
От начального до среднего уровня: Произвольный доступ (I)

Введение
В предыдущей статье, От начального до среднего уровня: FileSave и FileLoad, мы обсудили библиотечные функции FileLoad и FileSave, и было дано хорошее вводное объяснение. Хотя многие считают их малоперспективными из-за некоторых трудностей, которые они создают при выполнении определенных операций, они весьма полезны, когда речь идет о генерации лог-файлов. Эти файлы, для тех кто не знает, служат для того, чтобы мы понимали, как на самом деле работает наш код в определенных сценариях, и являются крайне полезным инструментом для любого разработчика.
Несмотря на это, функции FileSave и FileLoad в основном ориентированы на реализацию, при которой доступ к данным файлов будет последовательным. Это объясняется самим принципом работы этих функций. Однако зачастую большинство разработчиков реализуют произвольный доступ к файлу, даже несмотря на то, что функции FileLoad и FileSave могут обеспечить такой доступ косвенно, загружая и сохраняя весь файл в памяти.
Поэтому, даже если возможно создать произвольный доступ, он фактически не будет осуществляться привычным способом. В данном случае цель состоит в том, чтобы загружать только необходимые части файла небольшими блоками. Такая ситуация, хотя и кажется бессмысленной во времена, когда компьютерная память достаточно дешева, чтобы хранить в ней большие файлы, может быть очень полезной во многих других сценариях, где цель состоит в том, чтобы фрагментировать файл определенным образом.
Произвольный доступ к файлам (Часть 1)
Если вы изучите документацию различных языков программирования, чтобы проверить встроенные в них процедуры и функции, и уделите особое внимание разделу работы с файлами, то заметите, что зачастую языки предоставляют гораздо больше возможностей, чем вам реально понадобится или вы будете использовать на практике. Некоторые языки, как, например, C++, имеют очень небольшое количество функций и процедур для работы с файлами.
Однако в случае с C++ мы располагаем средствами ввода-вывода, которые можно расширять и использовать для других задач, что позволяет использовать более выразительный, условно-символьный синтаксис. В будущем мы обсудим подобные ресурсы здесь, в MQL5. Пока давайте остановимся на основах, так как нет смысла усложнять всё раньше времени.
Тогда, если вы посмотрите документацию MQL5, вы заметите, что там существует множество различных функций и процедур, предназначенных как для чтения, так и для записи данных в файлы. Самыми простыми методами являются FileLoad и FileSave, которые были представлены и объяснены в предыдущей статье. Однако, как уже указывалось во введении к этой статье, данные методы не предназначены для произвольного доступа к содержимому файла. Именно поэтому в документации MQL5 упоминается несколько других методов, поскольку их цель состоит именно в том, чтобы обеспечить произвольный доступ к содержимому любого файла.
Что ж, это частично объясняет присутствие стольких различных методов, описанных в документации. Однако это не объясняет, как работать с этими методами, а также не объясняет, как мы можем обрабатывать типы данных, реализованные программистом. Да, уважаемый читатель, вы, как программист, не ограничены работой только с типами, определенными в языке программирования. Хорошие языки программирования, такие как MQL5, позволяют нам создавать уникальные типы, ориентированные на специфические ситуации. Возможно, вы не совсем понимаете, о чем я говорю, так как это кажется довольно необычным.
Однако в статьях этой же серии, когда мы говорили о template и typename, мы делали именно это: создавали уникальные типы, специально ориентированные на определенную проблему. Мы также можем использовать объединения и структуры для создания определенного типа, цель которого — создание абстракции для специальных данных.
Итак, этим мы сознательно вводим ограничение, чтобы упростить то, что будет рассмотрено далее. Поскольку цель состоит в том, чтобы максимально дидактично показать, как выполнять определенные виды операций, объяснение каждой из тех функций и процедур для работы с файлами, которые мы видели в документации MQL5, становится совершенно излишним, так что мы можем сосредоточиться на одном подходе к моделированию.
Таким образом, материал, который будет представлен здесь, ни в коем случае не должен рассматриваться как единственный способ сделать это. В зависимости от конкретной ситуации, использование функции или процедуры из стандартной библиотеки MQL5 будет, безусловно, наилучшим способом решения определенных типов задач. Это объясняется тем, что процесс в таком случае становится более прямым, а не косвенным, направленным на получение решения другого типа.
Тем не менее, мы ограничимся использованием лишь нескольких функций и процедур. Однако это не помешает экспериментировать с другими функциями или процедурами, чтобы понять работу более специфических операций в стандартной библиотеке MQL5. Итак, уважаемый читатель, постарайтесь увидеть и представить возможности, выходящие за рамки того, что будет показано здесь. Потому что мы можем получить одинаковые результаты, используя немного разные методы. Хотя те или иные методы могут быть понятнее разным программистам. Итак, начнём с кода, показанного ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Код 01
Теперь, когда мы запустим код 01, мы увидим, что файл будет создан в соответствующей песочнице среды исполнения. Я полагаю, что у вас, уважаемый читатель, не должно возникнуть трудностей с пониманием того, о каком файле идет речь и где он будет создан. Однако, есть одна деталь, касающаяся содержимого данного файла. Вот где начинается самое интересное.
Обратите внимание на следующее: В этом коде 01 мы указываем в строке 08, что файл открывается в режиме записи. В случае успеха переменная получит значение, которое можно будет использовать для работы с файлом. До этого момента всё было очень просто. Настолько, что для обозначения завершения операций, выполняемых с файлом, мы используем строку 18, цель которой — закрыть файл, освободив его для использования в любых других целях. Однако по-настоящему нас интересует участок между строками 13 и 16. Именно туда мы записываем данные в файл.
Прежде чем рассматривать, как можно выполнить чтение, давайте разберемся с этим вопросом касательно записи. Потому что это гораздо важнее, чем может показаться на первый взгляд.
Мы ясно видим, что именно хотим записать в файл, поскольку всё содержимое очень простое и понятное. И все-таки возникает вопрос, что же на самом деле записывается в файл? Чтобы ответить на этот вопрос, мы можем взглянуть на содержимое файла ниже:

Изображение 01
На изображении 01 показан результат операций записи в файл. "Подождите, это содержимое кажется немного странным". Давайте тогда рассмотрим тот же файл, что и на изображении 01, но в бинарном формате. Можно увидеть его ниже:
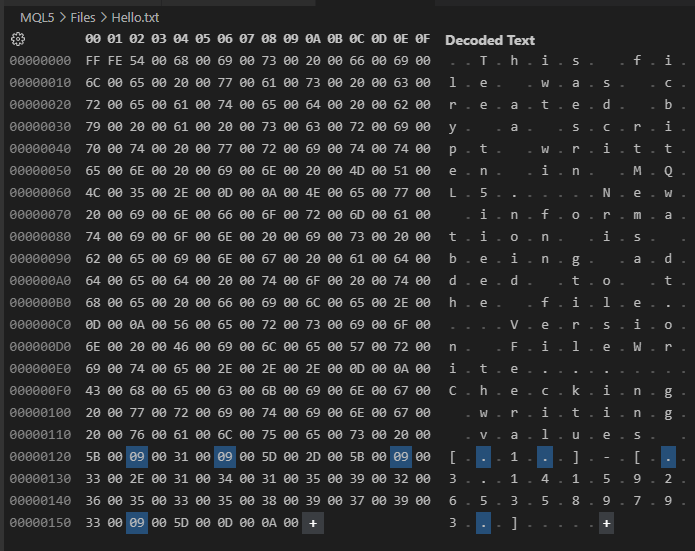
Изображение 02
А теперь, обратите внимание, уважаемый читатель: содержимое изображения 02 в точности совпадает с содержимым изображения 01. Однако на изображении 02 мы видим каждый байт файла, записанный кодом 01. Обратите внимание на нечто интересное на изображении 02, что может стать решающим фактором между чтением корректного значения и чтением совершенно ошибочного значения, когда мы будем выполнять чтение с произвольным доступом.
Хотя мы ничего не указывали в начале файла, и это видно на изображении 01 и в коде 01, в начале показанного на изображении 02 файла, мы видим два странных байта, которые не имеют особого смысла. Эти байты предназначены для указания типа формата и в данном случае нас не интересуют. При этом в коде 01 ясно видно, что явно они нигде не задаются. Однако здесь присутствуют и другие символы, которые также не встречаются в коде 01. Это символы возврата каретки и новой строки.
На этом же изображении 02 выделены некоторые байты. Почему? Они вставляются для разделения/выравнивания данных, записываемых в строке 16 кода 01, символами табуляции. Крайне важно понимать значение этих символов табуляции. Потому что, в зависимости от типа записываемого содержимого и, главным образом, от цели, для которой создается файл, эти лишние символы могут полностью уничтожить любую возможность корректно прочитать файл в дальнейшем. Возможно, вы не ожидаете присутствия этих символов, и в итоге они разрушат систему индексации в момент чтения данных.
"Хорошо, я понял, что не всегда то, что написано в коде, действительно будет представлено точно так же при записи в файл. Но всегда ли это так?" Всё зависит от ситуации, уважаемый читатель. Обратите внимание: если мы изменим код 01 на код, показанный ниже, результат может быть совершенно другим:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileClose(handle); 19. 20. Print("Success"); 21. } 22. //+------------------------------------------------------------------+
Код 02
Теперь обратите внимание: единственное различие между кодом 01 и этим кодом 02 заключается как раз в дополнительном значении, которое мы добавили в функцию FileOpen. И только из-за этого простого изменения посмотрите, что происходит, когда код 02 создает файл. Это можно заметить, сравнив показанное ниже изображение 03 с изображением 02:
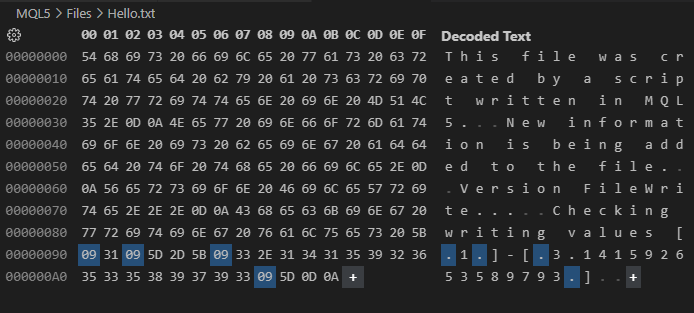
Изображение 03
"Ух ты! А я-то думал, что небольшие изменения в коде не сильно повлияют на результат". Уважаемый читатель, есть вещи, которые вы сможете по-настоящему понять только поэкспериментировав и увидев их применение на практике. Одна из них — как раз та, которую вы только что наблюдали своими глазами. Именно поэтому я и советую вам стараться практиковаться и изучать содержание статей, пытаясь применить материал немного иначе, но самое главное — проверять, что происходит при изменении определенных элементов кода.
Продолжая тему, обратите внимание, что результат, представленный на изображении 03, гораздо ближе к тому содержимому, которое можно было бы ожидать, глядя на код 02. Но даже при этом у нас остается вопрос с символами табуляции, возврата каретки и новой строки, которые всё ещё продолжают появляться. Почему так происходит? Причина заключается в том, что мы не запрашиваем запись файла в бинарном режиме.
В любом случае, мы внесем небольшое изменение в код. Это делается для того, чтобы прочитать определенную точку файла, просто чтобы проверить одну небольшую деталь, которую вам важно понять ещё до перехода к бинарной записи файла.
Не понимая, когда файл следует записывать в двоичном, а когда в обычном текстовом режиме, довольно сложно сделать правильный выбор на разных этапах реальной реализации.
Чтобы мы могли наглядно увидеть то, что я хочу показать, нам необходимо создать новый код. Данный код приведен ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Код 03
Этот код 03, помимо того что позволяет нам записывать файл, точно так же как это делал код 02, также позволяет нам читать содержимое файла. Чтобы всё прошло гладко и вы поняли, что нас ждёт дальше, сначала нужно разобраться, чего ожидать от выполнения кода 03.
По сути, будет записан тот файл, который мы видим на изображении 03. Чтобы гарантировать, что файл действительно содержит ожидаемую информацию, мы используем строку 18 для сброса буфера в файл на диске. Эта операция, показанная в строке 18, в определенные моменты может оказаться излишней. В зависимости от того, насколько операционная система загружена операциями чтения или записи на диск, запись, выполняемая строками с 13 по 16, может происходить в режиме реального времени. Однако в какой-то момент этого может и не произойти. Поскольку я не хочу закрывать файл, чтобы потом снова открывать его для чтения сохраненных данных, мы используем эту библиотечную функцию в строке 18, чтобы "принудительно" осуществить немедленный сброс данных в файл.
Что ж, как только это сделано, у нас появляется определенная гарантия того, что файл действительно будет содержать данные, которые можно увидеть на изображении 03. Теперь переходим к чтению. Поскольку указатель файла был изменен и теперь находится в конце, нам нужно переместить его в другое место. В данном случае мы укажем на начало файла. Для этого мы используем строку 20, где буквально перемещаем указатель чтения и записи в начало файла на диске. Обратите внимание на это, уважаемый читатель. Чтение, которое мы выполним, будет производиться не из содержимого буфера, а из самого файла.
Это относится как к записи, так и к чтению: мы можем использовать метод чтения, показанный в строке 21, где чтение будет выполняться до тех пор, пока не будет достигнут конец файла. Нас здесь действительно интересует то, что делает строка 22. В этой строке мы указываем приложению вывести в терминал MetaTrader 5 содержимое, прочитанное из файла. Именно эта часть нас здесь больше всего и интересует.
Теперь обратите внимание: в нашем случае у нас написано четыре строки. Их можно увидеть на изображении 01. Тогда, очевидно, при выполнении строки 22 кода 03 мы получим в терминале выведенный результат, похожий на тот, что показан на изображении 01. Однако, если посмотреть на терминал MetaTrader 5, то увидим нечто похожее на изображение 04 ниже:
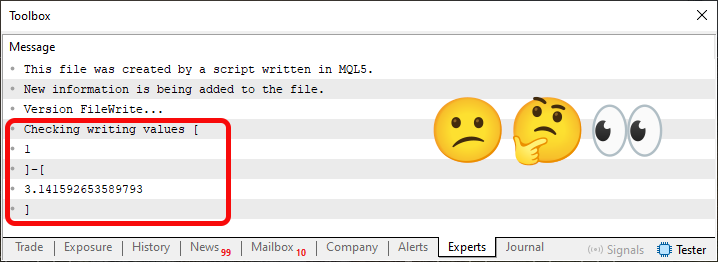
Изображение 04
"Ммм, странно. Судя по всему, первые три строки отображаются корректно. Однако область, отмеченная красным, показывает нам данные, отличающиеся от ожидаемых. Очень странно". Что ж, уважаемый читатель, хотя это может показаться так, представленный результат, в принципе, очень хорош для нас. Однако я хочу напомнить всем, что здесь мы делаем это максимально простым способом, как раз для того, чтобы найти ответ на то, что в принципе все сделали бы, но что в итоге привело бы к отличающимся от ожидаемых результатов.
Но здесь мы видим такой результат, несколько странный, именно из-за символа табуляции. "Но подождите, как это возможно?" Итак, уважаемый читатель, поскольку мы читаем файл в небинарном режиме, функция FileReadString прекратит чтение, как только обнаружит комбинацию символа возврата каретки и символа новой строки, а также символ табуляции. Достаточно обратиться к документации за подробностями, хотя там и упоминается использование CSV-файлов. В принципе, в данном случае это не так, поскольку содержимое файла не предназначено для представления формата CSV.
Что ж, здесь снова есть чему поучиться. Так происходит, потому что среди флагов чтения файла тот факт, что мы не указали, какой тип данных должна анализировать операция чтения в строке 22, приводит к интерпретации, при которой во время чтения учитываются символы табуляции. Таким образом, для решения этого вопроса нам необходимо ещё раз изменить код, использовав тот вариант, который приведен ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. FileWrite(handle, "This file was created by a script written in MQL5."); 14. FileWrite(handle, "New information is being added to the file."); 15. FileWrite(handle, "Version FileWrite..."); 16. FileWrite(handle, "Checking writing values [", 1, "]-[", M_PI, "]"); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Код 04
Обратите внимание, что, как уже говорилось, нам нужно изменить только один пункт кода. Это строка 08, которую можно увидеть в коде 04. Однако, даже при этом, результат сильно отличается от того, что было видно на изображении 04. В этом случае при выполнении кода 04 в терминале отобразится следующее:
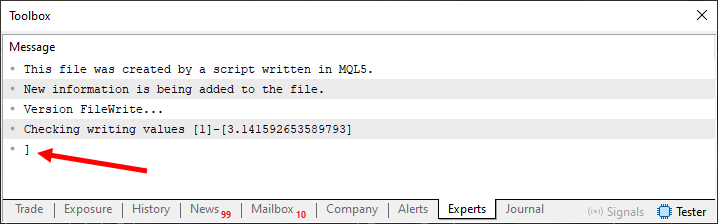
Изображение 05
Прошу заметить, что в данном случае содержимое очень похоже на то, чего мы ожидали, глядя на часть кода, отвечающую за запись. Конечно, у нас возникла небольшая проблема, ее можно увидеть на изображении 05. Но это второстепенная проблема, поскольку цель, в некотором роде, можно считать достигнутой. Цель как раз и заключалась в том, чтобы прочитать файл таким образом, чтобы получить нечто очень похожее на текст, который присутствует между строками 13 и 16 кода 04.
Отлично, теперь, когда это сделано и наглядно показано, мы можем начать думать о вопросе бинарного чтения и записи. Это позволяет нам перейти к произвольному доступу к содержимому файла. Однако такой тип содержимого, который мы записываем и читаем из файла, из-за своей большой схожести с обычным повседневным текстом, не совсем подходит для наглядной и простой демонстрации того, как на практике осуществляются бинарные операции и операции произвольного доступа. Для этого, а также в качестве первого шага и для получения первоначального и базового представления по данной теме, нам необходимо изменить содержимое на что-то немного более простое. Это делается с помощью кода, показанного ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 0, SEEK_SET); 19. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 20. 21. FileClose(handle); 22. } 23. //+------------------------------------------------------------------+
Код 05
При выполнении этого кода 05 будет создан файл со значениями от нуля до девяти, как это делается в строке 14. Но есть одна небольшая деталь, и крайне важно, чтобы вы её хорошо поняли. Обратите внимание, что при записи мы указываем, что записываемое значение имеет тип CHAR_VALUE. Понимание этого очень важно, потому что по умолчанию эта функция будет записывать значения типа INT_VALUE. "Но подождите, я не понимаю, почему нам важно это понимать. Что ж, чтобы понять важность этой информации, необходимо вспомнить или, точнее говоря, нужно, чтобы вы уже понимали, как работать с объединениями.
В этой серии были опубликованы две базовые статьи об объединениях, и одна из них — От начального до среднего уровня: Объединение (I) . Помимо этих знаний, вам также потребуется понимать, как работать с массивами. Это также объяснялось в других статьях этой же серии. Учитывая, что вы обладаете всеми необходимыми знаниями, описанными в предыдущих статьях, мы можем попытаться понять, почему при выполнении этого кода 05 мы получим результат, приведенный ниже:
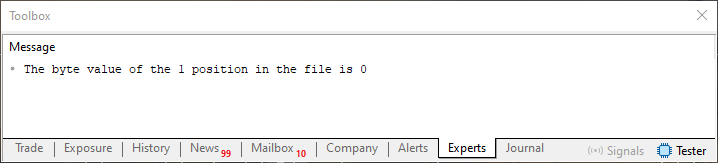
Изображение 06
Хорошо, при выполнении строки 19 из кода 05 отобразится нечто похожее на то, что показано на изображении 06. Но что означает это сообщение, выведенное на терминал? Как видите, в этом сообщении выведены два числовых значения. Первое значение указывает на текущую позицию в файле. Второе значение относится к содержанию конкретной позиции. Теперь слушайте внимательно. При таком способе чтения файл следует рассматривать как массив, иными словами, это массив, индекс которого автоматически увеличивается. Мы также можем указать индекс внутри данного массива, и это делается с помощью строки 18.
Точно так же, как отсчет в массиве начинается с нулевого индекса, когда мы собираемся получить доступ к данным в файле, индекс тоже начинается с нуля. Однако, в отличие от ситуации, когда мы указывали индекс за пределами массива, здесь, при работе с файлами, система всегда будет устанавливать индекс в корректную позицию. Попробуйте код 05, чтобы понять его, заменив нулевое значение, используемое в функции в строке 18, на другие значения. Посмотрите на результат. Это поможет вам понять, как осуществляется доступ к данным.
Но здесь необходимо также понять еще один аспект. Обратите внимание, что FileReadInteger также использует CHAR_VALUE. Это связано с тем, что мы хотим прочитать всего один байт. Обычно считывались бы четыре байта, что продвинуло бы индекс или позицию в файле на те же самые четыре байта. Обратите самое пристальное внимание на упоминаемые мной детали. Именно по этой причине понимание объединений очень поможет в осмыслении такого способа доступа к данным файла.
Прежде чем переходить к следующему шагу, хорошенько протестируйте код 05, пока действительно не поймете, как он работает, то есть пока не осознаете, что файлы — это не что иное, как массивы, сохраненные на диске. Как только вы это усвоите, вам будет гораздо проще понять, что мы будем делать дальше.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_BIN)) == INVALID_HANDLE) 09. { 10. Print("Error..."); 11. return; 12. }; 13. for (uchar c = 0; c < 10; c++) 14. FileWriteInteger(handle, c, CHAR_VALUE); 15. 16. FileFlush(handle); 17. 18. FileSeek(handle, 4, SEEK_SET); 19. FileWriteInteger(handle, 45, CHAR_VALUE); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 4, SEEK_SET); 24. Print("The byte value of the ", FileTell(handle), " position in the file is ", FileReadInteger(handle, CHAR_VALUE)); 25. 26. FileClose(handle); 27. } 28. //+------------------------------------------------------------------+
Код 06
Теперь посмотрите на код 06. Как вы увидите, он очень похож на код 05. Однако здесь мы делаем кое-что, что выходит немного за рамки кода 05, так как записываем в файл с помощью абсолютно произвольного доступа. Здесь кроется одна не самая смешная шутка, если вы так и не смогли закрепить концепцию массива совместно с концепцией файла. Это происходит, потому что в этом коде 06 мы можем выполнить операцию, которая была бы невозможна, если бы мы действительно работали с массивами. По крайней мере, если работать с массивами так, как это обычно делается в большинстве случаев.
Прежде чем объяснять код 06, давайте посмотрим на результат его выполнения. Данный код приведен ниже:
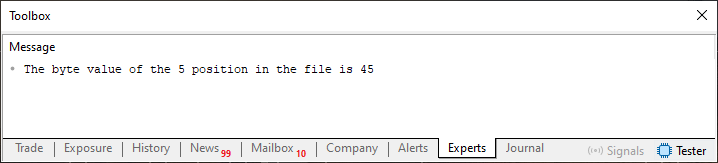
Изображение 07
А теперь самое интересное: понять, как было получено это сообщение с изображения 07. Во-первых, обратите внимание, что единственные изменения в коде 06 по сравнению с кодом 05 касаются строк 18 и 19. Эти две строки используются для изменения значения определенной позиции в файле. Это было бы равносильно указанию нового значения в заданной позиции внутри массива. До этого момента всё очень просто для понимания, так как указанная позиция находится в пределах того, что создается циклом в строке 13.
Вы можете сделать то же самое, даже не создавая предварительную позицию, или, точнее, вы не ограничены созданием массива до присвоения значения определенной позиции. Помните, что здесь мы имеем дело с файлами. В этом случае можно указать позицию значительно выше верхнего предела массива, и операция всё равно будет работать.
Возможно, это вызвало некоторую путаницу. На практике всё довольно просто. Замените значение функции FileSeek в строке 18 на значение, превышающее десять элементов, созданных циклом в строке 13, например, на 14. Не забудьте также изменить значение в строке 23 на то же значение, которое использовалось в строке 18. В результате выполнения этого кода будет получен результат, показанный ниже:
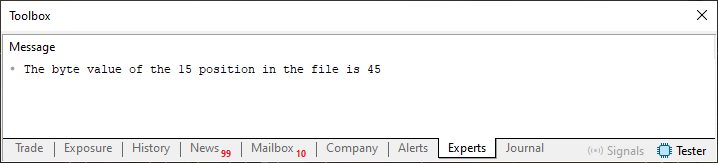
Изображение 08
"Как странно! Я всегда представлял себе, что запись в файл будет производиться байт за байтом, позиция за позицией. Итак, можем ли мы писать где угодно, независимо от того, какие данные существуют заранее?" Это, безусловно, любопытно. Уважаемый читатель, именно такие ситуации делают работу над программированием такой запоминающейся и увлекательной, хотя порой она может показаться несколько запутанной для тех, кто только начинает с ней знакомиться.
Заключительные идеи
В этой статье мы впервые познакомились с файлами с произвольным доступом. Конечно, когда я говорю это, то полагаю, что вы, мой уважаемый читатель, и понятия не имели, что в работе с файлами существует так много тонкостей.
Поскольку в этой статье мы практически полностью сконцентрировались на реализации первой записи в произвольную позицию внутри файла, у нас не было возможности объяснить некоторые детали, связанные с индексацией данных внутри самого файла. И так как этот вопрос очень важен, у нас уже есть тема для обсуждения в следующей статье. Поэтому постарайтесь изучить и закрепить на практике то, что было показано в этой статье, и для этого с пользой примените исходные коды, включенные в приложение. А мы с вами увидимся в следующей статье.
| Файл MQ5 | Описание |
|---|---|
| Code 01 | Демонстрация доступа к файлам |
| Code 02 | Демонстрация доступа к файлам |
| Code 03 | Демонстрация доступа к файлам |
| Code 04 | Демонстрация доступа к файлам |
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/16246
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования