
通过辅助指标减少内存消耗
1. 问题
或许,您已经运用或创建了使用其他辅助指标来操作的 EA 交易或指标。
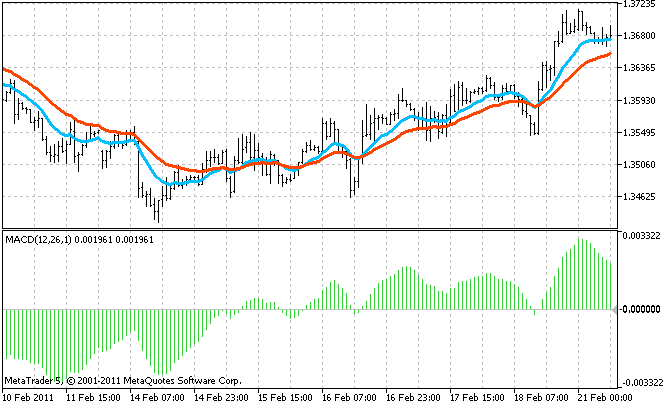
例如,著名的 MACD 指标使用 EMA(指数移动平均线)指标的两个副本来计算它们的值之间的差异:
事实上,此类复合指标等于几个简单的指标。例如,前述 MACD 消耗的内存和处理器时间是单一 EMA 的三倍多,因为它必须为主指标的缓存和其所有辅助指标的缓存分配内存。
除了 MACD 以外,还有很多使用两个以上辅助指标的复杂指标。
此外,如果满足以下条件,则这些内存开销将大为增加:
- 指标使用多个时间框架(例如,它跟踪几个时间框架的波动的并行性),因此为每个时间框架创建辅助指标的单独副本;
- 指标是多货币;
- 交易者使用指标在多个货币对上交易(我认识同时交易二十多个货币对的人)。
这些条件的组合可导致计算机的内存不足(我知道真实的案例,当时由于使用此类指标,一台客户端需要数吉字节的内存)。以下是在 MetaTrader 5 客户端中内存不足的一个例子:
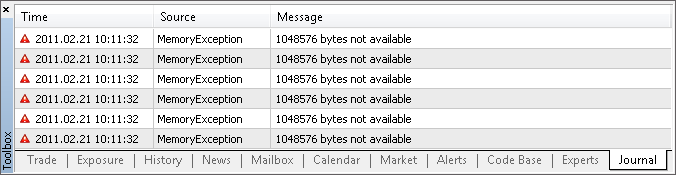
在此类情形中,客户端不能将指标放在图表中,或者不能正确地计算指标(如果指标的代码未处理内存分配错误的话),甚至还会关闭。
很幸运,客户端可以使用更多虚拟内存,即在硬盘上存储部分信息来弥补内存不足。所有程序都会运行,但非常缓慢……
2. 测试复合指标
为了在本文的范畴内继续我们的调查,让我们创建一个复合指标,一个比 MACD 更复杂的指标。
让它成为一个跟踪趋势开始的指标。它将汇总来自 5 个时间框架的信号,例如:H4、H1、M15、M5、M1。它将允许确定大小上升趋势的共振,这样应能提高预测的可靠性。作为每个时间框架上的信号来源,我们将使用 Ichimoku 和 Price_Channel 指标,这两个指标包含在 MetaTrader 5 交付中:
- 如果 Ichimoku 的 Tenkan(红)线高于 Kijun(蓝)线,则趋势为上升;如果低于蓝线,则趋势为下降;
- 如果价格高于 Price_Channel 的中线,则趋势为上升;如果低于中线,则趋势为下降。
我们的指标总共将使用 10 个辅助指标:5 个时间框架,每个框架 2 个指标。让我们将这个指标称为 Trender。
以下是其完整源代码(也包含在本文的附件中):
#property indicator_separate_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_minimum -1 #property indicator_maximum 1 #property indicator_type1 DRAW_HISTOGRAM #property indicator_color1 DarkTurquoise // The only buffer of the indicator double ExtBuffer[]; // Timeframes of auxiliary indicators ENUM_TIMEFRAMES TF[5] = {PERIOD_H4, PERIOD_H1, PERIOD_M15, PERIOD_M5, PERIOD_M1}; // Handles of auxiliary indicators for all timeframes int h_Ichimoku[5], h_Channel[5]; //+------------------------------------------------------------------+ void OnInit() { SetIndexBuffer(0, ExtBuffer); ArraySetAsSeries(ExtBuffer, true); // Create auxiliary indicators for (int itf=0; itf<5; itf++) { h_Ichimoku[itf] = iCustom(Symbol(), TF[itf], "TestSlaveIndicators\\Ichimoku", 9, 26, 52 ); h_Channel [itf] = iCustom(Symbol(), TF[itf], "TestSlaveIndicators\\Price_Channel", 22 ); } } //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime& time[], const double& open[], const double& high[], const double& low[], const double& close[], const long& tick_volume[], const long& volume[], const int& spread[]) { ArraySetAsSeries(time, true); int limit = prev_calculated ? rates_total - prev_calculated : rates_total -1; for (int bar = limit; bar >= 0; bar--) { // Time of the current bar datetime Time = time [bar]; //--- Gather signals from all timeframes double Signal = 0; // total signal double bufPrice[1], bufTenkan[1], bufKijun [1], bufMid[1], bufSignal[1]; for (int itf=0; itf<5; itf++) { //=== Bar price CopyClose(Symbol(), TF[itf], Time, 1, bufPrice); double Price = bufPrice[0]; //=== The Ichimoku indicator CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); double Tenkan = bufTenkan[0]; CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); double Kijun = bufKijun [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; //=== The channel indicator CopyBuffer(h_Channel [itf], 2, Time, 1, bufMid); double Mid = bufMid[0]; if (Price > Mid) Signal++; if (Price < Mid) Signal--; } ExtBuffer[bar] = Signal/10; } return(rates_total); } //+------------------------------------------------------------------+
您应在一个图表上使用此指标,该图表具有指标从中收集信号的最小时间框架;只有这样才能查看所有小趋势。在我们的案例中是 M1 时间框架。指标看起来如下所示:
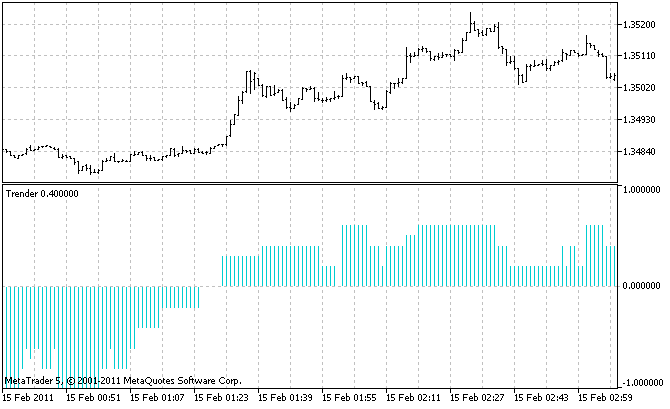
现在,我们来讨论最重要的部分:让我们计算此指标消耗的内存量。
看一看 Ichimoku 指标的源代码(本文附带了完整代码):
#property indicator_buffers 5
以及 Price_Channel 指标的源代码(本文附带了完整代码):
#property indicator_buffers 3
在这些代码行中,您可以看到创建了 8 个缓存。将其乘以 5 个时间框架。添加 Trender 指标本身的一个缓存。我们总共有 41 个缓存!在这些看起来简单(在图表上)的指标背后是如此令人惊讶的值。
在客户端的默认属性下,一个缓存大约包含 100000 个双精度类型的值,每个值消耗 8 字节内存。因此 41 个缓存大约消耗 31 Mb 内存。并且这些仅是值本身;我不知道除了值本身以外,还在缓存中存储了哪些服务信息。
您也许会说:“31 Mb 不是太多”。但是,当交易者使用很多货币对时,这个数量将成为一个问题。除了指标以外,图表本身也消耗很多内存。与指标不同,每根柱一次包含几个值:开盘价、最高价、最低价、收盘价(OHLC)、时间和成交量。我们如何将其存放到一台计算机中?
3. 解决问题的方法
当然,您可以在您的计算机上安装更多内存。但是,如果由于技术、财务或任何其他原因,这种情形不适合您,或者您已经耗尽可以安装的内存量但内存还是不够,则您应该检查这些消耗大量内存的指标并减小它们的消耗量。
为此……回想一下您在学校学的几何学。假定我们的复合指标的所有缓存是一个实心矩形:
这个矩形的面积是消耗的内存。您可以通过减小宽度或高度来减小面积。
在这个案例中,宽度是绘制指标所依据的柱的数量。高度是指标缓存的数量。
4. 减小柱的数量
4.1. 简单的解决方法要调整 MetaTrader 的设置,您不必是一名程序员:
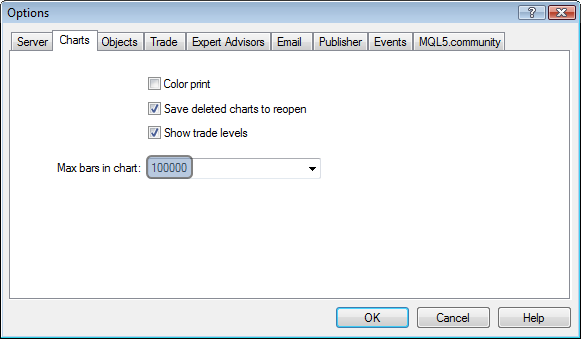
减小 "Max bars in chart"(图表中的最大柱数)的值即可减小这些窗口中指标缓存的大小。它简单、高效,每一个人都可操作(如果交易者在交易时不需要很长的价格历史)。
4.2. 还有其他解决方法吗?
MQL5 程序员知道指标缓存在指标中作为没有预设大小的动态数组声明。例如 Ichimoku 的 5 个缓存:
double ExtTenkanBuffer[]; double ExtKijunBuffer[]; double ExtSpanABuffer[]; double ExtSpanBBuffer[]; double ExtChinkouBuffer[];
未指定数组大小,因为它是由 MetaTrader 5 客户端本身为整个可用历史设置的。
在 OnCalculate 函数中也是如此:
int OnCalculate (const int rates_total, // size of the array price[] const int prev_calculated, // number of bars processed at the previous call const int begin, // the start of reliable data const double& price[] // array for the calculation );
在这个函数中,价格缓存被传递给指标。客户端已经为其分配了内存,程序员不能影响其大小。
此外,MQL5 允许将一个指标的缓存用作另一个指标的价格缓存(“依据另一个指标绘制一个指标”)。但即使在这里,程序员也不能设置大小限制;他们只是传递指标句柄。
因此,在 MQL5 中不能限制指标缓存的大小。
5. 减小缓存的数量
在这里,程序员有大量的选择。我已经发现减小复合指标的缓存数量的几种简单理论方式。然而,所有这些都意味着要减少辅助指标的缓存数量,因为在主指标中,所有缓存都是必需的。
让我们详细地看一看这些方式并检查它们是否起作用以及它们有什么优点和缺点。
5.1. “需要”方法
如果一个辅助指标包含多个缓存,则有可能并不是所有这些缓存都是主指标所需要的。因此,我们可以禁用未使用的指标以释放它们消耗的内存。为此,我们需要在辅助指标的源代码中进行一些更改。
让我们对我们的辅助指标之一 Price_Channel 进行更改。它包含三个缓存,Trender 仅读取其中的一个;因此我们要移除不必要的东西。
本文附带了 Price_Channel(初始指标)和 Price_Channel-Need(经过完全改造的)指标的完整代码。此外,我将仅说明做出的更改。
首先,将缓存的数量从 3 减小到 1:
//#property indicator_buffers 3 #property indicator_buffers 1 //#property indicator_plots 2 #property indicator_plots 1
然后,删除两个不必要的缓存数组:
//--- indicator buffers //double ExtHighBuffer[]; //double ExtLowBuffer[]; double ExtMiddBuffer[];
现在,如果我们尝试编译这个指标,则编译器将显示调用这些数组的所有行:
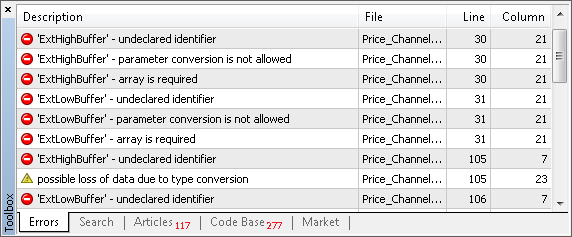
此方法能够快速找出需要更改的地方。当指标代码非常大时,它相当方便。
在我们的案例中,总共有 4 个 "undeclared identifier"(未声明的标识符)行。让我们纠正它们。
如我们所预期的,其中两个位于 OnInit 中。但是除了它们以外,我们还必须删除含有必要的 ExtMiddBuffer 的行。代之以的是,我们添加一个类似的,但含有另一个缓存索引的行。因为指标不再含有索引为 2 的缓存,只有索引 0 可用:
// SetIndexBuffer(0,ExtHighBuffer,INDICATOR_DATA); // SetIndexBuffer(1,ExtLowBuffer,INDICATOR_DATA); // SetIndexBuffer(2,ExtMiddBuffer,INDICATOR_DATA); SetIndexBuffer(0,ExtMiddBuffer,INDICATOR_DATA);
如果您计划在一个可视模型中使用“切割”指标,则应考虑外观设置应与缓存的索引一起改变。在本例中:
//#property indicator_type1 DRAW_FILLING #property indicator_type1 DRAW_LINE
如果您不需要可视化,则可以跳过外观的更改 - 它不会导致错误。
让我们继续处理“未声明的标识符”列表。最后两个更改(也是可预期的)位于在其中填充指标缓存数组的 OnCalculate 中。因为所需的 ExtMiddBuffer 调用删除的 ExtHighBuffer 和 ExtLowBuffer,中间变量代替了它们:
//--- the main loop of calculations for(i=limit;i<rates_total;i++) { // ExtHighBuffer[i]=Highest(High,InpChannelPeriod,i); double high=Highest(High,InpChannelPeriod,i); // ExtLowBuffer[i]=Lowest(Low,InpChannelPeriod,i); double low=Lowest(Low,InpChannelPeriod,i); // ExtMiddBuffer[i]=(ExtHighBuffer[i]+ExtLowBuffer[i])/2.0;; ExtMiddBuffer[i]=( high + low )/2.0;; }
如您所见,在整个“外科手术”中没有困难的地方。很快就找到需要的东西;经过几次“手术刀切割”,两个缓存被排除在外。在整个复合指标 Trender 中,总共节省了 10 个缓存(2 x 5 个时间框架)。
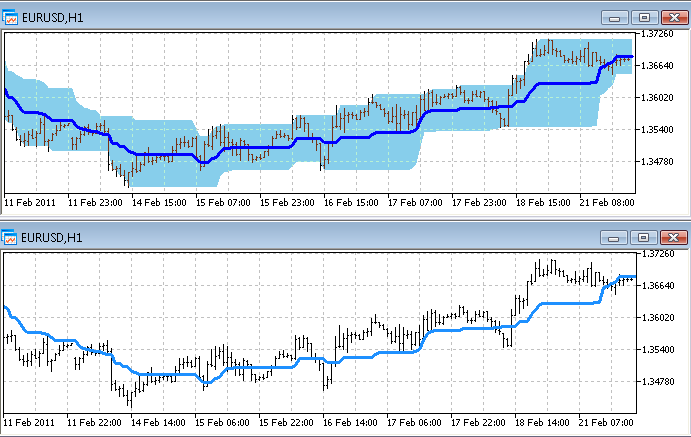
您可以在另一个指标下打开 Price_Channel 和 Price_Channel-Need 以查看消失的缓存:
要在 Trender 指标中使用 Price_Channel-Need,我们需要在 Trender 的代码中将辅助指标 "Price_Channel" 的名称纠正为 "Price_Channel-Need"。此外,我们需要将所需缓存的索引从 2 改为 0。本文附带了现成的 Trender-Need 代码。
5.2. “聚集”方法
如果主指标读取一个辅助指标的多个缓存的数据,然后执行聚集操作(例如累加或比较),则不必在主指标中执行此操作。我们可以使其成为一个辅助指标,然后将结果传递给主指标。因此不必有多个缓存;用一个缓存即可代替全部缓存。
在本例中,此方法适用于 Ichimoku。因为 Trender 使用来自该指标的 2 个缓存(0 - Tenkan,1 - Kijun);
CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); double Tenkan = bufTenkan[0]; CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); double Kijun = bufKijun [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--;
如果我们将 Ichimoku 的 0 和 1 缓存聚集到一个信号缓存,则上述 Trender 片断应被替换为:
CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufSignal); Signal += bufSignal[0];
本文附带了完整的 Trender-Aggregate 代码。
现在,让我们看一看应该对 Ichimoku 做出的关键更改。
此外,此指标包含未使用的缓存。因此,除了“聚集”方法以外,我们还可以应用“需要”方法。如此一来,在 Ichimoku 中的 5 个缓存仅剩下一个 - 聚集必要缓存的那个:
//#property indicator_buffers 5
#property indicator_buffers 1
//#property indicator_plots 4
#property indicator_plots 1
让我们给唯一的缓存取一个新的名称:
//--- indicator buffers //double ExtTenkanBuffer[]; //double ExtKijunBuffer[]; //double ExtSpanABuffer[]; //double ExtSpanBBuffer[]; //double ExtChinkouBuffer[]; double ExtSignalBuffer[];
新名称有实际意义 - 它允许从指标删除先前使用的缓存的所有名称。它能够(使用在“需要”方法中描述的编译)快速找到应更改的所有行。
如果您要在图表中对指标进行可视化,则不要忘记更改外观设置。您还应考虑到,在本例中,与它消耗的两个缓存相比,聚集缓存有不同的值域。现在,它不显示价格派生,而是显示两个缓存中较大的一个。在图表下方的一个单独窗口中显示此类结果更加方便:
//#property indicator_chart_window #property indicator_separate_window
因此,在 OnInit 中进行以下更改:
//--- indicator buffers mapping // SetIndexBuffer(0,ExtTenkanBuffer,INDICATOR_DATA); // SetIndexBuffer(1,ExtKijunBuffer,INDICATOR_DATA); // SetIndexBuffer(2,ExtSpanABuffer,INDICATOR_DATA); // SetIndexBuffer(3,ExtSpanBBuffer,INDICATOR_DATA); // SetIndexBuffer(4,ExtChinkouBuffer,INDICATOR_DATA); SetIndexBuffer(0,ExtSignalBuffer,INDICATOR_DATA);
最有趣的部分在 OnCalculate 中。注:直接删去三个不必要的缓存(如我们使用“需要”方法一样),用临时变量 Tenkan 和 Kijun 代替必要的 ExtTenkanBuffer 和 ExtKijunBuffer。这些变量在循环结束时使用,用于计算聚集缓存 ExtSignalBuffer:
for(int i=limit;i<rates_total;i++) { // ExtChinkouBuffer[i]=Close[i]; //--- tenkan sen double high=Highest(High,InpTenkan,i); double low=Lowest(Low,InpTenkan,i); // ExtTenkanBuffer[i]=(high+low)/2.0; double Tenkan =(high+low)/2.0; //--- kijun sen high=Highest(High,InpKijun,i); low=Lowest(Low,InpKijun,i); // ExtKijunBuffer[i]=(high+low)/2.0; double Kijun =(high+low)/2.0; //--- senkou span a // ExtSpanABuffer[i]=(ExtTenkanBuffer[i]+ExtKijunBuffer[i])/2.0; //--- senkou span b high=Highest(High,InpSenkou,i); low=Lowest(Low,InpSenkou,i); // ExtSpanBBuffer[i]=(high+low)/2.0; //--- SIGNAL double Signal = 0; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; ExtSignalBuffer[i] = Signal; }
总共减少 4 个缓存。如果我们仅对 Ichimoku 应用“需要”方法,则我们仅会减少 3 个缓存。
在整个 Trender 中,总共节省了 20 个缓存(4 x 5 个时间框架)。
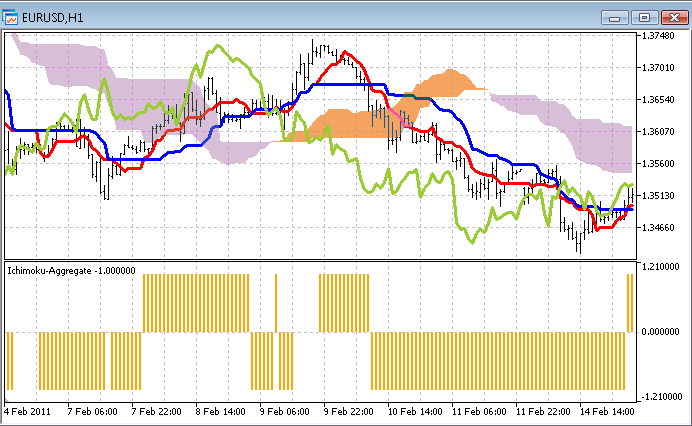
本文附带了完整的 Ichimoku-Aggregate 代码。要将这个指标与原来的指标进行比较,在一个图表上打开它们。如您记住的,现在,修改后的指标显示在图表下方的一个单独窗口中:
5.3. “包含”方法
减小缓存数量的最激进的方式是删除所有辅助指标。如果我们这样做,则在我们的指标中将仅剩下一个缓存 - 属于主指标的那个缓存。缓存数量不能再少了。
可以通过将辅助指标的代码移到主指标来实现相同的结果。有时这似乎是耗时的事情,但是最终效果是值得这样做的。最大的困难是改写从指标移动的代码。这些代码并不是计划用于在其他指标的代码中运行的。
以下是改写期间出现的主要问题:
- 名称冲突。变量、函数具有相同的名称(尤其是诸如 OnCalculate 等系统函数);
- 缺少缓存。在某些指标中,如果指标逻辑与缓存中数据的存储/处理紧密关联,则可能成为不可克服的障碍。在本例中,用简单的数组来代替缓存并不是万能药,因为我们的目标是减少内存消耗。拒绝在内存中存放大量历史数据非常重要。
让我们来说明能够有效解决这些问题的方法。
应作为一个类来编写每一个辅助指标。然后,指标的所有变量和函数都(在它们的类里)有唯一的名称,并且不会与其他指标冲突。
如果移动很多指标,则可以考虑将这些类进行标准化以避免在使用时出现混淆。为此,创建一个基本指标类,然后从该类继承所有辅助指标类。
我编写的类如下所示:
class CIndicator { protected: string symbol; // currency pair ENUM_TIMEFRAMES timeframe; // timeframe double Open[], High[], Low[], Close[]; // simulation of price buffers int BufLen; // necessary depth of filling of price buffers public: //--- Analogs of standard functions of indicators void Create(string sym, ENUM_TIMEFRAMES tf) {symbol = sym; timeframe = tf;}; void Init(); void Calculate(datetime start_time); // start_time - address of bar that should be calculated };
现在,让我们依据该类创建一个用于 Ichimoku 指标的类。首先,以属性的形式,编写具有原始名称的输入参数。以后不要更改指标的任何代码:
class CIchimoku: public CIndicator { private: // Simulation of input parameters of the indicator int InpTenkan; int InpKijun; int InpSenkou;
保留所有缓存的名称。是的,这是您听到的 - 我们声明了这个指标的所有 5 个缓存。但是它们是假的。每个缓存都只包含一根柱:
public: // Simulation of indicator buffers double ExtTenkanBuffer [1]; double ExtKijunBuffer [1]; double ExtSpanABuffer [1]; double ExtSpanBBuffer [1]; double ExtChinkouBuffer[1];
为什么我们这样做 ?为了减少以后更改代码的量。您会看到这一点。重新定义继承的方法 CIchimoku.Calculate,将其填以从 Ichimoku 获取的 OnCalculate 函数的代码。
注意,在移动此函数时,按历史柱进行的循环被删除。现在,仅计算具有指定时间的一根柱。计算的主代码保持不变。这是我们为什么如此小心地保留指标的所有缓存和参数的名称的原因。
您也应注意到,价格缓存被填以 Calculate 方法一开始的值。值的数量与计算一根柱需要的数量一样多。
void Calculate(datetime start_time) { CopyHigh (symbol,timeframe,start_time,BufLen,High); CopyLow (symbol,timeframe,start_time,BufLen,Low ); CopyClose(symbol,timeframe,start_time,1 ,Close); // int limit; //--- // if(prev_calculated==0) limit=0; // else limit=prev_calculated-1; //--- // for(int i=limit;i<rates_total;i++) int i=0; { ExtChinkouBuffer[i]=Close[i]; //--- tenkan sen double high=Highest(High,InpTenkan,i); double low=Lowest(Low,InpTenkan,i); ExtTenkanBuffer[i]=(high+low)/2.0; //--- kijun sen high=Highest(High,InpKijun,i); low=Lowest(Low,InpKijun,i); ExtKijunBuffer[i]=(high+low)/2.0; //--- senkou span a ExtSpanABuffer[i]=(ExtTenkanBuffer[i]+ExtKijunBuffer[i])/2.0; //--- senkou span b high=Highest(High,InpSenkou,i); low=Lowest(Low,InpSenkou,i); ExtSpanBBuffer[i]=(high+low)/2.0; } //--- done // return(rates_total); };
当然,我们会跳过保留原来的代码。但是在本例中,我们将不得不改写很大一部分的代码,这需要理解其运行逻辑。在本例中,指标很简单并且容易理解。但是,如果指标很复杂会怎么样呢?我已经向您展示了在此类情况中能有所帮助的方法。
现在让我们填写 CIchimoku.Init 方法;此处,一切都很简单:
void Init(int Tenkan = 9, int Kijun = 26, int Senkou = 52) { InpTenkan = Tenkan; InpKijun = Kijun; InpSenkou = Senkou; BufLen = MathMax(MathMax(InpTenkan, InpKijun), InpSenkou); };
Ichimoku 包含另外两个应复制到 CIchimoku 类的函数:Highest 和 Lowest。它们搜索价格缓存指定部分内的最高价和最低价。
我们的价格缓存不是真实的;它们的量非常小(您已经在上述 Calculate 方法中看到了它们的填写)。这是为什么我们必须稍微更改一下 Highest 和 Lowest 函数的运行逻辑的原因。
在这种情形下,我也遵循进行最少更改的原则。所有修改都包含添加一行代码,将缓存中的柱的索引从全局索引(当缓存长度是整个可用历史记录时)变为局部索引(因为现在的价格缓存仅包含计算一根指标柱所需要的值):
double Highest(const double&array[],int range,int fromIndex) { fromIndex=MathMax(ArraySize(array)-1, 0); double res=0; //--- res=array[fromIndex]; for(int i=fromIndex;i>fromIndex-range && i>=0;i--) { if(res<array[i]) res=array[i]; } //--- return(res); }
以同样的方式修改 Lowest 方法。
对 Price_Channel 指标进行类似修改,但是将被表示为名为 CChannel 的类。两个类的完整代码见本文所附的 Trender-Include 文件。
我已经描述了移动代码的主要方面。我认为,对于大多数指标而言,这些方法足够了。
具有非标准设置的指标可能造成额外困难。例如,Price_Channel 包含不显著的代码行:
PlotIndexSetInteger(0,PLOT_SHIFT,1); PlotIndexSetInteger(1,PLOT_SHIFT,1);
它们表示指标图在 1 根柱上偏移。在我们的案例中,它将导致这样的情形:CopyBuffer 和 CopyHigh 函数使用两根不同的柱,尽管在它们的参数中设置了相同的柱坐标(时间)。
在 Trender-Include 中解决了这个问题(在 CChannel 类的必要部分中添加了 "ones",与 CIchimoku 类截然不同,CIchimoku 类不存在这个问题)。因此,如果您需要这样一个“狡诈的”指标,则您需要知道在哪里找到它。
现在,我们完成了移动,两个指标都作为 Trender-Include 指标内的两个类来编写。接下来更改这些指标的调用方式。在 Trender 中,我们有句柄数组;在 Trender-Include 中,对象数组代替了它们:
// Handles of auxiliary indicator for all timeframes //int h_Ichimoku[5], h_Channel[5]; // Instances of embedded auxiliary indicators CIchimoku o_Ichimoku[5]; CChannel o_Channel[5];
现在,OnInit 中辅助指标的创建看起来如下所示:
for (int itf=0; itf<5; itf++) { o_Ichimoku[itf].Create(Symbol(), TF[itf]); o_Ichimoku[itf].Init(9, 26, 52); o_Channel [itf].Create(Symbol(), TF[itf]); o_Channel [itf].Init(22); }
并且以直接调用对象的属性来代替 OnCalculate 中的 CopyBuffer:
//=== The Ichimoku indicator o_Ichimoku[itf].Calculate(Time); //CopyBuffer(h_Ichimoku[itf], 0, Time, 1, bufTenkan); //double Tenkan = bufTenkan[0]; double Tenkan = o_Ichimoku[itf].ExtTenkanBuffer[0]; //CopyBuffer(h_Ichimoku[itf], 1, Time, 1, bufKijun ); //double Kijun = bufKijun [0]; double Kijun = o_Ichimoku[itf].ExtKijunBuffer [0]; if (Tenkan > Kijun) Signal++; if (Tenkan < Kijun) Signal--; //=== The Channel indicator o_Channel[itf].Calculate(Time); //CopyBuffer(h_Channel [itf], 2, Time, 1, bufMid); //double Mid = bufMid[0]; double Mid = o_Channel[itf].ExtMiddBuffer[0]; if (Price > Mid) Signal++; if (Price < Mid) Signal--;
减少了 40 个缓存。这样做是值得的。
在每一次依据上述“需要”和“聚集”方法修改 Trender 之后,我在可视模式中测试了得到的指标。
让我们现在就进行此测试:在图表上打开初始指标 (Trender) 和修改后的指标 (Trender-Include)。我们可以说一切都很正确,因为两个指标的线条精准地一致:
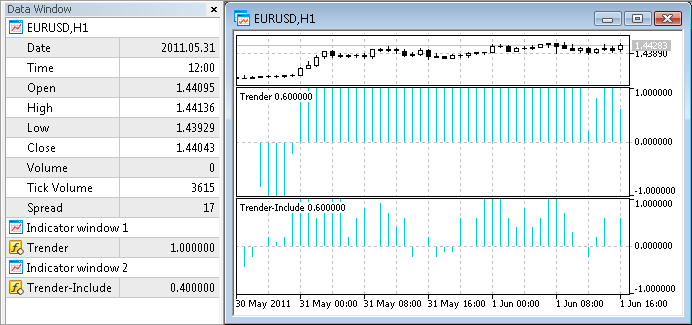
5.4. 我们能够一个接一个的进行吗?
我们已经考虑了减少辅助指标的缓存数量的三种方法。但是,如果我们尝试从根本上改变方法 - 如果我们尝试减少同时保留在内存中的缓存的数量而不是减少它们的总数量会怎么样呢?换言之,我们将一个接一个地将指标加载到内存中,而不是一次性加载所有指标。我们需要组织一个“环形路”:创建一个辅助指标,读取其数据,删除该指标,创建下一个辅助指标,依此类推,直到我们遍历所有时间框架。Ichimoku 指标的最大缓存数量 - 5。因此理论上,可以在内存中同时保留最多 5 个缓存(另加主指标的 1 个缓存),总共减少 35 个缓存!
可能吗?在 MQL5 中,有一个用于删除指标的特殊函数 - IndicatorRelease。
但是,它并不如看起来那样简单。MetaTrader 5 注重 MQL5 程序的高速运行,这是为什么所有调用的时间序列都保存在高速缓存中的原因, - 以备其他 EA、指标或脚本需要使用它们。并且仅在长时间没有调用它们时,才会卸载它们以释放内存。此等待时间长达 30 分钟。
因此,不断地创建和删除指标不能立即节省大量内存。但是,它能让计算机的运行显著变慢,因为在每次创建时都会为整个价格历史计算指标。考虑一下在主指标的每一根柱上执行此类操作有多合理……
然而,对“头脑风暴”而言,“指标环形路”的想法仍然非常有趣。如果您想出优化指标内存的其他原创想法,请将您的评论添加到本文。或许在有关本主题的下一篇文章中会将它们用于理论或实践。
6. 测量内存的实际消耗
在以前的章节中,我们已经实施了减少辅助指标的缓存数量的三种行之有效的方法。现在,让我们分析它是如何减少内存的实际消耗的。
我们将使用微软 Windows 操作系统中的“任务管理器”测量客户端消耗的内存大小。在“进程”选项卡中,您将看到客户端消耗的 RAM 和虚拟内存的大小。例如:
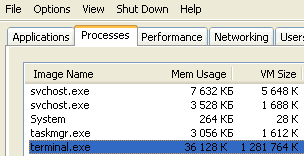
依据以下算法进行测量,该算法允许查看客户端的最小内存消耗(接近指标的内存消耗):
- 从 MetaQuotes-Demo 服务器下载一个深入价格历史(对于交易品种历史的自动下载,足以在一个交易品种上运行测试);
- 为下一次测量设置客户端(打开需要的图表和指标),并且重新启动客户端以清除内存中不必要的信息;
- 等待重启后的客户端完成所有指标的计算。处理器零加载即表示计算完成;
- 将客户端最小化到任务栏(通过单击客户端右上角的标准“最小化”按钮)。此时它将释放未用于计算的内存(在以上屏幕截图中,您可以看到仍然处于最小化状态的内存消耗的例子 - 您可以看到 RAM 的消耗比虚拟内存少很多);
- 在任务管理器中将“内存使用” (RAM) 和“虚拟内存大小”两列的值相加。这是它们在 Windows XP 中的名称,操作系统的不同版本可能有略微不同的名称。
测量的参数:
- 为了让测量更加精确,我们将使用在 MetaQuotes 演示帐户中可用的所有货币对,而不是一个价格图表,即 22 个 M1 图表。然后我们将计算平均值;
- "Max bars in chart" (图表中的最大柱数)选项(在第 4.1 节中描述)具有标准值 - 100000;
- 操作系统 - Windows XP,32 位。
期待什么样的测量结果?有两个说明:
- 即使 Trender 指标使用 41 个缓存,也不意味着它消耗 41 x 100000 根柱。原因是缓存分布在五个时间框架内,并且大的时间框架包含的柱比小的时间框架包含的柱要少。例如,EURUSD 的 M1 历史大约包含 400 万根柱,而 H1 历史只包含大约 70000 根柱 (4000000/60)。这是为什么您不应期待在减少 Trender 中的缓存数量之后,内存消耗也会同样减少的原因。
- 内存不仅仅被指标本身消耗,也会被指标使用的价格序列消耗。Trender 使用五个时间框架。因此,如果我们减少缓存数量几倍,内存的总消耗并不会减少相同的倍数。因为将使用内存中的所有这五个价格序列。
在测量消耗时,您可能会面临影响内存消耗的其他一些因素。这是为什么我们进行这些实际测量的原因 - 查看作为指标优化结果的真正节省。
下表列出了所有测量的结果。首先,我测量了空客户端消耗的内存大小。通过从下一次测量减去该值,我们可以计算一个图表消耗的内存大小。再从下一次测量中减去客户端和一个图表消耗的内存,我们得到每个指标消耗的内存大小。
| 内存消耗对象 |
指标缓存数量 |
时间框架数量 |
内存消耗量 |
|---|---|---|---|
| 客户端 |
0 |
0 |
客户端 38 Mb |
| 图表 |
0 |
1 |
一个空的图表 12 Mb |
| Trender 指标 |
41 |
5 |
一个指标 46 Mb |
| Trender-Need 指标 |
31 |
5 |
一个指标 42 Mb |
| Trender-Aggregate 指标 | 21 |
5 |
一个指标 37 Mb |
| Trender-Include 指标 | 1 |
5 |
一个指标 38 Mb |
依据测量结果得出的结论:
- 减少指标缓存的数量并不会造成指标使用的内存出现同等程度的减少。
本章前文说明了这种效应的原因。或许指标使用的时间框架越短,减少缓存数量的效果就越显著。
- 将辅助指标的代码移到主指标内并不会始终都能带来最好的结果。
那么,为什么“包含”方法不能与“聚集”方法一样高效呢?为了确定原因,我们需要记住这些指标的代码的主要差异。在“聚集”方法中,计算所需的价格序列是由客户端作为 OnCalculate 中的输入数组传递的。在“包含”方法中,使用 CopyHigh、CopyLow 和 CopyClose 为每根柱主动请求(所有时间框架的)所有数据。在使用这些函数时,很可能正是价格时间序列的高速缓存的特性导致内存的额外消耗。
总结
本文介绍了减少辅助指标内存消耗的三种行之有效的方法,还介绍了通过调整客户端来节省内存的一种方法。
应依据您的具体情形的可接受性和适当性采用相应的方法。已保存缓存数和兆字节数取决于您处理的指标:在某些指标中能够“剪掉”很多,但在其他指标中不能做任何事情。
节省内存能够增大在客户端中同时使用的货币对的数量。这样提高了交易投资组合的可靠性。对您的计算机的技术资源进行这样的简单考量就可转换为任您处置的资金资源。
附件
附件包含了本文描述的指标。要使一切工作正常,请将它们保存到 "MQL5\Indicators\TestSlaveIndicators" 文件夹中,因为 Trender 指标的所有版本(Trender-Include 除外)都将在该文件夹中寻找辅助指标。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/259
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
 新MQL4中的离线图表
新MQL4中的离线图表
 机器学习:支持向量机如何应用于交易
机器学习:支持向量机如何应用于交易
 MetaTrader 4 Build 600及以上的数据结构 - MQL4文章
MetaTrader 4 Build 600及以上的数据结构 - MQL4文章
这种做法是可以理解的。但任务的紧迫性却令人困惑。
实际上,我写这篇文章的想法是在一个人的抱怨下产生的,我为他写了一个复合指标,他抱怨说这个指标没有安装在某些货币对上。调查后发现,有一些指标是非常持久的,而且很多指标都无法安装到终端上(也就是说,问题不在于货币对,而在于在这个货币对之前,又有十几个同样的持久指标被打开了)。该指标的消耗量是文章中测试指标的 2 倍。
即使是 32 位的 3GB 内存也能达到如此大的内存容量。
如果您在大量货币对上进行交易,就不会出现这种情况,这就是问题所在。
顺便说一下,终端分配的内存不能超过 2GB(总计:RAM + 虚拟内存)。在我的实验中,它就是在这个值上关闭的。
当然,这个问题在 64 位时不应该存在。
好吧,我们假设这个任务是相关的(我同意有人会关心这个问题)。但仔细想想,节省内存的任务与提高性能的任务是直接矛盾的。
并不总是这样。在这篇文章中,大部分方法都不会降低性能。
Expert Advisor 只要求从指标中获取最后一个柱状图,这与文章中考虑的方案属于不同的类别。用另一种程序取代另一种程序并不总是可能/方便的。
。
共同对上的每个指标都有自己的数据实例是不太可能的--文章 中有一个关于并行计算 的有趣表格,可以通过关键词 "2 个指标 "找到。
指标的问题在于,每个指标都在自己的线程中运行,因此必须在线程中存储所有必要的数据。
线程之间的数据通过 CopyBuffer() 复制。但问题是:你可以从线程中获取数据,但无法将数据传输到线程中。这就是为什么不能构建一个指标的多个实例接收相同预处理数据的 mogostage 指标。但就在这个层面上,却蕴藏着优化计算的 巨大机会。
我认为,如果 MQ 能解决这个问题,那么使用指标的工作将变得更加方便和灵活。现在,数据只能作为外部参数传递,而且只能在线程开始时传递。
非常有用
如果我正确理解了主流思想,就会产生一个问题:
为什么MT5 安装的 所有标准指标都没有设计成 "类"?
那为什么向导大师不考虑这种想法?
如果不从 "工具">"选项 "中限制最大条形图,我用来减少缓冲区空间的快速方法是