
Forex veri analizinde ilişkilendirme kurallarını kullanma

İlişkilendirme kuralları kavramına giriş
Modern algoritmik alım-satım, analiz için yeni yaklaşımlar gerektirir. Piyasa sürekli değişiyor ve klasik teknik analiz yöntemleri artık karmaşık piyasa ilişkilerini tanımlamakla başa çıkamıyor.
Uzun süredir verilerle çalışıyorum ve birçok başarılı fikrin birbiriyle ilişkili alanlardan geldiğini fark ettim. Bugün, alım-satımda ilişkilendirme kurallarını kullanma deneyimimi paylaşmak istiyorum. Bu yöntem perakende analitiğinde kendini kanıtlamıştır ve satın almalar, işlemler, fiyat hareketleri ve gelecekteki arz ve talep arasındaki bağlantıları bulmamızı sağlar. Bunu döviz piyasasına uygularsak ne olur?
Temel fikir basittir - istikrarlı fiyat davranışı kalıpları, göstergeler ve bunların kombinasyonlarını arıyoruz. Örneğin, USDJPY'deki bir düşüşün ardından EURUSD'de ne sıklıkla bir yükseliş görülür? Ya da güçlü hareketlerden önce en sık hangi koşullar ortaya çıkar?
Bu makalede, bu fikre dayalı bir alım-satım sistemi oluşturma sürecinin tamamını göstereceğim. Şunları yapacağız:
- MQL5'te geçmiş verileri toplama
- Bunları Python'da analiz etme
- Önemli kalıpları bulma
- Bunları işlem sinyallerine dönüştürme
Neden bu özel dizilim? MQL5, borsa verileri ve alım-satım otomasyonu ile çalışmak için mükemmeldir. Buna karşılık Python, analiz için güçlü araçlar sağlar. Deneyimlerime dayanarak, böyle bir kombinasyonun alım-satım sistemleri geliştirmek için çok etkili olduğunu söyleyebilirim.
Kodda, yani Forex'e ilişkilendirme kuralları uygulama alanında pek çok ilginç şey olacak.
Geçmiş Forex verilerinin toplanması ve hazırlanması
İhtiyacımız olan tüm verileri toplamak ve hazırlamak bizim için son derece önemlidir. Son iki yıl için (2022'den beri) ana döviz paritelerinin H1 verilerini temel alalım.
Şimdi ihtiyacımız olan verileri toplayacak ve CSV formatında dışa aktaracak bir MQL5 komut dosyası oluşturacağız:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Python'da verileri işleme
Bir veri kümesi oluşturduktan sonra, verilerin doğru bir şekilde işlenmesi önemlidir.
Bu amaçla, tüm zahmetli işlerle ilgilenen özel ForexDataProcessor sınıfını oluşturdum. Ana bileşenlerine bir göz atalım.
Verileri yüklemekle başlayacağız. Fonksiyonumuz ana döviz paritelerinin saatlik verileriyle çalışır - EURUSD, GBPUSD, USDJPY ve USDCHF. Veriler, ana fiyat bilgilerini içeren CSV formatında olmalıdır.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Yükleme işlemi başarıyla tamamlandıktan sonra, en ilginç kısım başlar - teknik göstergelerin hesaplanması. Burada, zaman içinde kendini kanıtlamış çok sayıda araca başvuruyorum. Hareketli ortalamalar, değişen sürelerdeki trendlerin belirlenmesine yardımcı olur. SMA(50) genellikle dinamik destek veya direnç görevi görür. Klasik periyodu 14 olan RSI osilatörü, aşırı alış ve aşırı satış piyasa bölgelerini belirlemek için iyidir. MACD, momentum ve terse dönüş noktalarını belirlemek için vazgeçilmezdir. Bollinger Bands mevcut piyasa volatilitesinin net bir resmini verir.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
Veri ayrıklaştırma özel bir ilgiyi hak etmektedir. Tüm sürekli değerlerin net kategorilere ayrılması gerekir. Bu konuda altın ortalamayı bulmak önemlidir - çok keskin bir ayrım kalıp arayışını zorlaştıracak, çok yakın bir ayrım ise önemli piyasa nüanslarının kaybolmasına yol açacaktır. Örneğin, trendi belirlemek için, daha basit bir ayrım daha iyi çalışır - fiyatın ortalamaya göre konumuna bağlı olarak:
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Mum formasyonları da özel bir yaklaşım gerektirir. İstatistiksel analize dayanarak, en küçük mum gövdesi boyutunda Doji’yi, aşırı fiyat hareketlerinde ise Long_Bullish ve Long_Bearish’i ayrıştırıyorum. Bu sınıflandırma, piyasanın kararsızlık anlarını ve güçlü hareketlerini net bir şekilde belirlememizi sağlar.
Verileri işlemenin sonunda, tüm döviz pariteleri ortak bir zaman ölçeğine sahip tek bir veri dizisinde birleştirilir. Bu adım temel bir öneme sahiptir - farklı enstrümanlar arasındaki karmaşık ilişkilerin araştırılmasına olanak sağlar. Artık bir paritenin trendinin diğerinin volatilitesini nasıl etkilediğini veya mum formasyonlarının tüm piyasadaki işlem hacimleriyle nasıl ilişkili olduğunu görebiliriz.
Python'da Apriori algoritmasının uygulanması
Verileri hazırladıktan sonra, ana aşamaya geçiyoruz - finansal verilerimizdeki ilişkilendirme kurallarını bulmak için Apriori algoritmasını uyguluyoruz. Başlangıçta market sepetlerini analiz etmek için geliştirilen Apriori algoritmasını döviz paritelerinin zaman serileriyle çalışmak üzere uyarlıyoruz.
Döviz piyasası bağlamında "işlem", zamanın belirli bir noktasında çeşitli göstergelerin ve döviz paritelerinin durumlarının bir kümesidir. Örneğin:- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
Algoritma, bu tür durumların sıkça ortaya çıkan kombinasyonlarını arar ve buna dayanarak işlem kuralları oluşturulur.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Döviz paritesi analizi için ilişkilendirme kurallarının uyarlanması
Apriori algoritmasını döviz piyasasına uyarlama çalışmalarım sırasında ilginç zorluklarla karşılaştım. Bu yöntem aslında market içi satın alımları analiz etmek için oluşturulmuş olsa da, Forex için potansiyeli bana umut verici göründü.
Asıl zorluk, Forex piyasasının bir marketteki normal alışverişten kökten farklı olmasıydı. Finans piyasalarında çalıştığım yıllar boyunca, sürekli değişen fiyatlar ve göstergelerle uğraşmaya alıştım. Ancak genellikle süpermarket fişlerinde sadece muz ve süt arasındaki bağlantıları arayan bir algoritmayı nasıl uygularsınız?
Yaptığım denemeler sonucunda beş ölçütten oluşan bir sistem doğdu. Her birini iyice test ettim.
'Support' çok zorlu bir ölçüt olarak ortaya çıktı. Bir keresinde bir alım-satım sistemine neredeyse mükemmel performansa sahip bir kural dahil ediyordum, ancak support sadece 0.02'ydi. Neyse ki bunu zamanında fark ettim - pratikte böyle bir kural sadece her yüz yılda bir devreye girer!
'Confidence' daha basitmiş. Piyasada çalıştığınızda, %70'lik bir olasılığın bile mükemmel bir gösterge olduğunu çabucak öğrenirsiniz. Önemli olan kalan %30 ile riskleri akıllıca yönetmektir. Risk yönetimini her zaman aklımızda tutmalıyız. Bu olmadan, elinizde bir Kase olsa bile bir düşüş veya hatta ciddi bir kayıpla karşı karşıya kalacaksınız.
'Lift' benim favori göstergem haline geldi. Yüzlerce saat süren testlerden sonra, bir kalıp fark ettim - 1.5'in üzerinde lift'e sahip kurallar gerçek piyasada işe yarıyor. Bu keşfin sinyal sıralama yaklaşımım üzerinde önemli bir etkisi oldu.
'Leverage' ile uğraşmak komik bir deneyimdi. İlk başta işe yaramadığını düşünerek sistemden tamamen çıkarmak istedim. Ancak piyasadaki özellikle dalgalı bir dönemde, yanlış sinyallerin çoğunun ayıklanmasına yardımcı oldu.
'Conviction' forumları araştırdıktan sonra en son eklendi. Bu göstergenin, bulunan kalıpların gerçek önemini değerlendirmek için ne kadar gerekli olduğunu anlamama yardımcı oldu.
Benim için en şaşırtıcı şey, algoritmanın farklı döviz pariteleri arasında beklenmedik bağlantıları nasıl bulduğuydu. Örneğin, EURUSD'deki belirli kalıpların USDJPY hareketlerini bu kadar doğru bir şekilde tahmin edebileceğini kim düşünebilirdi? Piyasada çalıştığım 9 yıl boyunca, algoritmanın keşfettiği ilişkilerin çoğunu fark etmedim. İkili işlem (pair trading), sepet işlemi (basket trading) ve arbitraj bir zamanlar benim alanım olmasına rağmen. cmillion'ın paritelerin karşılıklı hareketlerine dayalı robotlarını yeni geliştirmeye başladığı zamanları hala hatırlıyorum.
Şimdi araştırmalarıma devam ediyor, yeni gösterge ve zaman dilimi kombinasyonlarını test ediyorum. Piyasa sürekli değişiyor ve her gün yeni keşifler getiriyor. Önümüzdeki hafta, sistemi yıllık veriler üzerinde test etmenin sonuçlarını ve algoritmanın canlı demo işlemlerindeki ilk sonuçlarını yayınlamayı planlıyorum. Burada çok ilginç birkaç bulgu var.
Dürüst olmak gerekirse, bu projenin bu kadar ileri gideceğini tahmin bile etmiyordum. Her şey veri madenciliği üzerine yapılan basit bir deneme ve sınıflandırma algoritmalarının ihtiyaçları için tüm piyasa hareketlerini katı bir şekilde sınıflandırma girişimleri olarak başladı ve sonunda tam teşekküllü bir alım-satım sistemine dönüştü. Sanırım bu yaklaşımın gerçek potansiyelini yeni yeni anlamaya başlıyorum.
Forex için uygulama özellikleri
Kodun kendisine biraz geri dönelim. Kodumuz, finansal verileri işlemek için algoritmanın birkaç önemli uyarlamasına sahiptir:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Bu gruplandırma, göstergelerin daha anlamlı kombinasyonlarının bulunmasına yardımcı olur ve hesaplama karmaşıklığını azaltır.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Yalnızca güçlü istatistiksel anlamlılığa (lift > 1.5) ve trend göstergelerinin veya RSI'ın zorunlu olarak dahil edilmesine sahip kuralları seçiyoruz.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
Ağırlıklı puan, kuralların alım-satım için potansiyel yararlılıklarına göre sıralanmasına yardımcı olur.
Bulunan ilişkilerin görselleştirilmesi
İlişkilendirme kurallarını bulduktan sonra bunları doğru bir şekilde görselleştirmeli ve analiz etmeliyiz. Bu amaçla, bulunan kalıpların görsel analizi için çeşitli yollar sağlayan özel ForexRulesVisualizer sınıfını geliştirdim.
Kural ölçütlerinin dağılımı
Analizdeki ilk adım, bulunan kuralların ana ölçütlerinin dağılımını anlamaktır. 'Support', 'confidence', 'lift' ve 'leverage' dağılım grafiği, bulunan kuralların kalitesini değerlendirmeye ve gerekirse algoritma parametrelerini ayarlamaya yardımcı olur.
Özellikle faydalı bir araç, farklı piyasa koşulları arasındaki bağlantıları net bir şekilde gösteren etkileşimli ağ grafiğiydi. Bu grafikte, düğümler gösterge durumlarıdır (örneğin "EURUSD_Trend=Uptrend" veya "USDJPY_RSI_Zone=Overbought") ve kenarlar, kenar kalınlığının 'lift' değeriyle orantılı olduğu bulunan kuralları temsil eder.
Döviz paritesi etkileşimlerinin ısı haritası 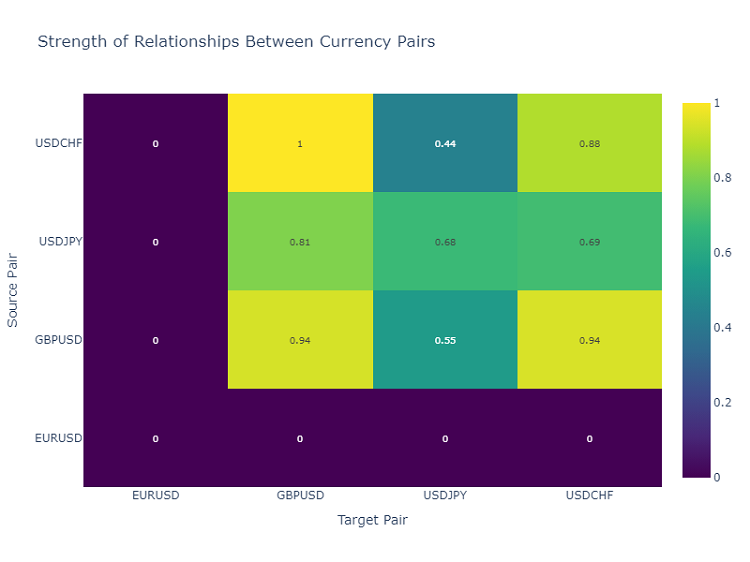
Döviz pariteleri arasındaki ilişkileri analiz etmek için, farklı enstrümanlar arasındaki ilişkilerin gücünü gösteren bir ısı haritası kullanıyorum. Bu, birbirini en sık etkileyen paritelerin belirlenmesine yardımcı olur ve çeşitlendirilmiş bir alım-satım portföyü oluşturmak için kritik öneme sahiptir.
İşlem sinyalleri oluşturma
İlişkilendirme kurallarını bulduktan ve görselleştirdikten sonra, bir sonraki önemli adım bunları işlem sinyallerine dönüştürmektir. Bu amaçla, piyasanın mevcut durumunu analiz eden ve bulunan kurallara göre işlem sinyalleri üreten ForexSignalGenerator sınıfını geliştirdim.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Kuralların gücünün değerlendirilmesi
Kuralların görselleştirilmesiyle ilgili uzun denemelerin ardından, en zor kısmın zamanı geldi - gerçek işlem sinyalleri oluşturmak. İtiraf ediyorum, bu görev beni biraz terletti. Grafiklerde güzel kalıplar bulmak bir şeydir ve bunları çalışan bir alım-satım sistemine dönüştürmek oldukça başka bir şeydir.
ForexSignalGenerator adında ayrı bir modül oluşturmaya karar verdim. İlk başta, sadece en güçlü kurallara göre sinyaller üretmek istedim, ancak her şeyin çok daha karmaşık olduğunu çabucak fark ettim. Piyasa sürekli değişiyor ve dün iyi işleyen bir kural bugün başarısız olabilir.
Kuralların gücünü değerlendirmek için ciddi bir yaklaşım benimsemem gerekti. Birkaç başarısız denemeden sonra bir ölçek sistemi geliştirdim. En çok oranları seçmekte zorlandım - muhtemelen düzinelerce kombinasyon denedim. Sonunda, nihai değerlendirmenin %40'ını oluşturan 'lift' (bu gerçekten önemli bir göstergedir), %30'unu oluşturan 'confidence', %20'sini oluşturan 'support' ve %10'unu oluşturan 'leverage' üzerinde karar kıldım.
İlginçtir ki, en güçlü sinyaller genellikle kural bir trend bileşeni içerdiğinde elde edildi. Hatta bu tür kuralların gücüne özel bir %20 bonus ekledim ve pratikte bunun haklı olduğunu gördüm.
Mevcut piyasa durumunun analizini yaparken de çok çalışmam gerekti. İlk başta, göstergelerin mevcut değerlerini kuralların koşullarıyla karşılaştırdım. Ancak daha sonra daha geniş bir bağlamı dikkate almam gerektiğini fark ettim. Örneğin, son birkaç periyottaki genel trendin, volatilite durumunun ve hatta günün saatinin doğrulanmasını ekledim.
Şu anda sistem her bir döviz paritesi için yaklaşık 20 farklı parametreyi analiz etmektedir. Bulduğum bazı kalıplar beni gerçekten şaşırttı.
Elbette sistem hala mükemmel olmaktan uzaktır. Bazen kendimi temel faktörleri eklemem gerektiğini düşünürken yakalıyorum. Ancak, bunu daha sonraya bıraktım. İlk olarak, mevcut sürümü bitirmek istiyorum.
Sinyal sıralama ve toplama
Sistemin geliştirilmesi sırasında, sadece kurallar bulmanın yeterli olmadığını, sinyallerin kalitesinin sıkı bir şekilde kontrol edilmesi gerektiğini çabucak fark ettim. Birkaç başarısız alım-satım işleminden sonra, sıralamanın belki de kalıpları bulmaktan daha önemli olduğu anlaşıldı.
Minimum kural gücünün basit bir eşiği ile başladım. İlk başta 0.5 olarak ayarladım, ancak yanlış pozitifler almaya devam ettim. İki haftalık testten sonra 0.7'ye yükselttim ve durum gözle görülür şekilde iyileşti. Sinyallerin sayısı yaklaşık üçte bir oranında azaldı, ancak kaliteleri önemli ölçüde arttı.
İkinci sıralama düzeyi, özellikle can sıkıcı bir olayın ardından ortaya çıktı. Mükemmel performansa sahip bir kural vardı, ona göre bir pozisyon açtım, ancak piyasa tam tersi yönde hareket etti. Araştırmaya başladığımda, o anda diğer kuralların ters sinyaller verdiğini gördüm. O zamandan beri tutarlılığı kontrol etmeye başladım; yalnızca birden fazla kural aynı yönü işaret ediyorsa pozisyon açıyorum.
Volatilite ile başa çıkmak ilginç bir deneyim oldu. Sakin dönemlerde sistemin saat gibi çalıştığını, ancak piyasa hareketlenir hareketlenmez sorunların başladığını fark ettim. Bu yüzden ATR'a dayalı dinamik bir filtre ekledim. Son 20 gün içinde volatilite 75'inci yüzdelik dilimin üzerindeyse, kuralların gücü için gereklilikleri %20 artırıyoruz.
En zor kısım, birbiriyle çelişen sinyalleri kontrol etmekti. Bazı kurallar alış yapmayı, bazıları ise satış yapmayı söylüyor ve tüm kuralların iyi parametreleri var. Farklı yaklaşımlar denedim, ancak sonunda basit bir çözümde karar kıldım: sinyallerde önemli çelişkiler varsa, bu durumu atlıyoruz. Bunu yaparak bazı fırsatları kaybediyoruz, ancak riskleri önemli ölçüde azaltıyoruz.
Gelecek ay, zamana göre sıralamayı da ekleyeceğim. Belirli saatlerde kuralların gözle görülür şekilde daha kötü çalıştığını fark ettim. Bu durum özellikle likiditenin düşük olduğu ve önemli haberlerin yayınlandığı dönemlerde ortaya çıkmaktadır. Bunun başarılı işlemlerin yüzdesini daha da artıracağını düşünüyorum.
Test sonuçları
Sistemi birkaç ay geliştirdikten sonra önemli bir soruyla karşılaştım: Bulunan her kuralın gücünü nasıl doğru bir şekilde değerlendirebilirim? Kağıt üzerinde her şey basit görünüyordu, ancak gerçek piyasa ilk yaklaşımın tüm zayıflıklarını hızla ortaya çıkardı.
Uzun denemeler sonucunda, farklı faktörler için bir ağırlık sistemine ulaştım. 'Lift'i ana bileşen yaptım (%40 etki) - pratikte bunun gerçekten kritik derecede önemli bir gösterge olduğunu gördüm. 'Confidence' %30'luk bir etkiye sahip - sonuçta kuralın güvenilirliği de büyük önem taşıyor. 'Support' ve 'leverage'a daha küçük ağırlıklar verdim - bunlar daha çok filtre görevi görüyor.
Sinyal sıralamanın ayrı bir hikaye olduğu ortaya çıktı. İlk başta, arka arkaya tüm kurallara göre işlem yapmaya çalıştım, ancak hatamı çabucak anladım. Bu yüzden, çok seviyeli bir sıralama sistemi uygulamak zorunda kaldım. İlk olarak, zayıf kuralları minimum güç eşiğine göre sıralıyoruz. Ardından sinyalin birkaç kural tarafından doğrulanıp doğrulanmadığını kontrol ediyoruz - tek bir kurala dayanan sinyaller genellikle daha az güvenilirdir.
Volatilitenin dikkate alınmasının özellikle önemli olduğu kanıtlandı. Sakin dönemlerde sistem mükemmel çalıştı, ancak volatilite artar artmaz yanlış sinyallerin sayısı keskin bir şekilde arttı. Volatilite arttıkça daha katı hale gelen dinamik filtreler eklemek zorunda kaldım.
Sistemin test edilmesi neredeyse üç ay sürdü. Dört majör parite için iki yıllık bir geçmiş üzerinde çalıştırdım. Sonuçlar oldukça beklenmedikti. Örneğin, USDJPY en iyi performansı gösterdi - 1.6 RR ile %65 karlı işlem yüzdesi. Ancak GBPUSD hayal kırıklığı yarattı - 1.4 RR ile sadece %58.
İlginç bir şekilde, 'lift' değeri 2.0'ın üzerinde ve 'confidence' değeri 0.8'in üzerinde olan kurallar tüm pariteler için sürekli olarak en iyi sonuçları verdi. Görünüşe göre, bu seviyeler Forex piyasasında gerçekten bir tür doğal önem eşikleridir.
Daha fazla iyileştirme
Şu anda sistemi iyileştirmek için birkaç yön görüyorum. İlk olarak, kuralların parametrelerinin daha dinamik hale getirilmesi gerekiyor - piyasa değişiyor ve sistemin de buna uyum sağlaması gerekiyor. İkinci olarak, makroekonomi ve haberlerin arka planına ilişkin net bir eksiklik söz konusudur. Evet, sistemi karmaşıklaştıracaktır, ancak potansiyel kazanımlar buna değer.
Uyarlanabilir filtreler uygulamak özellikle ilginç görünüyor. Farklı piyasa aşamaları açıkça farklı sistem ayarları gerektirir. Şu anda kabaca uygulanıyor, ancak bunu geliştirmenin birkaç yolunu şimdiden görebiliyorum.
Gelecek hafta, pozisyon büyüklüklerinin dinamik optimizasyonunu içeren yeni bir sürümü test etmeye başlamayı planlıyorum. Geçmiş veriler üzerindeki ilk sonuçlar umut verici görünmektedir, ancak gerçek piyasa her zaman olduğu gibi kendi ayarlamalarını yapacaktır.
Sonuç
Algo alım-satımda ilişkilendirme kurallarının kullanılması, net olmayan piyasa kalıplarını bulmak için ilginç fırsatlar sunar. Burada başarının anahtarı uygun veri hazırlığı, dikkatli kural seçimi ve iyi düşünülmüş bir sinyal üretim sistemidir.
Herhangi bir alım-satım sisteminin sürekli izleme ve değişen piyasa koşullarına adaptasyon gerektirdiğini unutmamak önemlidir. İlişkisel kurallar güçlü bir analiz aracıdır, ancak diğer teknik ve temel analiz yöntemleriyle birlikte kullanılmaları gerekir.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/16061
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Görünüşe göre, okuyucunun zaten böyle bir yöntem hakkında biraz bilgi sahibi olması gerektiği varsayılıyor ve eğer değilse?
Özellikle bahsedilen ölçümleri anlamıyorum:
Lift benim favori göstergem haline geldi. Yüzlerce saatlik testten sonra bir model fark ettim - 1,5'in üzerinde kaldırma oranına sahip kurallar gerçek piyasada gerçekten işe yarıyor. Bu keşif, sinyal filtreleme yaklaşımımı ciddi şekilde etkiledi.
Yöntemi doğru anladıysam, kuantum segmentlerinde korelasyon sinyalleri aranır. Ancak bir sonraki adımı anlamamıştım. Hedef olan nedir? Ortaya çıkan kuralların hedefe karşı kontrol edildiğini ve metriklere karşı değerlendirildiğini varsayıyorum.
Eğer öyleyse, bu benim yöntemimi yansıtıyor ve performansı ve verimliliği değerlendirmek ilginç.