
Переосмысливаем классические стратегии (Часть 17): Моделирование технических индикаторов

Применение машинного обучения и других современных статистических методов для алгоритмической торговли является исключительно сложной задачей. Проблемы, с которыми сталкивается наше сообщество, касаются исключительно финансовых рынков, и из—за этого они редко обсуждаются в более широких кругах, связанных с машинным обучением. В результате классическое обучение под наблюдением предлагает очень мало практических рекомендаций по вопросам, которые важны для нашего сообщества. Одной из наиболее часто упускаемых из виду проблем в нашей области является тот факт, что при моделировании финансовых данных у нас нет фиксированной целевой переменной. На первый взгляд этот вопрос может не показаться проблематичным, но он таким является.
Чтобы это проиллюстрировать, давайте подумаем о том, как эти модели применяются в медицине. Читатель должен помнить, что медицина - это область, из которой изначально появились многие методы обучения с учителем (supervised learning), а наше сообщество "заимствует" эти методы. В медицине целевая переменная является определенной и четко очерченной. Врач может захотеть классифицировать пациента либо как больного раком, либо как нет — это задача бинарной классификации с четкой и неизменной меткой класса. Цель врача никогда не меняется, и она основана на физической реальности. Более того, медицинские модели работают в рамках естественных ограничений — биологических, этических или процедурных, — которые придают задаче обучения последовательную структуру.
Напротив, в финансовой сфере отсутствует такая структура. Как у алгоритмических трейдеров, у нас нет четкого определения цели. Мы можем моделировать рынок с точки зрения годовой доходности, ежедневной доходности, 15-минутной доходности, ежегодного повышения цен, максимальной просадки, волатильности или даже относительного изменения между активами. На самом деле существует бесконечно много способов определить, что означает “цель” в контексте торговли. И хотя все эти целевые показатели основаны на одних и тех же базовых данных, некоторые целевые показатели гораздо труднее прогнозировать, чем другие.
В связи с этим возникает важный вопрос: может ли наш очевидный предел эффективности быть вызван не слабостью модели или качеством данных, а неудачным выбором цели? Что еще хуже, мы заранее не знаем, какова “правильная” цель или существует ли вообще универсальная цель на разных рынках. Каждый рынок может иметь собственную оптимальную постановку задачи прогнозирования.
С этой точки зрения становится ясно, что эффективность наших статистических моделей не обязательно отражает их истинные возможности. Ограничения, с которыми мы сталкиваемся, — уровни ошибок, которые кажутся непреодолимыми, — часто являются симптомами методологического "стеклянного потолка".
В этой статье будет продемонстрировано, что с помощью тщательных экспериментов и адаптивной методологии мы можем постоянно улучшать эффективность нашей модели, просто переосмысливая то, что мы просим модель предсказать, а не только то, как мы ее обучаем. Последовательно перебирая разные определения целевой переменной, мы покажем, что эффективность зависит не только от качества данных и сложности модели, но также — и, возможно, это самое главное — от методологии, как именно мы ставим задачу обучения.
Получение наших данных в MetaTrader 5
Чтобы начать наше упражнение, мы сначала получаем необходимые рыночные данные из терминала MetaTrader 5. Для этого проекта мы применим несколько преобразований к большому набору функций — всего в ходе обсуждения будет использовано 22 признака. Чтобы обеспечить согласованность между данными, с которыми сталкивается наша модель во время обучения, и данными, которые она получит во время реальной торговли, мы извлекаем наши данные с помощью специального скрипта в MQL5. Такой подход позволяет нам воспроизводить одни и те же преобразования данных даже после периода бэктестинга.
Скрипт извлекает четыре основных ценовых уровня — цена открытия, максимума, минимума и закрытия — и применяет к каждому из них технический индикатор. Как только эти значения получены, скрипт записывает как исходные цены, так и соответствующие им значения индикатора. Далее мы вычислим рост (изменение) для каждого из четырех уровней цен и связанных с ними индикаторов. Затем рассчитаем относительный рост между каждой парой ценовых уровней — например, рост между ценами открытия и максимума, открытия и минимума, открытия и закрытия. Этот процесс позволяет получить детальную разбивку движения цен внутри свечей, что позволяет модели лучше понять, как меняются цены внутри каждого бара.
//+------------------------------------------------------------------+ //| Fetch Data MA | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_TYPE MODE_SMA //--- Type of moving average we have //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Detailed Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000; input int MA_PERIOD = 5; input int HORIZON = 5; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA O", "True MA H", "True MA L", "True MA C", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", "Diff MA Close 2", //--- Growth Across Price Levels "O-C", "H-L", "O-H", "O-L", "C-H", "C-L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_reading[(i + HORIZON)], //--- Growth Across Price Levels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_TYPE //+------------------------------------------------------------------+
Приступаем к нашему анализу на Python
Как только скрипт для извлечения данных будет завершен, мы перейдем на Python для выполнения анализа. Как и в большинстве наших экспериментов с машинным обучением, нашей первой целью является установление базового уровня эффективности с использованием классических парадигм моделирования. Мы начинаем с загрузки наших стандартных библиотек Python.
#Import the libraries we need to get started import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Стоит отметить, что первоначальная версия нашего скрипта на MQL5, используемая здесь, немного отличается от окончательной версии, представленной далее в этом обсуждении — более ранняя версия извлекает 17 столбцов, в то время как окончательная версия включает дополнительные признаки. Эти расхождения и мотивация для расширения набора данных станут ясны к концу статьи.
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
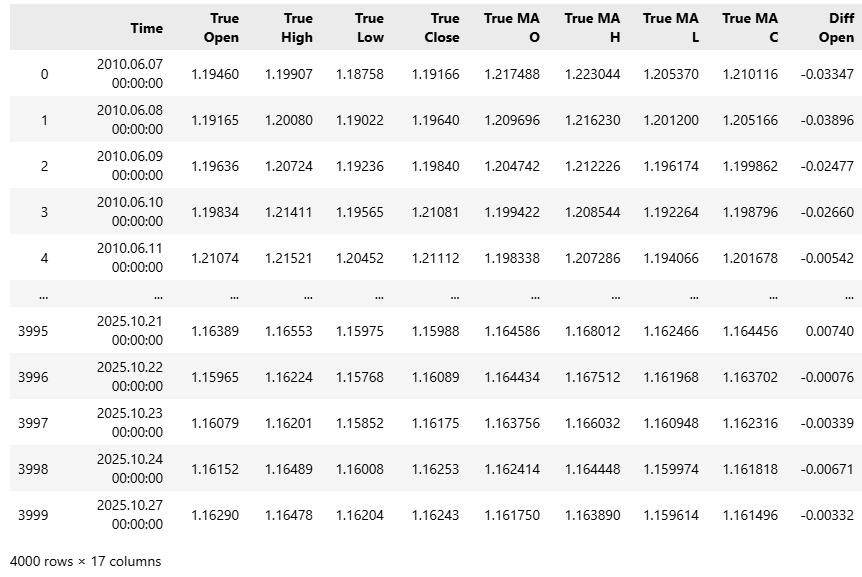
Рисунок 1: Наш набор данных довольно большой и в исходном состоянии содержит 17 столбцов
После ознакомления с набором данных мы приступаем к нанесению меток на наши данные, используя классический подход "на шаг вперед".
#Classical Target #Baseline value HORIZON = 1 #Label the data data['Target'] = data['True Close'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Читатели должны помнить, что мы намерены оценить эту статистическую модель путем ее тестирования на истории. Поэтому мы отбросим наблюдения за последние три года и сохраним их в отдельном тестовом наборе. Мы не будем обучать модель на этом тестовом наборе, поскольку это противоречило бы цели нашего обсуждения.
#Drop the last 3 years of data test = data.iloc[-(365*3):,:] data = data.iloc[:-(365*3),:]
Интересно отметить, что сила корреляции между целью и входными параметрами особенно нестабильна с течением времени. Мы проверили это, рассчитав корреляцию Пирсона между нашей целью и каждой входной переменной, используя расширяющийся диапазон наблюдений. Это дает нам вектор, значения которого отражают силу корреляции между целью и каждым входным параметром. Затем мы взяли L1-норму (сумму абсолютных значений) этого вектора, чтобы получить единую меру общей силы корреляции.
Мы начали с одного дня данных, затем перешли к двум дням, трем дням и так далее, постепенно расширяя выборку, пока не достигли полного года (365 дней). Как показано на рисунке ниже, уровень корреляции не является стационарным — он колеблется. В одни дни он проявляется сильно, в другие — ослабевает. В целом, похоже, он ослабевает по мере расширения диапазона, что указывает на нестабильность взаимосвязи между входными параметрами и целевым значением во времени.
corr_strength = [] EPOCHS = 365 for i in np.arange(EPOCHS): corr_strength.append(np.linalg.norm(data.loc[:i+1,:].corr().iloc[:,-1],ord=1)) sns.barplot(corr_strength) plt.ylabel('Correlational Strength') plt.title('Correlation Between Future Price And Historical Data')
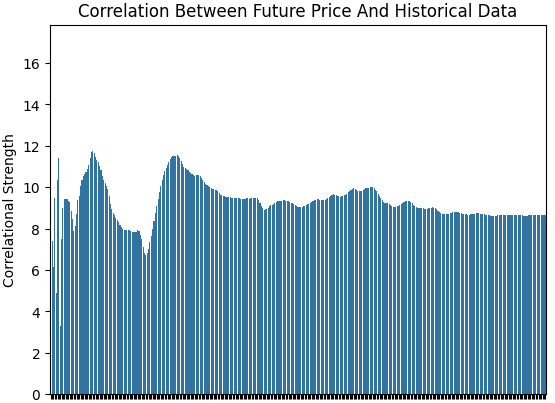
Рисунок 2: Сила корреляции по историческому набору данных EURUSD не является постоянной
Затем мы визуализировали корреляционную структуру между всеми входными параметрами в обучающем наборе, используя тепловую карту. Как мы видим, цель, как правило, имеет сильную корреляцию с ценовыми уровнями в абсолютных значениях и их скользящими средними, в то время как изменения в этих входных параметрах лишь слабо коррелируют с целью.
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 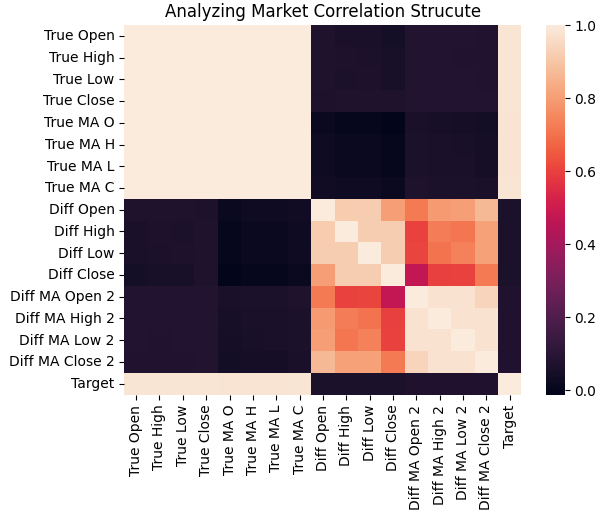
Рисунок 3: Корреляционная структура наших исторических данных по рынку EURUSD показывает, что целевое значение тесно связано с историческими ценами
Это не всё, что мы можем узнать из корреляционной матрицы. Мы также можем выполнить разложение на собственные значения, используя функцию eig из NumPy, которая возвращает как собственные значения, так и собственные векторы. Пока что сосредоточимся на собственных значениях. Собственные значения показывают, какая часть дисперсии в корреляционной структуре охватывается каждой главной компонентой. Иными словами, собственные значения показывают, сколько доминирующих “режимов выражения” имеют наши рыночные данные.
Стабильный рынок, как правило, управляется одним доминирующим режимом — например, сильным трендом или процессом возвращения к среднему значению, — в то время как более хаотичный рынок демонстрирует несколько конкурирующих режимов. В нашем случае график баров собственных значений показывает два больших, доминирующих режима, а также третий, немного превышающий средний пороговый уровень. Это позволяет предположить, что в нашей системе могут быть два доминирующих режима поведения и третий, более слабый. Оставшиеся собственные значения незначительны и ими можно пренебречь, поскольку они не вносят существенного вклада в корреляционную структуру данных.
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
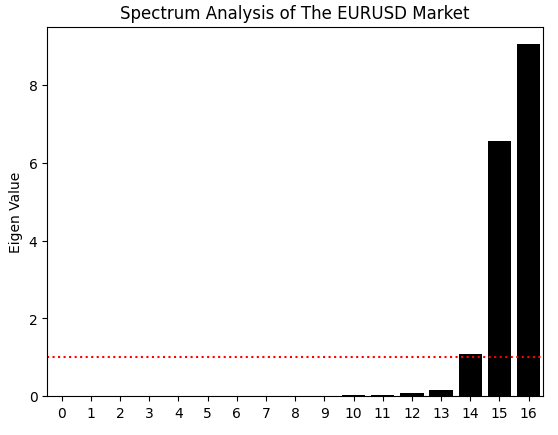
Рисунок 4: Собственные значения корреляционной структуры наших исторических данных по EURUSD указывают на наличие у рынка трех основных нестабильных режимов
Теперь перейдём к загрузке наших библиотек статистического обучения
from sklearn.linear_model import LinearRegression
Определим наши входные параметры и цель. Начнём с простой модели, которая принимает 4 входных параметра.
X = ['True Open','True High','True Low','True Close'] y = 'Target'
Обучим модель на наших рыночных данных.
model = LinearRegression() model.fit(data.loc[:,X],data[y])
Модель, по-видимому, имеет разумное представление о рыночных результатах даже вне выборки.
preds = model.predict(test.loc[:,X]) plt.plot(preds,color='black') plt.plot(test.loc[:,y].values,color='red',linestyle=':') plt.title('Visualizing Our Accuracy Out of Sample') plt.xlabel('Historical Time') plt.ylabel('EURUSD Exchange Rate') plt.legend(['Model Predictions','Observed Exchange Rate']) plt.grid()
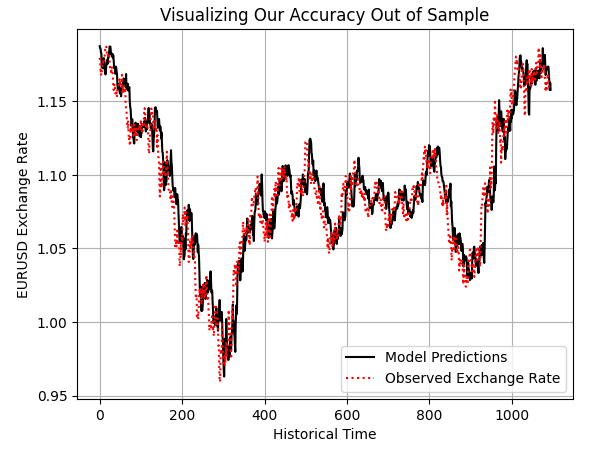
Рисунок 5: Изучаем прогнозы нашей модели вне выборки, чтобы проверить, насколько модель адекватна
Экспортирование в ONNX
Теперь мы готовы экспортировать наши обученные статистические модели в формат ONNX. ONNX (Open Neural Network Exchange) - это общепризнанный API, позволяющий разработчикам создавать и развертывать модели машинного обучения без переноса каких-либо зависимостей из используемой для их создания обучающей среды.Для начала загрузим необходимые библиотеки ONNX.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Далее определим входные и выходные параметры нашей модели. В нашем случае модель принимает четыре входных параметра и выдает один выходной параметр.
initial_types = [('float_input',FloatTensorType([1,4]))] final_types = [('float_output',FloatTensorType([1,1]))]
Далее создадим буфер протокола ONNX — промежуточную структуру, которая хранит нашу модель до окончательного преобразования.
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12) После этого сохраним модель в файл с расширением .onnx, передавая в функцию сохранения ONNX как протокол ONNX protobuf, так и желаемое имя файла.
onnx.save(onnx_proto,"EURUSD 2022-2025 LR.onnx") Установление базового уровня с помощью классических методов
Теперь мы готовы начать разработку своей торговой системы на MQL5. Первым шагом является импорт файла ONNX, который мы только что экспортировали из нашего анализа на Python.
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ru/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ru/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR.onnx" as const uchar onnx_proto[];
Затем загрузим несколько вспомогательных библиотек, которые помогут нам выполнять рутинные задачи, такие как открытие, закрытие и изменение сделок, проверка наличия новых свечей, управление буферами ONNX и другие связанные с этим операции.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *time; TradeInfo *trade; ONNXFloat *onnx_model;
Затем инициализируем несколько глобальных переменных, которые будут использоваться на протяжении всей работы программы.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int atr_handler; double atr[]; float prediction;
Во время инициализации создадим нашу ONNX-модель из буфера, загруженного нами ранее. В предыдущих обсуждениях мы разработали специальную библиотеку для эффективной работы с файлами ONNX. Благодаря этой пользовательской библиотеке значительно сократилось количество шагов настройки, необходимых для загрузки и использования нашей модели ONNX.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_model = new ONNXFloat(onnx_proto); trade = new TradeInfo(Symbol(),PERIOD_CURRENT); time = new Time(Symbol(),PERIOD_D1); atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); if(!onnx_model.DefineOnnxInputShape(0,1,4)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); } if(!onnx_model.DefineOnnxOutputShape(0,1,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
Если модель ONNX или другие выделенные ресурсы больше не используются, необходимо высвободить их надлежащим образом, поскольку это считается передовой практикой при разработке MetaTrader 5.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete onnx_model; delete time; delete trade; }
Всякий раз при поступлении новых ценовых данных мы обновляем буферы наших индикаторов, определяем соответствующие входные параметры для модели ONNX и получаем прогноз. Основываясь на этом прогнозе, мы соответственно открываем или закрываем сделки. При возникновении какой-либо проблемы пользователю выводится сообщение об ошибке.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(prediction > iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } if(prediction < iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
На данный момент мы готовы приступить к тестированию на истории. Начнем с выбора торговой системы, которую хотим протестировать — в данном случае, базовой версии нашей торговой системы. Определим период тестирования, который продлится с 2022 по октябрь 2025 года (на момент написания статьи).

Рисунок 6: Первоначальное базовое тестирование на истории очень важно, оно дает нам ориентир, к которому следует стремиться
Затем определим условия тестирования, при которых стратегия должна оцениваться. Для моделирования реалистичного поведения рынка, мы включаем случайную задержку, которая помогает приблизиться к непредсказуемому характеру реальной торговли.
Рисунок 7: Выберем настройки случайной задержки для реалистичной имитации реальных рыночных условий
Как видно из результатов, стратегия выглядит довольно нестабильной при такой простой настройке. Эти результаты не так уж удивительны, поскольку модель предназначена для прогнозирования только на шаг вперед — эффективного составления прогнозов от сделки к сделке, от свечи к свече. Такой подход не соответствует взглядам обычного трейдера на рынок, и это, естественно, ограничивает реалистичность и надежность системы. Тем не менее, это служит нашим базовым результатом, полученным в соответствии со стандартными лучшими рекомендациями.
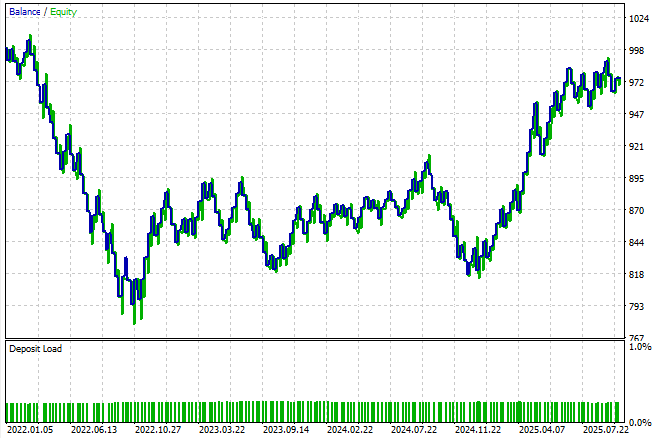
Рисунок 8: Кривая эквити, построенная в соответствии с первоначальной версией нашей торговой системы, призывает нас прикладывать больше усилий
При более тщательном изучении результатов бэктеста мы замечаем, что система работает крайне неэффективно. Она не только постоянно теряет деньги на протяжении всего бэктеста, но и ее распределение сделок также неоптимально и не отражает реального понимания динамики рынка. За трехлетний период статистическая модель открыла 183 длинные позиции и только одну короткую. Этот дисбаланс подчеркивает неспособность модели эффективно интерпретировать рынок и ясно демонстрирует, что мы можем добиться гораздо более высоких результатов, чем могут предложить только стандартные методы машинного обучения.
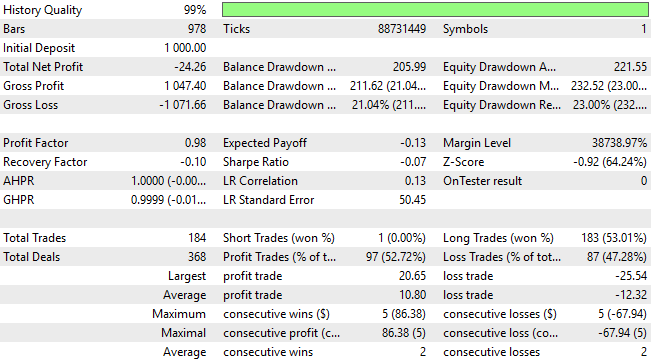
Рисунок 9: Подробная статистика нашей торговой системы раскрывает недостатки традиционного подхода
Улучшение базового уровня с использованием классических методов
Теперь приступим к реализации усовершенствований в нашу торговую систему. Первое усовершенствование, которое можно выполнить, касается горизонта прогнозирования. В целом, прогнозирование всего на один шаг в будущее не отражает того, как работают успешные трейдеры-люди. Поэтому мы расширим наш горизонт прогнозирования на 10 шагов вперед, что должно обеспечить более реалистичный прогноз, чем прогнозирование на один шаг вперёд. На данном этапе остальная часть кода в нашем Jupyter notebook остается неизменной, поэтому мы опустили эти разделы и выделим только те сегменты, которые отличаются.
#Classical Target #V1 value HORIZON = 10
После настройки нашей модели таким образом, чтобы смотреть на 10 шагов вперед, мы сохраняем ее в файл, а затем загружаем обновленную версию в нашу торговую систему.
onnx.save(onnx_proto,"EURUSD 2022-2025 LR V1.onnx") Реализация усовершенствований в нашу торговую систему MetaTrader 5
Как упоминалось ранее, общая структура торговой системы в основном остается прежней. Следовательно, для краткости мы исключаем неизмененные сегменты кода.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR V1.onnx" as const uchar onnx_proto[];
Как только обновленная модель будет внедрена в систему, мы проведем новое тестирование на истории за тот же период, чтобы оценить ее эффективность.
Рисунок 10: Сейчас мы оценим нашу первую попытку превзойти базовую версию нашей торговой системы
Изучая кривую эквити, полученную с помощью этой новой версии нашей системы, мы замечаем, что визуально между двумя версиями почти ничего не изменилось. Однако более пристальный взгляд на подробную статистику позволяет выявить несколько существенных усовершенствований.
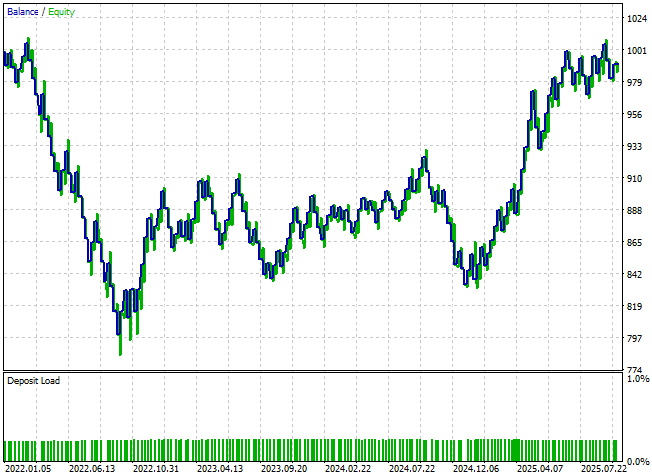
Рисунок 11: Кривая эквити, полученная в результате нашей первой попытки усовершенствовать торговую систему, выглядит идентичной первой системе, с которой мы начинали
Общий чистый убыток значительно снизился — с 24 до 8 долларов, хотя результат по−прежнему остается нежелательным. Более того, общее количество коротких сделок остается на нулевом уровне, что указывает на то, что системе по-прежнему не хватает сбалансированного или всестороннего понимания направления рынка. Таким образом, очевидно, что, хотя внесенные изменения и помогли, все еще есть значительные возможности для усовершенствования.
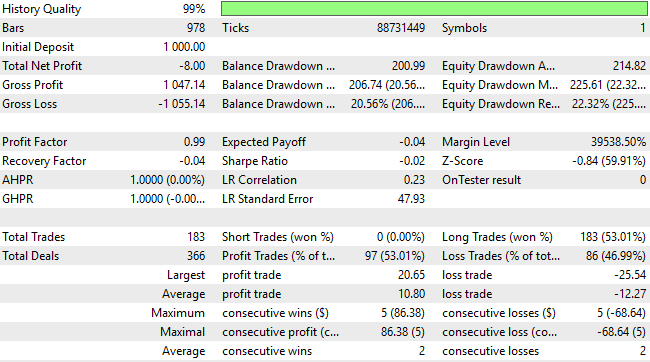
Рисунок 12: Подробный анализ наших новых результатов показывает, что мы добились некоторых усовершенствований, но находимся еще далеко от своих целей
Превосходство над классическими методами
На данный момент мы почти исчерпали принципы классического моделирования. Поэтому сейчас мы начнем отходить от традиционных идеологий и искать усовершенствования, основываясь на выводах, собранных в этой серии статей. Одно особенно важное наблюдение, которое мы сделали, заключается в том, что на большинстве рынков технические индикаторы часто кажутся более удобными для прогнозирования, чем сама цена. Основываясь на этом понимании, теперь мы изменим настройки нашего моделирования, изменив целевую переменную — с будущего значения цены на будущее значение скользящей средней.#Classical Target #V1 value HORIZON = 10 #Label the data data['Target'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Естественно, это изменение требует от нас также пересмотра входного пространства нашей модели. Мы введем четыре новые переменные, описывающие текущее состояние скользящих средних, расширяя наш общий набор функций.
X = ['True Open','True High','True Low','True Close','True MA O','True MA H','True MA L','True MA C'] y = 'Target'
Следовательно, нам также необходимо пересмотреть входную форму нашей модели, чтобы отразить эту обновленную конфигурацию.
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,1]))]
После завершения сохраним новую модель.
onnx.save(onnx_proto,"EURUSD 2022-2025 R V2.onnx") Реализация наших усовершенствований на MQL5
Теперь обновим нашу торговую систему, чтобы она соответствовала обновленной модели ONNX.
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ru/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ru/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V2.onnx" as const uchar onnx_proto[];
Поскольку индикаторы скользящей средней теперь являются частью входного пространства модели, начнем с определения системных констант, определяющих как период, так и тип используемых скользящих средних.
//--- System constants #define MA_PERIOD 5 #define MA_TYPE MODE_SMA
Затем создадим хэндлы индикаторов для непрерывного считывания и обновления последних значений скользящих средних по мере появления новых ценовых уровней.
//---Setup our technical indicators atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW);
Наша процедура открытия сделок также меняется. Сначала мы копируем последние значения индикаторов с четырех хэндлов скользящих средних в соответствующие буферы. Затем, используя функцию из нашей библиотеки OnyxTools под названием DefineInputValues(), подготовим текущие входные признаки для модели ONNX. После этого вызовем функцию OnyxPredict() для получения прогноза, который хранится в переменной с плавающей точкой, под названием "prediction". Сразу после получения прогноза мы сравним прогнозируемое моделью будущее значение скользящей средней с ее текущим значением. Если ожидается рост скользящей средней, мы открываем длинные позиции. Если ожидается её падение, мы откроем короткие позиции.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,1,ma_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(prediction > ma_reading[0]) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(prediction < ma_reading[0]) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
Как и прежде, мы запустим эту новую версию системы на том же тестовом периоде, который модель никогда не видела во время обучения.

Рисунок 13: Прогон нашей пересмотренной торговой системы на том же периоде бэктестирования для оценки усовершенствований
Кривая эквити теперь, наконец, начинает демонстрировать признаки улучшения — формируется восходящий тренд, хотя она все еще демонстрирует некоторую волатильность.
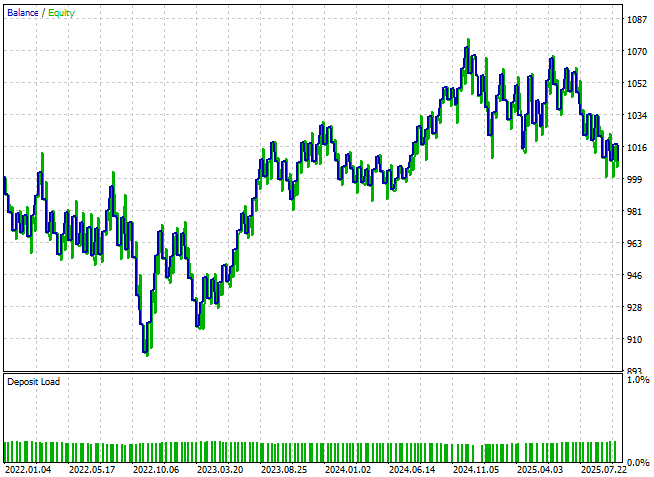
Рисунок 14: Наша система наконец-то впервые превысила уровень безубыточности
При просмотре подробной статистики эффективности мы обнаруживаем, что стратегия превысила уровень безубыточности. В то время как прибыль остается скромной, доля прибыльных сделок превысила 50%, составив около 53%, профит-фактор теперь указывает на положительное математическое ожидание. Очевидно, что эти усовершенствования подталкивают систему в правильном направлении, хотя возможностей для совершенствования еще много.
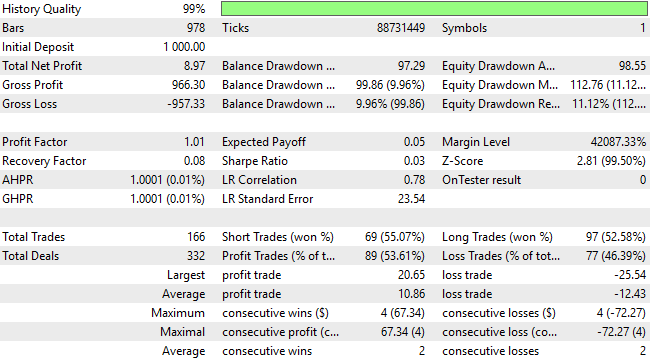
Рисунок 15: По-видимому, система теперь более сбалансированно различает сигналы на покупку и продажу, хотя её прибыльность не является приемлемой
Реализация большего количества усовершенствований
Поскольку мы продолжаем отходить от классических идеологий, можно опереться на еще одно ключевое наблюдение из нашей серии статей, а именно преодоление ограничений искусственного интеллекта. В том исследовании мы заметили, что использование нескольких горизонтов прогнозирования иногда позволяет создавать модели, которые являются более внутренне согласованными, то есть более согласуются сами с собой, чем с реальными данными. Теперь мы проверим, может ли то же самое понимание помочь нам в этом упражнении. Для этого создадим два целевых значения для нашей модели.
А именно, значение индикатора скользящей средней на один шаг вперед и значение того же индикатора на десять шагов вперед. Для тех, кто не читал предыдущую статью, логика, лежащая в основе этого подхода, проста: мы будем использовать наши торговые сигналы исходя из предполагаемого наклона между двумя горизонтами прогнозирования. Другими словами, если ожидается, что скользящая средняя упадет в течение двух прогнозируемых периодов, мы будем продавать. В противном случае, если ожидается её рост, мы будем покупать.
#Classical Target #V1 value HORIZON = 10 #Label the data data['Target 1'] = data['True MA C'].shift(-1) data['Target 2'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
Как и ожидалось, эти перемены изменят выходную форму нашей модели ONNX. Поэтому мы должны обновить определение модели, чтобы отразить новую выходную конфигурацию.
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,2]))]
Затем сохраним и перезагрузим измененную модель в нашей системе.
onnx.save(onnx_proto,"EURUSD 2022-2025 R MFH V3.onnx") Реализация усовершенствований на MQL5
Теперь загрузим обновленный ONNX-файл.//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R MFH V3.onnx" as const uchar onnx_proto[];
После загрузки мы определяем новую форму модели.
if(!onnx_model.DefineOnnxOutputShape(0,2,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); }
Теперь внесём все необходимые коррективы в то, как интерпретируются прогнозы. Важно подчеркнуть, что на данном этапе мы больше не сравниваем прогнозы модели с реальным значением индикатора. Вместо этого мы торгуем исключительно на предполагаемом наклоне между краткосрочным и долгосрочным прогнозами.
if(onnx_model.Predict()) { onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } }
Для тех, кто следит за этим в своей деятельности, я рекомендую поддерживать четкую файловую иерархию. На своей локальной рабочей станции я создал отдельную папку для каждой версии торговой системы. Это помогает поддерживать хорошие стандарты работы и упрощает откат к более ранним версиям при необходимости.
Рисунок 16: Поддержание четкой файловой структуры важно при выполнении итеративных усовершенствований торговой системы
Как только соответствующая версия торговой системы будет готова, мы запустим наши тесты в том же периоде тестирования на истории, что и раньше.
Рисунок 17: Бэктестинг третьей версии нашей торговой системы на тестовом периоде для оценки внесенных нами изменений
Итоговая кривая эквити показывает значительное улучшение по сравнению с нашими первоначальными результатами. Восходящий тренд сейчас гораздо более выражен и доминирует, чем когда мы впервые приступили к этому анализу. Более того, торговая система теперь устанавливает новые максимумы капитала, которые ранее были недостижимы при непосредственном прогнозировании будущих уровней цен. Хотя на кривой баланса сохраняется некоторая волатильность, а полная стабилизация еще не достигнута, общая траектория роста явно укрепилась.
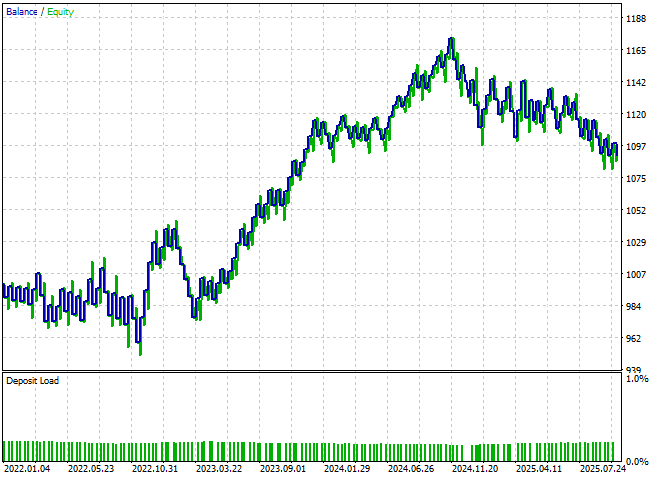
Рисунок 18: Наша новая кривая эквити демонстрирует, что наша система теперь выходит на новые максимумы по капиталу, которых мы не могли достичь ранее.
При рассмотрении подробных результатов мы видим существенные улучшения: система перешла от первоначального убытка в 24 единицы к прибыли в 90 единиц — замечательное преобразование. Это особенно впечатляет, учитывая, что мы не увеличили сложность стратегии и не изменили архитектуру моделирования. Все достижения, полученные на данный момент, связаны исключительно с выявлением лучших методологических решений и отказом от тех, которые больше не служат нашим целям.
Более пристальный взгляд на распределение сделок позволяет получить более глубокое представление. Обновленная версия торговой системы теперь позволяет совершать значительно больше коротких сделок, исправляя один из основных недостатков предыдущей версии, который затруднял выявление возможностей для продажи. Теперь модель классифицирует короткие сделки с точностью около 62%, хотя и остается немного предвзятой — количество длинных позиций примерно в два раза превышает количество коротких. Это требует от нас больших усилий, и мы задаемся вопросом: несмотря на значительное улучшение результатов, есть ли еще возможности для дальнейшего совершенствования?
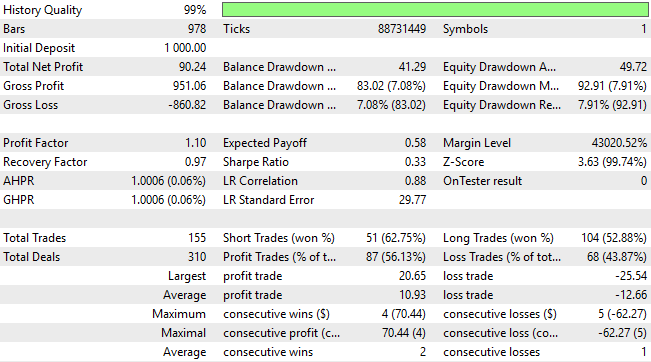
Рисунок 19: Подробный анализ результатов, которые мы получили в третьей версии нашей торговой системы
Поиск возможностей для дальнейших усовершенствований
Теперь мы готовы углубиться в работу над дальнейшими улучшениями нашей торговой системы. После некоторого времени размышлений я пришел к выводу, что мы могли бы добиться лучших результатов, предоставив нашей модели более подробное описание текущего состояния рынка. Чтобы добиться этого, я ввел несколько новых признаков в наш набор данных, доведя общее количество входных переменных до 23. Все 23 признака полностью реализованы с помощью скриптов, представленных в начале этой статьи.
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
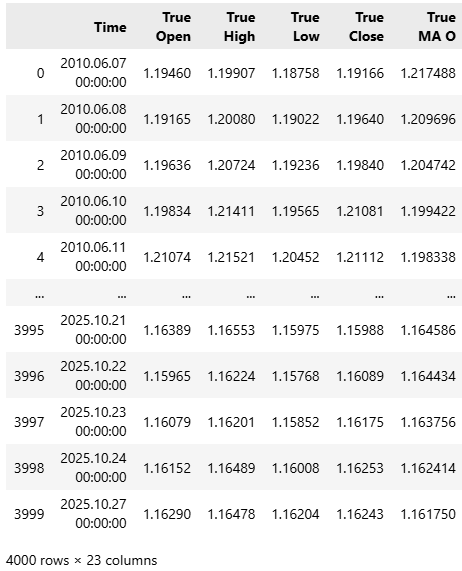
Рисунок 20: Наши обновленные рыночные данные содержат в общей сложности 23 колонки
С учетом этих дополнений теперь мы можем изучить, как изменилась корреляционная структура данных. При сравнении новой тепловой карты с предыдущей, показанной на рис. 3, различия поразительны. На этот раз, если мы сосредоточимся на двух прогнозируемых целевых показателях, мы сможем наблюдать гораздо более надежную и структурированную корреляцию между целевыми показателями и входными параметрами. В отличие от рисунка 3, где целевые переменные показали слабые или противоречивые взаимосвязи с входными параметрами, новая тепловая карта заметно насыщеннее, что указывает на более сильные и значимые зависимости в данных.
Это усовершенствование имеет смысл. Как, возможно, помнит читатель, значения скользящей средней, которые мы сейчас прогнозируем, напрямую зависят от уровней цен. Таким образом, сильная корреляция между скользящими средними и входными параметрами является как ожидаемой, так и желательной, поскольку скользящая средняя по сути агрегирует прошлые цены.
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 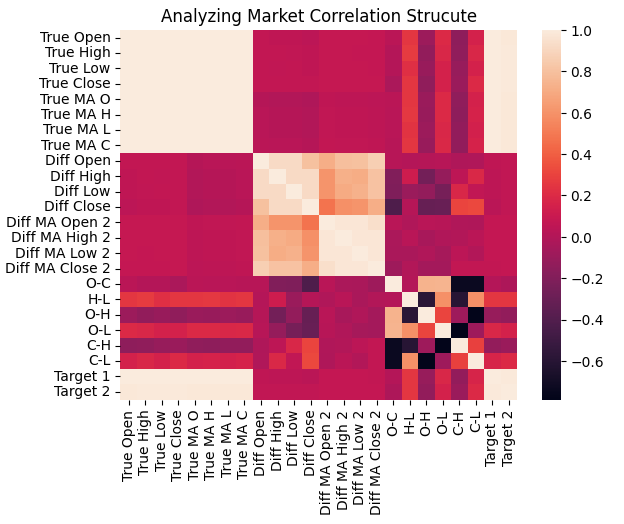
Рисунок 21: Наши обновленные рыночные данные демонстрируют более сильные уровни корреляции, чем те, с которых мы начинали на рисунке 3
Однако, при анализе спектра собственных значений, полученных из корреляционной матрицы этого нового набора данных, возникает более сложная картина. На рисунке 4, представляющем более ранний набор данных, мы наблюдали примерно два доминирующих собственных значения, а третье лишь немного превышало среднее. Это означало, что ранее в системе было два сильных способа выражения, а также третий, относительно незначительный.
Теперь, в обновленном представлении рынка — после добавления новых признаков — мы находим четыре собственных значения, превышающих среднее пороговое значение. Это критически важное наблюдение. Это говорит о том, что наш расширенный набор признаков привнес дополнительные доминирующие режимы динамики, или, проще говоря, более четкие рыночные режимы. Хотя это дает более полное описание рынка, также создается проблема: данные теперь выражают более высокую степень структурной сложности, что может затруднить надежное моделирование. Система, которую мы пытаемся смоделировать, теперь демонстрирует больше режимов и динамического поведения, чем раньше.
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
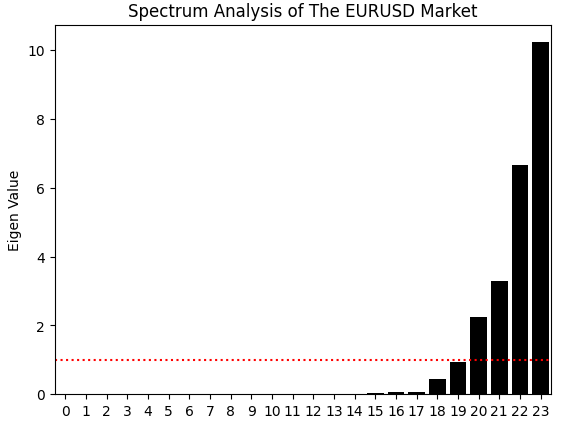
Рисунок 22: К сожалению, похоже, что рыночные данные также становятся все более сложными из-за конкурирующих способов выражения
Тем не менее, мы продолжаем отделять наши входные переменные от целевых.
X = data.iloc[:,1:-2].columns y = ['Target 1','Target 2']
Определим обновленную входную форму для модели.
initial_types = [('float_input',FloatTensorType([1,len(X)]))] final_types = [('float_output',FloatTensorType([1,2]))]
Наконец, сохраним только что обученную модель в файл.
onnx.save(onnx_proto,"EURUSD 2022-2025 R V4.onnx") Для читателей, интересующихся точной конфигурацией, новая модель теперь имеет 22 входных признака.
len(X)
22
Реализуем наши усовершенствования
Как только модель обучена, загрузим ее в торговую систему.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V4.onnx" as const uchar onnx_proto[];
И не забудьте соответствующим образом обновить определение модели ONNX.
if(!onnx_model.DefineOnnxInputShape(0,1,22)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); }
Основное изменение происходит в том, как система обрабатывает новые входящие ценовые данные. Теперь каждый из 22 признаков должен быть определен и индивидуально приведен к плавающему типу, чтобы предотвратить потерю точности при автоматическом усечении данных. Помимо этих корректировок входных данных, логика интерпретации прогнозов модели остается неизменной.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,HORIZON*2,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,HORIZON*2,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,HORIZON*2,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,HORIZON*2,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); onnx_model.DefineInputValues(8,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(9,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(10,(float) iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(11,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(12,(float) ma_o_reading[0] - ma_o_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(13,(float) ma_h_reading[0] - ma_h_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(14,(float) ma_l_reading[0] - ma_l_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(15,(float) ma_reading[0] - ma_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(16,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(17,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(18,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(19,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(20,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(21,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
Затем выполним тестирование на истории за тот же период оценки, что и раньше.
Рисунок 23: Запуск четвертой версии нашей торговой системы в течение того же периода тестирования на истории
К сожалению, итоговая кривая эквити практически не показывает улучшений. Показатели практически не изменились, а итоговый результат по счету оказался ниже.
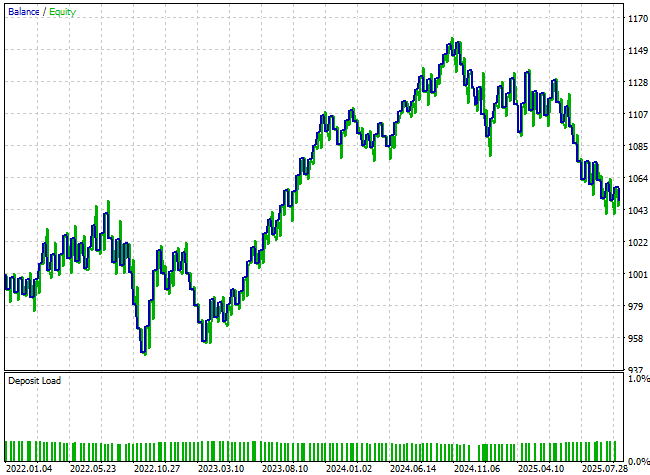
Рисунок 24: Новые признаки, которые мы добавили, по-видимому, сделали очень мало для того, чтобы наша модель лучше отражала состояние рынка.
Более пристальный взгляд на подробную статистику эффективности показывает, что сейчас мы приближаемся к области убывающей отдачи. Снизилась как общая чистая прибыль, так и общая точность работы торговой системы. Напомним, что одной из наших главных задач было помочь системе выявить больше возможностей для открытия коротких позиций, поскольку в предыдущей версии было открыто почти в два раза больше длинных позиций, чем коротких. Однако этот дисбаланс все еще сохраняется — модель по-прежнему благоприятствует долгосрочным сделкам, а желаемое усовершенствование в коротких позициях еще не достигнуто.
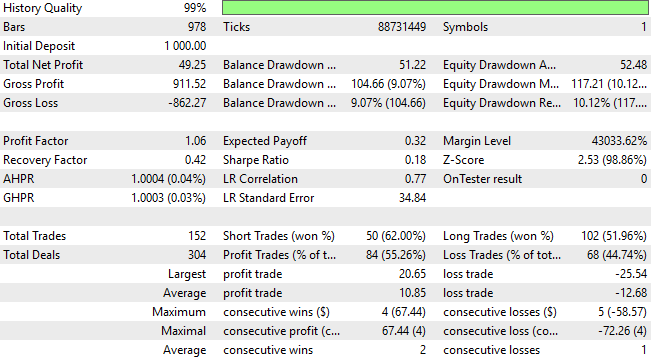
Рисунок 25: Наши подробные результаты показывают, что наши новые признаки, возможно, снижают наш доход
Последняя попытка усовершенствований
Возможно, внедренные нами 22 признака, были нелинейно связаны друг с другом. В результате жесткая линейная модель, на которую мы до сих пор опирались, возможно, оказалась недостаточно гибкой, чтобы охватить эти сложные взаимосвязи. Чтобы решить эту проблему, мы теперь определяем более мощную нелинейную модель, а именно Случайный лес. Случайный лес работает путем построения ансамбля из нескольких деревьев решений и последующего усреднения их выходных данных. Это позволяет ему изучать нелинейные взаимодействия и улавливать более тонкие зависимости в данных, которые линейные модели могут упускать из виду.
from sklearn.ensemble import RandomForestRegressor
Теперь мы обучим свою новую нелинейную модель на том же наборе данных.
model = RandomForestRegressor(random_state=0,max_depth=5,n_estimators=50) model.fit(data.loc[:,X],data[y])
Наконец, экспортируем её в ONNX-файл.
onnx.save(onnx_proto,"EURUSD 2022-2025 RFR V5.onnx") Реализация изменений на MQL5
Загрузим обновленную ONNX-модель, которую только что экспортировали.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 RFR V5.onnx" as const uchar onnx_proto[];
Как только модель загружена, мы снова запустим торговую систему в том же периоде тестирования на истории, что и раньше.

Рисунок 26: Запуск окончательной версии нашей торговой системы в течение того же периода тестирования
К сожалению, результаты показывают, что, хотя прибыльность немного улучшилась по сравнению с предыдущей версией, эффективность остается значительно ниже оптимальных результатов, достигнутых при использовании торговой стратегии версии 3. Более того, при анализе распределения коротких и длинных сделок, мы обнаруживаем, что качество сигнала снова ухудшилось. Соотношение коротких и длинных сделок ухудшилось, что указывает на то, что модель вновь теряет способность эффективно выявлять возможности для продажи. Другими словами, мы, похоже, прилагаем больше усилий только для того, чтобы догнать более простую модель, реализованную в версии 3, которая позволила добиться более сильных и стабильных результатов при меньшей сложности.
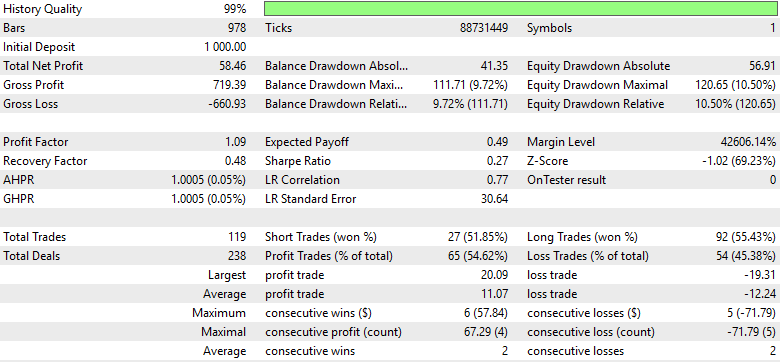
Рисунок 27: Подробный анализ окончательной версии нашей торговой системы показывает, что мы снижаемся по сравнению с нашими пиковыми показателями эффективности
При рассмотрении кривой эквити, полученной в этой последней версии, мы не наблюдаем существенного улучшения стабильности или прибыльности. Этот результат дает нам уверенность в том, что, вероятно, мы достигли естественной точки остановки в нашем исследовании все более сложных моделей. Поэтому, возможно, наиболее разумным будет вернуться к версии 3 торговой системы и использовать ее в качестве стабильной базовой версии для будущих экспериментов.
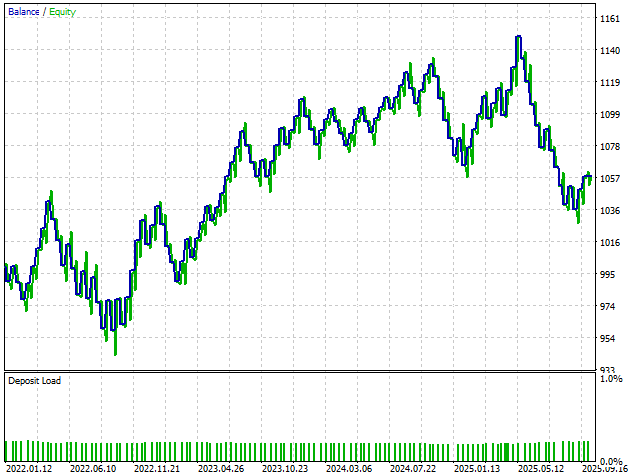
Рисунок 28: Итоговая кривая эквити, которую мы получили из финальной версии нашей торговой системы, говорит о том, что третья версия была оптимальной
Заключение
Ознакомившись с этим обсуждением, читатель получит более глубокое представление об истинных проблемах, которые ограничивают прибыльность и потенциал статистических моделей в финансовой области. Важно отметить, что успех в меньшей степени зависит от сложности модели и в большей степени от методологии — от того, как модели разрабатываются, применяются и интерпретируются.
Использование самых совершенных моделей или самых больших наборов данных не гарантирует лучших результатов; это может даже привести к ненужным затратам и убывающей отдаче. Простая модель, применяемая с умом, часто превосходит сложную, построенную на ошибочных предположениях. Эффективность модели определяется не только математикой, но и целями, системой оценки и выбором дизайна, которые на нее накладываются. Во многих случаях методология сама по себе является скрытым ограничением — “слоном в комнате”.
На протяжении десятилетий финансовое моделирование опиралось на фиксированные взаимосвязи и жесткие горизонты прогнозирования, несмотря на то, что рынки по своей сути динамичны. Когда модели терпят неудачу, это часто происходит не потому, что они не могут учиться, а потому, что перед ними ставится неправильная цель или их обучают с помощью неверного подхода.
Это обсуждение подчеркивает важность тщательного экспериментирования, усердия и методологической строгости при применении машинного обучения в сфере финансов. Когда прогресс застопоривается, решение не всегда заключается в более масштабной модели или большем количестве данных; иногда ключевым моментом является просто определение лучшей цели или совершенствование процесса. Продуманная методология, а не просто сложность, раскрывает истинный потенциал статистических моделей.
| Название файла | Описание файла |
|---|---|
| Benchmark.mq5 | Базовая версия нашей торговой системы не была прибыльной, но позволила нам установить ключевые показатели эффективности, чтобы превзойти их. |
| V1.mq5 | Первая версия нашей торговой системы была создана в соответствии с классическими методами, но при тестировании на истории не дала положительных результатов. |
| V2.mq5 | Вторая версия нашей торговой системы отошла от классических методов моделирования и с незначительным успехом смоделировала индикатор скользящей средней. |
| V3.mq5 | Лучшая версия торговой системы, которую мы обнаружили в ходе нашего обсуждения, моделировала индикатор скользящей средней на нескольких горизонтах и торговала с учетом предполагаемого наклона. |
| V4.mq5 | Четвертая версия торговой системы сохранила ту же цель, что и третья версия, но использовала больше данных. Это изменение в методологии ограничило нашу прибыльность. |
| V5.mq5 | В финальной версии нашей торговой системы для моделирования более крупного набора данных использовался нелинейный алгоритм обучения. Хотя она оказалась более прибыльной, чем четвертая версия нашей торговой системы, она не смогла сравниться по результатам с третьей версией. |
| Deep_Analysis_V5.ipynb | Для анализа рыночных данных, полученных для нашего обсуждения, мы использовали Jupyter Notebook. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20090
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования