
Datenkennzeichnung für die Zeitreihenanalyse (Teil 4):Deutung der Datenkennzeichnungen durch Aufgliederung

Einführung
Im vorangegangenen Artikel dieser Reihe haben wir das NHITS-Modell erwähnt, bei dem wir nur die Vorhersage der Schlusskurse für eine einzige Eingangsvariable validiert haben. In diesem Artikel werden wir die Interpretierbarkeit des Modells und die Verwendung mehrerer Kovariaten zur Vorhersage von Schlusskursen erörtern. Zur Veranschaulichung werden wir ein anderes Modell, NBEATS, verwenden, um mehr Möglichkeiten aufzuzeigen. Es sei jedoch darauf hingewiesen, dass der Schwerpunkt dieses Artikels auf der Interpretierbarkeit des Modells liegen soll, und die Antwort auf die Frage, warum das Thema der Kovariaten ebenfalls eingeführt wird, wird gegeben werden. So können Sie jederzeit verschiedene Modelle zur Überprüfung Ihrer Ideen verwenden. Natürlich handelt es sich bei diesen beiden Modellen im Wesentlichen um qualitativ hochwertige, interpretierbare Modelle, und Sie können auch andere Modelle verwenden, um Ihre Ideen mit den in meinem Artikel erwähnten Bibliotheken zu überprüfen. Es ist erwähnenswert, dass diese Artikelserie darauf abzielt, Lösungen für Probleme zu bieten. Bitte bedenken Sie sorgfältig, bevor Sie sie direkt auf Ihren realen Handel anwenden, die reale Handelsimplementierung kann mehr Parameteranpassungen und mehr Optimierungsmethoden erfordern, um zuverlässige und stabile Ergebnisse zu liefern.
Die Links zu den drei vorangegangenen Artikeln lauten:
- Datenkennzeichnung für Zeitreihenanalyse (Teil 1): Erstellen eines Datensatzes mit Trendmarkierungen durch den EA auf einem Chart
- Datenkennzeichnung für Zeitreihenanalyse (Teil 2): Datensätze mit Trendmarkern mit Python erstellen
- Datenkennzeichnung für die Zeitreihenanalyse (Teil 3):Beispiel für die Verwendung von Datenkennzeichnungen
Inhaltsverzeichnis
- Einführung
- Über NBEATS
- Bibliotheken importieren
- Die Klasse TimeSeriesDataSet umschreiben
- Datenverarbeitung
- Lernrate abrufen
- Definieren der Trainingsfunktion
- Modellschulung und -prüfung
- Modell interpretieren
- Schlussfolgerung
Über NBEATS
Dieses Modell wurde in verschiedenen Fachzeitschriften und Websites ausführlich zitiert und erläutert. Um Ihnen jedoch zu ersparen, ständig zwischen verschiedenen Websites hin- und herzuwechseln, habe ich beschlossen, eine einfache Einführung in dieses Modell zu geben. NBEATS kann Eingabe- und Ausgabesequenzen beliebiger Länge verarbeiten und ist nicht von einer bestimmten Merkmalstechnik oder Eingabeskalierung für Zeitreihen abhängig. Es kann auch Polynome und Fourier-Reihen als Basisfunktionen für interpretierbare Konfigurationen verwenden, um Trend- und Saisonzerlegungen zu simulieren. Darüber hinaus verwendet dieses Modell eine duale Residualstapeltopologie, sodass jeder Baustein zwei Residualzweige hat, einen entlang der Rückwärtsvorhersage und den anderen entlang der Vorwärtsvorhersage, was die Trainierbarkeit und Interpretierbarkeit des Modells erheblich verbessert. Wow, das sieht sehr beeindruckend aus!Die Adresse der Publikation lautet: https://arxiv.org/pdf/1905.10437.pdf
1. Architektur des Modells:
2.Implementierungsprozess des Modells
Die eingegebene Zeitreihe (Dimension ist Länge) wird auf einen niedrigdimensionalen Vektor (Dimension ist dim) abgebildet, und der zweite Teil bildet ihn auf die Zeitreihe (Länge ist Länge) zurück. Dieser Schritt ähnelt auch dem AutoEncoder, der die Zeitreihe auf einen niedrigdimensionalen Vektor abbildet, um Kerninformationen zu speichern, und sie dann wiederherstellt. Dieser Prozess kann einfach wie folgt dargestellt werden: 
Das Modul erzeugt zwei Sätze von Expansionskoeffizienten, einen für die Vorhersage der Zukunft (forecast) und einen für die Vorhersage der Vergangenheit (backcast). Dieser Prozess kann durch die folgende Formel dargestellt werden:

3. die Interpretierbarkeit
Insbesondere ist die Dekomposition, die Aufgliederung des Modells interpretierbar. Das NBEATS-Modell führt ein gewisses Vorwissen in jede Schicht ein, wodurch einige Schichten gezwungen werden, bestimmte Arten von Zeitreihenmerkmalen zu erlernen, und eine interpretierbare Zeitreihendekomposition erreicht wird. Die Implementierungsmethode besteht darin, die Expansionskoeffizienten an die Funktionsform der Ausgangssequenz zu binden. Wenn Sie beispielsweise möchten, dass ein bestimmter Schichtenblock hauptsächlich die Saisonalität der Zeitreihe vorhersagt, können Sie die folgende Formel verwenden, um die Ausgabe als saisonal zu erzwingen:


4. Die Kovariaten
In diesem Artikel werden wir Kovariaten einführen, die uns helfen, den Zielwert vorherzusagen. Im Folgenden wird die Definition der Kovariaten erläutert:- static_categoricals: Eine Liste kategorischer Variablen, die sich im Laufe der Zeit nicht ändern.
- static_reals: Eine Liste kontinuierlicher Variablen, die sich nicht mit der Zeit verändern.
- time_varying_known_categoricals: Eine Liste kategorischer Variablen, die sich mit der Zeit ändern und in der Zukunft bekannt sind, wie z. B. Urlaubsinformationen.
- time_varying_known_reals: Eine Liste von kontinuierlichen Variablen, die sich mit der Zeit ändern und in der Zukunft bekannt sind, wie z. B. Daten.
- time_varying_unknown_categoricals: Eine Liste kategorischer Variablen, die sich mit der Zeit verändern und in der Zukunft nicht bekannt sind, wie z. B. Trends.
- time_varying_unknown_reals: Eine Liste von kontinuierlichen Variablen, die sich mit der Zeit verändern und in der Zukunft nicht bekannt sind, wie z. B. Anstiege oder Rückgänge.
5. Externe Variablen
Das NBEATS-Modell kann auch externe Variablen einführen, die, laienhaft ausgedrückt, keinen Bezug zu unserem Datensatz haben, aber das Modell ändert sich entsprechend. Das Team der Veröffentlichung nannte es NBEATSx, und wir werden in diesem Artikel nicht darauf eingehen.Importieren der Bibliotheken
Da gibt es nichts zu sagen. Tun Sie es einfach!
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
Uumschreiben der Klasse TimeSeriesDataSet
Da gibt es nichts zu sagen. Tun Sie es einfach! Warum Sie dies tun, erfahren Sie in den früheren Artikeln dieser Reihe.
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
Datenverarbeitung
Wir werden das Laden von Daten und die Datenvorverarbeitung hier nicht wiederholen, für spezifische Erklärungen verweisen wir auf den entsprechenden Inhalt meiner drei vorhergehenden Artikel, dieser Artikel erklärt nur die entsprechenden Änderungen an den Stellen.
1. Die Datenerfassung
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2. Die Vorbehandlung
Im Gegensatz zu früher werden wir hier über Kovariaten sprechen, warum tun wir das? Es gibt nämlich noch weitere Varianten dieses Modells, NBEATSx und GAGA. Wenn Sie sich für diese oder andere Modelle interessieren, die in der von uns verwendeten Bibliothek pytorch-forecasting enthalten sind, ist es wichtig, die Kovariaten zu verstehen. Wir sind hier, um kurz darüber zu sprechen.
Funktionen gegen unsere Forex-Datenleiste, verwenden Sie die Datenspalten „open“, „high“ und „low“ als Kovariaten. Natürlich können Sie auch andere Daten als Kovariaten verwenden, z. B. MACD, ADX, RSI und andere verwandte Indikatoren, aber denken Sie bitte daran, dass sie mit unseren Daten in Zusammenhang stehen müssen. Sie können keine externen Variablen wie Sitzungsprotokolle der Federal Reserve, Zinsentscheidungen, Nicht-Erwerbsdaten usw. als kovariate Eingaben hinzufügen, da dieses Modell nicht über die Funktion verfügt, diese Daten zu analysieren. Vielleicht schreibe ich eines Tages einen Artikel, in dem ich erkläre, wie man externe Variablen zu unserem Modell hinzufügt.
Lassen Sie uns nun erörtern, wie man Kovariaten in der Klasse New_TmSrDt() hinzufügt. Die folgenden Variablendefinitionen sind in dieser Klasse enthalten:
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
Die spezifische Bedeutung dieser Variablen habe ich bereits zuvor erläutert. Nun überlegen wir, zu welcher Kategorie die Variablen „open“, „low“, „low“ gehören? Die anderen sind leicht zu unterscheiden, die verwirrenden sind:
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
Da die Variablen „open“, „high“, „low“ keine Kategorien sind, bleiben nur time_varying_known_reals und time_varying_unknown_reals zur Auswahl. Man könnte sagen, dass wir „close“ vorhersagen wollen, dann kann jeden Kurs des Balkens „open“, „high“, „low“ in Echtzeit erhalten werden, warum kann es nicht zu time_varying_known_reals hinzugefügt werden? Bitte denken Sie sorgfältig nach: Wenn Sie nur den Wert eines Balkens vorhersagen, dann ist diese Idee etabliert, Sie können sie vollständig als time_varying_known_reals klassifizieren, aber was, wenn wir die Werte mehrerer Balken vorhersagen wollen? Da man nur die Daten des aktuellen Balkens kennt und die dahinter liegenden Werte völlig unbekannt sind, ist es für die in unserem Artikel besprochene Umgebung nicht geeignet, weshalb wir es zu time_varying_unknown_reals hinzufügen sollten. Wenn Sie jedoch nur den Wert von „close“ eines Balkens vorhersagen, können Sie ihn auf jeden Fall zu time_varying_known_reals hinzufügen, daher ist es wichtig, unseren Anwendungsfall sorgfältig zu prüfen. Es gibt auch einen Sonderfall von time_varying_known_reals. In der Tat hat jeder unserer Balken einen festen Zyklus, wie z.B. M15, H1, H4, D1, usw., sodass wir die Zeit, zu der die zu prognostizierenden Balken gehören, vollständig berechnen können. Sie können also die Zeit vollständig als time_varying_known_reals hinzufügen, wir werden diesen Artikel nicht diskutieren, interessierte Leser können ihn selbst hinzufügen. Wenn Sie Kovariaten verwenden möchten, können Sie „time_varying_unknown_reals=["close"]“ in „time_varying_unknown_reals==["close","high","open","low"]“ ändern. Natürlich unterstützt unsere Version von NBEATS diese Funktion nicht!
Der Code lautet also:
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
Lernrate abrufen
Da gibt es nichts zu sagen. Tun Sie es einfach! Warum Sie dies tun, erfahren Sie in den früheren Artikeln dieser Reihe.
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
Anmerkung: Es gibt ein paar Unterschiede zwischen dieser Funktion und Nbits, da die Funktion NBeats.from_dataset() keine hidden_size-Parameter hat. Und der Verlustparameter kann nicht die Methode MQF2DistributionLoss() verwenden.
Definieren der Trainingsfunktion
Da gibt es nichts zu sagen. Tun Sie es einfach! Warum Sie dies tun, erfahren Sie in den früheren Artikeln dieser Reihe.
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer Anmerkung: Die Funktion NBeats.from_dataset() in dieser Funktion erfordert das Hinzufügen einer interpretierbaren Variablen für die Aufgliederung vom Typ stack_types. Wir verwenden also den Standardwert. Neben diesen beiden Standardeinstellungen gibt es auch eine „generische“ Option.
Modellschulung und -prüfung
Jetzt implementieren wir die Trainings- und Vorhersagelogik des Modells, die im vorigen Artikel erläutert wurde, und es gibt keine Änderungen, sodass ich nicht weiter darauf eingehen werde.
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
Anmerkung: Stellen Sie sicher, dass Sie TensorBoard installiert haben, bevor Sie es ausführen! Das ist wichtig, denn sonst passieren unerklärliche Fehler.
Trainingsergebnis (Es gibt 10 Bilder, die erscheinen, wenn Sie den Code ausführen, und hier ist ein zufälliges Bild als Beispiel):

Testergebnis:

Interpretieren des Modells
Es gibt viele Möglichkeiten, die Daten zu interpretieren, aber das NBEATS-Modell ist einzigartig, da es die Vorhersagen in Saisonalität und Trends aufschlüsselt (da diese beiden in diesem Artikel ausgewählt wurden, können die Ergebnisse natürlich nur in diese beiden aufgeschlüsselt werden, aber es sind viele andere Kombinationen möglich).
Wenn Sie mit dem Training fertig sind und die Vorhersage zerlegen wollen, können Sie den Code hinzufügen:
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
Wenn Sie die Vorhersage bei der Durchführung einer Prognose zerlegen möchten, können Sie den folgenden Code hinzufügen:
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) Das Ergebnis ist wie folgt:
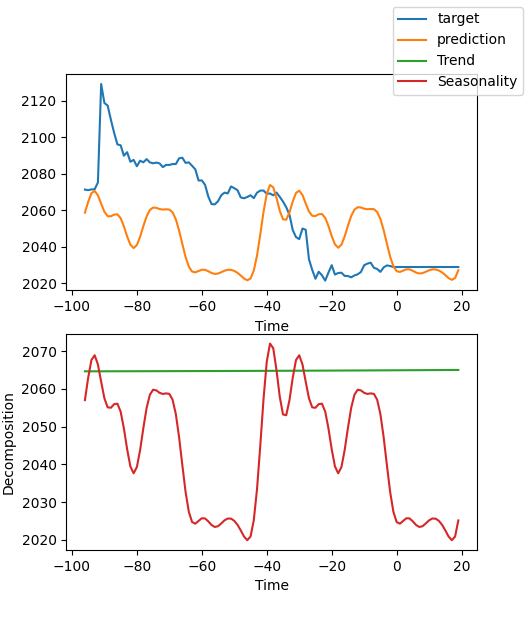
Aus der Abbildung geht hervor, dass unsere Ergebnisse nicht gut genug sind, weil wir nur ein grobes Beispiel zeigen, unser Modell nicht sorgfältig optimiert haben und unsere Datenkennzahlen noch nicht wissenschaftlich spezifiziert sind. Außerdem werden die meisten Modellparameter nur standardmäßig verwendet und nicht angepasst, sodass wir viel Raum für Optimierungen haben.
Schlussfolgerung
In diesem Artikel wird erörtert, wie unsere markierten Daten zur Vorhersage künftiger Preise mit Hilfe des NBEATS-Modells verwendet werden können. Gleichzeitig demonstrieren wir die spezielle Funktion für die Interpretation und Aufgliederung des Modells NBEATS. Obwohl unsere Code-Änderungen nicht signifikant sind, beachten Sie bitte unsere Diskussion über Kovariaten im Text. Wenn Sie die Verwendung der verschiedenen Kovariaten wirklich verstehen, können Sie dieses Modell auf andere Anwendungsszenarien ausweiten! Ich bin davon überzeugt, dass dies Ihnen helfen wird, die Genauigkeit von EA zu verbessern und die Aufgaben, die Sie erledigen müssen, genau zu erledigen. Natürlich ist dieser Artikel nur ein Beispiel. Wenn Sie es auf den tatsächlichen Handel anwenden wollen, ist es immer noch ein bisschen grob. Es gibt viele Stellen, die weiter optimiert werden müssen, also verwenden Sie es nicht direkt im Handel! Gleichzeitig haben wir auch einige Informationen über externe Variablen erwähnt. Ich weiß nicht, ob jemand an dieser Richtung interessiert ist. Wenn ich genügend Informationen bekomme, werde ich vielleicht in Zukunft in dieser Artikelserie darauf eingehen, wie man das umsetzen kann.
So, dieser Artikel endet hier, ich hoffe, Sie können etwas damit anfangen!
Der gesamte Code:
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13218
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.