
聚类分析(第一部分):精通指标线的斜率

抽象
聚类分析是人工智能最重要的元素之一。 据观测,通常以数字或点的元组形式,被分组为聚类或堆。 其目标是,通过为聚类或类别成功分配观测点,将该类别的已知属性分配给新观测点,然后采取相应地行动。 此处的目标是查看指标的斜率能否以及如何告诉我们行情是横盘、亦或跟随趋势。
编号和命名约定
作为示例的指标 “HalfTrend” 是在传统的 MQL4 中构建的,因此价格图表上的柱线或蜡条线 (iB) 的索引从其最大值 (rates_total)、最久远的柱线的索引递减计数至零、零号柱线是最新和当前柱线。 指标启动后第一次调用 OnCalculate() 函数时,prev_calculated 的初值为零,因为尚未计算任何内容;在随后的调用中,它可以用来检测有多少根柱线已经被计算过,还有多少没有计算。
该指标使用双色指标线,由两个数据缓冲区 up[] 和 down[] 实现 - 每个都拥有自己的颜色。 同一时间只有两个缓冲区之一会收到大于零的有效值,另一个在相同位置(具有相同索引 iB 的缓冲区元素)分配为零,而这意味着该时刻它不会被绘制。
为了尽可能简单地在其他指标或程序里运用此聚类分析,针对 HalfTrend 指标加入了尽可能少的内容。 指标代码中后添加的行用以下注释“囊括”:
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ .... //+------------------------------------------------------------------+
您可以在文件 ClusterTrend.mqh 中找到完整的聚类分析函数和数据,该文件附于文后。 整个计算的基础是如下的所有聚类数据结构:
struct __IncrStdDev { double µ, // average σ, // standard deviation max,min, // max. and min. values S2; // auxiliary variable uint ID,n; // ID and no. of values };
µ 是均值,σ 是标准差 - 方差根,它表示聚类中的值围绕均值附近的变化程度 - max 和 min 分别是聚类中的最大值和最小值,S2 是辅助变量。 n 是聚类中的数值数量,ID 是聚类的标识符。
这个数据结构是规划在一个二维数组当中:
__cluster cluster[][14];
由于在 MQL5 中只能动态调整多维数组的第一维,故将需检查的数值类型数量分配给它。 如此它便可很容易地改变。 第二维是分类值的数量,固定在如下一维数组中:
double CatCoeff[9] = {0.0,0.33,0.76,1.32,2.04,2.98,4.21,5.80,7.87};
由于 CatCoeff 条件里系数的数量决定了 Cluster 的第二维的固定大小,因此两条线紧挨着彼此,它必须大于 5。 原因将在下面解释。 由于两个数组互为条件,因此可以轻松地一起更改它们。
仅检测指标值与其先前值的差异:x[iB] - x[iB+1]。 这些差异被转换为点数 (_Point),以便实现不同交易产品的可比性,例如含有 5 个小数位的 EURUSD,和仅含有两个小数位的 XAUUSD(黄金)。
挑战
为了进行交易,本质上要了解行情是横盘,亦或趋势强弱。 在窄幅震荡走势中,围绕一个合适的平均指标,当从通道的边界回返时进行交易,直至回到通道的中心;而在趋势中,必须在远离指标平均水平的趋势方向上进行交易,直至再次自通道中心向反方向远离,即逆势翻转。 因此,可用在 EA 当中的近乎完美的指标需要能明确区分这两种状态。 EA 需要一个反映行情行为的数字,且它需要阈值才能知道在这种情况下,指标的数字是表示趋势还是横盘。 从视觉上看,在这方面进行评估通常看似很容易。 但视觉感受往往难以量化化为公式和/或数字。 聚类分析是一种对数据进行分组,或将它们分配到类别的数学方法。 它将帮助我们区分这两种行情状态。聚类分析通过优化来定义或实现:
- 聚类数量
- 聚类的中心
- 点的分配仅针对一个聚类 - 如果可能(= 没有重叠聚类)。
- 把所有或尽可能多的数字元组(可能除了异常值)分配给一个聚类,
- 聚类的大小尽可能小
- 它们尽可能少地重叠(那样的话然后不清楚一个点是否属于它,或其相邻聚类),
- 聚类的数量尽可能少。
这会导致这样一个事实,特别是带来许多点、值或元素、以及许多聚类,该问题在计算上可能变得非常昂贵。
O-计数法
计算工作量的采用 O-计数法的形式表示。 例如,O(n) 意味着这里的计算只需要访问所有 n 个元素一次。 众所周知,体现这个量值重要性的例子是数值排序算法。 最快的通常为 O(nlog(n)),最慢的通常为 O(n²)。 不仅在过去,这对于大数据和速度不那么快的计算机来说都是一个重要的标准。 今天,计算机的速度提升了很多倍,但与此同时,在某些领域,数据量(环境的光学分析,和对象分类)增长得更多。
聚类分析中第一个也是最著名的算法是 k-means。 它通过最小化到聚类中心的(欧几里德)距离,把 n 个观测值或 d 维向量分配给 k 个聚类。 这导致计算成本为 O(n^(dk+1))。 我们只有一个维度 d,即各个指标与前一个值的差异,但整个价格历史,例如用于 GBPUSD D1(日线)蜡烛图的 MQ 模拟账户包括 7265 根柱线,或报价蜡烛线,即公式中的 n。 由于一开始我们不知道有多少聚类是有用的,或者我们需要多少,故我采用 k=9 聚类或类别。 根据这个关系,这将导致效力为 O(7265^(1*9+1)) 或 O(4,1*10^38)。 对于普通的交易计算机来说量太大了。 运用此处介绍的方法,可在 16 毫秒内实现聚类,即每秒 454.063 个值。 运用此程序计算 GBPUSD m15 的柱线(15 分钟的柱线)时,我们有 556.388 根柱线和 9 个聚类,它需要 140 毫秒,或每秒 3.974.200 个值。 这表明聚类甚至比 O(n) 更好,这可以通过 MQ 的终端组织数据的方式来证明,因为在这个周期里所有计算指标的算力也注入了。
指标
作为指标,我采用来自 MQ 的 “HalfTrend”,它附于文后。 它有更长的水平运行旅程:

对于这个指标,我现在的问题在于它是否有明确的分离,即可被解释为横盘迹象的阈值,和一个表明无论是上涨亦或下跌趋势的阈值。 当然,每个人都会立即看到,如果该指标恰好是水平的,则行情为横盘。 但行情的斜率高度变化如此之小,以至于仍然认为行情处于横盘,并自某个高度开始必须假设其为趋势。 想象一下 EA 只看到一个数字,其中浓缩了整个图表图片,而不是我们在上图中看到的较大的图片。 这将通过聚类分析来解决。 但在我们转向聚类分析之前,我们首先研究在指标中所做的修改。
指标里的变化
由于应尽可能少地修改指标,因此聚类已移至外部文件 ClusterTrend.mqh,该文件会在指标的开头包含;
当然这个文件也附于文后。 但仅此还不够。 为了令您自己的尝试尽可能简单,还加了输入变量 NumValues :
input int NumValues = 1;
该值为 1 意味着(仅)一种数值类型应被检查。 例如,如果您想分析一个计算两个平均值的指标,且您想估算两者的斜率,那么这两个 NumValues 之间的距离应设为 3。 然后进行计算的数组会自动调整。 如果该值设置为零,则不执行聚类分析。 如此,这个额外的负担就可以很轻易地通过设置关闭。
甚而,还有全局变量
string ShortName;
long StopWatch=0;
ShortName 在 OnInit() 中会被赋予指标简称:
ShortName = "HalfTrd "+(string)Amplitude;
IndicatorSetString(INDICATOR_SHORTNAME,ShortName);
在打印结果时,这可用于识别。
StopWatch 用于计时,在进行聚类分析时,传递第一个值之前即刻设置,并在打印结果后读取:
if (StopWatch==0) StopWatch = GetTickCount64();
...
if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch;
几乎与所有指标一样,它也会大规模循环遍历价格历史的所有可用柱线。 该指标计算其值,以便图表上索引 iB=0 的柱形包含当前、最近接收的价格,而最大可能的索引代表价格历史的开始,即最久远的柱线。 这个循环结束前的最后一件事,封闭括弧,数值是要分析计算,并传递给聚类函数进行评估。 那里一切都是自动化的。 下面将进一步说明。
在循环结束之前的代码块中,首先要做的是确保对每根柱线仅执行一次基于历史价格的聚类分析,而非每次出现新价格时都重复工作:
//+------------------------------------------------------------------+
//| added for cluster analysis |
//+------------------------------------------------------------------+
if ( (prev_calculated == 0 && iB > 0 ) // we don't use the actual bar
|| (prev_calculated > 9 && iB == 1)) // during operation we use the second to last bar: iB = 1
{
然后我们检查它是否是初始化的第一根柱线,设置秒表,并废弃前一个。 结果(如果有):
if (prev_calculated==0 && iB==limit) { // only at the very first pass/bar
StopWatch = GetTickCount64(); // start the stop whatch
if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // in case everything is recalculated delete prev. results
}
然后指标值由柱线指数 iB,和前一根柱线的索引 iB+1 来判定。 由于该指标线是双色的(见上文),并且这是由两个缓冲区 up[] 和 down[]实现的,始终会有其中之一为 0,0,故此不会绘制,而能看到的指标线是两个缓冲区之一大于零的那个:
double actBar = fmax(up[iB], down[iB]), // get actual indi. value of bar[iB]
prvBar = fmax(up[iB+1], down[iB+1]); // get prev. indi. value
为了确保聚类分析能够受到计算开始的数值影响,虽然指标根本还未计算过,但需有这个安全检查:
if ( (actBar+prvBar) < _Point ) continue; // skip initially or intermediately missing quotes
现在我们可以传递指标当前与其前值的绝对差值。
enterVal(fabs(actBar-prvBar)/_Point, // abs. of slope of the indi. line
0, // index of the value type
1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1
NumValues // used for initialization (no. of value types) and if < 1 no clustering
);
为什么我们在第一个参数中使用绝对差 fabs(actBar-prvBar)? 如果我们传递的是纯差值,我们将不得不判断两倍数量的聚类,大于零和小于零的聚类。 然后,价格在整个可用价格历史记录中上涨或下跌也将变得相关,这可能会令结果失真。 最终,(对我而言)重要的是坡度的陡峭度,而非它的方向。 在外汇市场,我认为可以合理地假设价格的涨跌在某种程度上是相同的 — 大概与股市不同。
第二个参数,0,是所传递数值的类型索引(0=第一个,1=第二个,..)。 有了两条指标线及其差异,我们需要分别为数值设置 0、1 和 2。
第三个参数
1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1
与学习率有关。 指数 iB 从最大值递减到 0。 rates_total 是所有柱线的总数。 因此,iB/rates_total 是尚未计算的比率,大多从 1(未计算)递减到 0(所有均已计算),因此 1 减去此值后大多从 0(尚未学习)递增到 1(完成)。 这个比率的重要性在下面解释。
需要最后一个参数来进行初始化,以及指示是否应该计算聚类。 如果它大于零,它指定(见上文)数值类型的数量,例如指标线,从而判定文件 ClusterTrend.mqh 中全局数组 Cluster[]][] 的第一维大小(见上文)。
在遍历整个价格历史的大循环完毕后,每个类别/聚类的所有结果都在智能系统选项卡里打印一行:
prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // printed at the beginning of each line
0, // the value type to be printed
NumValues); // if <=0 this value type is not printed
这里的第一个参数是为了提供信息,并打印在每行的开头;第二个参数,0,表示所计算指标类型(0=第一个,1=第二个,..),最后是 NumValues。 如果为 0,则不打印此指标类型。
总体而言,添加的模块如下所示:
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if ( (prev_calculated == 0 && iB > 0 ) // we don't use the actual bar || (prev_calculated > 9 && iB == 1)) // during operation we use the second to last bar: iB = 1 { if (prev_calculated==0 && iB==limit) { // only at the very first pass/bar StopWatch = GetTickCount64(); // start the stop whatch if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // in case everything is recalculated delete prev. results } double actBar = fmax(up[iB], down[iB]), // get actual indi. value of bar[iB] prvBar = fmax(up[iB+1], down[iB+1]); // get prev. indi. value if ( (actBar+prvBar) < _Point ) continue; // skip initially or intermediately missing quotes enterVal(fabs(actBar-prvBar)/_Point, // abs. of slope of the indi. line 0, // index of the value type 1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1 NumValues // used for initialization (no. of value types) and if < 1 no clustering ); } //+------------------------------------------------------------------+ } // end of big loop: for(iB = limit; iB >= 0; iB--) .. //+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if (prev_calculated < 1) // print only once after initialization { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // printed at the beginning of each line 0, // the value type to be printed NumValues); // if <=0 this value type is not printed if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and Ram: ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL),", Time: ", TimeToString(StopWatch/1000,TIME_SECONDS),":",StringFormat("%03i",StopWatch%1000) ); } //+------------------------------------------------------------------+
这些都是指标里的变化。
ClusterTrend.mqh 文件中的聚类分析
该文件与指标位于同一文件夹中,因此它必须包含在“ClusterTrend.mqh”形式中。
在一开始,#define 做了一些简化。 #define crash(strng) 人为地引发除 0,而编译器无法识别,只因实际当中(仍然?)指标程序无法自行终止。 这也并非十分成功,但至少申明错误维度规范的 alert() 能被调用一次。 更正它,并重新编译您的指标。
为分析而构建的数据结构已在上面进行了讲述。
现在我们来深入这个方法的思想核心。
实际上,均值、方差以及聚类分析都必须依据可用的总体数据来计算。 首先,必须收集数据,然后在第二步中通过一个或多个循环完成这些数值和聚类。 传统上,逐一到达的所有先前数值的平均值,应在第二个循环里依据整体数据较大的那个进行计算求和。 这会非常耗时。 但是我找到了 Tony Finch: 的一篇文章:“加权均值和方差的增量计算”,其中他计算均值和方差增量,即一次遍历所有数据,替代将所有数据相加,然后累加和除以数值的数量。 因此,根据第 1 页的公式 (4) 计算包括新传输的所有先前值的新(简单)平均值:
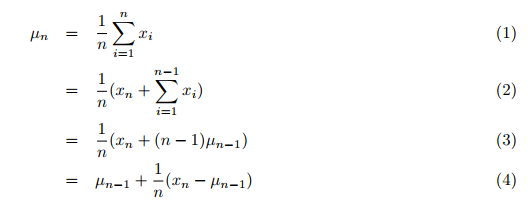
其中:
- µn = 更新后的平均值,
- µn-1 = 之前的平均值,
- n = 当前数值的数量(包括新数值),
- xn = 第 n 个新值。
甚至方差也是即时计算的,替代平均之后的第二个循环。 然后计算增量方差(公式 24,25;第 3 页):
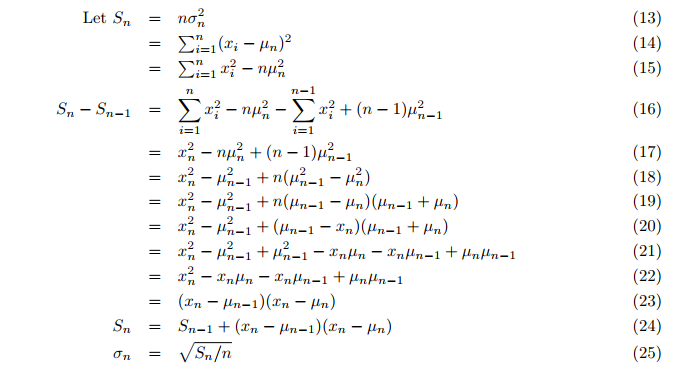
其中:
- Sn = 辅助变量 S 的更新值,
- σ = 方差。
因此,可以一次性计算总体的均值和方差,每次在函数 incrStdDeviation(..) 中更新最后的新值:
在此基础上,以这种方式计算出的平均值已经可以用于历史数据的第一部分之后的分类。 您可能会问,为什么我们不能简单地利用移动平均线,它可以用很少的数据,快速而简单地获得有用的结果? 移动平均线调整。 但是对于分类的目标,我们需要一个相对恒定的比较值。 想象一下要测量河流的水位。 很明显,正常水位的比较值一定不能随当前高度变化。 例如,在趋势强劲的时期,移动平均线的差值也会增加,而与该数值的差值会不合理地变小。 当行情趋于横盘时,平均值也会降低,实际上与该基值的差值会增加。 所以我们需要一个非常稳定的值,尽可能大量数据的平均值。
现在聚类问题出现。 传统上,有人会再次用所有数值来形成聚类。 那么,平均值的增量计算给了我们另一种可能性:我们用最久远的 50% 历史数据作为平均值,最新的 50% 作为聚类(继续计算平均值)。 这个百分比 (50%) 在这里被称为学习率,从这个意义上说,只有 50% 的平均值是“学习的”。 然而,它的计算在达到 50% 后并没有停止,且现在非常稳定,可以产生很好的结果。 尽管如此,50% 这个数字仍然是我的任性决定,所以我做了另外两个平均值来比较:25% 和 75%。它们在达到学习率后开始计算它们的平均值。 据此,我们可以看到斜率发生了怎样的变化,以及变化的程度。
创建均值和聚类
几乎所有事情都由文件 ClusterTrend.mqh 里的函数 enterVal() 进行管控: :
//+------------------------------------------------------------------+ //| | //| enter a new value | //| | //+------------------------------------------------------------------+ // use; enterVal( fabs(indi[i]-indi[i-1]), 0, (double)iB/(double)rates_total ) void enterVal(const double val, const int iLne, const double learn, const int NoVal) { if (NoVal<=0) return; // nothing to do if true if( ArrayRange(Cluster,0)<NoVal || Cluster[iLne][0].n <= 0 ) // need to inicialize setStattID(NoVal); incrStdDeviation(val, Cluster[iLne][0]); // the calculation from the first to the last bar if(learn>0.25) incrStdDeviation(val, Cluster[iLne][1]); // how does µ varies after 25% of all bars if(learn>0.5) incrStdDeviation(val, Cluster[iLne][2]); // how does µ varies after 50% of all bars if(learn>0.75) incrStdDeviation(val, Cluster[iLne][3]); // how does µ varies after 75% of all bars if(learn<0.5) return; // I use 50% to learn and 50% to devellop the categories int i; if (Cluster[iLne][0].µ < _Point) return; // avoid division by zero double pc = val/(Cluster[iLne][0].µ); // '%'-value of the new value compared to the long term µ of Cluster[0].. for(i=0; i<ArraySize(CatCoeff); i++) { if(pc <= CatCoeff[i]) { incrStdDeviation(val, Cluster[iLne][i+4]); // find the right category return; } } i = ArraySize(CatCoeff); incrStdDeviation(val, Cluster[iLne][i+4]); // tooo big? it goes to the last category }
val 是从指标接收到的数值,iLine 是数值类型的索引,learn 是学习率或完成/历史的比率,最后NoVal 能令我们知道有多少(如果有的话)数值类型要计算。
首先是测试(NoVal<=0),是否打算进行聚类。
接着检查(ArrayRange(Cluster,0) < NoVal),数组 Cluster[][] 的第一维是否已计算过数值类型的大小。 如果还没有,则执行初始化,所有值都设零,ID 由函数 setStattID(NoVal) 进行赋值(参见下文)。
我想保持较低的代码量,便于其他人可以轻松地使用它,并可令我在一段时间不用它之后,能再次理解它。 因此,值val 通过一个相同的函数 incrStdDeviation(val, Cluster[][]) 分配给相应的数据结构,并在该处进行处理。
The incrStdDeviation(val, Cluster[iLne][0]) 函数计算从第一个值到最后一个值的平均值。 如前所述,第一个索引 [iLine] 表示数值类型,第二个索引 [0] 表示所计算数值类型的数据结构。 据上述可知,我们需要比静态数组 CatCoeff[9] 中的元素数量多 5 个。现在我们明白为什么了:
- [0] .. [3] 需要不同的均值 [0]:100%, [1]:25%, [2]:50%, [3]:75%,
- [4] .. [12] 需要 CatCoeff[9]: 的 9 个类别:0.0, .., 7.87
- [13] 需要作为最后一个类别,其数值大于 CatCoeff[8] 的最大类别(此处为 7.87)。
现在我们即可理解为什么我们需要一个稳定的平均值。 为了找到类别或聚类,我们计算 val/Cluster[iLne][0].µ 的比率。这是数值类型的总体平均值,针对的是索引 iLine。 因此,如果我们变换方程,数组 CatCoeff[] 的系数是整体平均值的乘数:
pc = val/µ => pc*µ = val
这意味着我们不仅系统性预定义了聚类的数量(大多数聚类方法都需要这样做),我们还预定义了聚类的属性,这是相当不寻常的,但这就是这种聚类方法只需要一次即可通过的原因,而其他方法需要多次遍历所有数据,才能找到聚类的最佳属性(见上文)。(CatCoeff[0]) 的第一个系数为零。 之所以这样选择,是因为指标 “HalfTrend” 设计用于多柱线水平运行,因此指标值的差异为零。 因此,期望这一类别将达到显著的规模。 所有其他分配:
pc <= CatCoeff[i] => val/µ <= CatCoeff[i] => val <= CatCoeff[i]*µ.
鉴于肯定有异常值会破坏 CatCoeff[] 中的给定类别,因此针对这些值还有一个额外的类别:
i = ArraySize(CatCoeff);
incrStdDeviation(val, Cluster[iLne][i+4]); // tooo big? it goes to the last category
评估和打印
在指标大循环结束之后,且仅当它是第一遍时 (prev_calculated < 1),结果由 prtStdDev() 打印到日志里,然后秒表停止,并打印 (参阅上述):
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if (prev_calculated < 1) { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, 0, NumValues); if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL)," Ram: ",TimeToString(StopWatch/1000,TIME_SECONDS)); } //+------------------------------------------------------------------+
prtStdDev(..) 首先打印带有 HeadLineIncrStat(pre) 的标题,然后为每个数值类型(索引 iLine)在一行里打印所有 14 个结果,每个结果都用到 retIncrStat():
void prtStdDev(const string pre, int iLne, const int NoVal) { if (NoVal <= 0 ) return; // if true no printing if (Cluster[iLne][0].n==0 ) return; // no values entered for this 'line' HeadLineIncrStat(pre); // print the headline int i,tot = 0,sA=ArrayRange(Cluster,1), sC=ArraySize(CatCoeff); for(i=4; i<sA; i++) tot += (int)Cluster[iLne][i].n; // sum up the total volume of all but the first [0] category retIncrStat(Cluster[iLne][0].n, pre, "learn 100% all["+(string)sC+"]", Cluster[iLne][0], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][1].n, pre, "learn 25% all["+(string)sC+"]", Cluster[iLne][1], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][2].n, pre, "learn 50% all["+(string)sC+"]", Cluster[iLne][2], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][3].n, pre, "learn 75% all["+(string)sC+"]", Cluster[iLne][3], 1, Cluster[iLne][0].µ); // print the base the first category [0] for(i=4; i<sA-1; i++) { retIncrStat(tot, pre,"Cluster["+(string)(i)+"] (<="+_d22(CatCoeff[i-4])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // print each category } retIncrStat(tot, pre,"Cluster["+(string)i+"] (> "+_d22(CatCoeff[sC-1])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // print the last category }
此处: tot += (int)Cluster[iLne][i].n 是类别 4-13 中数值的总合,以便为这些类别提供比较值 (100%)。 而这就是我们通过打印输出得到的:
GBPUSD PERIOD_D1 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_D1 HalfTrd 2 100100 learn 100% all[9] 7266 (100.0%) 217.6 (1.00*µ) 1800.0 (1.21%) 0.0 - 148850.0 GBPUSD PERIOD_D1 HalfTrd 2 100025 learn 25% all[9] 5476 (100.0%) 212.8 (0.98*µ) 470.2 (4.06%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100050 learn 50% all[9] 3650 (100.0%) 213.4 (0.98*µ) 489.2 (4.23%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100075 learn 75% all[9] 1825 (100.0%) 182.0 (0.84*µ) 451.4 (3.90%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 400000 Cluster[4] (<=0.00) 2410 ( 66.0%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_D1 HalfTrd 2 500033 Cluster[5] (<=0.33) 112 ( 3.1%) 37.9 (0.17*µ) 20.7 (27.66%) 1.0 - 76.0 GBPUSD PERIOD_D1 HalfTrd 2 600076 Cluster[6] (<=0.76) 146 ( 4.0%) 124.9 (0.57*µ) 28.5 (26.40%) 75.0 - 183.0 GBPUSD PERIOD_D1 HalfTrd 2 700132 Cluster[7] (<=1.32) 171 ( 4.7%) 233.3 (1.07*µ) 38.4 (28.06%) 167.0 - 304.0 GBPUSD PERIOD_D1 HalfTrd 2 800204 Cluster[8] (<=2.04) 192 ( 5.3%) 378.4 (1.74*µ) 47.9 (25.23%) 292.0 - 482.0 GBPUSD PERIOD_D1 HalfTrd 2 900298 Cluster[9] (<=2.98) 189 ( 5.2%) 566.3 (2.60*µ) 67.9 (26.73%) 456.0 - 710.0 GBPUSD PERIOD_D1 HalfTrd 2 1000421 Cluster[10] (<=4.21) 196 ( 5.4%) 816.6 (3.75*µ) 78.9 (23.90%) 666.0 - 996.0 GBPUSD PERIOD_D1 HalfTrd 2 1100580 Cluster[11] (<=5.80) 114 ( 3.1%) 1134.9 (5.22*µ) 100.2 (24.38%) 940.0 - 1351.0 GBPUSD PERIOD_D1 HalfTrd 2 1200787 Cluster[12] (<=7.87) 67 ( 1.8%) 1512.1 (6.95*µ) 136.8 (26.56%) 1330.0 - 1845.0 GBPUSD PERIOD_D1 HalfTrd 2 1300999 Cluster[13] (> 7.87) 54 ( 1.5%) 2707.3 (12.44*µ) 1414.0 (14.47%) 1803.0 - 11574.0 Time needed for 7302 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:016
那么我们看到了什么? 我们逐列分析。 第一列告诉您交易品种、时间帧、指标名称及其分配给 ShortName 的"振幅"。 第二列显示每个数据结构的 ID。 100nnn 表明它只是一个平均值计算,最后三位数字表示 100、25、50 和 75 的学习率。 400nnn .. 1300nnn 是类别、聚类或堆。 这里的最后三位数字表示类别或其平均值 μ 的乘数,这也显示在括号中的 Cluster 下的第三列中。 它很清晰,不言自明。
现在它变得有趣了。 第 4 列显示相应类别中的值数量和括号中的百分比。 有趣的是,该指标大部分时间都是水平的(Cat.#4 2409 根柱线或天数 66.0%),这表明在三分之二的时间内都是可以成功进行交易的范围。 但是在类别 #8、#9 和 #10 中有更多(局部)最大值,而类别 #5 收到的值却少得惊人(112,3.1%)。 现在这可以解释为两个阈值之间的缺口,并可为我们提供以下粗略数值:
if fabs(slope) < 0.5*µ => 行情横盘,尝试进行范围交易
if fabs(slope) > 1.0*µ => 行情处于趋势,尝试随波逐流
ID 为 100nnn 的前 4 行能帮助我们估计 µ 的稳定性。 如上所述,我们不需要波动太大的值。 我们看到,µ 从 100100 处的 217.6(日线点数)下降到 100075 处的 182.1(仅该值最后的 25% 用于此 µ)或 16%。 我觉得,一点就好,但不要过多。 而这告诉我们什么? GBPUSD 的波动性有所下降。 此类别中的第一个值的日期为 2014.05.28 00:00:00。 可能应该考虑到这一点。
计算平均值时,方差 σ 显示了有价值的信息,这将我们带到第 6 列(σ (Range %))。 它表示单个值与平均值的接近程度。 对于正态分布值,所有值的 68% 位于方差之内。 对于方差,这意味着越小越好,换句话说,平均值越准确(模糊度越低)。 括号中的值后面是最后两列的比率 σ/(max-min)。 这也是方差和均值品质的度量。
现在我们看看 GBPUSD D1 的结果是否在较小的时间帧内重复,如 M15 蜡烛图。 为此,您只需简单地将图表的时间帧从 D1 切换到 M15:
GBPUSD PERIOD_M15 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_M15 HalfTrd 2 100100 learn 100% all[9] 556389 (100.0%) 18.0 (1.00*µ) 212.0 (0.14%) 0.0 - 152900.0 GBPUSD PERIOD_M15 HalfTrd 2 100025 learn 25% all[9] 417293 (100.0%) 18.2 (1.01*µ) 52.2 (1.76%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100050 learn 50% all[9] 278195 (100.0%) 15.9 (0.88*µ) 45.0 (1.51%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100075 learn 75% all[9] 139097 (100.0%) 15.7 (0.87*µ) 46.1 (1.55%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 400000 Cluster[4] (<=0.00) 193164 ( 69.4%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_M15 HalfTrd 2 500033 Cluster[5] (<=0.33) 10528 ( 3.8%) 3.3 (0.18*µ) 1.7 (33.57%) 1.0 - 6.0 GBPUSD PERIOD_M15 HalfTrd 2 600076 Cluster[6] (<=0.76) 12797 ( 4.6%) 10.3 (0.57*µ) 2.4 (26.24%) 6.0 - 15.0 GBPUSD PERIOD_M15 HalfTrd 2 700132 Cluster[7] (<=1.32) 12981 ( 4.7%) 19.6 (1.09*µ) 3.1 (25.90%) 14.0 - 26.0 GBPUSD PERIOD_M15 HalfTrd 2 800204 Cluster[8] (<=2.04) 12527 ( 4.5%) 31.6 (1.75*µ) 4.2 (24.69%) 24.0 - 41.0 GBPUSD PERIOD_M15 HalfTrd 2 900298 Cluster[9] (<=2.98) 11067 ( 4.0%) 47.3 (2.62*µ) 5.5 (23.91%) 37.0 - 60.0 GBPUSD PERIOD_M15 HalfTrd 2 1000421 Cluster[10] (<=4.21) 8931 ( 3.2%) 67.6 (3.75*µ) 7.3 (23.59%) 54.0 - 85.0 GBPUSD PERIOD_M15 HalfTrd 2 1100580 Cluster[11] (<=5.80) 6464 ( 2.3%) 94.4 (5.23*µ) 9.7 (23.65%) 77.0 - 118.0 GBPUSD PERIOD_M15 HalfTrd 2 1200787 Cluster[12] (<=7.87) 4390 ( 1.6%) 128.4 (7.12*µ) 12.6 (22.94%) 105.0 - 160.0 GBPUSD PERIOD_M15 HalfTrd 2 1300999 Cluster[13] (> 7.87) 5346 ( 1.9%) 241.8 (13.40*µ) 138.9 (4.91%) 143.0 - 2971.0 Time needed for 556391 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:140
当然,现在的平均斜率要小得多。 它从每天 217.6 点下降到 15 分钟内的 18.0 点。 但从这里也可以看到类似的行为:
if fabs(slope) < 0.5*µ => 行情横盘,尝试进行范围交易
if fabs(slope) > 1.0*µ => 行情处于趋势,尝试随波逐流
与解释日线时间帧相关的所有其他内容都保持其有效性。
结束语
以 “HalfTrend” 指标为例,有可能表明通过简单的分类或聚类分析,可以获得关于指标行为的非常有价值的信息,否则的话,计算量会很大。 正常情况下,均值和方差在单独的循环中计算,然后是进行聚类的附加循环。 在此,我们能够在一个计算指标的大循环中判定所有这些,其中数据的第一部分用于学习,而第二部分则是应用所学知识。 尽管如此,所有这一切都在不到一秒钟的时间内完成,即便数据超过 50 万条。 这令其可以实时判定和显示这些信息,这对交易非常有价值。
一切都经过精心设计,从而用户可快速轻松地将所需的这种分析代码行插入到他们自己的指标之中。 这不仅可令他们能够测试:自己的指标是否、如何、以及怎样告诉行情处于趋势或横盘的问题,还为进一步开拓他们自己的思路提供了基准。
下一步是什么?
在下一篇文章中,我们将把这种方法应用于标准指标。 其结果会导致对它们的新认知方式,和扩展的解释。 当然,若您想自己运用此工具包,这些也是如何进行处理的示例。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/9527
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

卡尔,这个指标可以在 mt4 中运行吗?
非常感谢!
卡尔,这个指标可以在 mt4 中运行吗?
非常感谢!
必须修改。有一些关于MT4和MT5区别的文章,如:
https://www.mql5.com/zh/articles/81
https://www.mql5.com/zh/articles/66
https://www.mql5.com/en/forum/179991// MT4 => MT5转换器
https://www.mql5.com/zh/code/16006// MT4订单到MT5
https://www.mql5.com/en/blogs/post/681230
https://www.mql5.com/zh/users/iceron/publications=> 选择他的 CrossPlattform 文章
只是反过来而已。
hi Carl. thank you for your idea!
Have you heard of the product named "Trend Pro"?
I think the indicator in your article are very similar to "Trend Pro". At least in appearance.
Are they the same?
If not, do you know the difference between them.
hi Carl. thank you for your idea!
Have you heard of the product named "Trend Pro"?
I think the indicator in your article are very similar to "Trend Pro". At least in appearance.
Are they the same?
If not, do you know the difference between them.