
Кластерный анализ (Часть I): Использование наклона индикаторных линий

Введение
Кластерный анализ — один из важнейших элементов искусственного интеллекта. Данные, обычно отображаемые в виде кортежей (tuples) чисел или точек, группируются в кластеры или кучи. Цель состоит в том, чтобы путем успешного присвоения наблюдаемой точки кластеру или категории присвоить известные свойства этой категории наблюдаемой новой точке, а затем действовать соответствующим образом. В этой статье мы проверим, может ли наклон индикатора указывать на флэтовый или трендовый характер рынка. И если да, то насколько хорошо.
Нумерация и наименования
Индикатор HalfTrend, который я буду использовать в качестве примера, написан в традициях языка MQL4. Индекс баров или свечей (iB) на ценовом графике отсчитывается от своего наибольшего значения (rates_total), индекса самого раннего бара до нуля, самого позднего и текущего бара. При первом вызове функции OnCalculate() после запуска индикатора значение prev_calculated равно нулю, так как никаких вычислений еще не было. При последующих вызовах это значение позволяет определить, какие бары уже рассчитаны, а какие – нет.
Индикатор использует двухцветную индикаторную линию, реализованную двумя буферами данных - up[] и down[]. У каждого - свой цвет. Только один из двух буферов получает значение больше нуля за раз, для другого устанавливается ноль в той же позиции (элемент буфера с тем же индексом iB). Это значит, что он не отображается.
Чтобы максимально упростить дальнейшее использование кластерного анализа с другими индикаторами или программами, в индикатор HalfTrend было внесено минимум дополнений. Добавленные строки обрамлены следующими комментариями в коде индикатора:
//+------------------------------------------------------------------+ //| добавлен для кластерного анализа | //+------------------------------------------------------------------+ .... //+------------------------------------------------------------------+
В полном виде функции и данные кластерного анализа приведены в файле ClusterTrend.mqh, приложенном в статье. В основе всех расчетов лежит следующая структура данных всех кластеров:
struct __IncrStdDev { double µ, // среднее σ, // стандартное отклонение max,min, // макс. и мин. значения S2; // вспомогательная переменная uint ID,n; // идентификатор и количество значений };
µ - среднее значение. σ - стандартное отклонение, представляющее собой корень дисперсии, показывающий, насколько близко значения в кластере изменяются вокруг среднего. Max и min - соответственно максимальное и минимальное значения в кластере. S2 - вспомогательная переменная. n - число значений в кластере, ID - идентификатор кластера.
Эта структура данных организована в виде двумерного массива:
__cluster cluster[][14];
Поскольку в MQL5 динамически настраивается только первое измерение многомерных массивов, ему присваивается количество исследуемых типов значений, что позволяет легко его менять. Второе измерение - это количество значений классификации, которые фиксируются в следующем одномерном массиве:
double CatCoeff[9] = {0.0,0.33,0.76,1.32,2.04,2.98,4.21,5.80,7.87};
Обе строки находятся непосредственно друг под другом, так как количество коэффициентов в CatCoeff предопределяет фиксированный размер второго измерения кластера. Он должен быть больше на 5. Причину поясню ниже. Так как оба массива предопределяют друг друга, их можно легко менять вместе.
Проверяется только разница значения индикатора и его предыдущего значения: x[iB] - x[iB+1]. Эта разница пересчитывается в пункты (_Point), чтобы можно было сопоставлять разные торговые инструменты, такие как EURUSD с 5 знаками после запятой и XAUUSD (золото) с двумя знаками.
Задачи
Для торговли важно знать, является ли рынок флэтовым либо находится в слабом или сильном тренде. При флэте необходимо торговать от границы канала около подходящего среднего индикатора по направлению к индикатору, обратно к центру канала, в то время как при тренде необходимо торговать по тренду по направлению от среднего индикатора и от центра канала, то есть действовать ровно наоборот. Таким образом, идеальный индикатор в составе советника должен четко разделять эти два состояния. Советнику необходимо число, в котором отражается рыночное действие. Также ему нужны пороговые значения, чтобы знать, указывает ли это число индикатора на тренд или на флэт. Часто кажется, что для этого достаточно визуального анализа. Однако визуальное восприятие обычно трудно выразить в виде формулы и/или числа. Кластерный анализ - это математический метод группировки данных или их распределения по категориям. Он поможет нам разделить эти два состояния рынка.Кластерный анализ определяет или вычисляет посредством оптимизации:
- количество кластеров
- центры кластеров
- назначение точек только одного из кластеров, если это возможно (= нет перекрывающих друг друга кластеров).
- все или как можно больше числовых кортежей (возможно, за исключением выбросов) могут быть назначены одному кластеру,
- размер кластеров минимален
- кластеры перекрываются как можно реже (иначе неясно, к какому кластеру принадлежит точка),
- число кластеров минимально.
Чем больше точек, значений, элементов и кластеров, тем более ресурсоемкими являются вычисления.
О-символика
Вычислительные затраты представлены в виде O-символики. Например, O(n) означает, что здесь вычисление должно получить доступ ко всем n элементам только один раз. Хорошо известными примерами важности этой величины являются значения алгоритма сортировки. Самые быстрые обычно имеют O(nlog(n)), самые медленные - O(n²). Этот критерий был особенно важен для больших объемов данных во времена, когда компьютеры были гораздо менее производительными. Сегодня вычислительные возможности компьютеров намного шире, но в то же время в некоторых областях объем данных тоже сильно увеличился (оптический анализ объектов окружающей среды и категоризация объектов).
Первый и самый известный алгоритм кластерного анализа - метод k-средних. Он назначает n наблюдений или векторов с размерностью dс для k кластеров, минимизируя (евклидовы) расстояния до центров кластеров. Это приводит к вычислительным затратам O(n^(dk+1)). У нас есть только одно измерение d, соответствующее отличие индикатора от предыдущего значения, но вся ценовая история, например, демо-счета MQ для свечей GBPUSD D1 включает 7265 баров или свечей (n в формуле). Поскольку вначале мы не знаем, сколько кластеров нам нужно, я использую k=9 кластеров или категорий. Согласно этому соотношению, затраты составят O(7265^(1*9+1)) или O(4,1*10^38). Довольно много для среднестатистического компьютера. Представленный здесь способ позволяет достичь кластеризации за 16 мсек, что составляет 454 063 значений в секунду. При расчете баров на GBPUSD M15 с помощью этой программы мы получаем 556 388 баров и, опять же, 9 кластеров. Расчет занимает 140 мсек или 3 974 200 значений в секунду. Расчет показывает, что кластеризация даже лучше чем O(n), что можно объяснить тем, как терминал организует данные - вычислительные усилия по вычислению индикатора также входят в этот период.
Индикатор
Я использую индикатор HalfTrend от MetaQuotes (приложен к статье). Он часто находится во флэте:

Возникает вопрос, есть ли какие-то пороговые значения, указывающие на флэт и тренд (не важно, бычий или медвежий). Понятно, что если линия индикатора расположена горизонтально, то рынок флэтовый. Но до какой высоты наклона изменения остаются незначительными и рынок по-прежнему считается флэтовым, и с какой высоты можно говорить о тренде? Представим, что советник видит только одно число, в котором сосредоточена вся картина графика, но не общая картина, как мы видим на скриншоте выше. Эта проблема решается с помощью кластерного анализа. Но прежде чем перейти к нему, сначала рассмотрим изменения, внесенные в индикатор.
Изменения в индикаторе
Так как индикатор нужно менять по минимуму, кластеризация была перенесена во внешний файл ClusterTrend.mqh, подключенный в начало индикатора:
Разумеется, файл приложен к статье. Но одного этого недостаточно. Чтобы упростить наши попытки, была добавлена переменная NumValues:
input int NumValues = 1;
Значение 1 указывает на то, что должен быть исследован только один тип значения. Например, если вы хотите проанализировать индикатор, который вычисляет два средних значения и вы хотите оценить наклон обоих, а также расстояние между ними, NumValues должен быть равен 3. Затем массив, по которому производится расчет, автоматически корректируется. Если значение равно нулю, кластерный анализ не выполняется. Эту дополнительную нагрузку можно легко отключить в настройках.
Кроме того, есть глобальные переменные:
string ShortName;
long StopWatch=0;
ShortName – короткое имя индикатора в OnInit():
ShortName = "HalfTrd "+(string)Amplitude;
IndicatorSetString(INDICATOR_SHORTNAME,ShortName);
которое будет использоваться для идентификации при печати результатов.
StopWatch используется для выбора времени. Оно устанавливается непосредственно перед первым значением, переданным для кластерного анализа, и считывается после печати результатов:
if (StopWatch==0) StopWatch = GetTickCount64();
...
if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch;
Как и большинство других индикаторов, HalfTrend располагает большим циклом по всем доступным барам ценовой истории. Индикатор рассчитывает свои значения так, чтобы бар на графике с индексом iB = 0 содержал текущие, самые поздние полученные цены, а наибольший возможный индекс представлял начало истории цен (самые ранние бары). Перед окончанием цикла анализируемое значение рассчитывается и отправляется в функцию кластера для оценки. Вся работа там автоматизирована. Подробности приведу ниже.
В блоке кода прямо перед концом цикла нужно убедиться, что кластерный анализ с историческими ценами выполняется только один раз для каждого бара, а не каждый раз, когда приходит новая цена:
//+------------------------------------------------------------------+
//| добавлен для кластерного анализа |
//+------------------------------------------------------------------+
if ( (prev_calculated == 0 && iB > 0 ) // мы не используем реальный бар
|| (prev_calculated > 9 && iB == 1)) // во время операции используется предпоследний бар: iB = 1
{
Затем мы проверяем, что это самый первый бар инициализации для установки таймера и обнуления предыдущих результатов (если они были):
if (prev_calculated==0 && iB==limit) { // только на первом проходе/баре
StopWatch = GetTickCount64(); // включаем секундомер
if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // если всё пересчитывается, удаляем предыдущие результаты
}
Затем значение индикатора определяется с помощью индексов текущего iB и предыдущего (iB+1) баров. Так как индикаторная линия двухцветная (см. выше) и реализована с помощью двух буферов up[] и down[], один из которых всегда равен 0,0 и поэтому не отображается, значение индикатора составляет тот буфер, что выше нуля:
double actBar = fmax(up[iB], down[iB]), // получаем реальное индикаторное значение бара [iB]
prvBar = fmax(up[iB+1], down[iB+1]); // получаем предыдущее индикаторное значение
Чтобы убедиться, что значения в начале расчета влияют на результаты кластерного анализа (хотя индикатор вообще не рассчитывался), введем следующую проверку безопасности:
if ( (actBar+prvBar) < _Point ) continue; // пропускаем котировки, отсутствующие в начале или промежуточном положении
Теперь мы можем передать абсолютную разность текущего и предыдущего значений индикатора.
enterVal(fabs(actBar-prvBar)/_Point, // абс. разность наклона индикаторной линии
0, // индекс типа значения
1.0 - (double)iB/(double)rates_total, // скорость обучения: используем 1-iB/rates_total или iB/rates_total, в зависимости от того, что находится в промежутке 0 .. 1
NumValues // используется для инициализации (количество типов значений) и если < 1, кластеризация не проводится
);
Почему мы используем абсолютную разность fabs(actBar-prvBar) в первом аргументе? Если бы мы отправили чистую разницу, нам пришлось бы определять вдвое большее количество кластеров (для значений больше и меньше нуля). В этом случае на результат повлияет тот факт, выросла или упала цена в пределах доступной истории цен. Это может исказить результаты. В конечном итоге для меня важна сила наклона, а не его направление. Я думаю, разумно предположить, что на форексе взлеты и падения цен в некоторой степени эквивалентны. Возможно, на фондовом рынке ситуация иная.
Второй аргумент (0) - индекс типа переданного значения (0=первый, 1=второй,..). Например, при двух индикаторных линиях и их разнице, нам необходимо установить 0, 1 и 2 для соответствующего значения.
Третий аргумент
1.0 - (double)iB/(double)rates_total, // скорость обучения: использовать 1-iB/rates_total или iB/rates_total, в зависимости от того, что находится в промежутке 0 .. 1
касается скорости обучения. Индекс iB изменяется от наибольшего значения до 0. rates_total - общее количество всех баров. Таким образом, iB/rates_total представляет собой отношение того, что еще не было вычислено, и падает с почти 1 (ничего не вычислено) до нуля (все вычислено). Соответственно, 1 минус данное значение увеличивается с почти 0 (еще ничего не изучено) до 1 (всё изучено). Важность этого соотношения объясню ниже.
Последний параметр нужен для инициализации и для того, чтобы определить, нужно ли рассчитывать кластеры. Если он больше нуля, он указывает (см. выше) количество типов значений, например инидкаторных линий, и таким образом определяет размер первого измерения глобального массива Cluster[]][] в файле ClusterTrend.mqh (см. выше).
По окончании большого цикла по всей истории цен все результаты сразу выводятся на вкладку советников по одной строке для каждой категории/кластера:
prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // отображается в начале каждой строки
0, // отображаемый тип значения
NumValues); // если <=0, этот тип значения не отображается
Здесь первый аргумент предназначен для информации и печатается в начале каждой строки, второй (0) обозначает рассчитанный тип индикатора (0=первый, 1=второй,...). Следом идет NumValues. Если он равен 0, этот тип индикатора не выводится.
Добавленный блок в полном виде выглядит так:
//+------------------------------------------------------------------+ //| добавлен для кластерного анализа | //+------------------------------------------------------------------+ if ( (prev_calculated == 0 && iB > 0 ) // мы не используем реальный бар || (prev_calculated > 9 && iB == 1)) // во время операции используется предпоследний бар: iB = 1 { if (prev_calculated==0 && iB==limit) { // только на первом проходе/баре StopWatch = GetTickCount64(); // включаем секундомер if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // если всё пересчитывается, удаляем предыдущие результаты } double actBar = fmax(up[iB], down[iB]), // получаем реальное индикаторное значение бара [iB] prvBar = fmax(up[iB+1], down[iB+1]); // получаем предыдущее индикаторное значение if ( (actBar+prvBar) < _Point ) continue; // пропускаем котировки, отсутствующие в начале или промежуточном положении enterVal(fabs(actBar-prvBar)/_Point, // абс. разность наклона индикаторной линии 0, // индекс типа значения 1.0 - (double)iB/(double)rates_total, // скорость обучения: использовать 1-iB/rates_total или iB/rates_total, в зависимости от того, что находится в промежутке 0 .. 1 NumValues // используется для инициализации (количество типов значений) и если < 1, кластеризация не проводится ); } //+------------------------------------------------------------------+ } // конец большого цикла: for(iB = limit; iB >= 0; iB--) .. //+------------------------------------------------------------------+ //| добавлен для кластерного анализа | //+------------------------------------------------------------------+ if (prev_calculated < 1) // отобразить только один раз после инициализации { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // отображается в начале каждой строки 0, // отображаемый тип значения NumValues); // если <=0, этот тип значения не отображается if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and Ram: ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL),", Time: ", TimeToString(StopWatch/1000,TIME_SECONDS),":",StringFormat("%03i",StopWatch%1000) ); } //+------------------------------------------------------------------+
Это все изменения, которые я хотел внести в индикатор.
Кластерный анализ в файле ClusterTrend.mqh
Файл находится в той же папке, что и индикатор, поэтому его необходимо подключить в виде ClusterTrend.mqh.
В начальной части есть упрощения, связанные с #define. #define crash(strng) намеренно вызывает деление на 0, которое компилятор не распознает, поскольку индикатор (по-прежнему?) не умеет завершать собственную работу. По крайней мере, alert(), заявляющий о неправильной спецификации измерения, вызывается только один раз. Необходимо это исправить и перекомпилировать индикатор.
Структура данных, используемых для этого анализа, уже была описана выше.
Рассмотрим суть этого подхода.
Среднее значение, дисперсия, а также кластерный анализ используют в целом доступные данные. Данные сначала должны быть собраны. Затем производится кластеризация одним или несколькими циклами. Традиционно среднее от всех предыдущих значений, поступающих одно за другим, вычисляется на втором цикле в больших общих данных для суммирования. Это занимает очень много времени. Однако мне удалось найти статью Тони Финча "Инкрементальный расчет взвешенного среднего и дисперсии" (на английском), в которой автор вычисляет среднее значение и дисперсию инкрементально, то есть за один проход по всем данным, вместо того, чтобы суммировать все данные и затем делить сумму на количество значений. Таким образом, новое (простое) среднее значение по всем предыдущим значениям, включая вновь переданное, рассчитывается по формуле (4), п.1:
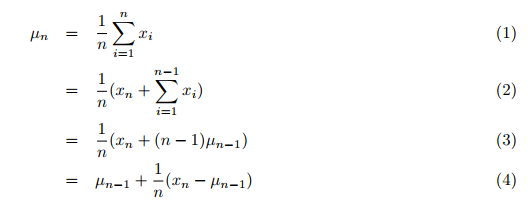
где:
- µn = обновленное среднее значение,
- µn-1 = предыдущее среднее значение,
- n = текущее количество значений (включая новое),
- xn = новое n-е значение.
Даже дисперсия вычисляется на лету, а не на втором цикле после среднего значения. Затем рассчитывается инкрементальная дисперсия (формулы 24, 25; п. 3):
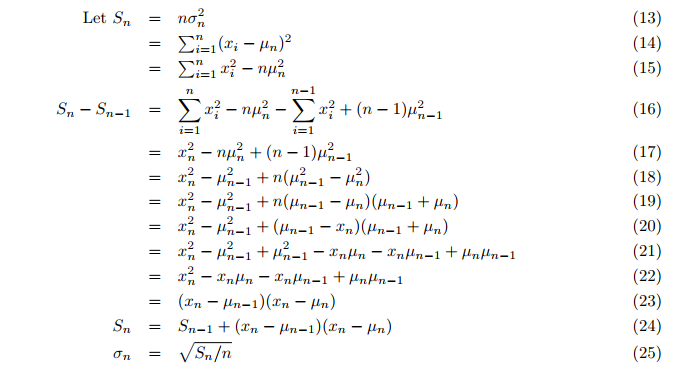
где:
- Sn = обновленное значение вспомогательной переменной S,
- σ = дисперсия.
Таким образом, среднее значение и дисперсия генеральной совокупности могут быть рассчитаны за один проход, каждый раз обновляя последнее новое значение в функции incrStdDeviation(..):
Исходя из этого, рассчитанное таким образом среднее значение можно использовать для классификации уже после первой части исторических данных. Вы можете спросить, почему бы просто не использовать скользящую среднюю, которая быстро и легко выдает полезные результаты с небольшим объемом данных? Скользящая средняя варьируется. А для целей классификации нам нужна относительно постоянная величина сравнения. Представьте, что нам нужно измерить уровень воды в реке. Понятно, что сравнительное значение нормального уровня воды не должно изменяться с текущей высотой. В частности, во время сильных трендов различия скользящей средней также увеличиваются, а разница с данным значением становится неоправданно меньше. Когда рынок становится флэтовым, среднее значение также уменьшается, увеличивая разницу с базовым значением. Поэтому нам нужно очень стабильное значение, являющееся средним максимально возможного значения.
Мы наконец-то дошли до кластеризации. Обычно для формирования кластеров используются все значения. Однако инкрементный расчет среднего значения дает нам еще одну возможность: мы используем самые ранние 50% исторических данных для среднего значения и самые поздние 50% – для кластеризации (продолжая вычисление среднего значения). Этот процент (50%) здесь называется скоростью обучения в том смысле, что среднее значение "усвоено" только до 50%. Однако его расчет не прекращается после достижения 50%, но теперь он настолько стабилен, что дает хорошие результаты. Тем не менее, введение 50%, по сути, остается моим произвольным решением, поэтому я ввел два других средних значения для сравнения: 25% и 75%. Они начинают вычислять свое среднее значение после достижения своей скорости обучения. Благодаря этому мы можем видеть, в какую сторону и насколько сильно изменился наклон.
Создание среднего значения и кластера
Практически всё управляется функцией enterVal() файла ClusterTrend.mqh:
//+------------------------------------------------------------------+ //| | //| добавляем новое значение | //| | //+------------------------------------------------------------------+ // использовать; enterVal( fabs(indi[i]-indi[i-1]), 0, (double)iB/(double)rates_total ) void enterVal(const double val, const int iLne, const double learn, const int NoVal) { if (NoVal<=0) return; // если true, ничего не делаем if( ArrayRange(Cluster,0)<NoVal || Cluster[iLne][0].n <= 0 ) // необходима инициализация setStattID(NoVal); incrStdDeviation(val, Cluster[iLne][0]); // расчет от первого до последнего бара if(learn>0.25) incrStdDeviation(val, Cluster[iLne][1]); // как варьируется µ после 25% всех баров if(learn>0.5) incrStdDeviation(val, Cluster[iLne][2]); // как варьируется µ после 50% всех баров if(learn>0.75) incrStdDeviation(val, Cluster[iLne][3]); // как варьируется µ после 75% всех баров if(learn<0.5) return; // Я использую 50% для обучения и 50% для работы с категориями int i; if (Cluster[iLne][0].µ < _Point) return; // избежим деления на ноль double pc = val/(Cluster[iLne][0].µ); // '%'-новое значение в сравнении с долговременным µ от Cluster[0].. for(i=0; i<ArraySize(CatCoeff); i++) { if(pc <= CatCoeff[i]) { incrStdDeviation(val, Cluster[iLne][i+4]); // найдем нужную категорию return; } } i = ArraySize(CatCoeff); incrStdDeviation(val, Cluster[iLne][i+4]); // слишком большое? Включим его в последнюю категорию }
val – значение, полученное от индикатора, iLine – индекс типа значения, learn – скорость обучения или соотношение выполненной работы/истории. Наконец, NoVal позволяет нам узнать, сколько типов значений (если таковые имеются) должны быть рассчитаны.
Сперва проверим (NoVal<=0), намеренно ли проводится кластеризация или нет.
Затем посмотрим (ArrayRange(Cluster,0) < NoVal), имеет ли первое измерение массива Cluster[][] размер типов значений для расчета. В противном случае выполняется инициализация, все значения обнуляются, а идентификатор присваивается функцией setStattID(NoVal) (см. ниже).
Я хочу, чтобы объем кода был небольшим и не возникало сложностей с его применением. Кроме того, это позволит быстро вспомнить его по прошествии какого-то времени. Таким образом значение val присваивается соответствующей структуре данных через одну и ту же функцию incrStdDeviation(val, Cluster[][]) и обрабатывается там же.
Функция incrStdDeviation(val, Cluster[iLne][0]) рассчитывает среднее значение от первого значения до последнего. Как уже было сказано, первый индекс [iLine] обозначает тип значения, а второй индекс [0] обозначает структуру данных типа значения для расчета. Как мы уже знаем, нам нужно на 5 элементов больше, чем имеется в статическом массиве CatCoeff[9]. Теперь мы видим почему:
- [0] .. [3] необходимы для различных средних значений [0]:100%, [1]:25%, [2]:50%, [3]:75%,
- [4] .. [12] необходимы для 9 категорий CatCoeff[9]: 0.0, .., 7.87
- [13] необходим в качестве последней категории для значений, которые больше, чем самая большая категория CatCoeff[8] (в данном случае 7.87).
Теперь мы видим, для чего нам нужно стабильное среднее значение. Чтобы найти категорию или кластер, мы рассчитываем соотношение val/Cluster[iLne][0].µ. Это общее среднее значение типа с индексом iLine. Следовательно, коэффициенты массива CatCoeff[] являются множителями общего среднего значения, если преобразовать уравнение:
pc = val/µ => pc*µ = val
Это означает, что мы не только предварительно определили количество кластеров (это требуется для большинства методов кластеризации), мы также предварительно определили свойства кластеров, что довольно необычно, но именно по этой причине для этого метода кластеризации требуется только один проход, в то время как другие методы требуют нескольких проходов по всем данным, чтобы найти оптимальные свойства кластеров (см. выше).Самый первый коэффициент (CatCoeff [0]) равен нулю. Он был выбран, потому что индикатор HalfTrend предназначен для горизонтального прогона нескольких баров, поэтому разница значений индикатора в этом случае равна нулю. Таким образом, ожидается, что эта категория достигнет значительных размеров. Все остальные назначения выполняются, при условии что:
pc <= CatCoeff[i] => val/µ <= CatCoeff[i] => val <= CatCoeff[i]*µ.
Поскольку нам никуда не деться от выбросов, которые уничтожили бы указанные категории в CatCoeff[], для таких значений существует дополнительная категория:
i = ArraySize(CatCoeff);
incrStdDeviation(val, Cluster[iLne][i+4]); // слишком большое? Включим его в последнюю категорию
Оценка и отображение результатов
Сразу по окончании большого цикла индикатора и только при первом проходе (prev_calculated < 1) результаты печатаются в журнале с помощью prtStdDev(), затем StopWatch останавливается и также отображается:
//+------------------------------------------------------------------+ //| добавлен для кластерного анализа | //+------------------------------------------------------------------+ if (prev_calculated < 1) { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, 0, NumValues); if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL)," Ram: ",TimeToString(StopWatch/1000,TIME_SECONDS)); } //+------------------------------------------------------------------+
prtStdDev(..) сначала отображает заголовок с HeadLineIncrStat(pre), а затем для каждого типа значения (индекс iLine) – все 14 результатов в каждой строке с использованием retIncrStat():
void prtStdDev(const string pre, int iLne, const int NoVal) { if (NoVal <= 0 ) return; // при true не отображаем if (Cluster[iLne][0].n==0 ) return; // в эту 'строку' не вводим никаких значений HeadLineIncrStat(pre); // отображаем заголовок int i,tot = 0,sA=ArrayRange(Cluster,1), sC=ArraySize(CatCoeff); for(i=4; i<sA; i++) tot += (int)Cluster[iLne][i].n; // суммируем общий объем всех категорий кроме первой [0] retIncrStat(Cluster[iLne][0].n, pre, "learn 100% all["+(string)sC+"]", Cluster[iLne][0], 1, Cluster[iLne][0].µ); // отобразим основание первой категории [0] retIncrStat(Cluster[iLne][1].n, pre, "learn 25% all["+(string)sC+"]", Cluster[iLne][1], 1, Cluster[iLne][0].µ); // отобразим основание первой категории [0] retIncrStat(Cluster[iLne][2].n, pre, "learn 50% all["+(string)sC+"]", Cluster[iLne][2], 1, Cluster[iLne][0].µ); // отобразим основание первой категории [0] retIncrStat(Cluster[iLne][3].n, pre, "learn 75% all["+(string)sC+"]", Cluster[iLne][3], 1, Cluster[iLne][0].µ); // отобразим основание первой категории [0] for(i=4; i<sA-1; i++) { retIncrStat(tot, pre,"Cluster["+(string)(i)+"] (<="+_d22(CatCoeff[i-4])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // отобразим каждую категорию } retIncrStat(tot, pre,"Cluster["+(string)i+"] (> "+_d22(CatCoeff[sC-1])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // отобразим последнюю категорию }
Здесь tot += (int)Cluster[iLne][i].n – число значений в категориях 4-13, просуммированных для получения сравнительного значения (100%) для этих категорий. Отображаемые данные приведены ниже:
GBPUSD PERIOD_D1 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_D1 HalfTrd 2 100100 learn 100% all[9] 7266 (100.0%) 217.6 (1.00*µ) 1800.0 (1.21%) 0.0 - 148850.0 GBPUSD PERIOD_D1 HalfTrd 2 100025 learn 25% all[9] 5476 (100.0%) 212.8 (0.98*µ) 470.2 (4.06%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100050 learn 50% all[9] 3650 (100.0%) 213.4 (0.98*µ) 489.2 (4.23%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100075 learn 75% all[9] 1825 (100.0%) 182.0 (0.84*µ) 451.4 (3.90%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 400000 Cluster[4] (<=0.00) 2410 ( 66.0%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_D1 HalfTrd 2 500033 Cluster[5] (<=0.33) 112 ( 3.1%) 37.9 (0.17*µ) 20.7 (27.66%) 1.0 - 76.0 GBPUSD PERIOD_D1 HalfTrd 2 600076 Cluster[6] (<=0.76) 146 ( 4.0%) 124.9 (0.57*µ) 28.5 (26.40%) 75.0 - 183.0 GBPUSD PERIOD_D1 HalfTrd 2 700132 Cluster[7] (<=1.32) 171 ( 4.7%) 233.3 (1.07*µ) 38.4 (28.06%) 167.0 - 304.0 GBPUSD PERIOD_D1 HalfTrd 2 800204 Cluster[8] (<=2.04) 192 ( 5.3%) 378.4 (1.74*µ) 47.9 (25.23%) 292.0 - 482.0 GBPUSD PERIOD_D1 HalfTrd 2 900298 Cluster[9] (<=2.98) 189 ( 5.2%) 566.3 (2.60*µ) 67.9 (26.73%) 456.0 - 710.0 GBPUSD PERIOD_D1 HalfTrd 2 1000421 Cluster[10] (<=4.21) 196 ( 5.4%) 816.6 (3.75*µ) 78.9 (23.90%) 666.0 - 996.0 GBPUSD PERIOD_D1 HalfTrd 2 1100580 Cluster[11] (<=5.80) 114 ( 3.1%) 1134.9 (5.22*µ) 100.2 (24.38%) 940.0 - 1351.0 GBPUSD PERIOD_D1 HalfTrd 2 1200787 Cluster[12] (<=7.87) 67 ( 1.8%) 1512.1 (6.95*µ) 136.8 (26.56%) 1330.0 - 1845.0 GBPUSD PERIOD_D1 HalfTrd 2 1300999 Cluster[13] (> 7.87) 54 ( 1.5%) 2707.3 (12.44*µ) 1414.0 (14.47%) 1803.0 - 11574.0 Time needed for 7302 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:016
Что мы видим? Пойдем от столбца к столбцу. В первом столбце указаны символ, таймфрейм, название индикатора и его "Амплитуда" (Amplitude), как указано в ShortName. Во втором столбце отображается идентификатор каждой структуры данных. 100nnn показывает, что это просто вычисление среднего значения с последними тремя цифрами, указывающими скорость обучения (100, 25, 50 и 75). 400nnn .. 1300nnn – категории, кластеры или кучи. Здесь последние три цифры указывают категорию или множитель для среднего µ, которое также показано в третьем столбце Cluster в скобках. Это всё понятно и не требует пояснений.
Теперь самая интересная часть. В четвертом столбце указано количество значений в соответствующей категории и процентное соотношение в скобках. Интересно то, что индикатор большую часть времени находится в горизонтальном положении (категория #4 – 2409 баров или дней 66.0%), то есть торговля в диапазоне могла бы быть успешной две трети от всего времени. Тем не менее, (локальных) максимумов было больше в категориях #8, #9 и #10, в то время как в категории #5 значений наблюдалось на удивление мало (112, 3.1%). И теперь этот факт можно интерпретировать как разрыв между двумя пороговыми значениями. Он дает нам следующие приблизительные значения:
если fabs(slope) < 0.5*µ => рынок флэтовый, необходимо торговать в диапазоне
если fabs(slope) > 1.0*µ => рынок трендовый, необходимо оседлать волну
Первые 4 строки с идентификаторами 100nnn позволяют нам оценить стабильность значения µ. Как уже было сказано, нам не нужно значение, которое колеблется слишком сильно. Мы видим, что µ снижается с 217.6 (пунктов в день) при 100100 до 182.1 при 100075 (для данного µ используются только последние 25% значений), или 16%. Думаю, не слишком много. Что это нам говорит? Волатильность GBPUSD снизилась. Первое значение в этой категории датировано 28.05.2014 00:00:00. Возможно, это следует учитывать.
При вычислении среднего значения дисперсия σ отображает ценную информацию, что приводит нас к столбцу 6 (σ (Range %)). Он показывает, насколько близки отдельные значения к среднему значению. Для нормально распределенных значений 68% всех значений находятся в пределах дисперсии. Применительно к дисперсии это значит, чем меньше, тем точнее (четче) среднее значение. В круглых скобках указано соотношение σ/(макс-мин) из последних двух столбцов. Это также показатель качества дисперсии и среднего.
Теперь посмотрим, повторяются ли результаты GBPUSD D1 на меньших таймфреймах, в частности на M15. Для этого достаточно просто переключить таймфрейм графика с D1 на M15:
GBPUSD PERIOD_M15 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_M15 HalfTrd 2 100100 learn 100% all[9] 556389 (100.0%) 18.0 (1.00*µ) 212.0 (0.14%) 0.0 - 152900.0 GBPUSD PERIOD_M15 HalfTrd 2 100025 learn 25% all[9] 417293 (100.0%) 18.2 (1.01*µ) 52.2 (1.76%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100050 learn 50% all[9] 278195 (100.0%) 15.9 (0.88*µ) 45.0 (1.51%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100075 learn 75% all[9] 139097 (100.0%) 15.7 (0.87*µ) 46.1 (1.55%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 400000 Cluster[4] (<=0.00) 193164 ( 69.4%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_M15 HalfTrd 2 500033 Cluster[5] (<=0.33) 10528 ( 3.8%) 3.3 (0.18*µ) 1.7 (33.57%) 1.0 - 6.0 GBPUSD PERIOD_M15 HalfTrd 2 600076 Cluster[6] (<=0.76) 12797 ( 4.6%) 10.3 (0.57*µ) 2.4 (26.24%) 6.0 - 15.0 GBPUSD PERIOD_M15 HalfTrd 2 700132 Cluster[7] (<=1.32) 12981 ( 4.7%) 19.6 (1.09*µ) 3.1 (25.90%) 14.0 - 26.0 GBPUSD PERIOD_M15 HalfTrd 2 800204 Cluster[8] (<=2.04) 12527 ( 4.5%) 31.6 (1.75*µ) 4.2 (24.69%) 24.0 - 41.0 GBPUSD PERIOD_M15 HalfTrd 2 900298 Cluster[9] (<=2.98) 11067 ( 4.0%) 47.3 (2.62*µ) 5.5 (23.91%) 37.0 - 60.0 GBPUSD PERIOD_M15 HalfTrd 2 1000421 Cluster[10] (<=4.21) 8931 ( 3.2%) 67.6 (3.75*µ) 7.3 (23.59%) 54.0 - 85.0 GBPUSD PERIOD_M15 HalfTrd 2 1100580 Cluster[11] (<=5.80) 6464 ( 2.3%) 94.4 (5.23*µ) 9.7 (23.65%) 77.0 - 118.0 GBPUSD PERIOD_M15 HalfTrd 2 1200787 Cluster[12] (<=7.87) 4390 ( 1.6%) 128.4 (7.12*µ) 12.6 (22.94%) 105.0 - 160.0 GBPUSD PERIOD_M15 HalfTrd 2 1300999 Cluster[13] (> 7.87) 5346 ( 1.9%) 241.8 (13.40*µ) 138.9 (4.91%) 143.0 - 2971.0 Time needed for 556391 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:140
Конечно, средний наклон теперь намного меньше. Он снижается с 217.6 пунктов в день до 18.0 пунктов за 15 минут. Но и здесь можно увидеть похожее поведение:
если fabs(slope) < 0.5*µ => рынок флэтовый, необходимо торговать в диапазоне
если fabs(slope) > 1.0*µ => рынок трендовый, необходимо оседлать волну
Все остальное, связанное с интерпретацией дневного таймфрейма, сохраняет свою актуальность.
Заключение
Использовав в качестве примера индикатор HalfTrend, мы показали, что простая категоризация или кластерный анализ может предоставить очень ценную информацию о поведении индикатора, получение которой иным способом требует больших вычислительных ресурсов. Обычно среднее значение и дисперсия вычисляются в отдельных циклах, за которыми следуют дополнительные циклы для кластеризации. Здесь же мы организовали всё в одном большом цикле, который также вычисляет индикатор. Первая часть данных используется для обучения, а вторая – для применения того, что изучено. И всё это менее чем за секунду даже при большом объеме данных. Это позволяет отображать актуальную информацию в оперативном режиме, что особенно ценно для торговли.
Все продумано так, чтобы пользователи могли быстро и легко вставить строки кода, необходимые для такого анализа, в собственный индикатор. Это не только позволяет им проверить, может ли их собственный индикатор определить текущее состояние рынка, но и предоставляет ориентиры для дальнейшего развития их собственной идеи.
Что дальше?
В следующей статье мы применим этот подход к стандартным индикаторам. Это позволит взглянуть на них по-новому и расширить их интерпретацию. Также будут приведены примеры того, как действовать, если вы хотите использовать этот инструментарий самостоятельно.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/9527
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте Карл, можно ли запустить этот индикатор в mt4? Если да, то какие изменения нужно внести.
Большое спасибо!
Привет, Карл, можно ли запустить этот индикатор в mt4? Если да, то какие изменения нужно внести.
Большое спасибо!
Ну, это должно быть изменено. Есть несколько статей о разнице между мт4 и мт5, например:
https://www.mql5.com/ru/articles/81
https://www.mql5.com/ru/articles/66
https://www.mql5.com/en/forum/179991 // Конвертер МТ4 => МТ5
https://www.mql5.com/ru/code/16006 // Ордера из мт4 в мт5
https://www.mql5.com/en/blogs/post/681230
https://www.mql5.com/ru/users/iceron/publications => Выберите его статьи CrossPlattform.
Только наоборот.
спасибо за вашу идею!
Слышали ли вы о продукте под названием "Trend Pro"?
Мне кажется, индикатор в вашей статье очень похож на "Trend Pro". По крайней мере, внешне.
Я думаю, что индикатор в вашей статье очень похож на "Trend Pro".
Если нет, то знаете ли вы разницу между ними.
Привет, Карл. Спасибо за идею!
Слышали ли вы о продукте под названием "Trend Pro"?
Мне кажется, индикатор в вашей статье очень похож на "Trend Pro". По крайней мере, внешне.
Они одинаковые?
Если нет, то знаете ли вы разницу между ними.