
Gelecekteki trendlerin anahtarı olarak hacimsel sinir ağı analizi

Tüm alım-satımın giderek daha otomatik hale geldiği bir çağda, geçmişteki yatırımcıların önermelerini hatırlamamızda fayda var. Bunlardan biri, hacmin her şeyin anahtarı olduğunu savunur. Gerçekten de, teknik analiz ve hacim analizi, makine öğrenimine özellik olarak beslemek için yararlı ve çok ilginç olacaktır. Belki de doğru bir yorumla bu bize bir sonuç verecektir. Bu makalede, LSTM mimarisini kullanarak işlem hacmini ve hacim tabanlı özellikleri analiz etme yaklaşımını değerlendireceğiz.
Sistemimiz hacim anormalliklerini analiz edecek ve gelecekteki fiyat hareketlerini tahmin edecektir. Sistemin dikkat çekmek istediğim temel özellikleri, anormal hacmin tespiti, hacim kümeleme ve doğrudan Python + MetaTrader 5 paketi aracılığıyla model eğitimidir.
Ayrıca sonuçların görselleştirilmesiyle birlikte kapsamlı bir geriye dönük test gerçekleştireceğiz. Model, Rusya borsasının saatlik zaman diliminde özel bir verimlilik göstermektedir; bu durum, Sberbank hisse senedinin geçen yılki geçmiş verileri üzerinde yapılan test sonuçlarıyla doğrulanmaktadır. Bu makalede, sistemin mimarisini, çalışma prensiplerini ve uygulanmasının pratik sonuçlarını ayrıntılı olarak inceleyeceğim.
Kod dökümü: Verilerden tahminlere
Derinlere inelim ve hacimlerde şu anda neler olup bittiğini gerçekten anlayacak bir sistem oluşturmaya çalışalım. Basit şeylerle başlayalım - verileri alma ve işleme şeklimiz. Bir yandan, karmaşık bir şey yok - verileri indiriyoruz ve çalışıyoruz... Ancak şeytan, her zaman olduğu gibi, ayrıntıda gizlidir.
Veri kaynağı: Daha derinlemesine inceleme
Veri yükleme fonksiyonumuz aşağıdadır.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Oldukça basit görünüyor. Daha kolay olan copy_rates_from yerine kasıtlı olarak copy_rates_range kullanıyorum. Likit olmayan enstrümanlarla çalışırken sıfır periyotlarını kaybetmemek için buna ihtiyacımız var.
Daha sonra, özellikler ve göstergelerle çalışmaya başlıyoruz.
Ön işleme: Veri hazırlama sanatı
Özellikleri seçerek zaman kaybetmeyelim, bunun yerine en belirgin olanlardan birkaçına odaklanalım.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
Özellik seçimini ele almak bir orkestrayı akort etmeye benzer. Her özelliğin veri senfonisinde kendi rolü ve kendine özgü bir sesi vardır. Temel setimize bakalım.
İlki en basit olanıdır: hacmin hareketli ortalamasını alıyoruz. 5 periyotluk ortalama hacim en ufak dalgalanmaları yakalarken, 20 periyotluk olan çok daha güçlü hacim trendlerine tepki verir.
Hacmin ortalamaya oranı da ilginç olabilir. Gelecekte keskin bir sıçrama olduğunda, sıklıkla güçlü bir fiyat hareketi meydana gelir.
Ayrıca son 24 çubuktaki fiyat momentumuna ve hacim momentumuna da bakıyoruz.
Hacim volatilitesi adı verilen daha da ilginç bir özellik vardır. Ben buna piyasanın tedirginliğinin bir göstergesi diyebilirim. Hacim volatilitesi arttığında, bu durum ciddi yatırımcılardan piyasaya güçlü girişler olduğunu gösterebilir.
Fiyat ve hacim korelasyonu da modelimiz tarafından dikkate alınmaktadır. Sonunda, yeni oluşturduğumuz göstergeleri görselleştirerek tüm bu noktalara kesinlikle canlı olarak bakacağız.
Performans darboğazı
Sistemin aşırı yüklenmesini önlemek için, veri gruplama ve paralel hesaplama uygulayabiliriz. Başka bir deyişle, verileri küçük parçalara böler ve paralel olarak işleriz.
Bu basit teknik, veri işlemeyi birkaç kat hızlandırır ve ayrıca büyük hacimli verilerde bellek sızıntılarıyla ilgili sorunları önlemeye yardımcı olur.
Makalenin bir sonraki bölümünde, en ilginç kısımdan bahsedeceğim - sistemin anormal hacimleri nasıl tespit ettiği ve bundan sonra ne olacağı.
"Siyah kuğular" arayışında: Anormal hacimler nasıl anlaşılır?
Hepimiz anormal hacimlerin ne olduğunu ve bunları bir grafikte nasıl göreceğimizi duymuşuzdur. Belki de deneyimli herhangi bir yatırımcı bunları fark edebilir. Peki bu deneyimi kodun içine nasıl yerleştirebiliriz? Bu tür hacimleri arama mantığı nasıl formüle edilir?
Anormallikleri avlama
Bir dizi denemenin ardından, bu alandaki araştırmalarım İzolasyon Ormanı yönteminde karar kıldı. Neden bu yöntem? Z-skorları veya yüzdelik dilim skorları gibi klasik yöntemler küçük bir yerel anormalliği gözden kaçırabilir, ancak önemli olan mutlak veya yüzdelik değerler değil, diğerlerinden farklı olan ve genel bağlamın dışında kalan hacimlerdir.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Elbette, parametrelerle oynamak daha iyi olacaktır ve daha da iyi bir çözüm, BGA gibi algoritmalar kullanarak tüm model ayarlarını seçmek olacaktır. Değeri ders kitaplarında önerilen 0.05'e ayarladım, bu da %5 anormalliğe karşılık geliyor. Ancak gerçek piyasa tahmin edilebileceğinden çok daha gürültülüdür. Bu nedenle çıta biraz yükseltildi. Anormallikleri fiyat hareketleriyle gruplandırarak kendi gözlerinizle görmeniz de faydalı olacaktır (bu konuya aşağıda döneceğiz).
Kümeleme: Kalıpları bulma
Anormallikler iyi bir tahmin için yeterli değildir. Ayrıca hacimlerin kümelenmesine de ihtiyacımız var. Aşağıdaki kümeleme seçeneğine odaklanacağız:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Kümeleme için seçilen özellikler oldukça basittir. Sadece hacimleri kümelemenin garip olacağını düşünüyorum, aksi takdirde neden özelliklerimizi ve göstergelerimizi oluşturalım ki? Diğer bir husus ise, özelliklerin sayısının ve hacim göstergelerinin oldukça iyileştirilebileceğidir.
Üç küme seçildi çünkü tüm hacimleri koşullu olarak "arka plan veya birikim" hacimleri, "çalışma ve hareket" hacimleri ve "aşırı hareket" hacimleri olarak ayıracağım.
Beklenmedik bulgular
Verilerin işlenmesi çeşitli kalıplar ve sekanslar ortaya çıkardı, örneğin, anormal hacimleri üçüncü hacim kümesi takip eder, daha sonra aktif hacim gelir ve ancak bundan sonra fiyatlar bir yönde hareket eder.
Bu durum özellikle borsa seansının açılışını takip eden ilk saatlerde belirginleşmektedir. Burada kümelerin ve bunlara eşlik eden fiyat hareketlerinin bir ısı haritasını oluşturmak faydalı olacaktır.
Sinir ağı: Bir makine piyasayı okuması için nasıl eğitilir?
Sinir ağlarını uzun süredir kullandığım için, hacim analizimize bir sinir ağı uygulamak mantıklı olacaktır. LSTM mimarisini henüz denemedim, ancak bu mimarinin diğer alanlardaki örneklerini gördükten sonra nihayet denemeye karar verdim.
Daha yakından bakalım.
Mimari: Daha azı daha çoktur
Daha basit daha iyidir. Şaşırtıcı derecede basit bir mimari buldum:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
İlk bakışta, tüm mimari çok ilkel görünüyor, sadece iki LTSM katmanı ve bir doğrusal katman. Ancak güç basitlikte yatar. Çünkü ne yazık ki, daha derin öğrenme ile daha kapsamlı bir ağ kurarsak, aşırı uyum elde ederiz. Başlangıçta, üç LSTM katmanı, ek tam bağlantılı katmanlar ve karmaşık bir bırakma yapısı ile çok daha karmaşık bir ağ oluşturdum. Sonuçlar etkileyiciydi... Test verileri üzerinde. Ancak ağ gerçek uzun vadeli piyasayla karşılaşır karşılaşmaz her şey darmadağın oldu. Yani, aşırı uyum vardı.
Aşırı uyum sorunuyla mücadele
Aşırı uyum, modern sinir ağlarının en büyük sorunudur. Sinir ağı, test veri alanlarında ilişkileri bulmayı öğrenme konusunda harikadır, ancak gerçek piyasa koşullarında tamamen kaybolur. Bu sorunu özellikle sunulan mimaride şu şekilde çözmeye çalışıyorum:
- Tek bir katman, hacim ve fiyat arasındaki ilişkinin karmaşıklığıyla başa çıkamaz
- Üç katman, gerçekte var olmayan bağlantıları bulabilir
Gizli katmanın büyüklüğü standart şekilde seçilmiştir - 64 nöron. Daha fazla nöron kullanmak daha iyi olabilir. Gelecekte, aşırı uyumla mücadele etmek için çalışan bir çözüm sunduğumda, daha fazla nöron içeren daha karmaşık bir mimari kullanabileceğiz.
Girdi verileri: Özellik seçme sanatı
Eğitim için girdi özelliklerine bakalım:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Özellik seti ile çok sayıda deneme yapabiliriz. Teknik göstergeler, fiyat türevleri, hacim türevleri, fiyat ve hacim türevleri, ne istersek ekleyebiliriz. Ancak daha fazla özelliğin her zaman tahmin kalitesini artırmayacağını unutmayın. Ve görünüşte en mantıklı olan her özellik aslında verilerdeki basit bir gürültüden ibaret olabilir.
'volume_cluster' ve 'is_anomaly' kombinasyonu burada ilginç görünüyor. Bu özellikler tek tek mütevazıdır, ancak birlikte çok ilginçtirler. Belirli kümelerde anormal hacimler ortaya çıktığında, bunun tahmin üzerinde alışılmadık bir etkisi olur.
Beklenmedik keşif
Sistemin, fiyat hareketlerinin güçlü olduğu dönemlerde en etkili olduğu ortaya çıktı. Ayrıca, çoğu yatırımcının okunamaz olarak adlandırdığı anlarda, yani yatay piyasalarda ve konsolidasyonlar sırasında kendini iyi gösterir. İşte bu anlarda, anormallikleri ve hacim kümelerini analiz eden sistem, görüşümüzün erişemediği şeyleri görür.
Bir sonraki bölümde, bu sistemin gerçek alım-satımda nasıl performans gösterdiğinden bahsedeceğim ve belirli sinyal örneklerini paylaşacağım.
Tahminlerden alım-satıma: Sinyalleri kara dönüştürmek
Herhangi bir algoritmik yatırımcı şunu bilir: basit bir tahmin modeli yeterli değildir. Çalışan bir alım-satım stratejisine dönüştürülmesi gerekir. Peki modelimizi pratikte nasıl uygulayacağız? Hadi keşfedelim. Makalenin bir sonraki bölümünde, sadece kuru teori değil, gerçek test alım-satımı, algoritmanın güçlendirilmesi, aşırı uyuma karşı mücadelenin iyileştirilmesi ile gerçek uygulama bulacaksınız, ancak şimdilik araştırmamızın olağan teorik kısmı ile devam edeceğiz.
İşlem sinyali anatomisi
Bir alım-satım stratejisi geliştirirken, kilit noktalardan biri işlem sinyallerinin üretilmesidir. Benim stratejimde sinyaller, bir sonraki dönem için beklenen getiriyi yansıtan model tahminlerine dayalı olarak üretilir.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1Sinyal eşiğinin seçilmesi
Bir yandan, eşiği basitçe 0'ın üzerine ayarlayabiliriz. Bu durumda, birçok sinyal üreteceğiz, ancak makas, komisyonlar ve piyasa gürültüsü nedeniyle gürültülü olacaklardır. Bu yaklaşım, strateji verimliliğini olumsuz yönde etkileyecek çok sayıda yanlış sinyale yol açabilir.
Dolayısıyla en makul karar, tahmin edilen karlılık eşiğini %0.1-%0.2'ye yükseltmek gibi görünmektedir. Bu, gürültünün çoğunu kesmemize ve komisyonların etkisini azaltmamıza olanak tanır, çünkü sinyaller yalnızca tahmin edilen önemli fiyat değişiklikleri olduğunda üretilecektir.
signal_threshold = 0.001 # Threshold 0.1%
Periyot kaydırmayı dikkate alarak sinyallerin uygulanması
Sinyaller üretildikten sonra, 24 periyotluk bir ileri kaydırma dikkate alınarak fiyatlara uygulanır. Bu, bir işlem kararının verilmesi ile uygulanması arasındaki gecikmeyi hesaba katmamızı sağlar.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
24 periyotluk bir kayma, t anında üretilen sinyalin t+24 zamanında fiyata uygulanacağı anlamına gelir. Bu önemlidir çünkü gerçekte işlem kararları anında uygulanamaz. Bu yaklaşım, alım-satım stratejisi verimliliğinin daha gerçekçi bir şekilde değerlendirilmesini sağlar.
Strateji karlılığının hesaplanmasıStrateji karlılığı, kaydırılmış sinyal ile fiyat değişikliğinin çarpımı olarak hesaplanır:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Sinyal 1'e eşitse, strateji karlılığı fiyat değişikliğine (price_change) eşit olacaktır. Sinyal -1'e eşitse, strateji karlılığı negatif fiyat değişikliğine (-price_change) eşit olacaktır. Sinyal 0'a eşitse, strateji karlılığı sıfır olacaktır.
Dolayısıyla, sinyalleri 24 periyot kaydırmak, bir işlem kararının verilmesi ile uygulanması arasındaki gecikmeyi hesaba katmamızı sağlar ve bu da strateji verimliliğinin değerlendirilmesini daha gerçekçi hale getirir.
Altın ortalama
Haftalar süren testlerden sonra %0.1'lik bir eşik değerinde karar kıldım. Peki neden:
- Bu eşikte, sistem oldukça sık sinyal üretiyor
- İşlemlerin yaklaşık %52-63'ü karlı
- İşlem başına ortalama kar, komisyonun yaklaşık 2.5 katıdır
En sıra dışı keşif, çoğu yanlış sinyalin zaman kümeleri halinde de yoğunlaşabilmesidir. İsterseniz, böyle bir zaman filtresini düşünebilirsiniz ve bunu daha sonra, makalenin bir sonraki bölümünde ele alacağız.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Risk yönetimi
Pozisyon açma mantığı ve açık işlemleri yönetme mantığı (alım-satım sürecinde işlemlerin desteklenmesi) ayrı bir hikaye oluşturur. Bir yandan, buradaki en bariz çözüm sabit durma seviyeleri kullanmaktır, ancak piyasa, zarar ve kar seviyelerinin sıradan bir mantıkla tanımlanamayacak kadar öngörülemez ve dinamiktir.
Çözümümüz oldukça basittir - durma seviyelerini dinamik olarak ayarlamak için tahmin edilen volatiliteyi kullanmak:
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Bu yaklaşımın da ayrıca test edilmesi gerekir. Bu eski, ancak güvenilir ve etkili sisteme göre durma seviyelerini seçmek için VaR risk analizi modelini uygulamak da mümkündür.
Beklenmedik bulgular
İlginç bir bulgu, ardışık sinyaller serisinin çok güçlü hareketleri tahmin edebilmesidir. Piyasa volatilitesi ortalama olarak çok güçlü bir şekilde yükseldiğinde de sorunlar ortaya çıkıyor, bu durumda eşiğimiz artık etkili alım-satım için yeterli olmuyor. Dikkat ederseniz, grafikteki düşüş dönemleri tam olarak yüksek volatilite ile ilişkilidir... Ama bizim için bu bir sorun değil! Bu sorunu bir sonraki bölümde çözecek ve ortadan kaldıracağız.
Görselleştirme ve günlük kaydı: Veri içinde boğulmaktan nasıl kaçınılır?
Günlük kaydı sistemini unutmamak da bizim için çok önemli. Genel olarak, yazdırmalar, çıktılar ve program yorumlarıyla ilgili her şey hata ayıklama aşamasında büyük önem taşır. Bu şekilde kodunuzdaki sorunların kaynağını çok hızlı ve verimli bir şekilde bulabilirsiniz.
Günlük kaydı sistemi: Ayrıntılar önemlidir
Günlük kaydı sistemi basit ama verimli bir formata dayanmaktadır:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
"Bunun nesi bu kadar zor ki?" diye sorabilirsiniz. Bu formatı, sistemin neden belirli bir anda bir pozisyon açtığını anlayamadığım birkaç acı deneyimden sonra keşfettim.
Artık sistemin her eylemi günlükte net bir iz bırakıyor. Anormal hacimlerle ilgili anları da kaydettiğime emin oluyorum:
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
Ayrıca görselleştirmeye de ihtiyacımız var. Manuel alım-satım deneyimi güçlü bir alışkanlık bıraktı - en sıradan bir grafiğe bakarken olduğu gibi verilere de aynı şekilde bakarak her şeyi görsel olarak gözlemlemek. İşte görselleştirme kodumuz:
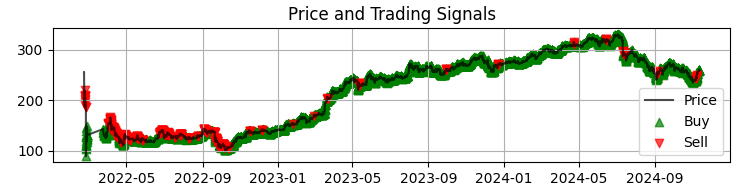
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
İlk grafiğimiz, elde edilen model sinyalleri ile Sber fiyatlarının grafiğidir. Ayrıca, anormal hacimlerin olduğu mumları vurgulayarak sinyalleri pekiştiriyoruz. Bu, sistemin piyasayı açık bir kitap gibi mükemmel bir şekilde okuduğu anları anlamamıza yardımcı olur.
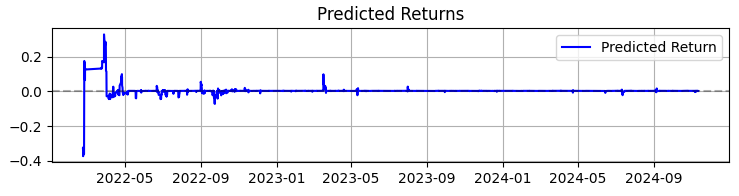
İkinci grafik ise tahmin edilen getiridir. Burada, seçilen varlık fiyatlarının güçlü hareketlerinden önce, genellikle çok güçlü bir tahmin serisinin başladığını açıkça görebiliriz. Dolayısıyla bu, tam da bu gözlem üzerine bir sistem oluşturmayı düşünme fikrini akla getiriyor. Elbette işlem sayısı düşecektir, ancak biz nicelik peşinde koşmuyoruz, nitelik için çabalıyoruz, öyle değil mi?
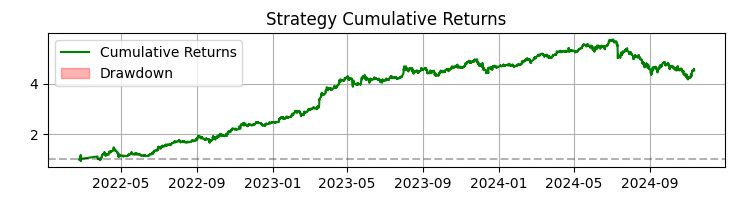
Üçüncü grafik, düşüşlerin vurgulandığı kümülatif getiridir.
Teoriden pratiğe: Sonuçlar ve beklentiler
Sistem çalışmasının sonuçlarını özetleyelim - sadece kuru sayılar değil, alım-satımda hacim analizi ile ilgilenen herkese yardımcı olabilecek keşifler.
Birincisi, piyasa aslında işlem hacmi aracılığıyla bizimle konuşuyor. Ancak bu dil tahmin edebileceğinizden çok daha karmaşıktır. Kişisel görüşüme göre, VSA gibi klasik yöntemler hızla demode oluyor ve piyasanın eşit derecede hızlı gelişimine ayak uyduramıyor. Formasyonlar daha karmaşık hale geliyor ve hacimler çıplak gözle zor görülebilen çok karmaşık formasyonlar oluşturuyor.
Genel olarak, yaklaşık üç yıllık makine öğrenimi deneyimimin bir sonucu olarak, piyasanın her yıl daha karmaşık hale geldiğini ve üzerinde çalışan, emir akışlarıyla kısmen trendleri ve birikimleri oluşturan algoritmaların da daha karmaşık hale geldiğini söyleyebilirim. Önümüzde sinir ağlarının savaşı var - kimin makinesinin daha verimli olacağını belirleyecek, piyasayı ele geçirmek için makineler arasında yaşanacak bir savaş.
Sistem üzerindeki çalışmaları özetlerken, sadece sayıları değil, aynı zamanda hacim analizi ile çalışan herkes için yararlı olabilecek ana keşifleri de paylaşmak istiyorum.
SBER hisse senedinde 365 gün boyunca sistem etkileyici sonuçlar gösterdi:
- Toplam getiri: Yıllık %365.0 (kaldıraçsız)
- Karla kapanan işlemlerin yüzdesi: %50.73
Ancak bu sayılar en önemli şey değildir. Daha da önemlisi, sistemin çeşitli piyasa koşullarına karşı dirençli olduğu kanıtlanmıştır. Sinyallerin doğası belirgin bir şekilde değişse de, hem trendde hem de yatay harekette eşit derecede iyi çalışmaktadır.
Yüksek volatilite dönemlerindeki sistem davranışının özellikle ilginç olduğu ortaya çıktı. Tam da çoğu yatırımcının piyasanın dışında kalmayı tercih ettiği zamanlarda sinir ağı hacim akışındaki en net kalıpları tespit ediyor. Belki de bunun nedeni, böyle anlarda kurumsal yatırımcıların eylemlerine dair daha belirgin "izler" bırakmalarıdır.
Bu proje bana ne öğretti?- Alım-satımda makine öğrenimi sihirli bir hap değildir. Başarı ancak piyasanın derinlemesine anlaşılması ve özelliklerin dikkatli bir şekilde tasarlanmasıyla elde edilebilir.
- Sürdürülebilirliğin anahtarı basitliktir. Ne zaman yeni katmanlar veya özellikler ekleyerek modeli karmaşıklaştırmaya çalışsam, sistem giderek daha kırılgan hale geldi.
- Hacimlerin bağlam içinde analiz edilmesi gerekir. Anormal hacimler veya kümeler tek başına çok az şey ifade eder. Sihir, diğer faktörlerle etkileşimlerine baktığımızda başlar.
Sırada ne var?
Sistem gelişmeye devam ediyor. Şu anda birkaç iyileştirme üzerinde çalışıyorum:
- Piyasa aşamasına bağlı olarak uyarlanabilir parametre ayarlaması
- Daha doğru analiz için akış emirlerini entegre etme
- Rusya piyasasının diğer enstrümanlarına genişleme
Sistemin kaynak kodu eklerde mevcuttur. İyileştirme önerilerinizi memnuniyetle karşılarım. Sistemi diğer araçlara uyarlamaya çalışacak olanların deneyimlerini duymak özellikle ilginç olacaktır.
Sonuç
Sonuç olarak, son aylarda benim için en değerli keşfin, bugün tartıştığımız hacimsel analiz gibi klasik yaklaşımların makine öğrenimi, sinir ağları ve büyük veri gibi yeni teknolojilere uyarlanması olduğunu belirtmek isterim.
Görünen o ki, geçmiş kuşakların deneyimleri hala canlı. Bizim görevimiz bu deneyimi sindirmek, özünü çıkarmak ve en son teknolojileri kullanarak kendi yatırımcı neslimizin bakış açısıyla geliştirmektir. Ve elbette modern çağın gerisinde kalamayız: kuantum makine öğrenimi, fiyatları ve hacimleri tahmin etmek için kuantum algoritmaları ve makine öğrenimi için çok boyutlu özellikler önümüzde duruyor. IBM'in 20 kübitlik kuantum süper bilgisayarı üzerinde piyasayı analiz etmeye çalışmıştım. Sonuçlar ilginçti, bunları size gelecek makalelerde kesinlikle anlatacağım.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/16062
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.


- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz