您应当知道的 MQL5 向导技术(第 60 部分):推理学习(Wasserstein-VAE),配合移动平均线和随机振荡器形态
概述
在实证 MA 与随机振荡器配对产生的形态时,我们已考察过机器学习作为我们的系统化手段。机器学习中训练网络主要有三种方法,分别是监督学习、强化学习、和推理。以每种学习方法的视角来看,它们都能在模型/网络开发的不同阶段使用,我们曾遇到过这样的情况,通过它们的整合,令模型得以丰富。
简要回顾
简单回顾一下我们早前的监督学习文章,其中涉及状态的特征建模。特征是平均移动线和随机振荡器两者的指标形态。状态是预测价格变化,其落后于我们的指标形态,并由我们的模型/网络预测。下面的简单示意图有助于概括这一点。

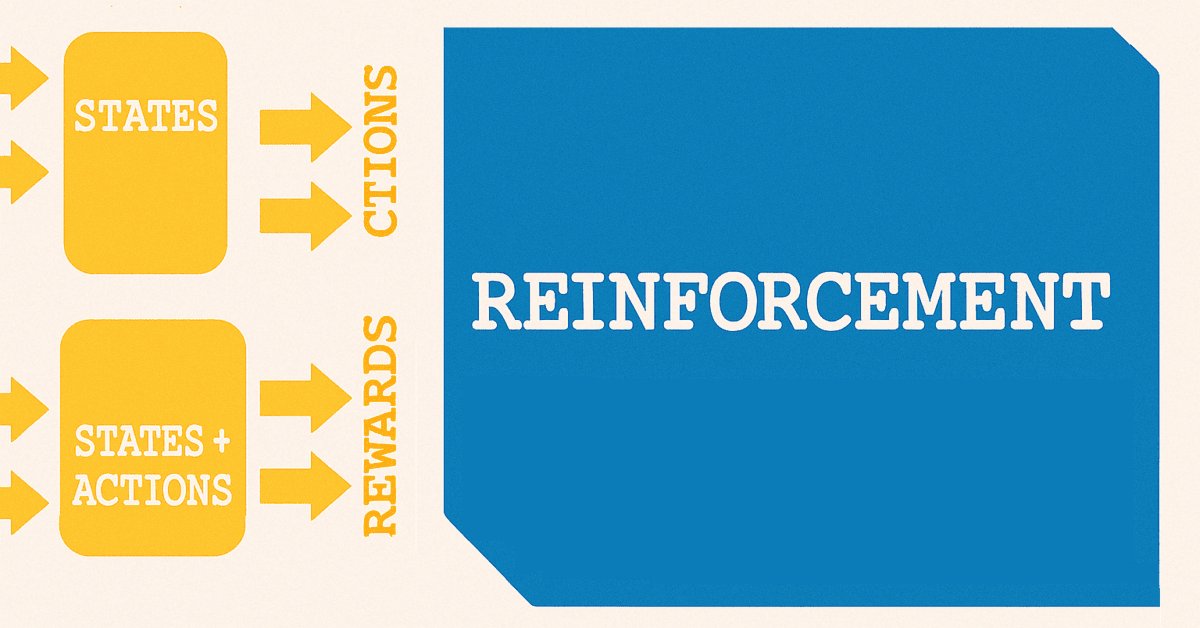
用“状态”一词来预测价格变化是偶然的,概因我们从监督学习转向强化学习。正如强化学习内建立的,状态是训练过程的关键起点,这与下图非常相似。

强化学习根据所用算法有多个变体,但原则上它们大多数都用到两个网络。第一个是政策,在上图所示两个网络中的上方,另一个是价值网络,表示为下方。
强化可能是模型或系统的专有训练方法,但我们在上一篇文章中的论证了,它在实际部署的模型上所用更多。当这完成后,探索与利用的平衡将更有助于确保已训练好的模型适配不断变化的市场环境。但是更甚于此,我们见识了做多或做空决策如何进一步处理,即选择预测状态所需的动作类型。
推理
这就为我们引出了推理,亦称为无监督学习。推理的目的是什么?当我先开始思考这一点时,我看到它允许我们针对给定状况取用已训练网络/模型,配合一些小调整和磨合,将其应用在不同的设定中。对于交易者来说,翻译一下就是针对 EURUSD 训练一个模型,然后稍作调整,将知识转化到 EURJPY。然而,正如大多数交易者所见证,即使开发一款非套利的智能系统,能够同时交易多个品种,也是一个风险回报方案存疑的脆弱过程。
首当其冲的是,跨多货币对训练不同模型的计算成本也不再如前那样令人望而却步。这在很大程度上得益于更快的 GPU,以及云基础设施的普及,为众多用户带来益处。因此,纸面上,这种状况应导致多种模型创建。虽然存储成本也在下降,尤其是考虑到数百万参数的大型模型现在像常规计算机文件一样存储,我认为通过编码器推理,这些知识可被压缩、及“更易存储”。
现在,更多或特殊存储的需求几乎被忽视,顾及它如此廉价,人们很容易对此不屑一顾。这尤为真实,若您考虑到监督学习模型已训练有素,且一个就位的强化学习系统保持其最新动态,推理会带来什么?嗯,我们的论调是,并非所有数据都处在连续时间序列形式。
如果就当前、或正在展开事件,参考旧历史数据中相似的案例,推理能有助于映射这些数据,同时白噪声最小化。映射指的是下图的设置概括:

故此,在历史数据特征可用的状况下,我们如下展示了配以无监督(此例为线性回归),我们如何能推理出对应的“状态-动作-奖励”。这一切都是因为我们训练了一个变分-自动编码器模型,将“特征-状态-动作-奖励”(FSAR)与我们称为编码的隐藏层配对。配合 FSAR 和编码数据集,我们就拟合了一个线性回归模型,然后帮助填补 FSAR 数据集中缺失的空白。这是在本文中即将探索的主要应用。
然而,如果退一步来考察监督学习、以及强化学习过程,就会发现随着时间推移,更全面地整合所收集知识的需要也随之增长。而再进行一次覆盖更长区间的监督学习,然后运行强化学习也是一个选项,推理学习应当是一个更具伸缩性和整体性的替代方案。
那么,回到我们的讲述,推理是从观察数据中估算隐藏变量。在贝叶斯(Bayesian)模型中,推理通常是当可见层数据集存在时,计算隐藏变量后验分布的过程。因此,从数学上可以正式定义如下:

其中:
- z 是潜在变量或编码,
- x 是观测数据,在我们的情况下是 FSAR,
- p(z∣x) 是后验(我们欲学习的内容)或是已见到 x 的情况下观察 z 给出的概率,
- p(x∣z) 是似然性,或当出现 z 时见到 x 的概率
- p(z) 是先验,
- p(x) 是证据。
P(x) 往往很棘手,或难以计算。
它为什么困难?分母 p(x) 涉及涵盖所有可能的潜在变量进行积分:

这在高维度中通常是难以计算,即随着潜在变量大小增加。
那 VAE 能如何提供帮助呢?VAE 将近似问题推理转化为一项优化任务。这是通过引入编码器/推理网络,和解码器/生成网络来达成的。编码器回答 q(z|x) 的问题,这是学到的外表近似;而解码器网络则定位于 p(x|z),这是从潜在代码(编码)中重造的数据(在本例中为 FSAR)。
VAE 的关键创新在于,它彻底取代计算后验,VAE 会针对证据低界优化(ELBO)进行优化。ELBO 是目标函数,通过近似真实数据分布训练 VAE,同时确保模型学到有意义的潜在表示,且更少噪声。以下是关键直觉:

如上所述,计算 p(x) 非常困难、且棘手;然而,证明 p(x)、以及 log p(x) 大于给定数值是可行、且易于的。由于我们的目标是最大化 p(x),通过最大化或提高低界,我们终将提高 p(x)。VAE 学习从数据中推理潜在结构,并依据梯度降序进行端到端训练。因此,它在一个框架内展示了摊销推理和生成式建模两者。
为什么 VAE 是推理哲学的核心?因为 VAE 通过编码器学习执行推理。这意味着,取代每次有新数据集就解决推理问题,而是使用共享编码器。这也被称为摊销推理。这是一款出色的工具,可在忠实度与规律性之间权衡权重,但也能帮助理解潜在变量如何表述生成式结构。
我们在本文中实现的 VAE,当比较分布时,由探索 Wasserstein(瓦瑟斯坦) 距离,替代传统的 KL-发散。原因大多是探索性的,我们在未来文章中可能研究 KL-发散。然而,有人认为 KL-发散过度约束潜在空间,进而可能导致后验塌陷。其次,瓦瑟斯坦距离,其论调,在比较分布时是一个更灵活的量值,尤其是在问题中分布有少量不重叠的状况下。
瓦瑟斯坦距离的核心思想是衡量将一个概率分布转换为另一个概率分布的“代价”。这就是为什么有时它被称为地球移动者的距离。它由以下方程表示:

其中:
-
P:真实数据分布(例如,高斯先验 p(z))。
-
Q:近似分布(例如编码器的输出 q(z∣x))。
-
γ:P 和 Q 上的联合分布(耦合)。
-
Γ(P,Q):P 与 Q 之间所有可能耦合的集合。
-
∥x−y∥:距离量值(例如欧几里得距离)。
-
inf:下确界(最大低界,即最小的转换成本)。
因此,瓦瑟斯坦计算出将质量 Q 移动到匹配 P 所需的最小“做功”额度。瓦瑟斯坦 VAE 重要之处在于它能产生更锐利的样本,具有更丰富的潜在表现力。一般认为在特定条件下训练时,它更为稳定。
瓦瑟斯坦 VAE 主要有两种常见实现。WVAE-MMD,以及 WVAE-GAN。前者利用最大均值差来比较 p(z) 和 q(z)。这就是我们在本文中将要采用的。作为一条旁注,后者 WVAE-GAN 利用对抗损耗来对齐潜在分布。我们在未来文章中或许会考察这一实现。最大均值差由以下方程表示:

其中:
-
P:真实先验(例如,p(z)=N(0,I))。
-
Q:编码器的分布(例如 q(z∣x))。
-
k(⋅,⋅):内核函数(例如,高斯 RBF)。
-
x,x′:来自 P 的两个独立样本。
-
y,y′:来自 Q 的两个独立样本。
VAE 实现
我们一开始会用 Python 实现模型/网络,主要是因为于此训练它们,比用原生 MQL5 更快捷。MQL5 中有一些利用 OpenCL 的变通方法,可以降低性能差距,不过我们尚未在本系列中考察这些。我们以 Python 实现 瓦瑟斯坦 VAE 类如下:
class WassersteinVAEUnsupervised(nn.Module): def __init__(self, feature_dim, encoding_dim, k_neighbors=5): super().__init__() self.encoding_dim = encoding_dim self.k_neighbors = k_neighbors # Feature encoder self.feature_encoder = nn.Sequential( nn.Linear(feature_dim, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, encoding_dim * 2) # mean and logvar ) # Buffer for storing training references self.register_buffer('ref_encoding', torch.zeros(1, encoding_dim)) self.register_buffer('ref_states', torch.zeros(1, 1)) self.register_buffer('ref_actions', torch.zeros(1, 1)) self.register_buffer('ref_rewards', torch.zeros(1, 1)) self._references_loaded = False def encode(self, features): h = self.feature_encoder(features) z_mean, z_logvar = torch.chunk(h, 2, dim=1) return z_mean, z_logvar def reparameterize(self, mean, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mean + eps * std def update_references(self, encoding_vectors, states, actions, rewards): """Store reference data for unsupervised prediction""" self.ref_encoding = encoding_vectors.detach().clone() self.ref_states = states.detach().clone().unsqueeze(-1) self.ref_actions = actions.detach().clone().unsqueeze(-1) self.ref_rewards = rewards.detach().clone().unsqueeze(-1) self._references_loaded = True def knn_predict(self, z, ref_values): # z shape: [batch_size, encoding_dim] # ref_values shape: [ref_size, 1] or [ref_size] # Ensure ref_values is properly shaped ref_values = ref_values.view(-1) # Flatten to [ref_size] # Calculate distances between z and reference encodings distances = torch.cdist(z, self.ref_encoding) # [batch_size, ref_size] # Get top-k nearest neighbors _, indices = torch.topk(distances, k=self.k_neighbors, largest=False) # [batch_size, k] # Gather corresponding reference values neighbor_values = torch.gather( ref_values.unsqueeze(0).expand(indices.size(0), -1), # [batch_size, ref_size] 1, indices ) # [batch_size, k] # Average the nearest values predictions = neighbor_values.mean(dim=1, keepdim=True) # [batch_size, 1] return predictions def gaussian_predict(self, z, ref_values): # Input validation assert z.dim() == 2, "z must be 2D [batch, encoding]" assert ref_values.dim() == 2, "ref_values must be 2D" # Calculate distances (Euclidean) distances = torch.cdist(z, self.ref_encoding) # [batch, ref_size] # Convert to similarities (Gaussian weights) weights = torch.softmax(-distances, dim=1) # [batch, ref_size] # Prepare reference values ref_values = ref_values.squeeze(-1) if ref_values.size(1) == 1 else ref_values ref_values = ref_values.unsqueeze(0) if ref_values.dim() == 1 else ref_values # Ensure proper shapes ref_values = ref_values.view(-1, 1) # Force [792, 1] shape # Calculate distances distances = torch.cdist(z, self.ref_encoding) # [batch_size, 792] # Convert to weights weights = torch.softmax(-distances, dim=1) # [batch_size, 792] # Matrix multiplication Weighted combination predictions = torch.matmul(weights, ref_values) # [batch, 1] return predictions.unsqueeze(-1) if predictions.dim() == 1 else predictions def linear_predict(self, z, ref_values): """Linear regression prediction using normal equations""" # Add bias term X = torch.cat([self.ref_encoding, torch.ones_like(self.ref_encoding[:, :1])], dim=1) y = ref_values # Compute closed-form solution XtX = torch.matmul(X.T, X) Xty = torch.matmul(X.T, y) theta = torch.linalg.solve(XtX, Xty) # Predict with new z values X_new = torch.cat([z, torch.ones_like(z[:, :1])], dim=1) return torch.matmul(X_new, theta) def predict_from_encoding(self, z): if not self._references_loaded: raise RuntimeError("Reference data not loaded") # Validate reference shapes self.ref_states = self.ref_states.view(-1, 1) self.ref_actions = self.ref_actions.view(-1, 1) self.ref_rewards = self.ref_rewards.view(-1, 1) states = self.knn_predict(z, self.ref_states) actions = self.gaussian_predict(z, self.ref_actions) rewards = self.linear_predict(z, self.ref_rewards) return states, actions, rewards def forward(self, features, states=None, actions=None, rewards=None): z_mean, z_logvar = self.encode(features) z = self.reparameterize(z_mean, z_logvar) if states is not None and actions is not None and rewards is not None: return { 'z': z, 'z_mean': z_mean, 'z_logvar': z_logvar } else: pred_states, pred_actions, pred_rewards = self.predict_from_encoding(z) return { 'states': pred_states, 'actions': pred_actions, 'rewards': pred_rewards }
我们上述 瓦瑟斯坦 VAE 的实现主要由四件事组成。特征编码器、引用缓冲区、预测方法、和双模前向通验。特征编码器是一个三层 MLP,其角色是把输入压缩到潜在空间参数(z、z-均值 & z-对数变量)。参考缓冲区存储预先训练好的模型输入,包括特征、状态、动作、和奖励、伴同其相应编码。列出的预测方法针对仅存在特征的不完整数据集,预测状态、动作、和奖励。这些方法分别是 K-NN、高斯加权、线性回归。它们于潜在空间内工作,编码映射到状态-动作-奖励缺失的数据点。双模前向通验处理训练和推理两者。
关键功能组件包括编码过程、参考系统、预测机制、和推理流程。在编码过程中,输入的特征-状态-动作-奖励经由编码器网络通验。输出把这些输入分割成 z、z-均值、和 z-对数-变量的“编码”。此外,在过程中,重参数化技巧令我们得到可微样本。参考系统存储“冻结”输出,及与其相应的 FSAR 输入配对。它需要通过 update_references() 函数显式初始化。
这三种预测机制目标在于预测状态、动作、或奖励。我们的模型搭配基本项工作,即可用特征始终作为 FSAR 数据集的一部分,不过有时可能 SAR(状态-行动-奖励)会缺失。KNN 聚类映射状态,高斯过程回归映射动作,线性回归映射奖励。因此,推理流程把输入特征编码到潜在空间,基于上述配对为每种输入类型选择预测方法,然后返回相应的状态/动作/奖励估算。
然而,我们上面的方式还有一些改进空间。这些大致可落入三大项。架构强化,训练提升,或者只是更加健壮。架构改进可能包括:添加频谱归一化,以强制利普希茨(Lipschitz)连续性;针对高斯过程加权实现可学习温度;包括引用内存管理(FIFO/修剪);并针对不确定性估算,添加蒙特卡洛(Monte-Carlo)抽样。训练过程也能通过引入对瓦瑟斯坦约束的梯度惩罚来改进;添加潜在空间正则化(MMD/覆盖项);实现自适应预测方法选择;并增加预测方法的权重融汇。
健壮性提升有点模糊,不过能尽力而为:分布外检测能力;参考品质评分系统;动态邻域大小调整;以及输入依赖性噪声缩放。
MMD-损失实现
我们实现的 瓦瑟斯坦 VAE 形式是 MMD-损失,且其针对 VAE 的两个损失函数如下所示:
def mmd_loss(y_true, y_pred, kernel_mul=2.0, kernel_num=5): """ MMD loss using Gaussian RBF kernel. Args: y_true: Ground truth samples (shape: [batch_size, dim]) y_pred: Predicted samples (shape: [batch_size, dim]) kernel_mul: Multiplier for kernel bandwidths kernel_num: Number of kernels to use Returns: MMD loss (scalar) """ batch_size = y_true.size(0) # Combine real and predicted samples xx = y_true yy = y_pred xy = torch.cat([xx, yy], dim=0) # Compute pairwise distances distances = torch.cdist(xy, xy, p=2) # Compute MMD using multiple RBF kernels loss = 0.0 for sigma in [kernel_mul ** k for k in range(-kernel_num, kernel_num + 1)]: if sigma == 0: continue kernel_val = torch.exp(-distances ** 2 / (2 * sigma ** 2)) k_xx = kernel_val[:batch_size, :batch_size] k_yy = kernel_val[batch_size:, batch_size:] k_xy = kernel_val[:batch_size, batch_size:] # MMD formula: E[k(x,x)] + E[k(y,y)] - 2*E[k(x,y)] loss += (k_xx.mean() + k_yy.mean() - 2 * k_xy.mean()) return loss / (2 * kernel_num) def compute_loss(predictions, batch): # Ensure shapes match (squeeze if needed) pred_states = predictions['states'].squeeze(-1) # [B, 1] → [B] pred_actions = predictions['actions'].squeeze(-1) pred_rewards = predictions['rewards'].squeeze(-1) # MMD Loss (distributional matching) mmd_state = mmd_loss(batch['states'], pred_states) mmd_action = mmd_loss(batch['actions'], pred_actions) mmd_reward = mmd_loss(batch['rewards'], pred_rewards) # Combine losses (adjust weights as needed) total_loss = mmd_state + mmd_action + mmd_reward return { 'loss': total_loss, 'mmd_state': mmd_state, 'mmd_action': mmd_action, 'mmd_reward': mmd_reward }
MMD-损失函数输入参数为 y_true 和 y_pred。它们表述的是真实样本与生成样本的比较。它们的维度对齐非常重要,事关能否计算比较。kernel_mul/kernel_num 输入控制 RBF 内核带宽,因此会影响分布差异不同尺度的敏感性。
样本组合,xy,把真实和生成样本结合起来,在一次运算中计算所有配对距离。这不仅节省内存,还能保证一致性的距离计算。距离计算采用 p=2(欧几里得距离),这是 MMD 的标准。这一选择直接影响到分布差异的敏感度。“cdist” 运算在数学上是主料,因为 MMD 依赖于配对比较。
多内核方式采用几何间隔带宽(kernel_mul^k)来获取多尺度分布特性的感知。它避免了会带来零除的 σ=0 场景。经过平均化之后,每个内核对最终损失的贡献相等。MMD 计算采用核心公式(k_xx + k_yy - 2k_xy),即量化分布间的差异。均值运算从有限样本中提供期望估值,并按内核计数归一化,令损失尺度能跨越不同配置一致。
改进该 MMD可配合内核选择,其中:增加自适应带宽选择,可基于样本统计实现;配合非 RBF 内核进行实验,可确立哪些内核最适合何种数据类型;可实现带宽的自动相关性判定。数值稳定性也可引入以下方式:在分母中加入小 ε,从而实现稳定性;实现对非常小内核值的对数域计算;以及剪裁极端距离值,以预防溢出。其它量值还包括计算效率,和 VAE 集成。
我们还有很多其它代码来运行这个推理,于此我们并未明确强调。值得注意的是,尽管 FASR 输入数据的生成,来自运行早前两篇关于 MA 和随机振荡器的文章中代码。监督学习文章为我们给出了 VAE 输入中的特征和状态组成部分,而强化学习文章代码则为我们给出了动作和奖励。
线性回归的实现
为了使用我们的推理模型,我们仅依赖回归函数,从潜在层,而非 VAE 网络,映射到缺失输入。对比我们之前文章中所做,当时我们须将训练好的网络导出为 ONNX 文件。
该情况的原因,是因为我们感兴趣的是完成训练的 VAE 输入数据集。
继续迈进,我们只有特征数据。故此问题变成基于这些特性的状态、行动、和奖励。为了回答这个问题,我们在初始化智能系统时,需要配对的特征编码、状态编码、动作编码、和奖励编码的数据集来训练一个线性回归模型。配合我们的已训练(或拟合)线性回归模型,对于任何新数据的特征数据点,我们会将其映射到一个编码,然后在同一模型内用该编码反向映射状态、动作、和奖励。
这种获取编码连接的拟合过程采用无监督学习。我们的线性回归的 MQL5 版本实现如下:
//+------------------------------------------------------------------+ // Linear Regressor (unchanged from previous implementation) | //+------------------------------------------------------------------+ class LinearRegressor { private: vector m_coefficients; double m_intercept; matrix m_coefficients_2d; vector m_intercept_2d; public: void Fit(const matrix &X, const vector &y) { int n = (int)X.Rows(); int p = (int)X.Cols(); matrix X_with_bias(n, p + 1); for(int i = 0; i < n; i++) { for(int j = 0; j < p; j++) X_with_bias[i][j] = X[i][j]; X_with_bias[i][p] = 1.0; } matrix Xt = X_with_bias.Transpose(); matrix XtX = Xt.MatMul(X_with_bias); matrix XtX_inv = XtX.Inv(); vector y_col = y; y_col.Resize(n, 1); vector beta = XtX_inv.MatMul(Xt.MatMul(y_col)); m_coefficients = beta; m_coefficients.Resize(p); m_intercept = beta[p]; } void Fit2d(const matrix &X, const matrix &Y) { int n = (int)X.Rows(); // Number of samples int p = (int)X.Cols(); // Number of input features int k = (int)Y.Cols(); // Number of output encodings // Add bias term (column of 1s) to X matrix X_with_bias(n, p + 1); for(int i = 0; i < n; i++) { for(int j = 0; j < p; j++) X_with_bias[i][j] = X[i][j]; X_with_bias[i][p] = 1.0; } // Calculate coefficients using normal equation: (X'X)^-1 X'Y matrix Xt = X_with_bias.Transpose(); matrix XtX = Xt.MatMul(X_with_bias); matrix XtX_inv = XtX.Inv(); matrix beta = XtX_inv.MatMul(Xt.MatMul(Y)); // Split coefficients and intercept m_coefficients_2d.Resize(p, k); // Coefficients for each output encodings m_intercept_2d.Resize(k); // Intercept for each input feature for(int j = 0; j < p; j++) { for(int d = 0; d < k; d++) { m_coefficients_2d[j][d] = beta[j][d]; } } for(int d = 0; d < k; d++) { m_intercept_2d[d] = beta[p][d]; } } double Predict(const vector &x) { return m_intercept + m_coefficients.Dot(x); } vector Predict2d(const vector &X) const { int p = (int)X.Size(); // Number of input features int k = (int)m_intercept_2d.Size(); // Number of output encodings vector predictions(k); // vector to store predictions for(int d = 0; d < k; d++) { // Initialize with intercept for this output dimension predictions[d] = m_intercept_2d[d]; // Add contribution from each feature for(int j = 0; j < p; j++) { predictions[d] += m_coefficients_2d[j][d] * X[j]; } } return predictions; } };
核心结构维持单独的存储系数,对于一维(变量 m_coefficients/m_intercept)、对于二维(变量 m_coefficients_2d/m_intercept_2d)。矩阵代数用来在批处理操作中提高效率。它实现了单输出和多输出回归两者的变体。其拟合方法使用法向方程,直接求解 (X'X)^- 1X'y。它在处理乖离时,在输入特征中添加一列 1。该类的二维专用化还通过矩阵运算同时处理多个输出。
预测方法采用点积实现,其作为输入和权重的高效线性结合。维度处理在单输出和多输出场景中都得以正确处理,内存管理预先分配结果向量以提高效率。我们使用伪 瓦瑟斯坦 VAE 类,调用和实现状态、动作、和奖励预测。MQL5 版本代码如下:
//+------------------------------------------------------------------+ // Wasserstein VAE Predictors Implementation (unchanged) | //+------------------------------------------------------------------+ class WassersteinVAEPredictors { private: LinearRegressor m_feature_predictor; LinearRegressor m_state_predictor; LinearRegressor m_action_predictor; LinearRegressor m_reward_predictor; bool m_predictors_trained; public: WassersteinVAEPredictors() : m_predictors_trained(false) {} void FitPredictors(const matrix &features, const vector &states, const vector &actions, const vector &rewards, const matrix &encodings) { m_feature_predictor.Fit2d(features, encodings); m_state_predictor.Fit(encodings, states); m_action_predictor.Fit(encodings, actions); m_reward_predictor.Fit(encodings, rewards); m_predictors_trained = true; } void PredictFromFeatures(const vector &y, vector &z) { if(!m_predictors_trained) { Print("Error: Predictors not trained yet"); return; } z = m_feature_predictor.Predict2d(y); } void PredictFromEncodings(const vector &z, double &state, double &action, double &reward) { if(!m_predictors_trained) { Print("Error: Predictors not trained yet"); return; } state = m_state_predictor.Predict(z); action = m_action_predictor.Predict(z); reward = m_reward_predictor.Predict(z); } };
在自定义信号类别内,我们现在还依赖 “Infer” 函数来处理预测。如下所示:
//+------------------------------------------------------------------+ //| Inference Learning Forward Pass. | //+------------------------------------------------------------------+ vector CSignal_WVAE::Infer(int Index, ENUM_POSITION_TYPE T) { vectorf _f = Get(Index, m_time.GetData(X()), m_close, m_ma, m_ma_lag, m_sto); vector _features; _features.Init(_f.Size()); _features.Fill(0.0); for(int i = 0; i < int(_f.Size()); i++) { _features[i] = _f[i]; } // Make a prediction vector _encodings; _encodings.Init(__ENCODINGS); _encodings.Fill(0.0); double _state = 0.0, _action = 0.0, _reward = 0.0; if(Index == 1) { m_vae_1.PredictFromFeatures(_features, _encodings); m_vae_1.PredictFromEncodings(_encodings, _state, _action, _reward); } else if(Index == 2) { m_vae_2.PredictFromFeatures(_features, _encodings); m_vae_2.PredictFromEncodings(_encodings, _state, _action, _reward); } else if(Index == 5) { m_vae_5.PredictFromFeatures(_features, _encodings); m_vae_5.PredictFromEncodings(_encodings, _state, _action, _reward); } vector _inference; _inference.Init(3); _inference[0] = _state; _inference[1] = _action; _inference[2] = _reward; // if(T == POSITION_TYPE_BUY) { if(_state > 0.5) { _inference[0] -= 0.5; _inference[0] *= 2.0; if(_action < 0.0) { _inference[0] = 0.0; } } else { _inference[0] = 0.0; } } else if(T == POSITION_TYPE_SELL) { if(_state < 0.5) { _inference[0] -= 0.5; _inference[0] *= -2.0; if(_action > 0.0) { _inference[0] = 0.0; } } else { _inference[0] = 0.0; } } return(_inference); }
此处和此处是有关如何由 MQL5 向导汇编智能系统的指南,供新读者参考。自上一篇文章,我们启动的 10 种形态里,只有 1、2、和 5 能通过前向漫游测试。因此,我们为该智能系统设计的多头和空头条件函数,仅处理这三种形态。我们正预测 3 个数值。状态、动作、与奖励。状态被绑定在 0 到 1 的范围内。动作也被绑定在类似的范围内,而奖励则在 -1 到 +1 之间。任何有训练并运用神经网络经验的人都知道,在按目标训练后,神经网络的输出测试或部署要遵守绑定限制,并不总是落在预期的绑定限制之内。前向测试后往往需要某种形式的数据归一化。
我们于此不执行任何归一化,只是提醒读者,在将已训练网络投入生产环境时应牢记。我们加载两年的 EURUSD 日线价格数据到 Python,去训练一个 VAE,为我们提供配对的特征-状态-动作-奖励编码数据集。这些数据集被拟合到线性回归模型之中,我们随后用这些模型来映射状态、行为、及特征出现时的奖励。这些加载的数据经由 Meta Trader 5 Python 模块处理,其中 80% 用于训练,剩下 20% 用于测试。
数据区间为 2023.01.01至 2025.01.01。故以前向漫游测试大约是 2025 年 1 月 1 日之前的五个月。我们执行的测试区间稍长,即 2024.07.01 至 2025.01.01 的 6个月,并呈现以下报告:
对于形态-1:


对于形态-2:


对于形态-5:


似乎只有形态-1 和形态-5 具备基于短短两年训练/测试窗口进行推理的能力。
结束语
我们总结所考察的机器学习中移动平均线和随机振荡器的结合形态,探讨推理学习的应用场景。我们提出了一种可能的推理学习实现路径,基于这样一个论调:即监督学习完成后,强化学习也会在实况测试环境中滚动推进;仍需一种更整体的方式,收集和“储存”来自监督学习和强化学习的所有知识。我相信推理学习已蓄势待发,并适合扮演这一角色,尤其是因为它的学习方法,并非复现我们之前在监督学习和强化学习中的做法。
| 名称 | 描述 |
|---|---|
| wz_60.mq5 | 向导汇编的智能系统,包含了展示必要汇编文件的头文件 |
| SignalWZ_60.mqh | 信号类文件 |
| 60_vae_1.onnx | 形态-1 的 VAE ONNX 模型,对于智能系统并非必要。 |
| 60_vae_2.onnx | 形态-2 的 VAE ONNX 模型,同理 |
| 60_vae_5.onnx | 形态-5 的 VAE ONNX 模型,同理 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/17818
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。