
Die Grenzen des maschinellen Lernens überwinden (Teil 9): Korrelationsbasierte Lernen von Merkmalen im selbstüberwachten Finanzwesen

Es gibt viele Hindernisse, die es jedem Mitglied unserer Gemeinschaft erschweren, maschinenlerngestützte Handelsanwendungen sicher einzusetzen. In dieser Artikelserie wollen wir die Aufmerksamkeit des Lesers auf Fehlerquellen lenken, die schwerer zu erkennen sind und in der Standardliteratur zum maschinellen Lernen nicht behandelt werden. Eine der folgenreichsten ist das stille Versagen, das eintritt, wenn die einem Modell zugrunde liegenden Annahmen verletzt werden.
Alle statistischen Modelle gehen von bestimmten Annahmen über die vorliegenden Daten und den Prozess, der diese Daten erzeugt hat, aus. Je weniger Annahmen ein Modell macht, desto flexibler – oder „leistungsfähiger“ – wird es, da Modelle mit weniger Annahmen viele komplexe Beziehungen lernen können. An dieser Stelle werden einige Leser vielleicht denken: „Wenn Modelle leistungsfähiger werden, wenn sie weniger Annahmen treffen, warum dann nicht ein Modell entwerfen, das überhaupt keine Annahmen trifft?“ Leider ist es unmöglich, ein statistisches Modell zu erstellen, das keinerlei Annahmen über die vorliegenden Daten enthält. Eine der wichtigsten Annahmen, die für die Erstellung eines Modells für maschinelles Lernen erforderlich sind, ist die Annahme, dass es eine Beziehung zwischen den Eingaben, die Sie haben, und dem Ziel, an dem Sie interessiert sind, gibt.
Diese Annahmen bilden die Grundlage für unsere Fähigkeit bzw. Unfähigkeit, jeden beliebigen Finanzmarkt gewinnbringend zu prognostizieren. Wenn diese Annahmen nicht eingehalten werden, geschieht nichts Sichtbares. Es gibt keine Warnung. Dieser stille Punkt des Scheiterns ist etwas, auf das die derzeitigen statistischen Modelle einfach später einmal stoßen, oft ohne dass sie entdeckt werden.
Akademische Texte enthalten oft statistische Tests, um festzustellen, ob die Annahmen eines Modells zutreffen. Es ist wichtig zu wissen, wie gut die Annahmen Ihres Modells mit der Art Ihres Problems übereinstimmen, denn dies sagt uns, ob das von uns gewählte Modell für die Aufgabe, die wir ihm übertragen wollen, in einem guten Zustand ist. Diese statistischen Standardtests bringen jedoch eine Reihe zusätzlicher materieller Herausforderungen mit sich, die das ohnehin schon schwierige Ziel noch weiter erschweren. Kurz gesagt, akademische Standardlösungen sind nicht nur schwierig auszuführen und sorgfältig zu interpretieren, sondern sie sind auch anfällig für falsche Ergebnisse, d. h. sie können ein Modell bestätigen, das nicht solide ist. Dadurch sind die Praktiker unübersehbaren Risiken ausgesetzt.
Daher wird in diesem Artikel eine praktischere Lösung vorgeschlagen, um sicherzustellen, dass die Annahmen Ihres Modells über die reale Welt nicht verletzt werden. Wir konzentrieren uns auf eine Annahme, die allen statistischen Modellen gemeinsam ist – von einfachen linearen Modellen bis zu modernen tiefen neuronalen Netzen. Sie alle gehen davon aus, dass das von Ihnen gewählte Ziel eine Funktion der Ihnen vorliegenden Beobachtungen ist. Wir zeigen, dass ein höheres Leistungsniveau erreicht werden kann, indem wir die gegebene Menge an Beobachtungen als Rohmaterial behandeln, aus dem wir neue Zielkandidaten generieren, die einfacher zu lernen sind. Dieses Paradigma wird auch als selbstüberwachtes Lernen bezeichnet.
Diese neuen, aus den Eingabedaten generierten Ziele sind per Definitionem garantiert Funktionen des Ziels. Dies mag unnötig erscheinen, aber tatsächlich stärkt es einen der größten blinden Flecken unserer statistischen Modelle und hilft uns, robustere und zuverlässigere numerisch gesteuerte Handelsanwendungen zu entwickeln. Beginnen wir.
Abrufen unserer Daten vom MetaTrader 5 Terminal
In dieser Diskussion wollen wir unsere Inputs, die OHLC-Kurse (Open, High, Low und Close), als Rohmaterial für neue Überwachungssignale verwenden, die unser statistisches Modell lernen kann. Aus Gründen der Reproduzierbarkeit ist es daher am besten, wenn wir alle Datenmanipulationen in MQL5 durchführen. Beim maschinellen Lernen wird angenommen, dass das Ziel, der zukünftige Preis, eine Funktion der Beobachtungen von OHLC ist. Dies verstößt gegen die Standardportfoliotheorie, denn wir wissen, dass die künftigen Renditen von den Erwartungen der Anleger und nicht von den historischen Preisen abhängen. Mit dieser Motivation wollen wir neue imaginäre Punkte berechnen, die zwischen den beobachteten Preisniveaus liegen. Um dies in MQL5 zu tun, wenden wir eine einfache Arithmetik an, um den imaginären Mittelpunkt zu berechnen, der sich zwischen jedem Paar von OHLC-Einspeisungen befindet. //+------------------------------------------------------------------+ //| Fetch Data Mid Points | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Mid Points.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- OHLC Mid Points "O-H M", "O-L M", "O-C M", "H-L M", "H-C M", "L-C M" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- OHLC Mid Points (iOpen(_Symbol,PERIOD_CURRENT,i) + iHigh(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iLow(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2 ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Analyse unserer Marktdaten in Python
Beginnen wir damit, dass wir zunächst unsere Standard-Python-Bibliotheken importieren.
#Load our libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Als Nächstes lesen Sie die CSV-Datei ein, die wir mit unserem MQL5-Skript erstellt haben.
#Read in the data
data = pd.read_csv('./EURUSD Mid Points.csv')
data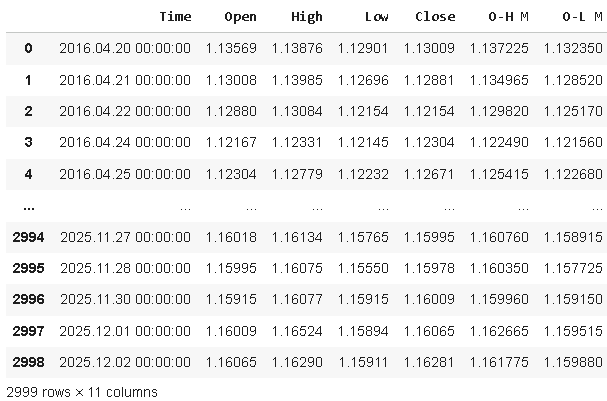
Abbildung 1: Visualisierung unserer Marktdaten, wie wir sie in unserem MQL5-Skript berechnet haben
Wir berechneten die Mittelwerte in unserem MQL5-Skript mit Hilfe unserer Kenntnisse der Arithmetik. Wir sollten jedoch einige Tests auf Korrektheit durchführen, um sicherzustellen, dass wir das umgesetzt haben, was wir uns vorgestellt haben. Wie in Abbildung 2 unten zu sehen ist, haben wir die historischen EURUSD-Hoch- und Tiefstkurse, wie wir sie von unserem Broker erhalten haben, eingezeichnet. Außerdem können wir feststellen, dass der gestrichelte imaginäre Mittelpunkt, den wir in MQL5 berechnet haben, wie erwartet zwischen dem Hoch und dem Tief liegt.
#Examine correctness plt.plot(data.loc[0:10,'High'],color='red') plt.plot(data.loc[0:10,'H-L M'],color='black',linestyle=':') plt.plot(data.loc[0:10,'Low'],color='blue') plt.grid() plt.legend(['High','H-L Mid','Low']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The High-Low Mid Point of EURUSD Exchange Rates')
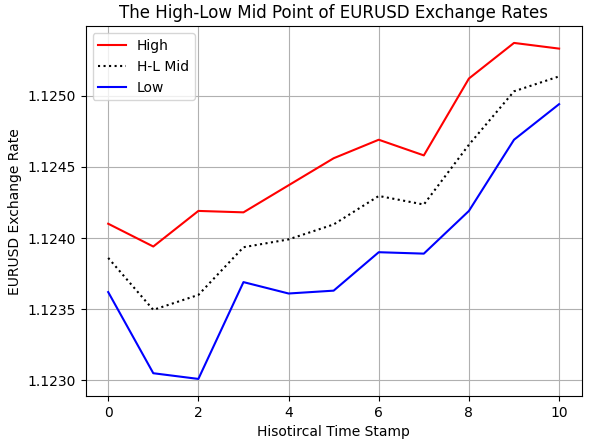
Abbildung 2: Visualisierung des Mittelwerts zwischen dem EURUSD-Hoch- und Tiefstkurs
Auch der Mittelwert zwischen Eröffnungs- und Schlusskurs wurde korrekt berechnet, wie in der folgenden Abbildung zu sehen ist.
#Examine correctness plt.plot(data.loc[70:90,'Open'],color='red') plt.plot(data.loc[70:90,'O-C M'],color='black',linestyle=':') plt.plot(data.loc[70:90,'Close'],color='blue') plt.grid() plt.legend(['Open','O-C Mid','Close']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The Open-Close Mid Point of EURUSD Exchange Rates')
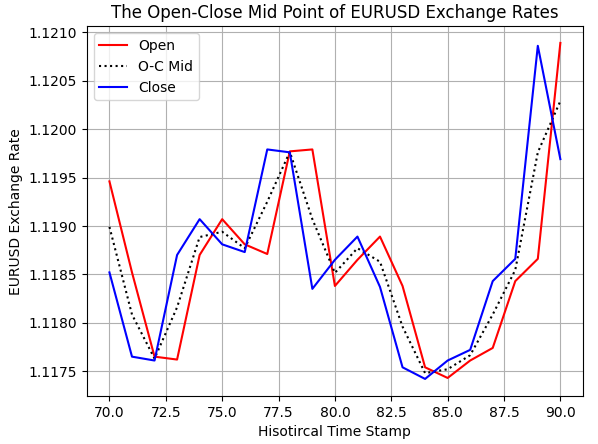
Abbildung 3: Visualisierung des Mittelpunkts zwischen dem Eröffnungs- und dem Schlusskurs.
Legen wir nun fest, wie weit wir in die Zukunft schauen wollen.
#Forecast horizon HORIZON = 2
Normalerweise wird in der akademischen Standardliteratur über statistisches Lernen an diesem Punkt vom Leser erwartet, dass er seine Eingaben und sein Ziel (target) trennt. Dies ist jedoch der entscheidende Unterschied zu der Lösung, die dieser Artikel dem Leser vermitteln möchte. Anstatt mit einem festen Ziel vor Augen zu arbeiten, werden wir so viele Ziele wie möglich aus den uns vorliegenden Beobachtungen generieren.
#Candidate targets candidate_y = data.iloc[:,4:11].columns candidate_x = data.iloc[:,1:5].columns
Für diese Übung haben wir das klassische Ziel des zukünftigen Preises beibehalten und zusätzlich haben wir andere Ersatzziele, von denen wir glauben, dass sie leichter zu lernen sind als das klassische Ziel.
candidate_y
Index(['Close', 'O-H M', 'O-L M', 'O-C M', 'H-L M', 'H-C M', 'L-C M'], dtype='object')
Wir erstellen die Spalten im Originaldatensatz, um den zukünftigen Wert jedes Zielkandidaten zu speichern.
data['Label 1'] = 0 data['Label 2'] = 0 data['Label 3'] = 0 data['Label 4'] = 0 data['Label 5'] = 0 data['Label 6'] = 0 data['Label 7'] = 0
Wir erstellen schließlich zusätzliche Spalten, die als binäre Ziele für jedes zu bewertende Ziel stehen.
data['Target 1'] = 0 data['Target 2'] = 0 data['Target 3'] = 0 data['Target 4'] = 0 data['Target 5'] = 0 data['Target 6'] = 0 data['Target 7'] = 0
Wir müssen nun unseren Datensatz kennzeichnen und dann den Zielwert eingeben. In dieser einfachen Schleife werden die zuvor definierten 0-Spalten iterativ mit dem zukünftigen Wert des Ziels und seiner jeweiligen binären Darstellung gefüllt.
#Label the dataset for i in np.arange(7): #Add labels to the data label = 'Label ' + str(i+1) data[label] = data[candidate_y[i]].shift(-HORIZON) #Define the labels as binary targets target = 'Target ' + str(i+1) data[target] = 0 #Add the target data.loc[data[label] > data[candidate_y[i]],target] = 1 #Drop the last missing forecast horizon period data = data.iloc[:-HORIZON,:] data
Laden wir nun die statistischen Lernbibliotheken, die wir benötigen, um zu bestimmen, welches Ziel für unser Modell angesichts der vorliegenden Beobachtungen leichter zu lernen ist.
from sklearn.model_selection import TimeSeriesSplit,cross_val_score from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Um unsere Vergleiche streng zu halten, werden wir für jedes Ziel das gleiche Modell verwenden.
def get_model(): return(LinearDiscriminantAnalysis())
Nun definieren wir unser Zeitreihen-Kreuzvalidierungsobjekt. Dadurch wird sichergestellt, dass wir bei der Kreuzvalidierung unseres Modells keine zufälligen Mischungen vornehmen.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)Wir bereiten ein Array vor, um unsere Genauigkeit bei jedem Ziel zu verfolgen.
scores = []
Die Kreuzvalidierung der Leistung desselben Modells mit denselben Eingaben, wobei nur das Ziel geändert wird, das das Modell aus den vorhandenen Beobachtungen zu lernen versucht.
#Classical Target scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-7],cv=tscv,scoring='accuracy'))) #Modern Targets scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-6],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-5],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-4],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-3],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-2],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-1],cv=tscv,scoring='accuracy')))
Jetzt kann der Leser den praktischen Wert der von uns vorgeschlagenen Lösung deutlich erkennen. Indem Sie Ihre eigenen Ziele auf der Grundlage der Beobachtungen, mit denen Sie begonnen haben, entwerfen, können Sie neue Fehlerniveaus erreichen, die Sie nie erreichen würden, wenn Sie sich an das klassische feste Ziel des zukünftigen Preises hielten würden.
scores
[np.float64(0.503006012024048),
np.float64(0.7082164328657314),
np.float64(0.6941883767535071),
np.float64(0.6328657314629258),
np.float64(0.6501002004008015),
np.float64(0.5739478957915832),
np.float64(0.5739478957915831)]
Wenn wir die Ergebnisse unserer vorgeschlagenen Lösung visualisieren, werden die Verbesserungen, die wir erzielt haben, offensichtlich. Unserem Modell fiel es leichter, jedes andere Ziel, das wir aus den Beobachtungen gebildet hatten, zu lernen, als den Preis selbst zu lernen. Es scheint, dass die Vorteile den zusätzlichen Aufwand, der mit dem Erwerb verbunden ist, durchaus wert sind.
sns.barplot(scores,color='black') plt.xticks([0,1,2,3,4,5,6],candidate_y) plt.axhline(scores[0],linestyle=':',color='red') plt.ylabel('Accuracy out of 100%') plt.xlabel('Selected Target') plt.title('EURUSD Forecasting Accuracy is a Function of The Target')
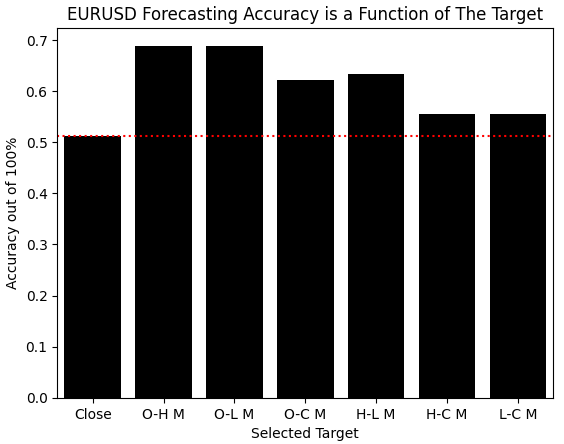
Abbildung 4: Die Veränderungen, die durch die Änderung unseres Ziels erzielt wurden, sind bemerkenswert und verdienen weitere Untersuchungen
Als numerisch orientierte algorithmische Händler können wir durch die sorgfältige Interpretation aussagekräftiger Zahlen aus unserem Datensatz schnell eine Menge über unseren Datensatz lernen. In diesem Fall müssen wir uns vor dem „Belohnungs-Hacking“ in Acht nehmen. Daher müssen wir die höchste Punktzahl ermitteln, die ein Modell hätte erreichen können, indem es immer die häufigste Kennzeichnung für jedes Ziel vorhersagt.
Da jedes Ziel entweder 1 oder 0 ist, gibt die Berechnung des Mittelwerts jedes Ziels Aufschluss darüber, welcher Zielwert am häufigsten vorkommt und in welchem Verhältnis er dominiert. Wenn die beiden Zielwerte gleichermaßen auftreten, sollte der Durchschnittswert dieses Ziels 0,5 betragen. Abweichungen unter 0,5 bedeuten, dass mehr Nuller vorhanden waren, und umgekehrt, dass mehr Einser gab. Der Mittelwert kann nur eins sein, wenn alle Zielwerte eins waren, und ebenso müssen alle Einträge null sein, um einen Mittelwert von null zu erhalten.
Wir können also feststellen, dass sich unsere Zielkandidaten gut verhalten und keines von ihnen zu weit von 0,5 abweicht, um die Verbesserungen gegenüber dem klassischen Modell vernünftig zu erklären.
data.iloc[:,-7:].mean()| Ziel | Average |
|---|---|
| Ziel 1 | 0.502836 |
| Ziel 2 | 0.507174 |
| Ziel 3 | 0.487154 |
| Ziel 4 | 0.494161 |
| Ziel 5 | 0.500167 |
| Ziel 6 | 0.474808 |
| Ziel 7 | 0.522856 |
Nachdem wir nun Ziele identifiziert haben, die leichter vorherzusagen sind als die ursprünglichen Kursniveaus, wollen wir nun lernen, wie unser neues Ziel mit dem klassischen Ziel zusammenhängt. Dies ist ein entscheidender Schritt. Wir beginnen mit dem Import eines einfachen linearen Modells
from sklearn.linear_model import LinearRegression
Statistische Instrumente können für Schlussfolgerungen oder für Erkenntnisse eingesetzt werden. Normalerweise verwenden wir unsere Instrumente für Schlussfolgerungen oder einfach für Prognosen. Heute werden wir uns darauf konzentrieren, diese Modelle zu nutzen, um Erkenntnisse zu gewinnen, nicht um Vorhersagen zu treffen.
explanation = LinearRegression()
Die Anwendung eines linearen Modells auf zwei Ziele mag zunächst unbegründet erscheinen. Dies ist jedoch eine durchaus sinnvolle Praxis.
explanation.fit(data[['Label 1']],data['Label 2'])
Die von unserem linearen Modell gelernten Koeffizienten sagen uns sofort, ob sich unsere beiden Ziele gemeinsam oder in entgegengesetzter Richtung bewegen. Unser lineares Modell schätzt Koeffizienten, die fast gleich 1 sind, was bedeutet, dass das neue Ziel, das wir generiert haben, dem klassischen Ziel fast perfekt folgt. Daher ist die Vorhersage des neuen Ziels genauso gut wie die Vorhersage des klassischen Ziels, mit dem Vorteil, dass das von uns formulierte neue Ziel weniger aufwendig zu erlernen ist.
explanation.coef_
array([0.99533718])
Alternativ hätte der Leser auch einfach die Korrelationsmatrix der von uns erstellten Zielkandidaten berechnen können, um zu demselben Ergebnis zu gelangen.
data.iloc[:,-14:-7].corr()
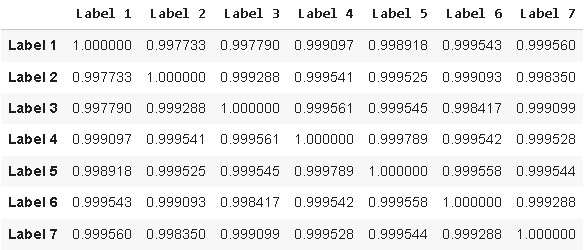
Abbildung 5: Visualisierung der Korrelation zwischen den von uns entwickelten Zielkandidaten und dem klassischen Ziel
Schließlich können wir uns dies auch visuell beweisen, indem wir das klassische Ziel, das wir haben, gegen das neue Ziel, das wir modellieren wollen, auftragen. Dabei zeigt sich, was wir durch die Erkenntnisse aus unserem linearen Modell und der Korrelationsmatrix bestätigt haben: Unsere beiden Ziele folgen einander mit klarer und eindeutiger Affinität.
plt.plot(data.iloc[0:200,-14],color='black') plt.plot(data.iloc[0:200,-13],linestyle=':',color='red') plt.grid() plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Historical Time') plt.title('Visualizing Our Classical & Candidate Target') plt.legend(['Classical Target','Candidate Target'])
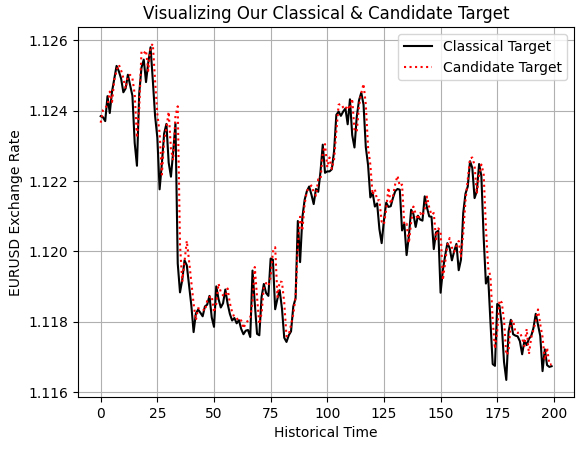
Abbildung 6: Visualisierung der Beziehung zwischen dem von uns entwickelten Zielkandidaten und dem klassischen Ziel
Nachdem wir nun herausgefunden haben, welches Ziel zum Lernen am besten ist, werden wir nun alle Eingabedaten, die wir bisher generiert haben, verwenden, um das Ziel zu modellieren, bei dem wir besonders gut sind.
X = ['Open','High','Low','Close','O-H M','O-C M', 'H-L M', 'H-C M', 'L-C M'] y = ['Target 2']
Zu meiner Überraschung änderte sich unser Leistungsniveau überhaupt nicht, trotz der zusätzlichen Eingaben, die wir in unser Modell einbrachten.
np.mean(cross_val_score(get_model(),data.loc[:,X],data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.7082164328657314)
Erinnern Sie sich an das Ergebnis, das wir mit den gewöhnlichen OHLC-Preisdaten erzielt haben.
scores[1]np.float64(0.7082164328657314)
Bevor wir zu dem Schluss kommen, dass wir das bestmögliche statistische Modell realisiert haben, müssen wir sicher sein, dass wir unsere Leistung nicht verbessern können, indem wir eine detailliertere Beschreibung des Marktverhaltens für unser Modell erstellen. Daher werden wir das Wachstum in den einzelnen Preisfeeds berechnen, und zusätzlich werden wir auch das Wachstum über verschiedene Preisfeeds hinweg berechnen. All diese Merkmale werden mit den ursprünglichen Merkmalen, mit denen wir begonnen haben, aggregiert, wodurch wir eine hochdimensionale und detaillierte Perspektive auf die EURUSD-Wechselkurse erhalten.
#Feature Engineering initial_features = data.loc[:,X] #Growth in individual Price Levels new_features = initial_features new_features['Delta Open'] = data['Open'].shift(HORIZON) - data['Open'] new_features['Delta High'] = data['High'].shift(HORIZON) - data['High'] new_features['Delta Low'] = data['Low'].shift(HORIZON) - data['Low'] new_features['Delta Close'] = data['Close'].shift(HORIZON) - data['Close'] #Growth across all Price levels new_features['Growth O-H'] = data['Open'].shift(HORIZON) - data['High'].shift(HORIZON) new_features['Growth O-L'] = data['Open'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth O-C'] = data['Open'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth H-L'] = data['High'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth H-C'] = data['High'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth L-C'] = data['Low'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features = new_features.iloc[HORIZON:,:] new_features.reset_index(drop=True,inplace=True) data = data.loc[HORIZON:,:] data.reset_index(inplace=True,drop=True) new_features
Unsere Intuition mag uns zu der Annahme verleitet haben, dass ein solcher Ansatz garantiert zu Verbesserungen führt; in dieser Artikelserie wollen wir jedoch den Zahlen eine Stimme geben und die Daten für sich selbst sprechen lassen. Es scheint, dass all unsere Bemühungen, diese neuen Merkmale zu kultivieren, umsonst waren, denn wir sind immer noch nicht in der Lage, ein identisches Modell zu übertreffen, das gezwungen war, weit weniger Daten zu beobachten.
np.mean(cross_val_score(get_model(),new_features,data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.688118007375461)
Für die Leser, die es noch einmal wissen müssen: Das ist der Punktestand, den wir zu übertreffen versuchen. Das Feature-Engineering ist ein notwendiger Schritt, um sicherzustellen, dass wir das bestmögliche Modell für die uns vorliegenden Daten verwenden. Es ist nicht garantiert, dass es Ihre Ergebnisse verbessert. Wie alle wiederkehrenden Leser inzwischen wissen sollten, gibt es bei der Optimierung keine Garantien.
scores[1]np.float64(0.6889680605037813)
In diesem Stadium haben wir das Feature-Engineering auf der Grundlage direkter Transformationen der rohen Preisdaten ausgeschöpft. Da diese zusätzlichen beschreibenden Merkmale keine Verbesserungen brachten, stellt sich als Nächstes die Frage, ob die im Datensatz enthaltenen Informationen nicht besser in einem anderen Koordinatensystem ausgedrückt werden sollten.
Einige Beziehungen sind in hochdimensionalen Umgebungen möglicherweise schwer zu erlernen. Könnte es daher sein, dass unser Modell diese Beziehungen in einer aussagekräftigeren niedrigdimensionalen Darstellung des ursprünglichen Datensatzes besser erlernen kann? Diese Frage wird durch eine Familie von statistischen Algorithmen beantwortet, die als Techniken des „Manifold Learning“ bekannt sind. In dieser Diskussion werden wir die unabhängige Komponentenanalyse (ICA) als Algorithmus für vielfältiges Lernen verwenden.
ICA ist eine leistungsstarke Erweiterung des beliebten Algorithmus der Hauptkomponentenanalyse (PCA). Zu den vielen Unterschieden gehört, dass die PCA schnell berechnet werden kann, weil sie auf geschlossenen Lösungen beruht, die in linearer Algebra ausgedrückt werden. ICA ist jedoch besser als ein Optimierungsproblem zu verstehen, für das es keine geschlossene Lösung gibt, sondern das iterativ angegangen werden muss.
ICA wurde in der Signalverarbeitungsbranche populär, wo man feststellte, dass sie in der Lage ist, Signale zu isolieren und zu trennen, die sich gegenseitig stören könnten. ICA ist in der Lage, jede beliebige Datenmatrix in maximal unabhängige und nicht-gaußsche Vektoren zu reduzieren, von denen man annimmt, dass sie die ursprünglichen Quellen des Signals sind, das die Beobachtungen erzeugt hat. Leser, die an einem tieferen Verständnis der ICA interessiert sind, finden hier einen gut geschriebenen Forschungsartikel zu diesem Thema.
#Manifold Learning from sklearn.decomposition import FastICA from sklearn.model_selection import RandomizedSearchCV
In der Regel sind hochdimensionale Datensätze eine Herausforderung für das Lernen aus ihnen. Vielfältige Lerntechniken wie FastICA sind durch die Überzeugung motiviert, dass, obwohl die Daten in einem hochdimensionalen Raum aufgezeichnet werden, die meisten Dimensionen nur ein Umgebungsraum sind und der tatsächliche Prozess, an dem wir interessiert sind, möglicherweise nur von einigen wenigen wichtigen Dimensionen dominiert wird. Daher werden wir unseren FastICA-Algorithmus iterativ unsere ursprünglichen Marktdaten mit 20 Spalten mit 1 bis 18 Spalten darstellen lassen und unsere Leistung jedes Mal aufzeichnen.
#Keep track of our performance manifold = [] #Search for a manifold where the objective is easier to learn res = [] for i in np.arange(new_features.shape[1]-2): enc = FastICA(n_components=i+1) new_manifold = pd.DataFrame(enc.fit_transform(new_features)) res.append(np.mean(cross_val_score(get_model(),new_manifold,data.iloc[:,-6],cv=tscv,scoring='accuracy'))) #Remember the score we are trying to outperform res.append(scores[1])
Wie wir sehen können, wurden unsere besten Ergebnisse im letzten Balken-Chart erzielt, was bedeutet, dass ein Modell, das nur OHLC-Daten verwendet, auch nach Anwendung von FastICA noch besser abgeschnitten hätte. An diesem Punkt können wir also sicher sein, dass wir ein optimales Modell haben, indem wir einfach die OHLC-Marktdaten verwenden, und wir können unser Modell nun mit Zuversicht in das ONNX-Format exportieren.
sns.barplot(res,color='black') plt.axhline(np.max(res),color='red',linestyle=':') plt.scatter(np.argmax(res),np.max(res),color='red')
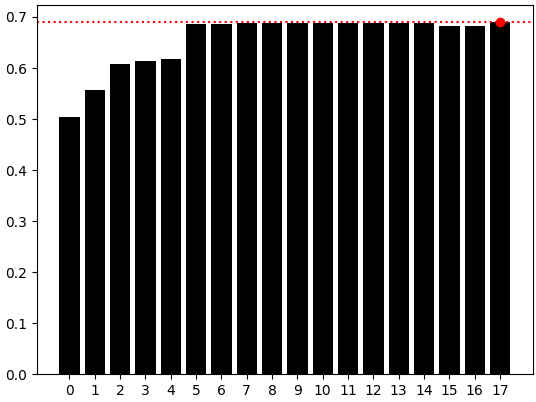
Abbildung 7: Das einfache Modell mit 4 Säulen (OHLC) war immer noch unser bestes Modell
Exportieren nach ONNX
Wir sind nun bereit, unser statistisches Modell in das Open Neural Network Exchange-Format (ONNX) zu exportieren. ONNX ermöglicht es uns, unser maschinelles Lernmodell effizient und operativ zu teilen und unser Modell plattformunabhängig auszudrücken. Deshalb laden wir die erforderlichen Bibliotheken.
import onnx from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn
Wir definieren die Eingabeform des Modells. Das Modell nimmt vier primäre Preisdaten auf, und diese Eingabetypen sind vom Typ float, den wir mit dem Vorlagentyp Float angeben.
initial_types = [('float_input',FloatTensorType([1,4]))]
Wir legen auch die Ausgabeform des Modells fest: Das Modell hat eine Ausgabe – das Ziel.
final_types = [('float_output',FloatTensorType([1,1]))]
Danach müssen wir eine Trennung der Eingänge erzwingen. Wir wollen unser Modell nicht für denselben Zeitraum trainieren, den wir im MetaTrader 5 backtesten wollen. Daher lassen wir die letzten fünf Jahre aus unserem Datensatz aus und behalten den Rest als Trainingsset.
train = data.iloc[:(-365*5),:] test = data.iloc[(-365*5):,:]
Der Random-Forest ist ein leistungsstarke und flexible statistische Modell, das nichtlineare Effekte in den Daten erlernen kann. Daher wird in dieser Diskussion das Random-Forest-Modell verwendet, obwohl es dem Leser freisteht, ein beliebiges Modell zu verwenden.
In diesem Beispiel verwenden wir die ATR, um unsere Stop-Losses entsprechend der Marktvolatilität zu setzen. Alles andere wird zunächst von unserem Modell erledigt.
from sklearn.ensemble import RandomForestRegressor
Dann passen wir das Modell auf unsere Trainingsdaten an.
model = RandomForestRegressor() model.fit(data.loc[:,['Open','High','Low','Close']],data.loc[:,'Label 2'])
Von dort aus bereiten wir die Umwandlung des Modells in seinen ONNX-Prototyp vor. Dieser Prototyp ist eine Zwischendatei, bevor wir unser ONNX-Modell auf der Festplatte speichern.
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12)Jetzt können wir die ONNX-Datei speichern.
onnx.save(onnx_proto,'EURUSD MidPoint RFR.onnx')
Prüfung unserer Annahmen
Jetzt können wir mit der Erstellung der Anwendung beginnen. Wir beginnen mit dem Laden der ONNX-Datei, die wir gerade auf die Festplatte geschrieben haben.
//+------------------------------------------------------------------+ //| EURUSD MidPoint.mq5 | //| Copyright 2025, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD MidPoint RFR.onnx" as const uchar onnx_proto[];
Und dann legen wir die technischen Indikatoren fest, die wir brauchen werden.
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int atr_handler; double atr_reading[];
Außerdem benötigen wir einige globale Variablen, um die aktuellen Geld- und Briefkurse zu verfolgen, sowie einige wichtige Funktionen für unser Modell, wie den Handler und die Ein- und Ausgänge des Modells.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double ask,bid; vectorf model_inputs,model_outputs; long model;
Dann laden wir die Handelsbibliothek, die uns bei der Verwaltung unserer Positionsein- und -ausgänge hilft.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Wenn unsere Anwendung zum ersten Mal geladen wird, laden wir die entsprechenden technischen Indikatoren und beginnen mit der Initialisierung unseres Modells anhand des ONNX-Exports, den wir zuvor erstellt haben. Wir legen die Eingabe- und Ausgabeformen fest und überprüfen schließlich, ob das Modell gültig ist, bevor wir die Kontrolle an die aufrufende Instanz zurückgeben.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our indicators atr_handler = iATR("EURUSD",PERIOD_D1,14); //--- Setup the ONNX model model = OnnxCreateFromBuffer(onnx_proto,ONNX_DATA_TYPE_FLOAT); //--- Define the model parameter shape ulong input_shape[] = {1,4}; ulong output_shape[] = {1, 1 }; OnnxSetInputShape(model,0,input_shape); OnnxSetOutputShape(model,0,output_shape); model_inputs = vectorf::Zeros(4); model_outputs = vectorf::Zeros( 1 ); if(model != INVALID_HANDLE) { return(INIT_SUCCEEDED); } //--- return(INIT_FAILED); }
Wenn unsere Anwendung nicht mehr genutzt wird, geben wir die Ressourcen frei, die für den technischen Indikator und das ONNX-Modell vorgesehen waren.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up memory we are no longer using when the application is off IndicatorRelease(atr_handler); OnnxRelease(model); }
Immer wenn wir neue Preisniveaus erhalten, aktualisieren wir unsere aktuelle Aufzeichnung der Zeit, und wenn sich eine neue Tageskerze gebildet hat, holen wir frische Kopien der aktuellen Preisniveaus und berechnen dann unseren imaginären Mittelpunkt entsprechend den aktuellen Preisen neu. Wir übergeben dem ONNX-Modell dann seine vier Eingaben und erhalten eine Vorhersage. Wenn unser Modell davon ausgeht, dass der Mittelwert in der Zukunft über dem aktuellen Wert liegt, kaufen wir, andernfalls verkaufen wir.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- When price levels change datetime current_time = iTime("EURUSD",PERIOD_D1,0); static datetime time_stamp; //--- Update the time if(current_time != time_stamp) { time_stamp = current_time; //--- Fetch indicator current readings CopyBuffer(atr_handler,0,0,1,atr_reading); double open = iOpen("EURUSD",PERIOD_D1,0); double close = iClose("EURUSD",PERIOD_D1,0); double high = iHigh("EURUSD",PERIOD_D1,0); double low = iLow("EURUSD",PERIOD_D1,0); double o_h_mid = ((open + high)/2); model_inputs[0] = (float) open; model_inputs[1] = (float) high; model_inputs[2] = (float) low; model_inputs[3] = (float) close; ask = SymbolInfoDouble("EURUSD",SYMBOL_ASK); bid = SymbolInfoDouble("EURUSD",SYMBOL_BID); //--- If we have no open positions if(PositionsTotal() == 0) { if(!(OnnxRun(model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_outputs))) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } else { Comment("Forecast: ",model_outputs); //--- Trading rules if((model_outputs[1] > o_h_mid)) { //--- Buy signal Trade.Buy(0.01,"EURUSD",ask,ask-(atr_reading[0] * 2),ask+(atr_reading[0] * 2),""); } else if((model_outputs[1] < o_h_mid)) { //--- Sell signal Trade.Sell(0.01,"EURUSD",bid,bid+(atr_reading[0] * 2),bid-(atr_reading[0] * 2),""); } } } } } //+------------------------------------------------------------------+
Wir sind nun bereit, den fünfjährigen Backtest unseres Modells von Februar 2020 bis zum Zeitpunkt der Erstellung dieses Berichts im Jahr 2025 durchzuführen.

Abbildung 8: Auswahl der Backtest-Tage für unseren 5-Jahres-Test unserer neuen Annahmen
Wir haben zufällige Verzögerungseinstellungen gewählt, um eine realistische Emulation von Netzwerkverzögerungen und anderen Latenzen zu erhalten, die beim Live-Handel auftreten.

Abbildung 9: Stellen Sie sicher, dass Sie zufällige Verzögerungseinstellungen wählen, um eine robuste Emulation der realen Marktbedingungen zu erhalten.
Wenn der Test abgeschlossen ist, können wir die Kapitalkurve beobachten, die durch den in diesem Artikel vorgeschlagenen Ansatz entsteht. Wie Sie sehen, ergibt sich trotz des möglichst einfachen Modells ein dominanter Aufwärtstrend in der Kapitalkurve über fünf Jahre hinweg. Er verwendet alle Signale, was für ein so einfaches Modell erstaunlich ist und zeigt, dass selbstüberwachtes Lernen durchaus seine Vorteile hat.

Abbildung 10: Die neue Kapitalkurve, die sich aus unseren neuen Annahmen ergibt
Wenn wir uns die detaillierten Statistiken über die Leistung des Modells ansehen, sehen wir außerdem einen gesunden Gewinnfaktor und eine gesunde erwartete Auszahlung. Ein Wert größer als eins bedeutet, dass das Modell über fünf Jahre hinweg einen Gewinn erzielt hat. Es ist jedoch enttäuschend zu sehen, dass das Modell erneut eine Tendenz zu Kaufpositionen aufweist: Das Modell ging über fünf Jahre fast dreimal so viele Kaufpositionen ein wie Verkaufspositionen. Dies zeigt, dass es noch Schwachstellen und blinde Flecken gibt, die wir noch nicht abgedeckt haben. Obwohl das Random-Forest-Modell in der Lage sein sollte, starke nichtlineare Beziehungen zu erlernen, ist es interessant festzustellen, dass in dem Modell immer noch Verzerrungen auftreten.

Abbildung 11: Detaillierte Statistiken über die Leistung unserer neuen statistischen Strategie
Schlussfolgerung
Zusammenfassend hat dieser Artikel gezeigt, wie statistische Signale höherer Ordnung auf selbstüberwachte Weise realisiert und in einem algorithmischen Handelssystem angewendet werden können. Indem wir uns nur auf die von unserem Broker erhaltenen Daten verlassen, können wir neue Signale erzeugen, die unsere statistischen Modelle zuverlässiger lernen können. Selbst ein einfaches Modell, das mit einem selbstüberwachten Paradigma erstellt wurde, scheint robust genug zu sein, um fünf Jahre lang unbeaufsichtigt zu bleiben und immer noch solide Leistungen zu erbringen. Darüber hinaus hat der Artikel dem Leser gezeigt, wie er nach mehr Inputs suchen kann, um die Genauigkeit zu verbessern – und nicht davon auszugehen, dass mehr Daten automatisch zu besseren Ergebnissen führen, sondern stattdessen empirisch zu testen, ob mehr Daten wirklich helfen. Wie wir in diesem Artikel gesehen haben, können sogar die einfachsten Dinge als starke Handelssignale genutzt werden.
Wie wir im Eröffnungsartikel dieser Artikelserie ausführlich erörtert haben, sind die Leistungskennzahlen, die wir zur Kritik an statistischen Modellen verwenden, nicht unbedingt mit unseren Zielen als Gemeinschaft der algorithmischen Händler vereinbar. Daher sollte der Leser beachten, dass die statistische Genauigkeit des Modells von 68 % in unserer Diskussion nur 52 % Rentabilität ergibt.
| Dateiname | Beschreibung der Datei |
|---|---|
| Selbstüberwachtes Lernen: Generating Targets From OHLC Data.ipynb | Das Jupyter-Notebook, das wir zur Durchführung unserer statistischen Analyse der historischen EURUSD-Marktdaten verwendet haben. |
| EURUSD MidPoint.mq5 | Die Handelsanwendung, die wir entwickelt haben, übernimmt ihre Handelssignale auf der Grundlage selbstüberwachter Signale, die sie gelernt hat. |
| Fetch Data Mid Points.mq5 | Das MQL5-Skript, das wir zum Abrufen und Bearbeiten unserer historischen EURUSD-Marktdaten verwendet haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20514
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.