码时编译器将提供的信息类型。
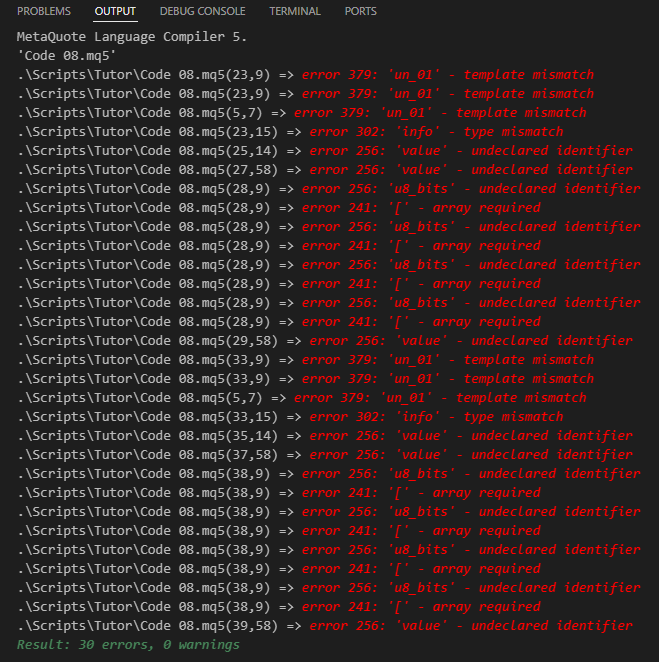
图 08
我们似乎没有走在正确的轨道上,因为这样多的错误有点令人沮丧。然而,这就是问题所在,这真的让许多初学者感到困惑。因为所有这些错误(如图 08 所示)的发生都是因为编译器不知道使用哪种数据类型。由于我已经在本文中就各种主题提供了许多解释,不想让你混淆这个问题的解决方案,我将暂停一下,把这个问题留给下一篇文章来解释。
最后的探讨
在这篇文章中,我们开始探索一个非常困难的话题,当然,除非你练习所展示的内容。然而,由于我想让你好好学习,我决定打断这篇文章的最后一个话题。正确解释如何告诉编译器要做什么需要时间,我不想进一步混淆一个已经足够复杂的主题。
因此,请尝试实践本文所展示的内容。但基本上,试着弄清楚如何告诉编译器应该使用哪些数据,以便本文末尾提供的代码 08 能够正常工作。冷静地思考,因为在下一篇文章中,我们将看到如何实际做到这一点,以及如何利用它来发挥你的优势。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15669
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

un_01 <ulong> info;