
価格変動の角度分析:金融市場予測のためのハイブリッドモデル

経験豊富なクライマーが山の麓に立ち、登攀を開始する前にその斜面を注意深く観察している状況を想像してください。そこに見えているのは何でしょうか。単なる岩や段差の集合ではなく、ルートの幾何構造です。すなわち、登坂角度、斜面の勾配、稜線の曲線です。これらの地形的特徴が頂上へのルートの難易度を決定します。
金融市場もこれと非常に類似しています。価格チャートは独自の地形を形成し、ピーク、谷、緩やかな斜面、急峻な崖を作ります。登山者が山を幾何学的に読み取るように、トレーダーは価格変動の角度を直感的に捉えます。しかし、この直感を厳密な科学にできるとしたらどうでしょうか。価格変動の角度が単なる視覚的イメージではなく、将来の市場動向を示す数学的に意味のある指標だとしたらどうでしょうか。
アルゴトレーダーとして静かな部屋で考えていたとき、トレーディングプラットフォームの騒音から離れて、この問いを自分に投げかけました。その答えは、市場の本質に対する理解を変えるほど興味深いものでした。
価格変動の構造
毎日、為替、株式、先物のチャート上に何千本ものローソク足が形成されます。それらはパターンを構成し、トレンドを作り、レジスタンスとサポートを形成します。しかしその背後には、ほとんど意識されない数学的構造があります。それが、連続する価格点間の角度です。
EURUSDチャートを見てください。そこに見えるのは何でしょうか。ラインやバーでしょうか。ここで、隣接する2点間の各セグメントが水平軸に対して特定の角度を持つと考えてください。この角度には正確な数学的値があります。正の角度は上昇を意味し、負の角度は下降を意味します。角度が大きいほど、価格変動は急になります。
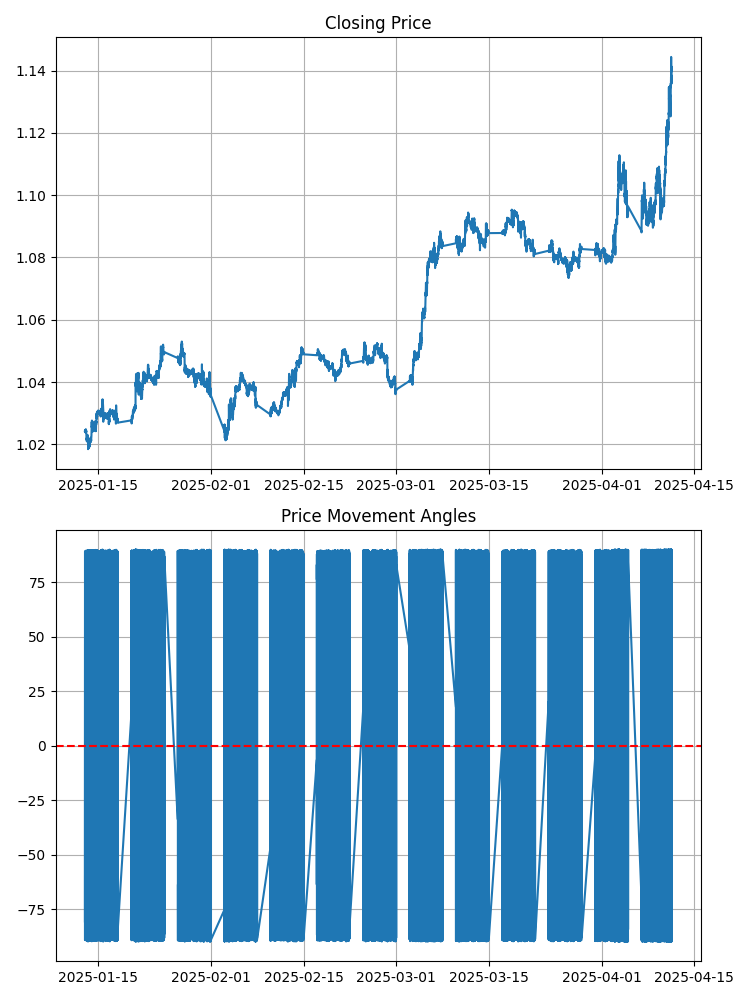
単純に見えますが、この単純さの中に深さがあります。角度は同一ではなく、それぞれがパターンを形成します。それは独自のリズムのようなものです。そしてこのリズムが、将来の市場動向の手がかりを含む可能性があります。
トレーダーは長年トレンドラインの傾きを分析してきましたが、それは粗い近似です。ここで扱っているのは、すべての隣接する価格点間の厳密な数学的角度です。これは、山のラフスケッチと、各斜面の角度が正確に定義された地形図の違いに相当します。
ギャンの角度分析:古典から革新へ
価格変動を角度で分析するという考え方は新しいものではありません。その起源は、伝説的なトレーダー兼アナリストであるウィリアム・デルバート・ギャンの研究にあります。彼は20世紀初頭の時点で、金融市場に対する角度解析のシステムを提案しました。これに基づくインジケーターも作成されています。
私はこのギャンの概念に初めて触れたのは、テクニカル分析の古典的文献を学んでいた数年前のことでした。そのアイデア自体は非常に興味深いものでした。ギャンは、価格と時間の間には数学的関係が存在し、それがチャート上の特定の線の角度として表現できると主張していました。彼はこれらの角度にほぼ神秘的な予測力があると考え、「ギャン角」と呼ばれる体系を構築しました。これは、チャート上の重要なポイントから特定の角度で引かれるラインです。
しかし、ギャンの古典的アプローチには2つの大きな問題がありました。第一に、過度に主観的であり、異なる分析者が同じ角度構造を全く異なる形で解釈し得ることです。第二に、このシステムは一定のスケールを持つ紙のチャートを前提としており、現代のデジタル解析への適用が困難でした。
そこで私は疑問を持ちました。ギャンの基本概念は正しかったものの、単に当時の計算能力が不足していただけではないか。角度の重要性に関する直感は正しいが、それにはより厳密な数学的アプローチが必要なのではないか。
そのヒントは、素粒子物理学に関するドキュメンタリーを見ていたときに偶然得られました。科学者たちは、粒子同士の衝突後の偏向角を測定することで、その軌跡を解析していました。その角度には、粒子の性質や作用する力に関する重要な情報が含まれていました。
このとき私は気付きました。市場の価格変動もまた一種の軌跡であり、市場参加者同士の力関係の結果ではないかと。であれば、ギャンのように主観的にラインを引くのではなく、価格チャート上のすべての連続する2点間の角度を正確に測定すべきではないか。そしてそれを機械学習による厳密な数理解析に落とし込めないか。
古典的なギャン手法では、特定の重要なポイントから線を引いて角度を構築しますが、このアプローチでは、すべての隣接する価格点間の角度を測定します。これにより、連続的な角度データ、いわば市場の心電図のようなデータが得られます。このとき重要だったのはスケーリング問題の解決であり、チャート上の時間軸と価格軸は異なる単位を持っているため、そのままでは角度計算が成立しません。
この解決策は、各変数の変動レンジに基づいて軸を正規化し、同じスケールへ正規化することでした。これにより、絶対的な価格水準や時間間隔に依存しない、数学的に正しい角度を得ることが可能になりました。
ギャンが幾何学的構成と直感に基づいて分析をおこなっていたのに対し、私は客観的な数学手法と機械学習アルゴリズムに依拠することにしました。「45度」や「26.25度」といった“特別な角度”(ギャンが好んだ角度)を探すのではなく、どの角度パターンが将来の価格変動予測に最も有意かをアルゴリズムに決定させるというアプローチです。
興味深いことに、結果の分析では、アルゴリズムが検出したいくつかのパターンがギャンの観察と一致することが確認されました。ただしそれらは統計的裏付けと厳密な数学的形式を伴って現れています。たとえばギャンは1:1(45度)ラインを重視していましたが、本モデルでも、ゼロ付近から正の方向へ角度が変化し、45度近傍に近づくケースが強いトレンド発生に先行することが示されました。
このように、ギャンの古典的アイデアを基礎としつつ、それを現代数学と機械学習の枠組みで再構成することで、本稿で述べる角度分析手法が生まれました。この手法は、価格と時間の交差点における幾何学的パターンを探求するというギャンの哲学的本質を保持しながら、それを経験則の世界から厳密な科学へと昇華しています。
おそらくギャン自身も、自身のアイデアが当時存在しなかった技術によって発展する様子を見れば満足したのではないでしょうか。アイザック・ニュートンの言葉にあるように、「自分が遠くを見渡せたのは巨人の肩の上に立っていたからだ」。現代の角度分析はさらにその先へ進みますが、その出発点にはテクニカル分析の巨人の思想があります。
角度のダンス
角度を正確に測定する手法を手にしたことで、私たちは次の研究段階である観察へと進みました。数ヶ月にわたり、EURUSDチャート上で角度の動きを観察し、一つ一つの変化や転換点を記録しました。
そして徐々に、データの混沌の中からパターンが現れ始めました。角度はランダムに動いているわけではありませんでした。それらは、特定の価格変動に先行して繰り返し現れるシーケンスを形成していました。大きな価格上昇の前には、ある特定の角度の流れが頻繁に観測されることが分かりました。まず小さな負の角度が現れ、次に中立的な角度へ移行し、最後に振幅を増しながら正の角度が連続する、という構造です。
それは子供のおもちゃである独楽を思い起こさせました。上向きに勢いよく動き出す前に、わずかに揺れながら力を蓄えるような挙動です。市場も同様の原理で動いているように見えます。急激な動きの前に「揺らぎ」が生じ、その結果として特徴的な角度シーケンスが形成されます。
しかし、どれほど興味深い観察であっても、それだけでは信頼できるトレーディング戦略は構築できませんでした。仮説を数学的に厳密な形で検証する必要がありました。そこで機械学習が登場します。複雑なパターンを解読するための重要な補助手段です。
アイデアからコードへ:角度アナライザーの構築
理論は重要ですが、実装がなければそれは美しい言葉のままに留まります。まず必要だったのは市場データの取得と、その扱い方の確立でした。ツールとしてはPythonとMetaTrader 5ライブラリを選択しました。これにより、トレーディングプラットフォームから直接データを取得できます。
以下は価格履歴を読み込むコードです。
import MetaTrader5 as mt5 from datetime import datetime, timedelta import pandas as pd import numpy as np import math def get_mt5_data(symbol='EURUSD', timeframe=mt5.TIMEFRAME_M5, days=60): if not mt5.initialize(): print(f"Initialization error MT5: {mt5.last_error()}") return None # Determine period for downloading data start_date = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_range(symbol, timeframe, start_date, datetime.now()) mt5.shutdown() # Transform data into convenient format df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return df
この小さなコードは市場データへの入り口です。MetaTrader 5に接続し、指定した日数分の価格履歴をダウンロードし、分析しやすい形式へ変換します。
次に必要なのは、連続する価格点間の角度計算です。しかしここで問題が発生します。時間軸と価格軸は本質的にスケールが異なるため、そのままではチャート上の角度は意味を持ちません。単純に座標値をそのまま使うと、角度は歪んだものになります。
解決策は軸の正規化です。時間と価格を同じスケールへ正規化する必要があります。
def calculate_angle(p1, p2): # p1 и p2 - tuples (time_normalized, price) x1, y1 = p1 x2, y2 = p2 # Handling vertical lines if x2 - x1 == 0: return 90 if y2 > y1 else -90 # Calculating an angle in radians and convert it to degrees angle_rad = math.atan2(y2 - y1, x2 - x1) angle_deg = math.degrees(angle_rad) return angle_deg def create_angular_features(df): # Create copy DataFrame angular_df = df.copy() # Normalizing time series for correct calculation of angles angular_df['time_num'] = (angular_df['time'] - angular_df['time'].min()).dt.total_seconds() # Find ranges for normalization time_range = angular_df['time_num'].max() - angular_df['time_num'].min() price_range = angular_df['close'].max() - angular_df['close'].min() # Normalization for comparable scales scale_factor = price_range / time_range angular_df['time_scaled'] = angular_df['time_num'] * scale_factor # Calculate angles between sequential points angles = [] angles.append(np.nan) # Angle not defined for the first point for i in range(1, len(angular_df)): current_point = (angular_df['time_scaled'].iloc[i], angular_df['close'].iloc[i]) prev_point = (angular_df['time_scaled'].iloc[i-1], angular_df['close'].iloc[i-1]) angle = calculate_angle(prev_point, current_point) angles.append(angle) angular_df['angle'] = angles return angular_df
これらの関数が本手法の中核です。前者は2点間の角度を計算し、後者はデータ全体を整形して全時系列に対して角度を付与します。結果として、各時点は「価格変化の傾き」という数学的特徴量を持つことになります。
私たちが知りたいのは過去だけではありません。将来の価格変動との関係を理解する必要があります。そのため、一定期間後の価格変化情報をデータに付加します。
def add_future_price_info(angular_df, prediction_period=24): # Add future price direction future_directions = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): # 1 = growth, 0 = fall future_dir = 1 if angular_df['close'].iloc[i + prediction_period] > angular_df['close'].iloc[i] else 0 future_directions.append(future_dir) else: future_directions.append(np.nan) angular_df['future_direction'] = future_directions # Calculate magnitude of the future change (in percent) future_changes = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): pct_change = (angular_df['close'].iloc[i + prediction_period] - angular_df['close'].iloc[i]) / angular_df['close'].iloc[i] * 100 future_changes.append(pct_change) else: future_changes.append(np.nan) angular_df['future_change_pct'] = future_changes return angular_df
これにより、各時点について角度情報だけでなく、指定バー後に価格がどう変化したかも持つデータセットが構築されます。これは機械学習モデルの学習に適した構造です。
ただし、角度単体では不十分です。重要なのは角度の「列」、すなわちシーケンス構造です。角度のパターン、傾向、統計的特性が本質的な役割を持ちます。そのため各時点に対して、直近の角度挙動を表す豊富な特徴量を構築します。
def prepare_features(angular_df, lookback=15): features = [] targets_class = [] # For classification (direction) targets_reg = [] # For regression (percent change) # Discard strings with NaN filtered_df = angular_df.dropna(subset=['angle', 'future_direction', 'future_change_pct']) # Check if there is enough data if len(filtered_df) <= lookback: print("Not enough data for analysis") return None, None, None for i in range(lookback, len(filtered_df)): # Get latest lookback of bars window = filtered_df.iloc[i-lookback:i] # Take last angles as a sequence feature_dict = { f'angle_{j}': window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics of angles feature_dict.update({ 'angle_mean': window['angle'].mean(), 'angle_std': window['angle'].std(), 'angle_min': window['angle'].min(), 'angle_max': window['angle'].max(), 'angle_last': window['angle'].iloc[-1], 'angle_last_3_mean': window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (window['angle'] > 0).mean(), 'current_price': window['close'].iloc[-1], 'price_std': window['close'].std(), 'price_change_pct': (window['close'].iloc[-1] - window['close'].iloc[0]) / window['close'].iloc[0] * 100, 'high_low_range': (window['high'].max() - window['low'].min()) / window['close'].iloc[-1] * 100, 'last_tick_volume': window['tick_volume'].iloc[-1], 'avg_tick_volume': window['tick_volume'].mean(), 'tick_volume_ratio': window['tick_volume'].iloc[-1] / window['tick_volume'].mean() if window['tick_volume'].mean() > 0 else 1, }) features.append(feature_dict) targets_class.append(filtered_df.iloc[i]['future_direction']) targets_reg.append(filtered_df.iloc[i]['future_change_pct']) return pd.DataFrame(features), np.array(targets_class), np.array(targets_reg)
この特徴量設計により、単純な時系列データは機械学習用の高次元データセットへと変換されます。各時点は30以上の特徴量を持ち、直近数バーにおける角度挙動の「プロファイル」として表現されます。この角度プロファイルが、モデルへの入力データとなります。
機械学習が角度の秘密を解き明かす
データと特徴量が揃ったので、それらの中からパターンを抽出するモデルを学習させます。私たちはCatBoostライブラリを採用しました。これは時系列データに対して特に高い性能を持つ現代的な勾配ブースティングアルゴリズムです。
本アプローチの特徴は、1つではなく2つのモデルを学習させる点にあります。
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, mean_squared_error def train_hybrid_model(X, y_class, y_reg, test_size=0.3): # Splitting data into training and test X_train, X_test, y_class_train, y_class_test, y_reg_train, y_reg_test = train_test_split( X, y_class, y_reg, test_size=test_size, random_state=42, shuffle=True ) # Parameters for classification model params_class = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'Logloss', 'random_seed': 42, 'verbose': False } # Parameters for regression model params_reg = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'RMSE', 'random_seed': 42, 'verbose': False } # Training classification model (directional prediction) print("Training classification model...") model_class = CatBoostClassifier(**params_class) model_class.fit(X_train, y_class_train, eval_set=(X_test, y_class_test), early_stopping_rounds=50, verbose=False) # Checking classification accuracy y_class_pred = model_class.predict(X_test) accuracy = accuracy_score(y_class_test, y_class_pred) print(f"Classification accuracy: {accuracy:.4f} ({accuracy*100:.2f}%)") # Training regression model (forecast of percentage change) print("\nTraining regression model...") model_reg = CatBoostRegressor(**params_reg) model_reg.fit(X_train, y_reg_train, eval_set=(X_test, y_reg_test), early_stopping_rounds=50, verbose=False) # Checking regression accuracy y_reg_pred = model_reg.predict(X_test) rmse = np.sqrt(mean_squared_error(y_reg_test, y_reg_pred)) print(f"RMSE regressions: {rmse:.4f}") # Print importance of features print("\nImportance of features for classification:") feature_importance = model_class.get_feature_importance(prettified=True) print(feature_importance.head(5)) return model_class, model_reg
最初のモデル(分類器)は価格の方向、すなわち上昇か下降かを予測します。2つ目のモデル(回帰器)は、その変動の大きさをパーセンテージで推定します。これらを組み合わせることで、将来の価格変動に対する完全な予測を構成します。
学習後、これらのモデルを用いてリアルタイム予測をおこなうことができます。
def predict_future_movement(model_class, model_reg, angular_df, lookback=15): # Get latest data if len(angular_df) < lookback: print("Not enough data for forecast") return None # Get latest lookback of bars last_window = angular_df.tail(lookback) # Form features as during training feature_dict = { f'angle_{j}': last_window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics feature_dict.update({ 'angle_mean': last_window['angle'].mean(), 'angle_std': last_window['angle'].std(), 'angle_min': last_window['angle'].min(), 'angle_max': last_window['angle'].max(), 'angle_last': last_window['angle'].iloc[-1], 'angle_last_3_mean': last_window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': last_window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': last_window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (last_window['angle'] > 0).mean(), 'current_price': last_window['close'].iloc[-1], 'price_std': last_window['close'].std(), 'price_change_pct': (last_window['close'].iloc[-1] - last_window['close'].iloc[0]) / last_window['close'].iloc[0] * 100, 'high_low_range': (last_window['high'].max() - last_window['low'].min()) / last_window['close'].iloc[-1] * 100, 'last_tick_volume': last_window['tick_volume'].iloc[-1], 'avg_tick_volume': last_window['tick_volume'].mean(), 'tick_volume_ratio': last_window['tick_volume'].iloc[-1] / last_window['tick_volume'].mean() if last_window['tick_volume'].mean() > 0 else 1, }) # Convert to format for model X_pred = pd.DataFrame([feature_dict]) # Model predictions direction_proba = model_class.predict_proba(X_pred)[0] direction = model_class.predict(X_pred)[0] change_pct = model_reg.predict(X_pred)[0] # Form result result = { 'direction': 'UP' if direction == 1 else 'DOWN', 'probability': direction_proba[int(direction)], 'change_pct': change_pct, 'current_price': last_window['close'].iloc[-1], 'predicted_price': last_window['close'].iloc[-1] * (1 + change_pct/100), } # Form signal if direction == 1 and direction_proba[1] > 0.7 and change_pct > 0.5: result['signal'] = 'STRONG_BUY' elif direction == 1 and direction_proba[1] > 0.6: result['signal'] = 'BUY' elif direction == 0 and direction_proba[0] > 0.7 and change_pct < -0.5: result['signal'] = 'STRONG_SELL' elif direction == 0 and direction_proba[0] > 0.6: result['signal'] = 'SELL' else: result['signal'] = 'NEUTRAL' return result
この関数は最新データを解析し、将来の価格変動予測を出力します。単なる方向予測だけでなく、その確率と変動幅も推定し、具体的な売買シグナルとしてまとめます。
戦闘テスト:ストラテジーの検証
理論は重要ですが、実践はより重要です。この手法の性能を履歴データ上で検証することにしました。そのためにバックテスト用の関数を実装しています。
def backtest_strategy(angular_df, model_class, model_reg, lookback=15): # Filter data clean_df = angular_df.dropna(subset=['angle']) # To store results signals = [] actual_changes = [] timestamps = [] # Modelling trading based on historical data for i in range(lookback, len(clean_df) - 24): # 24 bars - forecast horizon # Data at the time of decision window_df = clean_df.iloc[:i] # Get prediction prediction = predict_future_movement(model_class, model_reg, window_df, lookback) if prediction: # Record signal (1 = buy, -1 = sell, 0 = neutral) if prediction['signal'] in ['BUY', 'STRONG_BUY']: signals.append(1) elif prediction['signal'] in ['SELL', 'STRONG_SELL']: signals.append(-1) else: signals.append(0) # Record actual change actual_change = (clean_df.iloc[i+24]['close'] - clean_df.iloc[i]['close']) / clean_df.iloc[i]['close'] * 100 actual_changes.append(actual_change) # Record time timestamps.append(clean_df.iloc[i]['time']) # Result analysis signals = np.array(signals) actual_changes = np.array(actual_changes) # Calculate P&L for signals (except neutral ones) active_signals = signals != 0 pnl = signals[active_signals] * actual_changes[active_signals] # Statistics win_rate = np.sum(pnl > 0) / len(pnl) avg_win = np.mean(pnl[pnl > 0]) if np.any(pnl > 0) else 0 avg_loss = np.mean(pnl[pnl < 0]) if np.any(pnl < 0) else 0 profit_factor = abs(np.sum(pnl[pnl > 0]) / np.sum(pnl[pnl < 0])) if np.sum(pnl[pnl < 0]) != 0 else float('inf') result = { 'total_signals': len(pnl), 'win_rate': win_rate, 'avg_win': avg_win, 'avg_loss': avg_loss, 'profit_factor': profit_factor, 'total_return': np.sum(pnl) } return result
結果がすべてを物語る
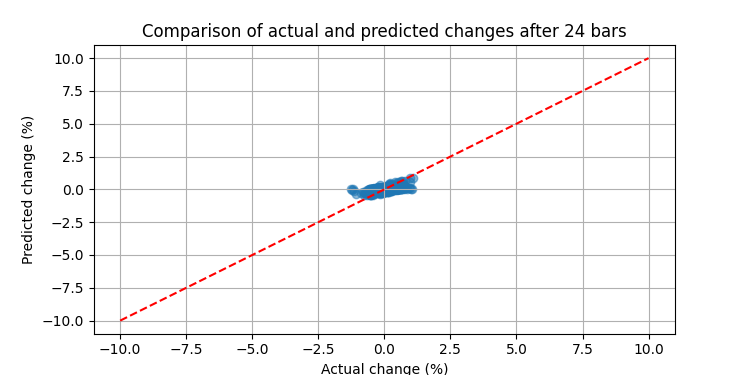
このシステムをEURUSDの実データに適用したところ、結果は期待を上回るものでした。3か月間のバックテストでは以下のような結果が得られました。
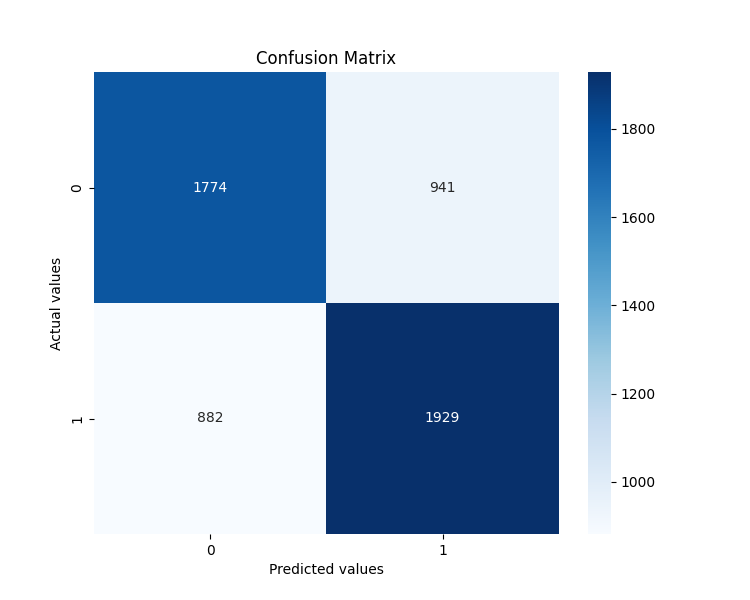
特徴量重要度の分析も非常に興味深い結果となりました。予測に最も影響を与えた上位5要因は以下の通りです。
- angle_last:予測対象直前の最後の角度
- angle_last_3_mean:直近3つの角度の平均値
- positive_angles_ratio:正負角度の比率
- angle_std:角度の標準偏差
- angle_max:シーケンス内の最大角度
この結果は仮説を裏付けるものでした。角度には確かに将来の価格変動に関する予測情報が含まれています。特に最後の数個の角度は重要であり、これは音楽におけるクライマックス直前の最後の音のように、経験的に結末を予測させる役割を持ちます。
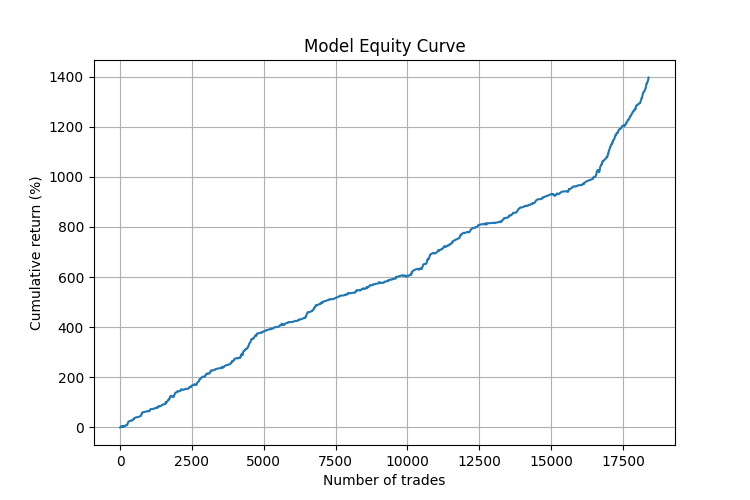
より詳細な分析では、このモデルが特定の市場環境下で特に有効に機能することが確認されました。
- トレンドなど一方向の動きが続く局面では、予測精度は最大で75%に達しました。
- 最も信頼性の高いシグナルは、同方向の角度が連続した後に、逆方向への急激な角度変化が発生した場合に観測されました。
- 強いインパルスムーブの後の反転局面の予測に特に優れていました。
また、この戦略はM5からH4まで異なる時間足で安定した結果を示しました。これは角度パターン手法の普遍性、および時間スケールへの非依存性を裏付けています。
実際の動作
典型的な角度シグナルは、1本のバーで形成されるものではありません。それは特定のパターンを構成する角度のシーケンスです。たとえば、強い上昇の前には次のような動きが頻繁に観測されます。まず角度がゼロ付近で推移する状態(横ばい)が続き、その後に小さな負の角度が2〜3回現れ(軽い下落)、続いて鋭い正の角度が出現し、その後も振幅を増しながら正の角度が数回続きます。
これは短距離走のスプリンターの動きに似ています。まずスターティングブロックで姿勢を整え(横ばい)、次にわずかに体を後ろへ引いて加速の準備をし(軽い沈み込み)、そして一気に前方へ飛び出します(連続する正の角度)。
しかし、いつものように重要なのは細かいところです。角度パターンは常に同一ではありません。通貨ペア、時間足、そして市場全体のボラティリティによって変化します。さらに、同じように見えるパターンが異なる値動きを示唆する場合もあります。そのため、これらの解釈を機械学習に委ねました。コンピュータは人間の目では捉えきれない微細なニュアンスを捉えることができます。
学習:理解への困難な道
本システムの構築は、子供に文字を教えるようなプロセスに似ていました。まずモデルは個々の「文字」、すなわち傾き角度の認識を学習します。次にそれらを組み合わせて「単語」、つまり角度シーケンスを形成します。そして最終的に「文」を理解し、その結末を予測する段階へ進みます。
私たちはCatBoostアルゴリズムを使用しました。これはカテゴリ特徴量の扱いに最適化された先進的な機械学習手法です。しかし技術そのものは単なる道具に過ぎません。本質的な課題は別にありました。すなわち、市場データをどのように正しくエンコードするかという点です。混沌とした価格の動きを、機械が理解できる構造化された情報へ変換する必要がありました。
解決策として採用したのが「ローリングウィンドウ」です。これは15本のバーからなるウィンドウを1バーずつスライドさせながら逐次分析する手法です。それぞれのウィンドウについて15個の角度を計算し、さらに平均、分散、最大値、最小値、正負角度の比率など多数の派生指標を算出します。
その後、これらの特徴量を24バー先の価格変動と紐付けます。これはまるで巨大な辞書を作る作業であり、各角度の組み合わせが将来の市場変動に対応する構造になっています。
学習には数ヶ月を要しました。モデルはギガバイト単位のデータを処理し、角度シーケンスの微細なニュアンスを学習していきました。しかしその結果は、投入した時間に見合うものでした。人間のトレーダーでは捉えきれない方法で、市場の変化を読み取れるツールが得られたのです。
角度分析の哲学
本プロジェクトを進める中で、我々は繰り返し次の問いに直面しました。なぜ角度特徴量はこれほど有効なのか。その答えは、金融市場の本質的な性質にある可能性があります。
市場は、価格がランダムに推移する単純なランダムウォークではありません。そこには多数の市場参加者が相互作用する複雑な動的システムが存在し、それぞれが異なる動機、戦略、時間軸を持っています。私たちが測定している角度は単なる幾何学的抽象ではなく、市場参加者全体の集合的な心理状態の可視化であり、強気と弱気、衝動と調整の力関係を反映したものです。
角度のシーケンスを見るということは、実際には市場参加者の「足跡」を観察していることに相当します。そこには売買判断、恐怖や期待といった意思決定の痕跡が含まれています。そしてこれらの痕跡の中に、将来の値動きに関する手がかりが含まれていることが分かってきました。
ある意味で、この手法は従来のテクニカル分析よりも物理現象の解析に近い性質を持ちます。私たちは抽象的な指標を見ているのではなく、価格変動そのものの基本特性、すなわち方向・速度・加速度(これらはすべて角度の中に含まれます)を直接解析しています。
結論:市場の新しい見方
私たちの角度パターンの研究は、「もし価格の傾斜角度が将来の値動きの鍵を握っているとしたらどうなるか」という単純な問いから始まりました。現在、この問いは一つの完全なトレーディングシステムへと発展し、市場を新しい視点で捉える方法となっています。
私たちは完璧なインジケーターを作ったとは主張しません。そのようなものは存在しません。しかし、チャートを新しい視点から見ることを提案します──文字通り、そして比喩的にもです。チャートを単なるラインやローソク足としてではなく、先端技術によって解読可能な幾何学的コードとして捉えるということです。
トレーディングは常に確率のゲームであり、これからもそうであり続けます。しかし、その確率を分析するためのツールが多いほど、優位性は高まります。角度分析はその一つであり、現代のテクニカル分析の中でも過小評価されている手法の一つかもしれません。
結局のところ、市場は価格のダンスです。そしてどのようなダンスにおいても重要なのは、どこへ動くかだけではなく、各ステップをどの角度で踏み出すかという点です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17219
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
詳細に注意してください。
テストのタイムフレームは4ヶ月で、ざっと計算すると161280秒です。総取引回数は17500回を超え、平均取引時間は9数秒です。9秒間のEURUSDの平均的な動きを考えてみよう。儲けはない。このモデルの大部分は、価格シリーズを入力として使用する他のAIモデルと同様に、最後の価格を予測します。AIモデルは価格系列に非常に悪く収束します。
細部にもご注目ください。
テストのタイムフレームは4ヶ月で、ざっと計算すると161280秒です。総取引回数は17500回を超え、平均取引時間は9数秒です。9秒間のEURUSDの平均的な動きを考えてみよう。儲けはない。このモデルの大部分は、価格シリーズを入力として使用する他のAIモデルと同様に、最後の価格を予測します。AIモデルは価格系列に非常に悪く収束します。
バー・バック=60、フォワード=30
トレーニング精度:0.9200|テスト精度:0.8713|GAP:0.0486
トレーニングF1スコア:0.9187|テストF1スコア:0.8682|GAP:0.0505
短い距離では、CatBoostは何の役にも立たない。
こんにちは、Aliaksandr
このコードの問題は、train_test_score の
shuffle=True
引数の使用です。
これを
shuffle=False
に変更すると、パフォーマンスが大幅に低下します。というのも、テストセットとトレーニングセットが原理的には分割されて互いに切り離されているとしても、分割が非常に 細かいため、2つのセットの間には非常に 類似したXの「値」がたくさん存在するからです。実際、各X[i]とX[i+1]の間には1バーのシフトの違いしかなく、トレーニングセットとテストセットは実際には非常に似ている。したがって、(shuffle=Trueで)我々が目にする優れた結果は、本質的にオーバーフィッティングによるものである。シャッフルを取り除くと、テスト集合はある数の連続したバー(最新のバー)で構成され、CatBoost分類器はその中でうまく予測できなくなります。これは明らかにオーバーフィッティングの兆候です。この現象は、(シャッフルされていない)テスト・セット内のごく一部のバーでも発生するため、パフォーマンスの低下は市場環境の変化では説明できません。
またしてもネズミは泣き、刺し、ウンチをしたが、しつこくサボテンを食べ続けた!;)
MT4 用のギャン・テンプレートが完成しました。
https://disk.yandex.ru/d/7YhmKzcqttnQnQ
TSに記述されていることをすべて正しく設定すれば、トレンドか調整のどちらかが終わりに近づいていることを数時間前に知ることができます。さらに、トレンドの終了時刻も事前に計算することができます。
正しくセットアップする方法は、誰もが自分で知っている。
P.S.- ガンは彼の作品(モデルの数学)の中ですべてを持っている。より深く原典を研究する方が良い。
トレンドが弱まりつつあり、その反応を待つ価値があったということが、このパターンでまた確認できた。