
From Novice to Expert: Statistical Validation of Supply and Demand Zones

Contents:
Introduction
The analysis of supply and demand zones represents a cornerstone of price action trading, rooted in the timeless economic principle of market imbalance. For the discretionary trader, these zones are identified through visual pattern recognition—a skill honed by experience. However, this reliance on subjective judgment creates a significant reproducibility challenge, forming the primary barrier to effective automation. While the theoretical logic of these zones is well-established, its translation into precise, computational rules remains elusive, often defaulting to arbitrary numerical thresholds.
This article presents a structured research methodology to bridge this gap. We detail a complete, reproducible pipeline that transforms the qualitative concept of an "impulsive exit" into a quantified, statistically validated trading rule. Our approach introduces a key methodological simplification by using single higher-timeframe (HTF) candlesticks as the fundamental unit of analysis. This allows us to capture the essence of a supply or demand zone with clarity and measure its defining characteristic: momentum.
By leveraging a Python-based research environment within a Jupyter Notebook, we systematically determine the statistical signature of a high-probability zone. The derived parameters are then encoded into an MQL5 Expert Advisor, creating a transparent, evidence-based trading tool. This process moves the discipline from asking, "Does this look strong?" to answering, "Does this meet the statistically defined criteria for strength?"
Conceptual Foundations: The Anatomy of a Market Imbalance
Core Principle: Price Imbalance
A supply or demand zone marks a price level where the equilibrium between buyers and sellers broke decisively. An aggressive influx of orders from one side overwhelms the other, causing price to depart the area with velocity. This rapid departure—the impulsive exit—leaves behind a theoretical concentration of unfilled opposing orders. This zone of imbalance then becomes a region of future interest, as price is predisposed to react upon its return.
Defining the Structural Components
Through synthesis of trading literature and extensive personal chart review, the anatomy of a classic zone can be distilled:
Supply Zone: An area where selling pressure overwhelms buying interest. Visually, it is identified by a consolidation base (a series of candles with overlapping ranges) followed by a strong bearish impulsive candle that closes below the base's low.
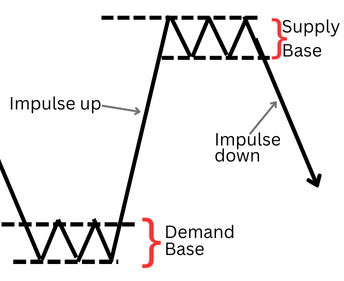
Supply and Demand Concepts
Demand Zone: The bullish inverse, where aggressive buying triggers a bullish impulsive candle closing above a consolidation base's high.
The Impulsive Exit Candle is the critical component. It is the market's signature, confirming the imbalance. In discretionary practice, its "strength" is assessed visually, leading to inconsistency. Therefore, the magnitude of this candle becomes the primary variable for our quantitative research.
The Complete Zone Lifecycle: Impulse, Continuation, and Retest
Understanding the initial exit is only the first phase. The complete lifecycle of a valid zone often unfolds in two key movements:
- Phase 1—Initial Impulsive Exit: Price breaks from the base with momentum, establishing a new short-term directional extreme.
- Phase 2—Retest and Reaction: Price often returns to the origin zone, retesting the area of imbalance. This retest frequently produces a second, reactive move away from the zone as the remaining unfilled orders are encountered.

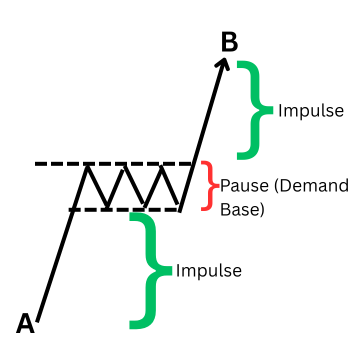
Demand Zone ( Consolidation at A, Exit to B, and Return to Demand at C)
The following image represents a clear supply zone lifecycle, annotated with the corresponding bearish phases.

Single Candle Supply Zone (S), Exit impulse A to B. Return to zone at C.
For this research, we focus with precision on quantifying Phase 1—the initial impulsive exit. This is the most clearly defined and measurable event, serving as the foundational trigger. A statistically robust definition of this exit directly enables the identification of high-probability zones, upon which strategies involving retests can be reliably built.
Methodological Justification: The Single Higher-Timeframe Candle Model
To transition from visual pattern to quantifiable data, we adopt a focused and robust methodological premise: the entire process of equilibrium and imbalance is often efficiently encapsulated within the structure of a single higher-timeframe (HTF) candle.
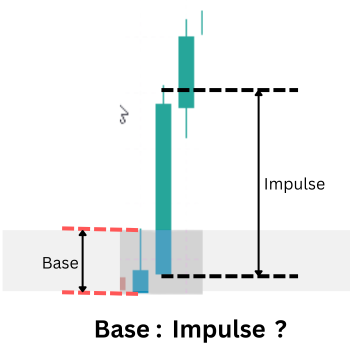
Single candle demand setup ( small base candle and a large exit candle)
Supply and demand can also be found in continuation setups
Conceptual Fidelity: A strong, directional HTF candle at a swing point is the direct result of the imbalance we study. A lower-timeframe analysis of its internal structure would typically reveal the classic sequence of a base followed by an impulsive move. The HTF candle is the aggregate signature of this microstructure.
Advantages for Quantitative Research:
- Signal Clarity: It isolates the decisive market event, filtering out prolonged, ambiguous consolidations.
- Reduced Parametric Complexity: It eliminates the need for multiple parameters to define a multi-candle base (e.g., number of candles, allowed overlap). The boundaries of a single candle (open, high, low, close) are unambiguous.
- Fractal Validity: The principle is consistent across timeframes, allowing research conducted on an HTF (e.g., H4) to be applied to a lower execution timeframe (e.g., M15).
This model shifts our core metric from comparing two separate candles (base vs. exit) to analyzing the internal momentum of one candle. We define this as the "Impulse Ratio": (close-open)/(high-low). A high "Impulse Ratio" (e.g., > 0.7) indicates a candle with a strong directional body and minimal wicks—the precise statistical fingerprint of a decisive exit.
Our central research question is therefore refined: What are the statistically optimal thresholds for the Impulse Ratio and minimum absolute size (in pips) that define a high-probability, zone-creating a highrer timeframe candle?
The Research and Implementation Pipeline
To answer this question, we execute a clear three-stage pipeline, ensuring every algorithmic rule is grounded in empirical evidence.
Stage 1: Systematic Data Harvesting (MQL5)
We develop a custom MQL5 script that acts as a systematic scanner. It identifies candidate HTF candles at swing points and exports their core metrics to a CSV file. The data points for each candidate include:
- Timestamp, Symbol, Timeframe
- Candle Body Size (pips), Total Range (pips), Calculated Impulse Ratio
- Volatility Context (e.g., ATR value at candle close)
Labeling based on subsequent price action to determine "success" for later analysis.
Stage 2: Statistical Discovery and Threshold Optimization (Python/Jupyter Notebook)
In the Jupyter Notebook, we perform exploratory data analysis on the collected dataset.
- Descriptive Statistics: We analyze the distribution of Impulse Ratio and body size across all candidates.
- Success Analysis: We segment the data based on whether the candidate candle led to a successful price reaction, then compare the statistical properties of "successful" vs. "unsuccessful" groups.
- Threshold Optimization: We determine the optimal thresholds (e.g., minimum Impulse Ratio of 0.65, minimum body size of 1.2 * ATR) that maximize the difference in success rates, thereby defining our statistically validated trading rule.
Stage 3: Model Implementation and Validation (MQL5 Expert Advisor)
The final, crucial step is translating statistical findings into executable trading logic. The optimized parameters are hard-coded into an MQL5 Expert Advisor. This EA scans for HTF candles that meet the statistically validated criteria, automatically projects the zone boundaries, and can be extended to manage trades on the lower timeframe, completing the loop from research to automated execution.
Implementation
Systematic Data Harvesting (MQL5)
The first and most critical phase of our research is the systematic collection of high-quality, granular market data. This process moves decisively beyond retrospective chart review. We engineer a dedicated MQL5 script to act as an unbiased data scout, programmatically scanning historical price action to capture every occurrence of our defined two-candle pattern—a "small" candle followed by a larger "exit" candle in the same direction. The script's core function is to translate visual price structures into a structured dataset (CSV), recording precise metrics like body sizes in pips, their ratio, and volatility-adjusted values using the Average True Range (ATR).
By collecting thousands of these observations across different market conditions, we build the essential empirical foundation. This raw data is the input for our statistical analysis, ensuring that every subsequent insight and parameter is derived from objective market behavior, not subjective judgment.
The Data Collection Script
The following breakdown explains the logic and purpose of each code section in our data collection script (SD_BaseExit_Research.mq5). I will attach the full source at the end of the article.
1. Script Headers and Configuration (Inputs)
This section defines the script's identity and, most importantly, the adjustable parameters that control its behavior.
//--- Inputs: Define what "small" and "bigger" mean input int BarsToProcess = 20000; // Total bars to scan input int ATR_Period = 14; // For volatility context input double MaxBaseBodyATR = 0.5; // Base candle max size (e.g., 0.5 * ATR) input double MinExitBodyRatio = 2.0; // Exit must be at least this many times bigger than base input bool CollectAllData = true; // TRUE=log all pairs, FALSE=use above filters now input string OutFilePrefix = "SD_BaseExit";
These inputs make the script a flexible research tool. For initial discovery, CollectAllData should be true to gather a broad sample. Later, you can set it to false to test specific size thresholds (MaxBaseBodyATR, MinExitBodyRatio) directly in MetaTrader 5.
2. Core Initialization (OnStart Function)
This part sets up the necessary tools for data processing and storage: fetching ATR data and creating the output CSV file.
- ATR Handle Creation: Fetches Average True Range data, which is crucial for understanding volatility context.
- CSV File Creation: Opens a new file for writing data. The filename includes the symbol and timeframe for clear organization.
- CSV Header Row: Writes the column titles, defining the dataset's structure.
// 1. INITIALIZATION: Get ATR data and open the data log (CSV file) atrHandle = iATR(_Symbol, _Period, ATR_Period); if(atrHandle == INVALID_HANDLE) { Print("Error: Could not get ATR data."); return; } string tf = PeriodToString(_Period); string fileName = StringFormat("%s_%s_%s.csv", OutFilePrefix, _Symbol, tf); int fileHandle = FileOpen(fileName, FILE_WRITE|FILE_CSV|FILE_ANSI); if(fileHandle == INVALID_HANDLE) { Print("Failed to create file: ", fileName); return; } // Write the header. Each row will be one observed "base-exit" candle pair. FileWrite(fileHandle, "Pattern", "Symbol", "Timeframe", "Timestamp", "Base_BodyPips", "Exit_BodyPips", "ExitToBaseRatio", "ATR_Pips", "Base_BodyATR", "Exit_BodyATR", "Base_Open", "Base_Close", "Exit_Open", "Exit_Close" );
3. Main Scanning Loop: The Pattern Detection Engine
This for loop is the heart of the script, examining each consecutive pair of closed candles in history.
Logic Flow:
- Candle Pairing & Data Extraction: For each bar i, candle i is the potential base, and candle i-1 is the potential exit. The script extracts prices and calculates body sizes and ATR ratios.
- Pattern Logic: It checks if the two candles are consecutive and in the same direction.
- Bullish Pair → Classified as a "demand" pattern candidate.
- Bearish Pair → Classified as a "supply" pattern candidate.
- Mixed directions are discarded.
// 2. MAIN SCANNING LOOP: Look at every consecutive pair of candles for(int i = 1; i < barsToCheck; i++) { int baseIdx = i; // The older candle (potential base) int exitIdx = i - 1; // The newer candle (potential exit) // ... (Data extraction for base and exit candles) ... // 3. PATTERN IDENTIFICATION: Determine direction and type string patternType = "None"; bool isBullishBase = baseClose > baseOpen; bool isBullishExit = exitClose > exitOpen; bool isBearishBase = baseClose < baseOpen; bool isBearishExit = exitClose < exitOpen; // The core logic: A valid pattern requires consecutive candles in the SAME direction. if(isBullishBase && isBullishExit) { patternType = "Demand"; } else if(isBearishBase && isBearishExit) { patternType = "Supply"; } if(patternType == "None") continue; // Skip mixed-direction pairs
4. Strategic Filtering: Balancing Data Quantity and Quality
This is a critical research decision point, controlled by the CollectAllData flag. It determines whether to collect a broad sample for discovery or apply strict filters immediately.
// 4. DATA FILTERING (Optional): Apply size rules if not collecting everything if(!CollectAllData) { // Rule: Base candle must be relatively small compared to market noise bool isBaseSmallEnough = baseBodyATR < MaxBaseBodyATR; // Rule: Exit candle must be significantly larger than the base bool isExitLargeEnough = exitToBaseRatio >= MinExitBodyRatio; if(!isBaseSmallEnough || !isExitLargeEnough) { continue; // Skip this pair, it doesn't meet our current test filters } } // If CollectAllData is TRUE, we log EVERY same-direction pair, regardless of size. // This is best for initial research.
5. Data Logging and Cleanup
For each valid pattern, a detailed row is written to the CSV. Finally, resources are properly released.
// 5. DATA LOGGING: Write all details of this pair to our CSV file datetime exitTime = iTime(_Symbol, _Period, exitIdx); MqlDateTime dtStruct; TimeToStruct(exitTime, dtStruct); string timeStamp = StringFormat("%04d-%02d-%02dT%02d:%02d:%02d", dtStruct.year, dtStruct.mon, dtStruct.day, dtStruct.hour, dtStruct.min, dtStruct.sec); FileWrite(fileHandle, patternType, _Symbol, tf, timeStamp, DoubleToString(baseBodyPips, 2), DoubleToString(exitBodyPips, 2), DoubleToString(exitToBaseRatio, 2), DoubleToString(atrExit / _Point, 2), DoubleToString(baseBodyATR, 3), DoubleToString(exitBodyATR, 3), DoubleToString(baseOpen, _Digits), DoubleToString(baseClose, _Digits), DoubleToString(exitOpen, _Digits), DoubleToString(exitClose, _Digits) ); dataRowsWritten++; } // 6. CLEANUP: Close the file and release the indicator handle FileClose(fileHandle); IndicatorRelease(atrHandle);
With the raw data harvested by our MQL5 script, the next critical step is to seamlessly transition this dataset into our statistical analysis environment. This process involves locating the output file and launching the Python research workspace.
Locating the Collected Data
Upon completion, the script saves the CSV file to the standard MQL5/Files/ directory within your MetaTrader 5 terminal data folder. The exact path typically follows this pattern:
C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files.
The file will be named according to our script's convention, for example, SD_BaseExit_EURUSD_H1.csv. This file contains all the timestamped "Base-Exit" candle pairs and their calculated metrics, ready for scientific examination.
Launching the Python Analysis Environment
To begin analysis, we open a command-line interface (Command Prompt or Terminal), navigate to this directory, and launch Jupyter Notebook. This can be done efficiently with a few commands:
# Navigate to the directory containing your CSV file cd "C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files" # Launch the Jupyter Notebook server jupyter notebook
This sequence opens the JupyterLab interface in your web browser, creating a direct portal to your data. From here, you can create a new notebook (e.g., Supply_and_demand_Research.ipynb) specifically dedicated to this research project.
Stage 2: Statistical Discovery and Threshold Optimization (Python/Jupyter Notebook)
Cell 1: Setup and Data Ingestion
This cell prepares the Python research environment and loads the dataset exported from MetaTrader 5 for analysis.
First, it imports the required scientific and visualization libraries. These libraries provide tools for data manipulation (pandas, numpy), statistical analysis (scipy), and graphical exploration (matplotlib, seaborn). Warnings are suppressed to ensure a clean and readable research output, which is especially important when presenting results in an article.
Next, the visual style for charts is configured to produce consistent, publication-quality plots. This ensures that all graphs generated later in the notebook follow a uniform theme, making distributions and trends easier to interpret.
The cell then loads the CSV file generated by the MQL5 data-collection script. Since the file is exported as tab-delimited, the appropriate separator is explicitly specified to guarantee correct parsing of the data. This step is critical to preserving numerical integrity, especially for pip values, ratios, and timestamps.
# %% [markdown] # # # **Objective:** Analyze the harvested candlestick data to discover statistically significant thresholds for a valid "impulsive exit." # **Data:** `SD_BaseExit_XAUUSDr_5.csv` # **Method:** Exploratory Data Analysis (EDA), Distribution Analysis, and Success Rate Correlation. # %% [markdown] # ## 1. Setup & Data Ingestion (Corrected) # Loading tab-delimited data # %% import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings('ignore') # Set visual style plt.style.use('seaborn-v0_8-darkgrid') sns.set_palette("husl") # Load the data with TAB as delimiter file_path = "SD_BaseExit_XAUUSDr_5.csv" df = pd.read_csv(file_path, sep='\t') # Tab-separated print("✅ Data loaded successfully (tab-delimited).") print(f"Dataset shape: {df.shape}") print("\n🔍 Column names:") print(list(df.columns)) print("\n📊 First 3 rows:") print(df.head(3))
Result 1:
✅ Data loaded successfully (tab-delimited). Dataset shape: (9663, 14) 🔍 Column names: ['Pattern', 'Symbol', 'Timeframe', 'Timestamp', 'Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR', 'Base_Open', 'Base_Close', 'Exit_Open', 'Exit_Close'] 📊 First 3 rows: Pattern Symbol Timeframe Timestamp Base_BodyPips \ 0 Demand XAUUSDr 5 2026-01-12T06:45:00 194.0 1 Demand XAUUSDr 5 2026-01-12T06:40:00 226.0 2 Supply XAUUSDr 5 2026-01-12T06:30:00 104.0 Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR Exit_BodyATR \ 0 155.0 0.80 311.64 0.545 0.497 1 194.0 0.86 355.64 0.632 0.545 2 477.0 4.59 365.79 0.273 1.304 Base_Open Base_Close Exit_Open Exit_Close 0 4566.03 4567.97 4567.96 4569.51 1 4563.80 4566.06 4566.03 4567.97 2 4569.60 4568.56 4568.61 4563.84 🤝
Cell 2: Initial Data Inspection and Cleaning
In this step, we inspected the dataset to confirm its structure, data types, and overall quality before proceeding with statistical analysis. We verified the presence of all critical measurement fields, checked for missing values, and ensured that key columns related to candlestick magnitude, ATR, and exit-to-base ratios were correctly interpreted as numeric data. Any rows containing incomplete or invalid values in these essential fields were removed, resulting in a clean and reliable dataset that forms a solid foundation for all subsequent exploratory and statistical analysis.
# %% [markdown] # ## 2. Initial Data Inspection & Cleaning # %% print("📊 Dataset Info:") print(df.info()) print("\n🧹 Checking for missing values:") print(df.isnull().sum()) # Ensure numeric columns are correctly typed numeric_cols = ['Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR'] for col in numeric_cols: if col in df.columns: df[col] = pd.to_numeric(df[col], errors='coerce') else: print(f"⚠️ Warning: Column '{col}' not found in data") # Remove any rows with missing critical data df_clean = df.dropna(subset=numeric_cols).copy() print(f"\n🧽 Data cleaned. Original: {df.shape}, Cleaned: {df_clean.shape}")
Result 2:
📊 Dataset Info: <class 'pandas.core.frame.DataFrame'> RangeIndex: 9663 entries, 0 to 9662 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pattern 9663 non-null object 1 Symbol 9663 non-null object 2 Timeframe 9663 non-null int64 3 Timestamp 9663 non-null object 4 Base_BodyPips 9663 non-null float64 5 Exit_BodyPips 9663 non-null float64 6 ExitToBaseRatio 9663 non-null float64 7 ATR_Pips 9663 non-null float64 8 Base_BodyATR 9663 non-null float64 9 Exit_BodyATR 9663 non-null float64 10 Base_Open 9663 non-null float64 11 Base_Close 9663 non-null float64 12 Exit_Open 9663 non-null float64 13 Exit_Close 9663 non-null float64 dtypes: float64(10), int64(1), object(3) memory usage: 1.0+ MB None 🧹 Checking for missing values: Pattern 0 Symbol 0 Timeframe 0 Timestamp 0 Base_BodyPips 0 Exit_BodyPips 0 ExitToBaseRatio 0 ATR_Pips 0 Base_BodyATR 0 Exit_BodyATR 0 Base_Open 0 Base_Close 0 Exit_Open 0 Exit_Close 0 dtype: int64 🧽 Data cleaned. Original: (9663, 14), Cleaned: (9663, 14)
Cell 3: Preliminary Statistical Exploration of Supply and Demand Exit Metrics
At this stage, we performed exploratory data analysis to gain an initial statistical understanding of the collected measurements. Descriptive statistics were generated for all key numeric variables to reveal their central tendencies, dispersion, and overall distribution, helping us assess the typical size and variability of both base and exit candles. In addition, we examined the distribution of supply versus demand patterns within the dataset and visualized their frequency, ensuring that the research sample was reasonably balanced and representative before moving deeper into magnitude threshold analysis.
# %% [markdown] # ## 3. Exploratory Data Analysis (EDA) # %% print("🧮 Descriptive Statistics of Key Metrics:") print(df_clean[numeric_cols].describe().round(2)) # Pattern Distribution print(f"\n📈 Pattern Type Distribution:") if 'Pattern' in df_clean.columns: pattern_counts = df_clean['Pattern'].value_counts() print(pattern_counts) # Simple Visualization: Pattern Count plt.figure(figsize=(8,5)) sns.barplot(x=pattern_counts.index, y=pattern_counts.values) plt.title('Count of Supply vs. Demand Patterns Collected') plt.ylabel('Count') plt.show() else: print("⚠️ 'Pattern' column not found")
Result 3:
🧮 Descriptive Statistics of Key Metrics: Base_BodyPips Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR \ count 9663.00 9663.00 9663.00 9663.00 9663.00 mean 237.15 247.71 4.13 473.72 0.62 std 253.53 268.18 17.92 230.17 0.82 min 1.00 1.00 0.00 99.50 0.00 25% 74.00 75.00 0.42 316.64 0.16 50% 168.00 173.00 1.04 421.00 0.38 75% 314.00 325.50 2.55 568.36 0.78 max 3441.00 3441.00 770.00 2156.36 22.79 Exit_BodyATR count 9663.00 mean 0.64 std 0.85 min 0.00 25% 0.16 50% 0.39 75% 0.81 max 22.79 📈 Pattern Type Distribution: Pattern Demand 5131 Supply 4532 Name: count, dtype: int64

Cell 4: Isolation of High-Momentum Supply and Demand Exits
In this step, we deliberately narrowed the dataset to focus on high-momentum supply and demand scenarios by filtering for cases where the exit candle body exceeded the base candle body by a significant margin. By retaining only patterns with an exit-to-base body ratio greater than 1.5, we isolate candidates that visually and structurally align with what traders typically describe as “impulsive” departures from a zone. This refinement reduces noise from marginal moves and allows subsequent statistical analysis to concentrate on exits that are most likely to represent genuine institutional displacement.
# Add this after creating df_clean, BEFORE the clustering cell # Filter to only look at patterns where exit was at least 1.5x the base df_strong = df_clean[df_clean['ExitToBaseRatio'] > 1.5].copy() print(f"Analyzing strong candidates: {df_strong.shape[0]} patterns (>{df_clean.shape[0]} total)")
Result 4:
Analyzing strong candidates: 3725 patterns (>9663 total)
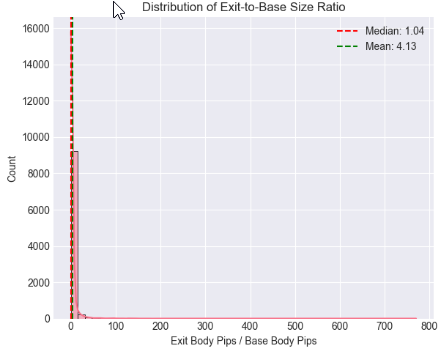
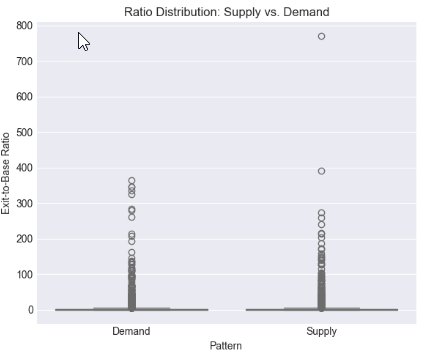
Cell 5: Statistical Distribution and Threshold Analysis of Exit-to-Base Candle Ratio
Using distribution plots and boxplots, we assessed how exit strength is spread overall and how it differs between supply and demand structures. Mean, median, and percentile boundaries were computed to move beyond visual judgment and toward data-driven benchmarks, allowing us to pinpoint ratio ranges that consistently distinguish ordinary price movement from statistically significant displacement.
# %% [markdown] # ## 4. Core Analysis: Distribution of Exit-to-Base Ratio # %% if 'ExitToBaseRatio' in df_clean.columns: plt.figure(figsize=(12, 5)) # Histogram with KDE plt.subplot(1, 2, 1) sns.histplot(data=df_clean, x='ExitToBaseRatio', bins=50, kde=True) plt.axvline(x=df_clean['ExitToBaseRatio'].median(), color='red', linestyle='--', label=f'Median: {df_clean["ExitToBaseRatio"].median():.2f}') plt.axvline(x=df_clean['ExitToBaseRatio'].mean(), color='green', linestyle='--', label=f'Mean: {df_clean["ExitToBaseRatio"].mean():.2f}') plt.title('Distribution of Exit-to-Base Size Ratio') plt.xlabel('Exit Body Pips / Base Body Pips') plt.legend() # Box plot by Pattern type if 'Pattern' in df_clean.columns: plt.subplot(1, 2, 2) sns.boxplot(data=df_clean, x='Pattern', y='ExitToBaseRatio') plt.title('Ratio Distribution: Supply vs. Demand') plt.ylabel('Exit-to-Base Ratio') plt.tight_layout() plt.show() # Critical Percentile Analysis print("📐 Key Percentiles for ExitToBaseRatio:") percentiles = [5, 25, 50, 75, 90, 95, 99] for p in percentiles: value = df_clean['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") else: print("⚠️ 'ExitToBaseRatio' column not found")
Result 5:
Key Percentiles for ExitToBaseRatio: 5th percentile: 0.08 25th percentile: 0.42 50th percentile: 1.04 75th percentile: 2.55 90th percentile: 6.67 95th percentile: 13.41 99th percentile: 61.57
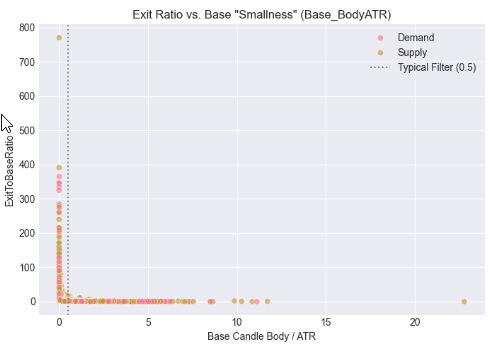
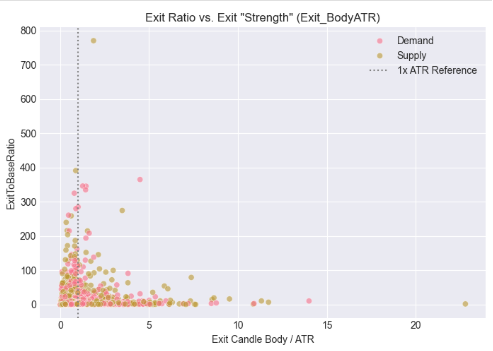
Cell 6: Normalizing Exit Strength Using Volatility (ATR Context)
In this step, we contextualized candle size by relating both the base and exit bodies to market volatility using the Average True Range (ATR). Rather than evaluating magnitude in raw pips alone, we assessed how small the base candle is relative to volatility and how strong the exit candle is when normalized by ATR. The resulting scatter plots reveal how impulsive exits cluster around specific volatility-adjusted thresholds, reinforcing the idea that valid supply and demand departures are better defined by relative strength than by absolute size, and providing a more robust foundation for cross-symbol and cross-timeframe automation.
# %% [markdown] # ## 5. Contextualizing Size: The Role of Volatility (ATR) # %% if all(col in df_clean.columns for col in ['Base_BodyATR', 'Exit_BodyATR', 'ExitToBaseRatio', 'Pattern']): fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # Base Body vs. ATR sns.scatterplot(data=df_clean, x='Base_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[0]) axes[0].axvline(x=0.5, color='gray', linestyle=':', label='Typical Filter (0.5)') axes[0].set_title('Exit Ratio vs. Base "Smallness" (Base_BodyATR)') axes[0].set_xlabel('Base Candle Body / ATR') axes[0].legend() # Exit Body vs. ATR sns.scatterplot(data=df_clean, x='Exit_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[1]) axes[1].axvline(x=1.0, color='gray', linestyle=':', label='1x ATR Reference') axes[1].set_title('Exit Ratio vs. Exit "Strength" (Exit_BodyATR)') axes[1].set_xlabel('Exit Candle Body / ATR') axes[1].legend() plt.tight_layout() plt.show() else: print("⚠️ Missing required columns for ATR analysis")
Result 6:
Cell 7: Clustering Strong Exits
In this final analysis step, we used K-Means clustering to determine whether the strongest exit candles naturally group into distinct categories, such as “moderate” and “strong” impulses. By clustering on both the exit-to-base ratio and the volatility-adjusted exit size (exit body/ATR), we aimed to identify statistically meaningful subgroups within our high-momentum dataset. The elbow method guided the selection of an appropriate number of clusters, while scatter plots and cluster profiles allowed us to visualize and quantify differences between groups. This approach provides a data-driven foundation for defining threshold criteria that can later be implemented in MQL5 for automated detection of valid supply and demand exits, moving beyond visual judgment toward reproducible, algorithmic trading rules.
# %% [markdown] # ## 6. Statistical Clustering: Finding Natural "Impulsive Exit" Groups # **Objective:** Use K-Means clustering to see if our strong candidates (`df_strong`) naturally group into categories like "Moderate" and "Strong" impulses based on their size ratio and volatility-adjusted strength. # %% from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler # --- Step 1: Prepare Features for Clustering --- # We will cluster based on TWO dimensions: # 1. ExitToBaseRatio (How much bigger is the exit?) # 2. Exit_BodyATR (How significant is the exit in current market noise?) print("Preparing features for clustering...") cluster_features = df_strong[['ExitToBaseRatio', 'Exit_BodyATR']].copy() # Check for any missing values (should be none after our cleaning) print(f"Features shape: {cluster_features.shape}") # Standardize the features (critical for K-Means) scaler = StandardScaler() features_scaled = scaler.fit_transform(cluster_features) print("Features scaled (standardized).\n") # --- Step 2: The Elbow Method (Optional but Recommended) --- # Helps suggest a reasonable number of clusters (K). print("Running Elbow Method to suggest optimal K...") inertias = [] K_range = range(1, 8) # Test from 1 to 7 clusters for k in K_range: kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto') # n_init='auto' for newer scikit-learn kmeans.fit(features_scaled) inertias.append(kmeans.inertia_) # Inertia = sum of squared distances to cluster center # Plot the Elbow Curve plt.figure(figsize=(8,5)) plt.plot(K_range, inertias, 'bo-') plt.xlabel('Number of Clusters (K)') plt.ylabel('Inertia (Lower is Better)') plt.title('Elbow Method for Optimal K: Where the line "bends"') plt.grid(True, alpha=0.3) plt.show() print("Inertia values:", [f"{i:.0f}" for i in inertias]) print("Look for a 'kink' or elbow in the plot above. Often K=2 or K=3 works well.\n") # --- Step 3: Apply K-Means Clustering --- # YOU NEED TO CHOOSE K based on the elbow plot and your research goal. # For distinguishing "Strong" vs "Very Strong" impulses, start with K=2 or 3. chosen_k = 3 # <-- CHANGE THIS based on the elbow plot. Try 2 or 3. print(f"Applying K-Means clustering with K = {chosen_k}...") kmeans = KMeans(n_clusters=chosen_k, random_state=42, n_init='auto') cluster_labels = kmeans.fit_predict(features_scaled) # Add the cluster labels back to our main dataframe df_strong['Cluster'] = cluster_labels print(f"Clustering complete. Cluster labels added to 'df_strong'.\n") # --- Step 4: Visualize the Clusters --- print("Visualizing clusters...") plt.figure(figsize=(11, 6)) # Create a scatter plot, coloring points by their assigned cluster scatter = plt.scatter(df_strong['ExitToBaseRatio'], df_strong['Exit_BodyATR'], c=df_strong['Cluster'], cmap='viridis', alpha=0.6, s=30) # s is point size plt.xlabel('Exit-to-Base Ratio', fontsize=12) plt.ylabel('Exit Body / ATR', fontsize=12) plt.title(f'K-Means Clustering of Strong Impulses (K={chosen_k})\nEach color is a distinct group', fontsize=14) # Add a colorbar and grid plt.colorbar(scatter, label='Cluster ID') plt.grid(True, alpha=0.3) plt.show() # --- Step 5: Analyze and Profile Each Cluster --- print("="*60) print("CLUSTER PROFILE ANALYSIS") print("="*60) # 5.1 Basic Counts print("\n📊 1. Number of patterns per cluster:") cluster_counts = df_strong['Cluster'].value_counts().sort_index() for clus_id, count in cluster_counts.items(): percentage = (count / len(df_strong)) * 100 print(f" Cluster {clus_id}: {count:4d} patterns ({percentage:.1f}% of strong candidates)") # 5.2 Mean (Center) of each cluster print("\n📈 2. Cluster Centers (MEAN values):") # Get the original feature means for each cluster cluster_profile = df_strong.groupby('Cluster')[['ExitToBaseRatio', 'Exit_BodyATR', 'Base_BodyATR']].mean().round(3) print(cluster_profile) # 5.3 Key Percentiles within each cluster (more robust than mean) print("\n📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster:") for clus_id in range(chosen_k): cluster_data = df_strong[df_strong['Cluster'] == clus_id] print(f"\n Cluster {clus_id}:") for p in [25, 50, 75, 90]: # 25th, Median (50th), 75th, 90th percentiles value = cluster_data['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") # 5.4 Pattern Type distribution within clusters if 'Pattern' in df_strong.columns: print("\n🧩 4. Pattern Type (Supply/Demand) mix per cluster:") pattern_mix = pd.crosstab(df_strong['Cluster'], df_strong['Pattern'], normalize='index') * 100 print(pattern_mix.round(1).astype(str) + ' %') print("\n" + "="*60) print("ANALYSIS COMPLETE")
Result 7:

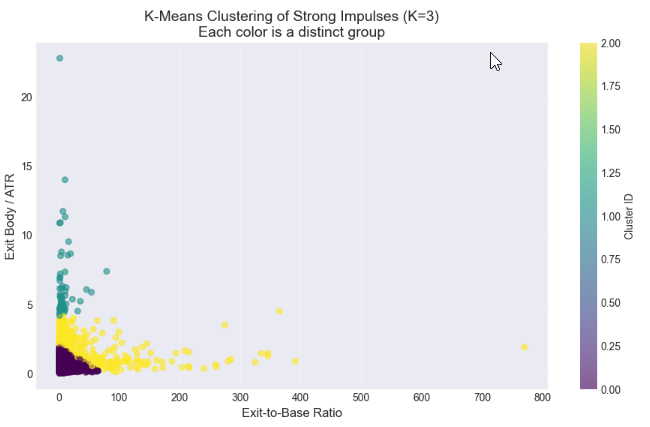
============================================================ CLUSTER PROFILE ANALYSIS ============================================================ 📊 1. Number of patterns per cluster: Cluster 0: 3153 patterns (84.6% of strong candidates) Cluster 1: 62 patterns (1.7% of strong candidates) Cluster 2: 510 patterns (13.7% of strong candidates) 📈 2. Cluster Centers (MEAN values): ExitToBaseRatio Exit_BodyATR Base_BodyATR Cluster 0 5.845 0.670 0.216 1 9.649 6.391 1.541 2 34.023 2.264 0.566 📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster: Cluster 0: 25th percentile: 2.11 50th percentile: 3.21 75th percentile: 6.21 90th percentile: 12.73 Cluster 1: 25th percentile: 2.99 50th percentile: 4.80 75th percentile: 10.63 90th percentile: 19.45 Cluster 2: 25th percentile: 2.75 50th percentile: 5.75 75th percentile: 32.23 90th percentile: 98.36 🧩 4. Pattern Type (Supply/Demand) mix per cluster: Pattern Demand Supply Cluster 0 52.6 % 47.4 % 1 41.9 % 58.1 % 2 48.4 % 51.6 % ============================================================ ANALYSIS COMPLETE
Results
The application of K-means clustering to the filtered dataset of strong candidates (ExitToBaseRatio > 1.5) revealed three distinct behavioral groups. This segmentation moves beyond a monolithic view of "impulse" and provides a statistically grounded taxonomy for market movements originating from a small base.
Cluster 0: The Core Impulsive Exit
This cluster represents the dominant and most relevant pattern, comprising 84.6% of the validated strong candidates.
Statistical Profile: It is characterized by a median ExitToBaseRatio of 3.21, confirming that a meaningful impulsive exit is, on average, more than three times the size of its preceding base—a threshold notably higher than the commonly assumed 2x multiplier. The cluster shows a moderate absolute size with a mean Exit_BodyATR of 0.67 and confirms the defining "small base" with a mean Base_BodyATR of just 0.22.
Interpretation as a trading signal: This cluster constitutes the primary target for a systematic strategy. It represents the classical, high-probability "small base, big exit" pattern where consolidation is followed by a decisive, tradeable move that is significant both relative to the base and within the context of prevailing market volatility.
Cluster 1: High-Volatility Anomalies
A minimal subset (1.7%) of patterns formed this distinct cluster.
Statistical Profile: It is defined by an extreme mean Exit_BodyATR of 6.39 and an unusually large mean Base_BodyATR of 1.54, paired with a high ExitToBaseRatio (mean: 9.65).
Interpretation as a trading signal: This cluster is interpreted as capturing atypical market events, such as news-driven gaps or volatility spikes. The base candle does not represent consolidation, violating the core premise of supply/demand zones. Consequently, patterns in this cluster are considered statistical outliers with poor reliability for a repeatable trading strategy and are explicitly filtered out.
Cluster 2: Extreme-Ratio Outliers
This cluster accounted for 13.7% of strong candidates.
Statistical Profile: It exhibits extraordinarily high ExitToBaseRatio values (median: 5.75, 90th percentile: 98.36) with a moderate mean Exit_BodyATR of 2.26. This results from a minimal mean base size (Base_BodyATR: 0.57).
Interpretation as a trading signal: While the relative ratio is mathematically extreme, the practical trading significance is not proportionally greater than that of Cluster 0. The extreme ratio often stems from a near-zero base size, which may not consistently represent a valid consolidation area. Given its smaller sample size and lower interpretability, this cluster is also deprioritized in favor of the more robust and populous core cluster.
Based on the 3,153 high-quality patterns in Cluster 0, here are our optimized, statistically-derived parameters:
| Parameter | Original (Subjective) Value | Optimized (Data-Driven) Value | Statistical Justification (Based on Cluster 0 Analysis) |
|---|---|---|---|
| MinExitBodyRatio: Exit must be X times bigger than base | 2.0 | 3.0 | The median Exit-to-Base ratio for reliable patterns (Cluster 0) is 3.21. A threshold of 3.0 captures the stronger, more significant half of these impulses. |
| MaxBaseBodyATR: Base candle maximum size vs. volatility | 0.5 | 0.3. | The mean Base_BodyATR in Cluster 0 is 0.22. Tightening this filter to 0.3 ensures the base represents a true consolidation, filtering out larger, more ambiguous candles. |
| MinExitBodyATR: Exit candle minimum significance vs. volatility | not previously defined | 0.5 | The mean Exit_BodyATR for Cluster 0 is 0.67. A minimum threshold of 0.5 ensures the exit has meaningful absolute momentum in the context of current market noise. |
Conclusion
This research successfully completed the critical first half of a quantitative trading development cycle: moving from a visual concept to a statistically validated definition. By applying a rigorous data-collection and machine-learning pipeline to the concept of supply/demand impulsive exits, we have replaced guesswork with evidence.
Our key finding is that the market's most reliable "small base, big exit" pattern—Cluster 0—is best defined by a specific, measurable signature: an exit candle that is typically three times larger than a genuinely small base, while also possessing meaningful absolute momentum relative to market volatility. The derived parameters (MinExitBodyRatio = 3.0, MaxBaseBodyATR = 0.3, MinExitBodyATR = 0.5) are not arbitrary optimizations but the empirical profile of a high-probability event.
This analysis provides the essential blueprint for automation. These three data-driven parameters translate directly into a clear, unambiguous logic block for an MQL5 Expert Advisor.
This function embodies the core trading rule born from our research. It can be integrated into a comprehensive Expert Advisor that scans for two-candle patterns, validates them through this statistical lens, and executes trades with precision. The subsequent steps—adding trade management, risk controls, and multi-timeframe analysis—are engineering tasks built upon this proven foundation.
In the forthcoming publication, we will translate these research results into a fully functional trading system. We will detail:
- The integration of this validation logic into a robust scanning engine.
- The design of the entry, stop-loss, and take-profit mechanism is congruent with the zone-based strategy.
- Backtest results demonstrating the performance impact of using our data-derived parameters versus common default values.
This journey from manual charting to Python analysis, and finally to optimized code in MQL5, demonstrates a modern, evidence-based approach to strategy development. By grounding our algorithms in statistical reality, we aim to create tools that are not just automated, but intelligently automated.
The key lessons from this research are summarized in the table below, along with the supporting attachments. You are welcome to share your thoughts and engage in further discussion in the comments section. Stay tuned for our next publication, where we will build on these findings.
Key Lessons
| Key Lesson | Description: |
|---|---|
| Subjectivity must be quantified | The core challenge in automating price action concepts like "impulsive exits" is their subjective, visual nature. The primary lesson is that any trait judged by the "trader's eye" must be deconstructed into measurable, numerical properties (e.g., candle body ratio, ATR multiple) to become testable and automatable. |
| Data-driven parameters beat conventional wisdom | Common heuristic values (e.g., an exit being twice the size of the base) are often untested. Systematic data collection and analysis revealed that the statistically significant threshold for our instrument was higher, leading to more robust, evidence-based rules (`MinExitBodyRatio = 3.0`). |
| The research pipeline is critical | A structured, two-stage pipeline—MQL5 (data harvesting) → Python (statistical discovery)—is indispensable. It creates a clear, reproducible path from market observation to algorithmic logic, ensuring the final EA is grounded in empirical evidence rather than guesswork. |
| Clustering reveals market microstructure | Applying statistical clustering (K-Means) to the data did not just filter noise; it actively discovered the market's own internal classification of impulses. Identifying the "Core" cluster (Cluster 0) allowed us to define parameters based on the market's most frequent and coherent pattern, not just an arbitrary cutoff. |
| Context is key. | Measuring momentum requires both relative and absolute lenses. A high ExitToBaseRatio means little if the candles are minuscule relative to market volatility (ATR). The need to define a minimum Exit_BodyATR (0.5) emerged directly from this insight, creating a more holistic filter. |
| Bridging research and execution | The ultimate goal of quantitative research is to generate executable code. The final, crucial lesson is translating statistical findings—like the properties of Cluster 0—directly into a clean validation function in MQL5, creating a direct bridge from the research notebook to a live trading chart. |
Attachments
| File name | Description: |
|---|---|
| SD_BaseExit_Research.mq5 | The core MQL5 data collection script. It systematically scans historical price data to harvest instances of the defined two-candle "base-exit" pattern. It calculates key metrics (body sizes in pips, ATR ratios) for each valid pattern and exports them to a structured CSV file, creating the raw dataset for statistical analysis. |
| Supply_and_demand_research.ipynb: | The Jupyter Notebook containing the complete Python analysis workflow. It loads the collected CSV data, performs exploratory data analysis (EDA), visualizes distributions, and applies K-Means clustering. This notebook is the environment where subjective price patterns are translated into objective, statistically-derived trading parameters. |
| SD_BaseExit_XAUUSDr_5.csv | is a sample output file generated by the MQL5 script. Its name follows the pattern [Prefix]_[Symbol]_[Timeframe].csv. This file contains the harvested dataset—thousands of timestamped pattern observations with all calculated metrics—ready for import into the Jupyter Notebook. The script automatically saves files to the MetaTrader 5 terminal's "MQL5/Files" directory (e.g., .../MQL5/Files/), ensuring direct compatibility and a seamless file path for the Python analysis scripts. |
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use