
機械学習の限界を克服する(第9回):自己教師あり学習を用いた金融における相関ベース特徴学習

多くの課題が存在する中で、機械学習を用いた取引アプリケーションをコミュニティの誰にとっても安全に展開するのは本質的に容易ではありません。本連載では、標準的な機械学習文献では十分に扱われていない、より検出しにくい誤差要因について読者に注意を促すことを目的としています。その中でも特に重要なのが、モデルの基礎的な仮定が破られた際に発生する、表面化しない失敗です。
すべての統計モデルは、手元のデータおよびそのデータを生成したプロセスについて一定の仮定を置いています。モデルが持つ仮定が少ないほど、そのモデルはより柔軟であり、すなわち「表現力が高い」と言えます。これは、仮定が少ないモデルほど多様な複雑な関係を学習できるためです。この時点で、一部の読者は「仮定を減らすほどモデルが強力になるのであれば、いっそのこと仮定を一切持たないモデルを設計できないのか」と考えるかもしれません。しかし残念ながら、データに対して完全に無仮定の統計モデルを構築することは不可能です。機械学習モデルを成立させるために必要な最も重要な仮定の一つは、入力データと予測対象との間に何らかの関係が存在するという仮定です。
これらの仮定は、私たちが対象とするあらゆる金融市場において、その予測可能性の有無を支える基盤となっています。これらの仮定が破られた場合でも、その影響はすぐには表面化しません。明確な警告が出ることもなく、モデルが限界に達していても検出できないということが、本質的な問題です。
学術的な文献では、モデルの仮定が成立しているかどうかを検証するための統計的検定が提供されています。モデルの仮定が問題設定とどの程度整合しているかを理解することは重要であり、それによって選択したモデルがタスクに対して適切かどうかを判断できます。しかし、これらの標準的な統計手法には、実務上さらなる困難が伴います。要するに、従来の学術的手法は実行や解釈が難しいだけでなく、誤った結論を導く可能性もあり、本来適切でないモデルを適切であると判断してしまうリスクがあります。その結果、実務者は未検出のリスクにさらされることになります。
したがって、本記事では、現実の問題においてモデルの仮定が破られていないことを確認するための、より実務的なアプローチを提案します。すべての統計モデル(単純な線形モデルから現代のディープニューラルネットワークに至るまで)に共通する一つの仮定に着目します。それは、予測対象は観測データの関数であるという仮定です。与えられた観測データの集合をそのまま扱うのではなく、それをより学習しやすい可能性のある新しい候補ターゲットを生成するための原材料として扱うことで、より高い性能が得られることを示します。このパラダイムは、自己教師あり学習として知られています。
入力データから生成されるこれらの新しいターゲットは、その定義上、目的変数の関数であることが保証されています。この手法は一見すると不要に見えるかもしれませんが、実際には統計モデルの最大の盲点の一つを補強し、より頑健で信頼性の高い数値駆動型取引アプリケーションの構築に寄与します。それでは始めましょう。
MetaTrader 5ターミナルからのデータ取得
この議論では、入力としてOpen、High、Low、Close (OHLC)の価格データを用い、それらを統計モデルが学習可能な新たな教師信号の原材料として扱います。そのため再現性の観点から、すべてのデータ処理はMQL5内で実行することが望ましいと考えられます。機械学習においては、目的変数である将来価格は観測値(OHLC)の関数であると仮定されます。しかしこの仮定は標準的なポートフォリオ理論とは整合しません。なぜなら、将来リターンは過去価格そのものではなく、投資家の期待によって決定されると考えられているためです。この考え方に基づき、価格水準の間に位置する新たな中間点を計算することにします。そのために、MQL5上で単純な計算を用い、各OHLCの価格ペアの間に存在する中間点を計算します。//+------------------------------------------------------------------+ //| Fetch Data Mid Points | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Mid Points.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- OHLC Mid Points "O-H M", "O-L M", "O-C M", "H-L M", "H-C M", "L-C M" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- OHLC Mid Points (iOpen(_Symbol,PERIOD_CURRENT,i) + iHigh(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iLow(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2 ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Pythonでの市場データ分析
まずは、標準的なPythonライブラリをインポートすることから始めましょう。
#Load our libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
次に、MQL5スクリプトを使用して生成したCSVファイルを読み込みます。
#Read in the data
data = pd.read_csv('./EURUSD Mid Points.csv')
data
図1:MQL5スクリプトで計算した市場データの可視化
私たちは、算術に関する理解を用いて、MQL5スクリプト内で中間点を計算しました。しかし、意図した通りに実装できていることを確認するために、正確性の検証をおこなう必要があります。図2に示すように、ブローカーから取得したEURUSDの過去の高値および安値のレートをプロットしています。さらに、MQL5で計算した破線の仮想的な中間点が、高値と安値の間に位置していることが確認でき、これは我々の想定通りの結果です。
#Examine correctness plt.plot(data.loc[0:10,'High'],color='red') plt.plot(data.loc[0:10,'H-L M'],color='black',linestyle=':') plt.plot(data.loc[0:10,'Low'],color='blue') plt.grid() plt.legend(['High','H-L Mid','Low']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The High-Low Mid Point of EURUSD Exchange Rates')
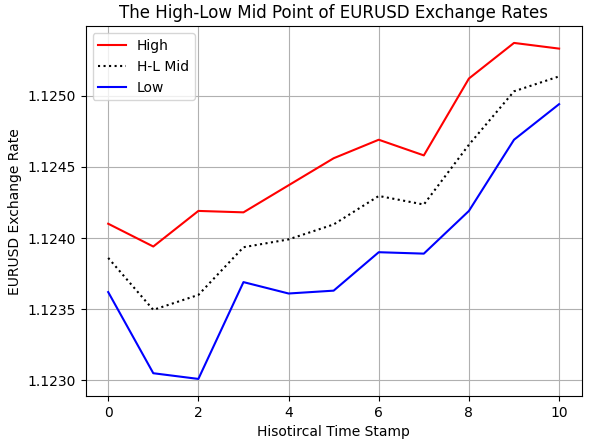
図2:EUR/USDの高値と安値の中間点の可視化
始値と終値の中間点も正しく計算されていることが、以下の図からわかります。
#Examine correctness plt.plot(data.loc[70:90,'Open'],color='red') plt.plot(data.loc[70:90,'O-C M'],color='black',linestyle=':') plt.plot(data.loc[70:90,'Close'],color='blue') plt.grid() plt.legend(['Open','O-C Mid','Close']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The Open-Close Mid Point of EURUSD Exchange Rates')
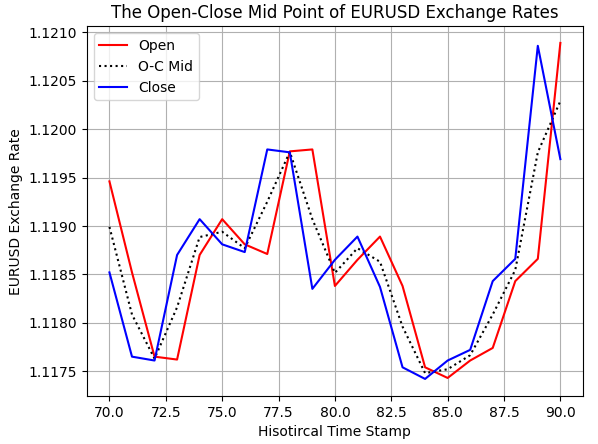
図3:始値と終値の中間点の可視化
次に、どの程度先の未来を予測したいのかを明確にします。
#Forecast horizon HORIZON = 2
通常、統計学習に関する標準的な学術文献では、この時点で読者は入力とターゲットを分離することが求められます。しかし、これこそが本記事が読者に提示しようとする解決策の本質的な違いです。固定されたターゲットを前提として作業するのではなく、手元にある観測値から可能な限り多くのターゲットを生成することにします。
#Candidate targets candidate_y = data.iloc[:,4:11].columns candidate_x = data.iloc[:,1:5].columns
この演習では、従来のターゲットである将来価格をそのまま維持し、さらに加えて、従来のターゲットよりも学習が容易であると考えられる他の代理ターゲットを導入します。
candidate_y
Index(['Close', 'O-H M', 'O-L M', 'O-C M', 'H-L M', 'H-C M', 'L-C M'], dtype='object')
元のデータセットに、各候補ターゲットの将来値を格納するための列を作成します。
data['Label 1'] = 0 data['Label 2'] = 0 data['Label 3'] = 0 data['Label 4'] = 0 data['Label 5'] = 0 data['Label 6'] = 0 data['Label 7'] = 0
最後に、評価したい各ターゲットに対して、バイナリターゲットを表す追加の列を作成します。
data['Target 1'] = 0 data['Target 2'] = 0 data['Target 3'] = 0 data['Target 4'] = 0 data['Target 5'] = 0 data['Target 6'] = 0 data['Target 7'] = 0
次に、データセットにラベルを付け、ターゲットを入力する必要があります。この単純なループは、以前に定義した0の列に、ターゲットの将来の値とその対応するバイナリ表現を繰り返し埋めていきます。
#Label the dataset for i in np.arange(7): #Add labels to the data label = 'Label ' + str(i+1) data[label] = data[candidate_y[i]].shift(-HORIZON) #Define the labels as binary targets target = 'Target ' + str(i+1) data[target] = 0 #Add the target data.loc[data[label] > data[candidate_y[i]],target] = 1 #Drop the last missing forecast horizon period data = data.iloc[:-HORIZON,:] data
次に、手持ちの観測データに基づいて、モデルにとってどちらのターゲットが学習しやすいかを判断するために必要な統計的学習ライブラリを読み込みます。
from sklearn.model_selection import TimeSeriesSplit,cross_val_score from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
比較の厳密性を保つため、各ターゲットに対して同じモデルを使用します。
def get_model(): return(LinearDiscriminantAnalysis())
次に、時系列クロスバリデーションオブジェクトを定義します。これにより、モデルのクロスバリデーション時にランダムなシャッフルがおこなわれないことが保証されます。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)各ターゲットごとの精度を記録するための配列を準備します。
scores = []
同じ入力を与えたまま、同一のモデルをクロスバリデーションで評価します。ただし、モデルが学習する対象(ターゲット)だけを変更します。つまり、観測データから何を予測するかだけを変えます。
#Classical Target scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-7],cv=tscv,scoring='accuracy'))) #Modern Targets scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-6],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-5],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-4],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-3],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-2],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-1],cv=tscv,scoring='accuracy')))
これにより、読者は私たちが提案するアプローチの実用的な価値を明確に理解できます。観測データから独自にターゲットを設計することで、従来のように「将来価格」という固定されたターゲットに制約されていた場合には到達できなかった、新たな誤差水準に到達することが可能になります。
scores
[np.float64(0.503006012024048),
np.float64(0.7082164328657314),
np.float64(0.6941883767535071),
np.float64(0.6328657314629258),
np.float64(0.6501002004008015),
np.float64(0.5739478957915832),
np.float64(0.5739478957915831)]
提案手法の結果を可視化すると、おこなった改善が一目瞭然となります。モデルは、価格そのものを予測しようとする場合よりも、観測データから構築したそれ以外のすべてのターゲットの方が、より容易に学習できることを示しました。このことから、これらの利得は、それを得るために必要となる追加の労力に十分見合うものであると考えられます。
sns.barplot(scores,color='black') plt.xticks([0,1,2,3,4,5,6],candidate_y) plt.axhline(scores[0],linestyle=':',color='red') plt.ylabel('Accuracy out of 100%') plt.xlabel('Selected Target') plt.title('EURUSD Forecasting Accuracy is a Function of The Target')
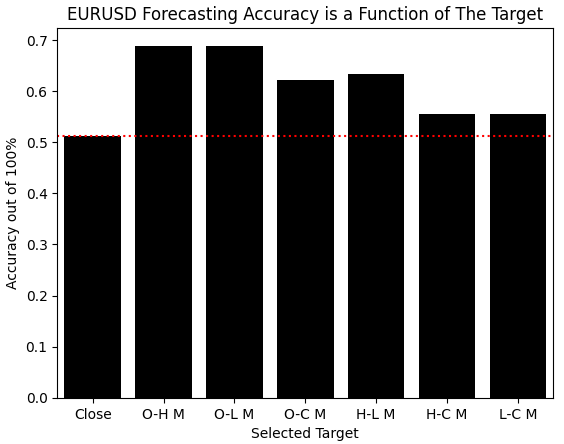
図4:目標を変更することで実現した変化は目覚ましく、さらなる検討に値する
数値ベースのアルゴリズムトレーダーとして、データセットから意味のある数値を慎重に解釈することで、そのデータについて多くの知見を迅速に得ることができます。この場合、「リワードハッキング」に注意する必要があります。そのため、各ターゲットに対して「常に最頻出ラベルを予測し続けた場合」にモデルが到達し得る最大スコアを把握しておく必要があります。
各ターゲットは0または1のいずれかであるため、各ターゲットの平均値を計算することにより、そのターゲットにおける最頻値と、その支配比率を知ることができます。両方の値が同程度に出現している場合、その平均値は0.5になります。0.5を下回る場合は0の方が多く存在していることを意味し、逆に0.5を上回る場合は1の方が多いことを意味します。平均値が1になるのはすべての値が1の場合のみであり、同様に平均値が0になるのは全ての値が0の場合のみです。
したがって、ターゲット候補は適切に構造化されており、いずれも平均値が0.5から大きく逸脱していないことから、従来モデルに対して観測された改善を十分に説明できるような極端な偏りは存在していないことが確認できます。
data.iloc[:,-7:].mean()| ターゲット | 平均 |
|---|---|
| ターゲット1 | 0.502836 |
| ターゲット2 | 0.507174 |
| ターゲット3 | 0.487154 |
| ターゲット4 | 0.494161 |
| ターゲット5 | 0.500167 |
| ターゲット6 | 0.474808 |
| ターゲット7 | 0.522856 |
従来の価格水準よりも予測しやすいターゲットを特定したので、次にその新しいターゲットと古典的なターゲットがどのような関係にあるのかを確認します。これは重要なステップです。まず、単純な線形モデルをインポートします。
from sklearn.linear_model import LinearRegression
統計的ツールは推論のためにも洞察のためにも使用できます。通常、これらのツールを予測目的で使用しますが、今回は予測ではなく、データ構造に対する洞察を得る目的で使用します。
explanation = LinearRegression()
一見すると、2つのターゲットに対して線形モデルを当てはめることは根拠がないように見えるかもしれません。しかし、これは完全に妥当な手法です。
explanation.fit(data[['Label 1']],data['Label 2'])
この線形モデルが学習した係数を見ることで、2つのターゲットが同じ方向に動くのか、それとも逆方向に動くのかを即座に判断できます。今回の線形モデルは1に非常に近い係数を推定しており、新しく生成したターゲットは古典的ターゲットとほぼ完全に一致して動いていることを示しています。したがって、新しいターゲットを予測することは古典的ターゲットを予測することと実質的に同等であり、さらに新しく設計したターゲットの方が学習コストが低いという利点があります。
explanation.coef_
array([0.99533718])
あるいは読者は、生成した候補ターゲットの相関行列を計算するだけでも、同じ結論に到達することができます。
data.iloc[:,-14:-7].corr()
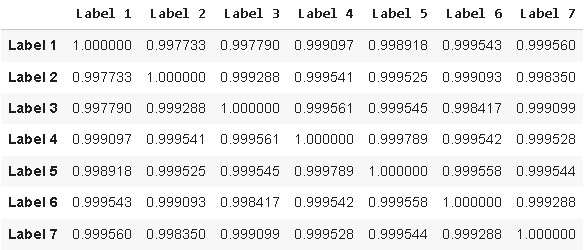
図5:設計した候補ターゲットと従来ターゲットとの相関の可視化
最後に、従来ターゲットと新しくモデリング対象としたターゲットをプロットすることで、この関係性を視覚的にも確認できます。これをおこなうと、線形モデルおよび相関行列から得られた洞察によって既に確認していた内容が再現されます。すなわち、2つのターゲットは明確かつ強い相関関係を持って推移していることが分かります。
plt.plot(data.iloc[0:200,-14],color='black') plt.plot(data.iloc[0:200,-13],linestyle=':',color='red') plt.grid() plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Historical Time') plt.title('Visualizing Our Classical & Candidate Target') plt.legend(['Classical Target','Candidate Target'])
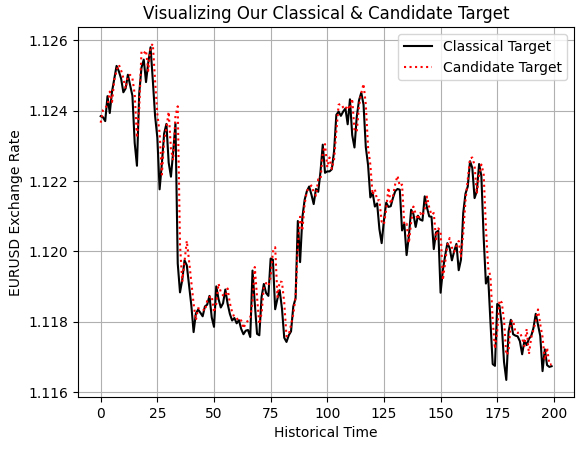
図6:設計した候補ターゲットと古典的なターゲットとの関係の可視化
ここまででどのターゲットを最もよく学習できているかを特定したので、次に、これまで生成してきたすべての入力データを用いて、そのターゲットのモデリングをおこないます。
X = ['Open','High','Low','Close','O-H M','O-C M', 'H-L M', 'H-C M', 'L-C M'] y = ['Target 2']
驚いたことに、追加の入力特徴量をモデルに与えたにもかかわらず、性能はまったく変化しませんでした。
np.mean(cross_val_score(get_model(),data.loc[:,X],data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.7082164328657314)
従来のOHLC価格データのみを使用して得ていたスコアを思い出してください。
scores[1]np.float64(0.7082164328657314)
これ以上モデルの性能を改善できないと結論づける前に、市場の振る舞いをより詳細に表現することで性能を改善できないかどうかを確認する必要があります。そのため、各価格系列における成長率を計算し、さらに異なる価格系列間での成長も計算します。これらの特徴量を、これまで使用してきた元の特徴量セットに統合することで、EUR/USDの為替レートをより高次元かつ詳細に表現します。
#Feature Engineering initial_features = data.loc[:,X] #Growth in individual Price Levels new_features = initial_features new_features['Delta Open'] = data['Open'].shift(HORIZON) - data['Open'] new_features['Delta High'] = data['High'].shift(HORIZON) - data['High'] new_features['Delta Low'] = data['Low'].shift(HORIZON) - data['Low'] new_features['Delta Close'] = data['Close'].shift(HORIZON) - data['Close'] #Growth across all Price levels new_features['Growth O-H'] = data['Open'].shift(HORIZON) - data['High'].shift(HORIZON) new_features['Growth O-L'] = data['Open'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth O-C'] = data['Open'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth H-L'] = data['High'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth H-C'] = data['High'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth L-C'] = data['Low'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features = new_features.iloc[HORIZON:,:] new_features.reset_index(drop=True,inplace=True) data = data.loc[HORIZON:,:] data.reset_index(inplace=True,drop=True) new_features
直感的には、このようなアプローチで改善が見込めると思うかもしれません。しかし本連載では、数値に基づいて判断し、データ自体の挙動を明らかにすることを目的としています。その結果として、新たに構築した特徴量に費やしたすべての努力が無駄であった可能性が示唆されます。というのも、依然として、より少ない情報しか観測していない同一のモデルを上回ることができていないためです。
np.mean(cross_val_score(get_model(),new_features,data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.688118007375461)
復習として、私たちが上回ろうとしているスコアは以下です。特徴量エンジニアリングは、与えられたデータに対して最良のモデルを構築するために必要なステップです。しかし、それが必ずしも性能改善を保証するわけではありません。これまでの読者であれば既に理解している通り、最適化の問題において保証は存在しません。
scores[1]np.float64(0.6889680605037813)
この段階で、生の価格フィードに対する直接的な変換に基づく特徴量エンジニアリングをすべて使い尽くしました。これらの追加の記述的特徴量が改善をもたらさなかった以上、次に問うべきは、データセットに含まれる情報が全く別の座標系で表現された方が適切ではないかという点です。
高次元空間では学習が困難な関係性が存在する可能性があります。したがって、元のデータセットをより意味のある低次元表現に変換することで、モデルがより良く関係性を学習できる可能性はあるのでしょうか。この問いに答えるのが、多様体学習と呼ばれる統計アルゴリズム群です。この議論では、その中でも独立成分分析(ICA)を手法として用います。
ICAは、主成分分析(PCA)の強力な拡張として知られています。多くの違いがありますが、PCAは線形代数に基づく閉形式解を持つため、高速に計算することができます。一方でICAは閉形式解を持たない最適化問題として捉えられ、反復的に解を探索する必要があります。
ICAは信号処理分野で発展した手法であり、互いに干渉している信号を分離および抽出する能力があることで知られています。ICAは、与えられたデータ行列を、観測データを生成した元の信号源であると考えられる、最大限独立かつ非ガウスなベクトルへと分解する手法です。ICAについてより深く理解したい読者は、こちらで関連する優れた研究記事を確認できます。
#Manifold Learning from sklearn.decomposition import FastICA from sklearn.model_selection import RandomizedSearchCV
一般的に、高次元データセットは学習が困難であることがあります。FastICAのような多様体学習手法は、「データは高次元空間に記録されているものの、その多くの次元は単なる周囲の空間に過ぎず、我々が関心を持つ実際の生成過程は、ごく少数の重要な次元によって支配されている可能性がある」という考えに基づいています。したがって、本実験ではFastICAアルゴリズムを用いて、元の20列の市場データを1次元から最大18次元まで段階的に表現し直し、その都度性能を記録します。
#Keep track of our performance manifold = [] #Search for a manifold where the objective is easier to learn res = [] for i in np.arange(new_features.shape[1]-2): enc = FastICA(n_components=i+1) new_manifold = pd.DataFrame(enc.fit_transform(new_features)) res.append(np.mean(cross_val_score(get_model(),new_manifold,data.iloc[:,-6],cv=tscv,scoring='accuracy'))) #Remember the score we are trying to outperform res.append(scores[1])
観測結果から確認できるように、最良の結果は最後の棒グラフにおいて得られました。これは、FastICAを適用した後であっても、OHLCデータのみを使用したモデルの方が依然として私たちのモデルを上回っていたことを示しています。したがって、現時点では、OHLC市場データのみを使用するだけで最適なモデルが得られていると確信することができます。また、これによりモデルをONNX形式へ自信を持ってエクスポートすることができます。
sns.barplot(res,color='black') plt.axhline(np.max(res),color='red',linestyle=':') plt.scatter(np.argmax(res),np.max(res),color='red')
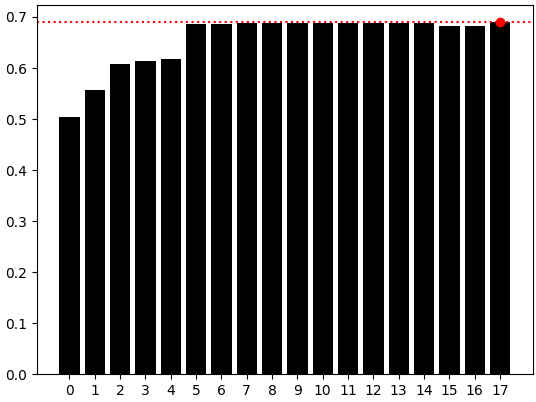
図7:4列(OHLC)を用いたシンプルなモデルが、依然として最も優れた性能を発揮したモデルであった
ONNXへのエクスポート
これで、統計モデルをONNX (Open Neural Network Exchange)形式にエクスポートする準備が整いました。ONNXを使用することで、機械学習モデルを効率的かつ運用的に共有し、プラットフォームに依存しない形でモデルを表現することが可能になります。必要なライブラリを読み込みます。
import onnx from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn
モデルの入力形状を定義します。 このモデルは4つの主要な価格フィードを受け取ります。これらの入力はfloat型であり、floatテンプレートタイプを使用して指定します。
initial_types = [('float_input',FloatTensorType([1,4]))]
また、モデルの出力形状も指定します。モデルには1つの出力、つまりターゲットがあります。
final_types = [('float_output',FloatTensorType([1,1]))]
その後、入力の分離を明示的におこなう必要があります。MetaTrader 5でバックテストをおこなう期間と同じ期間でモデルを学習することは避ける必要があるため、直近5年間をテストデータとして除外し、それ以外を学習データとして使用します。
train = data.iloc[:(-365*5),:] test = data.iloc[(-365*5):,:]
ランダムフォレストは非線形効果をデータから学習できる強力かつ柔軟な統計モデルです。そのため本記事ではランダムフォレストモデルを使用しますが、読者は任意のモデルを選択することも可能です。
この例では、ATRを用いて市場ボラティリティに基づいたストップロス設定をおこないます。それ以外の処理はすべてモデル側に委ねます。
from sklearn.ensemble import RandomForestRegressor
その後、学習データを用いてモデルを学習させます。
model = RandomForestRegressor() model.fit(data.loc[:,['Open','High','Low','Close']],data.loc[:,'Label 2'])
そこから、モデルをONNX形式へ変換する準備をおこないます。このプロトタイプは、ONNXモデルをディスクへ保存する前段階となる中間表現です。
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12)これでONNXファイルを保存する準備が整います。
onnx.save(onnx_proto,'EURUSD MidPoint RFR.onnx')
仮説の検証
これでアプリケーションの構築を開始する準備が整いました。まず、先ほどディスクに書き込んだONNXファイルを読み込みます。
//+------------------------------------------------------------------+ //| EURUSD MidPoint.mq5 | //| Copyright 2025, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD MidPoint RFR.onnx" as const uchar onnx_proto[];
次に、必要なテクニカル指標を定義します。
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int atr_handler; double atr_reading[];
また、現在のBid価格およびAsk価格を追跡するためのグローバル変数もいくつか必要になります。加えて、ハンドラやモデルの入出力など、モデル処理に必要な重要な関数もいくつか用意する必要があります。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double ask,bid; vectorf model_inputs,model_outputs; long model;
次に、ポジションのエントリーとエグジットを管理するために、Tradeライブラリを読み込みます。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
アプリケーションが初めて起動したとき、必要なテクニカル指標を読み込みし、先ほどエクスポートしたONNXモデルの初期化をおこないます。入力と出力の形状を設定し、最終的にモデルが正しく有効であることを確認したうえで、制御を呼び出し元へ返します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our indicators atr_handler = iATR("EURUSD",PERIOD_D1,14); //--- Setup the ONNX model model = OnnxCreateFromBuffer(onnx_proto,ONNX_DATA_TYPE_FLOAT); //--- Define the model parameter shape ulong input_shape[] = {1,4}; ulong output_shape[] = {1, 1 }; OnnxSetInputShape(model,0,input_shape); OnnxSetOutputShape(model,0,output_shape); model_inputs = vectorf::Zeros(4); model_outputs = vectorf::Zeros( 1 ); if(model != INVALID_HANDLE) { return(INIT_SUCCEEDED); } //--- return(INIT_FAILED); }
アプリケーションが使用されなくなった時点で、テクニカル指標とONNXモデルに割り当てられていたリソースを解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up memory we are no longer using when the application is off IndicatorRelease(atr_handler); OnnxRelease(model); }
新しい価格水準を受信するたびに、現在の時刻の記録を更新します。また、新しい日足が形成された場合には、最新の価格水準を取得し直し、その時点の価格に基づいて仮想的な中間点を再計算します。その後、ONNXモデルに4つの入力を渡し、予測結果を取得します。モデルが「将来の中間点が現在より高くなる」と予測した場合はロングポジションを開き、それ以外の場合はショートポジションを開きます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- When price levels change datetime current_time = iTime("EURUSD",PERIOD_D1,0); static datetime time_stamp; //--- Update the time if(current_time != time_stamp) { time_stamp = current_time; //--- Fetch indicator current readings CopyBuffer(atr_handler,0,0,1,atr_reading); double open = iOpen("EURUSD",PERIOD_D1,0); double close = iClose("EURUSD",PERIOD_D1,0); double high = iHigh("EURUSD",PERIOD_D1,0); double low = iLow("EURUSD",PERIOD_D1,0); double o_h_mid = ((open + high)/2); model_inputs[0] = (float) open; model_inputs[1] = (float) high; model_inputs[2] = (float) low; model_inputs[3] = (float) close; ask = SymbolInfoDouble("EURUSD",SYMBOL_ASK); bid = SymbolInfoDouble("EURUSD",SYMBOL_BID); //--- If we have no open positions if(PositionsTotal() == 0) { if(!(OnnxRun(model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_outputs))) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } else { Comment("Forecast: ",model_outputs); //--- Trading rules if((model_outputs[1] > o_h_mid)) { //--- Buy signal Trade.Buy(0.01,"EURUSD",ask,ask-(atr_reading[0] * 2),ask+(atr_reading[0] * 2),""); } else if((model_outputs[1] < o_h_mid)) { //--- Sell signal Trade.Sell(0.01,"EURUSD",bid,bid+(atr_reading[0] * 2),bid-(atr_reading[0] * 2),""); } } } } } //+------------------------------------------------------------------+
2020年2月から執筆時点の2025年までの5年間にわたるモデルのバックテストを開始する準備が整いました。

図8:新しい仮説に基づく5年間テストのためのバックテスト期間の選択
現実の取引において実際に発生するネットワーク遅延やその他のレイテンシを現実的に再現するため、ランダム遅延設定を有効にします。

図9:現実の市場環境をより堅牢にエミュレートするためにランダム遅延設定を必ず有効化する
テストが完了すると、本記事で提案したアプローチによって生成されたエクイティカーブを観察できます。ご覧のとおり、このモデルは非常に単純であるにもかかわらず、5年間の取引においてエクイティカーブにおいて優勢な上昇トレンドを示しています。すべてのシグナルを使用している点は、このような単純なモデルとしては驚くべき結果であり、自己教師あり学習には一定の有効性があることを示しています。

図10:新しい仮定によって生成されたエクイティカーブ
さらに、モデルのパフォーマンス詳細統計を確認すると、健全なプロフィットファクターと健全な期待値(期待利益)を確認できます。これらの値が1を上回っていることは、5年間の運用においてモデルが利益を上げたことを示しています。しかし一方で、取引のロングバイアスが再び見られる点は残念です。モデルは5年間でショートの約3倍のロングポジションを取っており、依然として未解決の弱点や盲点が存在することを示しています。ランダムフォレストモデルは強力な非線形関係を学習できるはずですが、それでもなおバイアスが残っている点は興味深い結果です。

図11:新しい統計戦略のパフォーマンス詳細統計
結論
本記事では、高次の統計的シグナルが自己教師ありの形で実現可能であり、それをアルゴリズム取引の枠組みに適用できることを示しました。ブローカーから受信したデータのみに依存することで、統計モデルがより確実に学習できる新しいシグナルを生成することができます。自己教師ありパラダイムに基づいて構築された単純なモデルであっても、5年間にわたり非監督的に運用されながらも安定したパフォーマンスを維持できるほど頑健であるように見えます。さらに本記事では、精度向上のために利用可能なより多くの入力を探索する方法についても示しており、データを増やせば自動的に結果が改善すると仮定するのではなく、それが本当に改善につながるかどうかを経験的に検証することの重要性を強調しています。本記事で見てきたように、最小限の要素であっても強力な売買シグナルとして利用することが可能です。
最後に、本連載の冒頭記事で広く議論した通り、統計モデルを評価するために用いるパフォーマンス指標は、アルゴリズムトレーダーとしての目的と必ずしも互換的ではありません。そのため、読者は本モデルの統計的精度が68%であったとしても、本議論における実際の収益性は52%にとどまったことに注意する必要があります。
| ファイル名 | ファイルの説明 |
|---|---|
| Self Supervised Learning:Generating Targets From OHLC Data.ipynb | EURUSDの過去市場データに対して統計分析をおこなうために使用したJupyter Notebook |
| EURUSD MidPoint.mq5 | 自己教師ありシグナルに基づいて取引をおこなうために構築した取引アプリケーション |
| Fetch Data Mid Points.mq5 | URUSDの過去市場データを取得し、中間点を計算および加工するために使用したMQL5スクリプト |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20514
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索