
L’utilizzo delle regole di associazione nell'analisi dei dati Forex

Introduzione al concetto di regole di associazione
Il trading algoritmico moderno richiede nuovi approcci analitici. Il mercato è in continua evoluzione e i metodi classici di analisi tecnica non sono più in grado di individuare le complesse relazioni di mercato.
Lavoro con i dati da molto tempo e ho notato che molte idee di successo provengono da settori affini. Oggi vorrei condividere la mia esperienza nell'utilizzo delle regole di associazione nel trading. Questo metodo ha dato prova della propria efficacia nell'analisi dei dati nel settore della vendita al dettaglio, consentendoci di individuare correlazioni tra acquisti, transazioni, variazioni dei prezzi e l'andamento futuro della domanda e dell'offerta. E se lo applicassimo al mercato dei cambi?
L'idea di base è semplice: cerchiamo pattern stabili di comportamento dei prezzi, indicatori e loro combinazioni. Ad esempio, con quale frequenza un rialzo dell'EUR/USD segue un calo dell'USD/JPY? O quali sono le condizioni che più spesso precedono movimenti di prezzo significativi?
In questo articolo, illustrerò l'intero processo di creazione di un sistema di trading basato su questa idea. Faremo quanto segue:
- Raccoglieremo i dati storici in MQL5
- Li analizzeremo in Python
- Individueremo pattern significativi
- Li trasformeremo in segnali di trading
Perché proprio questa combinazione di tecnologie? MQL5 è ottimo per lavorare con i dati di borsa e per l'automazione del trading. A sua volta, Python fornisce potenti strumenti di analisi. In base alla mia esperienza, posso affermare che tale combinazione è molto efficace per lo sviluppo di sistemi di trading.
Ci saranno molte cose interessanti nel codice, in particolare nell'ambito dell'applicazione delle regole di associazione al Forex.
Raccolta e preparazione dei dati storici del Forex
Per noi è estremamente importante raccogliere e preparare tutti i dati necessari. Prendiamo come riferimento i dati H1 delle principali coppie di valute degli ultimi due anni (a partire dal 2022).
Creeremo uno script MQL5 che raccoglierà ed esporterà i dati necessari in formato CSV:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Elaborazione dei dati in Python
Dopo aver creato un dataset, è importante gestire i dati correttamente.
A questo scopo, ho creato la classe speciale ForexDataProcessor, che si occupa di tutto il lavoro sporco. Analizziamo i suoi componenti principali.
Inizieremo caricando i dati. La nostra funzione utilizza dati orari per le principali coppie di valute: EURUSD, GBPUSD, USDJPY e USDCHF. I dati devono essere in formato CSV e includere le principali caratteristiche di prezzo.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Una volta completato il caricamento, inizia la parte più interessante: il calcolo degli indicatori tecnici. Qui mi affido ad un intero arsenale di strumenti collaudati nel tempo. Le medie mobili aiutano a identificare tendenze di durata variabile. SMA(50) spesso agisce come supporto o resistenza dinamica. L'oscillatore RSI con un periodo classico di 14 è utile per individuare le zone di ipercomprato e ipervenduto del mercato. Il MACD è indispensabile per identificare i punti di inversione e di momentum. Le Bande di Bollinger offrono un quadro chiaro dell'attuale volatilità del mercato.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
La discretizzazione dei dati merita un'attenzione particolare. Tutti i valori continui devono essere suddivisi in categorie chiare. In questo ambito, è fondamentale trovare un giusto equilibrio - una suddivisione troppo netta complicherà la ricerca di pattern, mentre una suddivisione troppo approssimativa porterà alla perdita di importanti sfumature di mercato. Ad esempio, per determinare il trend, una suddivisione più semplice funziona meglio - in base alla posizione del prezzo rispetto alla media.
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Anche i pattern a candela richiedono un approccio particolare. Sulla base di un'analisi statistica, distinguo le Doji in base alla dimensione minima del corpo della candela, mentre i Long_Bullish e i Long_Bearish in base a movimenti di prezzo estremi. Questa classificazione ci permette di identificare chiaramente i momenti di indecisione del mercato e i forti movimenti impulsivi.
Al termine dell'elaborazione, tutte le coppie di valute vengono combinate in un unico array di dati con una scala temporale comune. Questo passaggio è di fondamentale importanza: apre la possibilità di ricercare relazioni complesse tra diversi strumenti. Ora possiamo vedere come l'andamento di una coppia di valute influisce sulla volatilità di un'altra o come i pattern a candele giapponesi si relazionano ai volumi di scambio sull'intero mercato.
Implementazione dell'algoritmo Apriori in Python
Dopo aver preparato i dati, passiamo alla fase cruciale: l'implementazione dell'algoritmo Apriori per individuare le regole di associazione nei nostri dati finanziari. Adattiamo l'algoritmo Apriori, originariamente sviluppato per l'analisi di panieri di titoli, per farlo funzionare con serie temporali di coppie di valute.
Nel contesto del mercato valutario, una "transazione" è un insieme di stati di vari indicatori e coppie di valute in un determinato momento. Per esempio:- EURUSD_Trend = Tendenza rialzista
- GBPUSD_RSI_Zone = Ipercomprato
- USDJPY_Volatility_Zone = Alta
L'algoritmo individua le combinazioni più ricorrenti di tali stati, sulla base delle quali vengono poi definite le regole di trading.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Adattamento delle regole di associazione per l'analisi delle coppie di valute
Nel corso del mio lavoro di adattamento dell'algoritmo Apriori al mercato dei cambi, ho incontrato sfide interessanti. Sebbene questo metodo fosse stato originariamente creato per analizzare gli acquisti nei negozi fisici, il suo potenziale per il Forex mi è sembrato promettente.
La difficoltà principale risiedeva nel fatto che il mercato Forex è radicalmente diverso dallo shopping tradizionale in un negozio. Nel corso degli anni trascorsi a lavorare nei mercati finanziari, mi sono abituato a gestire prezzi e indicatori in continua evoluzione. Ma come si applica un algoritmo che di solito cerca solo correlazioni tra banane e latte sugli scontrini del supermercato?
A seguito dei miei esperimenti, è nato un sistema composto da cinque parametri. Li ho testati tutti a fondo.
“Support" si è rivelato un parametro di misurazione molto complesso. Una volta stavo quasi per includere una regola con ottime prestazioni in un sistema di trading, ma “Support” era solo di 0,02. Per fortuna me ne sono accorto in tempo - in pratica, una regola del genere si attiverebbe solo una volta ogni cento anni!
“Confidence" si è rivelata più semplice. Quando lavori nel mercato, impari presto che anche una probabilità del 70% è un ottimo indicatore. La cosa fondamentale è gestire i rischi con saggezza con il restante 30%. Dobbiamo sempre tenere presente la gestione del rischio. Senza di essa, subirete un drawdown o addirittura un tracollo anche se avete il Santo Graal tra le mani.
“Lift” è diventato il mio indicatore preferito. Dopo centinaia di ore di test, ho notato uno schema: le regole con un “lift” superiore a 1,5 funzionano effettivamente sul mercato reale. Questa scoperta ha avuto un profondo impatto sul mio approccio alla classificazione dei segnali.
Avere a che fare con "Leverage" si è rivelato divertente. Inizialmente volevo escluderlo completamente dal sistema, considerandolo inutile. Ma durante un periodo di particolare volatilità del mercato, ha contribuito a distinguere la maggior parte dei falsi segnali.
"Conviction" è stata aggiunta per ultima, dopo aver consultato i forum. Mi ha aiutato a capire quanto sia importante questo indicatore per valutare il reale significato dei pattern individuati.
La cosa che mi ha sorpreso di più è stata la capacità dell'algoritmo di individuare correlazioni inaspettate tra diverse coppie di valute. Ad esempio, chi avrebbe mai pensato che certi pattern nella coppia EUR/USD potessero prevedere i movimenti di USD/JPY con tale precisione? Nei 9 anni di lavoro nel mercato, non avevo notato molte delle relazioni che l'algoritmo ha individuato. Sebbene il pair trading, il basket trading e l'arbitraggio fossero un tempo il mio campo d'azione, ricordo ancora i tempi in cui cmillion stava iniziando a sviluppare i suoi robot basati sui movimenti reciproci delle coppie di valute.
Ora proseguo la mia ricerca, testando nuove combinazioni di indicatori e periodi di tempo. Il mercato è in continua evoluzione e ogni giorno porta nuove scoperte. La prossima settimana ho intenzione di pubblicare i risultati dei test del sistema sui dati annuali, nonché i primi risultati in tempo reale dell'algoritmo su un conto demo di trading. Ci sono diverse scoperte molto interessanti.
A dire il vero, non mi aspettavo nemmeno che questo progetto arrivasse a questo punto. Tutto è iniziato come un semplice esperimento di data mining e tentativi di classificare in modo rigoroso tutti i movimenti di mercato per le esigenze degli algoritmi di classificazione, e alla fine si è trasformato in un vero e proprio sistema di trading. Penso di aver appena iniziato a comprendere il vero potenziale di questo approccio.
Caratteristiche dell’implementazione per il Forex
Torniamo un attimo al codice stesso. Il nostro codice presenta diversi importanti adattamenti dell'algoritmo per la gestione dei dati finanziari:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Questo raggruppamento aiuta a trovare combinazioni di indicatori più significative e riduce la complessità computazionale.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Selezioniamo solo le regole con una forte significatività statistica (lift > 1,5) e l'inclusione obbligatoria di indicatori di trend o RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
Il punteggio ponderato aiuta a classificare le regole in base alla loro potenziale utilità per il trading.
Visualizzazione delle associazioni trovate
Dopo aver individuato le regole di associazione, dobbiamo visualizzarle e analizzarle correttamente. A questo scopo, ho sviluppato la classe speciale ForexRulesVisualizer, che offre diversi metodi di analisi visiva dei modelli individuati.
Distribuzione delle metriche delle regole
Il primo passo dell'analisi consiste nel comprendere la distribuzione delle principali metriche delle regole individuate. Il grafico di distribuzione di 'support', 'confidence', 'lift' e 'leverage' aiuta a valutare la qualità delle regole trovate e se necessario, a regolare i parametri dell'algoritmo.
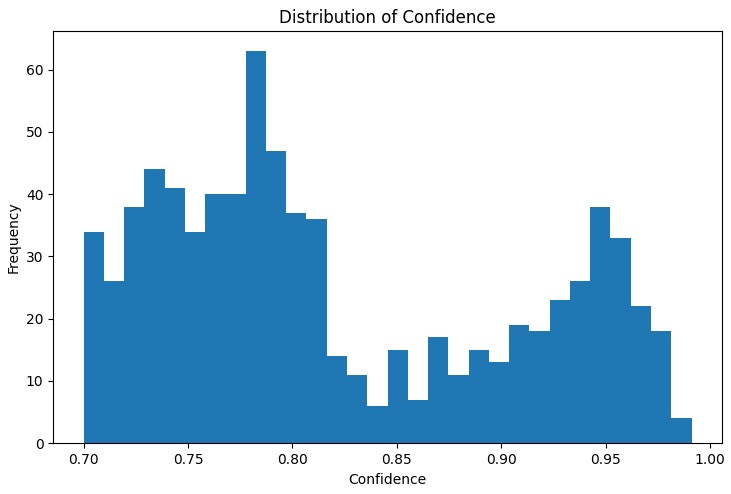
Uno strumento particolarmente utile è risultato essere il grafico di rete interattivo, che mostra chiaramente le connessioni tra le diverse condizioni di mercato. In questo grafico, i nodi sono gli stati degli indicatori (ad esempio "EURUSD_Trend=Uptrend" o "USDJPY_RSI_Zone=Overbought"), e i bordi rappresentano le regole trovate, dove lo spessore del bordo è proporzionale al valore di 'lift'.
Mappa di calore delle interazioni tra coppie di valute 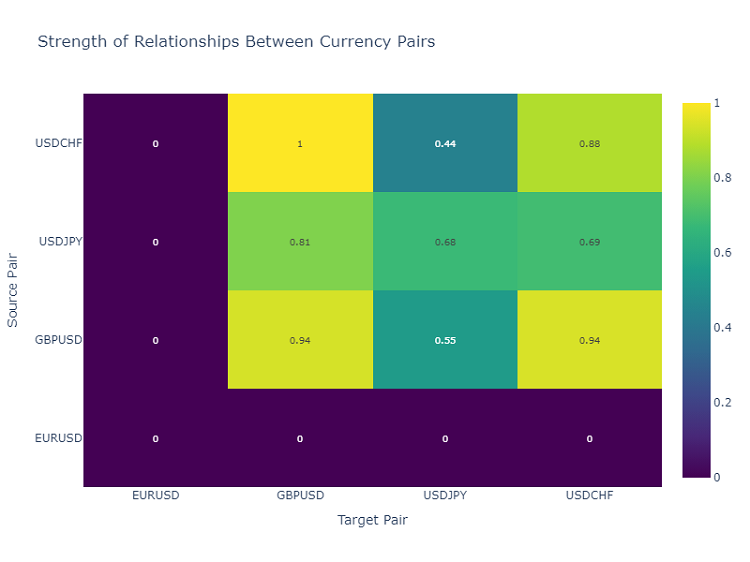
Per analizzare le relazioni tra le coppie di valute, utilizzo una mappa di calore, che mostra la forza delle correlazioni tra i diversi strumenti. Questo aiuta a identificare le coppie di valute che più spesso si influenzano a vicenda, aspetto fondamentale per costruire un portafoglio di trading diversificato.
Creazione di segnali di trading
Una volta individuate e visualizzate le regole di associazione, il passo successivo fondamentale è trasformarle in segnali di trading. A questo scopo, ho sviluppato la classe ForexSignalGenerator, che analizza lo stato attuale del mercato e genera segnali di trading in base alle regole individuate.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Valutare la solidità delle regole
Dopo lunghi esperimenti di visualizzazione delle regole, è giunto il momento della parte più difficile: la creazione di veri e propri segnali di trading. Lo ammetto, questo compito mi ha fatto sudare parecchio. Una cosa è individuare schemi interessanti sui grafici, tutt'altra cosa è trasformarli in un sistema di trading efficace.
Ho deciso di creare un modulo separato chiamato ForexSignalGenerator. Inizialmente, volevo semplicemente generare segnali secondo le regole più rigide, ma mi sono presto reso conto che la realtà è molto più complessa. Il mercato è in continua evoluzione e una regola che funzionava bene ieri potrebbe non funzionare più oggi.
Ho dovuto adottare un approccio serio per valutare la solidità delle regole. Dopo diversi esperimenti infruttuosi, ho sviluppato un sistema di scala. La parte più difficile è stata scegliere le proporzioni - probabilmente ho provato decine di combinazioni. Alla fine, ho deciso di assegnare il 40% del punteggio finale al fattore "lift" (un indicatore davvero fondamentale), il 30% a "confidence", il 20% a "support" e il 10% a "leverage".
Curiosamente,i segnali più forti, spesso si ottenevano quando la regola includeva una componente di tendenza. Ho persino aggiunto uno speciale bonus del 20% alla forza di tali regole e l'esperienza ha dimostrato che è giustificato.
Ho dovuto impegnarmi a fondo anche nell'analisi dell'attuale situazione di mercato. Inizialmente, ho semplicemente confrontato i valori attuali degli indicatori con le condizioni previste dalle regole. Ma poi mi sono reso conto che dovevo tenere conto del contesto più ampio. Ad esempio, ho aggiunto la verifica del trend generale degli ultimi periodi, dello stato di volatilità e persino dell'ora del giorno.
Attualmente, il sistema analizza circa 20 parametri diversi per ogni coppia di valute. Alcuni dei pattern che ho trovato mi hanno davvero sorpreso.
Certo, il sistema è ancora ben lontano dall'essere perfetto. A volte mi sorprendo a pensare che devo aggiungere fattori fondamentali. Tuttavia, ho deciso di rimandare questa questione in un secondo momento. Innanzitutto, voglio terminare la versione attuale.
Selezione e aggregazione dei segnali
Durante lo sviluppo del sistema, mi sono presto reso conto che trovare semplicemente delle regole non è sufficiente - abbiamo bisogno di un controllo rigoroso della qualità dei segnali. Dopo alcuni trade infruttuosi, è diventato chiaro che la selezione è forse ancora più importante dell'individuazione dei pattern stessi.
Ho iniziato con una semplice soglia di forza minima della regola. Inizialmente l'ho impostato a 0,5, ma continuavo a ricevere falsi positivi. Dopo due settimane di test, l'ho aumentato a 0,7 e la situazione è migliorata sensibilmente. Il numero dei segnali è diminuito di circa un terzo, ma la loro qualità è migliorata significativamente.
Il secondo livello di selezione è stato introdotto in seguito ad un episodio particolarmente grave. C'era una regola con ottime prestazioni, ho aperto una posizione seguendola, ma il mercato è andato nettamente nella direzione opposta. Quando ho iniziato ad approfondire la questione, è emerso che altre regole, in quel momento, davano segnali opposti. Da allora, verifico la coerenza aprendo solo se diverse regole puntano nella stessa direzione.
Gestire la volatilità si è rivelato interessante. Ho notato che durante i periodi di calma il sistema funziona come un orologio, ma non appena il mercato si anima, iniziano i problemi. Ho quindi aggiunto un filtro dinamico tramite ATR. Se la volatilità supera il 75° percentile negli ultimi 20 giorni, aumentiamo del 20% i requisiti di solidità delle regole.
La parte più difficile è stata verificare i segnali contrastanti. Capita che alcune regole dicano di comprare, altre di vendere e tutte le regole hanno dei parametri validi. Ho provato diversi approcci, ma alla fine ho optato per una soluzione semplice: se ci sono contraddizioni significative nei segnali, saltiamo questa situazione. Così facendo, perdiamo alcune opportunità, ma riduciamo significativamente i rischi.
Il mese prossimo aggiungerò la possibilità di ordinare i dati per tempo. Ho notato che in certe ore le regole funzionano decisamente peggio. Ciò è particolarmente evidente durante i periodi di bassa liquidità e in concomitanza con la pubblicazione di notizie importanti. Penso che questo dovrebbe aumentare ulteriormente la percentuale di operazioni andate a buon fine.
Risultati del test
Dopo diversi mesi di sviluppo del sistema, mi sono trovato di fronte a una domanda fondamentale: come valutare correttamente la robustezza di ciascuna regola individuata? Sulla carta sembrava tutto semplice, ma il mercato reale ha presto messo a nudo tutte le debolezze dell'approccio iniziale.
A seguito di lunghi esperimenti, sono giunto a un sistema di pesi per diversi fattori. Ho reso "Lift" la componente principale (influenza del 40%) - l'esperienza ha dimostrato che si tratta di un indicatore di importanza davvero cruciale. "Confidence" vale il 30% - dopotutto, anche la fiducia nella regola è molto importante. A "Support" e "leverage" è stato assegnato un peso minore - agiscono più come filtri.
La classificazione dei segnali si è rivelata una storia a parte. All'inizio ho provato a fare trading seguendo tutte le regole di seguito, ma mi sono subito reso conto del mio errore. Pertanto, ho dovuto introdurre un sistema di ordinamento multilivello. Innanzitutto, classifichiamo le regole deboli in base alla soglia minima di solidità. Successivamente controlliamo se il segnale è confermato da più regole - quelle singole sono generalmente meno affidabili.
Tenere conto della volatilità si è rivelato particolarmente importante. Durante i periodi di calma, il sistema ha funzionato perfettamente, ma non appena la volatilità è aumentata, il numero di falsi segnali è aumentato vertiginosamente. Ho dovuto aggiungere filtri dinamici che diventano più restrittivi all'aumentare della volatilità.
La fase di test del sistema ha richiesto quasi tre mesi. L'ho eseguito su uno storico di due anni per quattro coppie principali. I risultati sono stati del tutto inaspettati. Ad esempio, la coppia USDJPY ha mostrato la performance migliore - il 65% di operazioni profittevoli con un RR di 1,6. Ma la coppia GBPUSD è stata deludente - solo il 58% con un RR di 1,4.
È interessante notare che le regole con un valore di 'lift' superiore a 2,0 e un valore di 'confidence' superiore a 0,8 hanno costantemente mostrato i risultati migliori per tutte le coppie. A quanto pare, questi livelli rappresentano effettivamente una sorta di soglie di rilevanza naturale nel mercato Forex.
Ulteriori miglioramenti
Al momento, vedo diverse direzioni in cui migliorare il sistema. Innanzitutto, i parametri delle regole devono essere resi più dinamici - il mercato è in continua evoluzione e il sistema deve adattarsi. In secondo luogo, si nota una chiara mancanza di attenzione agli aspetti macroeconomici e al contesto dell'attualità. Sì, complicherà il sistema, ma i potenziali vantaggi ne valgono la pena.
L'applicazione di filtri adattivi sembra particolarmente interessante. Le diverse fasi del mercato richiedono chiaramente impostazioni di sistema differenti. Al momento è implementato in modo rudimentale, ma riesco già ad individuare diversi modi per migliorarlo.
La prossima settimana ho intenzione di iniziare a testare una nuova versione con ottimizzazione dinamica delle dimensioni delle posizioni. I risultati preliminari basati sui dati storici sembrano promettenti, ma il mercato reale, come sempre, apporterà i propri aggiustamenti.
Conclusioni
L'utilizzo di regole di associazione nel trading algoritmico apre interessanti opportunità per individuare pattern di mercato non ovvi. La chiave del successo in questo caso risiede in una corretta preparazione dei dati, un'attenta selezione delle regole e un sistema di generazione del segnale ben congegnato.
È importante ricordare che qualsiasi sistema di trading richiede un monitoraggio costante e un adattamento alle mutevoli condizioni di mercato. Le regole associative sono un potente strumento di analisi, ma devono essere utilizzate in combinazione con altri metodi di analisi tecnica e fondamentale.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/16061
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
A quanto pare, si presume che il lettore debba già avere una certa conoscenza di tale metodo, e in caso contrario?
Non capisco le metriche citate, in particolare:
Lift è diventato il mio indicatore preferito. Dopo centinaia di ore di test, ho notato uno schema: le regole con lift superiore a 1,5 funzionano davvero nel mercato reale. Questa scoperta ha influenzato seriamente il mio approccio al filtraggio dei segnali.
Se ho capito bene il metodo, i segnali correlati vengono cercati nei segmenti quantistici. Ma non ho capito il passo successivo. Qual è il target? Presumo che le regole risultanti vengano controllate rispetto all'obiettivo e valutate rispetto alle metriche.
Se è così, questo metodo riprende il mio, ed è interessante valutare le prestazioni e l'efficienza.