
От начального до среднего уровня: Шаблон и Typename (III)

Введение
Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
В предыдущей статье "От начального до среднего уровня: Шаблон и typename (II)", мы объяснили, как справиться с некоторыми специфическими повседневными ситуациями для программистов. Будь то ваше временное увлечение или вы профессиональный программист, использование шаблонов функций и процедур может быть весьма полезным в определенные моменты. Хотя в MQL5 это не очень распространено и не всегда применимо, полезно знать, что такую концепцию можно применить и что у нее есть свои моменты, которые необходимо правильно понимать, чтобы не запутаться при попытке модифицировать код, в котором в итоге используется такое моделирование.
Шаблоны применяются не только к функциям и процедурам. На самом деле они имеют широкий спектр практического применения, который в большей или меньшей степени зависит от типа приложения, который вы хотите разработать. Стоит напомнить - и подчеркнуть это еще раз, - что мы можем реализовать тот же вид приложения без использования шаблонов. Однако использование такого инструмента и ресурса из MQL5 делает этап внедрения более простым и приятным, а также позволяет избежать некоторых видов сложных и раздражающих сбоев при обнаружении.
Шаблоны в локальных переменных
В предыдущих двух статьях, в которых мы говорили только о шаблонах в функциях или процедурах, всё было довольно просто и даже интересно. Но благодаря объяснениям стало ясно, что шаблоны функций или процедур - это хороший способ делегировать работу компилятору, до такой степени, что создается перезагрузка функции или процедуры. Однако представленные примеры были очень простыми, поскольку тип используемых данных указывался только в связи с входными параметрами функции или процедуры. Хотя можно подняться на несколько более высокий уровень знаний.
Чтобы понять это, давайте начнем с простого примера: расчета средних величин. Да, даже при том, что это простая вещь, мы можем увидеть, как применить шаблоны в подобной ситуации. Но я хотел бы напомнить вам, что представленные здесь коды предназначены исключительно для образовательных целей. Они не обязательно представляют собой код, который будет использоваться в реальном мире.
Поскольку я думаю, что вы уже понимаете, как работает перегрузка функции или процедуры, мы можем сосредоточиться только на тех частях, которые действительно заслуживают внимания, убрав из кода всё лишнее. Таким образом, мы имеем из первых рук код, представленный ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. double Averange(const double &arg[]) 16. { 17. double local = 0; 18. 19. for (uint c = 0; c < arg.Size(); c++) 20. local += arg[c]; 21. 22. return local / arg.Size(); 23. } 24. //+------------------------------------------------------------------+ 25. long Averange(const long &arg[]) 26. { 27. long local = 0; 28. 29. for (uint c = 0; c < arg.Size(); c++) 30. local += arg[c]; 31. 32. return local / arg.Size(); 33. } 34. //+------------------------------------------------------------------+
Код 01
Перед нами обычный код, цель которого - вычислить среднее значение набора данных. Для тех, кто не понимает, средний расчет состоит в том, чтобы сложить все значения, а затем разделить результат данной суммы на количество элементов, присутствующих в расчете. Хотя этот тип вычислений простой, есть небольшая проблема: значения могут быть как положительными, так и отрицательными. Мы можем получить искаженное среднее значение, которое не отражает того, что мы действительно хотим знать. Но это незначительный момент, который здесь не имеет важности. Мы упомянули об этом только для того, чтобы вы знали, что код не всегда дает нам нужную информацию, даже если он был создан кем-то другим. Кроме того, тот факт, что другой программист создал определенный код, заставляет код реагировать на то, что искал этот программист, а не на то, что можем искать мы.
Однако я не думаю, что нужно объяснять, как работает код 01, поскольку он использует перегрузку, чтобы факторизация выполнялась наиболее подходящим способом. Результат выполнения данной операции можно увидеть на следующем изображении.
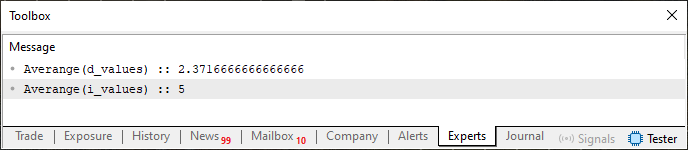
Рисунок 01
Другими словами, это что-то банальное и простое. Но я хочу, чтобы вы внимательно посмотрели на функцию, реализованную в строках 15 и 25. Что у них общего? Можно сказать, что они практически идентичны, за исключением одной специфической детали. Данная часть как раз и относится к типу используемых данных. В остальном они одинаковые, без видимых различий. И, действительно, если вы успели это заметить, значит, вы о чем-то задумались: мы можем преобразовать эти две функции, показанные в коде 01, в шаблон. Это упростит задачу. «Однако у меня есть сомнения на этот счет. В обеих функциях есть локальная переменная, которую можно увидеть в строках 17 и 27. Я знаю, как объявить и реализовать вызов функции в виде шаблона, поскольку я видел, как это делается в предыдущих статьях. Однако эта локальная переменная не дает мне покоя, я не знаю, как с ней работать. Возможно, я смогу сделать что-то похожее на код, представленный ниже».
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. double local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return (T)(local / arg.Size()); 24. } 25. //+------------------------------------------------------------------+
Код 02
На самом деле, вы можете сделать то, что показано в коде 02. Однако при попытке скомпилировать данный код вы получите такое предупреждение от компилятора:
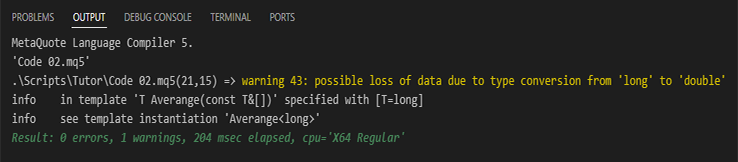
Рисунок 02
Прошу заметить, что ЭТО НЕ СООБЩЕНИЕ ОБ ОШИБКЕ, а предупреждение. Это происходит так, потому что в строке 21, где мы суммируем значения массива, будет момент, когда мы будем суммировать значение с плавающей точкой с целочисленным значением. И это может привести к искажению конечного результата. Однако конечный результат, когда мы выполним код (02), будет таким же, как на изображении 01. Тем не менее, это предупреждение компилятора может немного беспокоить некоторых программистов. Как можно исправить этот момент? Чтобы решить проблему, нам нужно выполнить преобразование типа, точно так же, как мы делаем это в строке 23, только применить преобразование здесь, в строке 21. Но будьте осторожны: не стоит использовать то, что показано ниже.
local += (T)arg[c];
Это НЕ РЕШИТ ВОПРОС С ПРЕДУПРЕЖДЕНИЕМ, так как нам нужно выполнить преобразование, чтобы значение в массиве было совместимо со значением переменной в строке 18. Хотя это может показаться сложным, на самом деле всё очень просто и понятно. Всё, что нам нужно сделать, это изменить строку 21 кода 02 на строку, которую вы видите чуть ниже.
local += (double)arg[c]; Теперь мы решили нашу проблему. У нас есть функция Average, реализованная в виде шаблона, и она работает замечательно. Однако есть и другой способ решить эти же проблемы, чтобы не так сильно изменить код. Давайте вернемся к коду 01. Прошу заметить, что код 02 представляет собой то, что реализовано в коде 01. Если проблемы возникают из-за локальной переменной, как показано выше, почему бы не сделать что-то более сложное? Таким образом, компилятор сам позаботится о подобных проблемах. Кажется смелым, не так ли?
Но если вы действительно поняли, как код 01 был преобразован в код 02 и как мы справились с предупреждением, выданным компилятором, вы должны были подумать о другом решении. Одно из таких решений, которое позволяет изменить тип переменной, объявленной в строке 18 из кода 02. Это было бы действительно интересным решением, и именно это мы и наблюдаем в процессе реализации.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. T local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return local / arg.Size(); 24. } 25. //+------------------------------------------------------------------+
Код 03
Код 03 дает тот же результат, что и на изображении 01, и не выдает никаких предупреждений от компилятора. Почему? Потому что, когда компилятор заметит, что нам нужен целочисленный тип, он приведет тип переменной в соответствие с целочисленным типом. Если компилятор заметит, что нам нужен тип с плавающей точкой, он сделает переменную, объявленную в строке 18, соответствующего типа для использования с плавающей точкой.
Таким образом, у нас получится гораздо более простой код, чем код 01, и хотя он очень похож на код 02, но нет необходимости вносить все различные корректировки. Это гарантирует, что произойдет преобразование типов, и предупреждения компилятора не будут выданы. Здорово, не правда ли? Думаю, если вы уже видели код, похожий на этот, то наверное представляли, как он работает. Но если понять основные концепции и увидеть, как всё сочетается друг с другом, то коды, которые раньше казались сложными, становятся более простыми и интересными.
Хорошо, это была самая приятная часть. А теперь увидим действительно интересную часть. Учитывая возможности использования, представленные в коде 03, теперь хочется поэкспериментировать с другими типами данных.
Поскольку на данный момент мы показали только тип данных, используемый объединением, мы можем попробовать использовать ту же технику, показанную в коде 03, для создания еще более крупного шаблона. Но, чтобы правильно разделить задачи, мы рассмотрим это в другой теме.
Использование элементов в объединениях
Сначала мы рассмотрим показанное в коде 03 в несколько более простом виде, по крайней мере, в начале. На самом деле, мы не собираемся снова изменять код 03, но мы собираемся использовать данную концепцию для создания динамической области памяти внутри объединения. Другими словами, мы собираемся создать шаблон для создания объединения между массивом и любым типом данных.
Когда мы изучали, как определяется объединение, мы увидели, что оно состоит из блока с фиксированным размером. У данного блока, определяемого в байтах, есть значение количества байтов, принадлежащих самому большому типу, присутствующему в объединении. Мы можем сделать так, чтобы это не было абсолютной истиной, то есть мы можем динамически настроить данное объединение компилятором, что позволит нам создать объединение, у которого, в принципе, будет динамический размер блока, так как ширина в байтах будет определена в момент компиляции нашего кода, и с этого момента она будет иметь фиксированный размер.
Сейчас вы, возможно, подумаете: «Мне это кажется очень сложным делом. На первый взгляд, я не знаю, как мы сообщим компилятору, как работать с таким подходом или реализацией. Нужно ли нам это именно сейчас?» Ну что ж, в каком-то смысле некоторые могут считать данную концепцию передовой, но, на мой взгляд, это всё же базовая концепция, которую должен знать каждый новичок, поскольку она значительно облегчает создание различных типов кода для более широких целей.
Я знаю, что многие могут подумать, что мы движемся слишком быстро. Однако мы идем как можно медленнее, не пропуская ни одной концепции или объяснения. Если данная база знаний будет хорошо сформирована и усвоена, всё последующее станет гораздо более естественным и легким для понимания. Хотя, поскольку я знаю, что будущие материалы могут быть немного запутанными поначалу, мы начнем с более простого кода. Это сделает изучение новых понятий более приятным и легким. Размышляя таким образом, давайте начнем с представленного ниже кода.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ulong info = 0xA1B2C3D4E5F6789A; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. ulong Swap(ulong arg) 13. { 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }info; 19. 20. info.value = arg; 21. 22. PrintFormat("The region is composed of %d bytes", sizeof(info)); 23. 24. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 25. { 26. tmp = info.u8_bits[i]; 27. info.u8_bits[i] = info.u8_bits[j]; 28. info.u8_bits[j] = tmp; 29. } 30. 31. return info.value; 32. } 33. //+------------------------------------------------------------------+
Код 04
Данный код еще не использует ресурс шаблона. Поскольку это уже объяснялось в другой статье, когда мы вводили тему объединения, я не вижу необходимости снова объяснять, как это работает. Однако, когда вводили код 04, мы не были заинтересованы в его расширении. Поэтому функция, из строки 12, на самом деле не существовала. Всё было сделано в рамках OnStart. Но сейчас, в связи с тем, что мы будем рассказывать о шаблонах в объединениях, уместно выделить всё в отдельный блок. Это облегчит первый контакт с шаблонами объединения. Затем мы увидим, что можно поместить всё в один блок кода, как было сделано изначально.
Когда вы скомпилируете и запустите код 04, вы увидите ответ в терминале MetaTrader 5.
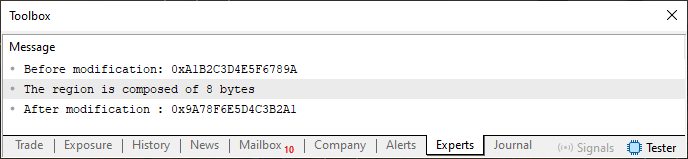
Рисунок 03
Другими словами, мы перемещаем биты. Всё просто. Как же нам изменить биты других типов данных? Потому что, если у нас есть такой тип, как ushort, у которого 2 байта, и мы отправим данный тип в функцию в строке 12, мы получим неправильный результат, или, по крайней мере, что-то довольно странное. Чтобы убедиться в этом, просто измените строку 06 из кода 04 на строку, показанную ниже.
const ushort info = 0xCADA;
Теперь, когда мы запускаем код 04 с этой строкой, показанной выше, результатом будет то, что мы видим на экране терминала MetaTrader 5.
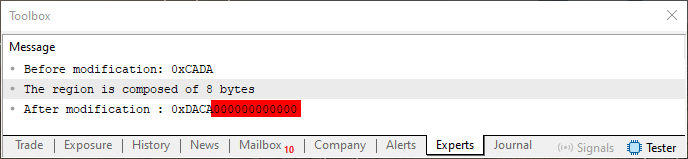
Рисунок 04
Прошу заметить одну вещь на изображении 04: область, которую я выделил красным цветом, - это ненужные данные, добавленные к значению типа ushort. Даже если вы заметили, что вращение действительно произошло, эти байты являются проблемой. Тем более, если нам нужно сохранить тип ushort. Именно в этом случае на помощь приходит шаблон.
Как уже было показано в предыдущей теме, работать со значениями различных типов очень просто, практично и безопасно. Это позволяет нам рассчитывать среднее значение. На самом деле, наше приложение может без проблем работать как с целочисленными значениями, так и со значениями с плавающей точкой. Но как сделать то же самое здесь, где мы используем и нуждаемся в объединении, чтобы упростить код? Что ж, это самая интересная часть.
Сначала нам нужно преобразовать код 04 в код, пригодный для шаблонов. Судя по тому, что было показано до настоящего момента, сделать это очень просто, особенно если вы на самом деле понимаете изложенные концепции. Затем, без особых проблем, мы создаем код, который показан ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. ulong value; 18. uchar u8_bits[sizeof(ulong)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Код 05
Однако при попытке скомпилировать код 05 компилятор выдает предупреждение. Данное предупреждение можно увидеть на изображении ниже.

Рисунок 05
А теперь подумайте вместе со мной. Вы видите это предупреждение, которое сообщает, что значение в строке 32 не совместимо с возвращаемым значением, так как у них разные типы. Где вы видели это раньше? Если вернуться немного назад в этой же статье, то увидите нечто подобное на изображении 02. Исходя из этого, у вас уже есть средства для решения этой самой проблемы. Можно пойти как в одну, так и в другую сторону. Однако, как вы должны были заметить в предыдущей теме, лучшим способом, который заставляет нас вносить меньше изменений в код, является тот, который преобразует переменную неправильного типа в ожидаемый тип в качестве возврата. Другими словами, НЕ нужно изменять строку 32, а нужно строку 15, где объявляется объединение значений.
Подумайте, почему я не говорю, что мы должны внести поправку в строку 17? Ведь именно там находится переменная, которая используется в строке 32 для возврата значения. Причина в том, что мы не собираемся изменять только строку 17, нам также нужно изменить массив в строке 18. А если мы изменим только строку 17, мы исправим часть проблемы. Однако проблема будет перемещаться из одного место в другое, поскольку мы не будем менять ширину объединения. Поэтому важно обращать внимание именно на то, что программируется. Если мы проявляем должную осторожность, проблем не возникнет, а наш код станет более полезным, охватывая большее количество случаев с гораздо меньшим риском и усилиями.
Теперь, ознакомившись с нужными шагами, мы можем изменить код 05 так, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. T value; 18. uchar u8_bits[sizeof(T)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Код 06
Выполнив код 06, который является всего лишь модификацией кода 05, мы получим результат, показанный на изображении ниже.
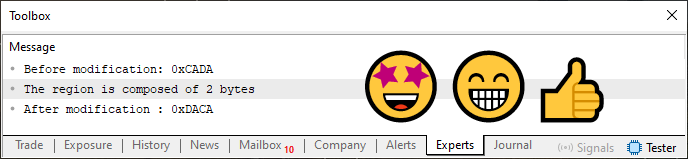
Рисунок 06
Просто идеально. Теперь у нас есть правильный ответ. Кроме того, мы преобразовали код 04 в гораздо более совершенный код. Теперь, когда компилятор может создавать и генерировать для нас перегруженные функции или процедуры, мы можем использовать любые типы данных без опасений. Основываясь на шаблоне кода 06, компилятор создаст соответствующие процедуры для корректной работы подпрограммы, всегда выдавая результаты, соответствующие ожидаемым.
Благодаря тому, что мы уже создали гораздо более интересную модель, вы, может быть, подумаете: «Ну, вот и всё. Теперь я знаю, как создавать шаблоны объединений». Верно, вы уже знаете, как это сделать в очень простом случае. Однако то, что мы здесь показали, НЕ ЯВЛЯЕТСЯ ШАБЛОНОМ ОБЪЕДИНЕНИЯ. Речь идет только о пригодности объединения для использования шаблона в функции или процедуре. Чтобы достичь того, что стало бы шаблоном объединения, вопрос, как говорят некоторые, стоит немного глубже. Но чтобы правильно разделить вопросы, мы посмотрим, как это сделать в другой, новой теме. Таким образом, мы не рискуем спутать одно с другим.
Определение шаблона объединения
Теперь давайте немного углубимся в вопрос о том, как работать с шаблонами. В отличие от того, что мы видели до этого момента, при определении шаблона для объединения, как и для других типов, которые мы рассмотрим позже, нам нужно принять некоторые решения, которые беспокоят начинающих программистов касательно того, как должен быть реализован код. Это связано с тем, что часть кода, которую мы будем создавать, может выглядеть, скажем, экзотично.
Если вам кажется, что код становится слишком сложным, прошу успокоиться и сделать шаг назад. В идеале мы должны стремиться изучать и практиковать то, что было показано до сих пор, пока не получим правильное понимание принципов и концепций. Только после этого вернитесь назад и начните с того места, на котором остановились до паузы.
Не пытайтесь забегать вперед и не думайте, что вы что-то поняли только потому, что увидели код, использующий определенный ресурс, ведь всё работает не так, как надо. Поймите эту концепцию правильно, и всё станет намного проще и понятнее.
Что же мы будем делать сейчас, на самом деле, довольно запутанно для столь раннего этапа. О путанице мы расскажем в следующей статье. В любом случае, необходимо сделать то, что будет показано здесь, и вы должны понимать, что произойдет, когда столкнетесь с чем-то подобным или когда вам нужно будет реализовать что-то показанным способом.
Как обычно, мы начнем с простого. Нашей целью будет нечто похожее на код 06, представленный в предыдущей теме. Однако МЫ НЕ ИСПОЛЬЗУЕМ ФУНКЦИЮ ИЛИ ПРОЦЕДУРУ. Об этом мы поговорим позже, поскольку это немного сложнее для понимания. Поэтому на данном этапе мы будем делать всё в функции OnStart. Давайте начнем. Во-первых, код, представлен ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }; 19. 20. { 21. un_01 info; 22. 23. info.value = 0xA1B2C3D4E5F6789A; 24. PrintFormat("The region is composed of %d bytes", sizeof(info)); 25. PrintFormat("Before modification: 0x%I64X", info.value); 26. macro_Swap(info); 27. PrintFormat("After modification : 0x%I64X", info.value); 28. } 29. 30. { 31. un_01 info; 32. 33. info.value = 0xCADA; 34. PrintFormat("The region is composed of %d bytes", sizeof(info)); 35. PrintFormat("Before modification: 0x%I64X", info.value); 36. macro_Swap(info); 37. PrintFormat("After modification : 0x%I64X", info.value); 38. } 39. } 40. //+------------------------------------------------------------------+
Код 07
При выполнении кода 07 получим результат, очень похожий на код 04. Однако здесь мы вводим два значения одновременно, чтобы показать всё сразу. Таким образом, фактический результат выполнения кода 07 - это то, что мы видим чуть ниже.
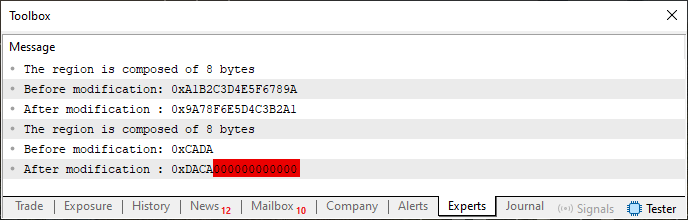
Рисунок 07
Точно так же, как мы отметили на изображении 04, где в итоговый результат были помещены неподходящие значения, здесь, на изображении 07, мы видим, что эти же значения появляются снова. Немного упростим: у нас есть значение, которое могло бы быть переменной ushort, но которому мешают другие неправильные значения. Я знаю, что поначалу данный код может показаться правильным, и даже может быть правильным, в зависимости от того, что в нем реализовано. Но цель данного исследования - способствовать созданию шаблона для использования вещей таким образом, чтобы получить результат, аналогичный тому, который был получен в предыдущей теме.
Однако без использования функций или процедур. Прошу заметить еще один момент: именно для того, чтобы избежать использования функции или процедуры на данном этапе, мы переносим общую часть кода в макрос. Ее можно увидеть со строки 07 и далее. Поскольку работа макросов уже описана, я не буду вдаваться в подробности, так как не вижу необходимости в данном конкретном случае.
Ладно, перейдем к главному вопросу. В отличие от предыдущей темы, сейчас мы имеем дело с другим видом ситуации, но с аналогичной целью. Обратите внимание, концепция, которую можно было применить раньше, больше не может быть применена. Это происходит, потому что в коде 07 у нас нет функции или процедуры, к которой можно применить шаблон. Однако основная концепция, которая применяется здесь, очень похожа на ту, что уже применялась, только вначале несколько запутанная.
Будьте внимательны, дорогой читатель. Наша цель - создать код, способный работать с любыми типами данных, как мы делали, когда создавали то, что впоследствии стало кодом 06. Однако для достижения данной цели нам придется прибегнуть к несколько иному виду перегрузки. Пока перегрузка применялась к функциям или процедурам. Но теперь нам нужна перегрузка типа. Это может показаться немного запутанным, но основная концепция та же, что и при использовании перегрузки для функций или процедур.
Затем обратите внимание на следующее: нам нужно, чтобы объединение, объявленное в строке 14 из кода 07, работало так же, как и объединение, присутствующее в коде 06. Но как это сделать? Всё очень просто. Достаточно сказать, что объединение строки 14 - шаблон. «Я не понимаю. Как мы собираемся это сделать?» Ну, как я уже сказал, это может быть немного запутанным при первом знакомстве с таким моделированием. Начнем с того, что ссылка, которую мы видим в строке 14, является локальной. И каждый шаблон ДОЛЖЕН БЫТЬ ГЛОБАЛЬНЫМ. Поэтому первое, что нужно сделать, это удалить данное объявление из процедуры OnStart. При этом преобразим объявление в глобальную модель. Затем нужно просто добавить то, что мы уже привыкли видеть, то есть преобразование объединения в шаблон, как это делается для функции или процедуры. Это приводит к тому, что показано ниже в коде 08.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
Код 08
Пока всё было очень легко и просто, ведь мы имеем дело именно с тем, что уже умеем делать. Однако, здесь начинаются сложности: если попытаться скомпилировать код 08, у вас ничего не получится. Это связано с тем, что с точки зрения компилятора код содержит тип ошибки, который трудно понять новичкам. Ниже показан тип информации, которую сообщит компилятор, когда мы попытаемся скомпилировать этот код.
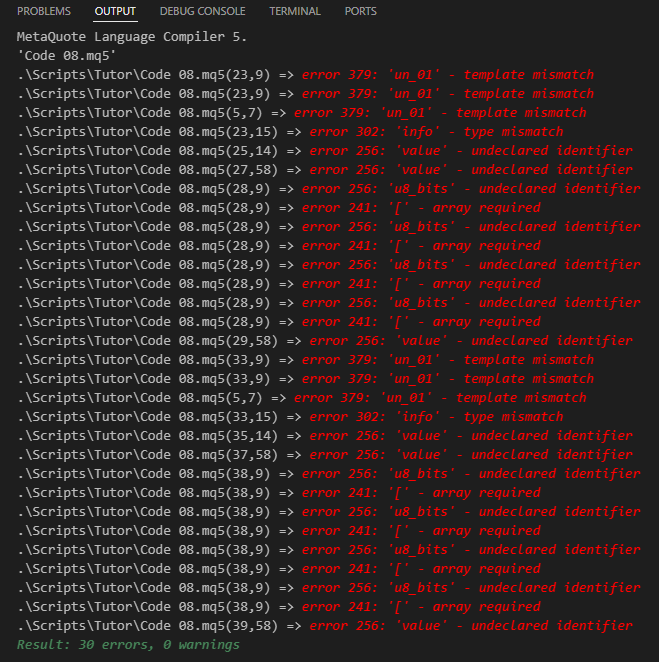
Рисунок 08
Похоже, что мы не на верном пути, поскольку такое количество ошибок несколько обескураживает. Однако именно здесь и кроется проблема, которая действительно смущает многих новичков. Потому что все эти ошибки, которые можно увидеть на рисунке 08, возникают из-за того, что компилятор НЕ ЗНАЕТ, какой тип данных следует использовать. Поскольку в этой статье я уже дал много объяснений на разные темы и не хочу запутать вас решением этого вопроса, я сделаю паузу, оставив данный вопрос для объяснения в следующей статье.
Заключительные идеи
В данной статье мы начали изучать очень сложную тему, если вы, конечно, не практикуете то, что вам показывается. Однако, поскольку я хочу, чтобы вы учились правильно, я решил прервать последнюю тему этой статьи. Правильное объяснение того, как указать компилятору, что делать, требует времени, и я не хочу еще больше запутывать тему, которая и так достаточно сложна.
Поэтому попробуйте применить на практике то, что было показано в этой статье. Но в основном попытаетесь понять, как сообщить компилятору, какие данные следует использовать, чтобы представленный в конце этой статьи код 08 действительно работал. Подумайте об этом спокойно, потому что в следующей статье мы увидим, как это сделать на самом деле, а также как использовать это в своих интересах.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15669
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Искусство ведения логов (Часть 2): Форматирование логов
Искусство ведения логов (Часть 2): Форматирование логов
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
un_01 <ulong> info;