
Уменьшаем расход памяти на вспомогательные индикаторы
1. В чем проблема
Вам, наверное, доводилось использовать или создавать советники или индикаторы, которые для своей работы используют несколько других вспомогательных индикаторов.
Например, всем известный индикатор MACD использует две копии индикатора EMA (Exponential Moving Average), вычисляя разницу между их значениями:
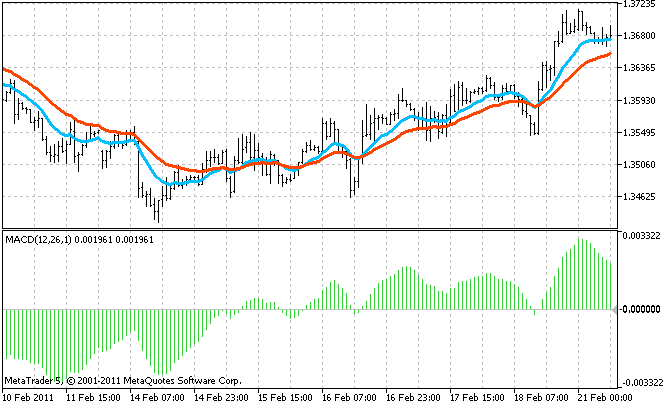
Такой составной индикатор фактически эквивалентен нескольким простым. Например, упомянутый MACD расходует памяти и процессорного времени в три раза больше, чем один EMA, поскольку терминалу приходится выделять память для буферов главного индикатора и для буферов всех его вспомогательных индикаторов.
Помимо MACD, есть и более сложные индикаторы, в которых задействуются не два, а несколько вспомогательных индикаторов.
Более того, эти расходы возрастают еще в разы, если:
- этот индикатор мультитаймфреймовый (например, отслеживает совпадение волн на нескольких ТФ), на каждый ТФ ему приходится создать отдельные копии вспомогательных индикаторов;
- этот индикатор мультивалютный;
- трейдер с помощью этого индикатора торгует на нескольких валютных парах (знаю трейдеров, у которых количество одновременно торгуемых пар переваливает за два десятка).
Сочетание этих условий способно приводить к элементарной нехватке оперативной памяти на компьютере (знаю реальные случаи, когда из-за подобных индикаторов терминал требовал гигабайты памяти). В MetaTrader нехватка памяти выглядит так:
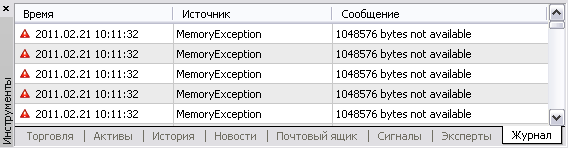
Терминал в такой ситуации просто не сможет поместить индикатор на график или некорректно его рассчитает (если в коде индикатора не предусмотрена обработка ошибки выделения памяти), а то и вовсе закроется.
В более удачном случае недостаток оперативной памяти компьютеру удается компенсировать
использованием большого объема виртуальной памяти, т.е. хранением части памяти на
жестком диске. Все программы будут работать, но очень медленно...
2. Тестовый составной индикатор
Чтобы продолжить наши исследования в рамках данной статьи более конкретно, давайте создадим какой-нибудь составной индикатор, более сложный, чем MACD.
Пусть это будет индикатор, ловящий зарождения трендов. Он будет суммировать сигналы сразу с 5 таймфреймов, например: H4, H1, M15, M5, M1. Это позволит ему ловить резонанс больших и маленьких зарождающихся трендов, что должно повысить надежность прогноза. В качестве источников сигналов на каждом таймфрейме будут выступать индикаторы Ichimoku и Price_Channel, входящие в поставку MetaTrader 5:
- по Ichimoku будем считать признаком восходящего тренда нахождение линии Tenkan (красная) выше линии Kijun (синяя), нисходящего тренда - наоборот;
- по Price_Channel восходящий тренд - если цена выше средней линии, нисходящий - если ниже.
Итого наш индикатор будет использовать 10 вспомогательных индикаторов: 5 таймфреймов по 2 индикатора. Назовем наш индикатор Trender.
Вот его полный исходный код (также он приложен к статье):
#property indicator_separate_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_minimum -1 #property indicator_maximum 1 #property indicator_type1 DRAW_HISTOGRAM #property indicator_color1 DarkTurquoise // Единственный буфер индикатора double ExtBuffer[]; // Таймфреймы вспомогательных индикаторов ENUM_TIMEFRAMES TF[5] = {PERIOD_H4, PERIOD_H1, PERIOD_M15, PERIOD_M5, PERIOD_M1}; // Хендлы вспомогательных индикаторов для всех таймфреймов int h_Ichimoku[5], h_Channel[5]; //+------------------------------------------------------------------+ void OnInit() { SetIndexBuffer(0, ExtBuffer); ArraySetAsSeries(ExtBuffer, true); // Создадим вспомогательные индикаторы for (int itf=0; itf<5; itf++) { h_Ichimoku[itf] = iCustom(Symbol(), TF[itf], "TestSlaveIndicators\\Ichimoku", 9, 26, 52 ); h_Channel [itf] = iCustom(Symbol(), TF[itf], "TestSlaveIndicators\\Price_Channel", 22 ); } } //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime& time[], const double& open[], const double& high[], const double& low[], const double& close[], const long& tick_volume[], const long& volume[], const int& spread[]) { ArraySetAsSeries(time, true); int limit = prev_calculated ? rates_total - prev_calculated : rates_total -1; for (int bar = limit; bar >= 0; bar--) { // Время текущего бара datetime Time = time [bar]; //--- Соберем сигналы со всех таймфреймов double Signal = 0; // суммарный сигнал double bufPrice[1], bufTenkan[1], bufKijun [1], bufMid[1], bufSignal[1]; for (int itf=0; itf<5; itf++) { //=== Цена бара CopyClose(Symbol(), TF[itf], Time, 1, bufPrice); double Price = bufPrice[0]; //=== Индикатор Ишимоку CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); double Tenkan = bufTenkan[0]; CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); double Kijun = bufKijun [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; //=== Индикатор канала CopyBuffer(h_Channel [itf], 2, Time, 1, bufMid); double Mid = bufMid[0]; if (Price > Mid) Signal++; if (Price < Mid) Signal--; } ExtBuffer[bar] = Signal/10; } return(rates_total); } //+------------------------------------------------------------------+
Использовать этот индикатор нужно на графике с самым младшим таймфреймом из тех, с которых он собирает сигналы, поскольку только так мы увидим проявления всех маленьких трендов. В нашем случае младший таймфреймом является M1. Так выглядит индикатор:
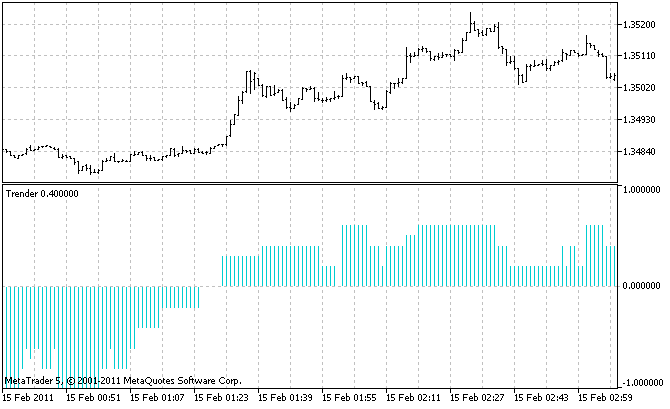
Ну и теперь перейдем к самому важному: подсчитаем, сколько же памяти потребляет такой индикатор.
Заглянем в исходный код индикатора Ichimoku (полный код см. в приложении):
#property indicator_buffers 5
и Price_Channel (полный код см. в приложении):
#property indicator_buffers 3
По этим строчкам кода видно, что эти индикаторы на двоих создают 8 буферов. Умножим это на 5 таймфреймов. И добавим 1 буфер самого индикатора Trender. Итого получится 41 буфер! Вот такие внушительные цифры могут скрываться за некоторыми простенькими на вид (на графике) индикаторами.
При стандартных настройках терминала один буфер содержит примерно 100000 значений, каждое имеет тип double и занимает 8 байт. Таким образом, 41 буфер - это примерно 31 Mb памяти. Это только сами значения, я не знаю, какая еще служебная информация содержится в буферах.
"31 Mb - это не так уж много", - скажете вы. Но когда трейдер торгует на большом количестве пар, такие объемы становятся проблемой для него. Помимо индикаторов, сами графики сильно пожирают память - ведь, в отличие от индикаторов, каждый бар имеет сразу несколько значений: OHLC, время, объем. Как всё это уместить на одном компьютере?
3. Направления решения проблемы
Вы можете, конечно, попробовать установить в ваш компьютер больше
оперативной памяти. Если же этот вариант вам не подходит по техническим, финансовым или иным причинам, или вы установили максимум памяти, а ее все равно недостаточно, то придется разбираться с прожорливыми индикаторами, чтобы как-то сократить их рацион.
Для этого давайте вспомним... школьную геометрию. Представим все буферы нашего составного индикатора в виде сплошного прямоугольника:
Площадь этого прямоугольника – это память, которую он занимает. Уменьшить площадь можно, если уменьшить ширину или высоту.
Ширина в данном случае – количество баров, на которых строятся индикаторы. Высота – количество индикаторных буферов.
4. Уменьшаем количество баров
4.1.
Простое решениеНе нужно даже быть программистом, чтобы "покрутить" настройки MetaTrader:

Уменьшив значение параметра «Макс. баров в окне», вы, как следствие, уменьшите и размер индикаторных буферов в этих окнах. Это просто, очень эффективно и доступно каждому (если у трейдера нет потребности при торговле глубоко просматривать историю).
4.2. Есть ли другое решение?
MQL5-программисты знают, что индикаторные буферы объявляются в индикаторе как динамические массивы без предварительного задания размера. Вот, например, 5 буферов в том же Ichimoku:
double ExtTenkanBuffer[]; double ExtKijunBuffer[]; double ExtSpanABuffer[]; double ExtSpanBBuffer[]; double ExtChinkouBuffer[];
Длина массивов не указывается, поскольку в любом случае размер этим массивам будет задан терминалом MetaTrader 5 на всю длину доступной истории.
Аналогично и в функции OnCalculate:
int OnCalculate (const int rates_total, // размер массива price[] const int prev_calculated, // обработано баров на предыдущем вызове const int begin, // откуда начинаются значимые данные const double& price[] // массив для расчета );
В ней индикатору передается ценовой буфер. Память под него уже выделена
терминалом, и программист не может повлиять на ее размер.
Кроме того, MQL5 позволяет использовать буфер одного индикатора в качестве ценового буфера для другого (строить "индикатор от индикатора"). Но и тут программист не может задать никаких ограничений размера, он передает лишь хендл индикатора.
Таким образом, в MQL5 не предусмотрено каких-либо механизмов для ограничения длины индикаторных буферов.
5. Уменьшаем количество буферов
Здесь у программиста существует большой выбор. Я придумал несколько несложных теоретических способов, как уменьшить количество буферов составного индикатора. Во всех способах, конечно, сокращаются буферы лишь вспомогательных индикаторов, т.к. предполагается, что в главном индикаторе все буферы нам нужны.
Рассмотрим далее эти способы подробнее и проверим, работают ли они на практике, какие имеют достоинства и недостатки.
5.1. Способ "Need"
Если во вспомогательном индикаторе много буферов, то может оказаться так, что не все они нужны главному индикатору. Поэтому неиспользуемые буферы можно просто отключить, чтобы они не занимали память. Для этого нужно внести изменения в исходный код этого вспомогательного индикатора.
Проделаем это с одним из наших вспомогательных индикаторов - Price_Channel. В нем три буфера, а Trender считывает только один, так что есть чего убрать ненужного.
Полный код индикаторов Price_Channel (исходный индикатор), Price_Channel-Need (уже полностью переделанный) приложен к статье, а далее я опишу только изменения, которые были в него внесены.
Первым делом уменьшаем счетчик буферов с 3 до 1:
//#property indicator_buffers 3 #property indicator_buffers 1 //#property indicator_plots 2 #property indicator_plots 1
И убираем два лишних буферных массива:
//--- indicator buffers //double ExtHighBuffer[]; //double ExtLowBuffer[]; double ExtMiddBuffer[];
Теперь, если попытаться скомпилировать этот индикатор, компилятор покажет все строки, где есть обращения к этим массивам:
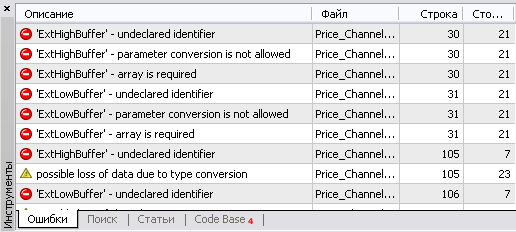
Такой прием позволяет быстро найти места, требующие изменений. Это будет весьма полезно, если код индикатора очень большой.
В нашем случае строчек с "undeclared identifier" всего 4. Давайте их править.
Как и следовало ожидать, две из них находятся в OnInit. Но вместе с ними пришлось убрать и строчку с нужным нам ExtMiddBuffer - добавив вместо нее аналогичную, но с другим номером буфера. Ведь буфера с номером 2 у индикатора теперь быть не может, а может быть только 0:
// SetIndexBuffer(0,ExtHighBuffer,INDICATOR_DATA); // SetIndexBuffer(1,ExtLowBuffer,INDICATOR_DATA); // SetIndexBuffer(2,ExtMiddBuffer,INDICATOR_DATA); SetIndexBuffer(0,ExtMiddBuffer,INDICATOR_DATA);
Если планируете "урезанный" индикатор использовать потом в визуальном режиме, то учитывайте, что при смене номера буфера нужно менять и настройки оформления. В нашем случае это:
//#property indicator_type1 DRAW_FILLING #property indicator_type1 DRAW_LINE
Если же визуализация вам не нужна, то можно и не тратить время на смену оформления - к ошибкам это не приводит.
Продолжим отрабатывать список "undeclared identifier". Последние 2 изменения (что, опять же, предсказуемо) приходятся на OnCalculate, где идет заполнение этих буферных массивов. Так как нужный нам ExtMiddBuffer обращается к удаленным ExtHighBuffer и ExtLowBuffer, вместо них пришлось подставить промежуточные переменные:
//--- the main loop of calculations for(i=limit;i<rates_total;i++) { // ExtHighBuffer[i]=Highest(High,InpChannelPeriod,i); double high=Highest(High,InpChannelPeriod,i); // ExtLowBuffer[i]=Lowest(Low,InpChannelPeriod,i); double low=Lowest(Low,InpChannelPeriod,i); // ExtMiddBuffer[i]=(ExtHighBuffer[i]+ExtLowBuffer[i])/2.0;; ExtMiddBuffer[i]=( high + low )/2.0;; }
Как видите, ничего сложного во всей этой "хирургической операции" не оказалось. Нужные места нашлись быстро, всего несколько "движений скальпелем" и - минус два буфера. В масштабах всего составного индикатора Trender экономия составит 10 буферов (2*5 ТФ).
Можно открыть друг под другом Price_Channel и Price_Channel-Need и увидеть исчезнувшие лишние буферы:
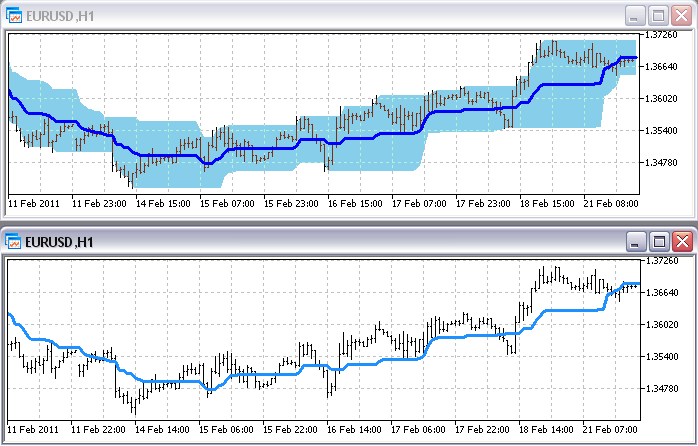
Чтобы использовать Price_Channel-Need в индикаторе Trender, надо исправить в коде Trender имя вспомогательного индикатора с "Price_Channel" на "Price_Channel-Need", а также номер нужного нам буфера в нем - вместо 2 теперь 0. Готовый Trender-Need прикреплен к статье.
5.2. Способ "Aggregate"
Если главный индикатор считывает из вспомогательного более одного буфера и проводит потом с ними какое-то агрегирующее действие (например, сложение или сравнение), то вовсе не обязательно проделывать это действие именно в главном индикаторе. Можно выполнить его прямо во вспомогательном, а в главный индикатор отдать лишь результат. Тогда отпадет необходимость в наличии нескольких буферов - их заменит один.
В нашем случае такой способ можно применить к Ichimoku. Ведь Trender использует из него 2 буфера (0 - Tenkan и 1 - Kijun):
CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); double Tenkan = bufTenkan[0]; CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); double Kijun = bufKijun [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--;
Если в Ichimoku агрегировать 0-й и 1-й буфер в один сигнальный, то представленный выше фрагмент кода в Trender заменится на такой:
CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufSignal); Signal += bufSignal[0];
Полностью этот Trender-Aggregate приложен к статье.
А теперь рассмотрим ключевые изменения, которые нужно внести в Ichimoku.
В этом индикаторе есть еще и неиспользуемые буферы. Так что кроме способа "Aggregate" заодно применим и описанный ранее способ "Need". Таким образом, из 5 буферов в Ichimoku останется лишь один - агрегирующий нужные нам буферы:
//#property indicator_buffers 5
#property indicator_buffers 1
//#property indicator_plots 4
#property indicator_plots 1
Дадим этому единственному буферу новое имя:
//--- indicator buffers //double ExtTenkanBuffer[]; //double ExtKijunBuffer[]; //double ExtSpanABuffer[]; //double ExtSpanBBuffer[]; //double ExtChinkouBuffer[]; double ExtSignalBuffer[];
В новом имени есть и практический смысл: оно позволяет удалить из кода индикатора имена всех ранее использовавшихся буферов. Это позволит (с использованием приема компиляции из описания способа "Need") быстро найти все строчки, которые нужно изменить.
Если вы собираетесь визуализировать индикатор на графике, то не забудьте внести изменения в настройки оформления. А также учтите, что агрегирующий буфер в нашем случае имеет другой диапазон значений, нежели поглощенные им два буфера. Он показывает теперь не ценовую производную, а какой из двух буферов больше. Отражать такие результаты удобней в отдельном окошке внизу графика:
//#property indicator_chart_window #property indicator_separate_window
Итак, вносим изменения в OnInit:
//--- indicator buffers mapping // SetIndexBuffer(0,ExtTenkanBuffer,INDICATOR_DATA); // SetIndexBuffer(1,ExtKijunBuffer,INDICATOR_DATA); // SetIndexBuffer(2,ExtSpanABuffer,INDICATOR_DATA); // SetIndexBuffer(3,ExtSpanBBuffer,INDICATOR_DATA); // SetIndexBuffer(4,ExtChinkouBuffer,INDICATOR_DATA); SetIndexBuffer(0,ExtSignalBuffer,INDICATOR_DATA);
И самое интересное - в OnCalculate. Обратите внимание: три ненужных буфера просто удаляем (мы ведь применяем и способ "Need"), а нужные нам ExtTenkanBuffer и ExtKijunBuffer заменяем временными переменными Tenkan и Kijun. Эти переменные и используются в конце цикла для расчета нашего агрегирующего буфера ExtSignalBuffer:
for(int i=limit;i<rates_total;i++) { // ExtChinkouBuffer[i]=Close[i]; //--- tenkan sen double high=Highest(High,InpTenkan,i); double low=Lowest(Low,InpTenkan,i); // ExtTenkanBuffer[i]=(high+low)/2.0; double Tenkan =(high+low)/2.0; //--- kijun sen high=Highest(High,InpKijun,i); low=Lowest(Low,InpKijun,i); // ExtKijunBuffer[i]=(high+low)/2.0; double Kijun =(high+low)/2.0; //--- senkou span a // ExtSpanABuffer[i]=(ExtTenkanBuffer[i]+ExtKijunBuffer[i])/2.0; //--- senkou span b high=Highest(High,InpSenkou,i); low=Lowest(Low,InpSenkou,i); // ExtSpanBBuffer[i]=(high+low)/2.0; //--- SIGNAL double Signal = 0; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; ExtSignalBuffer[i] = Signal; }
Итого - минус 4 буфера. А если бы мы применили к Ichimoku только способ "Need", то было бы лишь минус 3.
В рамках всего Trender наша экономия составила 20 буферов (4*5 ТФ).
Полный код Ichimoku-Aggregate приложен к статье. Чтобы посмотреть, как выглядит этот индикатор в сравнении с оригиналом, откроем их оба на одном графике. Измененный индикатор, как вы помните, выводится теперь в нижней части графика в отдельном окне:
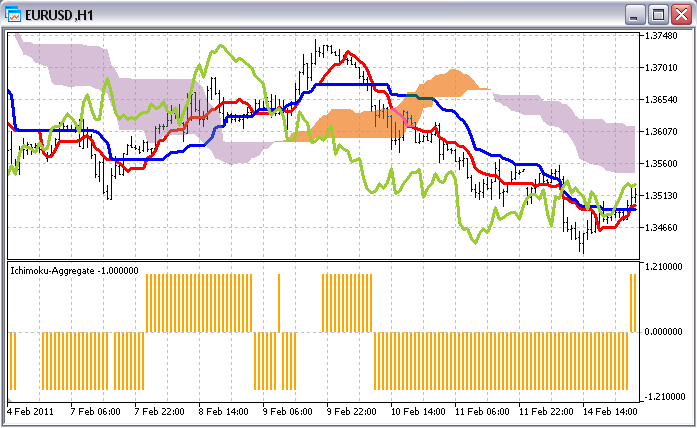
5.3.
Способ "Include"
Самый кардинальный способ уменьшить количество буферов - это вообще избавиться от вспомогательных индикаторов. Тогда в нашем составном индикаторе останется всего 1 буфер, принадлежащий главному индикатору. Меньше уже некуда.
Достичь такого результата можно, если перенести код вспомогательных индикаторов в главный индикатор. Иногда это может оказаться трудоемким занятием, но ожидаемый эффект того стоит. Главная сложность здесь - это адаптация перенесенного из индикаторов кода. Ведь он совсем не рассчитан на то, чтобы работать в коде другого индикатора.
Основные проблемы, которые при этом возникнут:
- Конфликт имен. Совпадающие имена переменных, функций, особенно системных (OnCalculate, например);
- Отсутствие буферов. В некоторых индикаторах это может стать непреодолимым препятствием для адаптации, если логика индикаторов тесно завязана именно на буферное хранение/обработку данных. Замена буферов на простые массивы в нашем случае не выход, т.к. наша цель - снижение расхода памяти. Нам важен именно полный отказ от хранения в памяти какой-либо гигантской истории.
Продемонстрирую далее приемы, позволяющие эффективно решить эти проблемы.
Нужно каждый вспомогательный индикатор оформить в виде класса. Тогда все переменные и функции индикаторов будут иметь (внутри своих классов) уникальные имена и не будут конфликтовать с другими индикаторами.
Если индикаторов переносится много, то имеет смысл также озаботиться стандартизацией этих классов, чтобы потом не путаться в работе с ними. Для этих целей нужно создать какой-нибудь базовый индикаторный класс, а классы всех вспомогательных индикаторов унаследовать от него.
Я написал вот такой класс:
class CIndicator { protected: string symbol; // валютная пара ENUM_TIMEFRAMES timeframe; // таймфрейм double Open[], High[], Low[], Close[]; // симуляция ценовых буферов int BufLen; // необходимая глубина заполнения ценовых буферов public: //--- Аналоги стандартных индикаторных функций void Create(string sym, ENUM_TIMEFRAMES tf) {symbol = sym; timeframe = tf;}; void Init(); void Calculate(datetime start_time); // start_time - адрес бара, который посчитать };
Теперь на его основе начнем создавать класс для индикатора Ichimoku. Первым делом пропишем в нем в виде свойств входные параметры индикатора с точно такими же именами, как в оригинале. Чтобы в коде индикатора не потребовалось потом что-либо менять:
class CIchimoku: public CIndicator { private: // Симуляция входных параметров индикатора int InpTenkan; int InpKijun; int InpSenkou;
Сохраним и названия всех буферов. Да, вы не ослышались, мы объявим все 5 буферов этого индикатора. Но они будут не настоящие. Они будут состоять всего из одного бара каждый:
public: // Симуляция индикаторных буферов double ExtTenkanBuffer [1]; double ExtKijunBuffer [1]; double ExtSpanABuffer [1]; double ExtSpanBBuffer [1]; double ExtChinkouBuffer[1];
Для чего это было сделано? Для того, чтобы меньше изменений потом вносить в код. Сейчас увидите. Переопределим унаследованный метод CIchimoku.Calculate, заполнив его перенесенным из Ichimoku кодом функции OnCalculate.
Обратите внимание, что при переносе из этой функции был удален цикл по барам истории, и там теперь рассчитывается всего один бар с заданным временем. А основной расчетный код при этом остался неизменным. Вот для чего мы так дотошно сохраняли все имена буферов и параметров индикатора.
Обратите также внимание, что в самом начале метода Calculate заполняются значениями ценовые буферы. Там ровно столько значений, сколько понадобится при расчете одного бара.
void Calculate(datetime start_time) { CopyHigh (symbol,timeframe,start_time,BufLen,High); CopyLow (symbol,timeframe,start_time,BufLen,Low ); CopyClose(symbol,timeframe,start_time,1 ,Close); // int limit; //--- // if(prev_calculated==0) limit=0; // else limit=prev_calculated-1; //--- // for(int i=limit;i<rates_total;i++) int i=0; { ExtChinkouBuffer[i]=Close[i]; //--- tenkan sen double high=Highest(High,InpTenkan,i); double low=Lowest(Low,InpTenkan,i); ExtTenkanBuffer[i]=(high+low)/2.0; //--- kijun sen high=Highest(High,InpKijun,i); low=Lowest(Low,InpKijun,i); ExtKijunBuffer[i]=(high+low)/2.0; //--- senkou span a ExtSpanABuffer[i]=(ExtTenkanBuffer[i]+ExtKijunBuffer[i])/2.0; //--- senkou span b high=Highest(High,InpSenkou,i); low=Lowest(Low,InpSenkou,i); ExtSpanBBuffer[i]=(high+low)/2.0; } //--- done // return(rates_total); };
Конечно, можно было не заботиться о сохранности оригинального кода. Но тогда чтобы перенести его, пришлось бы его сильно переделывать, а для этого нужно было бы разбираться в его логике работы. В нашем случае индикатор довольно простой, и разобраться было бы легко. Но представьте, что было бы, попадись нам индикатор сложнее? Я показал вам прием, который вам помог бы в таком случае.
Теперь заполним метод CIchimoku.Init, в нем всё просто:
void Init(int Tenkan = 9, int Kijun = 26, int Senkou = 52) { InpTenkan = Tenkan; InpKijun = Kijun; InpSenkou = Senkou; BufLen = MathMax(MathMax(InpTenkan, InpKijun), InpSenkou); };
В индикаторе Ichimoku есть еще две функции, которые тоже нужно перенести в класс CIchimoku: Highest и Lowest. Они ищут максимальное и минимальное значение на заданном фрагменте ценовых буферов.
Ценовые буферы у нас теперь не настоящие, у них очень короткий размер (вы видели их заполнение в методе Calculate выше), поэтому нужно немного изменить логику работы функций Highest и Lowest.
Здесь я тоже придерживался принципа минимальной правки, все изменения состоят в добавлении одной строки, которая, по сути, меняет нумерацию баров в буфере из глобальной (когда буфер длиной во всю доступную историю) в локальную (ведь у нас в ценовых буферах теперь лишь столько значений, сколько необходимо для расчета одного индикаторного бара):
double Highest(const double&array[],int range,int fromIndex) { fromIndex=MathMax(ArraySize(array)-1, 0); double res=0; //--- res=array[fromIndex]; for(int i=fromIndex;i>fromIndex-range && i>=0;i--) { if(res<array[i]) res=array[i]; } //--- return(res); }
Метод Lowest модифицируется аналогичным образом.
С индикатором Price_Channel тоже проделываются похожие изменения, только он уже будет представлен в виде класса с именем CChannel. Полностью оба класса вы можете увидеть в Trender-Include, приложенном к статье.
Я описал основные моменты переноса кода. Думаю, в большинстве индикаторов этих приемов окажется достаточно.
Индикаторы с нестандартными настройками могут представлять дополнительную сложность. Например, в том же Price_Channel есть неприметные строчки:
PlotIndexSetInteger(0,PLOT_SHIFT,1); PlotIndexSetInteger(1,PLOT_SHIFT,1);
Они означают, что график индикатора сдвинут на 1 бар. В нашем случае это приводит к тому, что, например, функции CopyBuffer и CopyHigh обращаются к двум разным барам, несмотря на то, что координаты бара (его время) заданы в их параметрах одинаковые.
В Trender-Include эта проблема решена (в классе CChannel добавлены "единички" где нужно, в отличие от класса CIchimoku, где такой проблемы не было), так что если вам тоже попадется подобный коварный индикатор, вы знаете, где искать подсказку.
Итак, с переноской мы закончили, и оба вспомогательных индикатора находятся теперь в виде двух классов внутри индикатора Trender-Include. Осталось нам изменить только обращения к этим индикаторам. В Trender у нас были массивы хендлов, а в Trender-Include их заменят массивы объектов:
// Хендлы вспомогательных индикаторов для всех таймфреймов //int h_Ichimoku[5], h_Channel[5]; // Объекты встроенных вспомогательных индикаторов CIchimoku o_Ichimoku[5]; CChannel o_Channel[5];
Создание всех вспомогательных индикаторов в OnInit теперь станет выглядеть так:
for (int itf=0; itf<5; itf++) { o_Ichimoku[itf].Create(Symbol(), TF[itf]); o_Ichimoku[itf].Init(9, 26, 52); o_Channel [itf].Create(Symbol(), TF[itf]); o_Channel [itf].Init(22); }
А в OnCalculate на смену CopyBuffer придет прямое обращение к свойствам объектов:
//=== Индикатор Ишимоку o_Ichimoku[itf].Calculate(Time); //CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); //double Tenkan = bufTenkan[0]; double Tenkan = o_Ichimoku[itf].ExtTenkanBuffer[0]; //CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); //double Kijun = bufKijun [0]; double Kijun = o_Ichimoku[itf].ExtKijunBuffer [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; //=== Индикатор канала o_Channel[itf].Calculate(Time); //CopyBuffer(h_Channel [itf], 2, Time, 1, bufMid); //double Mid = bufMid[0]; double Mid = o_Channel[itf].ExtMiddBuffer[0]; if (Price > Mid) Signal++; if (Price < Mid) Signal--;
Минус 40 буферов. Не зря мы потрудились.
После каждой переделки индикатора Trender описанными ранее способами "Need" и "Aggregate", я тестировал получившийся индикатор в визуальном режиме.
Проведем такой тест и сейчас: откроем на одном графике исходный индикатор (Trender) и переделанный (Trender-Include). Можно сделать вывод, что переделано всё было правильно, т.к. линии обоих индикаторов точно совпадают друг с другом:
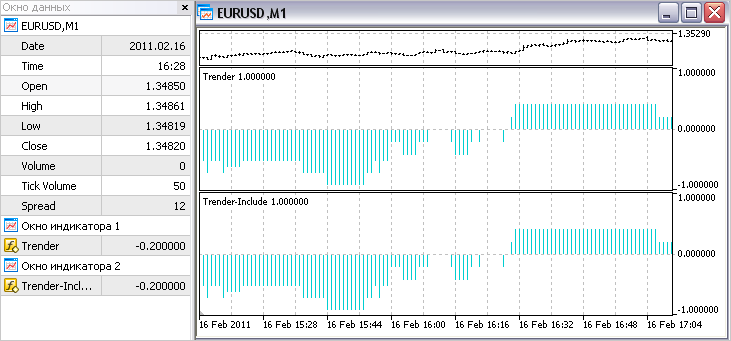
5.4. Можно ли по одному?
Мы рассмотрели уже 3 способа уменьшить количество буферов вспомогательных индикаторов. Но что если попробовать кардинально изменить подход - и уменьшать не общее количество буферов, а количество буферов, одновременно находящихся в памяти? То есть, не сразу все индикаторы загружать в память, а по одному. Организовать эдакую "карусель": создали один вспомогательный индикатор, прочитали с него данные, удалили, создали следующий и т.д., и так перебирать таймфрейм за таймфреймом. Больше всего буферов у индикатора Ichimoku - 5 штук. Значит, теоретически, в каждый момент времени в памяти могло бы находиться не более 5 буферов (плюс 1 буфер главного индикатора), и общая экономия составила бы 35 буферов!
Возможно ли это? В MQL5 ведь даже и функция есть для удаления индикаторов - IndicatorRelease.
Но, не все тут так просто, как кажется. MetaTrader 5 заботится о высокой скорости работы MQL5-программ, поэтому любые таймсерии, к которым было обращение, кэшируются в памяти - вдруг они понадобятся какому-то еще индикатору, эксперту или скрипту. И только если длительное время никто не будет повторно запрашивать эти данные, тогда они выгрузятся, освободив память. Это время ожидания составляет до 30 минут.
Так что, постоянное создание-удаление индикаторов не позволит достичь большой мгновенной экономии памяти. Зато, что очень важно, способно серьезно замедлить работу компьютера - ведь при каждом создании индикатора он рассчитывается на всей истории. Подумайте, насколько будет целесообразным проделывать такое на каждом историческом баре главного индикатора...
Тем не менее, идея с "индикаторной каруселью", несомненно, была интересной - в контексте "мозгового штурма". Если вы придумаете какие-то еще необычные идеи оптимизации памяти индикаторов, пишите в комментариях к статье - возможно, они найдут свое теоретическое или практическое рассмотрение в одной из следующих статей на эту тему.
6. Измеряем реальный расход памяти
Итак, в предыдущих главах мы реализовали 3 работающих способа уменьшения количества буферов вспомогательных индикаторов. Давайте теперь посмотрим, насколько это позволяет уменьшить реальный расход памяти.
Измерять объем занятой терминалом памяти будем с помощью "Диспетчера задач" Windows. На вкладке "Процессы" там видно, сколько терминал занимает оперативной и виртуальной памяти. Например:
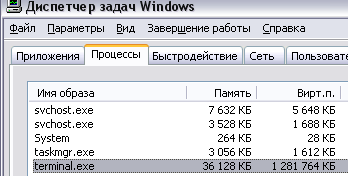
Измерения производятся по следующему алгоритму, позволяющему увидеть минимальный
расход памяти терминалом (это и будет близко к непосредственному расходу
памяти индикаторами):
- Скачиваем глубокую историю с сервера MetaQuotes-Demo (достаточно запустить тестирование по символу, чтобы история по нему автоматически скачалась);
- Терминал настраиваем на очередное измерение (открываем нужные графики и индикаторы) и перезапускаем - чтобы в памяти не оставалось ничего лишнего, кроме того, что нам нужно;
- Дожидаемся, пока перезапущенный терминал завершит расчеты всех индикаторов. Это станет видно по нулевой загрузке процессора;
- Сворачиваем терминал на панель задач (стандартная кнопка Windows "Свернуть" в правом верхнем углу терминала) - так он освобождает не используемую в данный момент для расчетов оперативную память (на скриншоте выше как раз пример расхода оперативной памяти в спокойном свернутом состоянии - видно, что ее может быть занято гораздо меньше по сравнению с виртуальной);
- В "Диспетчере задач" считываем сумму колонок "Память" (оперативная) и "Вирт.п." (виртуальная память). Так они называются в Windows XP, в других версиях ОС могут называться по-другому.
Параметры измерений:
- Для большей точности измерений, будем использовать не один ценовой график, а сразу все доступные пары на демо-счете MetaQuotes - т.е. 22 графика M1. Потом вычислять средние значения;
- Настройка "Макс. баров в окне" (описанная в главе 4.1) стандартная - 100000;
- ОС - Windows XP, 32 bit.
Чего ожидать от результатов измерений? Сделаю тут два замечания:
- Хотя индикатор Trender и задействует 41 буфер, это не означает, что он занимает 41*100000 баров. Ведь эти буферы раскинуты по пяти таймфреймам, и на старших из них баров меньше, чем на младших. Например, в истории EURUSD на минутках всего более 4 млн. баров, а на часовках, соответственно, лишь около 70000 (4000000/60). Поэтому не стоит ожидать, что уменьшение числа буферов в Trender приведет к такому же снижению расхода памяти;
- Память занимает не только индикатор, но и используемые им ценовые серии. Trender обращается к пяти таймфреймам. Это значит, что если мы уменьшим число буферов в несколько раз, то общий расход памяти не уменьшится во столько же раз. Потому что ценовых серий в памяти все равно будет использоваться 5.
При измерении расхода могут обнаружиться и другие факторы, которые нам неизвестны, но которые влияют на потребление памяти. Именно для этого мы и проводим практические измерения, чтобы увидеть,
какова будет реальная экономия от оптимизации индикатора.
Далее представлена таблица с результатами всех измерений. Сначала было измерено, сколько памяти потребляет пустой терминал. В следующем измерении, вычитая это число, стало возможным определить, сколько потребляет один график. В последующих измерениях, вычитая расход терминала и графика, выяснилось, сколько памяти приходится на каждый индикатор.
| Чей расход памяти измеряем |
Индикаторных
буферов |
Таймфреймы |
Расход памяти |
|---|---|---|---|
| Терминал |
0 |
0 |
38 Mb на терминал |
| График |
0 |
1 |
12 Mb на один пустой график |
| Индикатор Trender |
41 |
5 |
46 Mb на один индикатор |
| Индикатор Trender-Need |
31 |
5 |
42 Mb на один индикатор |
| Индикатор Trender-Aggregate | 21 |
5 |
37 Mb на один индикатор |
| Индикатор Trender-Include | 1 |
5 |
38 Mb на один индикатор |
Выводы по результатам измерений:
- Уменьшение числа индикаторных буферов снижает расход памяти индикатором не во столько же раз.
Причины этого описаны в данной главе выше. Вероятно, если бы индикатор использовал меньшее количество таймфреймов, выигрыш от уменьшения количества буферов оказался бы более значительным.
- Перенос кода всех вспомогательных индикаторов в главный индикатор не всегда является самым эффективным решением.
Почему же способ Include не оказался эффективней способа Aggregate? Чтобы определить причину, нужно вспомнить основные различия кода этих индикаторов. В Aggregate необходимые для расчетов ценовые серии подаются терминалом как входные массивы в OnCalculate, А в Include все эти данные (для всех таймфреймов) активно запрашиваются для каждого бара через CopyHigh, CopyLow, CopyClose. Видимо, это и приводит к появлению дополнительных расходов памяти, связанных с особенностями кэширования ценовых серий при использовании этих функций.
Заключение
Итак, из статьи вы узнали 3 работающих способа снижения расхода памяти на вспомогательные индикаторы, и 1 способ сэкономить память путем настройки терминала.
Какой из способов вы примените в ваших программах будет зависеть от того, какие из них окажутся доступными и оправданными в вашей ситуации. Количество сэкономленных буферов и мегабайтов тоже будет зависеть от индикаторов, которые вам попадутся: в каких-то можно будет "отрезать" побольше, а в каких-то не окажется ничего лишнего.
Сэкономленная память позволит вам увеличить число одновременно используемых в терминале валютных пар, индикаторов и стратегий, что повысит надежность вашего торгового портфеля. Так простая забота о технических ресурсах вашего компьютера может превращаться в материальные ресурсы на вашем депозите.
Приложения
К статье приложены индикаторы, описываемые в статье. Чтобы все работало, нужно сохранить их в папку "MQL5\Indicators\TestSlaveIndicators", т.к. все версии индикатора Trender (кроме Trender-Include, конечно же) ищут свои вспомогательные индикаторы в ней.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Индикаторы малой, промежуточной и основной тенденции
Индикаторы малой, промежуточной и основной тенденции
 Трассировка, отладка и структурный анализ кода
Трассировка, отладка и структурный анализ кода
 Статистические распределения вероятностей в MQL5
Статистические распределения вероятностей в MQL5
 Статистические оценки
Статистические оценки
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Подход понятен. Но вот смущает актуальность задачи.
Ну, собственно, идея написать эту статью мне пришла в голову именно после того, как один чел, которому я написал некий составной индикатор, пожаловался, что у него на некоторые пары этот индикатор не ставится. При расследовании выяснилось, что бывают очень памятежручие индикаторы, и много их в терминал не лезет (то есть проблема была не в паре, а в том, что перед этой парой открывалось еще с десяток с таким же жручим индикатором). Тот индикатор жрал раза в 2 больше, чем тестовый в статье.
Да даже 32-бит с его 3Гб вполне тянет такие размеры памяти
Если торговать на большом количестве пар, то не тянет, в том-то и дело.
Терминал, кстати, не может выделить памяти больше 2 Гб (в сумме: оперативная + виртуальная). В моих экспериментах он закрывался на этой отметке.
В 64 бит такой проблемы, конечно, существовать не должно.
Ладно, предположим что задача актуальна (согласен что есть люди которым это важно). Но задумайтесь, задача экономии памяти напрямую идёт в разрез с задачей быстродействия.
Не всегда. В статье, вот, как раз большинство методов не снижают быстродействия.
Советник, запрашивающий от индикаторов лишь последний бар, - это уже другой класс программы, нежели рассмотренный в статье. И не всегда возможно/удобно заменить одно на другое.
Вряд ли у каждого индикатора на общей паре свой экземпляр данных - в статье про параллельные вычисления есть интересная табличка, которая находится по ключевой фразе "2 индикатора".
Проблема индикаторов в том что каждый работает в своём потоке и для работы должен в самом потоке хранить все необходимые данные.
Данные между потоками копируются через CopyBuffer(). Но вот незадача, получить данные из потока можно, а вот передать их туда нет. Поэтому строить могоступеньчатые индикаторы в которых несколько экземпляров одного индикатора получают одни и те же предобработанные данные не получится. А ведь именно в этой плоскости могут лежать большие возможности по оптимизации вычислений.
Думаю если MQ решат эту задачу, работа с индикаторами станет более удобной и гибкой. Сейчас же данные можно только передать в качестве внешних параметров и только при запуске потока.
Очень полезно
если я правильно понял основную мысль, то возникает вопрос:
почему все стандартные индикаторы, которые есть в инсталляции MT5, не разработаны как "класс"?
Тогда почему мастеру не важна такая идея?
без ограничения максимального количества баров в меню Инструменты> Параметры, быстрый способ, который я использую для уменьшения буферного пространства - это