
开发多币种 EA(第 26 部分):交易品种信息工具
目录
概述
在上一篇文章中,我们最终构建了一个堪称全面的系统,该系统能够自动将一个简单的交易策略转化为功能齐全的 EA,确保该策略能在多种交易品种和时间周期上同时运行。与资本管理系统和风险管理器相关的问题也未被忽视,该系统允许在出现不利情况或相反地出现过于有利的情况时停止交易。
在整个系列中,我们几乎只使用了一种简单的交易策略,只是在最后部分,当主要功能已经实现后,我们才开始考虑添加一种新的交易策略并将其作为主要策略。这个例子展示了尝试释放几乎任何交易策略潜力的可能性(当然,前提是这种潜力确实存在)。
但既然已经达到了目前的水平,前方又为我们展现出了更为广阔的进一步工作空间。现在有许多可能的方向,这使得下一步的选择更加困难。为了克服这一问题,我们尝试改变安排和存储该项目源代码的方式。第一步是在第 23 部分中迈出的,当时我们将大部分代码分离到所谓的“库部分”,其余代码则留在“项目部分”。接下来,我们将注意力转向新代码库的功能,并在另一篇文章“迁移到 MQL5 Algo Forge(第一部分):创建主存储库”中介绍了初步步骤。 利用新存储库功能的策略仍在开发中。总体来说,我希望建立一种能力,使我们能够同时沿多个方向开展库部分的开发工作。这是否可行,还有待观察。
这个过程需要练习。这是唯一能让我们了解所做出的架构决策是否正确的方法。那么,让我们尝试使用已开发的名为 Advisor 的库来创建一个新项目。我们不会立即着手开发一个使用复杂交易策略的 EA 的大型项目。恰恰相反,我们将创建一个不以开发交易 EA 为目的的项目。
规划路径
有位读者就最近新增的策略 — SimpleCandles — 提出了一个很有意思的问题。在此策略中,参数之一是在给定时间周期内同一方向上连续蜡烛图的数量。因此,如果能有机会了解不同工具和不同时间周期下存在哪些此类蜡烛图序列,那将是非常好的,这样就不必把选择合适值的全部任务都留给优化器了。
事实上,即使是自动优化,仍然需要了解输入参数变化的限度。当然,你可以简单地设定一个较大的范围,但这会大大降低优化的效率。毕竟,参数组合的总数量将更大,而找到有效参数组合的概率则会更低。很难说具体能降低多少,但只要对这种下降有一个基本的了解,就足以尝试做出一些努力来提高效率。
收集这类关于不同交易品种价格行为的信息,也有助于回答以下问题:“不同的工具可以使用相同的参数范围吗?”如果是这样,那么这将简化第一阶段优化的组织工作。若非如此,那么在此阶段创建优化任务将不得不更为复杂。
一般来说,我们会尝试创建一个辅助 EA 或 EA 的一部分,以便能够以某种形式向我们显示一些关于交易品种和时间周期的统计数据。或许将来我们会发现它在交易策略中很有用。
但这将是第二个问题。首先,我们要解决的是如何组织源代码的存放方式,以便今后能在其他项目中复用。
创建一个项目
乍一看,这里似乎没有什么复杂的。我们之前曾以某种方式存储过代码,现在也可以继续这样做。但仍然存在差异。当我们把整个项目代码存储在一个文件夹中,对于每个后续项目,我们只需创建一个新文件夹,将之前项目的代码复制到其中,这是一种方法。这种方法的优点在于其简单性,并且在严格一致的开发中完全合理,无需担心向后兼容性。在初始阶段,当重大变化频繁发生时,这会方便得多。但当我们的项目开始发展壮大时,情况就不同了。在这个阶段,项目会明显分为两部分:一部分几乎不会发生变化,另一部分则可能会发生重大变化或需要从头开始创建。
在这种情况下,我们认为,将所有代码存储在一个文件夹中的缺点开始超过这种方法的优点。不久前,我们已经将大部分代码移到了 MQL5/Include/antekov/Advisor 文件夹中,并将这部分称为库部分。但现在看来,将库放在这个位置似乎不太方便。
假设我们正在并行开发两个使用 Advisor 库的项目。更改主要影响项目部分,但也对库部分进行了一些修改。如果两个项目都引用了位于同一位置( MQL5/Include/antekov/Advisor )的同一套库代码,则很可能发生冲突。为了避免这种情况,在从一个项目切换到另一个项目时,我们至少需要将库部分切换到存储在存储库另一个分支中的相应版本。虽然这并不复杂,但进行此类操作的需求却令人不快。你可能会在某天忘记切换,然后不得不清理已经在错误分支上进行的编辑,将它们移动到另一个分支。
所以,让我们尝试改变一下方法。每个项目都将是一个独立的代码仓库。项目文件夹内总会有一个名为 Include 的文件夹,其中包含库部件所在的文件夹。请注意:不是使用单个库部件,而是使用分布在多个不同文件夹中的多个库部件。每个库部分都将是一个独立代码仓库的克隆。
库部分仓库
对于库部分,我们将在 MQL5 Algo Forge 或任何其他公共 GIT 存储库上创建一个新的存储库。我们觉得之前给库起的名字 “Advisor” 太笼统了。让我们通过将其重命名为 Adwizard 来增加一些独特性。我们将继续这样称呼我们的库。
让我们把所有库部件文件都放到这个仓库里。创建存储库后,它包含一个名为 main 的分支。创建一个名为 develop 的新分支,文章和新库功能的分支将从该分支生成。这些辅助分支将在新功能实现后关闭,修改内容将合并到 develop 分支,然后合并到 main 分支。通常,这会在当我完成一篇文章的工作后发生。
为了确保此存储库中的代码在克隆到任何文件夹时都能正常工作,我们需要对一些库文件进行一些微小的修改。在 #include 指令中需要用到它们,因为我们使用了指向包含标准库的 Include 文件夹的路径。将它们替换为相对路径后,我们删除了指向 MQL5/Include/antekov/Advisor 文件夹中特定库位置的链接。
例如,在 Optimization.mqh 文件中进行了以下替换:
#include <antekov/Advisor/Optimization/Optimizer.mqh> #include "../Optimization/Optimizer.mqh"
在 OptimizerTask.mqh 文件中,我们仍然使用了来自 fxsaber 的第三方库的单个文件。我们还将其移动到了库内的 Utils 文件夹中:
#include <antekov/Advisor/Database/Database.mqh> #include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132 #include "../Database/Database.mqh" #include "../Utils/MTTester.mqh" // https://www.mql5.com/ru/code/26132
这些修改已提交到库的存储库。
项目仓库
为该项目创建一个新的 SymbolsInformer 存储库。在这个仓库中,除了 main 分支之外,我们还将创建一个名为 develop 的开发分支。如果这个项目将由多篇文章涵盖,那么建议将与不同文章相关的编辑工作拆分到不同的分支中。它们将从 develop 分支生成,并在准备就绪后合并回 develop 分支和 main 分支。
让我们创建一个文件夹来存放项目文件夹,例如 MQL5/Experts/Article/17606 。将此存储库克隆到选定的文件夹中,并在其中创建 Include 文件夹。在这个文件夹中,我们将放置本项目所依赖的其他库的存储库。目前只会有一个库 — Adwizard 。Include 文件夹接收克隆的 Adwizard 库存储库。如果需要另一个库,我们会将其克隆到同一个 Include 文件夹中。
经过这些操作后,我们将在终端文件夹中大致得到以下文件夹结构:
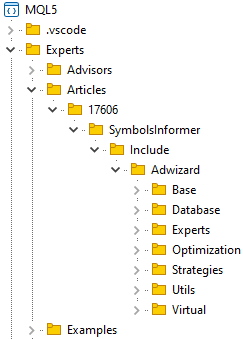
在 Adwizard 存储库的克隆文件夹中,切换到 develop 分支。这将是所有文章的共同点。如果我们在开发本项目期间不对 Adwizard 库进行任何更改,我们将保持在 develop 分支中,并在开发其他文章时进行新的编辑时更新它。如果在当前项目开发过程中,我们需要修复这个库中的某些问题,那么我们将创建一个新的分支。
在此之后,我们在项目存储库中创建一个分支,用于处理本文,并开始在该分支中进行开发。这里我们简要介绍了如何创建一个新项目。我会在另一篇文章中详细介绍。
项目描述
让我们尝试为所需工具的开发制定一份简短的技术规范。它将以 EA 的形式实现,因为它不包含那种需要周期性重算、并持续显示随时间变化数值的计算参数。
首先,为了统计单向蜡烛图序列的数量,我们需要设定一个特定的时间段,在此期间收集相关统计数据。这可以通过不同的方式来实现。例如,你可以指定从当前日期开始的天数,或者指定两个不同的日期来表示开始和结束。或许,首先,我们只会计算从当前日期开始的区间的统计数据。可以通过选择时间周期(例如,每日)及其蜡烛图数量来设置持续时间。我们称之为主要时间周期。
接下来,我们需要以某种方式指明我们想要针对哪些交易工具(交易品种)以及在哪些时间周期内进行计算。当然,也可以只针对开发的 EA 将要运行的交易品种和时间周期进行计算。但最好还是立即加入对多个交易品种和时间周期进行计算的功能。
基于以上内容,我们来整理一份 EA 输入参数列表:
- 主要时间周期
- 主要时间周期上的蜡烛图数量
- 交易品种列表
- 时间周期列表
这组参数将来可能会进行扩展。交易品种和时间周期列表将包含它们的名称,并以逗号分隔。我们将按照终端中命名的方式设置时间周期的名称,例如 M5、M15、H1 等。
对于每个交易品种和时间周期,我们将计算以下值:
- 平均蜡烛尺寸:
- 看涨(“上涨”或“买入”蜡烛,其收盘价不低于开盘价);
- 看跌(“下跌”或“卖出”蜡烛,其收盘价不高于开盘价);
- 全部(包括看涨和看跌的);
- 序列的平均长度(序列是指两个或多个方向相同的蜡烛图序列);
- 长度如下的序列的数量:
- 2
- 3
- ...
- 8
- 9
这个列表也是开放的,这意味着如果我们愿意,可以向其中添加新的计算值。
实现第一个版本
首先,让我们尝试制作最简单的版本。我们将把计算出的值存储在全局数组中,并以某种形式在日志和图表上作为注释显示结果。我们尚不清楚哪些数据对我们有用,哪些数据毫无意义。因此,我们主要使用第一个版本来确定我们实际需要的内容。其中,我们将不太注重检查输入的一致性以及安排信息的存储。
根据已整理的列表,输入参数可以设置如下:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Calculation period" sinput ENUM_TIMEFRAMES mainTimeframe_ = PERIOD_D1; // Main timeframe input int mainLength_ = 30; // Number of candles on the main timeframe input group "::: Symbols and timeframes " sinput string symbols_ = ""; // Symbols (comma separated) sinput string timeframes_ = ""; // Timeframes (e.g. M5, H1, H4)
由于输入在一个字符串中指定了多个交易品种和时间周期,我们需要数组来存储每个交易品种名称和每个时间周期的单独值。
我们将创建二维数组来存储计算值。第一个索引与交易品种相关联,第二个索引与时间周期相关联。由于在声明二维数组时,需要指定第二个维度上的元素数量,因此我们将引入 TFN 常量,其中我们将指示所有当前存在的标准时间周期的数量,结果为 21。
// Number of existing timeframes #define TFN (21) // Global variables string g_symbols[]; // Array of all used symbols ENUM_TIMEFRAMES g_timeframes[]; // Array of all used timeframes // Arrays of calculated values. // The first index is a symbol, the second index is a timeframe double symbolAvrCandleSizes[][TFN]; // Array of average sizes of all candles double symbolAvrBuyCandleSizes[][TFN]; // Array of average sizes of bullish candles double symbolAvrSellCandleSizes[][TFN]; // Array of average sizes of bearish candles double symbolAvrSeriesLength[][TFN]; // Array of average series lengths int symbolCountSeries2[][TFN]; // Array of the number of series of length 2 int symbolCountSeries3[][TFN]; // Array of the number of series of length 3 int symbolCountSeries4[][TFN]; // Array of the number of series of length 4 int symbolCountSeries5[][TFN]; // Array of the number of series of length 5 int symbolCountSeries6[][TFN]; // Array of the number of series of length 6 int symbolCountSeries7[][TFN]; // Array of the number of series of length 7 int symbolCountSeries8[][TFN]; // Array of the number of series of length 8 int symbolCountSeries9[][TFN]; // Array of the number of series of length 9
为了在时间周期常量(如 ENUM_TIMEFRAMES )、其字符串名称和索引之间进行转换,我们将提供所有时间周期数组中的辅助函数。借助这些函数,我们可以解决三个问题:
- 通过字符串名称获取时间周期常量( StringToTimeframe )
- 从符号常量中获取时间周期的字符串名称,不带 PERIOD_ 前缀( TimeframeToString )。
- 从符号常量 ( TimeframeToIndex ) 获取所有时间周期数组的索引
// Array of all timeframes ENUM_TIMEFRAMES tfValues[] = { PERIOD_M1, PERIOD_M2, PERIOD_M3, PERIOD_M4, PERIOD_M5, PERIOD_M6, PERIOD_M10, PERIOD_M12, PERIOD_M15, PERIOD_M20, PERIOD_M30, PERIOD_H1, PERIOD_H2, PERIOD_H3, PERIOD_H4, PERIOD_H6, PERIOD_H8, PERIOD_H12, PERIOD_D1, PERIOD_W1, PERIOD_MN1 }; //+------------------------------------------------------------------+ //| Convert a string name to a timeframe | //+------------------------------------------------------------------+ ENUM_TIMEFRAMES StringToTimeframe(string s) { // If the string contains the "_" symbol, leave only the characters that follow it int pos = StringFind(s, "_"); if(pos != -1) { s = StringSubstr(s, pos + 1); } // Convert to uppercase StringToUpper(s); // Arrays of corresponding string names of timeframes string keys[] = {"M1", "M2", "M3", "M4", "M5", "M6", "M10", "M12", "M15", "M20", "M30", "H1", "H2", "H3", "H4", "H6", "H8", "H12", "D1", "W1", "MN1" }; // Search for a match and return it if found FOREACH(keys) { if(keys[i] == s) return tfValues[i]; } return PERIOD_CURRENT; } //+------------------------------------------------------------------+ //| Convert a timeframe to a string name | //+------------------------------------------------------------------+ string TimeframeToString(ENUM_TIMEFRAMES tf) { // Get the timeframe name of the 'PERIOD_*' type string s = EnumToString(tf); // Return the part of the name after the '_' symbol return StringSubstr(s, StringFind(s, "_") + 1); } //+------------------------------------------------------------------+ //| Convert a timeframe to an index in an array of all timeframes | //+------------------------------------------------------------------+ int TimeframeToIndex(ENUM_TIMEFRAMES tf) { // Search for a match and return it if found FOREACH(tfValues) { if(tfValues[i] == tf) return i; } return WRONG_VALUE; }
所有值的计算将在 Calculate() 函数内部执行。在函数中设置一个嵌套循环,遍历所有交易品种和时间周期的组合。在它们内部,我们将检查该特定交易品种和时间周期是否有新的蜡烛图出现。如果答案是肯定的,那么我们就调用辅助计算函数。也可以通过 force 参数来指示是否需要立即计算所有值而无需等待新蜡烛图出现。启动 EA 时将使用此模式,以便我们可以立即看到结果。
//+------------------------------------------------------------------+ //| Calculate all values | //+------------------------------------------------------------------+ void Calculate(bool force = false) { string symbol; ENUM_TIMEFRAMES tf; // For each symbol and timeframe FOREACH_AS(g_symbols, symbol) { FOREACH_AS(g_timeframes, tf) { // If a new bar has arrived for the given symbol and timeframe, then if(IsNewBar(symbol, tf) || force) { // Find the number of candles for calculation int n = PeriodSeconds(mainTimeframe_) * mainLength_ / PeriodSeconds(tf); // Calculate the average candle sizes CalculateAvrSizes(symbol, tf, n); // Calculate the lengths of candlestick series CalculateSeries(symbol, tf, n); } } } }
我们将直接计算放在了两个辅助函数中。它们各自只针对一个时间周期内的一个交易品种进行计算。除了这两个参数之外,我们还要传递第三个参数 — 计算将基于的蜡烛图数量。
平均值在 CalculateAvrSizes() 函数中计算。 首先,我们使用交易品种和时间周期名称来定义用于存储此结果的二维数组中元素的 s 和 t 索引。开盘价等于收盘价的蜡烛图既被视为上涨蜡烛图,也被视为下跌蜡烛图。计算出的平均值将四舍五入到整数。
//+------------------------------------------------------------------+ //| Calculate average candle sizes | //+------------------------------------------------------------------+ void CalculateAvrSizes(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Number of up and down candles int nBuy = 0, nSell = 0; // Zero out the elements for the calculated average values symbolAvrCandleSizes[s][t] = 0; symbolAvrBuyCandleSizes[s][t] = 0; symbolAvrSellCandleSizes[s][t] = 0; // For all candles FOREACH(rates) { // Find the candle size double size = rates[i].high - rates[i].low; // Add it to the total size of all candles symbolAvrCandleSizes[s][t] += size; // If this is a bullish candle, then we take it into account if(IsBuyRate(rates[i])) { symbolAvrBuyCandleSizes[s][t] += size; nBuy++; } // If this is a downward candle, take it into account if(IsSellRate(rates[i])) { symbolAvrSellCandleSizes[s][t] += size; nSell++; } } // Get the size of one point for a symbol double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Find the average values in points symbolAvrCandleSizes[s][t] /= n * point; symbolAvrBuyCandleSizes[s][t] /= nBuy * point; symbolAvrSellCandleSizes[s][t] /= nSell * point; // Round them to whole points symbolAvrCandleSizes[s][t] = MathRound(symbolAvrCandleSizes[s][t]); symbolAvrBuyCandleSizes[s][t] = MathRound(symbolAvrBuyCandleSizes[s][t]); symbolAvrSellCandleSizes[s][t] = MathRound(symbolAvrSellCandleSizes[s][t]); } }
CalculateSeries() 函数中序列长度的计算方式类似。它使用由 100 个元素组成的辅助 seriesLens 数组。这个数组中每个元素的索引对应一个序列的长度,而该元素本身则对应具有该长度的序列的数量。因此,我们假定绝大多数序列的长度都不会超过 100 根蜡烛图。我们将只显示长度小于 10 根蜡烛图的序列数量。我们将 seriesLens 数组中长度完全相同的序列数重写为 symbolCountSeries* 类型结果的相应数组元素。
//+------------------------------------------------------------------+ //| Calculate the lengths of candlestick series | //+------------------------------------------------------------------+ void CalculateSeries(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Current series length int curLen = 0; // Direction of the previous candle bool prevIsBuy = false; bool prevIsSell = false; // Array of numbers of series of different lengths (index = series length) int seriesLens[]; // Set the size and initialize ArrayResize(seriesLens, 100); ArrayInitialize(seriesLens, 0); // For all candles FOREACH(rates) { // Determine the candle direction bool isBuy = IsBuyRate(rates[i]); bool isSell = IsSellRate(rates[i]); // If the direction is the same as the previous one, then if((isBuy && prevIsBuy) || (isSell && prevIsSell)) { // Increase the series length curLen++; } else { // Otherwise, if the length is within the required range, then if(curLen > 1 && curLen < 100) { // Increase the counter of the length series seriesLens[curLen]++; } // Reset the current series length curLen = 1; } // Save the direction of the current candle as the previous one prevIsBuy = isBuy; prevIsSell = isSell; } // Initialize the array element for the average series length symbolAvrSeriesLength[s][t] = 0; int count = 0; // For all series lengths we find the sum and quantity FOREACH(seriesLens) { symbolAvrSeriesLength[s][t] += seriesLens[i] * i; count += seriesLens[i]; } // Calculate the average length of candlestick series symbolAvrSeriesLength[s][t] /= (count > 0 ? count : 1); // Copy the values of the series lengths into the final arrays symbolCountSeries2[s][t] = seriesLens[2]; symbolCountSeries3[s][t] = seriesLens[3]; symbolCountSeries4[s][t] = seriesLens[4]; symbolCountSeries5[s][t] = seriesLens[5]; symbolCountSeries6[s][t] = seriesLens[6]; symbolCountSeries7[s][t] = seriesLens[7]; symbolCountSeries8[s][t] = seriesLens[8]; symbolCountSeries9[s][t] = seriesLens[9]; } }
Show() 函数负责显示结果。在第一个版本中,我们暂时只将输出限制在终端日志中,并在 EA 将要启动的图表上添加注释。因此,我们只需以文本形式呈现结果即可。单独的 TextComment() 函数负责将这些结果组织成文本形式。
//+------------------------------------------------------------------+ //| Show results | //+------------------------------------------------------------------+ void Show() { // Get the results as text string text = TextComment(); // Show it in the comment and in the log Comment(text); Print(text); }
在 EA 初始化函数中,我们只需要处理输入参数,将列出的交易品种名称和时间周期分成单独的值,并准备所需大小的数组来记录结果。之后,我们可以调用该函数来计算并显示结果:
//+------------------------------------------------------------------+ //| Initialize the EA | //+------------------------------------------------------------------+ int OnInit(void) { // Fill in the symbol array for calculations from the inputs SPLIT(symbols_, g_symbols); // If no symbols are specified, use the current single symbol if(ArraySize(g_symbols) == 0) { APPEND(g_symbols, Symbol()); } // Number of symbols for calculations int nSymbols = ArraySize(g_symbols); // Initialize arrays for calculated values Initialize(nSymbols); // Fill the array with timeframe names from the inputs string strTimeframes[]; SPLIT(timeframes_, strTimeframes); ArrayResize(g_timeframes, 0); // If timeframes are not specified, use the current one if(ArraySize(strTimeframes) == 0) { APPEND(strTimeframes, TimeframeToString(Period())); } // Fill the timeframe array from the timeframe names array FOREACH(strTimeframes) { ENUM_TIMEFRAMES tf = StringToTimeframe(strTimeframes[i]); if(tf != PERIOD_CURRENT) { APPEND(g_timeframes, tf); } } // Perform a forced recalculation Calculate(true); // Show the results Show(); return(INIT_SUCCEEDED); }
在上面的函数中,我们使用了一个新的 SPLIT 宏。它被添加到 Adwizard 库的 Utils/Macros.mqh 文件中。这是目前为止本项目所需的唯一库新增内容。
该宏本身旨在使用两种可能的分隔符(逗号和分号)将字符串拆分为多个部分。
#define SPLIT(V, A) { string s=V; StringReplace(s, ";", ","); StringSplit(s, ',', A); }
现在让我们来看看开发的 EA 的工作结果。
EA 测试
让我们在某个图表上使用默认参数启动 EA。然后,你可以看到类似以下的内容:
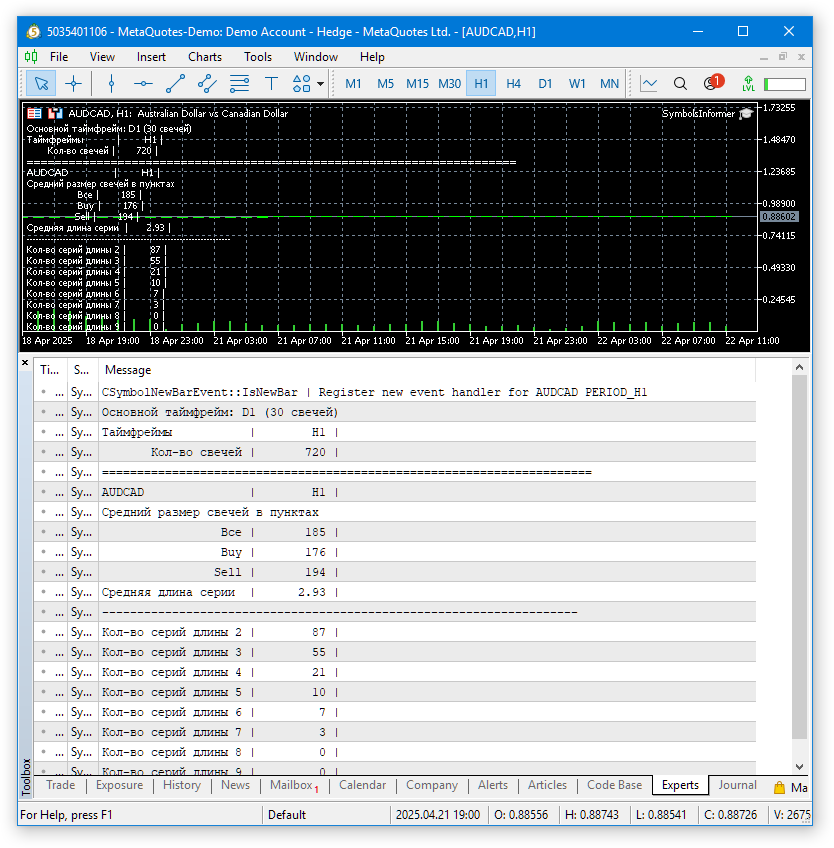
图 1.在 AUDCAD H1 上使用默认参数运行 EA 的结果
由于图表上的注释使用了非等宽字体,因此查看图表上的数值并不特别方便。终端日志使用等宽字体,因此在那里查看会更清晰、更方便。让我们看看在几个不同的交易品种和时间周期下,结果会如何。
让我们使用以下输入参数运行 EA:
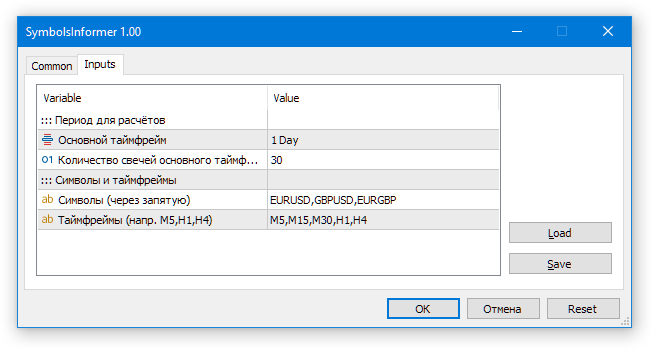
现在来看看结果。
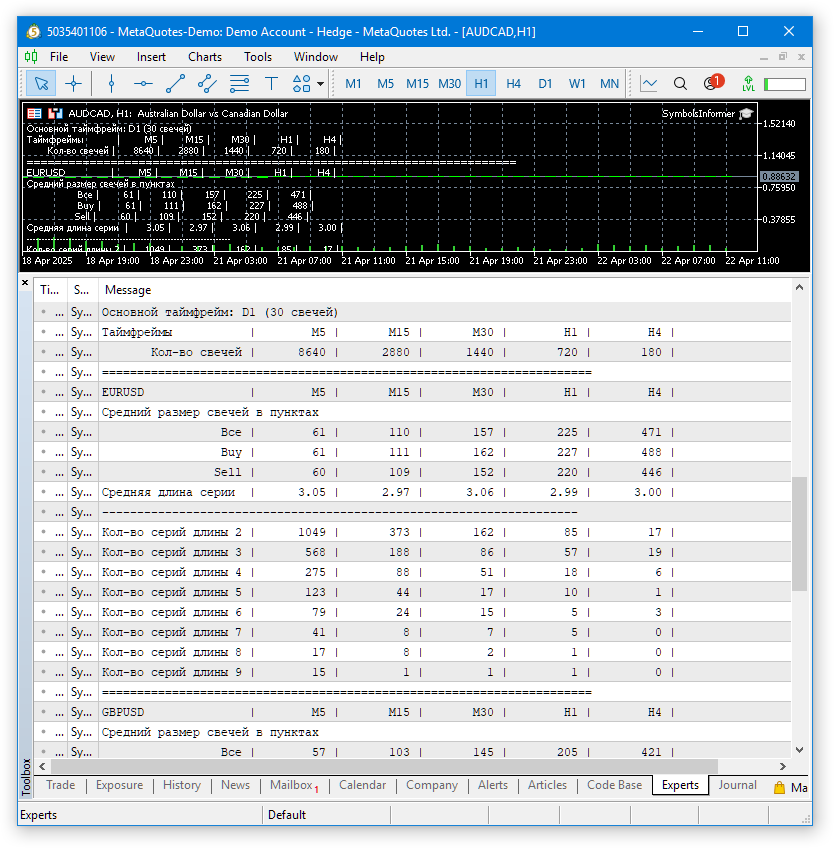
图 2.EA 在多个交易品种和时间周期下的结果
已成功完成多个交易品种和时间周期的计算。结果如表格所示。它们目前使用起来还不是特别方便,但仍然足以进行快速的初步分析。
结论
我们创建了第一个辅助信息工具 EA 版本,显示有关平均蜡烛图大小(以点为单位)和同向移动的蜡烛图序列长度的信息。乍一看,这与我们创建自动优化系统并推出实现各种简单策略的多货币 EA 的主要项目看起来与我们的主项目只有比较间接的关系。这确实是真的,因此关于这个 EA 的工作将在本系列文章的范围之外继续进行。但在工作过程中,我们会尝试并测试许多方案的实现,并希望之后能成功将其应用于主要项目中。
现在我们已经做了很多事情。选择一种不同的、更优的代码组织结构,将有助于在 Adwizard 库开发的后续阶段实现不同领域工作的并行化。我已经在考虑未来的一些改进方向了。其中之一是构建一个可视化界面,用于管理最终 EA 的工作。本文所讨论的项目将帮助我们尝试各种可能的方法,而不会在实现非常复杂的事情上陷入困境。在权衡了它们的利弊并选择了最合适的一个之后,我们将能够更有针对性地专注于开发主要项目。
感谢您的关注!期待很快与您见面!
重要警告
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| SymbolsInformer | 项目工作文件夹 | |||
| 1 | SymbolsInformer.mq5 | 1.00 | 用于显示单向 K 线序列长度信息的 EA | 第 26 部分 |
| SymbolsInformer/Include/Adwizard/Base | 其他项目类所继承的基类 | |||
| 2 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 3 | Factorable.mqh | 1.05 | 从字符串创建的对象的基类 | 第 24 部分 |
| 4 | FactorableCreator.mqh | 1.00 | 绑定 CFactorable 派生类的名称和静态构造函数的创建器类 | 第 24 部分 |
| 5 | Interface.mqh | 1.01 | 可视化各种对象的基类 | 第 4 部分 |
| 6 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 7 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| SymbolsInformer/Include/Adwizard/Database | 用于处理项目 EA 使用的所有类型数据库的文件 | |||
| 8 | Database.mqh | 1.12 | 处理数据库的类 | 第 25 部分 |
| 9 | db.adv.schema.sql | 1.00 | 最终 EA 的数据库结构 | 第 22 部分 |
| 10 | db.cut.schema.sql | 1.00 | 截断优化数据库的结构 | 第 22 部分 |
| 11 | db.opt.schema.sql | 1.05 | 优化数据库结构 | 第 22 部分 |
| 12 | Storage.mqh | 1.01 | 用于处理 EA 数据库中最终 EA 的键值存储的类 | 第 23 部分 |
| SymbolsInformer/Include/Adwizard/Experts | 包含不同类型已使用 EA 的公共部分的文件 | |||
| 13 | Expert.mqh | 1.22 | 最终 EA 的库文件。组参数可以从 EA 数据库中获取。 | 第 23 部分 |
| 14 | Optimization.mqh | 1.04 | 用于管理优化任务启动 EA 的库文件 | 第 23 部分 |
| 15 | Stage1.mqh | 1.19 | 单实例交易策略优化 EA(第一阶段)的库文件 | 第 23 部分 |
| 16 | Stage2.mqh | 1.04 | 用于优化一组交易策略实例的 EA 的库文件(第二阶段) | 第 23 部分 |
| 17 | Stage3.mqh | 1.04 | EA 库文件,用于将生成的标准化策略组保存到具有给定名称的 EA 数据库中。 | 第 23 部分 |
| SymbolsInformer/Include/Adwizard/Optimization | 负责自动优化的类 | |||
| 18 | OptimizationJob.mqh | 1.00 | 优化项目阶段作业类 | 第 25 部分 |
| 19 | OptimizationProject.mqh | 1.00 | 优化项目类 | 第 25 部分 |
| 20 | OptimizationStage.mqh | 1.00 | 优化项目阶段类 | 第 25 部分 |
| 21 | OptimizationTask.mqh | 1.00 | 优化任务类(创建) | 第 25 部分 |
| 22 | Optimizer.mqh | 1.03 | 项目自动优化管理器类 | 第 22 部分 |
| 23 | OptimizerTask.mqh | 1.03 | 优化任务类(流水线) | 第 22 部分 |
| SymbolsInformer/Include/Adwizard/Strategies | 用于演示项目工作方式的交易策略示例 | |||
| 24 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 25 | SimpleVolumesStrategy.mqh | 1.11 | 使用分时交易量的交易策略类 | 第 22 部分 |
| SymbolsInformer/Include/Adwizard/Utils | 辅助工具、用于代码简化的宏 | |||
| 26 | ExpertHistory.mqh | 1.00 | 用于将交易历史导出到文件的类 | 第 16 部分 |
| 27 | Macros.mqh | 1.07 | 用于数组操作的有用的宏 | 第 26 部分 |
| 28 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新 K 线的类 | 第 8 部分 |
| 29 | SymbolsMonitor.mqh | 1.00 | 用于获取交易工具(交易品种)信息的类 | 第 21 部分 |
| SymbolsInformer/Include/Adwizard/Virtual | 通过使用虚拟交易订单和头寸系统创建各种对象的类 | |||
| 30 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 31 | TesterHandler.mqh | 1.07 | 优化事件处理类 | 第 23 部分 |
| 32 | VirtualAdvisor.mqh | 1.10 | 处理虚拟仓位(订单)的 EA 类 | 第 24 部分 |
| 33 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 34 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 35 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 36 | VirtualOrder.mqh | 1.09 | 虚拟订单和仓位类 | 第 22 部分 |
| 37 | VirtualReceiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 23 部分 |
| 38 | VirtualRiskManager.mqh | 1.05 | 风险管理类(风险管理器) | 第 24 部分 |
| 39 | VirtualStrategy.mqh | 1.09 | 具有虚拟仓位的交易策略类 | 第 23 部分 |
| 40 | VirtualStrategyGroup.mqh | 1.03 | 交易策略组类 | 第 24 部分 |
| 41 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
源代码同时可在以下公共仓库中获取:SymbolsInformer 和 Adwizard
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17606
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
简直太丢人了(
明天我会仔细研究您这篇内容丰富的评论
@Rashid Umarov
你好
你是否一直在密切关注这个帖子,并且能够实现所有内容并进行优化?
能否请你帮我完成这些工作?
祝好