
Market Simulation (Part 22): Getting Started with SQL (V)

Introduction
Hello, and welcome to another article in the series on how to build a replication/simulation system.
In the previous article “Market Simulation (Part 21): First Steps in SQL (IV)”, we explained, in an abstract form, how a relational database can be separated from a non-relational one. But, first of all (and this was the reason for writing the previous article), we tried to show how the working principle of a database can be understood. This was done so that you could understand that, although it may seem reasonable to program certain things, in some cases an existing implementation can be used to achieve the expected result in an application.
This is precisely why we are spending time explaining SQL instead of programming in MQL5. We need to even things out a little so that everyone can understand why we will use SQL when we could create routines and more routines to build some implementation.
In this case, the implementation will allow us to develop a suitable and simple way for the replication/simulation system to have a command mechanism. That is, we need a way to store the order and position-management structure in order to carry out studies in the replication/simulation system. In my opinion, creating many routines for this is completely unnecessary, since MQL5 allows us to use certain SQL support through SQLite. But for those who are eager to keep creating code after code, we will show a better alternative. This is because the time that would be spent implementing, testing, and configuring procedures to create some kind of database can be used more productively on other matters.
Thus, when we actually begin developing the system required so that the replication/simulation system can truly be used as an alternative to demo accounts for studying a strategy, this will be done much faster and without many problems related to proper operation. The reason is that we will use SQL to provide the necessary path for creating the order-management mechanism.
However, what was explained in the previous article is very abstract if we leave everything as it is and remain in the realm of theory. But since this topic may also be of interest in other areas, for example if you want to create an Expert Advisor that uses a database to learn trading, you will need to put into practice what was described in the previous article. An important detail, and I will say it right away: I do not plan (at least at the moment) to explain how to create a database so that an Expert Advisor created in MQL5 begins to learn how to trade a particular symbol.
Explaining such things would also require explaining many other concepts and principles of database operation. But if you really want to learn this, I recommend that you study game algorithms in depth. This is because creating a database is a trivial task, just like programming an Expert Advisor in MQL5. But for the database to be truly useful and for the Expert Advisor to literally learn how to work in the market, you will need to know how to add certain data to the database being created. The easiest way to learn how to create such data is to study game algorithms.
However, there are other, more complex paths, such as studying wave motion or even the concept of heat distribution. But these directions are considerably more difficult, although the results will be very similar to the results of game algorithms.
Let us start by looking in practice at what was explained in the previous article. And since I like to divide everything into topics to make it easier to understand, let us move on to the first topic of this article.
Creating a simple database
We will not dwell on this for long here. This is because this topic has already been covered in several articles discussing SQL. However, since in the previous article we suggested using another program so that the work would be done directly in SQLite, which is the implementation we will use through MQL5, we need to consider some details relating exclusively to the use of SQLite.
The first thing we will look at is the relationship between SQLite data types and the data that we will place in the database. One of the features of SQLite that draws attention when it comes to data types is that it contains fewer types. But this is not a drawback; on the contrary, depending on what we are developing, it is a great advantage, in addition to another benefit that SQLite has over other implementations.
Another advantage I just mentioned is the fact that in SQLite data is dynamic, not static as in many other implementations. “But wait a minute. How can data in SQLite be dynamic? And why is this an advantage?” To understand this, you need to look at the small table below:
| Data type in SQLite | Explanation |
|---|---|
| NULL | Includes any NULL values. |
| INTEGER | Signed integers stored in 1, 2, 3, 4, 6, or 8 bytes, depending on the magnitude of the value. |
| REAL | Real numbers or floating-point values stored as 8-byte floating-point numbers. |
| TEXT | Text strings stored using the database encoding (which may be UTF-8, UTF-16BE, or UTF-16LE). |
| BLOB | Any block of data, with each block stored exactly as it was inserted. |
Please note that this table lists SQLite types. Now, just out of curiosity, let us see how things look in other SQL implementations. We will start with MySQL, whose type table is shown below:
| Data type in MySQL | Explanation |
|---|---|
| TINYINT | A very small integer. The signed value range for this numeric data type is from -128 to 127, and the unsigned range is from 0 to 255. |
| SMALLINT | A small integer. The signed value range for this numeric type is from -32768 to 32767, and the unsigned range is from 0 to 65535. |
| MEDIUMINT | A medium-sized integer. The signed value range for this numeric data type is from -8388608 to 8388607, and the unsigned range is from 0 to 16777215. |
| INTEGER | A normal-size integer. The signed value range for this numeric data type is from -2147483648 to 2147483647, and the unsigned range is from 0 to 4294967295. |
| BIGINT | A large integer. The signed value range for this numeric data type is from -9223372036854775808 to 9223372036854775807, and the unsigned range is from 0 to 18446744073709551615. |
| FLOAT | A small floating-point number (single precision). |
| DOUBLE | A normal-size floating-point number (double precision). |
| DECIMAL | A packed fixed-point number. The display length of records for this data type is defined when the column is created, and each record is adjusted to that length. |
| BOOLEAN | A Boolean value is a data type that can take only two values: “true” or “false”. |
| BIT | A bit-value type for which the number of bits per value can be specified from 1 to 64. |
| DATE | A date represented in the format YYYY-MM-DD. |
| DATETIME | A date and time record showing the date and time in the format YYYY-MM-DD HH:MM:SS. |
| TIMESTAMP | A timestamp indicating the amount of time since the beginning of the Unix epoch (00:00:00 on January 1, 1970). |
| TIME | The time of day displayed in the format HH:MM:SS. |
| YEAR | A year expressed in a 2- or 4-digit format, with 4 digits being the standard. |
| CHAR | A fixed-length string; entries of this type are padded with spaces on the right to match the specified length when stored. |
| VARCHAR | A variable-length string. |
| BINARY | Similar to the char type, but it represents a string of binary bytes of a specified length, rather than a string of nonbinary characters. |
| VARBINARY | Similar to the varchar type, but it represents a variable-length string of binary bytes, rather than a string of nonbinary characters. |
| BLOB | A binary string with a maximum length of 65535 (2^16 - 1) bytes of data. |
| TINYBLOB | A BLOB column with a maximum length of 255 (2^8 - 1) bytes of data. |
| MEDIUMBLOB | A BLOB column with a maximum length of 16777215 (2^24 - 1) bytes of data. |
| LONGBLOB | A BLOB column with a maximum length of 4294967295 (2^32 - 1) bytes of data. |
| TEXT | A string with a maximum length of 65535 (2^16 - 1) characters. |
| TINYTEXT | A text column with a maximum length of 255 (2^8 - 1) characters. |
| MEDIUMTEXT | A text column with a maximum length of 16777215 (2^24 - 1) characters. |
| LONGTEXT | A text column with a maximum length of 4294967295 (2^32 - 1) characters. |
| ENUM | An enumeration is an object in the form of a character string that receives a single value from a list of values declared when the table is created. |
| SET | Similar to an enumeration, it is a string object that may have zero or more values, each of which must be selected from the list of allowed values specified when the table is created. |
Please note that there are many more types, and we must choose the appropriate type correctly to avoid problems in the future. This is also the case in PostgreSQL, which has its own type table, shown below.
| Data types in PostgreSQL | Explanation |
|---|---|
| BIGINT | An 8-byte signed integer. |
| BIGSERIAL | An 8-byte auto-incrementing integer. |
| DOUBLE PRECISION | An 8-byte double-precision floating-point number. |
| INTEGER | A 4-byte signed integer. |
| NUMERIC | A selectable-precision number recommended for use in cases where precision is critical, for example when working with monetary values. |
| REAL | A single-precision floating-point number occupying 4 bytes. |
| SMALLINT | A 2-byte signed integer. |
| SMALLSERIAL | A 2-byte auto-incrementing integer. |
| SERIAL | A 4-byte auto-incrementing integer. |
| CHARACTER | A character string with a specified fixed length. |
| VARCHAR | A character string of variable but limited length. |
| TEXT | A character string of variable and unlimited length. |
| DATE | A calendar date consisting of day, month, and year. |
| INTERVAL | A time interval. |
| TIME WITHOUT TIME ZONE | The time of day, without specifying a time zone. |
| TIME WITH TIME ZONE | The time of day, including a time zone. |
| TIMESTAMP WITHOUT TIME ZONE | A date and time without specifying a time zone. |
| TIMESTAMP WITH TIME ZONE | A date and time including a time zone. |
| BOX | A rectangular “box” on a plane. |
| CIRCLE | A circle on a plane. |
| LINE | An infinite line on a plane. |
| LSEG | A line segment on a plane. |
| PATH | A geometric line on a plane. |
| POINT | A geometric point on a plane. |
| POLYGON | A closed geometric path on a plane. |
| CIDR | An IPv4 or IPv6 network address. |
| INET | An IPv4 or IPv6 host address. |
| MACADDR | A Media Access Control (MAC) address. |
| BIT | A fixed-length bit string. |
| BIT VARYING | A variable-length bit string. |
| TSQUERY | A search string for text. |
| TSVECTOR | A document for text search. |
| JSON | JSON text data. |
| JSONB | Decomposed binary JSON data. |
| BOOLEAN | A logical value representing “true” or “false”. |
| BYTEA | Short for “array of bytes”; this type is used for binary data. |
| MONEY | A currency amount. |
| PG_LSN | A PostgreSQL log sequence number. |
| TXID_SNAPSHOT | A user-level transaction ID snapshot. |
| UUID | A universally unique ID. |
| XML | XML data. |
Please note that PostgreSQL offers even more types. One might think: But all of this can turn into a nightmare for anyone who wants to use SQL. But that is not exactly true. SQL manages to adapt to our needs. This is necessary so that the database can be used in another application that is also created in SQL. The fact that we have more or fewer types makes choosing a type more or less difficult. This is because, if we choose the wrong type, when we need to change it, the entire database will have to be rebuilt. Although this is a fairly simple task, since we use scripts created specifically for this purpose, it can be quite difficult for someone who wants to learn SQL and does not know where to begin.
However, looking at these tables, it immediately becomes clear that, because SQLite uses few types, the types it contains require less maintenance effort. But this raises other issues that are not relevant here. What really interests us at this moment is that, having fewer types, SQLite has dynamic types; that is, they grow depending on the needs imposed by the information being stored.
But how is this applied in practice? To understand this, we need to create two different databases. One will be created using MySQL, and the other will be created using SQLite. Both use SQL as the base language. Let us see how to do this. The animation below shows how this process is performed in MySQL.
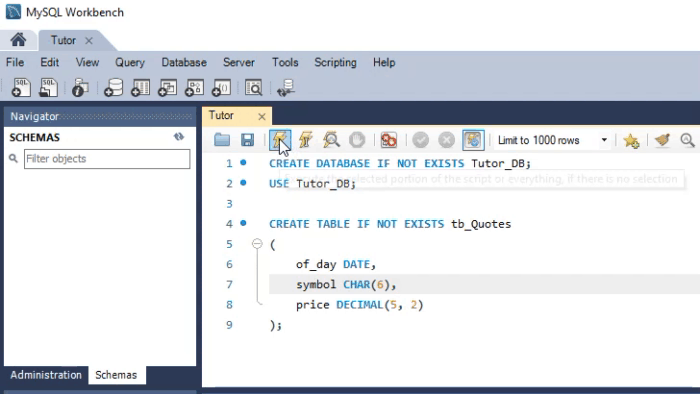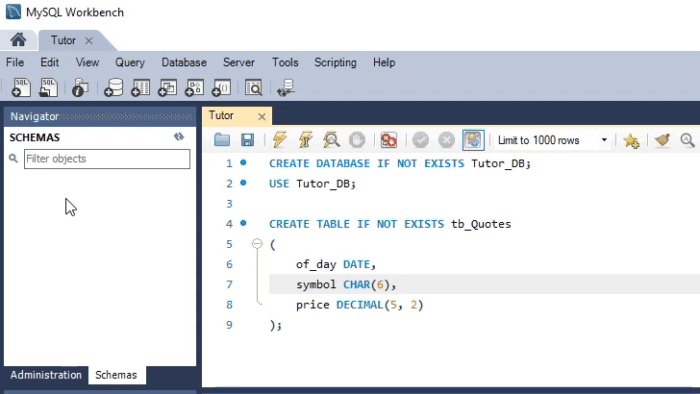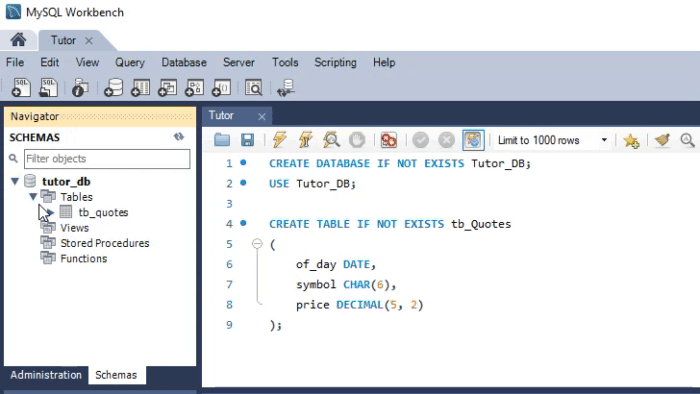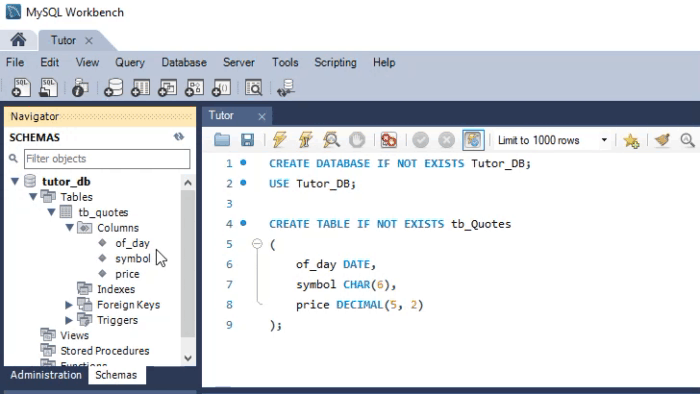
Please take a closer look at the types being used. The animation you see below performs almost the same procedure, only in SQLite.
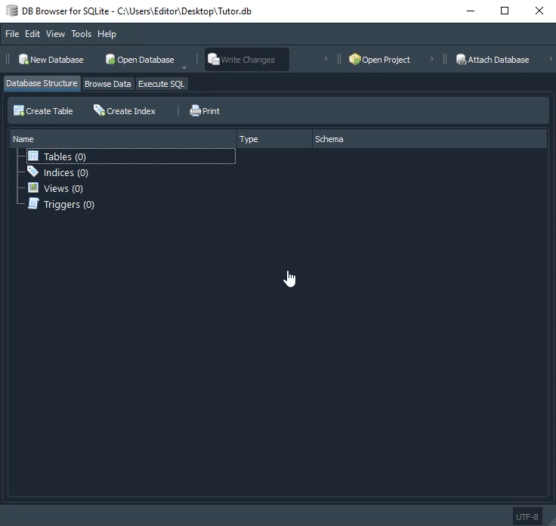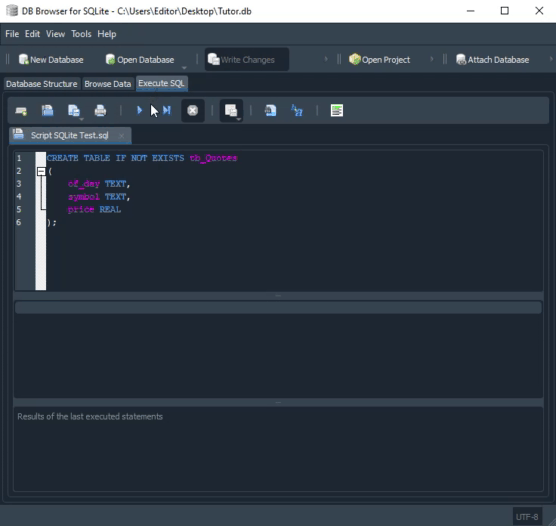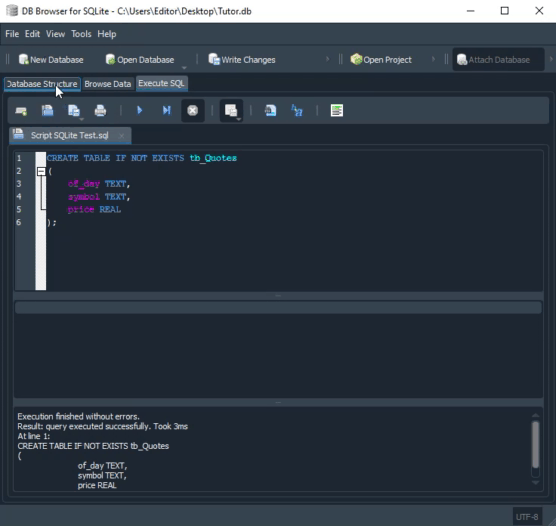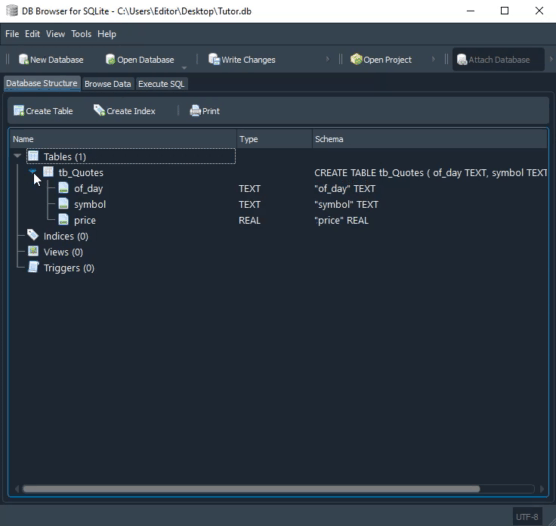
Pay attention to the types defined in the second animation. Although in the MySQL animation the script creates a database, this does not happen in SQLite. In this case, we must already have a database created and opened in DB Browser. Perhaps you are thinking: “Okay, the types are different, so the code will not work across both.” If you think so, it is because you came across this article by accident. I recommend reading the previous articles, where we showed how to use the same code in both MySQL and SQLite. Only in that case we used MetaEditor to run SQLite.
However, in this case we are interested in the fact that, in the MySQL code, when creating columns, we define their size. In SQLite we did not do that. Such dynamism can also be implemented in MySQL. But this is not something commonly found in implementations other than SQLite. The reason is that SQL programmers often prefer to define the type or even the size of fields in order to optimize certain characteristics of the database. Therefore, we have more work maintaining databases in different implementations.
But a question may arise here: can MySQL understand columns created by SQLite, or vice versa? You do not need to worry about this. Yes, any SQL implementation can understand the dimensionality used in the columns. For this reason, we showed the tables above to make it easier to understand that there is a certain overlap between data types. However, depending on the implementation, the programmer may decide to use one particular type or another in order to optimize certain aspects of the database.
Good. Now that we have presented the necessary elements, let us look in practice at how primary and foreign keys fit into this story.
Primary and foreign keys in practice
In the animations above, you can see that we are creating a very simple database. Its purpose is to store the symbol name together with the quote and the date when the quote was obtained. In practice, however, a database programmer would hardly create a database in this way. This is because one might want to add more than one symbol or additional information to the database itself, such as the trading name of the company whose symbol is shown in the table.
But it may also happen that a symbol changes its name. Although this is quite rare, it still occurs from time to time. We see an example of this on B3, where for some time the company VIA VAREJO had the ticker: VVAR3. For some reason, the symbol changed its ticker to VIIA3. Now imagine all the work that would have to be done to change the symbol name from VVAR3 to VIIA3 in every past record. But all of this could have been done very easily if the foundation had been built differently.
Although this example is very simple, it is practical enough to understand much more. Many people think that creating and maintaining a database is a simple task, but when they actually set out to do it, they end up making a bunch of mistakes that later require enormous effort to fix.
Let us first see how to create a basic solution using SQLite. To simplify the task and the explanation, you can look at the SQL script code just below. It will use what we are going to implement.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. -- symbol TEXT, 13. price NUMERIC, 14. fk_id INTEGER, 15. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 16. );
Code in SQLite
Please note that this code already contains some elements that DO NOT belong to SQL. In this case, we are talking about line 01, where we use an internal SQLite instruction. But why do we use this instruction here? The reason is that the SQLite documentation, which we left at the end of this article in the references section, states that before version 3.6.19 SQLite did not use foreign keys by default, so they need to be specified. Otherwise, it will not use them. Although the mentioned version is quite old, someone may still be using it for some reason. Apart from this fact, let us check what happens in this script. Remember that, for the script to execute correctly in SQLite, a database must be open in DB Browser.
In line 03 we create (if it does not exist) a table named tb_Symbols. In this table, in line 05, we define the primary key. In line 06 we define the symbol name. For now, we do not limit the number of records that this table will contain. The reason is that we still want to show how we arrived at a much more suitable database construction model. Thus, although the id value is always unique, the same symbol can be defined in several ids. But this is very easy to solve. However, before seeing how we will do this, let us first understand how the keys work here.
After creating the tb_Symbols table, we can modify (or, more precisely, create) a new table. It starts in line 09, where we indicate that we want to create the tb_Quotes table. Please note that line 12 is the original one, as shown in the animation above. However, unlike what was shown in the animation, here it appears as a comment. The reason is that the symbol name will no longer be present in this table. Because of this, we added lines 14 and 15 to the code. Now pay very close attention to the explanation; this is important. In line 14 we define a value that must have the same type as the primary key of the tb_Symbols table. In some cases, a programmer using SQLite does not define the type, leaving it to the program. Since we want to maintain a certain standard in the code, we will define the type.
This will be our foreign key in the tb_Quotes table. And now comes the truly important point in the script shown above. In line 15 we indicate what the foreign key is and what it will refer to. Please note that we need to specify the table name, as well as the name of the key or column that will be used. This key originates in the tb_Symbols table.
Thus, we create a referential, or relational, system in which quote information is separated from the symbol name. However, this separation is not real, because there is a relationship between the quote record and the symbol name. And this relationship arises precisely through the creation of primary and foreign keys. If you understand this relationship, you will understand that a real database can be created by linking different pieces of information together in such a way that they have a connection, while at the same time allowing us to add more or less data to the same record. All of this with minimal cost for maintaining or modifying the original database.
The code above can be written as shown below, which will be much closer to a possible real situation. Although we still have not solved the issue of the symbol name being repeated in more than one place in the tb_Symbols table.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. price NUMERIC, 13. fk_id INTEGER REFERENCES tb_Symbol (id) 14. );
Code in SQLite
Please note that we have now made a small change. It is on line 13 and has the same purpose: to link the tb_Quotes table with the tb_Symbols table using a foreign key. One more point: although we said that we link tables, it would be more correct to say that we link a record from the tb_Quotes table with another record from the tb_Symbols table. Good, now pay attention: it does not matter what we store in each of the tables. We can add more or fewer fields or data columns to the tables, and this will not directly affect the search and the results we get when searching.
But, depending on the need, additional information can be added to one of the tables. At the same time, all other tables linked to this table will also benefit from this, but we will not have to rewrite the database completely. You may not realize the full scale of this fact. But once you start using SQL, you will soon understand that it helps a great deal when we want to expand a database or create a relational system between different types of information.
All right, but how can we solve the problem of possible duplicate data in the database? This is very simple. When creating the table, we specify that the column must not contain certain values, or that the values cannot be duplicated. For example, let us modify the code shown above so that there are no null values in the columns. But we also do not want the symbol name to appear in more than one record in the same column. Thus, the corrected code looks like this:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY NOT NULL, 06. symbol TEXT NOT NULL UNIQUE 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT NOT NULL, 12. price NUMERIC NOT NULL, 13. fk_id INTEGER NOT NULL, 14. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 15. );
Code in SQLite
Now, if we run this script, we will notice that both tables are created as expected and as shown in the explanation above. However, unlike what happened before, we will now have no duplicate records. If we try to duplicate any record, SQL will not allow it. Likewise, our table will no longer contain values equal to null. Please note that the code for this is very simple and clear.
How to understand the last script
Before moving into new areas, it is very important to understand how the last script works. We really need to try to understand what is happening here. Otherwise we will be completely lost. Thus, after executing the last SQL script code shown above, in DB Browser we will get the following result:
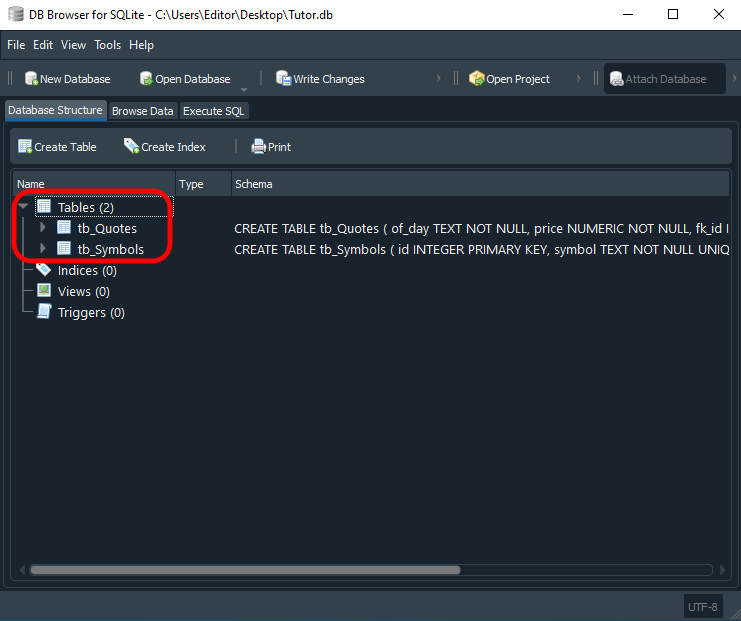
Note that we have highlighted the two tables shown here. But how do we actually use them? It may seem like something complex and possible only for great masters of computer technology. Not at all. Using this schema is easier than going forward. We have already shown how to add information to a table using a script. This was in the previous articles about SQL. Here we will use something very similar to what we have already seen.
To see how everything happens, let us add some data only as an example of interaction with this type of modeling. And since we have also shown the basic selection command, we can use it here as well. But first we will add a few records to our database. Let us replace the script above with another one that is slightly different from it.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes;
Script in SQLite
Perhaps you are looking at this and thinking: Wow, what complicated code; I will never be able to understand it. I think I will give up and do everything differently. But I tell you: are you going to give up now? Right now, when everything has become more interesting? After all, there is nothing complicated in the code above. Absolutely everything it contains has already been explained at this initial stage, where we provided some explanations on how to use the SQL language.
Perhaps the only part that may cause you some confusion is lines 03 and 04, where we tell SQL that, if the tb_Quotes and tb_Symbols tables exist, they should be removed. But why are we removing the tables before we even have time to use them? And the main question: why remove them? Could we not simply keep them and add new data to the database?
There is one answer to all these questions. We need to delete the tables for the simple reason that between lines 20 and 29 we will add values to them. However, each time this same script is run, SQL will report an error when adding values to the tables. The reason for this error is precisely the fact that we cannot duplicate certain fields in the database.
After running this script, we will get the following result:
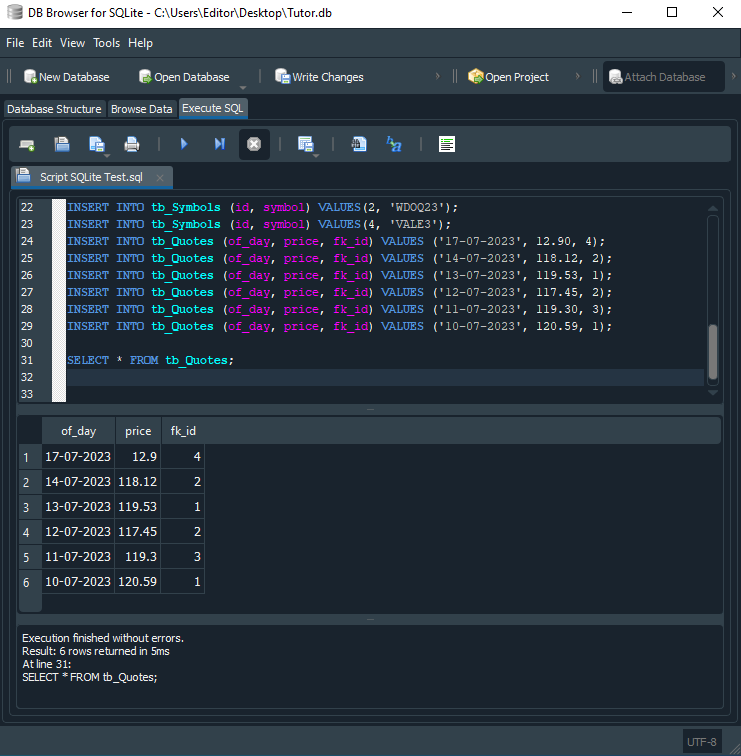
Please note that in the result we get exactly the contents of the tb_Quotes table. This is because, in line 31, we ask SQL to give us this information. But looking at it can be a little discouraging. This is because, if we have a very large database with quotes for various symbols, it is difficult to understand where each of them is, since the query result does not include the symbol name or any other information that would help us better understand what we are looking for in the database. But soon we will see how this can be improved by making a small change to the code in line 31, where we use the SELECT command.
Final thoughts
Before you give up and decide to abandon learning SQL, allow me to remind you, dear readers, that here we are still using only the most basic elements. We have not yet looked at some of SQL's capabilities. Once you understand them, you will see that SQL is far more practical than it seems. Although, most likely, we will eventually change the direction of what we are building, because the creation process is dynamic. We will show a little more about creating different things in SQL, because this is truly important and useful for you. Simply thinking that you are more capable than an entire community of programmers and developers will only lead to wasted time and opportunities. Do not worry, because what comes next will be even more interesting.
As I said, I am still not sure whether I will use SQLite or another SQL implementation. This is because the development of the elements needed for the replication/simulation system is a completely dynamic process. We have not yet decided in which direction we will actually move next. But regardless of how events develop in the next stages, when we return to MQL5, we will certainly use SQL to solve various tasks. I am not going to create any routine procedures to perform what SQL allows us to do and helps us with. But how we will use SQL in practice has not yet been finally determined.
In the next article, we will look at how to perform some other actions in SQL. After all, things are really starting to gain momentum now, and what we are going to examine and explain has already been almost completely determined. However, I want to emphasize that these articles are not an SQL course. I simply want to show a few points that may be useful in the future, because there is no sense in using MQL5 or any other language for what SQL itself can do for us. And we are not talking only about creating and maintaining a database. We are talking about programming as such.
Many people know only a few SQL commands, but forget them or do not show enough interest in deepening their knowledge in this area, thereby missing the opportunity to use a genuinely powerful tool, since many of the procedures that some people create in a language integrated with SQL can be performed directly in SQL. And knowing how to do such things will help a lot in your developments. So try to deepen your knowledge of this topic. Use these articles only as a guide: do not consider them the only source of information or something definitive. A hug to everyone; see you in the next article.
| File | Description |
|---|---|
| Experts\Expert Advisor.mq5 | Demonstrates interaction between Chart Trade and the Expert Advisor (Mouse Study is required for interaction). |
| Indicators\Chart Trade.mq5 | Creates a window for configuring the order to be sent (Mouse Study is required for interaction). |
| Indicators\Market Replay.mq5 | Creates controls for interaction with the replication/simulation service (Mouse Study is required for interaction). |
| Indicators\Mouse Study.mq5 | Provides interaction between graphical controls and the user (necessary both for the replication/simulation system and in the real market). |
| Services\Market Replay.mq5 | Creates and maintains the market replication/simulation service (the main file of the entire system). |
| Code VS C++\Servidor.cpp | Creates and maintains a server socket developed in C++ (MiniChat version). |
| Code in Python\Server.py | Creates and maintains a socket in Python for communication between MetaTrader 5 and Excel. |
| Indicators\Mini Chat.mq5 | Allows a mini chat to be implemented through an indicator (requires the use of the server). |
| Experts\Mini Chat.mq5 | Allows a mini chat to be implemented using an Expert Advisor (requires the server). |
| Scripts\SQLite.mq5 | Demonstrates the use of an SQL script through MQL5. |
| Files\Script 01.sql | Demonstrates the creation of a simple table with a foreign key. |
| Files\Script 02.sql | Shows how to add values to a table. |
Reference
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/12986
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use