
Нейросети в трейдинге: Пространственно-временная модель состояния для анализа финансовых данных (Окончание)

Введение
Работа по адаптации идей фреймворка E-STMFlow постепенно приблизилась к той фазе, когда фундамент уже заложен, а механизмы синхронизированы. За две предыдущие статьи мы проделали путь, сравнимый с аккуратным возведением каркаса сложного торгового инструмента. Сначала разобрались с природой событийного подхода, затем воссоздали ключевые блоки архитектуры. Теперь, готовясь к заключительному этапу, важно на мгновение остановиться и вновь погрузиться в общий контекст, чтобы оценка финальных результатов была максимально осмысленной.
За идеей E-STMFlow стоит стремление работать с потоком данных так, как он возникает в природе. В классическом компьютерном зрении это поток событий с матрицы event-камеры, где каждое минимальное изменение яркости рождает отдельный сигнал. В торговом мире роль таких событий играют тики — живые микроизменения рынка, которые рождаются без равномерного ритма, без заранее заданного темпа и часто без какой-либо предсказуемости. Рынок дышит так же неровно, как поток событий в физической системе. Иногда быстро, иногда медленно. Иногда с резкими всплесками, иногда почти незаметно. Именно поэтому событийная архитектура, созданная для анализа динамики, оказалась удивительно созвучной природе рыночных данных.
Фреймворк E-STMFlow построен вокруг представления состояния, которое обновляется каждым новым событием. В традиционных моделях глубокого обучения поток данных разрывается на блоки фиксированного размера. Свёртки проходят по статичным массивам, а внимание распределяется по заранее подготовленным фреймам. Здесь же всё иначе. Каждое событие — это шаг. Каждое изменение — обновление внутренних параметров. Каждая новая порция данных моментально влияет на скрытое состояние. В оригинальной области применения таким событием был пиксель, изменивший своё значение. В нашем случае — изменение цены, объёма, спреда или других признаков, которые мы используем для описания рыночного импульса.
Такой подход особенно ценен для финансовых рынков, ведь их динамика редко умеет ждать. Крупные участники действуют в доли секунды. Ликвидность перемещается скачками. А микроструктура реагирует на каждое движение подобно механическому маятнику, получившему новый толчок. Модели, основанные на регулярных свечах, неизбежно сглаживают эти нюансы и часто теряют тонкую структуру, где и рождаются торговые сигналы. Архитектура E-STMFlow как раз и позволяет сохранить эту структуру. Она не навязывает рынку искусственных интервалов. Не усредняет и не обрывает поток. Вместо этого она воспринимает каждый новый импульс как часть общего движения и удерживает в памяти всё, что действительно важно.
Суть оригинального фреймворка заключается в компактном Spatio-Temporal State Space Module — модуле, который объединяет пространственную и временную динамику в едином процессе обновления состояния. В камере пространство — это координаты пикселя, в торговле мы интерпретируем пространство иначе — как набор признаков, через которые рынок сообщает о своей текущей форме. Темп изменения цены, величина последнего движения, реакция объёма, особенности ликвидности — всё это формирует своеобразное многомерное пространство, в котором каждый тик оставляет след. Временная составляющая тоже важна. Тики приходят неравномерно, и модель должна учитывать не только их значения, но и ритм, с которым они появляются.
По этой причине событийная архитектура особенно хорошо подходит для обработки рыночных данных. Она естественно фильтрует периоды спокойствия. Если рынок стоит, то поток событий почти исчезает, и модель не тратит силы на обработку лишней информации. Зато при всплеске активности архитектура реагирует сразу, обновляя состояние на каждом шаге и формируя предельно оперативное понимание происходящего. Это свойство делает E-STMFlow крайне привлекательным кандидатом для применения в торговых алгоритмах, где необходимо быстро реагировать на изменение условий и избегать задержек.
Важно отметить и экономичность предложенного подхода. В отличие от тяжёлых трансформеров или глубоких рекуррентных структур, модели состояния работают быстро, потребляют минимум ресурсов и легко масштабируются. Фреймворк E-STMFlow допускает тонкую настройку размерности состояния, легко адаптируется под особенности анализируемого потока и не требует чрезмерного объёма памяти.
Авторская визуализация фреймворка E-STMFlow представлена ниже.

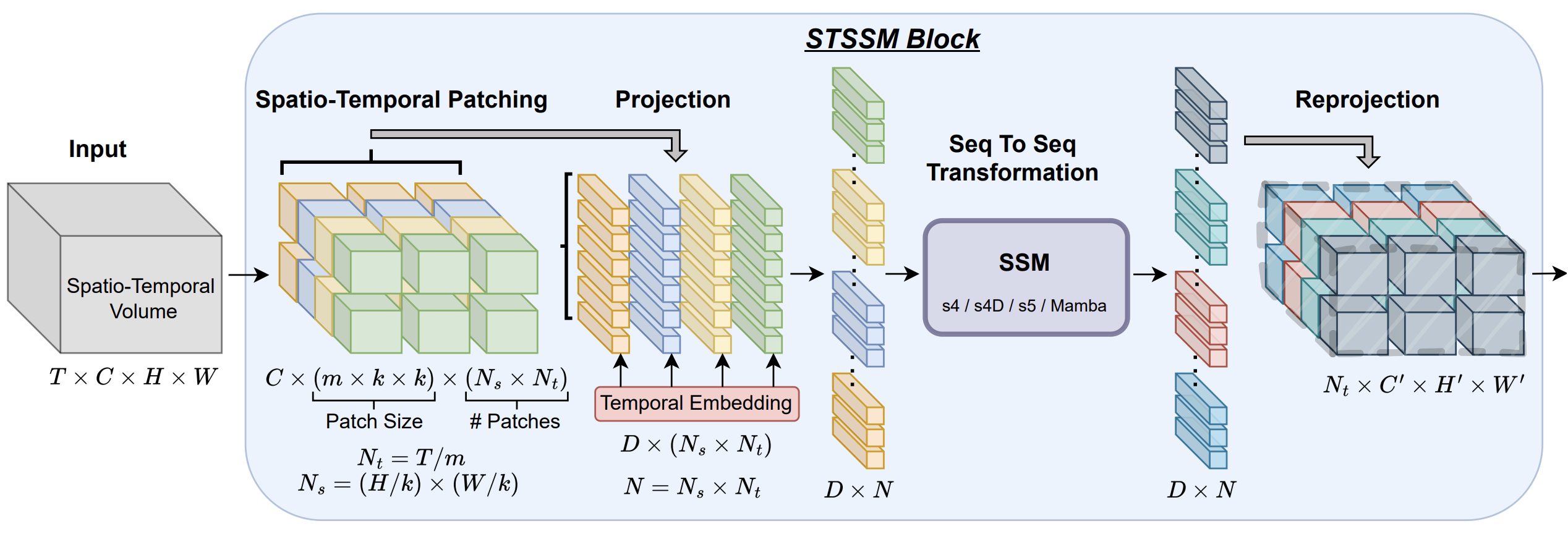
В предыдущих статьях мы уже подробно описали процесс формирования признаков, способы кодирования событий и механизм обновления скрытого состояния. Мы создали структуру, которая умеет принимать поток данных, преобразовывать его в компактное представление и передавать в вычислительные блоки OpenCL. На этих блоках теперь держится основная логика обработки. Каждое новое событие запускает обновление состояния, и это обновление постепенно формирует понимание направления и силы движения.
И теперь, восстановив полный контекст и вновь почувствовав внутренний ритм подхода, мы можем перейти к финальному этапу.
Объект верхнего уровня
После того как мы разобрали архитектуру E-STMFlow на отдельные модули и реализовали ключевые элементы обработки событий, мы подошли к тому этапу, который в инженерной работе всегда вызывает особое чувство. Настал момент собрать все созданные элементы в единый верхнеуровневый объект, придать системе целостность и заставить её работать как единый организм. Это та стадия, где разрозненные детали наконец начинают говорить на одном языке, а архитектура, ещё недавно напоминавшая схему будущего здания, постепенно превращается в полноценную конструкцию, способную выдержать нагрузки реального рынка.
Стоит подчеркнуть, что авторы фреймворка E-STMFlow сделали серьёзный шаг вперёд, обновив не только архитектуру энкодера, но и предложив свежий взгляд на устройство декодера. Они фактически расширили горизонты классических подходов, предложив более устойчивую и выразительную модель для работы с временными рядами. Однако в рамках нашего проекта мы сознательно оставили эту часть за пределами реализации. И не потому, что она неинтересна или трудна. Причина куда глубже и связана с практическими задачами, которые мы перед собой ставим.
Нашей целью остаётся создание автономного торгового робота, способного не просто прогнозировать цену в следующей точке, а принимать корректные торговые решения в условиях реального, шумного, капризного рынка. На финансовых графиках жизнь всегда кипит — цена движется рывками, ликвидность меняется по настроению толпы. И даже идеальный прогноз может оказаться бесполезным, если за ним не стоит понимание рыночной структуры. Поэтому точное предсказание будущего тика, как ни парадоксально это звучит, для нас не является самоцелью. Это полезный инструмент, но не основа всего торгового поведения.
Куда важнее получить глубокое, устойчивое, информативное латентное представление текущего состояния рынка — своего рода внутреннюю карту, на которой отмечены ключевые уровни, импульсы, коррекции, скрытые паттерны спроса и предложения. Агент, обладающий таким представлением, уже не действует вслепую. Он видит контекст, а не только следующее число в ряду. Понимает настроение рынка, а не лишь механическую динамику свечей. И именно энкодер E-STMFlow, с его новой структурой, позволяет сформировать такое богатое внутреннее состояние. Он придаёт модели ясность мысли, помогает ей выделять важное и отсекать шум, создаёт фундамент для принятия взвешенных и последовательных решений.
Именно поэтому верхнеуровневый объект, который мы сейчас формируем, становится ключевым звеном всей реализации. Он позволит объединить отдельные компоненты в единую рабочую конструкцию, где модернизированный энкодер станет сердцем системы, а остальные модули обеспечат ей гибкость и устойчивость.
Мы воссоздаём структуру энкодераE-STMFlow в новом классе CNeuronESTMEncoder. Он наследуется от блока CNeuronSpikeConvBlock и тем самым получает доступ ко всему функционалу, который уже доказал свою надёжность на предыдущих этапах разработки.
class CNeuronESTMEncoder : public CNeuronSpikeConvBlock { protected: CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronESTMEncoder(void) {}; ~CNeuronESTMEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &stack_size[], uint &dimension[], uint patch_dimension, uint ssm_dimension, uint &variables[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronESTMEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool Clear(void) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Внутри объекта размещён компонент cFlow — отдельный динамический массив, который будет отвечать за потоковую обработку данных и синхронизацию вычислений, характерных для архитектуры E-STMFlow. Внешне структура выглядит лаконично, но за этой лаконичностью скрывается довольно глубокая логика, выверенная авторами оригинального фреймворка.
Инициализация объекта энкодера — это тот самый этап, где архитектура перестаёт быть схемой на бумаге и превращается в работающий механизм. Здесь модель получает свои размеры, внутреннюю геометрию и последовательность вычислительных блоков, которые будут формировать восприятие рынка.
Важно, что структура E-STMFlow предполагает многослойную организацию, где каждый слой выполняет строго определённую роль. Именно поэтому процесс инициализации получился столь насыщенным. Модель словно получает инструктаж перед выходом на реальный рынок, где нет права на ошибку и каждый сбой приводит к искажению анализа рыночной ситуации.
bool CNeuronESTMEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &stack_size[], uint &dimension[], uint patch_dimension, uint ssm_dimension, uint &variables[], ENUM_OPTIMIZATION optimization_type, uint batch) { uint layers = stack_size.Size(); if(layers < 1 || dimension.Size() != (layers + 1) || variables.Size() != (layers + 1)) return false;
Алгоритм метода инициализации начинается с проверки корректности полученных параметров. Это своеобразный технический контроль перед запуском всей машины. Массивы stack_size, dimension и variables задают конфигурацию каждого уровня — ширину и глубину потоков, внутренние представления и размеры скрытых блоков. Если хотя бы один из этих массивов имеет неверную длину, дальнейшая работа модели теряет смысл, инициализация прерывается. Такой подход не только дисциплинирует архитектуру, но и предотвращает множество ошибок, которые в реальных торговых условиях могли бы привести к неправильному поведению робота.
После базовой проверки объект опирается на функциональность родительского класса, который задаёт общие параметры вычислительного контура.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, dimension[layers - 1], dimension[layers - 1], dimension[layers], variables[layers], 1, optimization_type, batch)) return false;
Этот шаг можно сравнить с подготовкой общей инфраструктуры. Создаются базовые настройки. Распределяются вычислительные ресурсы. Модель получает фундамент, на котором можно уверенно строить более тонкие структуры.
Далее начинается формирование внутренней последовательности вычислительных блоков, составляющих поток обработки данных cFlow.
cFlow.Clear();; cFlow.SetOpenCL(OpenCL); CNeuronTransposeOCL* transp = NULL; CNeuronSpikeConvBlock* conv = NULL; CNeuronSpikeSTSSM* ssm = NULL; uint index = 0;
Каждая итерация цикла — это один слой энкодера. И в каждом слое обязательным элементом становится модуль CNeuronSpikeSTSSM. Именно на нём строится ключевая логика E-STMFlow, связанная с обработкой скрытых состояний и последовательностей.
for(uint i = 0; i < layers; i++) { ssm = new CNeuronSpikeSTSSM(); if(!ssm || !ssm.Init(0, index, OpenCL, stack_size[i], dimension[i], patch_dimension, ssm_dimension, variables[i], optimization, iBatch) || !cFlow.Add(ssm)) { DeleteObj(ssm) return false; } index++;
Этот компонент обеспечивает устойчивость к рыночному шуму и позволяет модели удерживать контекст, что крайне важно при анализе финансовых временных рядов. Ведь рынок — это не набор изолированных состояний. Его динамика формируется цепочкой событий, где каждое следующее движение цены зависит от целой истории предыдущих импульсов.
Если параметры следующего слоя предполагают изменение количества анализируемых переменных, добавляется связка из транспозиций и сверточных блоков.
if(variables[i] != variables[i + 1]) { transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, variables[i], dimension[i], optimization, iBatch) || !cFlow.Add(transp)) { DeleteObj(transp) return false; } index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, variables[i], variables[i], variables[i + 1], dimension[i], 1, optimization, iBatch) || !cFlow.Add(conv)) { DeleteObj(conv) return false; } index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, dimension[i], variables[i + 1], optimization, iBatch) || !cFlow.Add(transp)) { DeleteObj(transp) return false; } index++; }
Это выглядит как техническая деталь, но фактически служит тонкой подстройкой архитектуры под меняющиеся размеры латентных представлений. Такой механизм напоминает перенастройку торговых инструментов под конкретный рыночный режим. Модель меняет внутреннюю структуру, чтобы сохранить согласованность вычислений и не потерять важную информацию на границе слоёв.
После обработки каждого уровня, в поток добавляется свёрточный блок, который подготавливает данные для следующего слоя.
if(i == (layers - 1)) break; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, dimension[i], dimension[i], dimension[i + 1], variables[i + 1], 1, optimization, iBatch) || !cFlow.Add(conv)) { DeleteObj(conv) return false; } index++; } //--- return true; }
Эти блоки усиливают способность модели выделять ключевые элементы рыночной структуры, стабилизируя подачу информации на глубокие уровни сети.
Завершаясь на последнем слое, цикл формирует целостный, последовательный вычислительный маршрут, по которому данные будут проходить при обучении и инференсе.
В итоге энкодер получает стройный, упорядоченный коридор обработки, где каждый модуль на своём месте и каждая трансформация точно рассчитана. Такая инициализация может показаться избыточно подробной, но для работы с реальными финансовыми данными она оправдана полностью. Рынок суров к неопределённым моделям — малейшая ошибка в архитектуре проявится в неверном восприятии цены, а значит и в неверных торговых решениях. Поэтому строгая последовательность действий в методе инициализации — это не формальность, а гарантия того, что модель будет работать надёжно, последовательно, как задумано.
Алгоритм прямого прохода получает почти линейную форму, благодаря динамическому массиву cFlow, который объединяет все элементы архитектуры в строгой последовательности. Такая организация делает вычислительный маршрут прозрачным и предсказуемым. Данные движутся от одного блока к другому без разветвлений, словно проходят по коридору, где каждый шаг заранее определён архитектурой. В условиях финансовых рынков это особенно важно, потому что последовательность преобразований должна быть стабильной, а модель — воспроизводимой. Любая неопределённость в структуре способна привести к нежелательным артефактам в обработке ценовых данных.
bool CNeuronESTMEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev)) return false;
Внутри метода feedForward мы начинаем с передачи анализируемых данных первому модулю и далее последовательно передаём управление каждому объекту, хранящемуся в cFlow. Каждый модуль получает результат предыдущего и выполняет свою часть вычислений, формируя всё более осмысленное латентное представление.
Такой подход напоминает поэтапный анализ рыночной ситуации. Сначала мы оцениваем локальную структуру цен, затем связываем её с контекстом, после чего учитываем более глобальные факторы. Линейная обработка в этом смысле создаёт естественную логику распознавания закономерностей в динамике цены.
Однако архитектура остаётся линейной лишь на первый взгляд. В действительности ключевую роль здесь играет поведение STSSM-блоков. Каждый раз, когда модель проходит через модуль CNeuronSpikeSTSSM, мы накладываем поверх его результатов дополнительное преобразование — операцию реализации остаточного соединения, позволяющего перенаправить часть предыдущего сигнала напрямую в выход текущего блока.
if(curr.Type() == defNeuronSpikeSTSSM) if(!SumAndNormilize(prev.getOutput(), curr.getOutput(), curr.getOutput(), 1, false, 0, 0, 0, 1)) return false; prev = curr; }
Такая механика отражает основную идею E-STMFlow, на которой и построен весь алгоритм. SSM-компонент отвечает за прогноз относительного изменения потока, тогда как остаточная связь удерживает модель в привязке к исходным значениям. Благодаря этому энкодер перестаёт быть предсказателем абсолютных значений и превращается в гибкий механизм, отслеживающий именно динамику состояния последовательности.
В контексте финансовых рядов такое решение более чем оправдано. Рынок редко движется прямолинейно и почти никогда не раскрывает направление заранее. Важнее уметь улавливать изменения: ускорения, замедления, смену ритма, изменение волатильности. Латентное представление, построенное исключительно на основе абсолютных величин, быстро теряет чувствительность к этим нюансам. А вот система, работающая с относительными изменениями и поддерживающая связь со своим предыдущим состоянием, получает преимущество. Она способна адаптироваться к рыночным режимам и не теряет контекст. Остаточные связи после SSM-блоков становятся своеобразным якорем, удерживающим модель в устойчивом положении, не позволяя ей слишком сильно отклоняться или уходить в область переусложнённых трансформаций.
Именно поэтому метод прямого прохода компактен, но далеко не примитивен. Он представляет собой тщательно выверенную комбинацию линейной архитектуры и динамических корректировок, встроенных непосредственно в логику STSSM-блоков. Такая структура позволяет модели формировать богатое, устойчивое и информативное латентное пространство, на которое можно опереться при принятии торговых решений. Для будущего торгового Агента это означает более чистый и стабильный анализ рынка. А значит — и более обоснованное поведение в условиях реальных ценовых колебаний.
После завершения всех итераций цикла управление передаётся одноимённому методу родительского класса.
return CNeuronSpikeConvBlock::feedForward(prev);
}
И этот момент играет важную роль в логике всего энкодера. Пока поток проходит через последовательность внутренних модулей cFlow, мы шаг за шагом преобразуем исходный сигнал, обогащая его локальными структурам, динамикой изменения и корректировками, заданными SSM-блоками. Но именно финальный вызов метода базового класса завершает этот маршрут и превращает всю накопленную информацию в цельное, аккуратно оформленное представление о рыночной ситуации.
Этот завершающий этап можно сравнить с тем, как трейдер после серии наблюдений и промежуточных оценок всё-таки приводит мысли в порядок и формулирует конкретный вывод. Внутренние модули дают нам черновые наброски — структуры локальных паттернов, темп изменений, контекстные связи. Родительский feedForward, в свою очередь, выполняет роль финального редактора. Он берёт результат последнего блока в цепочке, применяет необходимые преобразования и выдаёт пользователю уже стабилизированное, согласованное представление, которое можно передать на следующий этап обработки.
Важно и то, что этот итоговый формат заранее определяется конфигурацией модели. Пользователь задаёт параметры, выбирает количество признаков, размерность выходного пространства — и именно в этом формате родительский класс формирует результат. Это делает архитектуру гибкой. Один и тот же энкодер может адаптироваться под разные схемы анализа рынка, от компактных латентных представлений для торгового Агента до объёмных многомерных сигналов для сложных аналитических систем. Фактически происходит финальная упаковка данных, подстроенная под конкретную задачу и требования торговой стратегии.
Этап обратного прохода — это словно момент анализа после торговой сессии. Когда опытный трейдер садится за таблицы и графики, чтобы понять, где его решения совпали с рынком, а где промахнулись. В контексте нашего энкодера метод calcInputGradients выполняет именно такую роль. Он позволяет модели оценить свои прогнозы, выявить ошибки и распределить их по всем внутренним компонентам, превращая каждое отклонение в инструмент обучения.
bool CNeuronESTMEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Процесс начинается с проверки актуальности полученного указателя на объект исходных данных. Это позволяет убедиться, что мы имеем корректные данные для работы. Затем вызывается одноимённый метод родительского класса, который передает градиенты ошибки на уровень последнего элемента цепочки cFlow.
if(!CNeuronSpikeConvBlock::calcInputGradients(cFlow[-1])) return false;
Этот шаг можно представить как фиксацию окончательного результата, он становится отправной точкой для всех последующих корректировок.
Дальше начинается движение назад по цепочке, начиная с предпоследнего элемента и продвигаясь к первому. На каждом шаге для текущего блока вызывается метод CalcHiddenGradients, что позволяет вычислить локальную ошибку с учётом информации, поступающей от следующего уровня.
CNeuronBaseOCL* next = cFlow[-1]; CNeuronBaseOCL* curr = NULL; for(int i = cFlow.Total() - 2; i >= 0; i--) { curr = cFlow[i]; if(!curr || !curr.CalcHiddenGradients(next)) return false;
Этот алгоритм создаёт причинно-следственную цепочку. Если ошибка проявилась выше, каждый нижестоящий блок получает свою долю ответственности и корректирует собственные параметры. Такой подход обеспечивает, что каждая часть модели знает, за что она отвечает, и не перегружает соседей лишними корректировками.
Особое внимание уделяется STSSM-блокам. В прямом проходе мы добавляли остаточные связи, поэтому в обратном ходе градиенты нужно аккуратно корректировать с учётом этих связей.
if(next.Type() == defNeuronSpikeSTSSM) { if(curr.Activation() != None) { if(!DeActivation(curr.getOutput(), next.getPrevOutput(), next.getGradient(), curr.Activation()) || !SumAndNormilize(next.getPrevOutput(), curr.getGradient(), curr.getGradient(), 1, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(next.getGradient(), curr.getGradient(), curr.getGradient(), 1, false, 0, 0, 0, 1)) return false; } next = curr; }
Здесь стоит отметить, что поток операций зависит от наличия функции активации у слоя, предшествующего STSSM-блоку. В случае наличия токовой, сначала используются методы DeActivation. Он позволяет скорректировать градиенты по магистрали остаточных связей на производную функции активации, и лишь после этого осуществляется суммирование градиентов ошибки, полученных по двум информационным потокам. В случае отсутствия функции активации излишняя операция опускается.
Благодаря такой конструкции, STSSM-блоки обучаются не по абсолютным значениям, а по относительным изменениям потока, что идеально соответствует задачам анализа финансовых рядов. Ведь важно уловить динамику, а не фиксировать статические уровни.
После того как мы прошли весь массив cFlow, градиенты ошибки передаются на уровень исходных данных.
//--- if(!NeuronOCL.CalcHiddenGradients(next)) return false; if(next.Type() == defNeuronSpikeSTSSM) { if(NeuronOCL.Activation() != None) { if(!DeActivation(NeuronOCL.getOutput(), next.getPrevOutput(), next.getGradient(), NeuronOCL.Activation()) || !SumAndNormilize(next.getPrevOutput(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(next.getGradient(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } //--- return true; }
Здесь также проверяется, есть ли функция активации. И при необходимости применяется та же логика корректировки градиентов с учётом остаточной связи. Это позволяет аккуратно завершить весь обратный проход, не оставляя пробелов в распределении ошибок между слоями.
В результате весь метод формирует структурированную карту градиентов, и каждый блок понимает, как его вес повлиял на конечный результат, и в каком направлении его нужно скорректировать.
Для финансового анализа это особенно ценно. Модель не просто повторяет прошлые движения, она учится выделять ключевые динамические закономерности, распознавать скрытые сигналы и адаптироваться к меняющимся рыночным условиям. Такой подход обеспечивает устойчивость, точность и стабильность работы торгового Агента даже в условиях высокой волатильности и непредсказуемых рыночных рывков, превращая каждый цикл обучения в инструмент повышения профессионализма модели.
В совокупности класс CNeuronESTMEncoder становится той самой точкой сборки, где инженерная логика объединяется с финансовой практикой. Он готовит данные для дальнейших модулей, формирует ядро понимания рынка и обеспечивает связность всей архитектуры. И чем точнее, надёжнее и чище мы его реализуем, тем увереннее будет чувствовать себя наш Агент. Полный код данного класса и всех его методов представлен во вложении.
Архитектура модели
Как уже упоминалось, в нашем проекте создаётся полноценная торговая система, способная самостоятельно анализировать рынок, принимать решения и заключать сделки. Архитектура модели в целом основана на проверенных решениях из предыдущих работ, что позволило сохранить надёжные алгоритмы обработки сигналов и обучения. Существенные изменения коснулись только Энкодера окружающей среды — именно здесь был внедрён объект верхнего уровня CNeuronESTMEncoder, ставший ядром формирования латентного представления рынка.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronESTMEncoder; { uint temp[] = {prev_out, // Chanels In 16, 32, 64, 64 // Chanels Out }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In 12, 24, 12, 12 // Units Out }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; }
Создание нового слоя реализовано через объект CLayerDescription, где задаются все параметры объекта. Для каждого уровня мы указываем количество входных и выходных каналов, число элементов последовательности, размеры стеков и другие характеристики.
Особое внимание стоит уделить размерам стеков на каждом уровне анализа данных. В оригинальном фреймворке авторы предлагают последовательно уменьшать временное измерение, и в финальном выходе энкодера оно сводится к "1". Мы следуем этой логике, постепенно уменьшая размер стека на каждом слое, однако на последнем уровне оставляем значение с небольшим временным лагом. Это позволяет сохранить часть информации о недавней динамике рынка, что критично для точной оценки трендов и краткосрочных колебаний цен. Такой подход сочетает преимущества авторской методики с нашей задачей. Модель получает компактное, но всё ещё информативное представление временных рядов, способное поддерживать стабильное принятие торговых решений.
{ // Stack size
uint temp[] = {48,
24,
12,
4
};
if(ArrayCopy(descr.heads, temp) < (int)temp.Size())
return false;
}
descr.window=16;
descr.window_out=64;
descr.optimization = ADAM;
descr.batch = BatchSize;
if(!encoder.Add(descr))
{
delete descr;
return false;
}Особое внимание уделяется методу оптимизации параметров модели (ADAM) и размеру пакета усреднения (BatchSize). Эти параметры обеспечивают стабильность обучения на исторических данных.
Такой подход даёт нам несколько преимуществ. Во-первых, архитектура остаётся понятной и прозрачной — каждый параметр легко проследить и при необходимости скорректировать. Во-вторых, сохраняется гибкость — модификация отдельных слоёв или добавление новых компонентов не требует глобальных изменений. В-третьих, система готова к адаптации под разные рыночные условия, поскольку новый энкодер аккуратно вписывается в уже существующую структуру модели, обеспечивая обогащённое и информативное латентное представление состояния рынка.
В совокупности это позволяет строить торгового Агента, способного работать автономно и последовательно, опираясь на структурированные сигналы, извлечённые из рыночных данных. Полный код описания архитектуры доступен во вложении, что позволяет воспроизвести и расширять реализацию без потери целостности модели.
Тестирование
После того как архитектура моделей определена, мы переходим к финальному этапу — обучению и тестированию. Этот процесс, как и ранее, строится в два этапа, и каждый из них играет ключевую роль в формировании полноценной торговой стратегии поведения Агента.
Первый этап обучения осуществляется на исторических данных и напоминает репетицию начинающего трейдера на большой биржевой площадке. Представьте график EURUSD с Января 2024 по Июнь 2025 года как полотно, полное скрытых закономерностей. Модель, словно внимательный ученик, всматривается в каждую свечу, отслеживает объёмы, анализирует реакции рынка на индикаторы и выявляет закономерности. Реализованный нами энкодер фреймворка E-STMFlow позволяет одновременно разглядеть малейшие колебания цены и обозначить глобальные тренды. Он формирует информативное состояние для Актёра и Критика, объединяет признаки разных масштабов и обучается вместе с моделью. С каждым новым шагом модель постепенно превращается в уверенного трейдера, способного принимать самостоятельные решения.
Следующий этап — онлайн-обучение в тестере стратегий MetaTrader 5 — это уже не просто репетиция, а интенсивная отработка навыков. Здесь нет удобных исторических данных, каждая свеча — это живой импульс реального рынка. Модель реагирует мгновенно, оценивает шумовые колебания, приспосабливается к резким всплескам и корректирует действия при низкой ликвидности. CNeuronESTMEncoder синхронизирует работу всех блоков, объединяет признаки разных масштабов и продолжает обучение вместе с моделью, формируя гибкое и устойчивое поведение.
Завершающая проверка навыков проходит на данных с Июля по Октябрь2025 года. Здесь нет подсказок и возможности опереться на прошлое — только рынок и решения модели. Каждое движение тренирует способность сочетать признаки разного масштаба, прогнозировать реакции рынка и действовать с точностью. Результаты тестирования показывают, как реализованное решение превращает сложную архитектуру в слаженную, адаптивную и эффективную торговую систему.


Результаты тестирования демонстрируют аккуратную, сбалансированную динамику капитала с умеренной волатильностью. Баланс и эквити движутся синхронно, что указывает на стабильность поведения стратегии и корректную работу алгоритмов обработки рыночной информации.
Первые два месяца тестового периода характеризуются боковой динамикой с небольшими колебаниями вокруг уровня начального депозита. Это отражает отсутствие явного трендового преимущества на рассматриваемом участке рынка и показывает, что робот не форсирует сделки без достаточных сигналов. Лишь во второй половине периода наблюдается уверенный рост капитала. Кривая баланса достигает порядка 103.8USD и удерживается в этой области до завершения теста, что демонстрирует способность стратегии выявлять и использовать благоприятные рыночные возможности.
Максимальная просадка по балансу составила 4.02%, по средствам — 5.48%. Эти показатели отражают сдержанный риск-профиль и стабильность системы. Стратегия избегает глубоких просадок, сохраняя резерв устойчивости и обеспечивая безопасное управление капиталом, что особенно важно при малом стартовом депозите.
Чистая прибыль достигла 3.29%, и формируется коэффициент прибыли 1.35. Это значит, что каждый USD риска возвращает 1.35USD прибыли. Значение достаточно для первой стадии проработки алгоритма, хотя указывает на потенциал дальнейшей оптимизации входов и выходов для повышения общей эффективности.
Ожидаемое математическое вознаграждение на сделку равно 0.13 при 26 проведённых сделках, что подтверждает умеренно положительное смещение распределения результатов. Показатель восстановления равен 0.59, что демонстрирует умеренную скорость возвращения к предыдущему уровню после просадок. Низкое значение стандартной ошибки линейной регрессии (0.63) подтверждает гладкость кривой капитала без резких шумовых выбросов.
Структура сделок сбалансирована: из 26 торговых операций доля прибыльных составила 53.85%. Как длинные, так и короткие позиции показали примерно равное распределение успехов. Максимальная прибыль с одной сделки достигла 3.00USD, а максимальный убыток — 1.46USD. Это создаёт умеренно благоприятное соотношение выигрышей к потерям.
В целом, тестирование подтверждает, что логика робота, реализованная с использованием E-STMFlow, обеспечивает сдержанно-положительный рост капитала, минимальные просадки, предсказуемое распределение рисков и стабильность поведения. Несмотря на скромную абсолютную прибыль, форма кривой, качество риск-профиля и согласованность показателей указывают на высокий потенциал стратегии. Основные направления дальнейшей работы включают повышение точности входов, локальную оптимизацию трендовых фильтров и адаптивную калибровку стоп-параметров для увеличения ожидаемой доходности без существенного роста риска.
Заключение
Проведенная нами работа демонстрирует практическую эффективность фреймворка E-STMFlow при построении автономной торговой системы. Реализация объекта верхнего уровня CNeuronESTMEncoder позволила объединить отдельные компоненты архитектуры в единую слаженную структуру, обеспечив точное и информативное представление состояния рынка. Последовательное уменьшение размеров стеков и внедрение временного лага позволили сохранить критически важную информацию о недавней динамике цен, что повысило устойчивость принимаемых торговых решений.
Обучение и тестирование модели на исторических данных подтвердили стабильность стратегии, умеренный рост капитала, низкие просадки и предсказуемое распределение рисков. Результаты показали, что робот способен адаптироваться к волатильности рынка, корректировать действия в условиях шумовых колебаний и поддерживать сбалансированное соотношение выигрышей и убытков.
Предложенное решение демонстрирует высокий потенциал для построения автономных торговых агентов. Сочетание модульной архитектуры, продуманной обработки признаков разного масштаба и обучаемых связей между компонентами создаёт основу для надёжной и адаптивной системы. Дальнейшее развитие стратегии возможно через оптимизацию входов, адаптивную настройку фильтров и стоп-параметров, что позволит повысить доходность без существенного увеличения рисков, превращая прототип в полноценный инструмент профессионального трейдера.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Обучение 3 и даже 30 эпох — это очень мало. В "...\Experts\NeuroNet_DNG\NeuroNet.mqh" задана скорость обучения
Использование VAE, в отличие от других типов нейронных слоев, позволяет выучить границы распределения значений, а не только среднее.
И да, в E-STMFlow не предусмотрен ни только VAE, но и Актер с Критиком, как таковые.
Добрый вечер,
Обучение 3 и даже 30 эпох — это очень мало. В "...\Experts\NeuroNet_DNG\NeuroNet.mqh" задана скорость обучения
Использование VAE, в отличие от других типов нейронных слоев, позволяет выучить границы распределения значений, а не только среднее.
И да, в E-STMFlow не предусмотрен ни только VAE, но и Актер с Критиком, как таковые.
Основные проблемы производительности:
1. Последовательная обработка на CPU вместо батчинга на GPU
Код обрабатывает каждую позицию по очереди в цикле. Для каждого бара выполняется:2. Множественные синхронизации CPU-GPU
Каждый вызов feedForward/backProp требует передачи данных между CPU и GPU, что создает огромный оверхед.3. Неэффективное использование BatchSize
BatchSize = 1e4 определен, но код обрабатывает по одному примеру за раз вместо батчей.В итоге, я уже решился попробовать портировать вашу идею на Питон, а за основу беру исходник с оригинальной статьи и правлю его по вашей схеме. Посмотрим, что из этого получится. Или может вы подскажете какое-то решение производительности на MQL5? Или хотя бы направите?
Очень рад вашей обратной связи. Я так полагаю и 100 эпох не даст качественного обучения. Но прикол в том, что даже на арендованном сервере с хорошим GPU процесс обучения идёт крайне медленно. Ни процессор, ни видеокарта не загружаются по полной, а только лишь процентов на 10 в среднем. Чтобы прогнать 1000+ эпох мне придётся на две недели минимум сервак такой гонять... Проблема в том, что код выполняется последовательно на CPU, несмотря на то, что OpenCL инициализирован.
Основные проблемы производительности:
1. Последовательная обработка на CPU вместо батчинга на GPU
Код обрабатывает каждую позицию по очереди в цикле. Для каждого бара выполняется:2. Множественные синхронизации CPU-GPU
Каждый вызов feedForward/backProp требует передачи данных между CPU и GPU, что создает огромный оверхед.3. Неэффективное использование BatchSize
BatchSize = 1e4 определен, но код обрабатывает по одному примеру за раз вместо батчей.В итоге, я уже решился попробовать портировать вашу идею на Питон, а за основу беру исходник с оригинальной статьи и правлю его по вашей схеме. Посмотрим, что из этого получится. Или может вы подскажете какое-то решение производительности на MQL5? Или хотя бы направите?